网易一面:25Wqps高吞吐写Mysql,100W数据4秒写完,如何实现?
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
网易一面:25Wqps高吞吐写Mysql,100W数据4秒写完,如何实现?
说在前面
在尼恩的(50+)读者社区中,经常遇到一个 非常、非常高频的一个面试题,但是很不好回答,类似如下:
- Java怎么实现几十万条数据插入?
- JDBC 添加几万条数据,要求保证效率,请写出代码?
最近,有个小伙伴网易一面,又遇到了这个问题。
咱们一直心心念念的 “Java怎么实现几十万条数据插入?” 的教科书式的答案,
接下来, 尼恩为大家梳理一个教科书式的答案,
超高并发写mysql,一定要用到 批处理方案 。
其实,很多小伙伴都用过,但是却会少说一些核心参数, 少说一些核心步骤,导致面试严重丢分。
这里,尼恩也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典 PDF》V98版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到公号【技术自由圈】取
本文目录
什么是JDBC的批量处理语句?
当需要成批插入或者更新记录时,可以采用Java的批量更新机制,
这一机制允许多条语句一次性提交给数据库批量处理。通常情况下,批量处理 比单独提交处理更有效率
JDBC的批量处理语句包括下面三个方法:
- addBatch(String):添加需要批量处理的SQL语句或是参数;
- executeBatch():执行批量处理语句;
- clearBatch():清空缓存的数据
通常我们会遇到两种批量执行SQL语句的情况:
- 多条SQL语句的批量处理;
- 一个SQL语句的批量传参;
方式一:普通插入
没有对比,没有伤害
没有数据,不是高手
看看普通插入10000W条记录的 性能数据
/**
* 方式一
* 普通批量插入,直接将插入语句执行多次即可
*/
@Test
public void bulkSubmissionTest1() {
long start = System.currentTimeMillis();//开始计时【单位:毫秒】
Connection conn = jdbcUtils.getConnection();//获取数据库连接
String sql = "insert into a(id, name) VALUES (?,null)";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
for (int i = 1; i <= 1000000; i++) {
ps.setObject(1, i);//填充sql语句种得占位符
ps.execute();//执行sql语句
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
jdbcUtils.close(conn, ps, null);
}
//打印耗时【单位:毫秒】
System.out.println("百万条数据插入用时:" + (System.currentTimeMillis() - start)+"【单位:毫秒】");
}
用时

折算:3736/60= 62分钟多
方式二:使用批处理插入
使用PreparedStatement
JDBC的批量处理语句包括下面三个方法:
- addBatch(String): 将sql语句打包到一个Batch容器中, 添加需要批量处理的SQL语句或是参数;
- executeBatch():将Batch容器中的sql语句提交, 执行批量处理语句;
- clearBatch():清空Batch容器,为下一次打包做准备
注意 这三个方法实现sql语句打包,累计到一定数量一次提交
@Test
public void bulkSubmissionTest2() {
long start = System.currentTimeMillis();
Connection conn = jdbcUtils.getConnection();//获取数据库连接
String sql = "insert into a(id, name) VALUES (?,null)";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
for (int i = 1; i <= 1000000; i++) {
ps.setObject(1, i);
ps.addBatch();//将sql语句打包到一个容器中
if (i % 500 == 0) {
ps.executeBatch();//将容器中的sql语句提交
ps.clearBatch();//清空容器,为下一次打包做准备
}
}
//为防止有sql语句漏提交【如i结束时%500!=0的情况】,需再次提交sql语句
ps.executeBatch();//将容器中的sql语句提交
ps.clearBatch();//清空容器
} catch (SQLException e) {
e.printStackTrace();
} finally {
jdbcUtils.close(conn, ps, null);
}
System.out.println("百万条数据插入用时:" + (System.currentTimeMillis() - start)+"【单位:毫秒】");
}
用时

折算:3685/60= 61分钟多
方式一、二总结:到此可以看出其实批处理程序是没有起作用的
方式三:设置数据源的批处理重写标志
通过连接配置url设置&rewriteBatchedStatements=true,打开驱动的rewriteBatchedStatements 开关
在方式二的基础上, 允许jdbc驱动重写批量提交语句,在数据源的url需加上 &rewriteBatchedStatements=true ,表示(重写批处理语句=是)
驱动的url 设置参考如下:
spring.datasource.url = jdbc:mysql://localhost:3306/seckill?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&rewriteBatchedStatements=true
spring.datasource.username = root
spring.datasource.password = 123456
再执行 jdbc 的批处理
/**
* 方式三
*/
@Test
public void bulkSubmissionTest3() {
long start = System.currentTimeMillis();
Connection conn = jdbcUtils.getConnection();//获取数据库连接
String sql = "insert into a(id, name) VALUES (?,null)";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
for (int i = 1; i <= 1000000; i++) {
ps.setObject(1, i);
ps.addBatch();
if (i % 500 == 0) {
ps.executeBatch();
ps.clearBatch();
}
}
ps.executeBatch();
ps.clearBatch();
} catch (SQLException e) {
e.printStackTrace();
} finally {
jdbcUtils.close(conn, ps, null);
}
System.out.println("百万条数据插入用时:" + (System.currentTimeMillis() - start)+"【单位:毫秒】");
}
用时:

折算:10s
从60分钟到10s, 提升了多少倍?
