NIO圣经:一次穿透NIO、Selector、Epoll底层原理
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
NIO圣经:一次穿透NIO、epoll,实现你的NIO自由
此pdf电子书,是尼恩架构团队持续升级、持续迭代的作品。 目标是,通过不断升级、持续迭代,为大家构筑一个超底层、超强悍的高性能技术内功。
原 :《九阳真经:彻底明白操作系统 select、epoll 核心原理》
改:名为 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》

第1次迭代:2021.4
第2次迭代:2022.4
第3次迭代:2023.9
说在前面:
现在拿到offer超级难,甚至连面试电话,一个都搞不到。尼恩的技术社群中(50+),很多小伙伴凭借 “精通NIO+精通Netty”的绝活,拿到了滴滴/头条/JD等大厂offer,实现了大厂梦。
在学习的过程中,大家发现,NIO很难、Netty很难。
在这里,尼恩从架构师视角出发,NIO 核心原理做一个穿透式的介绍。
写了一个pdf 电子书,并且后续会持续升级:
(1) 《 NIO圣经:一次穿透NIO、Selector、Epoll底层原理 》PDF
当然,尼恩的其他的很多圣经PDF,也非常重要, 非常有价值
(2) 《 K8S 学习圣经 》PDF
(3) 《 Docker 学习圣经》PDF
带大家穿透Docker + K8S ,实现Docker + K8S 自由,让大家不迷路。
本书 《 NIO圣经:一次穿透NIO、Selector、Epoll底层原理 》PDF的 V3版本,后面会持续迭代和升级。供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
帮助大家进大厂,做架构,拿高薪。
本书目录
- NIO圣经:一次穿透NIO、epoll,实现你的NIO自由
- 说在前面:
- 本书目录
- V1版本背景
- 本圣经的宗旨:
- 学习高并发,epoll是个基础
- 高性能的核心杀手锏:异步化
- IO模型层的异步化
- 分层解耦的重要性
- 再谈阻塞与非阻塞、同步与异步
- 阻塞IO(BIO)的底层原理
- IO多路复用
- select 系统调用
- poll 系统调用
- epoll 底层系统调用
- 结合内核源码,深入Epoll的原理和源码
- 超级底层1:使用Epoll第一步epoll_create的超底层原理:
- 超级底层2:epoll_ctl的底层原理
- 超级底层3:使用Epoll第3步epoll_wait的底层原理
- 应用层用到的Linux epoll API:
- epoll的巨大优势
- 美团二面:epoll性能那么高,为什么?
- 彻底明白:高速ET模式与Netty的高速Selector
- IO线程模型
- 彻底解密:IO事件在Java、Native之间的翻译
- 彻底解密:Java NIO SelectionKey (选择键) 核心原理
- 背景
- 选择键的使用
- SelectionKey介绍
- SelectionKey对象代表着Channel和Selector的关联关系
- SelectionKeyImpl继承关系
- 向通道注册事件
- SelectionKey中使用了四个常量来代表事件类型:
- SelectionKey维护两个set集合成员:
- SelectionKey#interestOps()方法
- SelectionKey除开构造器方法,有13个方法:
- AbstractSelectionKey的属性
- AbstractSelectionKey的方法
- SelectionKeyImpl
- SelectionKeyImpl的属性
- 感兴趣的事件interestOps还可直接通过interestOps()方法设置
- 就绪的事件readyOps是通道实际发生的操作事件
- 判断事件是否注册
- 检测channel中什么事件已经就绪
- 访问这个ready set就绪的事件
- 使用的比特掩码来检测就绪事件
- SelectionKey#isAcceptable()
- 获取已经就绪的事件集合SelectionKeyImpl#readyOps()
- 新连接就绪事件的简单处理
- SelectionKey#isAcceptable()的源码
- 读就绪事件的简单处理
- SelectionKey#isReadable()的源码
- selectionKey如何失效
- 检查selectionKey是否仍然有效
- selectionKey的附件
- selectionKey的附件操作
- 为SelectionKey添加附件
- 注册Channel的时候添加附件
- EchoServerReactor 中的处理器附件
- EchoServerReactor 中的处理器附件
- Netty中的AbstractNioChannel.doRegister
- selectionKey的使用例子
- 强制停止Selector#select()后的selectKey结果
- 强制停止Selector#select()操作的方法
- 彻底明白:Selector(选择器) 核心原理
- 最强揭秘:Selector.open() 选择器打开的底层原理
- Selector.open()方法的使用
- Selector.open();
- 创建一个provider
- 在windows环境中这里创建的是WindowsSelectorProvider
- 随后调用WindowsSelectorProvider.openSelector
- SelectorProvider的实现与操作系统相关
- WindowsSelectorProvider的继承关系图
- SelectorImpl会初始化selectedKeys和keys
- AbstractSelector会初始化provider
- WindowsSelectorImpl构造器
- WindowsSelectorProvider.open()
- WindowsSelectorImpl结构
- FdMap结构
- SubSelector
- PollArrayWrapper 中 pollArray事件轮询队列
- pollArray文件描述符poll事件轮询队列的元素
- PollArrayWrapper的成员
- events&revents的取值如下:
- PollArrayWrapper的构造器
- NativeObject分配直接内存
- SubSelector的属性
- SubSelector的方法
- 调用JNI本地poll0方法查询事件
- selector的大致查询过程
- 最强揭秘:Selector.register() 注册的底层原理
- channel到selector注册的代码
- 通道注册示意图
- 注册大致流程
- SelectableChannel#register();
- channel.register() 方法的第二个参数。
- 用“位或”操作符将多个常量连接起来
- AbstractSelectableChannel.register(selector, ops,att)
- AbstractSelector.register
- WindowsSelectorImpl#implRegister实现注册
- pollWrapper的addEntry
- pollArray的元素内容
- 回顾AbstractSelector.register
- SelectionKeyImpl#interestOps(ops)
- SelectionKeyImpl.nioInterestOps
- channel#translateAndSetInterestOps
- WindowsSelectorImpl的putEventOps中
- 重点:将感兴趣的事件放到pollArray中由i指定的位置
- WindowsSelectorImpl#implRegister实现注册
- 扩容channelArray
- pollWrapper.grow(newSize)扩容PollArrayWrapper
- 辅助线程的管理
- WindowsSelectorImpl下的多线程提高poll的性能
- WindowsSelectorImpl的性能问题
- 回顾:整体的注册流程
- 最强揭秘:Selector.select() 事件查询的底层原理
- select方法的核心流程:
- select方法的调用流程
- SelectorImpl#select
- SelectorImpl#lockAndDoSelect
- WindowsSelectorImpl#doSelect
- 内部类subSelector#poll()
- C语言中的WindowsSelectorImpl#poll0()
- c的select方法的主要功能
- 在windows上select方法原型:
- SubSelector.processSelectedKeys
- SubSelector.processFDSet
- ServerSocketChannelImpl.translateReadyOps
- Selector的select()只用单线程
- 最强揭秘:Selector.wakeup() 唤醒的底层原理
- 如何唤醒被系统调用阻塞的进程?
- wakeup方法
- WindowsSelector唤醒的原理
- WindowsSelector的实现
- WindowsSelectorImpl的loopback连接
- 唤醒消息的发送端和接收端
- PipeImpl的成员
- pipe的简单实例
- PipeImpl#LoopbackConnector
- 创建pipe的过程,pipe.open(),打开本机通道
- 创建pipe的过程,两个socket的链接校验
- 回到WindowsSelectorImpl构造方法
- Nagel算法
- 为啥要禁用了TCP中的Nagle算法?
- 回到WindowsSelectorImpl构造方法
- source端放到了pollWrapper中
- 回顾:pollArray的结构
- pollArray的元素
- 回顾WindowsSelectorImpl的成员
- wakeup的消息发送
- WindowsSelectorImpl的wakeup实现
- WindowsSelectorImpl#setWakeupSocket0
- poll函数的事件标志符值
- wakeup()的要点:
- Selector关闭
- SelectorImpl#implCloseSelector
- 参考文献
- 技术自由的实现路径:
- 免费获取11个技术圣经PDF:
V1版本背景

本圣经的宗旨:
与《高并发三部曲》相配合,为大家打通任督二脉

学习高并发,epoll是个基础
epoll的重要性
epoll作为linux下高性能网络服务器的必备技术至关重要,
Java NIO、nginx、redis、skynet和大部分游戏服务器都使用到这一多路复用技术。
epoll的重要性,大厂面试必备
不少大厂在招聘服务端同学时,可能会问及epoll相关的问题。
比如epoll和select的区别是什么?
epoll高效率的原因是什么?
高性能的核心杀手锏:异步化
我们说,高性能的核心杀手锏:异步化,或者异步架构
nio (非阻塞io、noblocking io)是一种高性能的 io 架构方案, 是和bio(阻塞io) 相对而言的。
所以,从架构的维度来说,nio 就是一种异步化 的架构方案
问题的关键是,nio底层用的,又是一种同步io 模型。
这里,出现了围绕 nio 的一个大的知识冲突:
-
nio 是异步的吗? 是的
-
nio 是同步 io 吗? 是的
从文字上看, 这不彻底的自相矛盾, 狗屁不通, 天理不容吗?
是的,这就是围绕 nio 的 一个大的知识冲突,一个大的概念冲突。
这也是尼恩社群中, 一个困扰过上百个读者、甚至上千个读者的 技术困惑。
如何理清楚这个 技术谜题呢?
我们在架构学上,有一个很重要的策略: 解耦。
在这里,尼恩把nio 所在的处理链路、或者说 用户的api调用链路,也进行解耦。
如何对 用户的api调用链路解耦?
可以简单的, 把用户的api调用链路,解耦为三层, 如下图所示:
- 应用层:编程模型的异步化
- 框架层:IO线程的异步化
- OS层: IO模型的异步化
解耦之后,再庖丁解牛,一层一层的进行异步化架构。 引入一个牛逼轰轰的概念: 全链路异步。
全链路异步的三个层面
全链路异步化的最终目标,每一个组件,实现三个层面的 异步化,

一:应用层的异步化 :编程模型
随着 云原生时代的到来, 底层的 组件编程 越来越 响应式、流处理化。
于是应用层的开发,就引入了响应式 编程。
从命令式 编程转换到 响应式 编程,在非常多的场景 是大势所趋,比如在 io密集型场景。
需要注意的是:响应式编程, 学习曲线很大, 大家需要多看,多实操。
这个请大家去看 尼恩的 《响应式 圣经 PDF》电子书
二:框架层的异步化:IO线程模型异步架构
什么是 IO线程模型异步架构?
从一个io线程一次只能处理一个请求,到一个io线程一次能处理大量请求,就是 IO线程模型异步架构
来看看我们的经典组件,是同步还是异步的:
-
tomcat 同步的线程模型, 每一个线程在处理一个请求的时候,这个请求的处理过程中, 是阻塞的
-
HTTPClient 客户端组件 , 线程模型是同步的, 每一个线程在处理一个请求的时候,这个请求的处理过程中, 是阻塞的
-
AsyncHttpClient IO线程模型异步架构,一个io线程一次能处理大量请求
-
netty 底层IO框架, 核心就是线程模型异步架构,一个io线程一次能处理大量请求
IO线程模型异步架构 ,非常经典的模式,就是 io Reactor 线程模型
IO Reactor模式
了解了BIO和NIO的一些使用方式,Reactor模式就呼之欲出了。
NIO是基于事件机制的,有一个叫做Selector的选择器,阻塞获取关注的事件列表。获取到事件列表后,可以通过分发器,进行真正的数据操作。
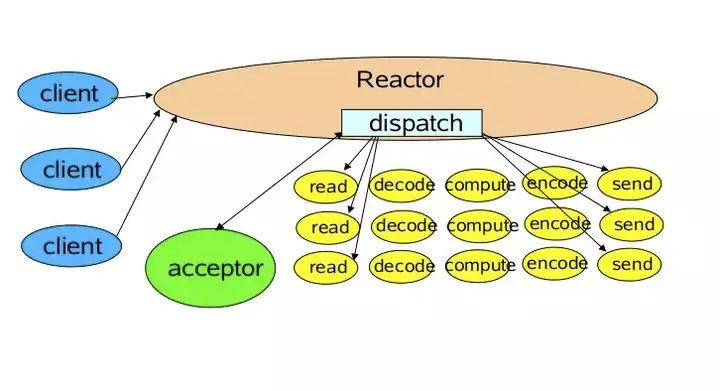
上图是Doug Lea在讲解NIO时候的一张图,指明了最简单的Reactor模型的基本元素。
你可以对比这上面的NIO代码分析一下,里面有四个主要元素:
- Acceptor 处理client的连接,并绑定具体的事件处理器
- Event 具体发生的事件
- Handler 执行具体事件的处理者。比如处理读写事件
- Reactor 将具体的事件分配给Handler
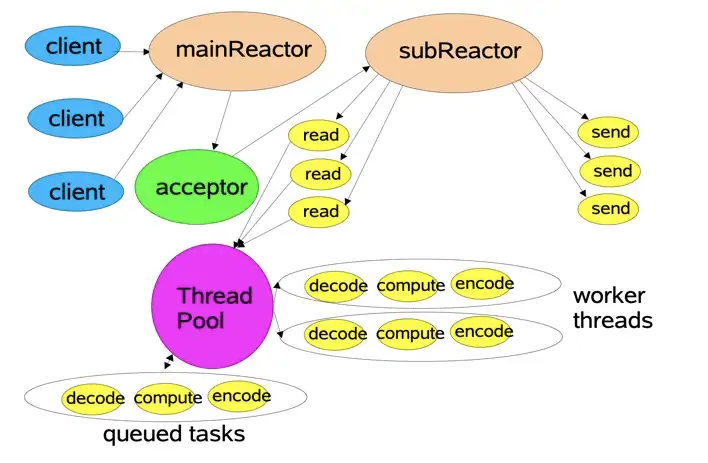
我们可以对上面的模型进行近一步细化,下面这张图同样是Doug Lea的ppt中的。
它把Reactor部分分为mainReactor和subReactor两部分。mainReactor负责监听处理新的连接,然后将后续的事件处理交给subReactor,subReactor对事件处理的方式,也由阻塞模式变成了多线程处理,引入了任务队列的模式。
这两个线程模型,非常重要。
一定要背到滚瓜烂熟。
这里不做展开,请大家去看尼恩的畅销书《Java 高并发核心编程卷 1 加强版》。
这个是面试的绝对重点
IO的王者组件,Netty框架,整体就是一个 Reactor 线程模型 实现
也是非常核心的知识,这里不做展开,请大家去看尼恩的畅销书《Java 高并发核心编程卷 1 加强版》。
首先来看线程模型的异步化。
三:OS层的异步化:IO模型
目前的一个最大难题,是底层操作系统层的 IO模型的异步化。
注意这里一个大的问题:
Netty 底层的IO模型,咱们一般用的是select或者 epoll,是同步IO,不是异步IO.
有关5大IO模型,是本文的基础知识,也是非常核心的知识,稍后详细介绍
为啥需要IO模型异步化
这里有一个很大的性能损耗点,同步IO中,线程的切换、 IO事件的轮询、IO操作, 都是需要进行 系统调用完成的。
系统调用的性能耗费在哪里?
首先,线程是很”贵”的资源,主要表现在:
- 线程的创建和销毁成本很高,线程的创建和销毁都需要通过重量级的系统调用去完成。
- 线程本身占用较大内存,像Java的线程的栈内存,一般至少分配512K~1M的空间,如果系统中的线程数过千,整个JVM的内存将被耗用1G。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。过多的线程频繁切换带来的后果是,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统CPU sy值特别高(超过20%以上)的情况,导致系统几乎陷入不可用的状态。
在Linux的性能指标里,有us和sy两个指标,使用top命令可以很方便的看到。

