蚂蚁面试:Springcloud核心组件的底层原理,你知道多少?
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
蚂蚁面试:Springcloud核心组件的底层原理,你知道多少?
尼恩特别说明: 尼恩的文章,都会在 《技术自由圈》 公号 发布, 并且维护最新版本。 如果发现图片 不可见, 请去 《技术自由圈》 公号 查找
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团、蚂蚁、得物的面试资格,遇到很多很重要的相关面试题:
说说:蚂蚁面试:Springcloud核心组件的底层原理,你知道多少?越多越好。
说说:Springcloud 生态的基础组件的底层原理?
最近有小伙伴在面试蚂蚁,问到了相关的面试题,可以说是逢面必问。
小伙伴没有系统的去梳理和总结,所以支支吾吾的说了几句,面试官不满意,面试挂了。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V175版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取
总结: Springcloud体系的几个核心组件

Nacos 注册中心的底层原理
与Eureka 、Zookeeper集群不同Nacos 既能支持AP,又能支持 CP。
Nacos 支持 CP+AP 模式,这意味着 Nacos 可以根据配置识别为 CP 模式或 AP 模式,默认情况下为 AP 模式。
- 如果注册到Nacos的client节点注册时ephemeral=true,那么Nacos集群对这个client节点的效果就是AP,采用distro协议实现;
- 而注册Nacos的client节点注册时ephemeral=false,那么Nacos集群对这个节点的效果就是CP的,采用raft协议实现。
根据client注册时的ephemeral属性,AP,CP同时混合存在,只是对不同的client节点效果不同。因此,Nacos 能够很好地满足不同场景的业务需求。
网易一面:Eureka怎么AP?Nacos既CP又AP,怎么实现的?
AP 模式的 Distro 分布式协议
Distro 协议是 Nacos 自主研发的一种 AP 分布式协议,专为临时实例设计,确保在部分 Nacos 节点宕机时,整个临时实例仍可正常运行。
作为一款具有状态的中间件应用的内置协议,Distro 确保了各 Nacos 节点在处理大量注册请求时的统一协调和存储。
Distro 协议 与Eureka Peer to Peer 模式同步过程, 大致是类似的。
Distro 协议的同步过程,大致如下:
- 每个节点是平等的都可以处理写请求,同时将新数据同步至其他节点。
- 每个节点只负责部分数据,定时发送自己负责数据的校验值,到其他节点来保持数据⼀致性。
- 每个节点独立处理读请求,并及时从本地发出响应。
Distro 协议 的具体介绍,请参见42岁老架构师尼恩的文章:
网易一面:Eureka怎么AP?Nacos既CP又AP,怎么实现的?
CP 模式的 Raft 分布式协议
Raft 适用于一个管理日志一致性的协议,相比于 Paxos 协议, Raft 更易于理解和去实现它。
为了提高理解性,Raft 将一致性算法分为了几个部分,包括领导选取(leader selection)、日志复制(log replication)、安全(safety),并且使用了更强的一致性来减少了必须需要考虑的状态。
相比Paxos,Raft算法理解起来更加直观。
Raft算法将Server node划分为3种状态,或者也可以称作角色:
- Leader:负责Client交互和log复制,同一时刻系统中最多存在1个。
- Follower:被动响应请求RPC,从不主动发起请求RPC。
- Candidate:一种临时的角色,只存在于leader的选举阶段,某个节点想要变成leader,那么就发起投票请求,同时自己变成candidate。如果选举成功,则变为candidate,否则退回为follower
Raft 分布式协议中node 状态或者说角色的流转如下:
在Raft中,问题被分解为:
- 领导选举
- 日志复制
- 安全和成员变化。
数据一致性通过复制日志来实现::
-
日志:每台机器都保存一份日志,日志来源于客户端的请求,包含一系列的命令。
-
状态机:状态机会按顺序执行这些命令。
-
一致性模型:在分布式环境中,确保多台机器的日志保持一致,从而使状态机回放时的状态保持一致。
Raft算法选主流程
Raft把集群中的节点分为三种状态:Leader、 Follower 、Candidate,每种状态下负责的任务也是不一样的,Raft运行时只存在Leader与Follower两种状态。
- Leader:负责日志的同步管理,处理来自客户端的请求,与Follower保持heartBeat的联系;
- Follower:刚启动时所有节点为Follower状态。响应Candidate的请求,选举完成后它的责任是响应Leader的日志同步请求,把请求到Follower的事务转发给Leader;
- Candidate:负责选举投票,一轮选举开始时节点从Follower转为Candidate发起选举,选举出Leader后从Candidate转为Leader状态;
Raft中使用心跳机制来出发leader选举。当服务器启动的时候,服务器成为follower。
只要follower从leader或者candidate收到有效的RPCs就会保持follower状态。
如果follower在一段时间内(该段时间被称为election timeout)没有收到消息,则它会假设当前没有可用的leader,然后开启选举新leader的流程。
1.基础概念之 Term 任期
Term任期的概念类比中国历史上的朝代更替,Raft 算法将时间划分成为任意不同长度的任期(term)。
时间划分为不同的Term(任期)。
Term(任期)用连续的数字进行表示。
一个Term包括两个阶段:
-
选举阶段
-
正常阶段。
每个服务器都会保存当前的任期Current Term。用于发送和接受RPC消息时验证比较。
如果一个候选人赢得选举,它将在该任期的剩余时间内担任领导者。
在某些情况下,选票可能会被平分,导致没有选出领导者,此时将开始新的任期并立即进行下一次选举。Raft 算法确保在给定的任期中只有一个领导者。
每次导致新的选举发生,Term就会改变+1。
每次Term的递增都将发生新一轮的选举,Raft保证一个Term只有一个Leader,在Raft正常运转中所有的节点的Term都是一致的,如果节点不发生故障一个Term(任期)会一直保持下去,当某节点收到的请求中Term比当前Term小时则拒绝该请求;
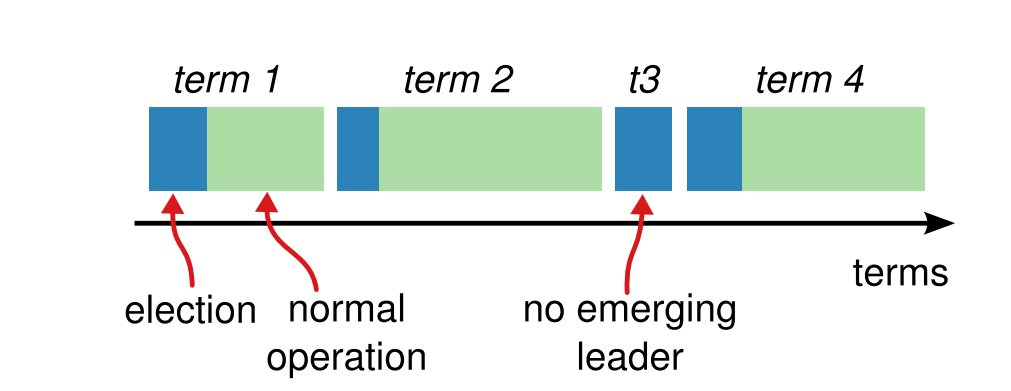
每一个任期的开始都是一次选举(election),一个或多个候选人尝试成为领导者。
2.基础概念之 Log Entry 日志条目
每一个client操作,对于Leader来说,都是增加一个Log Entry,然后复制同步到其他的Server。包括以下数据:
- term Leader收到log时的term
- index log下标。log存储结构是一个List
- command 操作指令
3.基础概念之 RPC
Raft 算法中服务器节点之间通信使用远程过程调用(RPCs),并且基本的一致性算法只需要两种类型的 RPCs,为了在服务器之间传输快照增加了第三种 RPC。
RPC有三种:
- RequestVote RPC:候选人在选举期间发起
- AppendEntries RPC:领导人发起的一种心跳机制,复制日志也在该命令中完成
- InstallSnapshot RPC:领导者使用该RPC来发送快照给太落后的追随者
RequestVote RPC(RequestVote 远程过程调用)通常用于选举领导者或者主节点。在分布式系统中,节点之间需要进行选举以确定领导者,而 RequestVote RPC 就是用来实现选举过程的通信机制之一。
RequestVote RPC 的基本流程如下:
- 节点发送 RequestVote 请求给其他节点,请求它们投票支持自己成为领导者。
- 其他节点收到请求后,会根据自己的选举算法判断是否给予支持。
- 如果其他节点认为该节点可以成为领导者,就会向其发送投票,并更新自己的状态以反映投票结果。
- 请求节点收到足够多的投票后,就可以成为领导者,并开始执行相应的操作。
RequestVote RPC 的内容通常包括:
- 请求节点的ID:用于标识请求的发起者。
- 请求的任期号:用于确保只有最新的领导者才能获得其他节点的投票。
- 候选人的最后日志条目的索引和任期号:用于其他节点判断候选人的日志是否比自己的日志更新,从而决定是否给予投票支持。
- 投票结果:表示其他节点是否投票支持候选人成为领导者。
通过 RequestVote RPC,分布式系统中的节点可以进行选举,确保系统在没有领导者时能够快速选举出新的领导者,从而保证系统的正常运行。