360倍
到此批处理语句才正是生效
注意
数据库连接的url设置了【&rewriteBatchedStatements=true】时,java代码种的sql语句不能有分号【;】号,
否则批处理语句打包就会出现错误,导致后面的sql语句提交出现【BatchUpdateException】异常

批量更新异常:BatchUpdateException
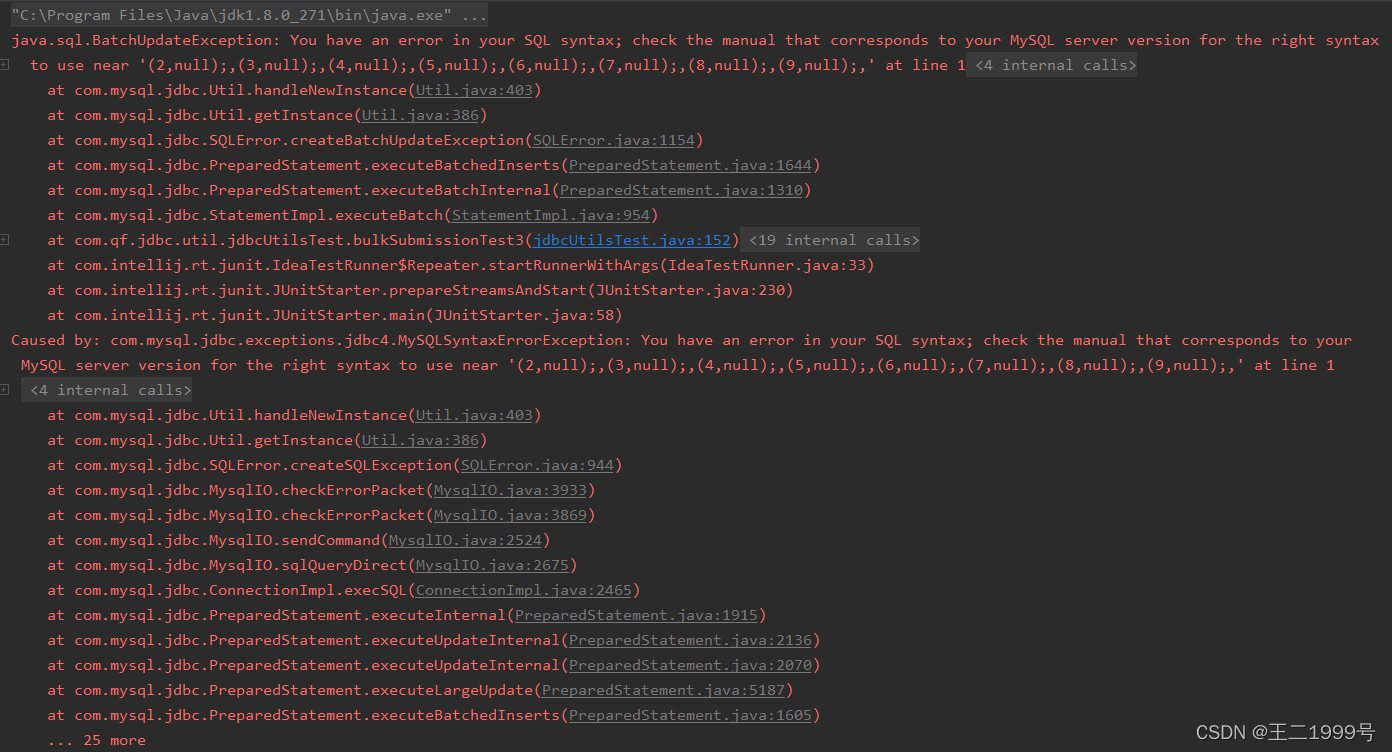
rewriteBatchedStatements底层原理
从 Java 1.2 开始,该Statement接口一直提供addBatch我们可以用来批处理多个语句的接口,以便在调用executeBatch方法时通过单个请求发送它们,如下面的示例所示:
String INSERT = "insert into post (id, title) values (%1$d, 'Post no. %1$d')";
try(Statement statement = connection.createStatement()) {
for (long id = 1; id <= 10; id++) {
statement.addBatch(
String.format(INSERT, id)
);
}
statement.executeBatch();
}
通过分析源码,会发现以下代码块:
if (this.rewriteBatchedStatements.getValue() && nbrCommands > 4) {
return executeBatchUsingMultiQueries(
multiQueriesEnabled,
nbrCommands,
individualStatementTimeout
);
}
updateCounts = new long[nbrCommands];
for (int i = 0; i < nbrCommands; i++) {
updateCounts[i] = -3;
}
int commandIndex = 0;
for (commandIndex = 0; commandIndex < nbrCommands; commandIndex++) {
try {
String sql = (String) batchedArgs.get(commandIndex);
updateCounts[commandIndex] = executeUpdateInternal(sql, true, true);
...
} catch (SQLException ex) {
updateCounts[commandIndex] = EXECUTE_FAILED;
...
}
}
因为rewriteBatchedStatements 标志is flase ,每个 INSERT 语句还是单独执行 executeUpdateInternal, 并没有走 executeBatchUsingMultiQueries 批处理逻辑。
因此,即使我们使用addBatch ,默认情况下,MySQL 在使用普通 JDBC对象executeBatch时仍会单独执行 INSERT 语句。
但是,如果我们启用rewriteBatchedStatementsJDBC 配置属性
方式一:在springboot应用中,调整dataSource的 url 参数
