京东太猛,手写hashmap又一次重现江湖
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
京东太猛,手写hashmap又一次重现江湖
说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如京东、极兔、有赞、希音、百度、网易的面试资格,遇到一个很重要的面试题:
手写一个hashmap?
尼恩读者反馈说,之前总是听人说,大厂喜欢手写hashmap、手写线程池,这次终于碰到了。
和线程池的知识一样,hashmap既是面试的核心知识,又是开发的核心知识。
手写线程池,之前已经通过博客、公众号的形式已经发布:
在这里,老架构尼恩再接再厉,和架构师唐欢一块,给大家做一下手写hashmap系统化、体系化的线程池梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典》V68版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请关注本公众号 【技术自由圈】获取,暗号:领电子书
手写极简版本的HashMap
如果对HashMap理解不深,可以手写一个极简版本的HashMap,不至于颗粒无收
尼恩给大家展示,两个极简版本的首先HashMap
- 一个GoLang手写HashMap极简版本
- 一个Java手写HashMap极简版本
一个GoLang手写HashMap极简版本
设计不能少,首先,尼恩给大家做点简单的设计:
如果确实不知道怎么写, 可以使用 Wrapper 装饰器模式,把Java或者Golang内置的 HashMap包装一下,然后可以交差了。
如果是使用Go语言实现的话,具体实现方式是通过Go语言内置的map来实现,其中key和value都是int类型。
以下是一个Go语言版本 简单的手写HashMap示例:
package main
import "fmt"
type HashMap struct {
data map[int]int
}
func NewHashMap() *HashMap {
return &HashMap{
data: make(map[int]int),
}
}
func (h *HashMap) Put(key, value int) {
h.data[key] = value
}
func (h *HashMap) Get(key int) int {
if val, ok := h.data[key]; ok {
return val
} else {
return -1
}
}
func main() {
m := NewHashMap()
m.Put(1, 10)
m.Put(2, 20)
fmt.Println(m.Get(1)) // Output: 10
fmt.Println(m.Get(3)) // Output: -1
}
这个HashMap实现了Put方法将key-value对存储在map中,Get方法从map中获取指定key的value值。
为啥要先说go语言版本, Go性能高、上手快,未来几年的Java开发,理论上应该是 Java、Go 并存模式, 所以,首先来一个go语言的版本。
当然,以上的版本,太low了。
这样偷工减料,一定会被嫌弃。 只是在面试的时候,可以和面试官提一嘴, 咱们对设计模式还是很娴熟滴。
既然是手写 手写HashMap ,那么就是要从0开始,自造轮子。接下来,来一个简单版本的Java手写HashMap示例。
一个Java手写HashMap极简版本
设计不能少,首先,尼恩给大家做点简单的设计:
- 数据模型设计:
设计一个Entry数组来存储每个key-value对,其中每个Entry又是一个链表结构,用于解决hash冲突问题。
- 访问方法设计:
设计Put方法将key-value对存储在map中,Get方法从map中获取指定key的value值。
以下是一个简单的Java手写HashMap示例:
public class MyHashMap<K, V> {
private Entry<K, V>[] buckets;
private static final int INITIAL_CAPACITY = 16;
public MyHashMap() {
this(INITIAL_CAPACITY);
}
@SuppressWarnings("unchecked")
public MyHashMap(int capacity) {
buckets = new Entry[capacity];
}
public void put(K key, V value) {
Entry<K, V> entry = new Entry<>(key, value);
int bucketIndex = getBucketIndex(key);
Entry<K, V> existingEntry = buckets[bucketIndex];
if (existingEntry == null) {
buckets[bucketIndex] = entry;
} else {
while (existingEntry.next != null) {
if (existingEntry.key.equals(key)) {
existingEntry.value = value;
return;
}
existingEntry = existingEntry.next;
}
if (existingEntry.key.equals(key)) {
existingEntry.value = value;
} else {
existingEntry.next = entry;
}
}
}
public V get(K key) {
int bucketIndex = getBucketIndex(key);
Entry<K, V> existingEntry = buckets[bucketIndex];
while (existingEntry != null) {
if (existingEntry.key.equals(key)) {
return existingEntry.value;
}
existingEntry = existingEntry.next;
}
return null;
}
private int getBucketIndex(K key) {
int hashCode = key.hashCode();
return Math.abs(hashCode) % buckets.length;
}
static class Entry<K, V> {
K key;
V value;
Entry<K, V> next;
public Entry(K key, V value) {
this.key = key;
this.value = value;
this.next = null;
}
}
}
咱们这个即为简单的版本,有两个特色:
- 解决hash碰撞,使用了 链地址法
- 将键转化为数组的索引的时候,使用 了 优化版本的 除留余数法
如果对这些基础知识不熟悉,可以看一下 尼恩给大家展示的基本原理。
哈希映射(哈希表)基本原理
为了一次存储便能得到所查记录,在记录的存储位置和它的关键字之间建立一个确定的对应关系H,已H(key)作为关键字为key的记录在表中的位置,这个对应关系H为哈希(Hash)函数, 按这个思路建立的表为哈希表。
哈希表也叫散列表。
从根本上来说,一个哈希表包含一个数组,通过特殊的关键码(也就是key)来访问数组中的元素。
哈希表的主要思想:
(1)存放Value的时候,通过一个哈希函数,通过关键码(key)进行哈希运算得到哈希值,然后得到映射的位置, 去寻找存放值的地方 ,
(2)读取Value的时候,也是通过同一个哈希函数,通过关键码(key)进行哈希运算得到哈希值,然后得到 映射的位置,从那个位置去读取。
哈希函数
哈希表的组成取决于哈希算法,也就是哈希函数的构成。
哈希函数计算过程会将键转化为数组的索引。
一个好的哈希函数至少具有两个特征:
(1)计算要足够快;
(2)最小化碰撞,即输出的哈希值尽可能不会重复。
那接下来我们就来看下几个常见的哈希函数:
直接定址法
- 取关键字或关键字的某个线性函数值为散列地址。
- 即 f(key) = key 或 f(key) = a*key + b,其中a和b为常数。
除留余数法
将整数散列最常用方法是除留余数法。除留余数法的算法实用得最多。
我们选择大小为m的数组,对于任意正整数k,计算k除以m的余数,即f(key)=k%m,f(key)<m。这个函数的计算非常容易(在Java中为k% M)并能够有效地将键散布在0到M-1的范围内。
数字分析法
- 当关键字的位数大于地址的位数,对关键字的各位分布进行分析,选出分布均匀的任意几位作为散列地址。
- 仅适用于所有关键字都已知的情况下,根据实际应用确定要选取的部分,尽量避免发生冲突。
平方取中法
- 先计算出关键字值的平方,然后取平方值中间几位作为散列地址。
- 随机分布的关键字,得到的散列地址也是随机分布的。
随机数法
- 选择一个随机函数,把关键字的随机函数值作为它的哈希值。
- 通常当关键字的长度不等时用这种方法。
每种数据类型都需要相应的散列函数.
例如,Interge的哈希函数就是直接获取它的值:
public static int hashCode(int value) {
return value;
}
对于字符串类型则是使用了s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]的算法:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
public static int hashCode(byte[] value) {
int h = 0;
for (byte v : value) {
h = 31 * h + (v & 0xff);
}
return h;
}
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}
double类型则是使用位运算的方式进行哈希计算:
public int hashCode() {
long bits = doubleToLongBits(value);
return (int)(bits ^ (bits >>> 32));
}
public static long doubleToLongBits(double value) {
long result = doubleToRawLongBits(value);
if ( ((result & DoubleConsts.EXP_BIT_MASK) == DoubleConsts.EXP_BIT_MASK)
&&
(result & DoubleConsts.SIGNIF_BIT_MASK) != 0L)
result = 0x7ff8000000000000L;
return result;
}
于是Java让所有数据类型都继承了超类Object类,并实现hashCode()方法。接下来我们看下Object.hashcode方法。Object类中的hashcode方法是一个native方法。
public native int hashCode();
hashCode 方法的实现依赖于jvm,不同的jvm有不同的实现,我们看下主流的hotspot虚拟机的实现。
hotspot 定hashCode方法在src/share/vm/prims/jvm.cpp中,源码如下:
JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle))
JVMWrapper("JVM_IHashCode");
return handle == NULL ? 0 : ObjectSynchronizer::FastHashCode (THREAD, JNIHandles::resolve_non_null(handle)) ;
JVM_END
接下来我们看下ObjectSynchronizer::FastHashCode 方法是如何返回hashcode的,ObjectSynchronizer::FastHashCode 在synchronized.hpp文件中,
intptr_t ObjectSynchronizer::identity_hash_value_for(Handle obj) {
return FastHashCode (Thread::current(), obj()) ;
}
intptr_t ObjectSynchronizer::FastHashCode (Thread * Self, oop obj) {
if (UseBiasedLocking) {
if (obj->mark()->has_bias_pattern()) {
// Box and unbox the raw reference just in case we cause a STW safepoint.
