大数据Flink学习圣经:一本书实现大数据Flink自由
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
大数据Flink学习圣经:一本书实现大数据Flink自由
学习目标:三栖合一架构师
本文是《大数据Flink学习圣经》 V1版本,是 《尼恩 大数据 面试宝典》姊妹篇。
这里特别说明一下:《尼恩 大数据 面试宝典》5个专题 PDF 自首次发布以来, 已经汇集了 好几百题,大量的大厂面试干货、正货 。 《尼恩 大数据 面试宝典》面试题集合, 将变成大数据学习和面试的必读书籍。
于是,尼恩架构团队 趁热打铁,推出 《大数据Flink学习圣经》,《大数据HBASE学习圣经》
《大数据Flink学习圣经》 后面会不断升级,不断 迭代, 变成大数据领域 学习和面试的必读书籍,
最终,帮助大家成长为 三栖合一架构师,进大厂,拿高薪。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到公号【技术自由圈】取

“Java+大数据” 双栖架构成功案例
成功案例1:
惊天大逆袭:失业4个月,3年小伙1个月喜提架构Offer,而且是大龄跨行,超级牛
成功案例2:
极速拿offer:阿里P6被裁后极速上岸,1个月内喜提2优质offer(含滴滴)
@
1. 什么是Flink
大数据
大数据(Big Data)是指规模庞大、结构多样且速度快速增长的数据集合。这些数据集合通常包含传统数据库管理系统无法有效处理的数据,具有高度的复杂性和挑战性。大数据的主要特点包括三个维度:三V,即Volume(数据量大)、Variety(数据多样性)、Velocity(数据速度)。
- 数据量大(Volume):大数据的最明显特征之一是其庞大的数据量。传统的数据处理方法和工具在处理这种规模的数据时可能会变得低效或不可行。
- 数据多样性(Variety):大数据不仅包括结构化数据(如表格数据),还包括半结构化数据(如JSON、XML)和非结构化数据(如文本、图像、音频、视频等)。这些数据可能来自不同的源头和不同的格式。
- 数据速度快(Velocity):大数据往往以高速率产生、流动和累积。这要求数据处理系统能够实时或近实时地处理数据,以便从中获取有价值的信息。
分布式计算
随着计算机技术的发展和数据规模的增大,单台计算机的处理能力和存储容量逐渐变得有限,无法满足大数据处理的要求。为了应对这一挑战,分布式计算应运而生,它利用多台计算机组成集群,将计算任务分割成多个子任务并在不同的计算节点上并行执行,从而提高计算效率和处理能力。
分布式计算的核心思想是将大问题划分为小问题,将任务分发给多个计算节点并行执行,最后将结果合并得到最终的解。这种方式有效地解决了单台计算机无法处理大规模数据和高并发计算的问题。同时,分布式计算还具有良好的可扩展性,可以根据数据量的增加灵活地扩展集群规模,以应对不断增长的数据挑战。
分布式计算的概念听起来很高深,其背后的思想却十分朴素,即分而治之,又称为分治法(Divide and Conquer)。分治法是一种解决问题的算法设计策略,它将一个问题分解成多个相同或相似的子问题,然后分别解决这些子问题,最后将子问题的解合并起来得到原问题的解。分治法常用于解决复杂问题,尤其是在大数据处理中,可以将大规模的数据集合分割成更小的部分,然后分别处理这些部分,最后合并结果。
在处理大数据问题时,可以使用分治法的思想来提高效率和可扩展性,以下是一些应用分治法处理大数据问题的示例:
-
MapReduce 模式:分治法的经典应用是 MapReduce 模式,它将大规模的数据集合分为多个小块,每个小块由不同的计算节点进行处理,然后将结果合并。这种方法适用于批处理任务,如数据清洗、转换、聚合等。
-
并行计算:将大规模的计算任务分解成多个小任务,分配给不同的计算节点并行处理,最后合并结果。这适用于需要大量计算的问题,如数值模拟、图算法等。
-
分布式排序:将大规模数据集合分割成多个部分,每个部分在不同的计算节点上进行排序,然后使用合并排序算法将这些有序部分合并为整体有序的数据集合。
-
分区和分片:在分布式存储系统中,可以将数据分区和分片存储在不同的节点上,通过分区键或哈希函数将数据分配到不同的存储节点上,从而实现数据的分布式存储和管理。
-
分布式机器学习:将大规模的机器学习任务分解成多个子任务,在分布式计算环境中分别进行训练,然后合并模型参数,如分布式随机梯度下降算法。
-
数据分割和合并:对于需要频繁访问的大数据集合,可以将数据分割成多个小块,每个小块存储在不同的存储节点上,然后根据需要进行合并,以减少数据访问的开销。

分治法在大数据处理中的应用不仅有助于提高处理效率,还可以充分利用分布式计算和存储资源,从而更好地应对大数据量和复杂性。然而,在应用分治法时需要考虑合适的数据分割策略、任务调度、结果合并等问题,以确保分治法的正确性和性能。
然而,分布式计算也带来了一些挑战,如数据一致性、通信开销、任务调度等问题,需要综合考虑各种因素来设计和优化分布式系统。同时,分布式计算也需要开发者具备分布式系统设计和调优的知识和技能,以确保系统的性能和稳定性。
分布式存储
当数据量巨大且单机存储已无法满足需求时,分布式存储和分布式文件系统成为处理大数据的关键技术。下面我会详细介绍分布式存储和分布式文件系统的概念、特点和常见的实现。
分布式存储:
分布式存储是将数据分散存储在多个节点上,以提供高容量、高性能、高可靠性和可扩展性的数据存储解决方案。每个节点都可以通过网络访问数据,并且多个节点协同工作来处理数据请求。分布式存储的核心目标是解决单机存储的瓶颈,同时提供高可靠性和可用性。
分布式存储的特点包括:
- 横向扩展性:可以通过增加节点来扩展存储容量和性能,适应不断增长的数据量和负载。
- 高可靠性和容错性:数据在多个节点上冗余存储,当某个节点出现故障时,数据依然可用,不会丢失。
- 数据分布和复制:数据按照一定策略分布在不同节点上,数据的复制确保了数据的可用性和容错性。
- 并发访问和高性能:支持多个客户端同时访问数据,实现高并发和更好的性能。
- 灵活的数据模型:支持多种数据类型和访问方式,如文件系统、对象存储、键值存储等。
分布式文件系统:
分布式文件系统是一种特殊类型的分布式存储,主要用于存储和管理文件数据。它提供了类似于传统单机文件系统的接口,但是在底层实现上,数据被分散存储在多个节点上。分布式文件系统能够自动处理数据的分布、复制、一致性和故障恢复等问题。
常见的分布式文件系统特点包括:
- 命名空间和路径:分布式文件系统通过路径来访问文件,类似于传统文件系统的目录结构。
- 数据分布和复制:文件被切分成块并分散存储在多个节点上,同时进行数据复制以实现冗余和高可用性。
- 一致性和数据一致性模型:分布式文件系统需要保证数据的一致性,不同节点上的数据副本需要保持同步。
- 访问控制和权限管理:提供用户和应用程序访问控制和权限管理功能,确保数据安全性。
- 高性能:分布式文件系统通常优化了数据的读写性能,以满足大数据场景的需求。
- 扩展性:可以通过增加节点来扩展存储容量和性能。
常见的分布式文件系统包括:
- Hadoop HDFS(Hadoop Distributed File System):Hadoop生态系统中的分布式文件系统,适用于大数据存储。
- Ceph:开源的分布式存储系统,提供块存储、文件系统和对象存储。
- GlusterFS:开源的分布式文件系统,可以线性扩展存储容量和性能。
总之,分布式存储和分布式文件系统在大数据时代扮演着重要角色,帮助我们存储、管理和访问海量的数据,解决了传统单机存储无法应对的挑战。
批处理和流处理
批处理和流处理是大数据处理领域中常见的两种数据处理模式,用于不同类型的数据处理需求。下面将详细介绍这两种模式,并给出相关的应用场景示例。
批处理(Batch Processing):
批处理是指将一批数据集合在一起,在一个固定的时间间隔内对这批数据进行处理和分析。批处理通常适用于数据量较大、处理周期较长、要求高一致性的场景。
特点:
- 数据被集中处理,适合周期性分析和报告生成。
- 数据被切分成小块,每个小块在一个作业中被处理。
- 数据处理时间较长,不适合实时性要求高的场景。
应用场景示例:
- 离线数据分析:对历史数据进行分析,从中发现趋势、模式和规律,用于业务决策。例如,销售数据分析、用户行为分析。
- 批量推荐系统:基于用户历史行为数据,定期生成推荐结果。例如,电影推荐、商品推荐。
- 数据清洗和预处理:对大规模数据进行清洗、过滤和预处理,提高数据质量和可用性。例如,清理无效数据、填充缺失值。
- 大规模ETL(Extract, Transform, Load):将数据从源系统中抽取出来,经过转换和加工后加载到目标系统。例如,数据仓库的构建。
流处理(Stream Processing):
流处理是指在数据生成的时候立即进行处理,实现数据的实时处理和分析。流处理通常适用于数据实时性要求高、需要快速响应的场景。
特点:
- 数据是实时流动的,需要快速处理和响应。
- 数据是持续不断地到达,需要实时计算和分析。
- 可能会遇到延迟和数据乱序等问题。
应用场景示例:
- 实时监控和告警:对实时数据进行监控和分析,及时发现异常并触发告警。例如,网络流量监控、系统性能监控。
- 实时数据分析:对流式数据进行实时分析,从中提取有价值的信息。例如,实时点击流分析、实时市场行情分析。
- 实时推荐系统:基于用户实时行为数据,实时生成推荐结果。例如,新闻推荐、广告推荐。
- 实时数据仓库:构建实时数据仓库,将实时数据集成、加工和分析。例如,实时销售数据分析、实时用户行为分析。
总之,批处理和流处理分别适用于不同类型的数据处理需求,根据业务需求和实时性要求选择合适的处理模式。
开源大数据技术