us是用户进程的意思,而sy是在内核中所使用的cpu占比。
如果进程在内核态和用户态切换的非常频繁,那么效率大部分就会浪费在切换之上。一次内核态和用户态切换的时间,普遍在 微秒 级别以上,可以说非常昂贵了。
cpu的性能是固定的,在无用的东西上浪费越小,在真正业务上的处理就效率越高。
影响效率的有两个方面:
-
进程或者线程的数量,引起过多的上下文切换。
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,如果你的代码切换了线程,它必然伴随着一次用户态和内核态的切换。
-
IO的编程模型,引起过多的系统态和内核态切换。
比如同步阻塞等待的模型,需要经过数据接收、软中断的处理(内核态),然后唤醒用户线程(用户态),处理完毕之后再进入等待状态(内核态)。
注意:一次内核态和用户态切换的时间,普遍在 微秒 级别以上,可以说非常昂贵了。
IO模型的异步化的第一个目标: 减少线程数量,减少线程切换系统调用带来 CPU 上下文切换的开销。
IO模型的异步化的第一个目标: 减少IO系统调用,减少线程切换系统调用带来的带来 CPU 上下文切换开销。
IO模型层的异步化
IO模型层的异步化, 也是逐步演进的, 演进的过程中,大概涉及到以下的模型
- 阻塞式IO (bio)
- 非阻塞式IO
- IO复用 (nio)
- 信号驱动式IO
- 异步IO(aio)
作为热身, 先简单看看两类简单的模型:阻塞IO模型、非阻塞IO模型
1.阻塞IO模型
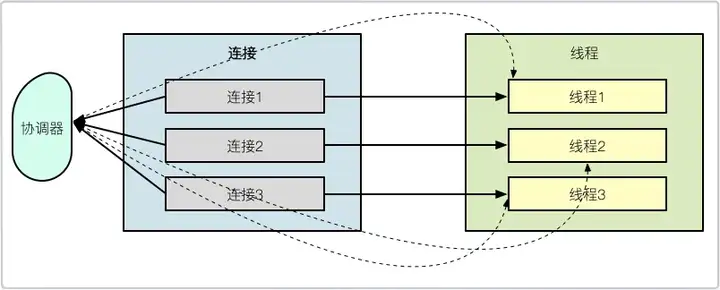
如上图,是典型的BIO模型,每当有一个连接到来,经过协调器的处理,就开启一个对应的线程进行接管。
如果连接有1000条,那就需要1000个线程。线程资源是非常昂贵的,除了占用大量的内存,还会占用非常多的CPU调度时间,所以BIO在连接非常多的情况下,效率会变得非常低。
就单个阻塞IO来说,它的效率并不比NIO慢。但是当服务的连接增多,考虑到整个服务器的资源调度和资源利用率等因素,NIO就有了显著的效果,NIO非常适合高并发场景。
2.非阻塞IO模型
其实,在处理IO动作时,有大部分时间是在等待。
比如,socket连接要花费很长时间进行连接操作,在完成连接的这段时间内,它并没有占用额外的系统资源,但它只能阻塞等待在线程中。这种情况下,系统资源并不能被合理的利用。
Java的NIO,在Linux上底层是使用epoll实现的。epoll是一个高性能的多路复用I/O工具,改进了select和poll等工具的一些功能。在网络编程中,对epoll概念的一些理解,几乎是面试中必问的问题。
epoll的数据结构是直接在内核上进行支持的。通过epoll_create和epoll_ctl等函数的操作,可以构造描述符(fd)相关的事件组合(event)。
这里有两个比较重要的概念:
fd每条连接、每个文件,都对应着一个描述符,比如端口号。内核在定位到这些连接的时候,就是通过fd进行寻址的event当fd对应的资源,有状态或者数据变动,就会更新epoll_item结构。在没有事件变更的时候,epoll就阻塞等待,也不会占用系统资源;一旦有新的事件到来,epoll就会被激活,将事件通知到应用方
关于epoll还会有一个面试题:相对于select,epoll有哪些改进?
这里直接给出答案:
- epoll不再需要像select一样对fd集合进行轮询,也不需要在调用时将fd集合在用户态和内核态进行交换
- 应用程序获得就绪fd的事件复杂度,epoll时O(1),select是O(n)
- select最大支持约1024个fd,epoll支持65535个
- select使用轮询模式检测就绪事件,epoll采用通知方式,更加高效
有关5大IO模型,是本文的基础知识,也是非常核心的知识,非常重要
接下来,通过尼恩的畅销书《Java 高并发核心编程卷 1 加强版》第2章,给大家做一个 IO模型层的异步化 演进的过程中的详细介绍。
《Java高并发核心编程卷1》第2章:高并发IO的底层原理
本书的原则是:从基础讲起。IO底层原理是隐藏在Java编程知识之下的基础知识,是开发人员必须掌握的基础原理,可以说是基础的基础,更是大公司面试通关的必备知识。
本章从操作系统的底层原理入手,通过图文并茂的方式,为大家深入剖析高并发IO的底层原理,并介绍如何通过设置来让操作系统支持高并发。
2.1 节 IO读写的基础原理
为了避免用户进程直接操作内核,保证内核安全,操作系统将内存(虚拟内存)划分为两部分,一部分是内核空间(Kernel-Space),一部分是用户空间(User-Space)。 在 Linux 系统中,内核模块运行在内核空间,对应的进程处于内核态;而用户程序运行在用户空间,对应的进程处于用户态。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内核空间,也有访问底层硬件设备的权限。内核空间总是驻留在内存中,它是为操作系统的内核保留的。应用程序是不允许直接在内核空间区域进行读写,也是不容许直接调用内核代码定义的函数的。每个应用程序进程都有一个单独的用户空间,对应的进程处于用户态,用户态进程不能访问内核空间中的数据,也不能直接调用内核函数的,因此要进行系统调用的时候,就要将进程切换到内核态才能进行。
内核态进程可以执行任意命令,调用系统的一切资源,而用户态进程只能执行简单的运算,不能直接调用系统资源,现在问题来了:用户态进程如何执行系统调用呢?答案为:用户态进程必须通过系统接口(System Call),才能向内核发出指令,完成调用系统资源之类的操作。
说明:
如果没有特别声明,本书后文所提到的内核,即指操作系统的内核。
用户程序进行IO的读写,依赖于底层的IO读写,基本上会用到底层的两大系统调用:sys_read & sys_write。虽然在不同的操作系统中,sys_read&sys_write两大系统调用的名称和形式可能不完全一样,但是他们的基本功能是一样的。
操作系统层面的sys_read系统调用,并不是直接从物理设备把数据读取到应用的内存中;sys_write系统调用,也不是直接把数据写入到物理设备。上层应用无论是调用操作系统的sys_read,还是调用操作系统的sys_write,都会涉及缓冲区。具体来说,上层应用通过操作系统的sys_read系统调用,是把数据从内核缓冲区复制到应用程序的进程缓冲区;上层应用通过操作系统的sys_write系统调用,是把数据从应用程序的进程缓冲区复制到操作系统内核缓冲区。
简单来说,应用程序的IO操作,实际上不是物理设备级别的读写,而是缓存的复制。sys_read&sys_write两大系统调用,都不负责数据在内核缓冲区和物理设备(如磁盘、网卡等)之间的交换。这项底层的读写交换操作,是由操作系统内核(Kernel)来完成的。所以,应用程序中的IO操作,无论是对Socket的IO操作,还是对文件的IO操作,都属于上层应用的开发,它们的在输入(Input)和输出(Output)维度上的执行流程,都是类似的,都是在内核缓冲区和进程缓冲区之间的进行数据交换。
其中,涉及到 用户空间内核空间、用户态内核态,又是一组极致复杂的概念
同样是本文的基础知识,也是非常核心的知识,非常重要
这里不做展开,请大家去看尼恩的3 高架构笔记 《高性能之葵花宝典》。
1.1.1 内核缓冲区与进程缓冲区
为什么设置那么多的缓冲区,导致读写过程那么麻烦呢?
缓冲区的目的,是为了减少频繁地与设备之间的物理交换。计算机的外部物理设备与内存与CPU相比,有着非常大的差距,外部设备的直接读写,涉及操作系统的中断。发生系统中断时,需要保存之前的进程数据和状态等信息,而结束中断之后,还需要恢复之前的进程数据和状态等信息。为了减少底层系统的频繁中断所导致的时间损耗、性能损耗,于是出现了内核缓冲区。
有了内核缓冲区,操作系统会对内核缓冲区进行监控,等待缓冲区达到一定数量的时候,再进行IO设备的中断处理,集中执行物理设备的实际IO操作,通过这种机制来提升系统的性能。至于具体在什么时候执行系统中断(包括读中断、写中断),则由操作系统的内核来决定,应用程序不需要关心。
上层应用程序使用sys_read系统调用时,仅仅把数据从内核缓冲区复制到上层应用的缓冲区(进程缓冲区);上层应用使用sys_write系统调用时,仅仅把数据从应用的用户缓冲区复制到内核缓冲区中。
内核缓冲区与应用缓冲区在数量上也不同,在Linux系统中,操作系统内核只有一个内核缓冲区。而每个用户程序(进程)则有自己独立的缓冲区,叫做用户缓冲区或者进程缓冲区。Linux系统中的用户程序的IO读写程序,在大多数情况下,并没有进行实际的IO操作,而是在用户缓冲区和内核缓冲区之间直接进行数据的交换。
1.1.2 典型IO系统调用sys_read&sys_write的执行流程
下面是一段进行Socket数据传输的服务端简单C语言代码。之所以简单,是因为服务端只接收一个连接,然后就开始通过C语言的read&write函数进行Socket的数据读写。参考的代码如下:
#include "InitSock.h"
#include <stdio.h>
#include <iostream>
using namespace std;
CInitSock initSock; // 初始化Winsock库
int main()
{
// 创建套节字
//参数1用来指定套接字使用的地址格式,通常使用AF_INET
//参数2指定套接字的类型,SOCK_STREAM指的是TCP,SOCK_DGRAM指的是UDP
SOCKET sListen = ::socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
sockaddr_in sin; //创建IP地址: ip+端口
sin.sin_family = AF_INET;
sin.sin_port = htons(4567); //1024 ~ 49151:普通用户注册的端口号
sin.sin_addr.S_un.S_addr = INADDR_ANY;
// 绑定这个套接字到一个IP地址
if(::bind(sListen, (LPSOCKADDR)&sin, sizeof(sin)) == SOCKET_ERROR)
{
printf("Failed bind() \n");
return 0;
}
//开始监听连接
//第二个参数2指的监听队列中允许保持的尚未处理的最大连接数
if(::listen(sListen, 2) == SOCKET_ERROR)
{
printf("Failed listen() \n");
return 0;
}
// 接受客户的连接请求,注意,这里只是演示,只接收一个客户端,不接收更多客户端
sockaddr_in remoteAddr;
int nAddrLen = sizeof(remoteAddr);
SOCKET sClient = 0;
char szText[] = " TCP Server Demo! \r\n";
while(sClient==0)
{
// 接受一个新连接
//((SOCKADDR*)&remoteAddr)一个指向sockaddr_in结构的指针,用于获取对方地址
sClient = ::accept(sListen, (SOCKADDR*)&remoteAddr, &nAddrLen);
if(sClient == INVALID_SOCKET)
{
printf("Failed accept()");
}
printf("接受到一个连接:%s \r\n", inet_ntoa(remoteAddr.sin_addr));
break;
}
while(TRUE)
{
// 向客户端发送数据
::send(sClient, szText, strlen(szText), 0);
// 从客户端接收数据
char buff[256] ;
int nRecv = ::read(sClient, buff, 256, 0);
if(nRecv > 0)
{
buff[nRecv] = '\0';
printf(" 接收到数据:%s\n", buff);
}
}
// 关闭客户端的连接
::closesocket(sClient);
// 关闭监听套节字
::closesocket(sListen);
return 0;
}
用户程序所使用的read和write函数,可以理解为C语言中的库函数,这个库函数专供用户程序使用。注意:这些库函数并不是内核程序,而内核空间的数据读写需要内核程序完成,所以,这些库函数里,还需要对系统调用进行更进一步的封装和调用。那么,这里涉及到哪里系统调用呢?由于不同的操作系统,或者同一个操作系统的不同版本,在具体实现上都有差异,所以,大家可以大致的理解为,C程序中使用的read库函数会调用到的系统调用为sys_read,由sys_read完成内核空间的数据读取;用户C程序中使用的write库函数会调用到的系统调用为sys_write,由sys_write完成内核空间的数据写入。
系统调用sys_read&sys_write,并不是使数据在内核缓冲区和物理设备之间的交换。sys_read调用把数据从内核缓冲区复制到应用的用户缓冲区,sys_write调用把数据从应用的用户缓冲区复制到内核缓冲区,两个系统调用的大致的流程,如图2-1所示。