Handle hobj (Self, obj) ;
// Relaxing assertion for bug 6320749.
assert (Universe::verify_in_progress() ||
!SafepointSynchronize::is_at_safepoint(),
"biases should not be seen by VM thread here");
BiasedLocking::revoke_and_rebias(hobj, false, JavaThread::current());
obj = hobj() ;
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
}
ObjectMonitor* monitor = NULL;
markOop temp, test;
intptr_t hash;
// 获取调用hashCode() 方法的对象的对象头中的mark word
markOop mark = ReadStableMark (obj);
// object should remain ineligible for biased locking
assert (!mark->has_bias_pattern(), "invariant") ;
if (mark->is_neutral()) { //普通对象
hash = mark->hash(); // this is a normal header
//如果mark word 中已经保存哈希值,那么就直接返回该哈希值
if (hash) { // if it has hash, just return it
return hash;
}
// 如果mark word 中还不存在哈希值,那就调用get_next_hash(Self, obj)方法计算该对象的哈希值
hash = get_next_hash(Self, obj); // allocate a new hash code
// 将计算的哈希值CAS保存到对象头的mark word中对应的bit位,成功则返回,失败的话可能有几下几种情形:
//(1)、其他线程也在install the hash并且先于当前线程成功,进入下一轮while获取哈希即可
//(2)、有可能当前对象作为监视器升级成了轻量级锁或重量级锁,进入下一轮while走其他case;
temp = mark->copy_set_hash(hash); // merge the hash code into header
// use (machine word version) atomic operation to install the hash
test = (markOop) Atomic::cmpxchg_ptr(temp, obj->mark_addr(), mark);
if (test == mark) {
return hash;
}
// If atomic operation failed, we must inflate the header
// into heavy weight monitor. We could add more code here
// for fast path, but it does not worth the complexity.
} else if (mark->has_monitor()) { //重量级锁
// 果对象是一个重量级锁monitor,那对象头中的mark word保存的是指向ObjectMonitor的指针,
//此时对象非加锁状态下的mark word保存在ObjectMonitor中,到ObjectMonitor中去拿对象的默认哈希值:
monitor = mark->monitor();
temp = monitor->header();
assert (temp->is_neutral(), "invariant") ;
hash = temp->hash();
//(1)如果已经有默认哈希值,则直接返回;
if (hash) {
return hash;
}
// Skip to the following code to reduce code size
} else if (Self->is_lock_owned((address)mark->locker())) { //轻量级锁锁
//如果对象是轻量级锁状态并且当前线程持有锁,那就从当前线程栈中取出mark word:
temp = mark->displaced_mark_helper(); // this is a lightweight monitor owned
assert (temp->is_neutral(), "invariant") ;
hash = temp->hash(); // by current thread, check if the displaced
//(1)如果已经有默认哈希值,则直接返回;
if (hash) { // header contains hash code
return hash;
}
}
// Inflate the monitor to set hash code
monitor = ObjectSynchronizer::inflate(Self, obj);
// Load displaced header and check it has hash code
mark = monitor->header();
assert (mark->is_neutral(), "invariant") ;
hash = mark->hash();
//计算默认哈希值并保存到mark word中后再返回
if (hash == 0) {
hash = get_next_hash(Self, obj);
temp = mark->copy_set_hash(hash); // merge hash code into header
assert (temp->is_neutral(), "invariant") ;
test = (markOop) Atomic::cmpxchg_ptr(temp, monitor, mark);
if (test != mark) {
hash = test->hash();
assert (test->is_neutral(), "invariant") ;
assert (hash != 0, "Trivial unexpected object/monitor header usage.");
}
}
// We finally get the hash
return hash;
}
关于对象头、java内置锁的内容请阅读《Java 高并发核心编程 卷2 加强版》。
ObjectSynchronizer :: FastHashCode()也是通过调用identity_hash_value_for方法返回值的,调用了get_next_hash()方法生成hash值,源码如下:
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) { //随机数 openjdk6、openjdk7 采用的是这种方式
// This form uses an unguarded global Park-Miller RNG,
// so it's possible for two threads to race and generate the same RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random() ;
} else
if (hashCode == 1) { //基于对象内存地址的函数
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addrBits = cast_from_oop<intptr_t>(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else
if (hashCode == 2) { //恒等于1(用于敏感性测试)
value = 1 ; // for sensitivity testing
} else
if (hashCode == 3) { //自增序列
value = ++GVars.hcSequence ;
} else
if (hashCode == 4) { //将对象的内存地址强转为int
value = cast_from_oop<intptr_t>(obj) ;
} else {
//生成hash值的方式六: Marsaglia's xor-shift scheme with thread-specific state
//(基于线程具体状态的Marsaglias的异或移位方案) openjdk8之后采用的就是这种方式
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD ;
assert (value != markOopDesc::no_hash, "invariant") ;
TEVENT (hashCode: GENERATE) ;
return value;
}
到底用的哪一种计算方式,和参数hashCode有关系,在src/share/vm/runtime/globals.hpp中配置了默认:
openjdk6:
product(intx, hashCode, 0, \
"(Unstable) select hashCode generation algorithm") \
openkjdk8:
product(intx, hashCode, 5, \
"(Unstable) select hashCode generation algorithm") \
也可以通过虚拟机启动参数-XX:hashCode=n来做修改。
到这里你知道hash值是如何生成的了吧。
哈希表因为其本身结构使得查找对应的值变得方便快捷,但是也带来了一些问题,问题就是无论使用哪种方式生成hash值,总有产生相同值的时候。接下来我们就来看下如何解决hash值相同的问题。
hash 碰撞(哈希冲突)
对于两个不同的数据元素通过相同哈希函数计算出来相同的哈希地址(即两不同元素通过哈希函数取模得到了同样的模值),这种现象称为哈希冲突或哈希碰撞。
一般来说,哈希冲突是无法避免的。如果要完全避免的话,那么就只能一个字典对应一个值的地址,这样一来, 空间就会增大,甚至内存溢出。减少哈希冲突的原因是Hash碰撞的概率就越小,map的存取效率就会越高。 常见的哈希冲突的解决方法有开放地址法和链地址法:
开放地址法
开放地址法又叫开放寻址法、开放定址法,当冲突发生时,使用某种探测算法在散列表中寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到。开放地址法需要的表长度要大于等于所需要存放的元素。
按照探测序列的方法,可以细分为线性探查法、平法探查法、双哈希函数探查法等。
这里为了更好的展示三种方法的效果,我们用例子来看看:设关键词序列为{47,7,29,11,9,84,54,20,30},哈希表长度为13,装载因子=9/13=0.69,哈希函数为f(key)=key%p=key%11
| 关键词(key) | 47 | 7 | 29 | 11 | 9 | 84 | 54 | 20 | 30 |
|---|---|---|---|---|---|---|---|---|---|
| 散列地址k(key) | 3 | 7 | 7 | 0 | 9 | 7 | 10 | 9 | 8 |
(1)线性探测法
当我们的所需要存放值的位置被占了,我们就往后面一直加1并对m取模直到存在一个空余的地址供我们存放值,取模是为了保证找到的位置在0~m-1的有效空间之中。
公式:fi=(f(key)+i) % m ,0 ≤ i ≤ m-1i会逐渐递增加1)
具体做法: 探查时从地址d开始,首先探查T[d],然后依次探查T[d+1]....直到T[m-1],然后又循环到T[0]、T[1],...直到探查到有空余的地址或者直到T[d-1]为止。
用线性探测法处理冲突得到的哈希表如下
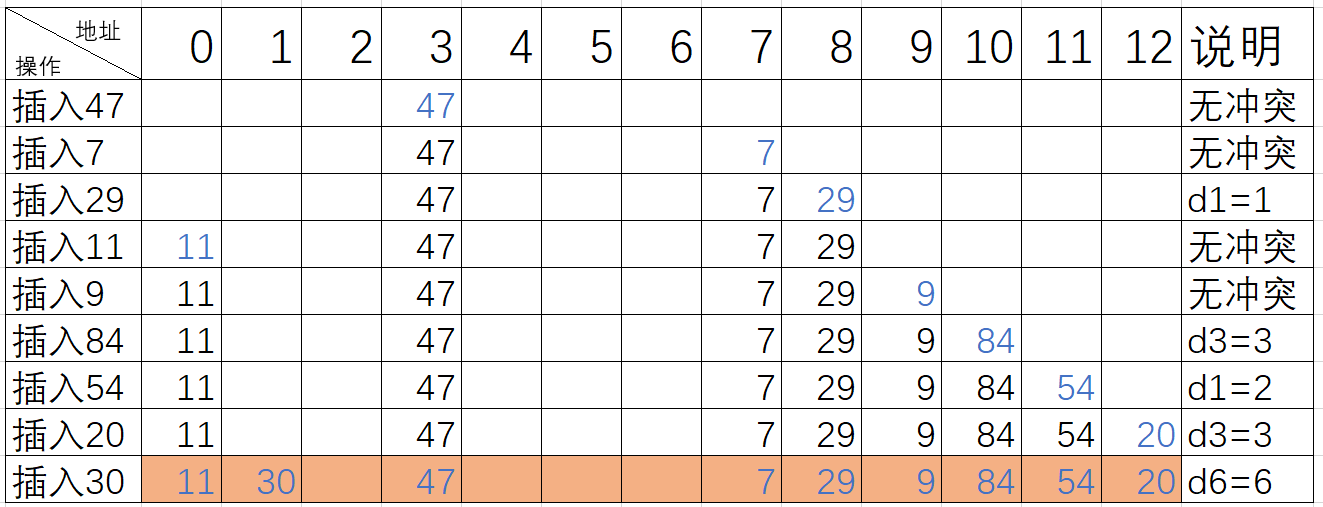
缺点:需要不断处理冲突,无论是存入还是査找效率都会大大降低。
(2)平方探查法
当我们的所需要存放值的位置被占了,会前后寻找而不是单独方向的寻找。
公式:fi=(f(key)+di) % m,0 ≤ i ≤ m-1
具体操作:探查时从地址 d 开始,首先探查 T[d],然后依次探查 T[d+di],di 为增量序列12、-12,22、-22, ……,q2、-q2 且q≤1/2 (m-1) ,直到探查到 有空余地址或者到 T[d-1]为止。
用平方探查法处理冲突得到的哈希表如下
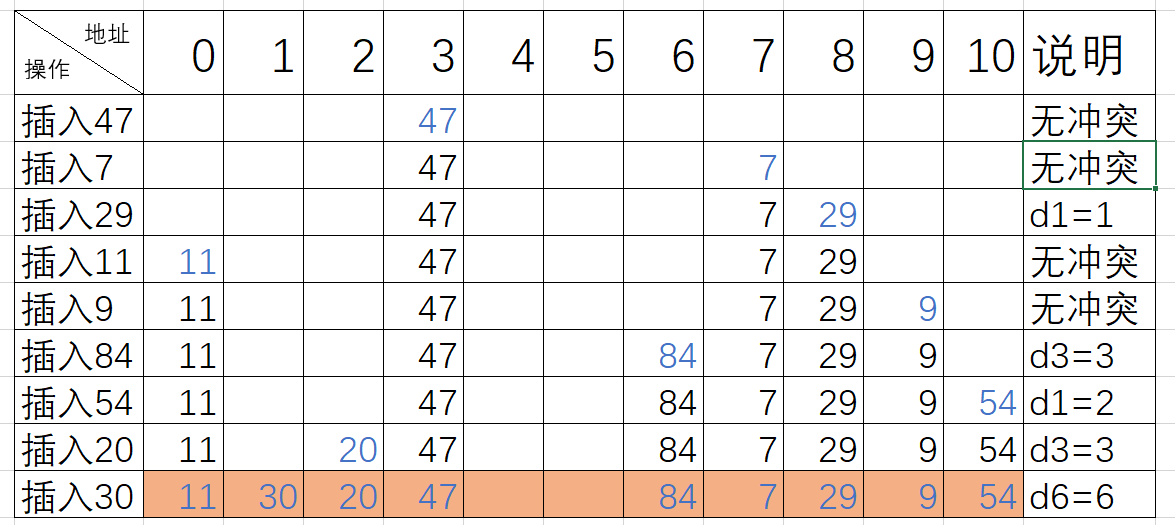
(3)双哈希函数探查法
公式:fi=(f(key)+i*g(key)) % m (i=1,2,……,m-1)
其中f(key) 和g(key) 是两个不同的哈希函数,m为哈希表的长度。
具体步骤:
双哈希函数探测法,先用第一个函数f(key)对关键码计算哈希地址,一旦产生地址冲突,再用第二个函数 g(key)确定移动的步长因子,最后通过步长因子序列由探测函数寻找空的哈希地址。
开发地址法,通过持续的探测,最终找到空的位置。为了解决这个问题,引入了链地址法。
链地址法
在哈希表每一个单元中设置链表,某个数据项对的关键字还是像通常一样映射到哈希表的单元中,而数据项本身插入到单元的链表中.
链地址法简单理解如下:
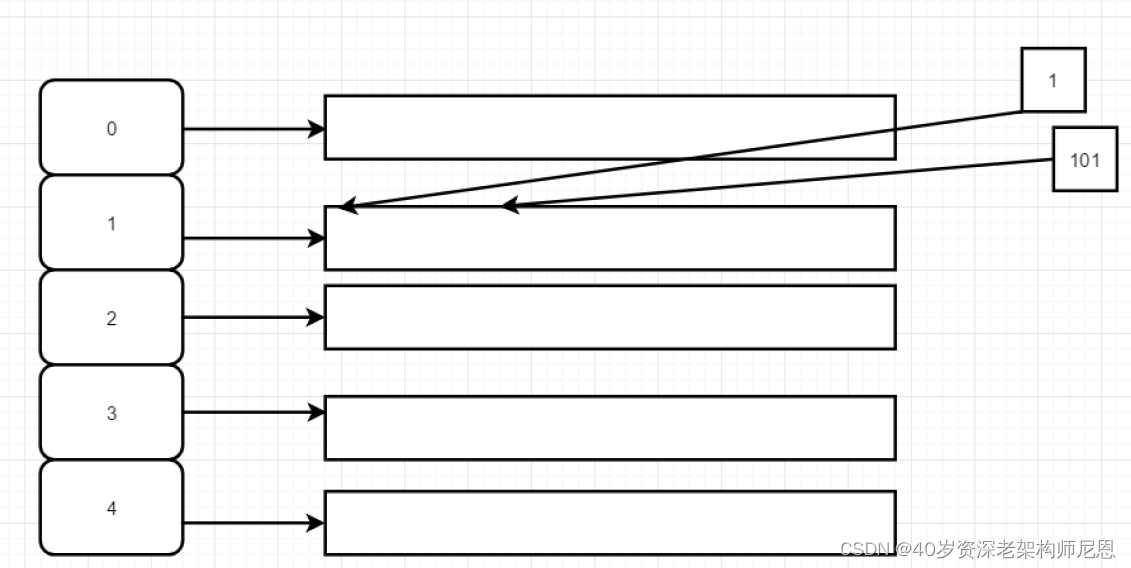
来一个相同的数据,就将它插入到单元对应的链表中,在来一个相同的,继续给链表中插入。
链地址法解决哈希冲突的例子如下:
(1)采用除留余数法构造哈希函数,而 冲突解决的方法为 链地址法。
(2)具体的关键字列表为(19,14,23,01,68,20,84,27,55,11,10,79),则哈希函数为f(key)=key MOD 13。则采用除留余数法和链地址法后得到的预想结果应该为:
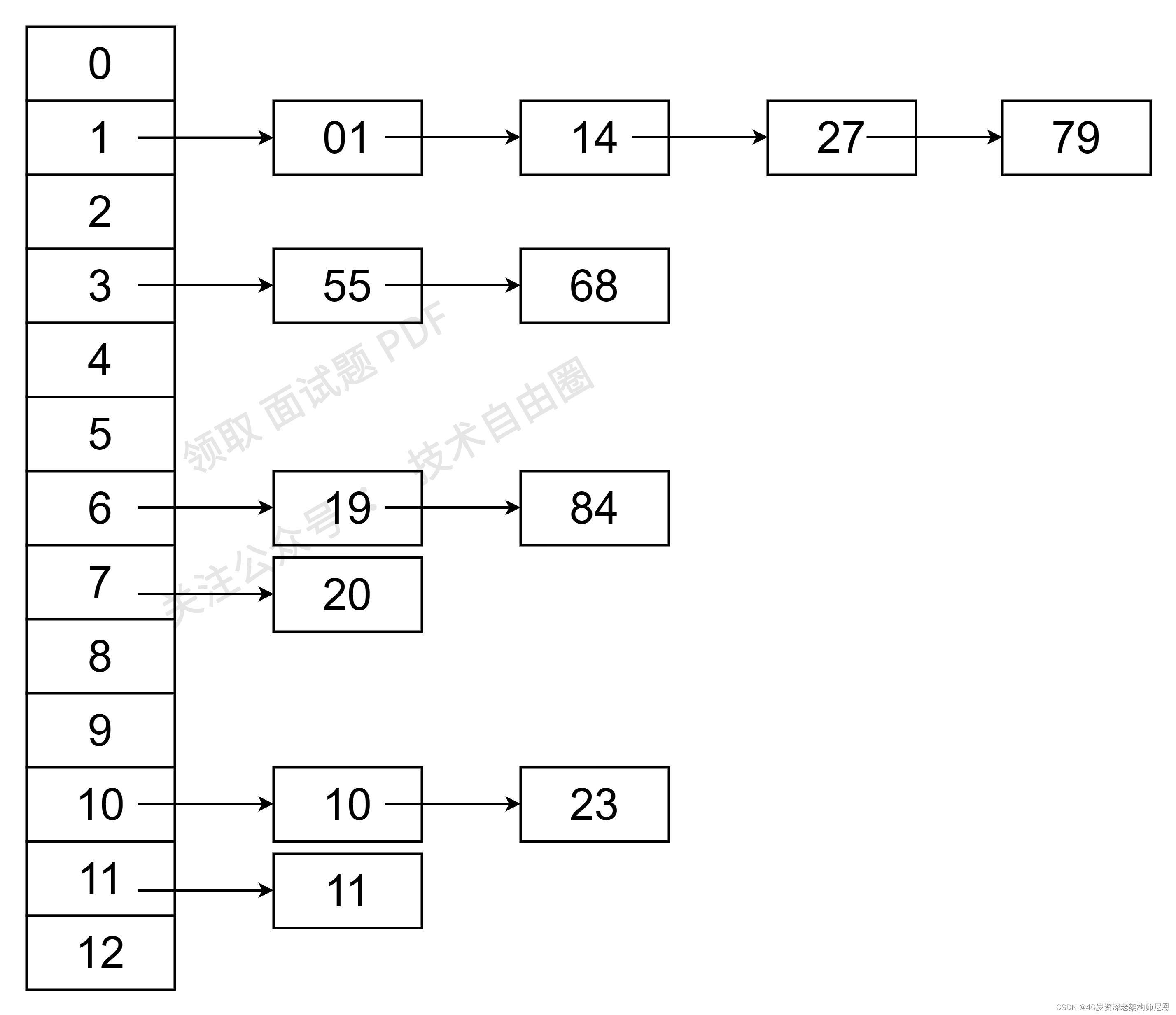
哈希造表完成后,进行查找时,首先是根据哈希函数找到关键字的位置链,然后在该链中进行搜索,如果存在和关键字值相同的值,则查找成功,否则若到链表尾部仍未找到,则该关键字不存在。
哈希表作为一个非常常用的查找数据结构,它能够在O(1)的时间复杂度下进行数据查找,时间主要花在计算hash值上。在Java中,典型的Hash数据结构的类是HashMap。
然而也有一些极端的情况,最坏的就是hash值全都映射在同一个地址上,这样哈希表就会退化成链表,例如下面的图片:
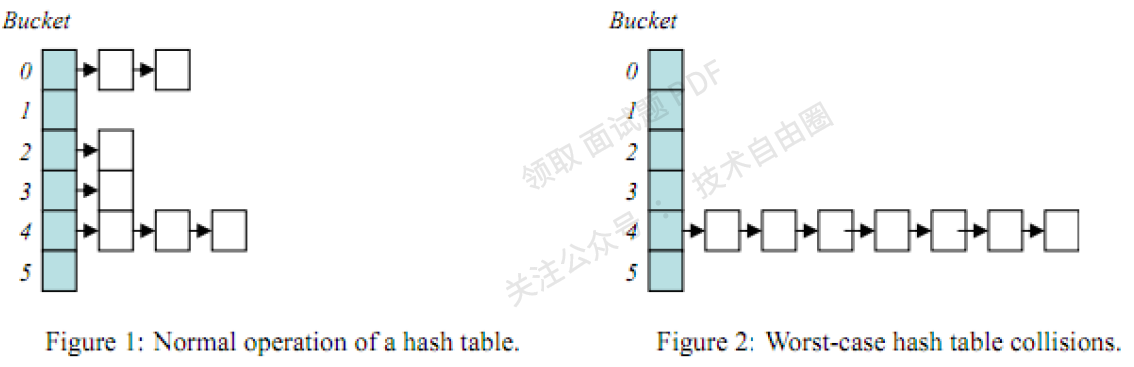
当hash表变成图2的情况时,查找元素的时间复杂度会变为O(n),效率瞬间低下,
所以,设计一个好的哈希表尤其重要,如HashMap在jdk1.8后引入的红黑树结构就很好的解决了这种情况。
手写一个相对复杂的HashMap
要拿高分,写个极简的版本,是不够的。
接下来模拟JDK的HashMap,我们就自己来手写hashMap。
复杂的HashMap的数据模型设计+接口设计
设计不能少,首先,尼恩给大家做点简单的设计:
- 数据模型设计:
宏观上来说:数组+ 链表
设计一个Table 数组来存储每个key-value对,一个key-value对封装为一个Node,其中每个Node可以增加指针,指向后继节点,可以形成一个链表结构,用于解决hash冲突问题。
- 访问方法设计:
设计一组方法,进行原始的 put、get。
既然接下来模拟JDK的HashMap,知己方能知彼,首先来看看,一个JDK 1.8版本ConcurrentHashMap实例的内部结构示例如图7-16所示。

图7-16 一个JDK 1.8 版本ConcurrentHashMap实例的内部结构
以上的内容,来自 尼恩的 《Java 高并发核心编程 卷2 加强版》,尼恩的高并发三部曲,很多小伙伴反馈说:相见恨晚,爱不释手。
接下来,开始定义顶层的访问接口。
定义顶层的访问接口
首先,我们需要的是确定HashMap结构,那么咱们就定义一个Map接口和一个Map实现类HashMap,其结构如下:
Map接口的实现
在Map接口中定义了以下几个方法
public interface Map<K,V> {
int size();
boolean isEmpty();
void clear();
V put(K key,V value);
V remove(K key);
V get(K key);
boolean containsKey(K key);
boolean containsValue(V value);
boolean equals(Object o);
int hashCode();
interface Entry<K, V> {
K getKey();
V getValue();
V setValue(V value);
int hashCode();
boolean equals(Object o);
}
}
手写实现类HashMap
定义好Map接口后,那么接下来我们就需要实现Map接口,定义实现类为HashMap。
HashMap类如下:
public class HashMap<K, V> implements Map<K, V> {
//数组默认初始容4
private int DEFAULT_CAPACITY = 1 << 2;
// 加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//数组扩容的阈值= loadFactorx 容量(capacity)
int threshold;
public HashMap() {
threshold = (int) (DEFAULT_CAPACITY * DEFAULT_LOAD_FACTOR);
}
......
}
HashMap类的构造函数中,仅对数组扩容阈值做了默认设置, 默认的数组扩容阈值等于数组默认容量*负载因子(0.75)
Node<K,V>节点的实现
在hashMap中定义数组集合节点Node<K,V>,Node<K,V>节点实现了Map中的Entry接口类,
在Node节点中定义了hash值,Key值,Value值和指针,
其核心代码如下:
/**
* 链表结点
*
* @param <K>
* @param <V>
*/
static class Node<K, V> implements Map.Entry<K, V> {
int hash;
K key;
V value;
Node<K, V> next;