spring.datasource.url = jdbc:mysql://localhost:3306/seckill?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&rewriteBatchedStatements=true
方式二:通过dataSource的方法设置
MysqlDataSource dataSource = new MysqlDataSource();
String url = "jdbc:mysql://localhost/high_performance_java_persistence?useSSL=false";
dataSource.setURL(url);
dataSource.setUser(username());
dataSource.setPassword(password());
dataSource.setRewriteBatchedStatements(true);
设置完了之后,调试executeBatch方法执行,你会看到:
这一次,executeBatchUsingMultiQueries被调用了
if (this.rewriteBatchedStatements.getValue() && nbrCommands > 4) {
return executeBatchUsingMultiQueries(
multiQueriesEnabled,
nbrCommands,
individualStatementTimeout
);
}
并且该executeBatchUsingMultiQueries方法会将各个 INSERT 语句拼接到 queryBuf (一个StringBuilder),
拼接后,运行单个execute调用:
StringBuilder queryBuf = new StringBuilder();
batchStmt = locallyScopedConn.createStatement();
JdbcStatement jdbcBatchedStmt = (JdbcStatement) batchStmt;
...
int argumentSetsInBatchSoFar = 0;
for (commandIndex = 0; commandIndex < nbrCommands; commandIndex++) {
String nextQuery = (String) this.query.getBatchedArgs().get(commandIndex);
...
queryBuf.append(nextQuery);
queryBuf.append(";");
argumentSetsInBatchSoFar++;
}
if (queryBuf.length() > 0) {
try {
batchStmt.execute(queryBuf.toString(), java.sql.Statement.RETURN_GENERATED_KEYS);
} catch (SQLException ex) {
sqlEx = handleExceptionForBatch(
commandIndex - 1, argumentSetsInBatchSoFar, updateCounts, ex
);
}
...