当谈论大数据处理时,Hadoop、YARN、Spark和Flink都是重要的技术。它们都属于大数据领域的分布式计算框架,但在功能和使用方式上有所不同。
Hadoop:
Hadoop是一个开源的分布式存储和计算框架,最初由Apache开发,用于处理大规模数据集。Hadoop的核心组件包括:
-
Hadoop Distributed File System(HDFS):HDFS是一种分布式文件系统,用于存储大规模数据。它将数据分成多个块,并将这些块分散存储在集群中的不同节点上。HDFS支持高可靠性、冗余存储和数据复制。
-
MapReduce:MapReduce是Hadoop的计算模型,用于处理分布式数据。它将计算任务分成Map和Reduce两个阶段,分布在集群中的节点上并行执行。Map阶段负责数据的拆分和处理,Reduce阶段负责数据的汇总和计算。
YARN(Yet Another Resource Negotiator):
YARN是Hadoop的资源管理器,它负责集群资源的管理和分配。YARN将集群资源划分为容器(Containers),并分配给不同的应用程序。这种资源的隔离和管理允许多个应用程序同时在同一个Hadoop集群上运行,从而提高了资源利用率和集群的多租户能力。
Spark:
Apache Spark是一个通用的分布式计算引擎,旨在提供高性能、易用性和多功能性。与传统的Hadoop MapReduce相比,Spark具有更快的执行速度,因为它将数据加载到内存中并进行内存计算。Spark支持多种计算模式,包括批处理、交互式查询、流处理和机器学习。
Spark的主要特点和组件包括:
-
RDD(Resilient Distributed Dataset):RDD是Spark的核心数据抽象,表示分布式的数据集。RDD支持并行操作和容错性,可以在计算过程中重新计算丢失的分区。
-
Spark SQL:Spark SQL是用于处理结构化数据的组件,支持SQL查询和操作。它能够将RDD和传统的数据源(如Hive)无缝集成。
-
Spark Streaming:Spark Streaming是用于处理实时流数据的模块,支持微批处理模式。它能够将实时数据流分割成小批次并进行处理。
-
MLlib:MLlib是Spark的机器学习库,提供了常见的机器学习算法和工具,用于训练和评估模型。
-
GraphX:GraphX是Spark的图计算库,用于处理图数据和图算法。
Flink:
Apache Flink是一个流式处理引擎和分布式批处理框架,具有低延迟、高吞吐量和容错性。Flink支持流批一体化,能够实现实时流处理和批处理作业的无缝切换。它的核心特点包括:
- DataStream API:Flink的DataStream API用于处理实时流数据,支持事件时间处理、窗口操作和状态管理。它能够处理高吞吐量的实时数据流。
- DataSet API:Flink的DataSet API用于批处理作业,类似于Hadoop的MapReduce。它支持丰富的操作符和优化技术。
- Stateful Stream Processing:Flink支持有状态的流式处理,可以在处理过程中保存和管理状态。这对于实现复杂的数据处理逻辑很有用。
- Event Time Processing:Flink支持事件时间处理,能够处理乱序事件并准确计算窗口操作的结果。
- Table API和SQL:Flink提供了Table API和SQL查询,使开发人员可以使用类似SQL的语法来查询和分析数据。
- 可以连接大数据生态圈各类组件,包括Kafka、Elasticsearch、JDBC、HDFS和Amazon S3
- 可以运行在Kubernetes、YARN、Mesos和独立(Standalone)集群上。
Flink在流处理上的几个主要优势如下:
-
真正的流计算引擎:Flink具有更好的streaming计算模型,可以进行非常高效的状态运算和窗口操作。Spark Streaming仍然是微批处理引擎。
-
更低延迟:Flink可以实现毫秒级的低延迟处理,而Spark Streaming延迟较高。
-
更好的容错机制:Flink支持更细粒度的状态管理和检查点机制,可以实现精确一次的状态一致性语义。Spark较难做到确保exactly once。
-
支持有限数据流和无限数据流:Flink可处理有开始和结束的有限数据流,也能处理无限不断增长的数据流。Spark Streaming更适合有限数据集。
-
更易统一批处理和流处理:Flink提供了DataStream和DataSet API,可以轻松统一批处理和流处理。Spark需要联合Spark SQL使用。
-
更优秀的内存管理:Flink具有自己的内存管理,可以根据不同查询优化内存使用。Spark依赖Hadoop YARN进行资源调度。
-
更高性能:在部分场景下,Flink拥有比Spark Streaming更高的吞吐和低的延迟。
总体来说,Flink作为新一代流处理引擎,在延迟、容错、易用性方面优于Spark Streaming。但Spark生态更加完善,也在努力减小与Flink的差距。需要根据具体场景选择最优的框架。
总的来说,Flink在流处理领域的优势主要体现在事件时间处理、低延迟、精确一次语义和状态管理等方面。这些特性使得Flink在处理实时流数据时能够更好地满足复杂的业务需求,特别是对于需要高准确性和可靠性的应用场景。
2. Flink 部署
Apache Flink在1.7版本中进行了重大的架构重构,引入了Master-Worker架构,这使得Flink能够更好地适应不同的集群基础设施,包括Standalone、Hadoop YARN和Kubernetes等。下面会详细介绍一下Flink 1.7版本引入的Master-Worker架构以及其在不同集群基础设施中的适应性。
Master-Worker架构:
Flink 1.7版本中引入的Master-Worker架构是为了解决之前版本中存在的一些问题,如资源管理、高可用性等。在这个架构中,Flink将任务管理和资源管理分离,引入了JobManager和ResourceManager两个主要角色。
-
JobManager:负责接受和调度任务,维护任务的状态和元数据信息,还负责处理容错机制。JobManager分为两种:JobManager(高可用模式)和StandaloneJobManager(非高可用模式)。
-
ResourceManager:负责管理集群中的资源,包括分配任务的资源、维护资源池等。
这种架构的优势在于解耦任务的管理和资源的管理,使得Flink能够更好地适应不同的集群环境和基础设施。
兼容性:
Flink的Master-Worker架构设计使其能够兼容几乎所有主流信息系统的基础设施,包括:
-
Standalone集群:在Standalone模式下,Flink的JobManager和ResourceManager都运行在同一个进程中,适用于简单的开发和测试场景。
-
Hadoop YARN集群:Flink可以部署在现有的Hadoop YARN集群上,通过ResourceManager与YARN ResourceManager进行交互,实现资源管理。
-
Kubernetes集群:Flink还支持在Kubernetes集群中部署,通过Kubernetes提供的资源管理能力来管理任务和资源。
这种兼容性使得Flink可以灵活地在不同的集群环境中运行,满足不同场景下的需求。
总之,Flink在1.7版本中引入的Master-Worker架构使其在资源管理、高可用性等方面有了更好的表现,同时也使得Flink能够更好地适应各种不同的集群基础设施,包括Standalone、Hadoop YARN和Kubernetes等。这为Flink的部署和使用带来了更多的灵活性和选择性。
Standalone集群是Apache Flink中一种简单的部署模式,适用于开发、测试和小规模应用场景。下面我将详细介绍Standalone集群的特点以及部署方式。
Standalone集群的特点:

-
简单部署:Standalone集群是Flink的最简单部署模式之一,不需要依赖其他集群管理工具,可以在单个机器上部署。
-
资源共享:Standalone集群中的JobManager和TaskManager共享同一份资源,例如内存和CPU。这使得资源管理相对简单,但也可能在资源竞争时影响任务的性能。
-
适用于开发和测试:Standalone集群适用于开发和测试阶段,可以在本地机器上模拟Flink集群环境,方便开发人员进行调试和测试。
-
不支持高可用性:Standalone集群默认情况下不支持高可用性,即不具备故障恢复和任务迁移的能力。如果需要高可用性,可以通过运行多个JobManager实例来实现。
Standalone集群的部署方式:
-
安装Flink:首先,需要下载并安装Flink。可以从官方网站下载预编译的二进制文件,解压到指定目录。也可以从以下网站下载:
apache-flink安装包下载_开源镜像站-阿里云 (aliyun.com)