public Node(int hash, K key, V value, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
......
}
定义好Node<K,V>节点后,我们需要定义一个数组,来存储Key-Value键值对;
数组定义如下:
// 数组
Node<K, V>[] table;
hash()函数实现
使用table中存储key-value键值对的前提是获取到table的下标值,在这我们采用最常用的hash函数-除留余数法f(key) =key%m 获取散列地址作为数组table的下标值,hash()函数实现如下:
private int hash(Object key) {
if (key == null) return 0;
int hash = (Integer) key % 4;
return hash;
}
开放地址法解决hash碰撞
通过hash()函数计算出散列地址作为数组下标后,那么我们就可以实现Key-Value键值对的存储。
HashMap的构造函数中仅设置了数组扩容的阈值,但是并没对数组进行初始化,那么就需要在第一次保存Key-Value值时进行数组table的初始化。
hash表最常见的问题就是hash碰撞,hash碰撞的解决方法有两种,开放地址法和链地址法,
我们先用最简单的开放地址法来解决hash冲突,那么保存Key-Value键值对的具体实现如下:
/**
* 插入节点
*
* @param key key值
* @param value value值
* @return
*/
@Override
public V put(K key, V value) {
//通过key计算hash值
int hash = hash(key);
//数组
Node<K, V>[] tab;
// 数组长度
int n;
// 数组的位置,即hash槽位
int i;
//根据数组长度和哈子自来寻址
Node<K, V> parent;
if ((tab = table) == null || (n = tab.length) == 0) {
//第一次put的时候,调用ensureCapacity初始化数组table
tab = ensureCapacity();
n = tab.length;
}
// 开始时插入元素
if ((parent = tab[i = hash]) == null) { //无hash碰撞,在当前下标位置直接插入
System.out.println("下标:" + i + ",数组插入的key:" + key + ",value:" + value);
//如果没有hash碰撞,就直接插入数组中
tab[i] = new Node<>(hash, key, value, null);
++size;
} else { // 有hash碰撞的时候,就采用线性探查法解决hash碰撞:fi=(f(key)+i)%4
if (i == (n - 1)) {
//若已是下标最大值,就从头开始查找空位置插入
for (int j = 0; j < i; j++) {
if (tab[j] == null) {
System.out.println("已最后一个下标,从0下标开始找,下标为:" + j + ",数组插入的key:" + key + ",value:" + value);
tab[j] = new Node<>(hash, key, value, null);
++size;
break;
}
}
} else { // 若不是下标最大值,那就从当前下标往后查找空位置插入
for (int index = 1; index < n - i - 1; index++) {
//先往后查找,若往后查找有空位,就直接插入,
if (tab[i + index] == null) {
System.out.println("从当前下标往后找,下标为:" + (i + index) + ",数组插入的key:" + key + ",value:" + value);
tab[i + index] = new Node<>(hash, key, value, null);
++size;
break;
}
}
}
}
// 判断当前数组是否需要扩容
if (size > threshold ){
//扩容操作
ensureCapacity();
}
return value;
}
在第一次调用put()方法保存Key-Value键值对的时候,调用ensureCapacity()方法初始化数组。
在保存Key-Value键值对后需要判断是否需要扩容,扩容的条件是当前数组中元素个数超过阈值就需要扩容。
调用ensureCapacity()方法进行扩容操作,每次新容量=1.5 * 数组原容量;
具体代码实现如下:
/**
* 数组扩容
*/
private Node<K, V>[] ensureCapacity() {
int oldCapacity = 0;
//数组未初始化,对数组进行初始化
if (table == null || table.length == 0) {
table = new Node[DEFAULT_CAPACITY];
return table;
}
// 数组已初始化,旧容量
oldCapacity = table.length;
// 扩容后新的数组容量
int newCapacity = 0;
// 如果数组的长度 == 容量
if (size > threshold) {
// 新容量为旧容量的1.5倍
newCapacity = oldCapacity + (oldCapacity >> 1);
//数组扩容阈值= 新容量*负载因子(0.75)
threshold = (int) (newCapacity * DEFAULT_LOAD_FACTOR);
//创建一个新数组
Node<K, V>[] newTable = new Node[newCapacity];
// 把原来数组中的元素放到新数组中
for (int i = 0; i < size; i++) {
newTable[i] = table[i];
}
table = newTable;
System.out.println(oldCapacity + "扩容为" + newCapacity);
}
return table;
}
从上述代码可看到,在原数组容量超过阈值的时候,就会进行扩容操作,扩容成功后还需要做以下几件事:
- 重新设置数组扩容的阈值, 这个时候扩容阈值= 数组新容量* 负载因子;
- 把旧数组的元素赋值到新数组中, 新数组的元素存放位置按照旧数组的位置进行存储,这一个步骤是最影响性能的。
- 返回新创建的数组。
HashMap存储Key-Value键值对到此就完成了,我们来写一个测试单元来看下执行效果,测试单元代码如下:
@Test
public void hashMapTest() {
HashMap<Integer, Integer> hashMap = new HashMap<>();
hashMap.put(4, 104);
hashMap.put(6, 108);
hashMap.put(7, 112);
hashMap.put(11, 111);
hashMap.put(15, 115);
hashMap.put(19, 119);
hashMap.put(1, 100);
hashMap.put(5, 105);
hashMap.put(9, 109);
hashMap.put(29, 129);
hashMap.put(13, 113);
hashMap.put(17, 117);
hashMap.put(21, 121);
hashMap.put(25, 125);
hashMap.put(33, 133);
hashMap.put(37, 137);
hashMap.put(41, 141);
hashMap.put(45, 145);
hashMap.put(49, 149);
}
执行结果如下:

存储结构如下图所示:

Key-Value 键值对已经保存到数组中了,那接下来我们就来探索下在HashMap中如何通过Key值某个Value值。
主要是通过for循环遍历查找,如果hash值相同或者Key值相同就说明找到Key-Value键值对,然后返回对应的value值,具体实现如下:
@Override
public V get(Object key) {
Node<K, V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* 通过key值在数组中查找value值
*
* @param hash
* @param key
* @return
*/
private Node<K, V> getNode(int hash, Object key) {
K k;
//如果不是就for循环查找
for (int i = 0; i < table.length; i++) {
if (table[i].hash == hash && ((k = table[i].key) == key || (key != null && key.equals(k)))) {
return table[i];
}
}
return null;
}
用测试单元来查看Key = 19 看返回的值是否正确,测试单元如下:
@Test
public void hashMapTest01() {
HashMap<Integer, Integer> hashMap = new HashMap<>();