AppendEntries RPC(AppendEntries 远程过程调用)通常用于领导者节点向其他节点发送日志条目,以实现日志复制。这个属于日志增量复制的类型。
领导者节点负责将自己的日志复制给其他节点,以确保系统中的所有节点都拥有相同的日志副本,从而保持数据一致性。
AppendEntries RPC 的基本流程如下:
- 领导者节点将自己的日志条目以 AppendEntries 请求的形式发送给其他节点。
- 其他节点收到请求后,会根据领导者的日志条目信息进行处理,将日志条目追加到自己的日志中。
- 如果其他节点的日志中存在与领导者发送的日志冲突的条目,节点会根据一定的规则进行日志的比较和冲突解决。
- 处理完请求后,其他节点会向领导者发送响应,表示是否成功追加日志条目。
AppendEntries RPC 的内容通常包括:
- 领导者的ID:用于标识发送请求的节点。
- 领导者的任期号:用于确保其他节点只接受来自最新领导者的日志复制请求。
- 领导者的日志条目:包括日志条目的索引、任期号以及具体的日志内容。
- 领导者的前一条日志条目的索引和任期号:用于其他节点在追加日志条目时进行一致性检查。
通过 AppendEntries RPC,领导者节点可以向其他节点发送日志条目,实现日志的复制和一致性维护,从而确保整个分布式系统的数据一致性和正确性。
InstallSnapshot RPC(安装快照远程过程调用)是用于在Raft一致性算法中进行日志复制的一种通信协议,属于日志的全量复制。
在Raft中,当领导者节点发现跟随者节点的日志太过庞大,或者跟随者节点刚刚加入集群时,会通过InstallSnapshot RPC来快速复制日志状态。
InstallSnapshot RPC 的基本流程如下:
- 领导者节点检测到某个跟随者节点的日志太过庞大,或者该节点刚刚加入集群。
- 领导者节点将当前的系统状态(快照)打包,并通过InstallSnapshot RPC将该快照发送给跟随者节点。
- 跟随者节点接收到领导者发送的快照后,将其应用到自己的状态机中,使得自己的状态与领导者节点的状态一致。
- 跟随者节点同时接收到快照的元数据(如快照的最后一个包含的日志索引和任期号等),并根据这些元数据更新自己的日志。
InstallSnapshot RPC 的内容通常包括:
- 领导者的ID:用于标识发送请求的节点。
- 领导者的任期号:用于确保其他节点只接受来自最新领导者的快照。
- 快照数据:包括当前系统的状态信息,如存储的数据、索引等。
- 快照元数据:包括快照的最后一个包含的日志索引和任期号等信息,用于更新跟随者节点的日志状态。
通过InstallSnapshot RPC,Raft算法可以实现在节点之间快速复制大规模的系统状态,从而提高了系统的效率和性能。
Raft 选举流程(Election)
下面两种情况会发起选举
- Raft初次启动,不存在Leader,发起选举;
- Leader宕机或Follower没有接收到Leader的heartBeat,发生election timeout从而发起选举。
Raft初始状态时所有节点都处于Follower状态,并且随机睡眠一段时间,这个时间在0~1000ms之间。
最先醒来的节点 进入Candidate状态,并且发起投票,即向其它所有节点发出requst_vote请求,同时投自己一票,这个过程会有三种结果:
- 自己被选成了主。当收到了大多数的投票后,状态切成leader,并且定期给其它的所有server发心跳消息(其实是不带log的AppendEntriesRPC)以告诉对方自己是current_term_id所标识的term的leader。每个term最多只有一个leader,term id作为logical clock,在每个RPC消息中都会带上,用于检测过期的消息,一个server收到的RPC消息中的rpc_term_id比本地的current_term_id更大时,就更新current_term_id为rpc_term_id,并且如果当前state为leader或者candidate时,将自己的状态切成follower。如果rpc_term_id比本地的current_term_id更小,则拒绝这个RPC消息。
- 别人成为了主。如1所述,当candidate在等待投票的过程中,收到了大于或者等于本地的current_term_id的声明对方是leader的AppendEntriesRPC时,则将自己的state切成follower,并且更新本地的current_term_id。
- 没有选出主。当投票被瓜分,没有任何一个candidate收到了majority的vote时,没有leader被选出。这种情况下,每个candidate等待的投票的过程就超时了,接着candidates都会将本地的current_term_id再加1,发起RequestVoteRPC进行新一轮的leader election。
投票策略:
一个任期内,一个节点只能投一张票,具体的是否同意和后续的Safety有关。
投票选举流程图解
(1)follower增加当前的term,转变为candidate。
(2)candidate投票给自己,并发送RequestVote RPC给集群中的其他服务器。
(3)收到RequestVote的服务器,在同一term中只会按照先到先得投票给至多一个candidate。且只会投票给log至少和自身一样新的candidate。
初始节点
Node1 转为 Candidate 发起选举
Node 确认选举
Node1 成为 leader,发送 Heartbeat
candidate节点保持(2)的状态,直到下面三种情况中的一种发生。
- 该节点赢得选举,即收到大多数节点的投票,然后转变为 leader 状态。
- 另一个服务器成为 leader,即收到合法心跳包(term 值大于或等于当前自身 term 值),然后转变为 follower 状态。
- 一段时间后仍未确定胜者,此时会启动新一轮的选举。
为了解决当票数相同时无法确定 leader 的问题,Raft 使用随机选举超时时间。
Raft 日志复制
当 Leader 选举产生后,它开始负责处理客户端的请求。
所有的事务(更新操作)请求都必须先由 Leader 处理。日志复制(Log Replication)就是为了确保执行相同的操作序列所做的工作。
日志复制(Log Replication)的主要目的是确保节点的一致性,在此阶段执行的操作都是为了确保一致性和高可用性。
在 Raft 中,当接收到客户端的日志(事务请求)后,先把该日志追加到本地的Log中,然后通过heartbeat把该Entry同步给其他Follower,Follower接收到日志后记录日志然后向Leader发送ACK,当Leader收到大多数(n/2+1)Follower的ACK信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端并在下个heartbeat中Leader将通知所有的Follower将该日志存储在自己的本地磁盘中。
Leader选举出来后,就可以开始处理客户端请求。流程如下:
- Leader收到客户端请求后,leader会把它作为一个log entry,append到它自己的日志中。并向其它server发送AppendEntriesRPC(添加日志)请求。
- 其它server收到AppendEntriesRPC请求后,判断该append请求满足接收条件,如果满足条件就将其添加到本地的log中,并给Leader发送添加成功的response。
- 如果某个follower宕机了或者运行的很慢,或者网络丢包了,则会一直给这个follower发AppendEntriesRPC直到日志一致。
- Leader在收到大多数server添加成功的response后,就将该条log正式提交。提交后的log日志就意味着已经被raft系统接受,并能应用到状态机中了。每个日志条目也包含一个整数索引来表示它在日志中的位置。
日志由有序编号的日志条目组成。
每个日志条目包含它被创建时的任期号(每个方块中的数字),并且包含用于状态机执行的命令。任期号用来检测在不同服务器上日志的不一致性。
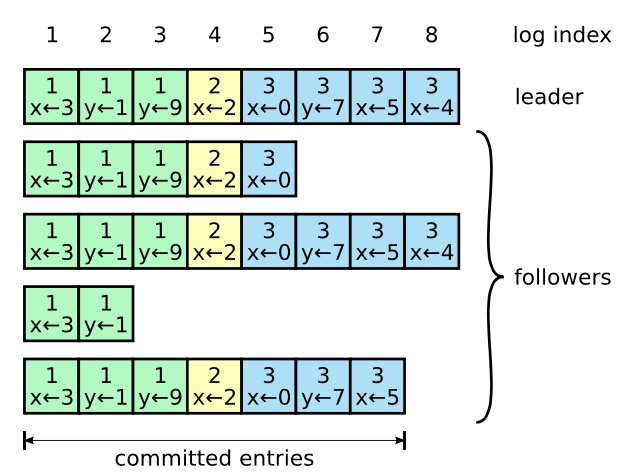
如上图所示,索引 1-7 的日志至少在其他两个节点上复制成功,就认为该日志是 commited 状态,而索引为8 的日志并未复制到多数节点,是 uncommitted 状态。
Leader Append-Only 原则
leader 对自己的日志不能覆盖和删除,只能进行 append 新日志的操作。
Log Matching 特性
Raft 的日志机制来维护不同服务器的日志之间的高层次的一致性。有下面两条特性
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同。
第一个特性来自这样的一个事实,领导人最多在一个任期里在指定的一个日志索引位置创建一条日志条目,同时日志条目在日志中的位置也从来不会改变。
第二个特性由附加日志 RPC 的一个简单的一致性检查所保证。在发送附加日志 RPC 的时候,领导人会把新的日志条目紧接着之前的条目的索引位置和任期号包含在里面。如果跟随者在它的日志中找不到包含相同索引位置和任期号的条目,那么他就会拒绝接收新的日志条目。一致性检查就像一个归纳步骤:一开始空的日志状态肯定是满足日志匹配特性的,然后一致性检查保护了日志匹配特性当日志扩展的时候。因此,每当附加日志 RPC 返回成功时,领导人就知道跟随者的日志一定是和自己相同的了。
强制复制
当一个新的leader选出来的时候,它的日志和其它的follower的日志可能不一样,这个时候,就需要一个机制来保证日志是一致的。
如下图所示,一个新leader产生时,集群状态可能如下:

最上面这个是新leader,a~f是follower,都出现了日志不一致的情况。
- a,b:follower 可能丢失部分日志
- c,d:follower 本地可能 uncommited 的日志
- e,f:follower 可能既缺少本该有的日志,也多出额外的日志
在 Raft 算法中,领导人处理不一致是通过强制跟随者直接复制自己的日志来解决了。这意味着在跟随者中的冲突的日志条目会被领导人的日志覆盖。leader会为每个follower维护一个nextIndex,表示leader给各个follower发送的下一条log entry在log中的index,初始化为leader的最后一条log entry的下一个位置。leader给follower发送AppendEntriesRPC消息,带着{term_id, (nextIndex-1)}, follower接收到AppendEntriesRPC后,会从自己的log中找是不是存在这样的log entry,如果不存在,就给leader回复拒绝消息,然后leader则将nextIndex减1,再重复发送AppendEntriesRPC,直到AppendEntriesRPC消息被接收。
举个例子
以leader和b为例:初始化,nextIndex为11,leader给b发送AppendEntriesRPC(6,10),b在自己log的10号槽位中没有找到term_id为6的log entry。则给leader回应一个拒绝消息。
接着,leader将nextIndex减一,变成10,然后给b发送AppendEntriesRPC(6, 9),b在自己log的9号槽位中同样没有找到term_id为6的log entry。
循环下去,直到leader发送了AppendEntriesRPC(4,4),b在自己log的槽位4中找到了term_id为4的log entry。
接收了消息。随后,leader就可以从槽位5开始给b推送日志了。
解决冲突的性能优化
当附加日志 RPC 的请求被拒绝的时候,跟随者可以返回冲突的条目的任期号和自己存储的那个任期的最早的索引地址。借助这些信息,领导人可以减小 nextIndex 越过所有那个任期冲突的所有日志条目;这样就变成每个任期需要一次附加条目 RPC 而不是每个条目一次。
Nacos 如何实现Raft算法
Nacos server在启动时,会通过RunningConfig.onApplicationEvent()方法调用RaftCore.init()方法。
启动选举
public static void init() throws Exception {
Loggers.RAFT.info("initializing Raft sub-system");
// 启动Notifier,轮询Datums,通知RaftListener
executor.submit(notifier);
// 获取Raft集群节点,更新到PeerSet中
peers.add(NamingProxy.getServers());
long start = System.currentTimeMillis();
// 从磁盘加载Datum和term数据进行数据恢复
RaftStore.load();
Loggers.RAFT.info("cache loaded, peer count: {}, datum count: {}, current term: {}",
peers.size(), datums.size(), peers.getTerm());
while (true) {
if (notifier.tasks.size() <= 0) {
break;
}
Thread.sleep(1000L);
System.out.println(notifier.tasks.size());
}
Loggers.RAFT.info("finish to load data from disk, cost: {} ms.", (System.currentTimeMillis() - start));
GlobalExecutor.register(new MasterElection()); // Leader选举
GlobalExecutor.register1(new HeartBeat()); // Raft心跳
GlobalExecutor.register(new AddressServerUpdater(), GlobalExecutor.ADDRESS_SERVER_UPDATE_INTERVAL_MS);
if (peers.size() > 0) {
if (lock.tryLock(INIT_LOCK_TIME_SECONDS, TimeUnit.SECONDS)) {
initialized = true;
lock.unlock();
}
} else {
throw new Exception("peers is empty.");
}
Loggers.RAFT.info("timer started: leader timeout ms: {}, heart-beat timeout ms: {}",
GlobalExecutor.LEADER_TIMEOUT_MS, GlobalExecutor.HEARTBEAT_INTERVAL_MS);
}
在init方法主要做了如下几件事:
- 获取Raft集群节点 peers.add(NamingProxy.getServers());
- Raft集群数据恢复 RaftStore.load();
- Raft选举 GlobalExecutor.register(new MasterElection());
- Raft心跳 GlobalExecutor.register(new HeartBeat());
- Raft发布内容
- Raft保证内容一致性
选举流程
其中,raft集群内部节点间是通过暴露的Restful接口,代码在 RaftController 中。
RaftController控制器是raft集群内部节点间通信使用的,具体的信息如下
POST HTTP://{ip:port}/v1/ns/raft/vote : 进行投票请求
POST HTTP://{ip:port}/v1/ns/raft/beat : Leader向Follower发送心跳信息
GET HTTP://{ip:port}/v1/ns/raft/peer : 获取该节点的RaftPeer信息
PUT HTTP://{ip:port}/v1/ns/raft/datum/reload : 重新加载某日志信息
POST HTTP://{ip:port}/v1/ns/raft/datum : Leader接收传来的数据并存入
DELETE HTTP://{ip:port}/v1/ns/raft/datum : Leader接收传来的数据删除操作
GET HTTP://{ip:port}/v1/ns/raft/datum : 获取该节点存储的数据信息
GET HTTP://{ip:port}/v1/ns/raft/state : 获取该节点的状态信息{UP or DOWN}
POST HTTP://{ip:port}/v1/ns/raft/datum/commit : Follower节点接收Leader传来得到数据存入操作
DELETE HTTP://{ip:port}/v1/ns/raft/datum : Follower节点接收Leader传来的数据删除操作
GET HTTP://{ip:port}/v1/ns/raft/leader : 获取当前集群的Leader节点信息
GET HTTP://{ip:port}/v1/ns/raft/listeners : 获取当前Raft集群的所有事件监听者
RaftPeerSet