}
因此,对于普通的 JDBCStatement批处理,MySQLrewriteBatchedStatements配置属性将附加当前批处理的语句并在单个数据库往返中执行它们。
将 rewriteBatchedStatements 与 PreparedStatement 一起使用
使用 JPA 和 Hibernate 时, SQL 语句都将使用 JDBC 执行PreparedStatement,而不是Statement,这是有充分理由的:
- PreparedStatement准备好的语句允许你增加语句缓存的可能性
- PreparedStatement准备好的语句允许你避免 SQL 注入攻击,因为你绑定参数值而不是像我们在之前的
String.format调用中那样注入它们。
但是,由于 Hibernate 默认不启用 JDBC 批处理,我们需要提供以下配置属性来激活自动批处理机制:
spring.jpa.properties.hibernate.jdbc.batch_size=10
spring.jpa.properties.hibernate.order_inserts=true
spring.jpa.properties.hibernate.order_updates=true
因此,当持久化 10 个Post实体时:
for (long i = 1; i <= 10; i++) {
entityManager.persist(
new Post()
.setId(i)
.setTitle(String.format("Post no. %d", i))
);
}
Hibernate 将执行单个 JDBC INSERT,如datasource-proxy日志条目所示:
Type:Prepared, Batch:True, QuerySize:1, BatchSize:10,
Query:["
insert into post (title, id) values (?, ?)
"],
Params:[
(Post no. 1, 1), (Post no. 2, 2), (Post no. 3, 3),
(Post no. 4, 4), (Post no. 5, 5), (Post no. 6, 6),
(Post no. 7, 7), (Post no. 8, 8), (Post no. 9, 9),
(Post no. 10, 10)
]
注意:如果使用
IDENTITY实体标识符策略,Hibernate 将无法自动批处理插入语句。看看这篇文章。
因此,使用默认的 MySQL JDBC 驱动程序设置,一条语句被发送到 MySQL 数据库服务器。
但是,如果你检查数据库服务器日志,我们可以看到语句到达后,MySQL 执行每个语句,就好像它们在 for 循环中运行一样:
Query insert into post (title, id) values ('Post no. 1', 1)
Query insert into post (title, id) values ('Post no. 2', 2)
Query insert into post (title, id) values ('Post no. 3', 3)
Query insert into post (title, id) values ('Post no. 4', 4)
Query insert into post (title, id) values ('Post no. 5', 5)
Query insert into post (title, id) values ('Post no. 6', 6)
Query insert into post (title, id) values ('Post no. 7', 7)
Query insert into post (title, id) values ('Post no. 8', 8)
Query insert into post (title, id) values ('Post no. 9', 9)
Query insert into post (title, id) values ('Post no. 10', 10)
Query commit
因此,启用rewriteBatchedStatementsMySQL JDBC Driver 设置后:
dataSource.setRewriteBatchedStatements(true);
当我们重新运行之前插入 10 个实体的测试用例时Post,我们可以看到在数据库端执行了以下 INSERT 语句:
Query insert into post (title, id)
values ('Post no. 1', 1),('Post no. 2', 2),('Post no. 3', 3),
('Post no. 4', 4),('Post no. 5', 5),('Post no. 6', 6),
('Post no. 7', 7),('Post no. 8', 8),('Post no. 9', 9),
('Post no. 10', 10)
Query commit
语句更改的原因是 MySQL JDBC 驱动程序现在调用将executeBatchWithMultiValuesClause批处理的 INSERT 语句重写为单个多值 INSERT 的方法。
if (!this.batchHasPlainStatements &&
this.rewriteBatchedStatements.getValue()) {
if (getQueryInfo().isRewritableWithMultiValuesClause()) {
return executeBatchWithMultiValuesClause(batchTimeout);
}
...