图2-1 系统调用sys_read&sys_write的执行流程
这里以sys_read系统调用为例,先看下一个完整输入流程的两个阶段:
- 应用程序等待数据准备好。
- 从内核缓冲区向用户缓冲区复制数据。
如果是sys_read一个socket(套接字),那么以上两个阶段的具体处理流程如下:
- 第一个阶段,应用程序等待数据通过网络中到达网卡,当所等待的分组到达时,数据被操作系统复制到内核缓冲区中。这个工作由操作系统自动完成,用户程序无感知。
- 第二个阶段,内核将数据从内核缓冲区复制到应用的用户缓冲区。
再具体一点,如果是在C程序客户端和服务器端之间完成一次socket请求和响应(包括sys_read和sys_write)的数据交换,其完整的流程如下:
- 客户端发送请求:C程序客户端程序通过sys_write系统调用,将数据复制到内核缓冲区,Linux将内核缓冲区的请求数据通过客户端器的网卡发送出去。
- 服务端系统接收数据:在服务端,这份请求数据会被服务端操作系统通过DMA硬件,从接收网卡中读取到服务端机器的内核缓冲区。
- 服务端C程序获取数据:服务端C程序通过sys_read系统调用,从Linux内核缓冲区复制数据,复制到C用户缓冲区。
- 服务器端业务处理:服务器在自己的用户空间中,完成客户端的请求所对应的业务处理。
- 服务器端返回数据:服务器C程序完成处理后,构建好的响应数据,将这些数据从用户缓冲区写入内核缓冲区,这里用到的是sys_write系统调用,操作系统会负责将内核缓冲区的数据发送出去。
- 服务端系统发送数据:服务端Linux系统将内核缓冲区中的数据写入网卡,网卡通过底层的通信协议,会将数据发送给目标客户端。
说明:
由于生产环境的Java高并发应用基本都运行在Linux操作系统上,所以,以上案例中的操作系统,以Linux作为实例。
2.2 节 五种主要的IO模型
服务器端高并发IO编程,往往要求的性能都非常高,一般情况下都需要选用高性能的IO模型。还有,对于Java工程师来说,有关IO模型的知识也是通关大公司面试的必备知识。本章从最为基础的模型开始,为大家揭秘IO模型的核心原理。
常见的IO模型虽然有五种,但是可以分成四大类:
- 同步阻塞IO(Blocking IO)
首先,解释一下阻塞与非阻塞。阻塞IO,指的是需要内核IO操作彻底完成后,才返回到用户空间执行用户程序的操作指令,阻塞一词所指的是用户程序(发起IO请求的进程或者线程)的执行状态是阻塞的。可以说传统的IO模型都是阻塞IO模型,并且在Java中,默认创建的socket都属于阻塞IO模型。
其次,解释一下同步与异步。简单理解,同步与异步可以看成是发起IO请求的两种方式。同步IO是指用户空间(进程或者线程)是主动发起IO请求的一方,系统内核是被动接受方。异步IO则反过来,系统内核主动发起IO请求的一方,用户空间是被动接受方。
所谓同步阻塞IO,指的是用户空间(或者线程)主动发起,需要等待内核IO操作彻底完成后,才返回到用户空间的IO操作,IO操作过程中,发起IO请求的用户进程(或者线程)处于阻塞状态。
- 同步非阻塞NIO(Non-Blocking IO)
非阻塞IO,指的是用户空间的程序不需要等待内核IO操作彻底完成,可以立即返回用户空间去执行后续的指令,即发起IO请求的用户进程(或者线程)处于非阻塞的状态,与此同时,内核会立即返回给用户一个IO的状态值。
阻塞和非阻塞的区别是什么呢?
阻塞是指用户进程(或者线程)一直在等待,而不能干别的事情;非阻塞是指用户进程(或者线程)拿到内核返回的状态值就返回自己的空间,可以去干别的事情。在Java中,非阻塞IO的socket套接字,要求被设置为NONBLOCK模式。
说明:
这里所说的NIO(同步非阻塞IO)模型,并非Java编程中的NIO(New IO)类库。
所谓同步非阻塞NIO,指的是用户进程主动发起,不需要等待内核IO操作彻底完成之后,就能立即返回到用户空间的IO操作,IO操作过程中,发起IO请求的用户进程(或者线程)处于非阻塞状态。
- IO多路复用(IO Multiplexing)
为了提高性能,操作系统引入了一类新的系统调用,专门用于查询IO文件描述符的(含socket连接)的就绪状态。在Linux系统中,新的系统调用为select/epoll系统调用。通过该系统调用,一个用户进程(或者线程)可以监视多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核能够将文件描述符的就绪状态返回给用户进程(或者线程),用户空间可以根据文件描述符的就绪状态,进行相应的IO系统调用。
IO多路复用(IO Multiplexing)是高性能Reactor线程模型的基础IO模型,当然,此模型是建立在同步非阻塞的模型基础之上的升级版。
- 信号驱动IO模型
在信号驱动IO模型中,用户线程通过向核心注册IO事件的回调函数,来避免IO时间查询的阻塞。
具体来说,用户进程预先在内核中设置一个回调函数,当某个事件发生时,内核使用信号(SIGIO)通知进程运行回调函数。然后进入IO操作的第二个阶段——执行阶段:用户线程会继续执行,在信号回调函数中调用IO读写操作来进行实际的IO请求操作。
信号驱动IO可以看成是一种异步IO,可以简单理解为系统进行用户函数的回调。只是,信号驱动IO的异步特性做的不彻底。为什么呢? 信号驱动IO仅仅在IO事件的通知阶段是异步的,而在第二阶段,也就是在将数据从内核缓冲区复制到用户缓冲区这个过程,用户进程是阻塞的、同步的。
- 异步IO(Asynchronous IO)
异步IO,指的是用户空间与内核空间的调用方式大反转。用户空间的线程变成被动接受者,而内核空间成了主动调用者。在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户缓冲区内,内核在IO完成后通知用户线程直接使用即可。
异步IO类似于Java中典型的回调模式,用户进程(或者线程)向内核空间注册了各种IO事件的回调函数,由内核去主动调用。
异步IO包含两种:不完全异步的信号驱动IO模型和完全的异步IO模型。
接下来,对以上的五种常见的IO模型进行一下详细的介绍。
2.2.1 同步阻塞IO(Blocking IO)
默认情况下,在Java应用程序进程中,所有对socket连接的进行的IO操作都是同步阻塞IO(Blocking IO)。
在阻塞式IO模型中,Java应用程序从发起IO系统调用开始,一直到系统调用返回,在这段时间内,发起IO请求的Java进程(或者线程)是阻塞的。直到返回成功后,应用进程才能开始处理用户空间的缓存区数据。
同步阻塞IO的具体流程,如图2-2所示。

图2-2 同步阻塞IO的流程
举个例子,在Java中发起一个socket的sys_read读操作的系统调用,流程大致如下:
(1)从Java进行IO读后发起sys_read系统调用开始,用户线程(或者线程)就进入阻塞状态。
(2)当系统内核收到sys_read系统调用,就开始准备数据。一开始,数据可能还没有到达内核缓冲区(例如,还没有收到一个完整的socket数据包),这个时候内核就要等待。
(3)内核一直等到完整的数据到达,就会将数据从内核缓冲区复制到用户缓冲区(用户空间的内存),然后内核返回结果(例如返回复制到用户缓冲区中的字节数)。
(4)直到内核返回后,用户线程才会解除阻塞的状态,重新运行起来。
阻塞IO的特点是:在内核进行IO执行的两个阶段,发起IO请求的用户进程(或者线程)被阻塞了。
阻塞IO的优点是:应用的程序开发非常简单;在阻塞等待数据期间,用户线程挂起,用户线程基本不会占用CPU资源。
阻塞IO的缺点是:一般情况下,会为每个连接配备一个独立的线程,一个线程维护一个连接的IO操作。在并发量小的情况下,这样做没有什么问题。
但是,当在高并发的应用场景下,需要大量的线程来维护大量的网络连接,内存、线程切换开销会非常巨大。在高并发应用场景中,阻塞IO模型是性能很低的,基本上是不可用的。
总之,阻塞IO 存在 c10k 问题。
所谓c10k问题,指的是:服务器如何支持10k个并发连接,也就是concurrent 10000 connection(这也是c10k这个名字的由来)。
由于硬件成本的大幅度降低和硬件技术的进步,如果一台服务器能够同时服务更多的客户端,那么也就意味着服务每一个客户端的成本大幅度降低。
从这个角度来看,c10k问题显得非常有意义。
2.2.2 同步非阻塞NIO(None Blocking IO)
在Linux系统下,socket连接默认是阻塞模式,可以通过设置将socket变成为非阻塞的模式(Non-Blocking)。在NIO模型中,应用程序一旦开始IO系统调用,会出现以下两种情况:
(1)在内核缓冲区中没有数据的情况下,系统调用会立即返回,返回一个调用失败的信息。
(2)在内核缓冲区中有数据的情况下,在数据的复制过程中系统调用是阻塞的,直到完成数据从内核缓冲复制到用户缓冲。复制完成后,系统调用返回成功,用户进程(或者线程)可以开始处理用户空间的缓存数据。
同步非阻塞IO的流程,如图2-3所示。

图2-3 同步非阻塞IO的流程
举个例子。发起一个非阻塞socket的sys_read读操作的系统调用,流程如下:
(1)在内核数据没有准备好的阶段,用户线程发起IO请求时,立即返回。所以,为了读取到最终的数据,用户进程(或者线程)需要不断地发起IO系统调用。
(2)内核数据到达后,用户进程(或者线程)发起系统调用,用户进程(或者线程)阻塞(大家一定要注意,此处用户进程的阻塞状态)。内核开始复制数据,它会将数据从内核缓冲区复制到用户缓冲区,然后内核返回结果(例如返回复制到的用户缓冲区的字节数)。
(3)用户进程(或者线程)在读数据时,没有数据会立即返回而不阻塞,用户空间需要经过多次的尝试,才能保证最终真正读到数据,而后继续执行。
同步非阻塞IO的特点:应用程序的线程需要不断地进行IO系统调用,轮询数据是否已经准备好,如果没有准备好,就继续轮询,直到完成IO系统调用为止。
同步非阻塞IO的优点:每次发起的IO系统调用,在内核等待数据过程中可以立即返回。用户线程不会阻塞,实时性较好。
同步非阻塞IO的缺点:不断地轮询内核,这将占用大量的CPU时间,效率低下。
总体来说,在高并发应用场景中,同步非阻塞IO是性能很低的,也是基本不可用的,一般Web服务器都不使用这种IO模型。在Java的实际开发中,也不会涉及这种IO模型。但是此模型还是有价值的,其作用在于,其他IO模型中可以使用非阻塞IO模型作为基础,以实现其高性能。
说明:
同步非阻塞IO也可以简称为NIO,但是,它不是Java编程中的NIO,虽然它们的英文缩写一样,但是不能混淆。Java的NIO(New IO)类库组件,所归属的不是基础IO模型中的NIO(None Blocking IO)模型,而是另外的一种模型,叫做IO多路复用模型(IO Multiplexing)。
2.2.3 IO多路复用模型(IO Multiplexing)
如何避免同步非阻塞IO模型中轮询等待的问题呢?这就是IO多路复用模型。
在IO多路复用模型中,引入了一种新的系统调用,查询IO的就绪状态。在Linux系统中,对应的系统调用为select/epoll系统调用。通过该系统调用,一个进程可以监视多个文件描述符(包括socket连接),一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核能够将就绪的状态返回给应用程序。随后,应用程序根据就绪的状态,进行相应的IO系统调用。
目前支持IO多路复用的系统调用,有select、epoll等等。select系统调用,几乎在所有的操作系统上都有支持,具有良好的跨平台特性。epoll是在Linux 2.6内核中提出的,是select系统调用的Linux增强版本。
在IO多路复用模型中通过select/epoll系统调用,单个应用程序的线程,可以不断地轮询成百上千的socket连接的就绪状态,当某个或者某些socket网络连接有IO就绪状态,就返回这些就绪的状态(或者说就绪事件)。
举个例子来说明IO多路复用模型的流程。发起一个多路复用IO的sys_read读操作的系统调用,流程如下:
(1)选择器注册。在这种模式中,首先,将需要sys_read操作的目标文件描述符(socket连接),提前注册到Linux的select/epoll选择器中,在Java中所对应的选择器类是Selector类。然后,才可以开启整个IO多路复用模型的轮询流程。
(2)就绪状态的轮询。通过选择器的查询方法,查询所有的提前注册过的目标文件描述符(socket连接)的IO就绪状态。通过查询的系统调用,内核会返回一个就绪的socket列表。当任何一个注册过的socket中的数据准备好或者就绪了,就是内核缓冲区有数据了,内核就将该socket加入到就绪的列表中,并且返回就绪事件。
(3)用户线程获得了就绪状态的列表后,根据其中的socket连接,发起sys_read系统调用,用户线程阻塞。内核开始复制数据,将数据从内核缓冲区复制到用户缓冲区。
(4)复制完成后,内核返回结果,用户线程才会解除阻塞的状态,用户线程读取到了数据,继续执行。
说明:
在用户进程进行IO就绪事件的轮询时,需要调用了选择器的select查询方法,发起查询的用户进程或者线程是阻塞的。当然,如果使用了查询方法的非阻塞的重载版本,发起查询的用户进程或者线程也不会阻塞,重载版本会立即返回。
IO多路复用模型的sys_read系统调用流程,如图2-4所示。

图2-4 IO多路复用模型的sys_read系统调用流程
IO多路复用模型的特点:IO多路复用模型的IO涉及两种系统调用,一种是IO操作的系统调用,另一种是select/epoll就绪查询系统调用。IO多路复用模型建立在操作系统的基础设施之上,即操作系统的内核必须能够提供多路分离的系统调用select/epoll。
和NIO模型相似,多路复用IO也需要轮询。负责select/epoll状态查询调用的线程,需要不断地进行select/epoll轮询,查找出达到IO操作就绪的socket连接。
IO多路复用模型与同步非阻塞IO模型是有密切关系的,具体来说,注册在选择器上的每一个可以查询的socket连接,一般都设置成为同步非阻塞模型。只是这一点对于用户程序而言,是无感知的。
IO多路复用模型的优点:一个选择器查询线程,可以同时处理成千上万的网络连接,所以,用户程序不必创建大量的线程,也不必维护这些线程,从而大大减小了系统的开销。这是一个线程维护一个连接的阻塞IO模式相比,使用多路IO复用模型的最大优势。
通过JDK的源码可以看出,Java语言的NIO(New IO)组件,在Linux系统上,是使用的是select系统调用实现的。所以,Java语言的NIO(New IO)组件所使用的,就是IO多路复用模型。
IO多路复用模型的缺点:本质上,select/epoll系统调用是阻塞式的,属于同步阻塞IO。都需要在读写事件就绪后,由系统调用本身负责进行读写,也就是说这个事件的查询过程是阻塞的。
如果彻底地解除线程的阻塞,就必须使用异步IO模型。
2.2.4 信号驱动IO模型(SIGIO、Signa- Driven I/O)
在信号驱动IO模型中,用户线程通过向核心注册IO事件的回调函数,来避免IO时间查询的阻塞。
具体的做法是,用户进程预先在内核中设置一个回调函数,当某个事件发生时,内核使用信号(SIGIO)通知进程运行回调函数。 然后用户线程会继续执行,在信号回调函数中调用IO读写操作来进行实际的IO请求操作。
信号驱动IO的基本流程是:用户进程通过系统调用,向内核注册SIGIO信号的owner进程和以及进程内的回调函数。内核IO事件发生后(比如内核缓冲区数据就位)后,通知用户程序,用户进程通过sys_read系统调用,将数据复制到用户空间,然后执行业务逻辑。