心跳机制
Raft中使用心跳机制来触发leader选举。
心跳定时任务是在GlobalExecutor 中,通过 GlobalExecutor.register(new HeartBeat())注册心跳定时任务,具体操作包括:
- 重置Leader节点的heart timeout、election timeout;
- sendBeat()发送心跳包
public class HeartBeat implements Runnable {
@Override
public void run() {
try {
if (!peers.isReady()) {
return;
}
RaftPeer local = peers.local();
local.heartbeatDueMs -= GlobalExecutor.TICK_PERIOD_MS;
if (local.heartbeatDueMs > 0) {
return;
}
local.resetHeartbeatDue();
sendBeat();
} catch (Exception e) {
Loggers.RAFT.warn("[RAFT] error while sending beat {}", e);
}
}
}
简单说明了下Nacos中的Raft一致性实现,更详细的流程,可以下载源码,查看 RaftCore 进行了解。
源码可以通过以下地址检出:
git clone https://github.com/alibaba/nacos.git
sentinel高可用组件的底层原理
Sentinel是一个系统性的高可用保障工具,提供了等一系列的能力
- 限流
- 降级
- 熔断
- 预热
基于这些能力做了语意化概念抽象,这些概念对于理解实现机制特别有帮助。
流量控制有以下几个角度:
- 资源的调用关系,例如资源的调用链路,资源和资源之间的关系;
- 运行指标,例如 QPS、线程池、系统负载等;
- 控制的效果,例如直接限流、冷启动、排队等。
Sentinel 的设计理念是让您自由选择控制的角度,并进行灵活组合,从而达到想要的效果。
Sentinel使用滑动时间窗口算法来实现流量控制,流量统计。
滑动时间窗算法的核心思想是将一段时间划分为多个时间窗口,并在每个时间窗口内对请求进行计数,以确定是否允许继续请求。
以下是Sentinel底层滑动时间窗口限流算法的简要实现步骤:
- 时间窗口划分:将整个时间范围划分为多个固定大小的时间窗口(例如1秒一个窗口)。这些时间窗口会随着时间的流逝依次滑动。
- 计数器:为每个时间窗口维护一个计数器,用于记录在该时间窗口内的请求数。
- 请求计数:当有请求到来时,将其计入当前时间窗口的计数器中。
- 滑动时间窗口:定期滑动时间窗口,将过期的时间窗口删除,并创建新的时间窗口。这样可以保持时间窗口的滚动。
- 限流判断:当有请求到来时,Sentinel会检查当前时间窗口内的请求数是否超过了预设的限制阈值。如果超过了限制阈值,请求将被拒绝或执行降级策略。
- 计数重置:定期重置过期时间窗口的计数器,以确保计数器不会无限增长。
这种滑动时间窗口算法允许在一段时间内平滑控制请求的流量,而不是仅基于瞬时请求速率进行限流。
它考虑了请求的历史分布,更适用于应对突发流量和周期性负载的情况。
Sentinel熔断降级,是如何实现的?
在微服务架构中,Sentinel 作为一种流量控制、熔断降级和服务降级的解决方案,得到了广泛的应用。
Sentinel是一个开源的流量控制和熔断降级库,用于保护分布式系统免受大量请求的影响。
Sentinel熔断降级,是如何实现的?尼恩建议大家,从以下的几个维度去作答:
第一个维度,Sentinel主要功能:
一:熔断机制
- Sentinel使用滑动窗口统计请求的成功和失败情况。这些统计信息包括成功的请求数、失败的请求数等。
- 当某个资源(例如一个API接口)的错误率超过阈值或其他指标达到预设的条件,Sentinel将触发熔断机制。
- 一旦熔断触发,Sentinel将暂时阻止对该资源的请求,防止继续失败的请求对系统造成更大的影响。
二:降级机制
- Sentinel还提供了降级机制,可以在资源负载过重或其他异常情况下,限制资源的访问速率,以保护系统免受过多的请求冲击。
- 降级策略可以根据需要定制,可以是慢调用降级、异常比例降级等。
三:高可用性机制
Sentinel的高可用性主要通过以下方式来实现:
a. 多节点部署:将Sentinel配置为多节点部署,确保即使一个节点发生故障,其他节点仍然能够继续工作。
b. 持久化配置:Sentinel支持将配置信息持久化到外部存储,如Nacos、Redis等。这样,即使Sentinel节点重启,它可以加载之前的配置信息。
c. 集群流控规则:Sentinel支持集群流控规则,多个节点可以共享流量控制规则,以协同工作来保护系统。
d. 实时监控:Sentinel提供了实时监控和仪表板,可以查看系统的流量控制和熔断降级情况,帮助及时发现问题并采取措施。
四:自适应控制
Sentinel具有自适应控制的功能,它可以根据系统的实际情况自动调整流量控制和熔断降级策略,以适应不同的负载和流量模式。
总的来说,Sentinel的高可用性熔断降级机制是通过多节点部署、持久化配置、实时监控、自适应控制等多种手段来实现的。
这使得Sentinel能够在分布式系统中保护关键资源免受异常流量的影响,并保持系统的稳定性和可用性。
那么,Sentinel是如何实现这些功能的呢?在说说 Sentinel 的基本组件。
第二个维度, Sentinel 的基本组件:
Sentinel 主要包括以下几个部分:资源(Resource)、规则(Rule)、上下文(Context)和插槽(Slot)。
- 资源是我们想要保护的对象,比如一个远程服务、一个数据库连接等。
- 规则是定义如何保护资源的,比如我们可以通过设置阈值、时间窗口等方式来决定何时进行限流、熔断等操作。
- 上下文是一个临时的存储空间,用于存储资源的状态信息,比如当前的 QPS 等。
- 插槽属于责任链模式中的处理器/过滤器, 完成资源规则的计算和验证。
第三个维度, Sentinel 的流量治理几个核心步骤:
在 Sentinel 的运行过程中,主要分为以下几个核心步骤:
- 资源注册:当一个资源被创建时,需要将其注册到 Sentinel。在注册过程中,会为资源创建一个对应的上下文,并将资源的规则存储到插槽中。
- 流量控制:当有请求访问资源时,Sentinel 会根据资源的规则进行流量控制。如果当前 QPS 超过了规则设定的阈值,Sentinel 就会拒绝请求,以防止系统过载。
- 熔断降级:当资源出现异常时,Sentinel 会根据规则进行熔断或降级处理。熔断是指暂时切断对资源的访问,以防止异常扩散。降级则是提供一种备用策略,当主策略无法正常工作时,可以切换到备用策略。
- 规则更新:在某些情况下,我们可能需要动态调整资源的规则。Sentinel 提供了 API 接口,可以方便地更新资源的规则。
通过以上分析,我们可以看出,Sentinel 的核心思想是通过规则来管理和控制资源。这种设计使得 Sentinel 具有很强的可扩展性和灵活性。我们可以根据业务需求,定制各种复杂的规则。
第四个维度, Sentinel 的源码架构维度:
Sentinel 是一种非常强大的流量控制、熔断降级和服务降级的解决方案。 已经成为了替代Hystrix的主要高可用组件。
Sentinel 的源码层面的两个核心架构:
Sentinel可以用来帮助我们实现流量控制、服务降级、服务熔断,而这些功能的实现都离不开接口被调用的实时指标数据。
Sentinel 是一种非常强大的流量控制、熔断降级和服务降级的解决方案。 已经成为了替代Hystrix的主要高可用组件。
回到源码层面,在 Sentinel 源码,包括以下二大架构:
- 责任链模式架构
- 滑动窗口数据统计架构