}
方式四:通过数据库连接取消自动提交,手动提交数据
在方式三的基础上,取消自动提交sql语句,当sql语句都提交了才手动提交sql语句
需将Connection conn;连接的【conn.setAutoCommit(false)】(设置自动提交=否)
/**
* 方式四
*
*/
@Test
public void bulkSubmissionTest4() {
long start = System.currentTimeMillis();
Connection conn = jdbcUtils.getConnection();//获取数据库连接
String sql = "insert into a(id, name) VALUES (?,null)";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
conn.setAutoCommit(false);//取消自动提交
for (int i = 1; i <= 1000000; i++) {
ps.setObject(1, i);
ps.addBatch();
if (i % 500 == 0) {
ps.executeBatch();
ps.clearBatch();
}
}
ps.executeBatch();
ps.clearBatch();
conn.commit();//所有语句都执行完毕后才手动提交sql语句
} catch (SQLException e) {
e.printStackTrace();
} finally {
jdbcUtils.close(conn, ps, null);
}
System.out.println("百万条数据插入用时:" + (System.currentTimeMillis() - start)+"【单位:毫秒】");
}
用时:【4秒左右】

汇总一下,批处理操作的详细步骤
上述示例代码中,我们通过 JDBC 连接 MySQL 数据库,并执行批处理操作插入数据。
具体实现步骤如下:
- 获取数据库连接。
- 创建 Statement 对象。
- 定义 SQL 语句,使用 PreparedStatement 对象预编译 SQL 语句并设置参数。
- 取消自动提交
- 将sql语句打包到一个Batch容器中, 添加需要批量处理的SQL语句或是参数
- 执行批处理操作。
- 清空Batch容器,为下一次打包做准备
- 不断迭代第5-7步,直到数据处理完成。
- 关闭 Statement 和 Connection 对象。
使用setAutoCommit(false) 来禁止自动提交事务,然后在每次批量插入之后手动提交事务。
每次插入数据时都新建一个 PreparedStatement 对象以避免状态不一致问题。
在插入数据的循环中,每累计到一定量的数据 如 10000 条数据就执行一次 executeBatch() 插入数据。
另外注意:
- 使用批量提交数据,url一定要设置允许重写批量提交rewriteBatchedStatements=true,
- sql语句一定不能有分号,否则有BatchUpdateException异常,
- 在循环插入时带有适当的等待时间 和批处理大小 ,从而避免内存占用过高等问题:
- 设置适当的批处理大小:批处理大小指在一次插入操作中插入多少行数据。如果批处理大小太小,插入操作的频率将很高,而如果批处理大小太大,可能会导致内存占用过高。通常,建议将批处理大小设置为1000-5000行,这将减少插入操作的频率并降低内存占用。
- 采用适当的等待时间:等待时间指在批处理操作之间等待的时间量。等待时间过短可能会导致内存占用过高,而等待时间过长则可能会延迟插入操作的速度。通常,建议将等待时间设置为几秒钟到几十秒钟之间,这将使操作变得平滑且避免出现内存占用过高等问题。
- 可以考虑使用一些内存优化的技巧,例如使用内存数据库或使用游标方式插入数据,以减少内存占用。
- 总的来说,选择适当的批处理大小和等待时间可以帮助您平稳地进行插入操作,避免出现内存占用过高等问题。
索引: 在大量数据插入前暂时去掉索引,最后再打上,这样可以大大减少写入时候的更新索引的时间。数据库连接池:使用数据库连接池可以减少数据库连接建立和关闭的开销,提高性能。在没有使用数据库连接池的情况,记得在finally中关闭相关连接。数据库参数调整:增加MySQL数据库缓冲区大小、配置高性能的磁盘和I/O等。- 需要根据实际情况优化连接池和数据库的相关配置,以防止连接超时等问题。
所以,以上才是“教科书式” 答案:
结合 B站的方案,大家回到前面的面试题:
- Java怎么实现几十万条数据插入?
- JDBC 添加几万条数据,要求保证效率,请写出代码?
以上的方案,才是完美的答案,才是“教科书式” 答案。 后续,尼恩会给大家结合行业案例,分析出更多,更加劲爆的答案。
当然,如果遇到这类问题,可以找尼恩求助。
技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
免费获取11个技术圣经PDF:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号