hashMap.put(4, 104);
hashMap.put(6, 108);
hashMap.put(7, 112);
hashMap.put(11, 111);
hashMap.put(15, 115);
hashMap.put(19, 119);
System.out.println("hashMap get() value:" + hashMap.get(19));
}
执行结果如下:

从上述的HashMap 的put()方法采用的开发地址法持续探测最终找到空的位置保存Key-Value键值对,在get()方法中也是通过循环不断的探测hash值或Key值。这种方式在记录总数可以预知的情况下,可以创建完美的hash表,这种情况下存储效率是很高的。
但是在实际应用中,往往记录的数据量是不确定的,那么存储的数组元素超过阈值的时候就需要进行扩容操作,扩容操作的时间成本是很高的,频繁的扩容操作同样也会程序的性能。 采用开放地址法是通过不断的探测寻找空地址,探测的过程的时间成本也是很高的,而且在查找key-value键值对时,就不能单纯的使用数组下标的方式获取,而是通过循环的方式进行查找,这个过程也是十分消耗时间的。
针对hash表的开放地址法存在的问题,我们引入链地址法来解决, jdk1.7以及之前的HashMap就是采用的数组+链表的方式进行解决的。
链地址法解决hash碰撞
首先,我们对存储Key-Value键值对的put方法进行优化,优化的内容就是把有hash碰撞的Key-Value键值对用链表的形式进行存储,采用尾插入的方式往链表中插入有hash碰撞的Key-Value键值对,具体实现如下:
/**
* 插入节点
*
* @param key key值
* @param value value值
* @return
*/
@Override
public V put(K key, V value) {
...
// 开始时插入元素
if ((parent = tab[i = hash]) == null) {
System.out.println("下标为:"+i+"数组插入的key:" + key + ",value:" + value);
//如果没有hash碰撞,就直接插入数组中
tab[i] = new Node<>(hash, key, value, null);
++size;
} else { //有哈希碰撞时,采用链表存储
// 下一个子结点
Node<K, V> next;
K k;
System.out.println("下标为:"+i+"有哈希碰撞的key:" + key + ",value:" + value);
if (parent.hash == hash
&& ((k = parent.key) == key || (key != null && key.equals(k)))) {
// 哈希碰撞,且节点已存在,直接替换数组元素
next = parent;
} else {
System.out.println("下标为:"+i+"链表插入的key:" + key + ",value:" + value);
// 哈希碰撞, 链表插入
for (int linkSize = 0; ; ++linkSize) {
// System.out.println("linkSize="+linkSize+",node:"+parent);
//如果当前结点的下一个结点为null,就直接插入
if ((next = parent.next) == null) {
System.out.println("new链表长度为:" + linkSize);
parent.next = new Node<>(hash, key, value, null);
break;
}
if (next.hash == hash
&& ((k = next.key) == key || (key != null && key.equals(k)))) {
//如果节点已经存在,直接跳出for循环
break;
}
parent = next;
}
printLinked(hash);
}
}
...
}
执行测试单元结果如下:

存储的结构如下图所示:

保存有hash碰撞的Key-Value键值对时采用了链表形式,那么在调用get()方法查找的时候,
首先通过hash()函数计算出数组的下标索引值,然后通过下标索引值查找数组对应的Node<K,V>节点,通过key值和hash值判断第一个结点是否是查找的Key-Value键值对,
若不是第一个结点不是要查找的Key-Value键值对,就从头开始变量链表进行Key-Value键值查找,查找到了就返回Key-Value键值对,没有查找到就返回null,
使用链地址法优化后的get()方法实现代码如下:
@Override
public V get(Object key) {
Node<K, V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* 通过key值在数组/链表/红黑树中查找value值
*
* @param hash
* @param key
* @return
*/
private Node<K, V> getNode(int hash, Object key) {
//数组
Node<K, V>[] tab;
//数组长度
int n;
// (n-1)$hash 获取该key对应的数据节点的hash槽位,即链表的根结点
Node<K, V> parent;
//root的子节点
Node<K, V> next;
K k;
//如果数组为空,并且长度为空, hash槽位对应的节点为空,就返回null
if ((tab = table) != null && (n = table.length) > 0
&& (parent = tab[ hash]) != null) {
// 如果计算出来的hash槽位所对应的结点hash值等于hash值,结点的key=查找key值,
// 返回hash槽位对应的结点,即数组
if (parent.hash == hash && ((k = parent.key) == key || (key != null && key.equals(k)))) {
return parent;
}
//如果不在根结点,在子结点
if ((next = parent.next) != null) {
//在链表中查找,需要通过循环一个个往下查找
while (next != null) {
if (next.hash == hash && ((k = next.key) == key || (key != null && key.equals(k)))) {
return next;
}
next = next.next;
}
}
}
return null;
}
采用链地址法解决hash碰撞问题相比开放地址法来说,处理冲突简单且无堆积现象, 发生hash碰撞后不用探测空位置保存元素,数组table也不需要频繁的进行扩容操作。
而且链表地址法中链表采用的时候尾插入方式增加节点,不会出现环问题,而且链表的节点插入效率比较高;链表上的节点空间是动态申请的,它更适合需要保存的Key-Value键值对个数不确定的情况,节省了空间也提高了插入效率。
但是链表不支持随机访问,查找元素效率比较低,需要遍历结点,所以当链表长度过长的时候,查找元素效率就会比较低,那么在链表长度超过一定阈值的时候,我们可以把链表转换成红黑树来提升查询的效率。
红黑树提升查询效率
采用红黑树来提升查询效率,首先需要定义红黑树的节点,该节点继承了Node节点,同时新增了左右结点和父节点。代码如下:
/**
* 红黑树结点
*
* @param <K>
* @param <V>
*/
static final class RBTreeNode<K, V> extends Node<K, V> {
boolean color = RED;
// 左节点
RBTreeNode<K, V> left;
// 右节点
RBTreeNode<K, V> right;
// 父节点
RBTreeNode<K, V> parent;
public RBTreeNode(int hash, K key, V value, Node<K, V> next) {
super(hash, key, value, next);
}
public boolean hasTwoChildren() {
return left != null && right != null;
}
/**
* 是否为左结点
*
* @return
*/
public boolean isLeftChild() {
return parent != null && this == parent.left;
}
/**
* 判断是否为右子树
*
* @return
*/
public boolean isRightChild() {
return parent != null && this == parent.right;
}
/**
* 获取兄弟结点
*
* @return
*/
public RBTreeNode<K, V> sibling() {
if (isLeftChild()) {
return parent.right;
}
if (isRightChild()) {
return parent.left;
}
return null;
}
....