尼恩说明: 两大架构的源码,简单说说就可以了,具体可以参见《Sentinel 学习圣经》 最新版本。
更加详细的架构图,具体如下:
上图中的右上角就是滑动窗口的示意图,是 StatisticSlot 的具体实现。
StatisticSlot 是 Sentinel 的核心功能插槽之一,用于统计实时的调用数据。
Sentinel 是基于滑动窗口实现的实时指标数据收集统计,底层采用高性能的滑动窗口数据结构 LeapArray 来统计实时的秒级指标数据,可以很好地支撑写多于读的高并发场景。
有关Sentinel的更多的、更加系统化知识,请参见尼恩写的5W字PDF 《Sentinel学习圣经》
滑动窗口的核心数据结构
- ArrayMetric:滑动窗口核心实现类。
- LeapArray:滑动窗口顶层数据结构,包含一个一个的窗口数据。
- WindowWrap:每一个滑动窗口的包装类,其内部的数据结构用 MetricBucket 表示。
- MetricBucket:指标桶,例如通过数量、阻塞数量、异常数量、成功数量、响应时间,已通过未来配额(抢占下一个滑动窗口的数量)。
- MetricEvent:指标类型,例如通过数量、阻塞数量、异常数量、成功数量、响应时间等。
ArrayMetric 源码
滑动窗口的入口类为 ArrayMetric,实现了 Metric 指标收集核心接口,该接口主要定义一个滑动窗口中成功的数量、异常数量、阻塞数量,TPS、响应时间等数据。
public class ArrayMetric implements Metric {
private final LeapArray<MetricBucket> data;
public ArrayMetric(int sampleCount, int intervalInMs, boolean enableOccupy) {
if (enableOccupy) {
this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs);
} else {
this.data = new BucketLeapArray(sampleCount, intervalInMs);
}
}
}
int intervalInMs:表示一个采集的时间间隔,即滑动窗口的总时间,例如 1 分钟。int sampleCount:在一个采集间隔中抽样的个数,默认为 2,即一个采集间隔中会包含两个相等的区间,一个区间就是一个窗口。boolean enableOccupy:是否允许抢占,即当前时间戳已经达到限制后,是否可以占用下一个时间窗口的容量。
LeapArray 源码
LeapArray 用来承载滑动窗口,即成员变量 array,类型为 AtomicReferenceArray<WindowWrap<T>>,保证创建窗口的原子性(CAS)。
public abstract class LeapArray<T> {
//每一个窗口的时间间隔,单位为毫秒
protected int windowLengthInMs;
//抽样个数,就一个统计时间间隔中包含的滑动窗口个数
protected int sampleCount;
//一个统计的时间间隔
protected int intervalInMs;
//滑动窗口的数组,滑动窗口类型为 WindowWrap<MetricBucket>
protected final AtomicReferenceArray<WindowWrap<T>> array;
private final ReentrantLock updateLock = new ReentrantLock();
public LeapArray(int sampleCount, int intervalInMs) {
this.windowLengthInMs = intervalInMs / sampleCount;
this.intervalInMs = intervalInMs;
this.sampleCount = sampleCount;
this.array = new AtomicReferenceArray<>(sampleCount);
}
}
MetricBucket 源码
Sentinel 使用 MetricBucket 统计一个窗口时间内的各项指标数据,这些指标数据包括请求总数、成功总数、异常总数、总耗时、最小耗时、最大耗时等,而一个 Bucket 可以是记录一秒内的数据,也可以是 10 毫秒内的数据,这个时间长度称为窗口时间。
public class MetricBucket {
/**
* 存储各事件的计数,比如异常总数、请求总数等
*/
private final LongAdder[] counters;
/**
* 这段事件内的最小耗时
*/
private volatile long minRt;
}
Bucket 记录一段时间内的各项指标数据用的是一个 LongAdder 数组,数组的每个元素分别记录一个时间窗口内的请求总数、异常数、总耗时。也就是说:MetricBucket 包含一个 LongAdder 数组,数组的每个元素代表一类 MetricEvent。LongAdder 保证了数据修改的原子性,并且性能比 AtomicLong 表现更好。
public enum MetricEvent {
PASS,
BLOCK,
EXCEPTION,
SUCCESS,
RT,
OCCUPIED_PASS
}
当需要获取 Bucket 记录总的成功请求数或者异常总数、总的请求处理耗时,可根据事件类型 (MetricEvent) 从 Bucket 的 LongAdder 数组中获取对应的 LongAdder,并调用 sum 方法获取总数。
public long get(MetricEvent event) {
return counters[event.ordinal()].sum();
}
当需要 Bucket 记录一个成功请求或者一个异常请求、处理请求的耗时,可根据事件类型(MetricEvent)从 LongAdder 数组中获取对应的 LongAdder,并调用其 add 方法。
public void add(MetricEvent event, long n) {
counters[event.ordinal()].add(n);
}
WindowWrap 源码
因为 Bucket 自身并不保存时间窗口信息,所以 Sentinel 给 Bucket 加了一个包装类 WindowWrap。Bucket 用于统计各项指标数据,WindowWrap 用于记录 Bucket 的时间窗口信息(窗口的开始时间、窗口的大小),WindowWrap 数组就是一个滑动窗口。
public class WindowWrap<T> {
/**
* 单个窗口的时间长度(毫秒)
*/
private final long windowLengthInMs;
/**
* 窗口的开始时间戳(毫秒)
*/
private long windowStart;
/**
* 统计数据
*/
private T value;
}
总的来说:
- WindowWrap 用于包装 Bucket,随着 Bucket 一起创建。
- WindowWrap 数组实现滑动窗口,Bucket 只负责统计各项指标数据,WindowWrap 用于记录 Bucket 的时间窗口信息。
- 定位 Bucket 实际上是定位 WindowWrap,拿到 WindowWrap 就能拿到 Bucket。
loadbanlancer负载均衡组件的底层原理
介绍loadbanlancer负载均衡组件之前,首先尼恩给大家介绍一下 负载均衡的基础知识。
基础原理:负载均衡的类型
- 服务器端负载均衡
- 客户端侧负载均衡
1、服务器端负载均衡:
传统的方式前端发送请求会到我们的的nginx上去,nginx作为反向代理,然后路由给后端的服务器,由于负载均衡算法是nginx提供的,而nginx是部署到服务器端的,
所以这种方式又被称为服务器端负载均衡。