信号驱动IO模型,每当套接字发生IO事件时,系统内核都会向用户进程发送SIGIO事件,所以,一般用于UDP传输,在TCP套接字的开发过程中很少使用,原因是SIGIO信号产生得过于频繁,并且内核发送的SIGIO信号,并没有告诉用户进程发生了什么IO事件。
但是在UDP套接字上,通过SIGIO信号进行下面两个事件的类型判断即可:
- 数据报到达套接字
- 套接字上发生错误
因此,在SIGIO出现的时候,用户进程很容易进行判断和做出对应的处理:如果不是发生错误,那么就是有数据报到达了。
举个例子。发起一个异步IO的sys_read读操作的系统调用,流程如下:
(1)设置SIGIO信号的信号处理回调函数。
(2)设置该套接口的属主进程,使得套接字的IO事件发生时,系统能够将SIGIO信号传递给属主进程,也就是当前进程。
(3)开启该套接口的信号驱动I/O机制,通常通过使用fcntl方法的F_SETFL操作命令,使能(enable)套接字的 O_NONBLOCK非阻塞标志和O_ASYNC异步标志完成。
完成以上三步,用户进程就完成了事件回调处理函数的设置。当文件描述符上有事件发生时,SIGIO 的信号处理函数将被触发,然后便可对目标文件描述符执行 I/O 操作。关于以上三步的详细介绍,具体如下:
第一步:设置SIGIO信号的信号处理回调函数。Linux中通过 sigaction() 来完成。参考的代码如下:
// 注册SIGIO事件的回调函数
sigaction(SIGIO, &act, NULL);
sigaction函数的功能是检查或修改与指定信号相关联的处理动作(可同时两种操作),函数的原型如下:
int sigaction(int signum, const struct sigaction *act,
struct sigaction *oldact);
对其中的参数说明如下:
- signum参数指出要捕获的信号类型
- act参数指定新的信号处理方式
- oldact参数输出先前信号的处理方式(如果不为NULL的话)。
该函数是Linux系统的一个基础函数,不是为信号驱动IO特供的。在信号驱动IO的使用场景中,signum的值为常量 SIGIO。
第二步:设置该套接口的属主进程,使得套接字的IO事件发生时,系统能够将SIGIO信号传递给属主进程,也就是当前进程。属主进程是当文件描述符上可执行 I/O 时,会接收到通知信号的进程或进程组。
为文件描述符的设置IO事件的属主进程,通过 fcntl() 的 F_SETOWN 操作来完成,参考的代码如下:
fcntl(fd,F_SETOWN,pid)
当参数pid 为正整数时,代表了进程 ID 号。当参数pid 为负整数时,它的绝对值就代表了进程组 ID 号。
第三步:开启该套接口的信号驱动IO机制,通常通过使用fcntl方法的F_SETFL操作命令,使能(enable)套接字的 O_NONBLOCK非阻塞标志和O_ASYNC异步标志完成。参考的代码如下:
int flags = fcntl(socket_fd, F_GETFL, 0);
flags |= O_NONBLOCK; //设置非阻塞
flags |= O_ASYNC; //设置为异步
fcntl(socket_fd, F_SETFL, flags );
这一步通过 fcntl() 的 F_SETF- 操作来完成,O_NONBLOCK为非阻塞标志,O_ASYNC为信号驱动 I/O的标志。
使用事件驱动IO进行UDP通信应用的开发,参考的代码如下(C代码):
int socket_fd = 0;
//事件的处理函数
void do_sometime(int signal) {
struct sockaddr_in cli_addr;
int clilen = sizeof(cli_addr);
int clifd = 0;
char buffer[256] = {0};
int len = recvfrom(socket_fd, buffer, 256, 0, (struct sockaddr *)&cli_addr,
(socklen_t)&clilen);
printf("Mes:%s", buffer);
//回写
sendto(socket_fd, buffer, len, 0, (struct sockaddr *)&cli_addr, clilen);
}
int main(int argc, char const *argv[]) {
socket_fd = socket(AF_INET, SOCK_DGRAM, 0);
struct sigaction act;
act.sa_flags = 0;
act.sa_handler = do_sometime;
// 注册SIGIO事件的回调函数
sigaction(SIGIO, &act, NULL);
struct sockaddr_in servaddr;
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(8888);
servaddr.sin_addr.s_addr = INADDR_ANY;
//第二步为文件描述符的设置 属主
//设置将要在socket_fd上接收SIGIO的进程
fcntl(socket_fd, F_SETOWN, getpid());
//第三步:使能套接字的信号驱动IO
int flags = fcntl(socket_fd, F_GETFL, 0);
flags |= O_NONBLOCK; //设置非阻塞
flags |= O_ASYNC; //设置为异步
fcntl(socket_fd, F_SETFL, flags );
bind(socket_fd, (struct sockaddr *)&servaddr, sizeof(servaddr));
while (1) sleep(1); //死循环
close(socket_fd);
return 0;
}
当套件字的IO事件发生时,回调函数被执行,在回调函数中,用户进行执行数据复制即可。
信号驱动IO优势:用户进程在等待数据时,不会被阻塞,能够提高用户进程的效率。具体来说:在信号驱动式I/O模型中,应用程序使用套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。
信号驱动IO缺点:
- 在大量IO事件发生时,可能会由于处理不过来,而导致信号队列溢出。
- 对于处理UDP套接字来讲,对于信号驱动I/O是有用的。可是,对于TCP而言,由于致使SIGIO信号通知的条件为数众多,进行IO信号进一步区分的成本太高,信号驱动的I/O方式近乎无用。
- 信号驱动IO可以看成是一种异步IO,可以简单理解为系统进行用户函数的回调。只是,信号驱动IO的异步特性,又做的不彻底。为什么呢? 信号驱动IO仅仅在IO事件的通知阶段是异步的,而在第二阶段,也就是在将数据从内核缓冲区复制到用户缓冲区这个过程,用户进程是阻塞的、同步的。
如果要做彻底的异步IO,那就需要使用第五种IO模式:异步IO模式。
2.2.5 异步IO模型(Asynchronous IO)
异步IO模型(Asynchronous IO,简称为AIO)。AIO的基本流程是:用户线程通过系统调用,向内核注册某个IO操作。内核在整个IO操作(包括数据准备、数据复制)完成后,通知用户程序,用户执行后续的业务操作。
在异步IO模型中,在整个内核的数据处理过程中,包括内核将数据从网络物理设备(网卡)读取到内核缓冲区、将内核缓冲区的数据复制到用户缓冲区,用户程序都不需要阻塞。
异步IO模型的流程,如图2-5所示。

图2-5 异步IO模型的流程
举个例子。发起一个异步IO的sys_read读操作的系统调用,流程如下:
(1)当用户线程发起了sys_read系统调用(可以理解为注册一个回调函数),立刻就可以开始去做其他的事,用户线程不阻塞。
(2)内核就开始了IO的第一个阶段:准备数据。等到数据准备好了,内核就会将数据从内核缓冲区复制到用户缓冲区。
(3)内核会给用户线程发送一个信号(Signal),或者回调用户线程注册的回调方法,告诉用户线程,sys_read系统调用已经完成了,数据已经读入到了用户缓冲区。
(4)用户线程读取用户缓冲区的数据,完成后续的业务操作。
异步IO模型的特点:在内核等待数据和复制数据的两个阶段,用户线程都不是阻塞的。用户线程需要接收内核的IO操作完成的事件,或者用户线程需要注册一个IO操作完成的回调函数。正因为如此,异步IO有的时候也被称为信号驱动IO。
异步IO异步模型的缺点:应用程序仅需要进行事件的注册与接收,其余的工作都留给了操作系统,也就是说,需要底层内核提供支持。
理论上来说,异步IO是真正的异步输入输出,它的吞吐量高于IO多路复用模型的吞吐量。就目前而言,Windows系统下通过IOCP实现了真正的异步IO。而在Linux系统下,异步IO模型在2.6版本才引入,JDK的对其的支持目前并不完善,因此异步IO在性能上没有明显的优势。
大多数的高并发服务器端的程序,一般都是基于Linux系统的。因而,目前这类高并发网络应用程序的开发,大多采用IO多路复用模型。大名鼎鼎的Netty框架,使用的就是IO多路复用模型,而不是异步IO模型。
2.2.6 同步异步、阻塞非阻塞区别联系
首先同步和异步,是针对应用程序(如Java)与内核的交互过程的方向而言的。
同步类型的IO操作,发起方是应用程序,接收方是内核。
同步IO由应用进程发起IO操作,并阻塞等待,或者轮询的IO操作是否完成。
异步IO操作,应用程序在提前注册完成回调函数之后去做自己的事情,IO交给内核来处理,在内核完成IO操作以后,启动进程的回调函数。
阻塞与非阻塞,关注的是用户进程在IO过程中的等待状态。前者用户进程需要为IO操作去阻塞等待,而后者用户进程可以不用为IO操作去阻塞等待。同步阻塞型IO、同步非阻塞IO、多路IO复用,都是同步IO,也是阻塞性IO。
异步IO必定是非阻塞的,所以不存在异步阻塞和异步非阻塞的说法。真正的异步IO需要内核的深度参与。异步IO中的用户进程时候根本不去考虑IO的执行,IO操作主要交给内核去完成,而自己只等待一个完成信号。
2.3 通过合理配置来支持百万级并发连接
本章所聚焦的主题,是高并发IO的底层原理。前面已经深入浅出地介绍了高并发IO的模型。但是,即使采用了最先进的模型,如果不进行合理的操作系统配置,也没有办法支撑百万级的网络连接并发。在生产环境中,大家都使用Linux系统,所以,后续文字如果没有特别说明,所指的操作系统都是Linux系统。
说明:
在 Linux 环境中,任何事物都是用文件来表示,设备是文件,目录是文件,socket 也是文件。用来表示所处理对象的接口和唯一接口就是文件。应用程序在读/写一个文件时,首先需要打开这个文件,打开的过程其实质就是在进程与文件之间建立起连接,句柄的作用就是唯一标识此连接。此后对文件的读/写时,由这个句柄作为代表。最后关闭文件其实就是释放这个句柄的过程,也就是进程与文件之间的连接断开。。
这里所涉及的配置,就是Linux操作系统中文件句柄数的限制。在生产环境Linux系统中,基本上都需要解除文件句柄数的限制。原因是,Linux的系统默认值为1024,也就是说,一个进程最多可以接受1024个socket连接。这是远远不够的。
本书的原则是:从基础讲起。
文件句柄,也叫文件描述符。在Linux系统中,文件可分为:普通文件、目录文件、链接文件和设备文件。文件描述符(File Descriptor)是内核为了高效管理已被打开的文件所创建的索引,它是一个非负整数(通常是小整数),用于指代被打开的文件。所有的IO系统调用,包括socket的读写调用,都是通过文件描述符完成的。
在Linux下,通过调用ulimit命令,可以看到一个进程能够打开的最大文件句柄数量,这个命令的具体使用方法是:
ulimit -n
ulimit 命令是用来显示和修改当前用户进程一些基础限制的命令,-n选项用于引用或设置当前的文件句柄数量的限制值,Linux的系统默认值为1024。
理论上1024个文件描述符,对绝大多数应用(例如Apache、桌面应用程序)来说已经足够了。但是,是对于一些用户基数很大的高并发应用,则是远远不够的。一个高并发的应用,面临的并发连接数往往是十万级、百万级、甚至像腾讯QQ一样的上亿级。
文件句柄数不够,会导致什么后果呢?当单个进程打开的文件句柄数量超过了系统配置的上限值时,就会发出“Socket/File:Can't open so many files”的错误提示。
所以,对于高并发、高负载的应用,就必须要调整这个系统参数,以适应处理并发处理大量连接的应用场景。可以通过ulimit来设置这两个参数。方法如下:
ulimit -n 1000000
在上面的命令中,n的设置值越大,可以打开的文件句柄数量就越大。建议以root用户来执行此命令。
使用ulimit命令有一个缺陷,该命令仅仅只能修改当前用户环境的一些基础限制,仅在当前用户环境有效。也即是说,在当前的终端工具连接当前shell期间,修改是有效的;一旦断开用户会话,或者说用户退出Linux后,它的数值就又变回系统默认的1024了。并且,系统重启后,句柄数量又会恢复为默认值。
ulimit命令只能用于临时修改,如果想永久地把最大文件描述符数量值保存下来,可以编辑/etc/rc.local开机启动文件,在文件中添加如下内容:
ulimit -SHn 1000000
以上示例增加-S和-H两个命令选项。选项-S表示软性极限值,-H表示硬性极限值。硬性极限是实际的限制,就是最大可以是100万,不能再多了。软性极限值则是系统发出警告(Warning)的极限值,超过这个极限值,内核会发出警告。
普通用户通过ulimit命令,可将软极限更改到硬极限的最大设置值。如果要更改硬极限,必须拥有root用户权限。
终极解除Linux系统的最大文件打开数量的限制,可以通过编辑Linux的极限配置文件/etc/security/limits.conf来解决,修改此文件,加入如下内容:
* soft nofile 1000000
* hard nofile 1000000
soft nofile表示软性极限,hard nofile表示硬性极限。
举个实际例子,在使用和安装目前非常流行的分布式搜索引擎——ElasticSearch时,基本上就必须去修改这个文件,用于增加最大的文件描述符的极限值。当然,在生产环境运行Netty时,最好是修改/etc/security/limits.conf文件,增加文件描述符数量的限制。
除了修改应用进程的文件句柄上限之外,还需要修改内核基本的全局文件句柄上限,通过修改 /etc/sysctl.conf 配置文件来更改,参考的配置如下:
fs.file-max = 2048000
fs.nr_open = 1024000
fs.file-max表示系统级别的能够打开的文件句柄的上限,可以理解为全局的句柄数上限。是对整个系统的限制,并不是针对用户的。
fs.nr_open指定了单个进程可打开的文件句柄的数量限制,nofile受到这个参数的限制,nofile值不可用超过fs.nr_open值。
2.4 本章小结
本书的原则是:从基础讲起。本章彻底体现了这个原则。
本章聚焦的主题:一是底层IO操作的两个阶段,二是最为基础的四种IO模型,三是操作系统对高并发的底层的支持。
四种IO模型,基本上概况了当前主要的IO处理模型,理论上来说,从阻塞IO到异步IO,越往后,阻塞越少,效率也越优。在这四种IO模型中,前三种属于同步IO,因为真正的IO操作都将阻塞应用线程。
只有最后一种异步IO模型,才是真正的异步IO模型,可惜目前Linux操作系统或者说JDK的底层实现尚欠完善。不过,通过应用层优秀框架如Netty,同样能在IO多路复用模型的基础上,开发出具备支撑高并发(如百万级以上的连接)的服务器端应用。
最后强调一下,本章是理论课,比较抽象,但是一定要懂,理解了这些理论之后,再学习后面的章节就会事半功倍。
分层解耦的重要性
在尼恩的疯狂创客圈社群(50+)中, 经常有人被 IO模型, Reactor反应器模型,同步、异步搞晕。
尼恩用几十年的经验总结,给大家做一个简单梳理:
- 一定要分层,就想 WEB应用架构要分层一样。
- 线程模型和IO模型,要分开来看,不能混为一谈。
很多小伙伴把Reactor 反应器,一定认为底层的IO模型是NIO, 大家去看看Netty源码, Netty反应器,支持各种IO模,包括BIO。
所以,一定要分层去看。
尼恩把线程模型和IO模型的,给大家分为三层: 应用层、框架层、 OS层。
具体如下图所示:

Netty的 Reactor 模式,对应到是:线程模型, 而不是对应到 IO模型。
在IO模型的层面,Tomcat 也用了 NIO,大家一定不要以为Tomcat还用BIO,还用 ,大部分的HTTPClient客户端组件,都用了NIO,都不会使用BIO模型的。
在线程模型的层面,很多的HTTPClient组件,要么没有使用 Reactor模型,要么是使用了Reactor反应性线程模型,但是我们的业务程序不用,咱们的业务程序,用的还是其同步阻塞线程模型的API代码。

再谈阻塞与非阻塞、同步与异步
接下来,回到IO中特别容易混淆的概念:阻塞与同步,非阻塞与异步。
注意, 同步io、异步io,更多是在 OS操作系统层来谈的。
这里我们可以将整个流程总结为两个阶段:
- 数据准备阶段: 网络数据包到达网卡,通过
DMA(专门的辅助芯片) 方式将数据包拷贝到内存中,然后经过硬中断,软中断,接着通过内核线程ksoftirqd经过内核协议栈的处理,最终将数据发送到 内核Socket的接收缓冲区 receive buffer 中。 - 数据拷贝阶段: 当数据到达 内核Socket 的receive buffer 接收缓冲区中时,此时数据存在于内核空间 中,需要将数据拷贝到用户空间中,才能够被应用程序读取。

难点1:io模型中,阻塞与非阻塞的区别?
回到 io模型中,阻塞与非阻塞的区别。
阻塞与非阻塞的区别,主要发生在第一阶段:数据准备阶段。
讨论区别之前,假设一个业务场景:
在读数据场景中,应用程序发起系统调用read。
这时候,线程从用户态转为内核态,内核线程 试图去 读取内核 Socket的receive buffer 接收缓冲区中的网络数据,两种情况:
- 如果receive buffer 有数据的话,就进行 数据内存复制,
- 如果receive buffer 没有数据的话 ,怎么办?
处理的方式一:阻塞
如果这时内核Socket的接收缓冲区没有数据,那么线程就会一直阻塞等待,直到Socket接收缓冲区有数据为止。