-
配置Flink:进入Flink的安装目录,修改
conf/flink-conf.yaml配置文件。主要配置项包括jobmanager.rpc.address和taskmanager.numberOfTaskSlots等。 -
启动JobManager:打开终端,进入Flink安装目录,执行以下命令启动JobManager:
./bin/start-cluster.sh -
启动TaskManager:打开终端,进入Flink安装目录,执行以下命令启动TaskManager:
./bin/taskmanager.sh start -
提交作业:使用Flink客户端工具提交作业。可以使用以下命令提交JAR文件中的作业:
./bin/flink run -c your.main.Class ./path/to/your.jar -
停止集群:可以使用以下命令停止整个Standalone集群:
./bin/stop-cluster.sh
总之,Standalone集群是一个简单且易于部署的Flink集群模式,适用于开发、测试和小规模应用场景。然而,由于其资源共享和不支持高可用性的特点,不适合部署在生产环境中。
下面提供利用Docker部署flink standalone简单集群。
Docker部署flink简单集群
Flink程序可以作为集群内的分布式系统运行,也可以以独立模式或在YARN、Mesos、基于Docker的环境和其他资源管理框架下进行部署。
1、在服务器创建flink目录
mkdir flink
目录的结构如下:

2、docker-compose.yml脚本创建
docker 容器的编排文件,具体如下

3、启动flink
(1)后台运行
一般推荐生产环境下使用该选项。
docker-compose up -d
(2)前台运行
控制台将会同时打印所有容器的输出信息,可以很方便进行调试。
docker-compose up
4、浏览器上查看页面dashboard
访问web界面
http://cdh1:8081/

3. Flink快速应用
通过一个单词统计的案例,快速上手应用Flink,进行流处理(Streaming)和批处理(Batch)
实操1: 单词统计案例(批数据)
1.1 需求
统计一个文件中各个单词出现的次数,把统计结果输出到文件
步骤:
1、读取数据源
2、处理数据源
a、将读到的数据源文件中的每一行根据空格切分
b、将切分好的每个单词拼接1
c、根据单词聚合(将相同的单词放在一起)
d、累加相同的单词(单词后面的1进行累加)
3、保存处理结果
1.2 代码实现
- 引入依赖
<!--flink核心包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.2</version>
</dependency>
<!--flink流处理包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.7.2</version>
<scope>provided</scope>
</dependency>
- Java程序
package com.crazymaker.bigdata.wordcount.batch;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 1、读取数据源
* 2、处理数据源
* a、将读到的数据源文件中的每一行根据空格切分
* b、将切分好的每个单词拼接1
* c、根据单词聚合(将相同的单词放在一起)
* d、累加相同的单词(单词后面的1进行累加)
* 3、保存处理结果
*/
public class WordCountJavaBatch {
public static void main(String[] args) throws Exception {
String inputPath="D:\\data\\input\\hello.txt";
String outputPath="D:\\data\\output\\hello.txt";
//获取flink的运行环境
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = executionEnvironment.readTextFile(inputPath);
FlatMapOperator<String, Tuple2<String, Integer>> wordOndOnes = text.flatMap(new SplitClz());
//0代表第1个元素
UnsortedGrouping<Tuple2<String, Integer>> groupedWordAndOne = wordOndOnes.groupBy(0);
//1代表第1个元素
AggregateOperator<Tuple2<String, Integer>> out = groupedWordAndOne.sum(1);
out.writeAsCsv(outputPath, "\n", " ").setParallelism(1);//设置并行度
executionEnvironment.execute();//人为调用执行方法
}
static class SplitClz implements FlatMapFunction<String,Tuple2<String,Integer>>{
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] s1 = s.split(" ");
for (String word:s1) {
collector.collect(new Tuple2<String,Integer>(word,1));//发送到下游
}
}
}
}
源文件的内容

统计的结果

实操2: 单词统计案例(流数据)
nc
netcat:
flink开发时候,经常用socket作为source;使用linux/mac环境开发,可以在终端中开启 nc -l 9000(开启netcat程序,作为服务端,发送数据);
nc是netcat的缩写,有着网络界的瑞士军刀美誉。因为它短小精悍、功能实用,被设计为一个简单、可靠的网络工具。
nc作用
- 数据传输
- 文件传输
- 机器之间网络测速
2.1 需求
Socket模拟实时发送单词,
使用Flink实时接收数据,对指定时间窗口内(如5s)的数据进行聚合统计,每隔1s汇总计算一次,并且把时间窗口内计算结果打印出来。
2.2 代码实现
package com.crazymaker.bigdata.wordcount.stream;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Socket模拟实时发送单词,使用Flink实时接收数据
*/
public class WordCountStream {
public static void main(String[] args) throws Exception {
// 监听的ip和端口号,以main参数形式传入,约定第一个参数为ip,第二个参数为端口
// String ip = args[0];
String ip = "127.0.0.1";
// int port = Integer.parseInt(args[1]);
int port = 9000;
// 获取Flink流执行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取socket输入数据
DataStreamSource<String> textStream = streamExecutionEnvironment.socketTextStream(ip, port, "\n");
SingleOutputStreamOperator<Tuple2<String, Long>> tuple2SingleOutputStreamOperator = textStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
public void flatMap(String s, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] splits = s.split("\\s");
for (String word : splits) {
collector.collect(Tuple2.of(word, 1l));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Long>> word = tuple2SingleOutputStreamOperator.keyBy(0)
.sum(1);
// 打印数据
word.print();
// 触发任务执行
streamExecutionEnvironment.execute("wordcount stream process");
}
}
Flink程序开发的流程总结
Flink程序开发的流程总结如下:
1)获得一个执行环境
2)加载/创建初始化数据
3)指定数据操作的算子
4)指定结果数据存放位置
5)调用execute()触发执行程序
注意:Flink程序是延迟计算的,只有最后调用execute()方法的时候才会真正触发执行程序
4. Flink分布式架构与核心组件
Flink作业提交过程
standalone模式下的作业提交过程如下:
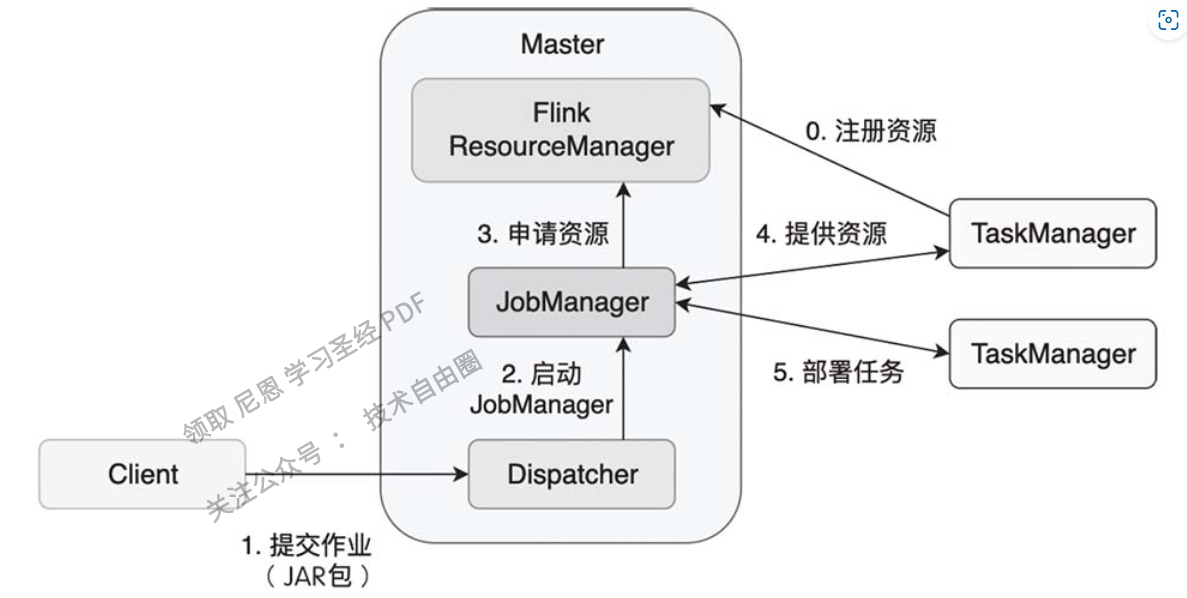
在一个作业提交前,Master和TaskManager等进程需要先被启动。
我们可以在Flink主目录中执行脚本来启动这些进程:
bin/start-cluster.sh。
Master和TaskManager被启动后,TaskManager需要将自己注册给Master中的ResourceManager。
这个初始化和资源注册过程发生在单个作业提交前,我们称之为第0步。
接下来,我们将逐步解析Flink作业的提交过程,具体步骤如下:
① 用户编写应用程序代码,并使用Flink客户端(Client)提交该作业。通常,这些程序会使用Java或Scala语言编写,并调用Flink API 构建出逻辑视图。这些代码以及相关配置文件被编译并打包,然后被提交至Master节点的Dispatcher,形成一个应用作业(Application)。
② Dispatcher接收到提交的作业后,会启动一个JobManager,该JobManager负责协调这个作业的各项任务。
③ JobManager向ResourceManager申请所需的作业资源,这些资源可能包括CPU、内存等。
④ 由于在前面的步骤中,TaskManager已经向ResourceManager注册了可供使用的资源,这时处于空闲状态的TaskManager将被分配给JobManager。
⑤ JobManager将用户作业中的逻辑视图转化为物理执行图,如图3-3所示,该图显示了作业被并行化后的执行过程。JobManager将计算任务分配并部署到多个TaskManager上。此时,一个Flink作业正式开始执行。
在计算任务执行过程中,TaskManager可能会与其他TaskManager交换数据,使用特定的数据交换策略。同时,TaskManager还会将任务的状态信息传递给JobManager,这些状态信息包括任务的启动、执行和终止状态,以及快照的元数据等。
Flink核心组件
在这个作业提交流程的基础上,我们可以更详细地介绍涉及的各个组件的功能和角色:
-
Client(客户端):用户通常使用Flink提供的客户端工具(如位于Flink主目录下的bin目录中的命令行工具)来提交作业。客户端会对用户提交的Flink作业进行预处理,并将作业提交到Flink集群中。在提交作业时,客户端需要配置一些必要的参数,例如使用Standalone集群还是YARN集群等。整个作业会被打包成一个JAR文件,DataStream API会被转换成一个JobGraph,该图类似于逻辑视图(如图3-2所示)。
-
Dispatcher(调度器):Dispatcher可以接收多个作业,每次接收作业时,会为该作业分配一个JobManager。Dispatcher通过提供表述性状态转移(REST)式的接口,使用超文本传输协议(HTTP)来对外提供服务。
-
JobManager(作业管理器):JobManager是单个Flink作业的协调者。每个作业都有一个对应的JobManager负责管理。JobManager将客户端提交的JobGraph转化为ExecutionGraph,该图类似于并行物理执行图(如图3-3所示)。JobManager会向ResourceManager申请所需的资源。一旦获取足够的资源,JobManager会将ExecutionGraph及其计算任务分发到多个TaskManager上。此外,JobManager还管理多个TaskManager,包括收集作业状态信息、生成检查点、必要时进行故障恢复等。
-
ResourceManager(资源管理器):Flink可以在Standalone、YARN、Kubernetes等环境中部署,而不同环境对计算资源的管理模式有所不同。为了解决资源分配问题,Flink引入了ResourceManager模块。在Flink中,计算资源的基本单位是TaskManager上的任务槽位(Slot)。ResourceManager的主要职责是从资源提供方(如YARN)获取计算资源。当JobManager需要计算资源时,ResourceManager会将空闲的Slot分配给JobManager。在计算任务结束后,ResourceManager会回收这些空闲Slot。
-
TaskManager(任务管理器):TaskManager是实际执行计算任务的节点。一般来说,一个Flink作业会分布在多个TaskManager上执行,每个TaskManager提供一定数量的Slot。当一个TaskManager启动后,相关的Slot信息会被注册到ResourceManager中。当Flink作业提交后,ResourceManager会将空闲的Slot分配给JobManager。一旦JobManager获取了空闲Slot,它会将具体的计算任务部署到这些Slot上,并在这些Slot上执行。在执行过程中,TaskManager可能需要与其他TaskManager进行数据交换,因此需要进行必要的数据通信。总之,TaskManager负责具体计算任务的执行,它会在启动时将Slot资源向ResourceManager注册。
Flink组件栈