}
接下来我们来优化一下Key-Value键值存储的put()方法,优化的点主要是Hash碰撞后的处理,具体如下:
- 通过hash()函数获得table下标索引值后,若该结点已是红黑树节点,就把需保存的Key-Value()节点插入到红黑树中,并判断是否平衡,若不平衡则进行自平衡操作;
- 通过hash()函数获得table下标索引值的节点是链表节点,则采用尾插入的方式插入链表结点,插入完成后判断链表长度是否超过链表长度阈值,若超过阈值就把链表转换成红黑树。
首先,我们先定义一个链表转红黑树的阈值,
//链表长度到达8时转成红黑树
private static final int TREEIFY_THRESHOLD = 8;
接下来我们看下put()方法的执行流程:
- 首先判断table是否有足够的容量,若没有足够容量,就进行扩容操作;
- 判断是否有hash冲突, 若无hash冲突,就把新增的key-value插入数组中对应的位置;
- 若有hash冲突的时候,判断是否该数组下标的结点是树节点还是链表节点,若是树节点就添加到树上; 若是链表节点就采用尾节点插入。
- 链表插入成功后需要判断一下链表的长度,若链表长度超过8时,就需要把链表转换成红黑树。
执行流程如下图所示:
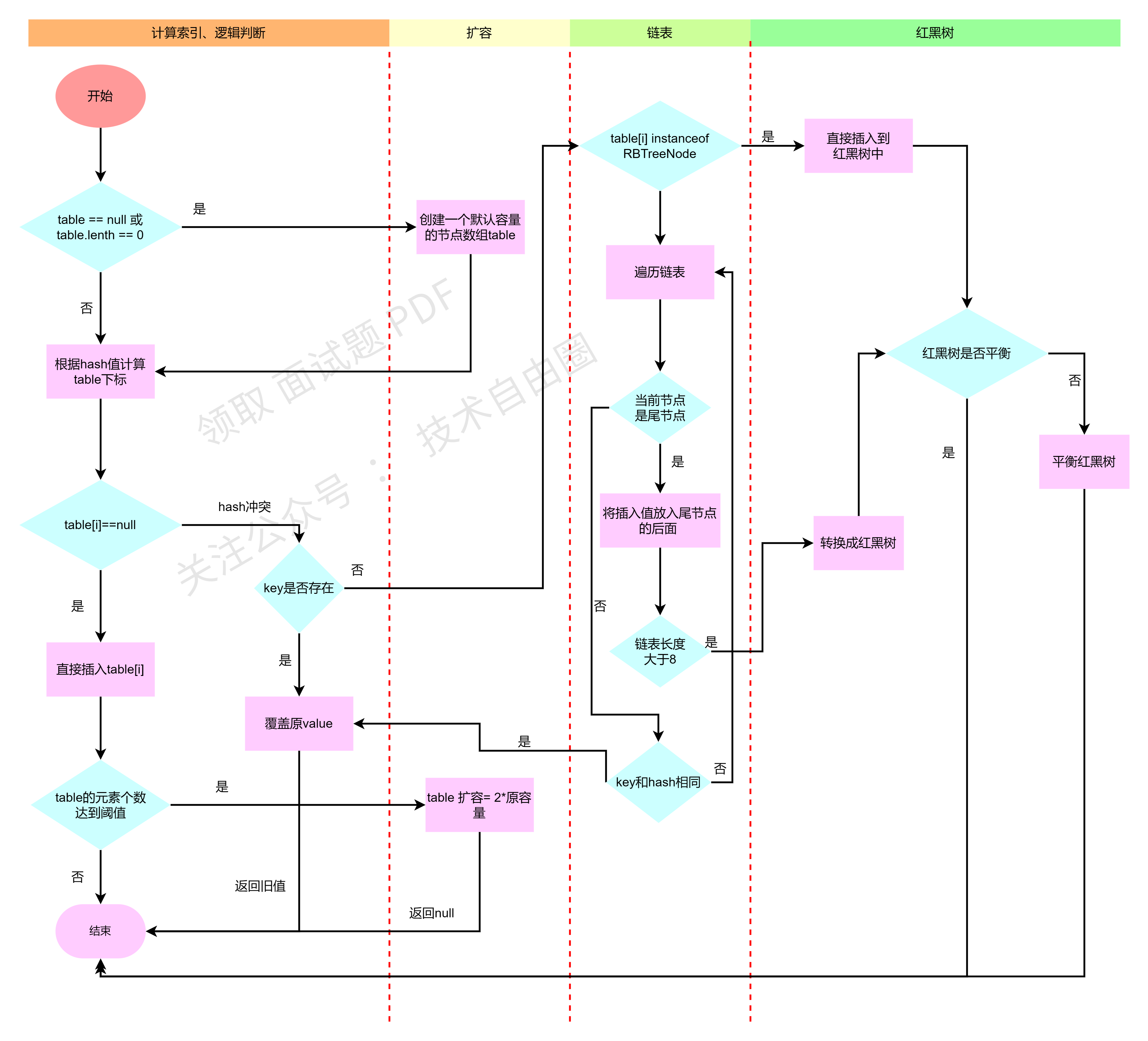
put()方法优化后的代码如下:
/**
* 插入节点
*
* @param key key值
* @param value value值
* @return
*/
@Override
public V put(K key, V value) {
//通过key计算hash值
int hash = hash(key);
//数组
Node<K, V>[] tab;
// 数组长度
int n;
// 数组的位置,即hash槽位
int i;
//根据数组长度和哈子自来寻址
Node<K, V> parent;
if ((tab = table) == null || (n = tab.length) == 0) {
//第一次put的时候,调用ensureCapacity创建数组
tab = ensureCapacity();
n = tab.length;
}
// 开始时插入元素
if ((parent = tab[i = (n - 1) & hash]) == null) {
System.out.println("数组插入的key:" + key + ",value:" + value);
//如果没有hash碰撞,就直接插入数组中
tab[i] = new Node<>(hash, key, value, null);
} else { //有哈希碰撞时,需要判断是红黑树还是链表
// 下一个子结点
Node<K, V> next;
K k;
System.out.println("有哈希碰撞的key:" + key + ",value:" + value);
if (parent.hash == hash
&& ((k = parent.key) == key || (key != null && key.equals(k)))) {
// 哈希碰撞,且节点已存在,直接替换数组元素
next = parent;
} else if (parent instanceof RBTreeNode) {
// 如果是红黑树节点,就插入红黑树节点
System.out.println("往红黑树中插入的key:" + key + ",value:" + value);
//先找到root根节点
int index = (tab.length - 1) & hash;
//取出红黑树的根结点
RBTreeNode<K, V> root = (RBTreeNode<K, V>) tab[index];
putRBTreeVal(root, hash, key, value);
} else {
System.out.println("链表插入的key:" + key + ",value:" + value);
printLinked(hash);
// 哈希碰撞, 链表插入
for (int linkSize = 0; ; ++linkSize) {
// System.out.println("linkSize="+linkSize+",node:"+parent);
//如果当前结点的下一个结点为null,就直接插入
if ((next = parent.next) == null) {
System.out.println("new链表长度为:" + linkSize);
parent.next = new Node<>(hash, key, value, null);
// 链表长度 >8时,链表的第九个元素开始转换为红黑树
if (linkSize >= TREEIFY_THRESHOLD - 1) {
Node<K, V> testNode = tab[i];
System.out.println("转换成红黑树插入的key:" + key + ",value:" + value);
/* for (int linkSize1 = 0; linkSize1 <linkSize+1; ++linkSize1){
System.out.println("linkSize1="+linkSize+",testNode:"+testNode);
testNode = testNode.next;
}*/
//System.out.println("node:"+parent.next);
System.out.println("链表长度为:" + linkSize);
linkToRBTree(tab, hash, ++linkSize);
}
break;
}
if (next.hash == hash
&& ((k = next.key) == key || (key != null && key.equals(k)))) {
//如果节点已经存在,直接跳出for循环
break;
}
parent = next;
}
}
}
if (++size > DEFAULT_CAPACITY * DEFAULT_LOAD_FACTOR) {
ensureCapacity();
}
return value;
}
首先我们来看下当链表的长度大于8时,是如何把链表转换成红黑树的, 这里采用的是遍历链表,然后把链表中的节点一个个转换成功红黑树节点后,插入到红黑树中,最后做自平衡操作。
我们来看下把链表转换成红黑树的实现代码如下
/**
* 把链表转换成红黑树
*
* @param tab
* @param hash
*/
private void linkToRBTree(Node<K, V>[] tab, int hash, int linkSize) {
// 通过hash计算出当前table数组的位置
int index = (tab.length - 1) & hash;
Node<K, V> node = tab[index];
int n = 0;
//遍历链表中的每个节点,将链表转换为红黑树
do {
//把链表结点转换成红黑树结点
RBTreeNode<K, V> next = replacementTreeNode(node, null);
putRBTreeVal(next, hash, next.key, next.value);
System.out.println("转换成红黑树数组的循环次数:" + n);
++n;
node = node.next;
} while (node != null);
System.out.println("n:" + n);
print(hash);
}
/**
* 把链表结点转换成红黑树结点
*
* @param p
* @param next
* @return
*/
RBTreeNode<K, V> replacementTreeNode(Node<K, V> p, Node<K, V> next) {
return new RBTreeNode<K, V>(p.hash, p.key, p.value, next);
}
链表转红黑树的时候,调用了节点插入的 putRBTreeVal()方法, 由于红黑树是二叉树的其中一种,根据二叉树的特性,左子树的值都比根结点值小,右子树的值都比根结点值大。
由于同一颗红黑树的hash值都是相同的,在插入新节点之前,那我们就需要比较Key值的大小,大的往右子树放,小的就往左子树放,那么putRBTreeVal()方法的实现如下:
RBTreeNode<K, V> putRBTreeVal(RBTreeNode<K, V> tabnode, int hash, K key, V value) {
if ((table[hash]) instanceof RBTreeNode) {
RBTreeNode<K, V> root = (RBTreeNode<K, V>) table[hash];
RBTreeNode<K, V> parent = root;
RBTreeNode<K, V> node = root;
int cmp = 0;
// 先找到父节点
do {
parent = node;
K k1 = node.key;
//比较key值
cmp = compare(key, k1);
if (cmp > 0) {
node = node.right;
} else if (cmp < 0) {
node = node.left;
} else {
V oldValue = node.value;
node.key = key;
node.value = value;
node.hash = hash;
return node;
}
} while (node != null);
//插入新节点
RBTreeNode<K, V> newNode = new RBTreeNode<>(hash, key, value, parent);