2、客户端侧负载均衡:
现在有三个实例,内容中心可以通过discoveryClient 获取到用户中心的实例信息,如果我们再订单中心写一个负载均衡 的规则计算请求那个实例,交给restTemplate进行请求,这样也可以实现负载均衡,这个算法里面,负载均衡是有订单中心提供的,而订单中心相对于用户中心是一个客户端,所以这种方式又称为客户端负负载均衡。

基础原理:常见的负载均衡算法的实现
无论是服务器端负载均衡,还是客户端侧负载均衡,都可以使用下面的常见的负载均衡算法包括:
- 轮询(Round Robin):按照顺序依次将请求分配给每个服务器,循环往复。适用于服务器性能相近的情况。
- 加权轮询(Weighted Round Robin):在轮询的基础上,给每个服务器分配一个权重,根据权重比例分配请求。适用于服务器性能不均匀的情况。
- 随机(Random):随机选择一个服务器来处理请求,不考虑服务器的性能。适用于服务器性能相近且负载不高的情况。
- 最小连接数(Least Connections):选择当前连接数最少的服务器来处理请求。适用于服务器性能差异较大,但负载相对均匀的情况。
- IP哈希(IP Hash):根据客户端的IP地址进行哈希计算,然后将请求分配给对应的服务器。适用于需要将同一个客户端的请求始终分配给同一台服务器的场景,比如会话保持。
- 一致性哈希(Consistent Hashing):根据请求的键(如URL、客户端ID等)进行哈希计算,然后将请求路由到哈希环上最近的服务器。适用于需要动态扩展和缩减服务器集群的场景。
随机(Random)负载均衡算法的实现
利用随机数从所有服务器中随机选取一台,可以用服务器数组下标获取。
public class RandomLoadBalance {
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Server {
private int serverId;
private String name;
}
// 随机算法的核心逻辑
public static Server selectServer(List<Server> serverList) {
Random selector = new Random();
int next = selector.nextInt(serverList.size());
return serverList.get(next);
}
public static void main(String[] args) {
List<Server> serverList = new ArrayList<>();
serverList.add(new Server(1, "服务器1"));
serverList.add(new Server(2, "服务器2"));
serverList.add(new Server(3, "服务器3"));
for (int i = 0; i < 10; i++) {
Server selectedServer = selectServer(serverList);
System.out.format("第%d次请求,选择服务器%s\n", i + 1, selectedServer.toString());
}
}
}
轮询(Round Robin、RR)负载均衡算法的实现
依次将用户的访问请求,按循环顺序分配到web服务节点上,从1开始到最后一台服务器节点结束,然后再开始新一轮的循环。这种算法简单,但是没有考虑到每台节点服务器的具体性能,请求分发往往不均衡。
已知服务器:
| 服务器 | 权重 |
|---|---|
| s1 | 1 |
| s2 | 2 |
| s3 | 3 |
优点:实现简单,无需记录各种服务的状态,是一种无状态的负载均衡策略。
缺点:实现绝对公平,当各个服务器性能不一致的情况,无法根据服务器性能去分配,无法合理利用服务器资源。
public class RoundRobin {
//计数器:每次轮询一个节点自增1
private static AtomicInteger NEXT_SERVER_COUNTER = new AtomicInteger(0);
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Server {
private int serverId;
private String name;
}
/**
* 轮询下标
* @param modulo 节点总数
* @return
*/
private static int select(int modulo) {
for (; ; ) {
int current = NEXT_SERVER_COUNTER.get();
//NEXT_SERVER_COUNTER + 1 % 节点总数
int next = (current + 1) % modulo;
//如果当前NEXT_SERVER_COUNTER为current,CAS更新为next
boolean compareAndSet = NEXT_SERVER_COUNTER.compareAndSet(current, next);
//CAS更新成功直接返回,否则自旋到当前线程CAS操作成功
if (compareAndSet) {
return next;
}
}
}
/**
* 选举节点
* @param serverList 节点个数
* @return
*/
public static Server selectServer(List<Server> serverList) {
return serverList.get(select(serverList.size()));
}
public static void main(String[] args) {
List<Server> serverList = new ArrayList<>();
serverList.add(new Server(1, "服务器1"));
serverList.add(new Server(2, "服务器2"));
serverList.add(new Server(3, "服务器3"));
for (int i = 0; i < 10; i++) {
Server selectedServer = selectServer(serverList);
System.out.format("第%d次请求,选择服务器%s\n", i + 1, selectedServer.toString());
}
}
}
加权轮询(WeightedRound-Robin、WRR)负载均衡算法的实现
根据设定的权重值来分配访问请求,权重值越大的,被分到的请求数也就越多。一般根据每台节点服务器的具体性能来分配权重。
| 服务器 | 权重 |
|---|---|
| s1 | 1 |
| s2 | 2 |
| s3 | 3 |
可以根据权重我们创建数组{s3,s2,s1,s3,s2,s3},然后再按照轮询的方式选择相应的服务器。
public class WeightedRoundRobinSimple {
//当前下标
private static Integer index = 0;
//节点以及对应权值
private static Map<String, Integer> mapNodes = new HashMap<>();
//节点的权值列表
private static List<String> nodes = new ArrayList<>();
// 准备模拟数据
static {
mapNodes.put("192.168.1.101", 1);
mapNodes.put("192.168.1.102", 3);
mapNodes.put("192.168.1.103", 2);
// 关键代码:类似于二维数组 降维成 一维数组,然后使用普通轮询
for (Map.Entry<String, Integer> entry : mapNodes.entrySet()) {
String key = entry.getKey();
for (int i = 0; i < entry.getValue(); i++) {
nodes.add(key);
}
}
System.out.println("简单版的加权轮询:" + JSON.toJSONString(nodes));//打印所有节点
}
public String selectNode() {
String ip = null;
synchronized (index) {
//如果当前下标 >= 节点数,将下标复位
if (index >= nodes.size()) {
index = 0;
}
//获取当前下标节点
ip = nodes.get(index);
//当前下标自增
index++;
}
return ip;
}
// 并发测试:两个线程循环获取节点
public static void main(String[] args) {
WeightedRoundRobinSimple r = new WeightedRoundRobinSimple();
new Thread(() -> {
for (int i = 1; i <= 6; i++) {
String serverIp = r.selectNode();
System.out.println(Thread.currentThread().getName() + "==第" + i + "次获取节点:" + serverIp);
}
}).start();
new Thread(() -> {
for (int i = 1; i <= 6; i++) {
String serverIp = r.selectNode();
System.out.println(Thread.currentThread().getName() + "==第" + i + "次获取节点:" + serverIp);
}
}).start();
}
}
SpringCloud 整合LoadBalancer 负载均衡
SpringCloud 微服务之间 RPC+负载均衡,常用的技术组件,大致如下:

SpringCloud 新版淘汰了 Ribbon,在 OpenFeign 中整合 LoadBalancer 负载均衡
首先回顾一下老版本的 Ribbon负载均衡
Ribbon负载均衡组件
Ribbon是Netflix开发的一个用于客户端负载均衡的工具,主要用于在微服务架构中调用其他服务的客户端。它具有以下特点和功能:
- 负载均衡:Ribbon可以将请求平均地分配给多个后端服务实例,以实现负载均衡,提高系统的性能和可靠性。
- 容错机制:当某个服务实例发生故障或不可用时,Ribbon能够自动将请求转发给其他健康的实例,提供容错能力。
- 自定义规则:Ribbon提供了丰富的负载均衡策略,用户可以根据实际需求选择合适的负载均衡规则,或者自定义自己的规则。
- 集成性:Ribbon可以与其他Netflix开发的组件(如Eureka、Hystrix等)无缝集成,提供更全面的服务治理和容错能力。
- 动态性:Ribbon支持动态刷新负载均衡规则和服务列表,能够随着系统的变化动态调整负载均衡策略,适应不同的场景和需求。
总的来说,Ribbon是一个强大而灵活的客户端负载均衡工具,可以帮助开发人员构建高性能、可靠的分布式系统。
Ribbon重要接口
| 接口 | 作用 | 默认值 |
|---|---|---|
| IClientConfig | 读取配置 | DefaultclientConfigImpl |
| IRule | 负载均衡规则,选择实例 | ZoneAvoidanceRule |
| IPing | 筛选掉ping不通的实例 | 默认采用DummyPing实现,该检查策略是一个特殊的实现, 实际上它并不会检查实例是否可用,而是始终返回true,默认认为所 有服务实例都是可用的. |
| ServerList |
交给Ribbon的实例列表 | Ribbon: ConfigurationBasedServerList Spring Cloud Alibaba: NacosServerList |
| ServerListFilter | 过滤掉不符合条件的实例 | ZonePreferenceServerListFilter |
| ILoadBalancer | Ribbon的入口 | ZoneAwareLoadBalancer |
| ServerListUpdater | 更新交给Ribbon的List的策略 | PollingServerListUpdater |
Ribbon负载均衡规则
| 规则名称 | 特点 |
|---|---|
| RandomRule | 随机选择一个Server |
| RetryRule | 对选定的负责均衡策略机上充值机制,在一个配置时间段内当选择Server不成功,则一直尝试使用subRule的方式选择一个可用的Server |
| RoundRobinRule | 轮询选择,轮询index,选择index对应位置Server |
| WeightedResponseTimeRule | 根据相应时间加权,相应时间越长,权重越小,被选中的可能性越低 |
| ZoneAvoidanceRule | (默认是这个)该策略能够在多区域环境下选出最佳区域的实例进行访问。在没有Zone的环境下,类似于轮询(RoundRobinRule) |
LoadBalancer 负载均衡组件
LoadBalancer 的优势主要是,支持响应式编程的方式异步访问客户端,依赖 Spring Web Flux 实现客户端负载均衡调用。
在 2020 年以前的 SpringCloud 采用 Ribbon作为负载均衡,但是 2020 年之后,SpringCloud 把 Ribbon 移除了,而是使用自己编写的 LoadBalancer 替代.
因此,在 2020 年以后的的 SpringCloud 版本,如果在没有加入 LoadBalancer 依赖,使用 RestTemplate 或 OpenFeign 远程调用,就会报以下错误:
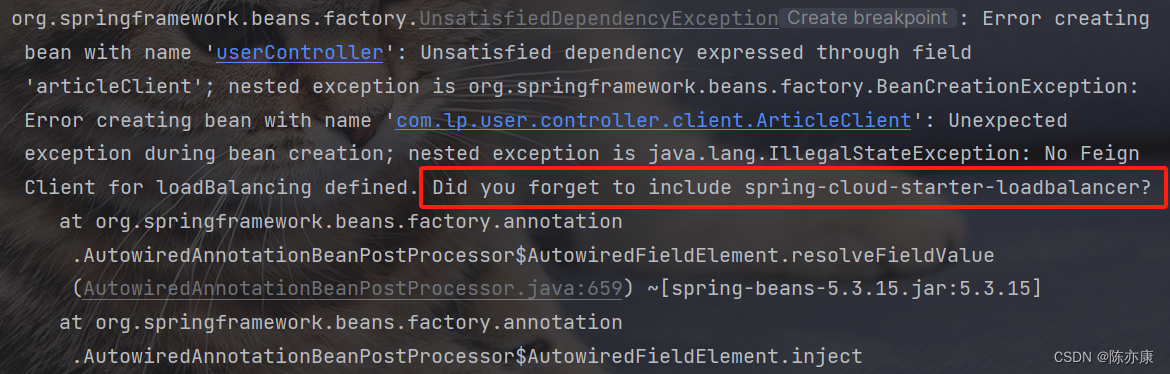
这就是在告诉你 LoadBalancing 是未定义的,并且问你是不是忘记加入 spring-cloud-starter-loadbalancer 依赖。
OpenFeign + LoadBalancer所需依赖
在需要进行远程调用的服务中引入openfeign 和 loadbalancer 依赖
<!--移除ribbon依赖,增加loadBalance依赖 , 添加spring-cloud的依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
maven依赖要排除 ribbon