-
部署层:
- Local模式:Flink支持本地模式,包括单节点(SingleNode)和单虚拟机(SingleJVM)模式。在SingleNode模式中,JobManager和TaskManager运行在同一个节点上;在SingleJVM模式中,所有角色都在同一个JVM中运行。
- Cluster模式:Flink可以部署在Standalone、YARN、Mesos和Kubernetes集群上。Standalone集群需要配置JobManager和TaskManager的节点,然后通过Flink提供的脚本启动。YARN、Mesos和Kubernetes集群提供了更强大的资源管理和集群扩展能力。
- Cloud模式:Flink还可以部署在各大云平台上,如AWS、谷歌云和阿里云,使用户能够在云环境中灵活地部署和运行作业。
-
运行时层:
- 运行时层是Flink的核心组件,支持分布式执行和处理。该层负责将用户提交的作业转化为任务,并分发到相应的JobManager和TaskManager上执行。运行时层还涵盖了检查点和故障恢复机制,确保作业的容错性和稳定性。
-
API层:
- Flink的API层提供了DataStream API和DataSet API,分别用于流式处理和批处理。这两个API允许开发者使用各种操作符和转换来处理数据,包括转换、连接、聚合、窗口等计算任务。
-
上层工具:
- 在API层之上,Flink提供了一些工具来扩展其功能:
- 复杂事件处理(CEP):面向流处理的库,用于检测和处理复杂的事件模式。
- 图计算库(Gelly):面向批处理的图计算库,用于执行图算法。
- Table API和SQL:针对SQL用户和关系型数据处理场景的接口,允许使用SQL语法和表操作处理流和批数据。
- PyFlink:针对Python用户的接口,使其能够使用Flink进行数据处理,目前主要基于Table API。
- 在API层之上,Flink提供了一些工具来扩展其功能:
综上所述,Flink在不同层次上提供了丰富的组件和工具,支持流式处理和批处理,以及与不同环境(本地、集群、云)的无缝集成,使开发者能够灵活地构建和部署大规模数据处理应用程序。
作业执行阶段

在Apache Flink中,数据流作业的执行过程可以划分为多个阶段,从逻辑视图到物理执行图的转换。这个过程包括从StreamGraph到JobGraph,再到ExecutionGraph,最终映射到实际的物理执行图。下面详细说明这个过程:
-
StreamGraph(逻辑视图):StreamGraph是用户编写的流处理应用程序的逻辑表示。它包含了数据流的转换操作、算子之间的关系、事件时间处理策略、容错配置等。StreamGraph是用户定义的数据流拓扑,是一种高级抽象,用户可以通过DataStream API构建StreamGraph。
-
JobGraph(作业图):JobGraph是从StreamGraph派生而来的,表示一个具体的作业执行计划。在JobGraph中,StreamGraph中的逻辑算子被映射为具体的物理算子,且有明确的执行顺序和任务间的依赖关系。JobGraph还包含了资源配置、任务并行度、优化选项等信息。JobGraph是从逻辑视图转向物理执行的关键步骤。
-
ExecutionGraph(执行图):ExecutionGraph是JobGraph的执行时表示,它是实际执行计划的核心。在ExecutionGraph中,JobGraph中的每个任务都会被映射到一个具体的执行任务,每个任务可以包含一个或多个子任务,这些子任务被映射到不同的TaskManager上。ExecutionGraph还负责维护作业的执行状态,以及任务之间的调度和通信。
-
物理执行图:ExecutionGraph被映射到实际的物理执行图,即在TaskManager集群上真正执行的任务拓扑。物理执行图包括了任务的并行执行、数据交换、任务状态管理等细节,它是作业在分布式环境中实际运行的体现。
总结起来,StreamGraph到JobGraph到ExecutionGraph的转换是Flink作业执行计划的关键步骤。从逻辑视图到物理执行图的转换过程考虑了作业的拓扑结构、资源分配、任务调度等方面的问题,确保了作业可以在分布式环境中高效执行。这一系列转换过程使得用户可以通过高层次的抽象来描述作业逻辑,而Flink框架会负责将其转化为可执行的任务图,实现数据流的处理和计算。
5. Flink 开发
Flink 应用程序结构主要包含三部分,Source/Transformation/Sink,如下图所示:

Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:
- 基于本地集合的 source
- 基于文件的 source
- 基于网络套接字的 source
- 自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:
- 写入文件
- 打印输出
- 写入 socket
- 自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 Sink。
开发环境搭建
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lagou</groupId>
<artifactId>flinkdemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--flink核心包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.2</version>
</dependency>
<!--flink流处理包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.7.2</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.12</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>1.7.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>