等有了数据, 随后将数据从内核空间拷贝到用户空间,系统调用read返回。
从图中我们可以看出:阻塞的特点是在第一阶段和第二阶段 都会等待。
处理的方式二:非阻塞(轮询)
数据准备阶段, 如果receive buffer 没有数据的话 ,怎么办?
处理的方式二: 非阻塞 非阻塞(轮询):

非阻塞IO
从上图中,我们可以看出:非阻塞的特点是第一阶段不会等待,但是在第二阶段还是会等待。
阻塞与非阻塞的区别
- 在第一阶段,当
Socket的接收缓冲区中没有数据的时候,阻塞模式下,IO线程会一直等待,一直干等,不能不干别的。注意,线程资源是宝贵的,如果IO连接越多,线程资源就会耗光。 非阻塞模式下IO线程不会等待,系统调用直接返回错误标志EWOULDBLOCK 。为了读到数据,非阻塞模式下, IO线程需要一致轮询。当然,也可以先去干别的事情,过一会再来轮询。 - 在第二阶段,当
Socket的接收缓冲区中有数据的时候,阻塞和非阻塞的表现是一样的,都会进入CPU数据复制操作,数据从内核空间拷贝到用户空间,然后系统调用返回。
难点2:io模型中,同步与异步的区别?
同步与异步的区别, 主要在第二阶段:数据拷贝阶段。
第二阶段数据拷贝干了啥?
数据拷贝属于cpu复制, 主要是将数据从内核空间Socket接收缓冲区,拷贝到用户空间的 字节数组,比如 nio buffer里边的 数组 。然后应用程序才可以操作这些数据。
同步与异步的区别, 就是 数据拷贝 发起方 不同。
在数据准备好,到了Socket接收缓冲区后,用户线程通过轮询,查询到了io事件(有数据可以读)
主要,接下来,开始执行内核程序,复制数据。
关键是,找个工作,谁来发起呢?
- io线程发起
- 内核线程发起
处理方式一:io线程发起数据拷贝

同步类型的IO操作,发起方是应用程序,接收方是内核。
同步IO由应用进程发起IO数据copy操作,把数据从 内核空间Socket接收缓冲区拷贝到用户空间的 字节数组,比如 nio buffer里边的 数组,或者轮询的IO数据复制是否完成。
注意这里是操作系统 , 完成这个操作的线程, 可以是io线程的内核态, 或者是一个另外的内核线程。 在操作系统中, 线程仅仅是一个 task 任务结构, 不同的操作系统,或者同一个操作系统的不同版本, 对这个 用户task 和 内核task 的处理,不一样。
咱们这里不用去纠结:
- 到底是,io线程(内核态) 亲自下场,自己去做cpu复制,
- 还是 io线程阻塞, 另外的内核线程去复制,完了再唤醒io线程
作为我们处于应用层的架构人员/开发人员, 在这里不纠结。
这里,假设底层用的是方案二, io线程阻塞, 另外的内核线程去复制,完了再唤醒io线程。
无论如何,同步 io,都是 由io线程发起数据拷贝, 承担 数据copy 发起方的职责, 这点是毋庸置疑的。
所以,
Linux下的 select 、epoll 都是io线程发起了 数据复制, 所以都 属于同步 IO。
Mac 下的 kqueue是io线程发起了 数据复制, 所以都 属于同步 IO。
处理方式二:内核线程发起数据拷贝
处理方式二:特点是,内核线程发起数据拷贝,而且由内核线程来执行第二阶段的数据拷贝操作,这就是 异步模式
当内核执行完数据拷贝操作后,会将数据回调给用户线程。
所以在异步模式下,关键是回调。
io线程只要注册好 数据的回调处理函数就OK了。
异步模式下, 数据准备阶段和数据拷贝阶段均是由内核来完成,不会对应用程序造成任何阻塞。

目前流行的操作系统中,Windows 中的 IOCP才真正属于异步 IO,实现的也非常成熟。
关键是,Windows很少用来作为服务器使用。
而常用来作为服务器使用的Linux,异步IO机制实现的不够成熟,与NIO相比性能提升的也不够明显。
Linux kernel 在5.1版本由Facebook的大神Jens Axboe引入了新的异步IO库io_uring ,改善了原来Linux native AIO的一些性能问题。
io_uring 性能相比Epoll以及之前原生的AIO提高了不少,本圣经后面有介绍。
异步IO库io_uring ,具体参见后面的章节: 干翻 nio ,王炸 io_uring 来了 !!
阻塞IO(BIO)的底层原理
接下来,尼恩带着大家从 最简单的 bio入手, 一步一步,穿透底层的 nio
数据的读取过程:dma 把接收到的数据写入Socket内核缓冲
首先,看看宏观的数据的读取过程
前面讲到, 宏观的数据的读取过程是:dma 会把网卡接收到的数据写入Socket内核缓冲

①阶段: 网卡收到网线传来的数据
②阶段: dma 硬件电路的传输;
③阶段: 最终将数据写入到内存核心空间 地址上
这个过程涉及到DMA传输、IO通路选择等硬件有关的知识


BIO的应用层网络编程
这是一段最基础的网络编程代码,
下面是 应用层的服务端 伪代码,先新建 socket 对象,依次调用 bind 、 listen 、 accept , 最后调用 recv 接收数据。
//创建socket
int s = socket(AF_INET, SOCK_STREAM, 0);
//绑定
bind(s, ...)
//监听
listen(s, ...)
//接受客户端连接
int c = accept(s, ...)
//接收客户端数据
recv(c, ...);
//将数据打印出来
printf(...)
应用层的服务端 和客户端的交互流程,大致如下:

为了方便后面的介绍,咱们来看几个操作系统维度的,基础 概念。
从这里开始,就知道 操作系统 这门课的重要性了。
咱们大学的时候, 稀里糊涂的在学习 操作系统, 以为没什么卵子用, 结果, 是有大用的,只是自己不知道。
这就是 无知者无畏。
操作系统工作队列
操作系统为了支持多任务,实现了进程调度的功能,会把进程分为“运行”和“等待”等几种状态。
-
运行状态是进程获得cpu使用权,正在执行代码的状态;
-
等待状态是阻塞状态,比如上述程序运行到recv时,程序会从运行状态变为等待状态,接收到数据后又变回运行状态。
操作系统会分时执行各个运行状态的进程,由于速度很快,看上去就像是同时执行多个任务。
下图中的计算机中运行着A、B、C三个进程,其中进程A执行着上述基础网络程序,一开始,这3个进程都被操作系统的工作队列所引用,处于运行状态,会分时执行。

操作系统 底层的 socket 结构
socket 结构,简单的理解, 属于 文件描述符的扩展结构。
socket 结构,拥有 文件描述符的 一些基础 属性,比如 文件描述符 id。也有一些扩展属性,比如发送缓存,接受缓存,等等一大堆。
当进程 A 执行到创建 socket 的语句时,操作系统会创建一个由文件系统管理的 socket 结构(java对象)。
这个 socket 对象包含了
- 发送缓冲区
- 接收缓冲区
- 等待队列等成员
socket 的等待队列是个非常重要的结构,它指向所有需要等待该 socket 事件的进程。
socket 结构图解

Socket的创建
服务端线程调用accept系统调用后开始阻塞,当有客户端连接上来并完成TCP三次握手后,内核会创建一个对应的Socket 作为服务端与客户端通信的内核接口。
在Linux内核的角度看来,一切皆是文件,Socket也不例外,当内核创建出Socket之后,会将这个Socket放到当前进程所打开的文件列表中管理起来。
下面,来看下进程管理这些打开的文件列表相关的内核数据结构是什么样的?

struct task_struct是内核中用来表示进程/线程的一个数据结构,它包含了进程的所有信息。
这里,只列出和文件管理相关的属性。
一个进程内打开的所有文件,是通过一个数组fd_array来进行组织管理,数组的下标即为我们常提到的文件描述符,数组中存放的是对应的文件数据结构struct file。
每打开一个文件,内核都会创建一个struct file与之对应,并在fd_array中找到一个空闲位置分配给它,数组中对应的下标,就是我们在用户空间用到的文件描述符。
对于任何一个进程,默认情况下,文件描述符 0表示 stdin 标准输入,文件描述符 1表示stdout 标准输出,文件描述符2表示stderr 标准错误输出。
前面讲到,一个Socket,也是一个文件描述符 ,socket的大致结构如下:

文件描述符,用于封装文件元信息,它的内核数据结构struct file中。
文件描述符,有一个private_data指针,指向具体的Socket结构。
struct file中的file_operations属性定义了文件的操作函数,不同的文件类型,对应的file_operations是不同的,针对Socket文件类型,这里的file_operations指向socket_file_ops。
我们在用户空间对Socket发起的读写等系统调用,进入内核首先会调用的是Socket对应的struct file中指向的socket_file_ops。
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_sock_ioctl,
#endif
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
比如:对Socket发起write写操作,在内核中首先被调用的就是socket_file_ops中定义的sock_write_iter。Socket发起read读操作内核中对应的则是sock_read_iter。
static ssize_t sock_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct socket *sock = file->private_data;
struct msghdr msg = {.msg_iter = *from,
.msg_iocb = iocb};
ssize_t res;
......
res = sock_sendmsg(sock, &msg);
*from = msg.msg_iter;
return res;
}
Socket内核结构
在进行网络程序的编写时会首先创建一个Socket,然后基于这个Socket进行bind,listen,
这个Socket称作为监听Socket。
这里需要注意的是,监听的 socket并不是数据传输的 Socket,监听socket和数据传输的 Socket是两类 Socket,一个叫作监听 Socket,一个叫数据传输Socket。
当我们调用accept后,内核会基于监听Socket创建出来一个新的Socket,专门用于与客户端之间的网络通信,这就是数据传输Socket。
在创建好传输socket后,并将监听Socket中的Socket操作函数集合(inet_stream_ops)ops赋值到新的Socket的ops属性中。
const struct proto_ops inet_stream_ops = {
.bind = inet_bind,
.connect = inet_stream_connect,
.accept = inet_accept,
.poll = tcp_poll,
.listen = inet_listen,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
......
}
接着内核会为已连接的Socket创建struct file并初始化,并把Socket文件操作函数集合(socket_file_ops)赋值给struct file中的f_ops指针。然后将struct socket中的file指针指向这个新分配申请的struct file结构体。
内核会维护两个队列:
-
一个是已经完成TCP三次握手,连接状态处于established的连接队列。内核中为icsk_accept_queue。
-
一个是还没有完成TCP三次握手,连接状态处于syn_rcvd的半连接队列。
然后调用socket->ops->accept,这里其实调用的是inet_accept,该函数会在icsk_accept_queue中查找是否有已经建立好的连接,如果有的话,直接从icsk_accept_queue中获取已经创建好的struct sock,并将这个struct sock对象赋值给struct socket中的sock指针。

struct sock在struct socket中是一个非常核心的内核对象,在这里,定义了我们在介绍网络包的接收发送流程中提到的接收队列,发送队列,等待队列,数据就绪回调函数指针,内核协议栈操作函数集合
然后,根据创建Socket时发起的系统调用sock_create中的protocol参数(TCP参数值为SOCK_STREAM),查找到对于 tcp 定义的操作方法实现集合 inet_stream_ops 和tcp_prot,并把它们分别设置到socket->ops和sock->sk_prot上。
socket相关的操作接口定义在struct socket结构的 ops指针指向的 inet_stream_ops函数集合中,负责对上给用户提供接口。 这个对上,对外,对应用层。
而socket与内核协议栈之间的操作接口定义在struct sock中的sk_prot指针上,这里指向tcp_prot协议操作函数集合。 这个对下,对内,对协议栈。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.backlog_rcv = tcp_v4_do_rcv,
......
}
之前提到的对Socket发起的系统IO调用,在内核中首先会调用Socket的文件结构struct file中的file_operations文件操作集合,然后调用struct socket中的ops指向的inet_stream_opssocket操作函数,最终调用到struct sock中sk_prot指针指向的tcp_prot内核协议栈操作函数接口集合。

系统IO调用结构
- 将struct sock 对象中的sk_data_ready 函数指针设置为 sock_def_readable,在Socket数据就绪的时候内核会回调该函数。
- struct sock中的等待队列sk_wq中存放的是系统IO调用发生阻塞的进程fd,以及相应的回调函数。记住这个地方,后边介绍会提到!
当struct file,struct socket,struct sock这些核心的内核对象创建好之后,最后就是把socket对象对应的struct file放到进程打开的文件列表fd_array中。随后系统调用accept返回socket的文件描述符fd给用户程序。
进程 A 从工作队列移动到该 socket 的等待队列中
阻塞IO的场景,当用户进程发起系统IO调用比如read时,用户进程会在内核态查看对应Socket接收缓冲区是否有数据到来。
- Socket接收缓冲区有数据,则拷贝数据到用户空间,系统调用返回。
- Socket接收缓冲区没有数据,则用户进程让出CPU进入阻塞状态,
- 当数据到达接收缓冲区时,用户进程会被唤醒,从阻塞状态进入就绪状态,等待CPU调度。
这里关注 Socket接收缓冲区没有数据,则用户进程让出CPU,进入阻塞状态 。
用户进程让出CPU,进入阻塞状态 ,操作系统会将进程 A 从工作队列移动到该 socket 的等待队列中 。
进程/线程阻塞。(注意,内核里边, 进程和线程,是一回事,都是task任务)

-
首先我们在用户进程中对Socket进行read系统调用时,用户进程会从用户态转为内核态。
-
在进程的struct task_struct结构找到fd_array,并根据Socket的文件描述符fd找到对应的struct file,调用struct file中的文件操作函数结合file_operations,read系统调用对应的是sock_read_iter。
-
在sock_read_iter函数中找到struct file指向的struct socket,并调用socket->ops->recvmsg,这里我们知道调用的是inet_stream_ops集合中定义的inet_recvmsg。
-
在inet_recvmsg中会找到struct sock,并调用sock->skprot->recvmsg,这里调用的是tcp_prot集合中定义的tcp_recvmsg函数。
在tcp_recvmsg内核函数中,将用户进程给阻塞掉的, 具体流程如下:

以上流程是linux的内核结构,和相关流程,大家不用太细致扣。
总之, 进程 task,进入到了 sk_wq 对待队列, 并将进程设置为可打断 INTERRUPTIBL。
调用sk_wait_event让出CPU,进程进入睡眠状态。
cpu 进行其他的进程调度, 当前进程离开cpu 的工作队列了。
题外知识:被阻塞的线程,是不会占用CPU资源
上图中,由于工作队列只剩下了进程 B 和 C ,依据进程调度, cpu 会轮流执行这两个进程的程序,
不会执行进程 A 的程序。
所以进程 A 被阻塞,不会往下执行代码,也不会占用 cpu 资源。

什么又是CPU的工作队列?
CPU的工作队列

操作系统维度的知识,回去翻翻课本。
线程、CPU与工作队列之间的关系

操作系统维度的知识,回去翻翻课本。
内核接收数据全过程
当 socket 接收到数据后,操作系统将该 socket 等待队列上的进程重新放回到工作队列,该进程变成运行状态,继续执行代码。
由于 socket 的接收缓冲区已经有了数据, recv 可以返回接收到的数据。

内核接收数据全过程:
-
计算机收到了对端传送的数据(步骤 ①)
-
数据经由网卡传送到内存(步骤 ②)
-
然后网卡通过中断信号通知 CPU 有数据到达,CPU 执行中断程序(步骤 ③)
-
中断程序先将网络数据写入到对应 Socket 的接收缓冲区里面(步骤 ④)
-
再唤醒进程 A(步骤 ⑤),重新将进程 A 放入工作队列中。
唤醒进程的过程如下图所示:

问题1:内核如何知道接收的网络数据时属于哪个socket?
socket数据包格式(源ip,源端口,协议,目的ip,目的端口)
一般通过目的ip,目的端口 就可以识别出来接收到的网络数据属于哪个socket。
如果目的ip,目的端口相同呢?
其实多个客户端与同一个服务端建立了连接,这个时候内核就会有多个socket。
并且为它们分配多个fd文件描述符。它们收到网络数据后无法通过目的端口来直接匹配socket,还需要再通过源ip和端口来确定属于哪个socket。
问题2:内核如何同时监控多个socket?
内核如何同时监控多个socket? 一个专用线程轮询所有socket,当某个socket有数据到达了,就通知用户io线程。
目前的经典解决办法:I/O 多路复用, 也就是IO multiplexing
多路复用在Linux内核代码迭代过程中依次支持了三种调用:
-
SELECT
-
POLL
-
EPOLL
IO多路复用
如何用尽可能少的线程去处理更多的连接,提升性能?
一个专用线程轮询所有socket,当某个socket有数据到达了,就通知用户io线程。
目前的经典解决办法:I/O 多路复用, 也就是IO multiplexing
IO multiplexing,涉及两个概念:
-
多路:尽可能少的线程来处理尽可能多的连接,这里的 多路 , 指的就是 需要处理的 连接。
bio ,阻塞式的,在阻塞IO模型中一个连接就需要分配一个独立的线程去专门处理这个连接上的读写,
所以 bio 就是 单路
-
复用:使用 尽可能少的线程 ,尽可能少的系统开销, 指的是线程的复用
那么这里的复用指的就是用有限的资源,比如用一个线程或者固定数量的线程去处理众多连接上的读写事件。
换句话说,到了IO多路复用模型中,多个连接可以复用这一个独立的线程去处理这多个连接上的读写。
如何让一个独立的线程去处理众多连接上的读写事件呢?
IO multiplexing 进行了 一次大解耦 , 把 IO 事件 (可以操作状态) ,和IO的操作,进行剥离
解耦出一个独立的 系统调用, 查询 IO 事件 (可以操作状态) ,
剩下的read、write等系统调用, 仅仅在有事件的情况下, 去进行 和IO的操作(读或者写)
多路复用在Linux内核代码迭代过程中依次支持了三种调用:
- SELECT 系统调用
- POLL 系统调用
- EPOLL 系统调用
select 系统调用
Linux 内核、Windows内核都提供了 系统调用操作,可以把1024个文件描述符的IO事件轮询,简化为一次轮询,轮询发生在内核空间。

在如下的代码中,先准备一个数组 fds 存放着所有需要监视的 socket 。
然后调用 select ,如果 fds 中的所有 socket 都没有数据,select 会阻塞,直到有一个 socket 接收到数据, select 返回,唤醒进程。
int fds[] = 存放需要监听的 socket
while(1){
int n = select(..., fds, ...) //fds 加入到socket 阻塞队列,select 返回后,唤醒进程
for(int i=0; i < fds.count; i++){
if(FD_ISSET(fds[i], ...)){
//fds[i]的数据处理}
}
}
用户可以遍历 fds数组 ,通过 FD_ISSET 判断具体哪个 socket 收到数据,然后做出处理。
使用select的核心步骤:
- 先准备了一个数组 fds,让 fds 存放着所有需要监视的 socket。
- 然后调用 select,如果 fds 中的所有 socket 都没有数据,select 会阻塞,直到有一个 socket 接收到数据,select 返回,唤醒进程。
- 用户可以遍历 fds,通过 FD_ISSET 判断具体哪个 socket 收到数据,然后做出处理。
Select系统调用的参数说明
select这个系统调用的原型如下
int select(int nfds, fd_set *readfds, fd_set *writefds
,fd_set *exceptfds, struct timeval *timeout);
- 第一个参数nfds用来告诉内核要扫描的socket fd的数量+1,select系统调用最大接收的数量是1024,但是如果每次都去扫描1024,实际上的数量并不多,则效率太低,这里可以指定需要扫描的数量。
最大数量为1024,如果需要修改这个数量,则需要重新编译Linux内核源码。32位机默认是1024个,64位机默认是2048
- 第2、3、4个参数分别是readfds、writefds、exceptfds,传递的参数应该是fd_set 类型的引用
- fd_set *readset: 要去查 读事件 的文件描述符集合。
- fd_set *writeset: 要去查 可写事件 的文件描述符集合。
- fd_set *exceptset:要去查 异常事件 的文件描述符集合。
返回之后,内核会检测每个socket的fd,如果发生事件,则将事件,从数组中移除。
-
如果没有读事件,就将对应的fd从第二个参数传入的fd_set中移除,
-
如果没有写事件,就将对应的fd从第二个参数的fd_set中移除,
-
如果没有异常事件,就将对应的fd从第三个参数的fd_set中移除。
注意,这里是副本传递:
这里我们应该要将实际的readfds、writefds、exceptfds拷贝一份副本传进去,而不是传入原引用,因为如果传递的是原引用,某些socket可能就已经丢失。
select 最后一个参数timeout 是等待时间,分三个场景:
- 传入0表示非阻塞,
- 传入>0表示等待一定时间,
- 传入NULL表示一 直阻塞,直到等到某个socket就绪。
BitMap结构一些常见的操作的函数
最早的 fd_set 是一个整数数组
定义FD_SETSIZE为1024,一个整数占4个字节,既32位,那么就是用包含1024个元素的整数数组来表示文件描述符集
后面的版本, 对fd_set 文件描述符集合,进行性能优化, 使用bitmap,代替了 整数数组
所以,这里的fd_set,从一个文件描述符数组,优化为一个BitMap结构。
在内核遍历完fd数组后,发现有IO就绪的fd,则会将该fd对应的BitMap中的值设置为1,内核处理完成之后,将修改后的fd数组,返回给用户线程。
在用户线程中需要重新遍历fd数组,找出IO就绪的fd出来,然后发起真正的读写调用。
下面是 处理 fd数组的过程中,需要用到的API:
void FD_CLR(int fd, fd_set *set); //将某个bit置0,fd传入bit的索引
int FD_ISSET(int fd, fd_set *set); //判断某个bit是否被置1了,fd传入索引
void FD_SET(int fd, fd_set *set); //将bitmap某个bit置1,fd传入bit的索引
void FD_ZERO(fd_set *set); //将bitmap中的所有bit归0,一般用来进行初始化
-
FD_CLR()这个函数用来将bitmap(fd_set )中的某个bit清0,在客户端异常退出时就会用到这个函数,将fd从fd_set中删除。
-
FD_ISSET()用来判断某个bit是否被置1了,也就是判断某个fd是否在fd_set中。
-
FD_ZERO()这个函数将fd_set中的所有bit清0,一般用来进行初始化等。
-
FD_SET()这个函数用来将某个fd加入fd_set中,当客户端新加入连接时就会使用到这个函数。
注意,每次调用select之前都要通过FD_ZERO和FD_SET重新设置文件描述符,因为文件描述符集合会在内核中被修改。
这里的文件描述符数组其实是一个BitMap,BitMap下标为文件描述符fd,下标对应的值为:1表示该fd上有读写事件,0表示该fd上没有读写事件。

select例子
然后调用 select ,如果 fds 中的所有 socket 都没有数据,select 会阻塞,直到有一个 socket 接收到数据, select 返回,唤醒进程。
int fds[] = 存放需要监听的 socket
while(1){
int n = select(..., fds, ...) //fds 加入到socket 阻塞队列,select 返回后,唤醒进程
for(int i=0; i < fds.count; i++){
if(FD_ISSET(fds[i], ...)){
//fds[i]的数据处理}
}
}
假如程序同时监视如下图的 Sock1、Sock2 和 Sock3 三个 Socket,
那么在调用 Select 之后,操作系统把进程 A 分别加入这三个 Socket 的等待队列中。

当任何一个socket收到数据后,中断程序将唤起进程。
下图展示了sock2接收到了数据的处理流程。

所谓唤起进程,就是将进程从所有的等待队列中移除,加入到工作队列里面。如下图所示。

对于调用了select的进程A而言:
- A存在于多个socket的等待队列中
- 当某个socket被写入数据时,A也被唤醒并从多个socket的等待队列中移除后加入内核的工作队列
- 但是此时A并不知道是哪个socket被写入了数据,所以只能遍历所有socket
- 在A处理完任务后移出内核的工作队列,但是此时却需要遍历所有socket并加入它们的等待队列中
select的执行流程
select是操作系统内核提供给我们使用的一个系统调用,它解决了在非阻塞IO模型中需要不断的发起系统IO调用去轮询各个连接上的Socket接收缓冲区所带来的用户空间与内核空间不断切换的系统开销。
select系统调用将轮询的操作交给了内核来帮助我们完成,从而避免了在用户空间不断的发起轮询所带来的的系统性能开销。

- 首先用户线程在发起select系统调用的时候会阻塞在select系统调用上。此时,用户线程从用户态切换到了内核态完成了一次上下文切换
- 用户线程将需要监听的Socket对应的文件描述符fd数组通过select系统调用传递给内核。此时,用户线程将用户空间中的文件描述符fd数组拷贝到内核空间。
select的不足:
每次调用 select 都需要这两步操作:添加进程到socket的等待队列,阻塞进程。
所以,需要socket列表两次遍历开销:
-
第1次:进程加入socket的等待队列时,需要遍历所有socket。
-
第2次:当进程A被唤醒后,唤醒后需要从所有的socket的等待队列中移除。
正是因为遍历操作开销大,出于效率的考量,才会规定select的最大监视数量,默认只能监视1024个socket。
另外就是fd的两次复制开销:
-
每次调用select都需要将fds列表传递给内核,需要进行一次复制,有一定的开销。
-
每次调用select完成后,都必须把fd集合从内核空间拷贝到用户空间,这也有一定的开销,这个开销在fd很多时会很大;
还有:用户线程依然要遍历文件描述符集合去查找具体IO就绪的Socket
虽然由原来在用户空间发起轮询,优化成了在内核空间发起轮询,
但select不会告诉用户线程到底是哪些Socket上发生了IO就绪事件,只是对IO就绪的Socket作了标记,用户线程依然要遍历文件描述符集合,去查找具体IO就绪的Socket。
时间复杂度依然为O(n)。
总之,select也不能解决C10K问题
以上select的不足所产生的性能开销都会随着并发量的增大而线性增长。
很明显select也不能解决C10K问题,只适用于1000个左右的并发连接场景。
所谓c10k问题,指的是:服务器如何支持10k个并发连接,也就是concurrent 10000 connection(这也是c10k这个名字的由来)。
poll 系统调用
poll的出现
1997 年,出现了 poll 作为 select 的替代者,最大的区别就是,poll 不再限制 socket 数量。
poll系统调用
poll其实内部实现基本跟select一样,区别在于它们底层组织fd[]的数据结构不太一样,从而实现了poll的最大文件句柄数量限制去除了。
poll的描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构,其他的都差不多,
poll管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。
int poll(struct pollfd *fds, unsigned int nfds, int timeout)
pollfd 结构
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 需要监听的事件 */
short revents; /* 实际发生的事件 由内核修改设置 */
};
成员变量说明:
(1)fd:每一个 pollfd 结构体指定了一个被监视的文件描述符,可以传递多个结构体,指示 poll() 监视多个文件描述符。
(2)events:表示要告诉操作系统需要监测fd的事件(输入、输出、错误),每一个事件有多个取值
(3)revents:revents 域是文件描述符的操作结果事件,内核在调用返回时设置这个域。events 域中请求的任何事件都可能在 revents 域中返回。
events&revents的取值如下:
| 事件 | 描述 | 是否可作为输入(events) | 是否可作为输出(revents) |
|---|---|---|---|
| POLLIN | 数据可读(包括普通数据&优先数据) | 是 | 是 |
| POLLOUT | 数据可写(普通数据&优先数据) | 是 | 是 |
| POLLRDNORM | 普通数据可读 | 是 | 是 |
| POLLRDBAND | 优先级带数据可读(linux不支持) | 是 | 是 |
| POLLPRI | 高优先级数据可读,比如TCP带外数据 | 是 | 是 |
| POLLWRNORM | 普通数据可写 | 是 | 是 |
| POLLWRBAND | 优先级带数据可写 | 是 | 是 |
| POLLRDHUP | TCP连接被对端关闭,或者关闭了写操作,由GNU引入 | 是 | 是 |
| POPPHUP | 挂起 | 否 | 是 |
| POLLERR | 错误 | 否 | 是 |
| POLLNVAL | 文件描述符没有打开 | 否 | 是 |
读事件/socket读就绪
什么时候,socket可读呢?
-
场景1:该套接字接收缓冲区中的数据字节数,大于等于套接字接收缓存区低水位标记SO_RCVLOWAT。
对于TCP和UDP套接字而言,缓冲区低水位的值默认为1。那就意味着,默认情况下,只要缓冲区中有数据,那就是可读的。
我们可以通过使用SO_RCVLOWAT套接字选项(参见setsockopt函数)来设置该套接字的低水位大小。
此种描述符就绪(可读)的情况下,当我们使用read/recv等对该套接字执行读操作的时候,套接字不会阻塞,而是成功返回一个大于0的值(即可读数据的大小)。
-
场景2:该连接的读半部关闭(也就是接收了FIN的TCP连接)。对这样的套接字的读操作,将不会阻塞,而是返回0(也就是EOF)。
-
场景3:该套接字是一个listen的监听套接字,并且目前已经完成的连接数不为0。对这样的套接字进行accept操作通常不会阻塞。
-
场景4:有一个错误套接字待处理。对这样的套接字的读操作将不阻塞并返回-1(也就是返回了一个错误),同时把errno设置成确切的错误条件。这些待处理错误(pending error)也可以通过指定SO_ERROR套接字选项调用getsockopt获取并清除。
写事件/socket写就绪
什么时候,socket可写呢?
-
场景2:socket内核中, 发送缓冲区中的可用字节数(发送缓冲区的空闲位置大⼩), 大于等于低水位标记 SO_SNDLOWAT, 此时可以无阻塞的写, 并且返回值大于0。
对于TCP和UDP而言,这个低水位SO_SNDLOWAT的值默认为2048,而套接字默认的发送缓冲区大小是8k,这就意味着一般一个套接字连接成功后,就是处于可写状态的。我们可以通过SO_SNDLOWAT套接字选项(参见setsockopt函数)来设置这个低水位。
此种情况下,我们设置该套接字为非阻塞,对该套接字进行写操作(如write,send等),将不阻塞,并返回一个正值(例如由传输层接受的字节数,即发送的数据大小)。
-
场景3:该连接的写半部关闭(主动发送FIN包的TCP连接)。
对这样的套接字的写操作将会产生SIGPIPE信号。所以我们的网络程序基本都要自定义处理SIGPIPE信号。因为SIGPIPE信号的默认处理方式是程序退出。
-
场景4:使用非阻塞的connect套接字已建立连接,或者connect已经以失败告终。即connect有结果了。
-
场景5:有一个错误的套接字待处理。对这样的套接字的写操作将不阻塞并返回-1(也就是返回了一个错误),同时把errno设置成确切的错误条件。这些待处理的错误也可以通过指定SO_ERROR套接字选项调用getsockopt获取并清除。
| 条件 | 可读吗? | 可写吗? | 异常吗? |
|---|---|---|---|
| 有数据可读 关闭连续的读一半 给监听套接口准备好新连接 |
● ● ● |
||
| 有可用于写的空间 关闭连接的写一半 |
● ● |
||
| 待处理错误 | ● | ● | |
| TCP带外数据 | ● |
poll() 系统调用的本质
select() 和 poll() 系统调用的本质一样
poll() 的机制与 select() 在本质上没有多大差别,每次调用时,都需要把 fd 集合从用户态拷贝到内核态,
二者管理多个描述符也是进行轮询,根据描述符的状态进行处理。
select中使用的文件描述符集合是采用的固定长度为1024的BitMap结构的fd_set,而poll换成了一个pollfd结构没有固定长度的数组,这样就没有了最大描述符数量的限制(当然还会受到系统文件描述符限制)
poll只是改进了select只能监听1024个文件描述符的数量限制,但是并没有在性能方面做出改进。
poll和select上本质并没有多大差别。
- 同样需要在内核空间和用户空间中对文件描述符集合进行轮询,查找出IO就绪的Socket的时间复杂度依然为O(n)。
- 同样需要将包含大量文件描述符的集合整体在用户空间和内核空间之间来回复制,无论这些文件描述符是否就绪。他们的开销都会随着文件描述符数量的增加而线性增大。
- select,poll在每次新增,删除需要监听的socket时,都需要将整个新的socket集合全量传至内核。
poll同样不适用高并发的场景。依然无法解决C10K问题。
epoll 底层系统调用
面试的核心点来了
背景:epoll 底层系统调用,是面试的核心知识点
学习高并发,epoll是个基础
此文持续升级, 争取用此文,给大家彻底把 epoll 介绍清楚
epoll的重要性
epoll作为linux下高性能网络服务器的必备技术至关重要,
Java NIO、nginx、redis、skynet和大部分游戏服务器都使用到这一多路复用技术。
select /poll低效的原因
一次select调用,将“维护等待队列(事件监听)”和“阻塞等待(事件查询)”两个步骤合二为一,紧密耦合