if (cmp > 0) {
parent.right = newNode;
} else if (cmp < 0) {
parent.left = newNode;
}
newNode.parent = parent;
//插入成功后自平衡操作
fixAfterPut(newNode, hash);
} else {
table[hash] = tabnode;
fixAfterPut(tabnode, hash);
}
return null;
}
虽然说红黑树不是严格的平衡二叉查找树,但是红黑树插入/移除节点后仍然需要根据红黑树的五个特性进行自平衡操作。
由于红色破坏原则的可能性最小,插入的新节点颜色默认是红色。
若红黑树还没有根结点,新插入的红黑树节点就会被设置为根结点,然后根据特性2(根节点一定是黑色)把根节点设置为黑色后返回。
若父节点是黑色的,插入节点是红色的,不会影响红黑树的平衡,所以直接插入无需做自平衡。
若插入节点的父节点为红色的,那么该父节点不可能成为根结点,就需要找到祖父节点和叔父节点,那这个时候就会出现两种状态:(1)父亲和叔叔为红色;(2)父亲为红色,叔叔为黑色。
出现这两种状态的时候就需要做自平衡操作,
如果父节点和叔父节点都是红色的话,根据红黑树的特性4(红色节点不能相连)可以推断出祖父节点肯定为黑色。那这个时候只需进行变色操作即可,把祖父节点变成红色,父节点和叔父节点变成黑色操作
若叔父节点为黑色, 父节点为红色,若新插入的红色节点在父节点的左侧,此处就出现了LL型失衡,自平衡操作就需要先进行变色,然后父节点进行右旋操作;若新插入的红色节点在父节点的右侧,此处就出现了LR型失衡,自平衡操作就需要先父节点进行左旋,将父节点设置为当前节点,然后再按LL型失衡操作进行自平衡操作即可。
若叔叔为黑节点,父亲为红色,并且父亲节点是祖父节点的右子节点,如果新插入的节点为其父节点的右子节点,此时就出现了RR型失衡操作, 自平衡处理操作是先进行变色处理,把父节点设置成黑色,把祖父节点设置为红色,然后祖父节点进行左旋操作;若新插入节点,为其父节点的左子节点,此时就出现了RL型失衡,自平衡操作是对父节点进行右旋,并将父节点设置为当前节点,接着按RR型失衡进行自平衡操作。
自平衡操作的实现代码如下:
/**
* 添加后平衡二叉树并设置结点颜色
*
* @param node 新添结点
* @param hash hash值
*/
private void fixAfterPut(RBTreeNode<K, V> node, int hash) {
RBTreeNode<K, V> parent = node.parent;
// 添加的是根节点 或者 上溢到达了根节点
if (parent == null) {
black(node);
return;
}
// 如果父节点是黑色,直接返回
if (isBlack(parent)) {
return;
}
// 叔父节点
RBTreeNode<K, V> uncle = parent.sibling();
// 祖父节点
RBTreeNode<K, V> grand = red(parent.parent);
if (isRed(uncle)) { // 叔父节点是红色【B树节点上溢】
black(parent);
black(uncle);
// 把祖父节点当做是新添加的节点
fixAfterPut(grand, hash);
return;
}
// 叔父节点不是红色
if (parent.isLeftChild()) { // L
if (node.isLeftChild()) { // LL
black(parent);
} else { // LR
black(node);
rotateLeft(parent, hash);
}
rotateRight(grand, hash);
} else { // R
if (node.isLeftChild()) { // RL
black(node);
rotateRight(parent, hash);
} else { // RR
black(parent);
}
rotateLeft(grand, hash);
}
}
/**
* 左旋
*
* @param grand
*/
private void rotateLeft(RBTreeNode<K, V> grand, int hash) {
RBTreeNode<K, V> parent = grand.right;
RBTreeNode<K, V> child = parent.left;
grand.right = child;
parent.left = grand;
afterRotate(grand, parent, child, hash);
}
/**
* 右旋
*
* @param grand
*/
void rotateRight(RBTreeNode<K, V> grand, int hash) {
RBTreeNode<K, V> parent = grand.left;
RBTreeNode<K, V> child = parent.right;
grand.left = child;
parent.right = grand;
afterRotate(grand, parent, child, hash);
}
void afterRotate(RBTreeNode<K, V> grand, RBTreeNode<K, V> parent, RBTreeNode<K, V> child, int hash) {
// 让parent称为子树的根节点
parent.parent = grand.parent;
if (grand.isLeftChild()) {
grand.parent.left = parent;
} else if (grand.isRightChild()) {
grand.parent.right = parent;
} else { // grand是root节点
int index = table.length - 1 & hash;
table[index] = parent;
}
// 更新child的parent
if (child != null) {
child.parent = grand;
}
// 更新grand的parent
grand.parent = parent;
print(hash);
}
使用单元测试看下红黑树的结果:
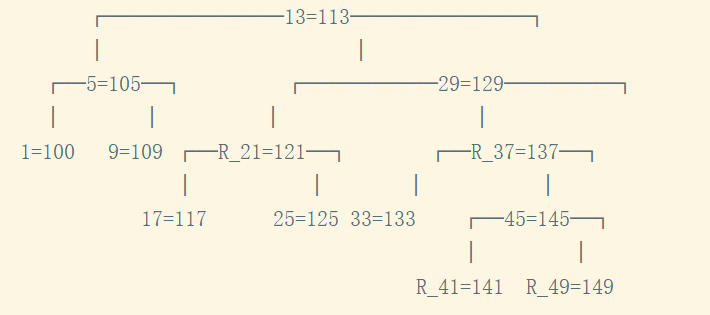
存储结构如下:
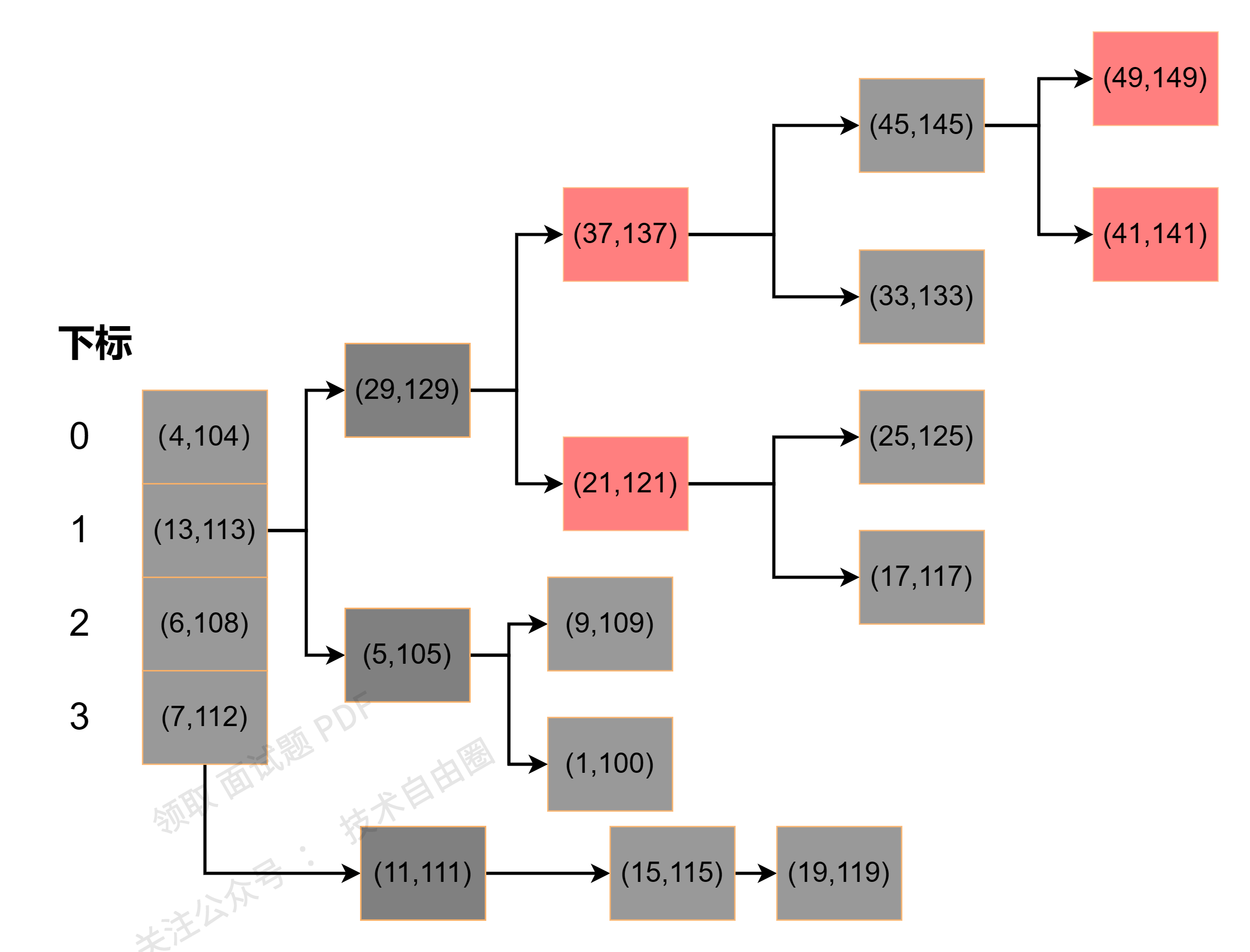
同样,查找Key-Value键值对的get()方法也同样需要做优化, 主要优化的内容就是在红黑树中查找Key-Value键值对;
实现步骤如下:
(1)通过hash值找到数组table的下标,
(2)通过数组table下标判断是否是红黑树节点,若是红黑树节点就在红黑树中查找;
(3)通过数组table下标判断是否是链表节点,若是链表节点就在链表中查找;
(4)若结点都不在红黑树和链表中,就在数组table中查找;
实现代码如下:
@Override
public V get(Object key) {
Node<K, V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* 通过key值在数组/链表/红黑树中查找value值
*
* @param hash
* @param key
* @return
*/
private Node<K, V> getNode(int hash, Object key) {
//数组
Node<K, V>[] tab;
//数组长度
int n;
// (n-1)$hash 获取该key对应的数据节点的hash槽位,即链表的根结点
Node<K, V> parent;
//root的子节点
Node<K, V> next;
K k;
//如果数组为空,并且长度为空, hash槽位对应的节点为空,就返回null
if ((tab = table) != null && (n = table.length) > 0
&& (parent = tab[(n - 1) & hash]) != null) {
// 如果计算出来的hash槽位所对应的结点hash值等于hash值,结点的key=查找key值,
// 返回hash槽位对应的结点,即数组
if (parent.hash == hash && ((k = parent.key) == key || (key != null && key.equals(k)))) {
return parent;
}
//如果不在根结点,在子结点
if ((next = parent.next) != null) {
//有子结点的时候,需要判断是链表还是红黑树
//在链表中查找,需要通过循环一个个往下查找
while (next != null) {
if (next.hash == hash && ((k = next.key) == key || (key != null && key.equals(k)))) {
return next;
}
next = next.next;
}
}
if (parent instanceof RBTreeNode) {
//在红黑树中查找
return getRBTreeNode((RBTreeNode<K, V>) parent, hash, key);
}
}
return null;
}
/**
* 在红黑树中查找结点
*
* @param node 根结点
* @param hash hash(key) 计算出的哈希值
* @param key 需要寻找的key值
* @return
*/
public Node<K, V> getRBTreeNode(RBTreeNode<K, V> node, int hash, Object key) {