Flink连接器
在实际生产环境中,数据通常分布在各种不同的系统中,包括文件系统、数据库、消息队列等。Flink作为一个大数据处理框架,需要与这些外部系统进行数据交互,以实现数据的输入、处理和输出。在Flink中,Source和Sink是两个关键模块,它们扮演着与外部系统进行数据连接和交互的重要角色,被统称为外部连接器(Connector)。
-
Source(数据源):Source是Flink作业的输入模块,用于从外部系统中读取数据并将其转化为Flink的数据流。Source负责实现与不同数据源的交互逻辑,将外部数据源的数据逐条或批量读取到Flink的数据流中,以便后续的数据处理。常见的Source包括从文件中读取数据、从消息队列(如Kafka、RabbitMQ)中消费数据、从数据库中读取数据等。
-
Sink(数据接收器):Sink是Flink作业的输出模块,用于将Flink计算的结果输出到外部系统中。Sink负责实现将Flink数据流中的数据写入到外部数据源,以便后续的持久化存储、展示或其他处理。Sink的实现需要考虑数据的可靠性、一致性以及可能的事务性要求。常见的Sink包括将数据写入文件、将数据写入数据库、将数据写入消息队列等。
外部连接器在Flink中的作用非常关键,它们使得Flink作业可以与各种不同类型的数据源和数据目的地进行交互,实现了数据的流入和流出。这种灵活的连接机制使得Flink在处理大数据时能够更好地集成已有的系统和数据,实现复杂的数据流处理和分析任务。
Source
Flink在批处理中常见的source主要有两大类。
- 基于本地集合的source(Collection-based-source)
- 基于文件的source(File-based-source)
基于本地集合的Source
在Flink中最常见的创建本地集合的DataSet方式有三种。
- 使用env.fromElements(),这种方式也支持Tuple,自定义对象等复合形式。
- 使用env.fromCollection(),这种方式支持多种Collection的具体类型。
- 使用env.generateSequence(),这种方法创建基于Sequence的DataSet。
使用方式如下:
package com.demo.broad;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.DataSet;
import java.util.ArrayList;
import java.util.List;
import java.util.ArrayDeque;
import java.util.Stack;
import java.util.stream.Stream;
public class BatchFromCollection {
public static void main(String[] args) throws Exception {
// 获取flink执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 0.用element创建DataSet(fromElements)
DataSet<String> ds0 = env.fromElements("spark", "flink");
ds0.print();
// 1.用Tuple创建DataSet(fromElements)
DataSet<Tuple2<Integer, String>> ds1 = env.fromElements(
new Tuple2<>(1, "spark"),
new Tuple2<>(2, "flink")
);
ds1.print();
// 2.用Array创建DataSet
DataSet<String> ds2 = env.fromCollection(new ArrayList<String>() {{
add("spark");
add("flink");
}});
ds2.print();
// 3.用ArrayDeque创建DataSet
DataSet<String> ds3 = env.fromCollection(new ArrayDeque<String>() {{
add("spark");
add("flink");
}});
ds3.print();
// 4.用List创建DataSet
DataSet<String> ds4 = env.fromCollection(new ArrayList<String>() {{
add("spark");
add("flink");
}});
ds4.print();
// 5.用ArrayList创建DataSet
DataSet<String> ds5 = env.fromCollection(new ArrayList<String>() {{
add("spark");
add("flink");
}});
ds5.print();
// 6.用List创建DataSet
DataSet<String> ds6 = env.fromCollection(new ArrayList<String>() {{
add("spark");
add("flink");
}});
ds6.print();
// 7.用List创建DataSet
DataSet<String> ds7 = env.fromCollection(new ArrayList<String>() {{
add("spark");
add("flink");
}});
ds7.print();
// 8.用Stack创建DataSet
DataSet<String> ds8 = env.fromCollection(new Stack<String>() {{
add("spark");
add("flink");
}});
ds8.print();
// 9.用Stream创建DataSet(Stream相当于lazy List,避免在中间过程中生成不必要的集合)
DataSet<String> ds9 = env.fromCollection(Stream.of("spark", "flink"));
ds9.print();
// 10.用List创建DataSet
DataSet<String> ds10 = env.fromCollection(new ArrayList<String>() {{
add("spark");
add("flink");
}});
ds10.print();
// 11.用HashSet创建DataSet
DataSet<String> ds11 = env.fromCollection(new HashSet<String>() {{
add("spark");
add("flink");
}});
ds11.print();
// 12.用Iterable创建DataSet
DataSet<String> ds12 = env.fromCollection(new ArrayList<String>() {{
add("spark");
add("flink");
}});
ds12.print();
// 13.用ArrayList创建DataSet
DataSet<String> ds13 = env.fromCollection(new ArrayList<String>() {{
add("spark");
add("flink");
}});
ds13.print();
// 14.用Stack创建DataSet
DataSet<String> ds14 = env.fromCollection(new Stack<String>() {{
add("spark");
add("flink");
}});
ds14.print();
// 15.用HashMap创建DataSet
DataSet<Tuple2<Integer, String>> ds15 = env.fromCollection(new HashMap<Integer, String>() {{
put(1, "spark");
put(2, "flink");
}}.entrySet());
ds15.print();
// 16.用Range创建DataSet
DataSet<Integer> ds16 = env.fromCollection(IntStream.rangeClosed(1, 8).boxed().collect(Collectors.toList()));
ds16.print();
// 17.用generateSequence创建DataSet
DataSet<Long> ds17 = env.generateSequence(1, 9);
ds17.print();
}
}
基于文件的Source
Flink支持直接从外部文件存储系统中读取文件的方式来创建Source数据源,Flink支持的方式有以下几种:
- 读取本地文件数据
- 读取HDFS文件数据
- 读取CSV文件数据
- 读取压缩文件
- 遍历目录
下面分别介绍每个数据源的加载方式:
读取本地文件
package com.demo.batch;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
public class BatchFromFile {
public static void main(String[] args) throws Exception {
// 使用readTextFile读取本地文件
// 初始化环境
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
// 加载数据
DataSet<String> datas = environment.readTextFile("data.txt");
// 触发程序执行
datas.print();
}
}
读取HDFS文件数据
package com.demo.batch;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
public class BatchFromFile {
public static void main(String[] args) throws Exception {
// 使用readTextFile读取本地文件
// 初始化环境
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
// 加载数据
DataSet<String> datas = environment.readTextFile("hdfs://node01:8020/README.txt");
// 触发程序执行
datas.print();
}
}
读取CSV文件数据
package com.demo.batch;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.common.functions.MapFunction;
public class BatchFromCsvFile {
public static void main(String[] args) throws Exception {
// 初始化环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 用于映射CSV文件的POJO class
public static class Student {
public int id;
public String name;
public Student() {}
public Student(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Student(" + id + ", " + name + ")";
}
}
// 读取CSV文件
DataSet<Student> csvDataSet = env.readCsvFile("./data/input/student.csv")
.ignoreFirstLine()
.pojoType(Student.class, "id", "name");
csvDataSet.print();
}
}
读取压缩文件
对于以下压缩类型,不需要指定任何额外的inputformat方法,flink可以自动识别并且解压。但是,压缩文件可能不会并行读取,可能是顺序读取的,这样可能会影响作业的可伸缩性。
| 压缩格式 | 扩展名 | 并行化 |
|---|---|---|
| DEFLATE | .deflate | no |
| GZIP | .gz .gzip | no |
| Bzip2 | .bz2 | no |
| XZ | .xz | no |
package com.demo.batch;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
public class BatchFromCompressFile {
public static void main(String[] args) throws Exception {
// 初始化环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 加载数据
DataSet<String> result = env.readTextFile("D:\\BaiduNetdiskDownload\\hbase-1.3.1-bin.tar.gz");
// 触发程序执行
result.print();
}
}
遍历目录
flink支持对一个文件目录内的所有文件,包括所有子目录中的所有文件的遍历访问方式。
对于从文件中读取数据,当读取数个文件夹的时候,嵌套的文件默认是不会被读取的,只会读取第一个文件,其他的都会被忽略。所以我们需要使用recursive.file.enumeration进行递归读取
package com.demo.batch;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
public class BatchFromCompressFile {
public static void main(String[] args) throws Exception {
// 初始化环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 加载数据
DataSet<String> result = env.readTextFile("D:\\BaiduNetdiskDownload\\hbase-1.3.1-bin.tar.gz");
// 触发程序执行
result.print();
}
}
读取kafka
public class StreamFromKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","teacher2:9092");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>("mytopic2", new SimpleStringSchema(), properties);
DataStreamSource<String> data = env.addSource(consumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = data.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word : s.split(" ")) {
collector.collect(Tuple2.of(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne.keyBy(0).sum(1);
result.print();
env.execute();
}
}
自定义source
private static class SimpleSource
implements SourceFunction<Tuple2<String, Integer>> {
private int offset = 0;
private boolean isRunning = true;
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
while (isRunning) {
Thread.sleep(500);
ctx.collect(new Tuple2<>("" + offset, offset));
offset++;
if (offset == 1000) {
isRunning = false;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
}
自定义Source,从0开始计数,将数字发送到下游在主逻辑中调用这个Source。
DataStream<Tuple2<String, Integer>> countStream = env.addSource(new SimpleSource());
Sink
flink在批处理中常见的sink
- 基于本地集合的sink(Collection-based-sink)
- 基于文件的sink(File-based-sink)
基于本地集合的sink
目标:
基于下列数据,分别进行打印输出,error输出,collect()
(19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8)
代码:
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class BatchSinkCollection {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
List<Tuple3<Integer, String, Double>> stuData = new ArrayList<>();
stuData.add(new Tuple3<>(19, "zhangsan", 178.8));
stuData.add(new Tuple3<>(17, "lisi", 168.8));
stuData.add(new Tuple3<>(18, "wangwu", 184.8));
stuData.add(new Tuple3<>(21, "zhaoliu", 164.8));
DataSet<Tuple3<Integer, String, Double>> stu = env.fromCollection(stuData);
stu.print();
stu.printToErr();
stu.collect().forEach(System.out::println);
env.execute();
}
}
基于文件的sink
- flink支持多种存储设备上的文件,包括本地文件,hdfs文件等。
- flink支持多种文件的存储格式,包括text文件,CSV文件等。
- writeAsText():TextOuputFormat - 将元素作为字符串写入行。字符串是通过调用每个元素的toString()方法获得的。
将数据写入本地文件
目标:
基于下列数据,写入到文件中
Map(1 -> "spark", 2 -> "flink")
代码:
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.Path;
import org.apache.flink.core.io.SimpleVersionedSerializer;
import java.util.HashMap;
import java.util.Map;
public class BatchSinkFile {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
Map<Integer, String> data1 = new HashMap<>();
data1.put(1, "spark");
data1.put(2, "flink");
DataSet<Map<Integer, String>> ds1 = env.fromElements(data1);
ds1.setParallelism(1)
.writeAsText("test/data1/aa", FileSystem.WriteMode.OVERWRITE)
.setParallelism(1);
env.execute();
}
}
将数据写入HDFS
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.core.fs.Path;
import org.apache.flink.core.io.SimpleVersionedSerializer;
import java.util.HashMap;
import java.util.Map;
public class BatchSinkFile {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
Map<Integer, String> data1 = new HashMap<>();
data1.put(1, "spark");
data1.put(2, "flink");
DataSet<Map<Integer, String>> ds1 = env.fromElements(data1);
ds1.setParallelism(1)
.writeAsText("hdfs://bigdata1:9000/a", FileSystem.WriteMode.OVERWRITE)
.setParallelism(1);
env.execute();
}
}
Flink API
Flink的API层提供了DataStream API和DataSet API,分别用于流式处理和批处理。这两个API允许开发者使用各种操作符和转换来处理数据,包括转换、连接、聚合、窗口等计算任务。
在Flink中,根据不同的场景(流处理或批处理),需要设置不同的执行环境。在批处理场景下,需要使用DataSet API,并设置批处理执行环境。在流处理场景下,需要使用DataStream API,并设置流处理执行环境。
以下是在不同场景下设置执行环境的示例代码,分别展示了批处理和流处理的情况,包括Scala和Java语言。