每次调用 select 都需要这两步操作:添加进程到socket的等待队列,阻塞进程。
select将“事件注册”和“事件查询”两个步骤合二为一,紧密耦合 ,
select/poll,需要两次socket列表遍历:
-
第1次:每次调用select都需要将fds列表传递给内核,有一定的开销。进程加入socket的等待队列时,需要遍历所有socket。
-
第2次:当进程A被唤醒后,唤醒后需要从所有的socket的等待队列中移除。
正是因为遍历操作开销大,出于效率的考量,才会规定select的最大监视数量,默认只能监视1024个socket。
epoll则“事件注册”和“事件查询”两个步骤进行解耦,一分为二,
如何优化:epoll 将这两个操作分开,先用 epoll_ctl 维护等待队列,再调用 epoll_wait 阻塞进程。

显而易见地,效率就能得到提升。
epoll 的优化措施:
epoll 是在 select 、poll出现 N 多年后才被发明的,是 select 和 poll 的增强版本。
epoll 通过以下一些措施来改进效率。
- 功能解耦:把则“事件注册”和“事件查询”两个步骤进行解耦,一分为二
- 空间换时间: 引入了就绪列表rdlist ,存储已经发生了io 事件的文件描述符
epoll 的三个方法
-
epoll_create:内核会创建一个 eventpoll 对象(专用的文件描述符,也就是程序中 epfd 所代表的对象)eventpoll 对象也是文件系统中的一员,和 socket 一样,它也会有等待队列。
-
epoll_ctl:事件注册, 添加待监控的socket如果通过 epoll_ctl 添加 sock1、sock2 和 sock3 的监视,内核会将三个 socket 添加到 eventpoll 监听队列。
-
epoll_wait:事件查询,阻塞等待进程 A 运行到了 epoll_wait 语句之后,进程A会等待eventpoll 的等待队列。
epoll 的优化措施一:功能解耦
select 低效的原因之一是将“维护等待队列”和“阻塞进程”两个步骤合二为一。
大多数应用场景中,需要监视的 socket 相对固定,并不需要每次都修改。
epoll 将这两个操作分开,先用 epoll_ctl 维护等待队列,再调用 epoll_wait 阻塞进程。
显而易见的,不需要再每次查询的时候, 进行大量的 数据复制, 效率就能得到提升。
epoll 的等待列表

epoll 的优化措施二:就绪列表rdlist
select 低效的另一个原因在于程序不知道哪些 socket 收到数据,只能一个个遍历。
如果内核维护一个“就绪列表”rdlist,引用收到数据的 socket ,就能避免遍历。

如下的代码中,先用 epoll_create 创建一个 epoll 对象 epfd ,再通过 epoll_ctl 将需要监视的 socket 添加到 epfd 的专用等待列表中,最后调用epoll_wait 等待数据,返回rdlist列表中的就绪socket。
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //第一步:将所有需要监听的 socket 添加到 epfd 中等待队列
while(1){
int n = epoll_wait(...) //第二步:阻塞进程,等待事件
for(接收到数据的 socket){
//处理
}
}
假设计算机中正在运行进程 A 和进程 B ,在某时刻进程 A 运行到了 epoll_wait 语句。
内核会将进程 A 放入 eventpoll 的等待队列中,阻塞进程。

当 socket 接收到数据,中断程序做两个工作:
-
一方面修改 rdlist
-
另一方面唤醒 eventpoll 等待队列中的进程,进程 A 再次进入运行状态。
也因为 rdlist 的存在,进程 A 可以知道哪些 socket 发生了变化。
结合内核源码,深入Epoll的原理和源码
一个使用了 epoll 的简单示例
int main(){
listen(lfd, ...);
cfd1 = accept(...);
cfd2 = accept(...);
efd = epoll_create(...);
epoll_ctl(efd, EPOLL_CTL_ADD, cfd1, ...);
epoll_ctl(efd, EPOLL_CTL_ADD, cfd2, ...);
epoll_wait(efd, ...)
}
其中和 epoll 相关的函数是如下三个:
epoll_create:创建一个 epoll 对象epoll_ctl:向 epoll 对象中添加要管理的连接epoll_wait:等待其管理的连接上的 IO 事件
epoll 的核心结构
epoll 的核心结构的几个成员的含义如下:
- `wq:等待队列链表。里边是用户等待事件的进程,IO时间就绪的时候,内核会通过 wq 来找到阻塞在 epoll 对象上的用户进程。
rbr: 一棵红黑树。管理被监听的所有 socket 连接。为了支持对海量连接的高效查找、插入和删除,eventpoll 内部使用了一棵红黑树。通过这棵树来管理用户进程下添加进来的所有 socket 连接。rdlist:就绪的描述符的链表。当有的连接就绪的时候,内核会把就绪的连接放到 rdllist 链表里。这样应用进程只需要判断链表就能找出就绪进程,而不用去遍历整棵树。

struct eventpoll 源文件:
// file:fs/eventpoll.c
struct eventpoll {
//sys_epoll_wait用到的等待队列
wait_queue_head_t wq;
//接收就绪的描述符都会放到这里
struct list_head rdllist;
//每个epoll对象中都有一颗红黑树
struct rb_root rbr;
......
}

超级底层1:使用Epoll第一步epoll_create的超底层原理:
当某个进程调用epoll_create方法时,内核会创建一个eventpoll对象(epfd文件描述符)

epoll_create是内核提供给我们创建epoll对象的一个系统调用,
epoll_create,打开一个epoll文件描述符。
#include <sys / epoll.h>
nfd = epoll_creat(max_size);
epoll_create()创建一个epoll实例。参数max_size标识这个监听的数目最大有多大,从Linux 2.6.8开始,max_size参数将被忽略,但必须大于零。
其中nfd为epoll句柄,epoll_create()返回引用新epoll实例的文件描述符。该文件描述符用于随后的所有对epoll的调用接口。
每创建一个epoll句柄,会占用一个fd,因此当不再需要时,应使用close关闭epoll_create()返回的文件描述符,否则可能导致fd被耗尽。当所有文件描述符引用已关闭的epoll实例,内核将销毁该实例并释放关联的资源以供重用。
返回值:
成功时,这些系统调用将返回非负文件描述符。如果出错,则返回-1,并且将errno设置为指示错误。
错误errno:
-
EINVAL大小不为正。
-
EMFILE遇到了每个用户对/ proc / sys / fs / epoll / max_user_instances施加的epoll实例数量的限制。
-
ENFILE已达到打开文件总数的系统限制。
-
ENOMEM没有足够的内存来创建内核对象。
当我们在用户进程中调用epoll_create时,内核会为我们创建一个struct eventpoll对象,
并且也有相应的struct file与之关联,同样需要把这个struct eventpoll对象所关联的struct file放入进程打开的文件列表fd_array中管理。
struct eventpoll对象关联的struct file中的file_operations 指针指向的是eventpoll_fops操作函数集合。
static const struct file_operations eventpoll_fops = {
.release = ep_eventpoll_release;
.poll = ep_eventpoll_poll,
}
当然eventpoll结构被申请完之后,在 ep_alloc 方法做一点点的初始化工作
//file: fs/eventpoll.c
static int ep_alloc(struct eventpoll **pep)
{
struct eventpoll *ep;
//申请 epollevent 内存
ep = kzalloc(sizeof(*ep), GFP_KERNEL);
//初始化等待队列头
init_waitqueue_head(&ep->wq);
//初始化就绪列表
INIT_LIST_HEAD(&ep->rdllist);
//初始化红黑树指针
ep->rbr = RB_ROOT;
......
}
和socket一类似,eventpoll也会有等待队列。
- wait_queue_head_t wq:epoll中的等待队列,队列里存放的是阻塞在epoll上的用户进程。在IO就绪的时候epoll可以通过这个队列找到这些阻塞的进程/线程并唤醒它们,从而执行IO调用读写Socket上的数据。
这里注意与Socket中的等待队列区分! Socket 等待队列 加入的是被Socket 上的 io操作所阻塞的 线程、进程
- struct list_head rdllist:epoll中的就绪队列,队列里存放的是都是IO就绪的Socket,被唤醒的用户进程可以直接读取这个队列获取IO活跃的Socket。无需再次遍历整个Socket集合。
rdllist正是epoll比select/poll高效之处,
select ,poll返回的是全量的socket连接,假如100W连接, 这里都需要返回,然后去遍历检查。
epoll通过 rdllist 这里,仅仅返回已经就绪的socket。用户进程可以直接进行IO操作。
-
struct rb_root rbr : 用红黑树管理全量 socket,假如是100W连接,这里也是有能力管理的
由于红黑树在查找,插入,删除等综合性能方面是最优的,所以epoll内部使用一颗红黑树来管理海量的Socket连接。
与epoll不同, select用数组管理全量 socket连接,poll用链表管理全量 socket连接。
超级底层2:epoll_ctl的底层原理
接下来,看看使用Epoll第2步,epoll_ctl的底层原理
epoll_ctl 系统调用的作用是啥? 可以用epoll_ctl添加或删除所要监听的socket。epoll_ctl,用于操作epoll函数所生成的实例。
#include <sys / epoll.h>
int epoll_ctl(int epfd,int op,int fd,struct epoll_event * event);
该系统调用对文件描述符epfd引用的epoll实例执行控制操作。它要求操作op对目标文件描述符fd执行。
op参数的有效值为:
-
EPOLL_CTL_ADD:在文件描述符epfd所引用的epoll实例上注册目标文件描述符fd,并将事件事件与内部文件链接到fd。 -
EPOLL_CTL_MOD:更改与目标文件描述符fd相关联的事件事件。 -
EPOLL_CTL_DEL:从epfd引用的epoll实例中删除(注销)目标文件描述符fd。该事件将被忽略,并且可以为NULL(但请参见下面的错误)。
eg: 如果通过epoll_ctl添加sock1、sock2和sock3的监视,
内核会将eventpoll添加到这三个socket的等待队列,具体的做法是,在socket的等待队列中,增加 ep_poll_callback 回调事件

在使用 epoll_ctl 注册每一个 socket 的时候,内核会做如下三件事情
- 1.分配一个红黑树节点对象 epitem,
- 2.添加等待事件到 socket 的等待队列中,其回调函数是 ep_poll_callback
- 3.将 epitem 插入到 epoll 对象的红黑树里
通过 epoll_ctl 添加两个 socket 以后,这些内核数据结构最终在进程中的关系图大致如下:

我们来详细看看 socket 是如何添加到 epoll 对象里的,找到 epoll_ctl 的源码。
// file:fs/eventpoll.c
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
struct eventpoll *ep;
struct file *file, *tfile;
//根据 epfd 找到 eventpoll 内核对象
file = fget(epfd);
ep = file->private_data;
//根据 socket 句柄号, 找到其 file 内核对象
tfile = fget(fd);
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else
error = -EEXIST;
clear_tfile_check_list();
break;
}
在 epoll_ctl 中首先根据传入 fd 找到 eventpoll、socket 相关的内核对象 。
对于 EPOLL_CTL_ADD 操作来说,会然后执行到 ep_insert 函数。
所有的注册都是在这个函数中完成的。
//file: fs/eventpoll.c
static int ep_insert(struct eventpoll *ep,
struct epoll_event *event,
struct file *tfile, int fd)
{
//3.1 分配并初始化 epitem
//分配一个epi对象
struct epitem *epi;
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
//对分配的epi进行初始化
//epi->ffd中存了句柄号和struct file对象地址
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
//3.2 设置 socket 等待队列
//定义并初始化 ep_pqueue 对象
struct ep_pqueue epq;
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
//调用 ep_ptable_queue_proc 注册回调函数
//实际注入的函数为 ep_poll_callback
revents = ep_item_poll(epi, &epq.pt);
......
//3.3 将epi插入到 eventpoll 对象中的红黑树中
ep_rbtree_insert(ep, epi);
......
}
为socket分配并初始化 epitem
对于每一个 socket,调用 epoll_ctl 的时候,都会为之分配一个 epitem。
epitem结构的主要数据如下:
//file: fs/eventpoll.c
struct epitem {
//红黑树节点
struct rb_node rbn;
//socket文件描述符信息
struct epoll_filefd ffd;
//所归属的 eventpoll 对象
struct eventpoll *ep;
//等待队列
struct list_head pwqlist;
}

epoll采用一颗红黑树来管理这些海量socket连接。所以struct epitem是一个红黑树节点。
首先要在epoll内核中创建一个表示Socket连接的数据结构struct epitem,
对 epitem 进行了一些初始化,首先在 epi->ep = ep 这行代码中将其 ep 指针指向 eventpoll 对象。
另外用要添加的 socket 的 file、fd 来填充 epitem->ffd。

其中使用到的 ep_set_ffd 函数如下。
static inline void ep_set_ffd(struct epoll_filefd *ffd,
struct file *file, int fd)
{
ffd->file = file;
ffd->fd = fd;
}
ep_item_poll 在socket 等待队列,插入事件回调
在创建 epitem 并初始化之后,ep_insert 中第二件事情就是设置 socket 对象上的sk_wq等待任务队列。
并把函数 fs/eventpoll.c 文件下的 ep_poll_callback 设置为数据就绪时候的回调函数。

在内核中创建完表示Socket连接的数据结构struct epitem后,我们就需要在Socket中的等待队列sk_wq上,创建等待项wait_queue_t,并且注册epoll的回调函数ep_poll_callback。
Socket中io事件一旦发生,就会执行这个 回调函数ep_poll_callback, 把epitem 加入到rdlist 就绪队列中。
epoll的回调函数ep_poll_callback正是epoll同步IO事件通知机制的核心所在,也是区别于select,poll采用内核轮询方式的根本性能差异所在。