排除被 其他包 隐形 引入的 ribbon,比如被 nacos client 带入的 ribbon

OpenFeign + LoadBalancer所需配置
配置文件 禁用 ribbon

OpenFeign + LoadBalancer所需注解
@LoadBalancerClients 是 Spring Cloud 提供的一个注解,用于配置全局性的负载均衡器属性。比如配置 自定义的负载均衡机制。

@LoadBalanced 是 Spring Cloud 提供的一个注解,用于标记 RestTemplate 或 WebClient 的 Bean,以启用负载均衡功能。
当一个 RestTemplate 或 WebClient 被标记为 @LoadBalanced 后,Spring Cloud 将会为其创建一个代理对象,并在发起 HTTP 请求时,自动添加负载均衡的能力。当发起 RPC 请求时,实际上是由负载均衡器选择一个目标服务实例,并将请求发送到该实例上。
在使用 RestTemplate 发起 HTTP RPC 请求时,如果 RestTemplate 被标记为 @LoadBalanced,则可以直接使用服务名作为 URL,而不需要指定具体的 IP 地址和端口号。Spring Cloud 会根据服务名解析出可用的服务实例,并通过负载均衡器选择其中一个来处理请求。

OpenFeign + LoadBalancer 的演示
启动 provider 服务端 , 具体请参见《尼恩Java面试宝典》配套视频:

启动 consumer 客户端的微服务 , 具体请参见《尼恩Java面试宝典》配套视频:

这个案例的展示界面如下, 具体请参见《尼恩Java面试宝典》配套视频:

执行请求之后,看断点

命中了 LoadBalancer 的断点

LoadBalancer自定义负载均衡策略
LoadBalancer默认提供了1种负载均衡策略:
- (默认) RoundRobinLoadBalancer - 轮询分配策略
下面是来自源码的结构

LoadBalancer基于Nacos权重自定义负载算法
ReactorLoadBalancer接口,实现自定义负载算法需要实现该接口,并实现choose逻辑,选取对应的节点
public interface ReactorLoadBalancer<T> extends ReactiveLoadBalancer<T> {
Mono<Response<T>> choose(Request request);
default Mono<Response<T>> choose() {
return this.choose(REQUEST);
}
}
通过nacos配置 权重
nacos可以配置不同实例的权重信息,可以在
- yaml中配置
spirng.cloud.nacos.discovery.weight数值范围从1-100 ,默认为1 - 可以在nacos面板找到该实例信息,并实时配置实例的权重

编辑权重

基于nacos权重实现自定义负载
权重:数值越高,代表被选取的概率越大.
根据RoundRobin源码,自定义NacosWeightLoadBalancer
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.DefaultResponse;
import org.springframework.cloud.client.loadbalancer.EmptyResponse;
import org.springframework.cloud.client.loadbalancer.Request;
import org.springframework.cloud.client.loadbalancer.Response;
import org.springframework.cloud.loadbalancer.core.*;
import reactor.core.publisher.Mono;
import java.util.*;
import java.util.concurrent.ThreadLocalRandom;
/**
* 基于nacos权重的负载均衡
*/
public class NacosWeightLoadBalancer implements ReactorServiceInstanceLoadBalancer {
private static final Log log = LogFactory.getLog(NacosWeightLoadBalancer.class);
private final String serviceId;
private ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
//nacos权重获取名称,在nacos元数据中
private static final String NACOS_WEIGHT_NAME = "nacos.weight";
public NacosWeightLoadBalancer(ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider, String serviceId) {
this.serviceId = serviceId;
this.serviceInstanceListSupplierProvider = serviceInstanceListSupplierProvider;
}
@Override
public Mono<Response<ServiceInstance>> choose(Request request) {
ServiceInstanceListSupplier supplier = this.serviceInstanceListSupplierProvider.getIfAvailable(NoopServiceInstanceListSupplier::new);
return supplier.get(request).next().map((serviceInstances) -> {
return this.processInstanceResponse(supplier, serviceInstances);
});
}
private Response<ServiceInstance> processInstanceResponse(ServiceInstanceListSupplier supplier, List<ServiceInstance> serviceInstances) {
Response<ServiceInstance> serviceInstanceResponse = this.getInstanceResponse(serviceInstances);
if (supplier instanceof SelectedInstanceCallback && serviceInstanceResponse.hasServer()) {
((SelectedInstanceCallback)supplier).selectedServiceInstance(serviceInstanceResponse.getServer());
}
return serviceInstanceResponse;
}
private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances) {
if (instances.isEmpty()) {
if (log.isWarnEnabled()) {
log.warn("No servers available for service: " + this.serviceId);
}
} else {
//根据权重选择实例,权重高的被选中的概率大
//nacos.weight的值越大,被选中的概率越大
Double totalWeight = 0D;
for (ServiceInstance instance : instances) {
String s = instance.getMetadata().get(NACOS_WEIGHT_NAME);
double weight = Double.parseDouble(s);
totalWeight = totalWeight + weight;
//放置当前实例的权重区间
instance.getMetadata().put("weight",String.valueOf(totalWeight));
}
//随机获取一个区间类的数值,nacos权重越大,区间越大,则随机数值落到相应的区间的概率是由区间的大小来决定的。
double index = ThreadLocalRandom.current().nextDouble(totalWeight);
//根据权重区间选择实例
for (ServiceInstance instance : instances) {
double weight = Double.parseDouble(instance.getMetadata().get("weight"));
if (index <= weight) {
return new DefaultResponse(instance);
}
}
}
return new EmptyResponse();
}
}
配置使用自定义负载均衡器
增加WeightLoadBalanceConfiguration
public class WeightLoadBalanceConfiguration {
@Bean
public ReactorLoadBalancer<ServiceInstance> weightLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new NacosWeightLoadBalancer(loadBalancerClientFactory
.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}
}
修改主类配置,使用NacosWeightLoadBalancer 负载均衡
@LoadBalancerClients({
@LoadBalancerClient(name = "loadbalance-provider-service", configuration = WeightLoadBalanceConfiguration.class)
})
说在最后:有问题找老架构取经
如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
遇到职业难题,找老架构取经, 可以省去太多的折腾,省去太多的弯路。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。
另外,尼恩也给一线企业提供 《DDD 的架构落地》企业内部培训,目前给不少企业做过内部的咨询和培训,效果非常好。

技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
免费获取11个技术圣经PDF:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号