批处理场景 - 设置DataSet API的批处理执行环境(Java):
import org.apache.flink.api.java.ExecutionEnvironment;
public class BatchJobExample {
public static void main(String[] args) throws Exception {
// 创建批处理执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 在这里添加批处理作业的代码逻辑
// ...
// 执行作业
env.execute("Batch Job Example");
}
}
流处理场景 - 设置DataStream API的流处理执行环境(Java):
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class StreamJobExample {
public static void main(String[] args) throws Exception {
// 创建流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 在这里添加流处理作业的代码逻辑
// ...
// 执行作业
env.execute("Stream Job Example");
}
}
批处理场景 - 设置DataSet API的批处理执行环境(Scala):
import org.apache.flink.api.scala._
object BatchJobExample {
def main(args: Array[String]): Unit = {
// 创建批处理执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 在这里添加批处理作业的代码逻辑
// ...
// 执行作业
env.execute("Batch Job Example")
}
}
流处理场景 - 设置DataStream API的流处理执行环境(Scala):
import org.apache.flink.streaming.api.scala._
object StreamJobExample {
def main(args: Array[String]): Unit = {
// 创建流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 在这里添加流处理作业的代码逻辑
// ...
// 执行作业
env.execute("Stream Job Example")
}
}
根据以上示例代码,可以在不同的场景下选择合适的执行环境和API来构建和执行Flink作业。注意在导入包时,确保使用正确的包名和类名,以适应批处理或流处理的环境。
以下是一些常用的API函数和操作,以表格形式提供:
| API 类型 | 常用函数和操作 | 描述 |
|---|---|---|
| DataStream API | map, flatMap |
对数据流中的每个元素进行映射或扁平化操作。 |
filter |
过滤出满足条件的元素。 | |
keyBy |
按指定的字段或键对数据流进行分区。 | |
window |
将数据流按照时间窗口或计数窗口划分。 | |
reduce, fold |
在窗口内对元素进行聚合操作。 | |
union |
合并多个数据流。 | |
connect, coMap, coFlatMap |
连接两个不同类型的数据流并应用相应的函数。 | |
timeWindow, countWindow |
定义时间窗口或计数窗口。 | |
process |
自定义处理函数,实现更复杂的流处理逻辑。 | |
| DataSet API | map, flatMap |
对数据集中的每个元素进行映射或扁平化操作。 |
filter |
过滤出满足条件的元素。 | |
groupBy |
按指定的字段或键对数据集进行分组。 | |
reduce, fold |
对分组后的数据集进行聚合操作。 | |
join, coGroup |
对两个数据集进行内连接或外连接操作。 | |
cross, cartesian |
对两个数据集进行笛卡尔积操作。 | |
distinct |
去除数据集中的重复元素。 | |
groupBy, aggregate |
分组并对分组后的数据集进行聚合操作。 | |
first, min, max |
获取数据集中的第一个、最小或最大元素。 | |
sum, avg |
计算数据集中元素的和或平均值。 | |
collect |
将数据集中的元素收集到本地的集合中。 |
这些API函数和操作涵盖了Flink中流处理和批处理的常见操作,可以帮助用户实现各种复杂的数据处理和分析任务。根据实际需求,可以选择适合的API函数和操作来构建Flink作业。
下面是一些参见的API的说明:
map
将DataSet中的每一个元素转换为另外一个元素
示例
使用map操作,将以下数据
"1,张三", "2,李四", "3,王五", "4,赵六"
转换为一个scala的样例类。
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 创建一个
User样例类 - 使用
map操作执行转换 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.common.functions.MapFunction;
public class User {
public String id;
public String name;
public User() {}
public User(String id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "User(" + id + ", " + name + ")";
}
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> textDataSet = env.fromCollection(
Arrays.asList("1,张三", "2,李四", "3,王五", "4,赵六")
);
DataSet<User> userDataSet = textDataSet.map(new MapFunction<String, User>() {
@Override
public User map(String text) throws Exception {
String[] fieldArr = text.split(",");
return new User(fieldArr[0], fieldArr[1]);
}
});
userDataSet.print();
}
}
flatMap
将DataSet中的每一个元素转换为0…n个元素
示例
分别将以下数据,转换成国家、省份、城市三个维度的数据。
将以下数据
张三,中国,江西省,南昌市
李四,中国,河北省,石家庄市
Tom,America,NewYork,Manhattan
转换为
(张三,中国)
(张三,中国,江西省)
(张三,中国,江西省,江西省)
(李四,中国)
(李四,中国,河北省)
(李四,中国,河北省,河北省)
(Tom,America)
(Tom,America,NewYork)
(Tom,America,NewYork,NewYork)
思路
-
以上数据为一条转换为三条,显然,应当使用
flatMap来实现 -
分别在
flatMap函数中构建三个数据,并放入到一个列表中姓名, 国家
姓名, 国家省份
姓名, 国家省份城市
步骤
- 构建批处理运行环境
- 构建本地集合数据源
- 使用
flatMap将一条数据转换为三条数据- 使用逗号分隔字段
- 分别构建国家、国家省份、国家省份城市三个元组
- 打印输出
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class UserProcessing {
public static class User {
public String name;
public String country;
public String province;
public String city;
public User() {}
public User(String name, String country, String province, String city) {
this.name = name;
this.country = country;
this.province = province;
this.city = city;
}
@Override
public String toString() {
return "User(" + name + ", " + country + ", " + province + ", " + city + ")";
}
}
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> userDataSet = env.fromCollection(new ArrayList<String>() {{
add("张三,中国,江西省,南昌市");
add("李四,中国,河北省,石家庄市");
add("Tom,America,NewYork,Manhattan");
}});
DataSet<User> resultDataSet = userDataSet.flatMap(new FlatMapFunction<String, User>() {
@Override
public void flatMap(String text, Collector<User> collector) throws Exception {
String[] fieldArr = text.split(",");
String name = fieldArr[0];
String country = fieldArr[1];
String province = fieldArr[2];
String city = fieldArr[3];
collector.collect(new User(name, country, province, city));
collector.collect(new User(name, country, province + city, ""));
collector.collect(new User(name, country, province + city, city));
}
});
resultDataSet.print();
}
}
mapPartition
将一个分区中的元素转换为另一个元素
示例
使用mapPartition操作,将以下数据
"1,张三", "2,李四", "3,王五", "4,赵六"
转换为一个scala的样例类。
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 创建一个
User样例类 - 使用
mapPartition操作执行转换 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.common.functions.MapPartitionFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class MapPartitionExample {
public static class User {
public String id;
public String name;
public User() {}
public User(String id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "User(" + id + ", " + name + ")";
}
}
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> userDataSet = env.fromCollection(new ArrayList<String>() {{
add("1,张三");
add("2,李四");
add("3,王五");
add("4,赵六");
}});
DataSet<User> resultDataSet = userDataSet.mapPartition(new MapPartitionFunction<String, User>() {
@Override
public void mapPartition(Iterable<String> iterable, Collector<User> collector) throws Exception {
// TODO: 打开连接
Iterator<String> iterator = iterable.iterator();
while (iterator.hasNext()) {
String ele = iterator.next();
String[] fieldArr = ele.split(",");
collector.collect(new User(fieldArr[0], fieldArr[1]));
}
// TODO: 关闭连接
}
});
resultDataSet.print();
}
}
map和mapPartition的效果是一样的,但如果在map的函数中,需要访问一些外部存储。例如:
访问mysql数据库,需要打开连接, 此时效率较低。而使用mapPartition可以有效减少连接数,提高效率
filter
过滤出来一些符合条件的元素
示例:
过滤出来以下以h开头的单词。
"hadoop", "hive", "spark", "flink"
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
filter操作执行过滤 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import java.util.ArrayList;
import java.util.List;
public class FilterExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> wordDataSet = env.fromCollection(new ArrayList<String>() {{
add("hadoop");
add("hive");
add("spark");
add("flink");
}});
DataSet<String> resultDataSet = wordDataSet.filter(word -> word.startsWith("h"));
resultDataSet.print();
}
}
reduce
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素
示例1
请将以下元组数据,使用reduce操作聚合成一个最终结果
("java" , 1) , ("java", 1) ,("java" , 1)
将上传元素数据转换为("java",3)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
redice执行聚合操作 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;
import java.util.ArrayList;
import java.util.List;
public class ReduceExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> wordCountDataSet = env.fromCollection(new ArrayList<Tuple2<String, Integer>>() {{
add(new Tuple2<>("java", 1));
add(new Tuple2<>("java", 1));
add(new Tuple2<>("java", 1));
}});
DataSet<Tuple2<String, Integer>> resultDataSet = wordCountDataSet.reduce((wc1, wc2) ->
new Tuple2<>(wc2.f0, wc1.f1 + wc2.f1)
);
resultDataSet.print();
}
}
示例2
请将以下元组数据,下按照单词使用groupBy进行分组,再使用reduce操作聚合成一个最终结果
("java" , 1) , ("java", 1) ,("scala" , 1)
转换为
("java", 2), ("scala", 1)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
groupBy按照单词进行分组 - 使用
reduce对每个分组进行统计 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple;
import java.util.ArrayList;
import java.util.List;
public class GroupByReduceExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> wordCountDataSet = env.fromCollection(new ArrayList<Tuple2<String, Integer>>() {{
add(new Tuple2<>("java", 1));
add(new Tuple2<>("java", 1));
add(new Tuple2<>("scala", 1));
}});
DataSet<Tuple2<String, Integer>> groupedDataSet = wordCountDataSet.groupBy(0).reduce((wc1, wc2) ->
new Tuple2<>(wc1.f0, wc1.f1 + wc2.f1)
);
groupedDataSet.print();
}
}
reduceGroup
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素
reduce和reduceGroup的区别