在socket 等待队列,插入事件回调 是通过 ep_item_poll 方法完成的
static inline unsigned int ep_item_poll(struct epitem *epi, poll_table *pt)
{
pt->_key = epi->event.events;
return epi->ffd.file->f_op->poll(epi->ffd.file, pt) & epi->event.events;
}
这里调用到了 socket 下的 file->f_op->poll()。
对于 socket 结构, 这个函数实际上是 sock_poll。
/* No kernel lock held - perfect */
static unsigned int sock_poll(struct file *file, poll_table *wait)
{
...
return sock->ops->poll(file, sock, wait);
}
对于 socket 结构, sock->ops->poll 其实指向的是 tcp_poll。
//file: net/ipv4/tcp.c
unsigned int tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
{
struct sock *sk = sock->sk;
sock_poll_wait(file, sk_sleep(sk), wait);
}
在 sock_poll_wait 的第二个参数传参前,先调用了 sk_sleep 函数。
在这个函数里它获取了 sock 对象下的等待队列列表头 wait_queue_head_t,待会等待队列项就插入这里。
这里稍微注意下,这里插入的目标,是 socket 的等待队列,不是 epoll 对象的等待队列。
来看 sk_sleep 源码:
//file: include/net/sock.h
static inline wait_queue_head_t *sk_sleep(struct sock *sk)
{
BUILD_BUG_ON(offsetof(struct socket_wq, wait) != 0);
return &rcu_dereference_raw(sk->sk_wq)->wait;
}
接着真正进入 sock_poll_wait。
static inline void sock_poll_wait(struct file *filp,
wait_queue_head_t *wait_address, poll_table *p)
{
poll_wait(filp, wait_address, p);
}
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}
这里的 qproc 是个函数指针,它在前面的 init_poll_funcptr 调用时被设置成了 ep_ptable_queue_proc 函数。
static int ep_insert(...)
{
...
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
...
}
//file: include/linux/poll.h
static inline void init_poll_funcptr(poll_table *pt,
poll_queue_proc qproc)
{
pt->_qproc = qproc;
pt->_key = ~0UL; /* all events enabled */
}
在 ep_ptable_queue_proc 函数中,
-
新建了一个等待队列项 eppoll_entry,并注册其回调函数为 ep_poll_callback 函数。
-
然后再将这个等待项eppoll_entry添加到 socket 的等待队列中。
//file: fs/eventpoll.c
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct eppoll_entry *pwq;
f (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
//初始化回调方法
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
//将ep_poll_callback放入socket的等待队列whead(注意不是epoll的等待队列)
add_wait_queue(whead, &pwq->wait);
}
q->private 用户指向等待的用户进程。
socket 是交给 epoll 来管理的,不需要在一个 socket 就绪的时候就唤醒进程,所以这里的 q->private 就设置成了 NULL。
//file:include/linux/wait.h
static inline void init_waitqueue_func_entry(
wait_queue_t *q, wait_queue_func_t func)
{
q->flags = 0;
q->private = NULL;
//ep_poll_callback 注册到 wait_queue_t对象上
//有数据到达的时候调用 q->func
q->func = func;
}
如上,等待队列项中仅仅只设置了回调函数 q->func 为 ep_poll_callback。
在后面的第 5 节数据来啦中我们将看到,内核软中断将数据收到 socket 的接收队列后,会通过注册的这个 ep_poll_callback 函数来回调,进而通知到 epoll 对象。
eppoll_entry 结构
注册socket过程中,出现一个数据结构struct eppoll_entry,那它的作用是干什么的呢?
我们知道socket->sock->sk_wq 等待队列中的类型是wait_queue_t,我们需要在struct epitem所表示的socket的等待队列上注册epoll回调函数ep_poll_callback。
这样当数据到达socket中的接收队列时,内核会回调sk_data_ready,唤醒被阻塞的 用户进程
sk_data_ready函数指针会指向sk_def_readable函数,在sk_def_readable中,会回调注册在等待队列里的等待项wait_queue_t -> func回调函数ep_poll_callback。
ep_poll_callback中需要找到epitem,将IO就绪的epitem放入epoll中的rdlist 就绪队列中。
问题是,socket等待队列中类型是wait_queue_t,无法关联到epitem。
所以就出现了struct eppoll_entry结构体,它的作用就是关联Socket等待队列中的等待项wait_queue_t和epitem。
所以,eppoll_entry 是一个胶水结构, 桥接的结构
struct eppoll_entry {
//指向关联的epitem
struct epitem *base;
// 关联监听socket中等待队列中的等待项 (private = null func = ep_poll_callback)
wait_queue_t wait;
// 监听socket中等待队列头指针
wait_queue_head_t *whead;
.........
};
这样在ep_poll_callback回调函数中就可以根据Socket等待队列中的等待项wait,通过container_of宏找到eppoll_entry,继而找到epitem了。
这里需要注意下这次等待项wait_queue_t中的private设置的是null,因为这里Socket是交给epoll来管理的,阻塞在Socket上的进程是也由epoll来唤醒。
在等待项wait_queue_t注册的func是ep_poll_callback,而不是之前的 autoremove_wake_function,在这里,被阻塞进程并不需要autoremove_wake_function来唤醒,所以,这里设置private为null
如果是select ,这里 被阻塞的用户进程,关联到wait_queue_t->private上
socket对应的 epitem 插入红黑树
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
数据来了,IO事件发生的时候
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
执行ep_poll_callback 就绪回调函数
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
执行 epoll 就绪通知
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
超级底层3:使用Epoll第3步epoll_wait的底层原理
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll_wait的使用
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
创建一个等待队列项 wait_queue_t
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
判断就绪队列上有没有事件就绪
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
定义等待事件并关联当前进程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
添加到等待队列
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
让出 CPU 主动进入睡眠状态
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll_wait 与 select阻塞原理类似
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll的整个工作流程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll()涉及到的两种wait队列分析
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
应用层用到的Linux epoll API:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll_ctl
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
struct epoll_event结构如下:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll的events事件类型
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll_event结构data成员变量:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Linux epoll API: epoll_wait
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
eventpoll数据结构
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll的巨大优势
要明白epoll的巨大优势,得先看 select缺点和优点
select缺点和优点:
select本质上是通过设置或者检查存放fd标志位的数据结构数据结构来进行下一步的处理,时间复杂度:O(n)
缺点1:每一次使用select,内核至少需要两次socket列表遍历
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
缺点2: 每次调用select都需要将fds列表传递给内核,涉及到fd的复制,这是一笔开销;
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
缺点3:对socket进行扫描是线性扫描。时间复杂度:O(n)
优点:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
poll缺点和优点:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll改进:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll改进的根本措施:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll的核心优点
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll的缺点:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
美团二面:epoll性能那么高,为什么?
说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如美团、拼多多、极兔、有赞、希音的面试资格,遇到一几个很重要的面试题:
- 说说epoll的数据结构
- 说说epoll的实现原理
- 协议栈如何与epoll通信?
- epoll线程安全如何加锁?
- 说说ET与LT的实现
- ……
这里尼恩给大家做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典》V88版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲 》《尼恩Java面试宝典》 的PDF文件,请到公号【技术自由圈】获取
详细内容在下面文章里:
说在最后
Linux相关面试题,是非常常见的面试题。
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
学习过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
彻底明白:高速ET模式与Netty的高速Selector
背景
epoll事件的两种触发模式
epoll有EPOLLLT和EPOLLET两种触发模式
- LT是默认的模式
- ET是“高速”模式。
ET和LT,来自电子的概念
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
执行epoll_wait时LT(水平触发)
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll_wait时ET和LT对比
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
ET和LT的区别
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Java中的selector触发模式
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Netty的Selector
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
如何使用netty自己的Linux epoll实现
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
如何使用netty自己的Linux epoll实现 step2:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
如何使用netty自己的Linux epoll实现,详细地址:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
为什么Netty使用NIO而不是AIO?
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
IO线程模型
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Reactor
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
单Reactor单线程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
单Reactor多线程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
主从Reactor多线程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Proactor
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Reactor与Proactor对比
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Netty的IO模型
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
配置单Reactor单线程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
配置单Reactor多线程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
配置主从Reactor多线程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
彻底解密:IO事件在Java、Native之间的翻译
背景:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Java的IO事件在类型
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey中的事件常量
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
poll() 系统调用的事件
pollfd结构
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
poll的events事件类型
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
socket读就绪条件(读事件):
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
socket写就绪条件(写事件):
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
poll() 系统调用的本质
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Net.java通过JNI加载不同平台的poll事件的定义值
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Net.c中的事件的值
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
NIO事件到JNI事件的翻译
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SocketChannelImpl#translateInterestOps
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SocketChannelImpl#translateReadyOps
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll() 系统调用的事件
struct epoll_event结构如下:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll的events事件类型
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
epoll_event结构data成员变量:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
彻底解密:Java NIO SelectionKey (选择键) 核心原理
Java 底层 NIO , 是基于select 系统调用的
但是其原理还是值得我们学习 ,值得我们去深入分析的。
背景
SelectionKey 与IO事件,紧密相关
选择键的使用
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey介绍
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey对象代表着Channel和Selector的关联关系
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKeyImpl继承关系
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
向通道注册事件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey中使用了四个常量来代表事件类型:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey维护两个set集合成员:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey#interestOps()方法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey除开构造器方法,有13个方法:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
AbstractSelectionKey的属性
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
AbstractSelectionKey的方法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKeyImpl
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKeyImpl的属性
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
感兴趣的事件interestOps还可直接通过interestOps()方法设置
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
就绪的事件readyOps是通道实际发生的操作事件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
判断事件是否注册
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
检测channel中什么事件已经就绪
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
访问这个ready set就绪的事件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
使用的比特掩码来检测就绪事件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey#isAcceptable()
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
获取已经就绪的事件集合SelectionKeyImpl#readyOps()
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
新连接就绪事件的简单处理
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey#isAcceptable()的源码
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
读就绪事件的简单处理
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey#isReadable()的源码
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
selectionKey如何失效
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
检查selectionKey是否仍然有效
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
selectionKey的附件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
selectionKey的附件操作
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
为SelectionKey添加附件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
注册Channel的时候添加附件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
EchoServerReactor 中的处理器附件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
EchoServerReactor 中的处理器附件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Netty中的AbstractNioChannel.doRegister
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
selectionKey的使用例子
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
强制停止Selector#select()后的selectKey结果
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
强制停止Selector#select()操作的方法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
彻底明白:Selector(选择器) 核心原理
Selector简介
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Selector的创建
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
注册Channel到Selector
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKey
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Selector#select()方法介绍:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
selector维护三个set集合:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
调用Selector的selectedKeys()方法来访问已选择键集合
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
每个Selector中还维护了publicKeys和publicSelectedKeys两个视图,供客户端使用。
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Collections.unmodifiableSet & ungrowableSet
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
停止Selector#select()选择操作的方法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
不同Selector实现类
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
不同操作系统平台的不同Selector实现类
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
最强揭秘:Selector.open() 选择器打开的底层原理
Selector.open()方法的使用
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Selector.open();
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
创建一个provider
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
在windows环境中这里创建的是WindowsSelectorProvider
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
随后调用WindowsSelectorProvider.openSelector
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectorProvider的实现与操作系统相关
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorProvider的继承关系图
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectorImpl会初始化selectedKeys和keys
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
AbstractSelector会初始化provider
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl构造器
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorProvider.open()
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl结构
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
FdMap结构
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SubSelector
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
PollArrayWrapper 中 pollArray事件轮询队列
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
pollArray文件描述符poll事件轮询队列的元素
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
PollArrayWrapper的成员
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
events&revents的取值如下:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
PollArrayWrapper的构造器
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
NativeObject分配直接内存
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SubSelector的属性
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SubSelector的方法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
调用JNI本地poll0方法查询事件
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
selector的大致查询过程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
最强揭秘:Selector.register() 注册的底层原理
channel到selector注册的代码
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
通道注册示意图
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
注册大致流程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectableChannel#register();
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
channel.register() 方法的第二个参数。
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
用“位或”操作符将多个常量连接起来
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
AbstractSelectableChannel.register(selector, ops,att)
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
AbstractSelector.register
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl#implRegister实现注册
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
pollWrapper的addEntry
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
pollArray的元素内容
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
回顾AbstractSelector.register
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKeyImpl#interestOps(ops)
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectionKeyImpl.nioInterestOps
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
channel#translateAndSetInterestOps
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl的putEventOps中
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
重点:将感兴趣的事件放到pollArray中由i指定的位置
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl#implRegister实现注册
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
扩容channelArray
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
pollWrapper.grow(newSize)扩容PollArrayWrapper
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
辅助线程的管理
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl下的多线程提高poll的性能
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl的性能问题
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
回顾:整体的注册流程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
最强揭秘:Selector.select() 事件查询的底层原理
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
select方法的核心流程:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
select方法的调用流程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectorImpl#select
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectorImpl#lockAndDoSelect
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl#doSelect
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
内部类subSelector#poll()
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
C语言中的WindowsSelectorImpl#poll0()
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
c的select方法的主要功能
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
在windows上select方法原型:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SubSelector.processSelectedKeys
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SubSelector.processFDSet
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
ServerSocketChannelImpl.translateReadyOps
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Selector的select()只用单线程
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
最强揭秘:Selector.wakeup() 唤醒的底层原理
如何唤醒被系统调用阻塞的进程?
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
wakeup方法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelector唤醒的原理
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelector的实现
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl的loopback连接
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
唤醒消息的发送端和接收端
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
this.pollWrapper.addWakeupSocket(this.wakeupSourceFd, 0);
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
PipeImpl的成员
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
pipe的简单实例
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
PipeImpl#LoopbackConnector
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
创建pipe的过程,pipe.open(),打开本机通道
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
创建pipe的过程,两个socket的链接校验
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
回到WindowsSelectorImpl构造方法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Nagel算法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
为啥要禁用了TCP中的Nagle算法?
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
回到WindowsSelectorImpl构造方法
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
source端放到了pollWrapper中
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
回顾:pollArray的结构
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
pollArray的元素
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
回顾WindowsSelectorImpl的成员
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
wakeup的消息发送
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl的wakeup实现
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
WindowsSelectorImpl#setWakeupSocket0
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
poll函数的事件标志符值
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
wakeup()的要点:
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
Selector关闭
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
SelectorImpl#implCloseSelector
.....
由于字数限制,此处省略
完整内容,请参见尼恩的《NIO学习圣经》,pdf 免费找尼恩获取
参考文献
https://www.jianshu.com/p/336ade82bdb0
https://www.zhihu.com/question/48510028
https://blog.csdn.net/daaikuaichuan/article/details/83862311
https://zhuanlan.zhihu.com/p/93369069
http://gityuan.com/2019/01/06/linux-epoll/
https://blog.51cto.com/7666425/1261446
https://zhuanlan.zhihu.com/p/340666719
https://zhuanlan.zhihu.com/p/116901360
https://www.cnblogs.com/wanpengcoder/p/11749319.html
https://zhuanlan.zhihu.com/p/64746509
https://zhuanlan.zhihu.com/p/34280875
https://blog.csdn.net/mrpre/article/details/24670659
技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
免费获取11个技术圣经PDF:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号