- reduce是将数据一个个拉取到另外一个节点,然后再执行计算
- reduceGroup是先在每个group所在的节点上执行计算,然后再拉取
示例
请将以下元组数据,下按照单词使用groupBy进行分组,再使用reduceGroup操作进行单词计数
("java" , 1) , ("java", 1) ,("scala" , 1)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
groupBy按照单词进行分组 - 使用
reduceGroup对每个分组进行统计 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class GroupByReduceGroupExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataSet<Tuple2<String, Integer>> wordCountDataSet = env.fromCollection(new ArrayList<Tuple2<String, Integer>>() {{
add(new Tuple2<>("java", 1));
add(new Tuple2<>("java", 1));
add(new Tuple2<>("scala", 1));
}});
DataSet<Tuple2<String, Integer>> groupedDataSet = wordCountDataSet.groupBy(0).reduceGroup((Iterable<Tuple2<String, Integer>> iter, Collector<Tuple2<String, Integer>> collector) -> {
Tuple2<String, Integer> result = new Tuple2<>();
for (Tuple2<String, Integer> wc : iter) {
result.f0 = wc.f0;
result.f1 += wc.f1;
}
collector.collect(result);
});
groupedDataSet.print();
}
}
aggregate
按照内置的方式来进行聚合, Aggregate只能作用于元组上。例如:SUM/MIN/MAX…
示例
请将以下元组数据,使用aggregate操作进行单词统计
("java" , 1) , ("java", 1) ,("scala" , 1)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
groupBy按照单词进行分组 - 使用
aggregate对每个分组进行SUM统计 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.aggregation.Aggregations;
import org.apache.flink.api.java.tuple.Tuple2;
import java.util.ArrayList;
import java.util.List;
public class GroupByAggregateExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> wordCountDataSet = env.fromCollection(new ArrayList<Tuple2<String, Integer>>() {{
add(new Tuple2<>("java", 1));
add(new Tuple2<>("java", 1));
add(new Tuple2<>("scala", 1));
}});
DataSet<Tuple2<String, Integer>> groupedDataSet = wordCountDataSet.groupBy(0);
DataSet<Tuple2<String, Integer>> resultDataSet = groupedDataSet.aggregate(Aggregations.SUM, 1);
resultDataSet.print();
}
}
注意
要使用aggregate,只能使用字段索引名或索引名称来进行分组
groupBy(0),否则会报一下错误:Exception in thread "main" java.lang.UnsupportedOperationException: Aggregate does not support grouping with KeySelector functions, yet.
distinct
去除重复的数据
示例
请将以下元组数据,使用distinct操作去除重复的单词
("java" , 1) , ("java", 2) ,("scala" , 1)
去重得到
("java", 1), ("scala", 1)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
distinct指定按照哪个字段来进行去重 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;
import java.util.ArrayList;
import java.util.List;
public class DistinctExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> wordCountDataSet = env.fromCollection(new ArrayList<Tuple2<String, Integer>>() {{
add(new Tuple2<>("java", 1));
add(new Tuple2<>("java", 1));
add(new Tuple2<>("scala", 1));
}});
DataSet<Tuple2<String, Integer>> resultDataSet = wordCountDataSet.distinct(0);
resultDataSet.print();
}
}
join
使用join可以将两个DataSet连接起来
示例:
有两个csv文件,有一个为score.csv,一个为subject.csv,分别保存了成绩数据以及学科数据。

需要将这两个数据连接到一起,然后打印出来。

步骤
-
分别将两个文件复制到项目中的
data/join/input中 -
构建批处理环境
-
创建两个样例类
* 学科Subject(学科ID、学科名字) * 成绩Score(唯一ID、学生姓名、学科ID、分数——Double类型) -
分别使用
readCsvFile加载csv数据源,并制定泛型 -
使用join连接两个DataSet,并使用
where、equalTo方法设置关联条件 -
打印关联后的数据源
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple4;
public class JoinExample {
public static class Score {
public int id;
public String name;
public int subjectId;
public double score;
public Score() {}
public Score(int id, String name, int subjectId, double score) {
this.id = id;
this.name = name;
this.subjectId = subjectId;
this.score = score;
}
@Override
public String toString() {
return "Score(" + id + ", " + name + ", " + subjectId + ", " + score + ")";
}
}
public static class Subject {
public int id;
public String name;
public Subject() {}
public Subject(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Subject(" + id + ", " + name + ")";
}
}
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Score> scoreDataSet = env.readCsvFile("./data/join/input/score.csv")
.ignoreFirstLine()
.pojoType(Score.class);
DataSet<Subject> subjectDataSet = env.readCsvFile("./data/join/input/subject.csv")
.ignoreFirstLine()
.pojoType(Subject.class);
DataSet<Tuple4<Integer, String, Integer, Double>> joinedDataSet = scoreDataSet.join(subjectDataSet)
.where("subjectId")
.equalTo("id")
.projectFirst(0, 1, 2, 3)
.projectSecond(1);
joinedDataSet.print();
}
}
union

将两个DataSet取并集,不会去重。
示例
将以下数据进行取并集操作
数据集1
"hadoop", "hive", "flume"
数据集2
"hadoop", "hive", "spark"
步骤
- 构建批处理运行环境
- 使用
fromCollection创建两个数据源 - 使用
union将两个数据源关联在一起 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import java.util.ArrayList;
import java.util.List;
public class UnionExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> wordDataSet1 = env.fromCollection(new ArrayList<String>() {{
add("hadoop");
add("hive");
add("flume");
}});
DataSet<String> wordDataSet2 = env.fromCollection(new ArrayList<String>() {{
add("hadoop");
add("hive");
add("spark");
}});
DataSet<String> resultDataSet = wordDataSet1.union(wordDataSet2);
resultDataSet.print();
}
}
connect
connect()提供了和union()类似的功能,即连接两个数据流,它与union()的区别如下。
-
connect()只能连接两个数据流,union()可以连接多个数据流。
-
connect()所连接的两个数据流的数据类型可以不一致,union()所连接的两个或多个数据流的数据类型必须一致。
-
两个DataStream经过connect()之后被转化为ConnectedStreams, ConnectedStreams会对两个流的数据应用不同的处理方法,且两个流之间可以共享状态。

DataStream<Integer> intStream = senv.fromElements(2, 1, 5, 3, 4, 7);
DataStream<String> stringStream = senv.fromElements("A", "B", "C", "D");
ConnectedStreams<Integer, String> connectedStream =
intStream.connect(stringStream);
DataStream<String> mapResult = connectedStream.map(new MyCoMapFunction());
// CoMapFunction的3个泛型分别对应第一个流的输入类型、第二个流的输入类型,输出类型
public static class MyCoMapFunction implements CoMapFunction<Integer, String, String>
{
@Override
public String map1(Integer input1) {
return input1.toString();
}
@Override
public String map2(String input2) {
return input2;
}
}
rebalance
Flink也会产生数据倾斜的时候,例如:当前的数据量有10亿条,在处理过程就有可能发生如下状况:

rebalance会使用轮询的方式将数据均匀打散,这是处理数据倾斜最好的选择。

步骤
-
构建批处理运行环境
-
使用
env.generateSequence创建0-100的并行数据 -
使用
fiter过滤出来大于8的数字 -
使用map操作传入
RichMapFunction,将当前子任务的ID和数字构建成一个元组在RichMapFunction中可以使用`getRuntimeContext.getIndexOfThisSubtask`获取子任务序号 -
打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
public class MapWithSubtaskIndexExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Long> numDataSet = env.generateSequence(0, 100);
DataSet<Long> filterDataSet = numDataSet.filter(num -> num > 8);
DataSet<Tuple2<Long, Long>> resultDataSet = filterDataSet.map(new RichMapFunction<Long, Tuple2<Long, Long>>() {
@Override
public Tuple2<Long, Long> map(Long in) throws Exception {
return new Tuple2<>(getRuntimeContext().getIndexOfThisSubtask(), in);
}
});
resultDataSet.print();
}
}
上述代码没有加rebalance,通过观察,有可能会出现数据倾斜。
在filter计算完后,调用rebalance,这样,就会均匀地将数据分布到每一个分区中。
hashPartition
按照指定的key进行hash分区
示例
基于以下列表数据来创建数据源,并按照hashPartition进行分区,然后输出到文件。
List(1,1,1,1,1,1,1,2,2,2,2,2)
步骤
- 构建批处理运行环境
- 设置并行度为
2 - 使用
fromCollection构建测试数据集 - 使用
partitionByHash按照字符串的hash进行分区 - 调用
writeAsText写入文件到data/partition_output目录中 - 打印测试
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.core.fs.FileSystem;
import java.util.ArrayList;
import java.util.List;
public class PartitionByHashExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Set parallelism to 2
env.setParallelism(2);
DataSet<Integer> numDataSet = env.fromCollection(new ArrayList<Integer>() {{
add(1);
add(1);
add(1);
add(1);
add(1);
add(1);
add(1);
add(2);
add(2);
add(2);
add(2);
add(2);
}});
DataSet<Integer> partitionDataSet = numDataSet.partitionByHash(num -> num.toString());
partitionDataSet.writeAsText("./data/partition_output", FileSystem.WriteMode.OVERWRITE);
partitionDataSet.print();
env.execute();
}
}
sortPartition
指定字段对分区中的数据进行排序
示例
按照以下列表来创建数据集
List("hadoop", "hadoop", "hadoop", "hive", "hive", "spark", "spark", "flink")
对分区进行排序后,输出到文件。
步骤
- 构建批处理运行环境
- 使用
fromCollection构建测试数据集 - 设置数据集的并行度为
2 - 使用
sortPartition按照字符串进行降序排序 - 调用
writeAsText写入文件到data/sort_output目录中 - 启动执行
参考代码
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.core.fs.FileSystem;
import java.util.ArrayList;
import java.util.List;
public class SortPartitionExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> wordDataSet = env.fromCollection(new ArrayList<String>() {{
add("hadoop");
add("hadoop");
add("hadoop");
add("hive");
add("hive");
add("spark");
add("spark");
add("flink");
}});
wordDataSet.setParallelism(2);
DataSet<String> sortedDataSet = wordDataSet.sortPartition(str -> str, Order.DESCENDING);
sortedDataSet.writeAsText("./data/sort_output/", FileSystem.WriteMode.OVERWRITE);
env.execute("App");
}
}
窗口
在许多情况下,我们需要解决这样的问题:针对一个特定的时间段,例如一个小时,我们需要对数据进行统计和分析。但是,要实现这种数据窗口操作,首先需要确定哪些数据应该进入这个窗口。在深入了解窗口操作的定义之前,我们必须先确定作业将使用哪种时间语义。
换句话说,时间窗口是数据处理中的一个关键概念,用于将数据划分为特定的时间段进行计算。然而,在确定如何定义这些窗口之前,我们必须选择适合的时间语义,即事件时间、处理时间或摄入时间。不同的时间语义在数据处理中具有不同的含义和用途,因此在选择时间窗口之前,我们需要明确作业所需的时间语义,以便正确地界定和处理数据窗口。
时间概念
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
窗口程序
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
滚动窗口
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
滑动窗口
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
会话窗口
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
基于数量窗口
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
触发器
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
清除器
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
6. Flink程序本地执行和集群执行
6.1. 本地执行
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
6.2. 集群执行
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
7. Flink的广播变量
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
8. Flink的累加器
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
9. Flink的分布式缓存
.....
由于字数限制,此处省略
完整内容,请参见《大数据Flink学习圣经》,pdf 找尼恩取
关于TABLE API & SQL , 以及状态和检查点等知识 会陆续补充!敬请期待!
说在后面
本文是《大数据Flink学习圣经》 V1版本, 是 《尼恩 大数据 面试宝典》 姊妹篇。
这里特别说明一下:《尼恩 大数据 面试宝典》5个专题 PDF 自首次发布以来, 已经收集了 好几百题,大量的大厂面试干货、正货 。 《尼恩 大数据 面试宝典》面试题集合, 已经变成大数据学习和面试的必读书籍。
于是,尼恩架构团队趁热打铁,推出 《大数据Flink学习圣经》。
完整的pdf,可以关注尼恩的 公号【技术自由圈】取。
并且,《大数据Flink学习圣经》、 《尼恩 大数据 面试宝典》 都会持续迭代、不断更新,以 吸纳最新的面试题,最新版本,具体请参见 公号【技术自由圈】
作者介绍
一作:Andy,资深架构师, 《Java 高并发核心编程 加强版》作者之1 。
二作:尼恩,41岁资深老架构师, IT领域资深作家、著名博主。《Java 高并发核心编程 加强版 卷1、卷2、卷3》创世作者。 《K8S学习圣经》《Docker学习圣经》《Go学习圣经》等11个PDF 圣经的作者。 也是一个 资深架构导师、架构转化 导师, 成功指导了多个中级Java、高级Java转型架构师岗位, 最高的学员年薪拿到近100W。
参考
推荐阅读
《尼恩大数据面试宝典专题2:绝密100个Spark面试题,熟背100遍,猛拿高薪》
《尼恩大数据面试宝典专题3:史上最全Hive面试题,不断迭代,持续升级》
《尼恩大数据面试宝典专题4:史上最全Flink面试题,不断迭代,持续升级》
《尼恩大数据面试宝典专题5:史上最全HBase面试题,不断迭代,持续升级》
技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
免费获取11个技术圣经PDF:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号