// 存储查找结果
Node<K, V> result = null;
K k;
int cmp = 0;
while (node != null) {
//左节点
RBTreeNode<K, V> nl = node.left;
// 右节点
RBTreeNode<K, V> nr = node.right;
K k2 = node.key;
int hash1 = node.hash;
//比较hash值,判断是在左子树还是右子树
if (hash > hash1) {
//查找结点在右子树
node = nr;
} else if (hash < hash1) {
//查找结点在左子树
node = nl;
} else if ((k = node.key) == key || (key != null && key.equals(k))) {
//如果key 相等,就返回node
return node;
} else if (nl == null) {
node = nr;
} else if (nr == null) {
node = nl;
} else if (key != null & k2 != null
&& key.getClass() == k2.getClass()
&& key instanceof Comparable
&& (cmp = compare(key, k2)) != 0
) {
node = cmp > 0 ? node.right : node.left;
} else if (node.right != null && (result = getRBTreeNode(node.right, hash, key)) != null) {
return result;
} else {
node = node.left;
}
}
return null;
}
如果HashMap需要通过key值移除Key-Value键值对,首先通过key值查找到节点,然后进行移除;
若需移除的节点在红黑树中,首先需要判断移除节点的度是多少,若度为2的话,就需要先找到后继节点后才可以移除,若度为1或0的话,可以直接进行移除操作,红黑树移除节点同样也需要判断红黑树是否平衡,若不平衡就需要红黑树自平衡操作,自平衡操作和插入节点的平衡操作一样,就不在赘述了。具体代码实现如下:
/**
* 结点删除
*
* @param key
* @return
*/
@Override
public V remove(K key) {
int hash = hash(key);
//数组
Node<K, V>[] tab;
Node<K, V> parent;
K k;
int index;
V oldValue = null;
//节点是存在的
if ((parent = table[index = (table.length - 1) & hash]) != null) {
if (parent instanceof RBTreeNode) { // 红黑树删除
RBTreeNode<K, V> willNode = (RBTreeNode<K, V>) parent;
//找到要删除的结点
RBTreeNode<K, V> removeNode = (RBTreeNode<K, V>) getRBTreeNode(willNode, hash, key);
oldValue = removeNode.value;
// 度为2 的结点
if (removeNode.hasTwoChildren()) {
//找到后继接地那
RBTreeNode<K, V> s = successor(removeNode);
removeNode.key = s.key;
removeNode.value = s.value;
removeNode.hash = s.hash;
// 删除后继节点
removeNode = s;
}
// 删除node节点(node的度必然是1或者0)
RBTreeNode<K, V> replacement = removeNode.left != null ? removeNode.left : removeNode.right;
if (replacement != null) { // node是度为1的节点
// 更改parent
replacement.parent = removeNode.parent;
// 更改parent的left、right的指向
if (removeNode.parent == null) { // node是度为1的节点并且是根节点
table[index] = replacement;
} else if (removeNode == removeNode.parent.left) {
removeNode.parent.left = replacement;
} else { // node == node.parent.right
removeNode.parent.right = replacement;
}
// 删除节点之后的处理
fixAfterRemove(replacement, hash);
} else if (removeNode.parent == null) { // node是叶子节点并且是根节点
table[index] = null;
} else { // node是叶子节点,但不是根节点
if (removeNode == removeNode.parent.left) {
removeNode.parent.left = null;
} else { // node == node.parent.right
removeNode.parent.right = null;
}
// 删除节点之后的处理
fixAfterRemove(removeNode, hash);
}
System.out.println("删除结点后的红黑树:"+key);
print(hash);
size--;
return oldValue;
} else if (parent.next != null) { //链表删除
Node<K, V> node = parent;
Node<K,V> preNode = null;
for (int linkSize = 0; ; ++linkSize) {
if (node.hash == hash
&& ((k = node.key) == key || (key != null && key.equals(k)))) {
if (linkSize == 0) {
//如果是第一个结点,就把第二个结点挂载到table中
oldValue = node.value;
table[index] = node.next;
} else {
if (preNode.next.next == null) {
//删除的如是尾节点, 就把尾节点置为null
oldValue = preNode.next.value;
preNode.next = null;
} else {
oldValue = preNode.next.value;
preNode.next = preNode.next.next;
}
}
size--;
break;
}
//删除结点的前结点
preNode = node;
if ((node = node.next) == null) {
break;
}
}
System.out.println("链表删除元素:"+key);
printLinked(hash);
} else { //数组删除
if (parent.hash == hash
&& ((k = parent.key) == key || (key != null && key.equals(k)))) {
oldValue = parent.value;
for (int i = index + 1; i < table.length; i++) {
table[i - 1] = table[i];
}
--size;
table[(table.length-1)] =null;
return oldValue;
}
}
}
return oldValue;
}
private RBTreeNode<K, V> successor(RBTreeNode<K, V> node) {
// 前驱节点在左子树当中(right.left.left.left....)
RBTreeNode<K, V> p = node.right;
if (p != null) {
while (p.left != null) {
p = p.left;
}
return p;
}
// 从父节点、祖父节点中寻找前驱节点
while (node.parent != null && node == node.parent.right) {
node = node.parent;
}
return node.parent;
}
private void fixAfterRemove(RBTreeNode<K, V> node, int hash) {
// 如果删除的节点是红色
// 或者 用以取代删除节点的子节点是红色
if (isRed(node)) {
black(node);
return;
}
RBTreeNode<K, V> parent = node.parent;
if (parent == null) return;
// 删除的是黑色叶子节点【下溢】
// 判断被删除的node是左还是右
boolean left = parent.left == null || node.isLeftChild();
RBTreeNode<K, V> sibling = left ? parent.right : parent.left;
if (left) { // 被删除的节点在左边,兄弟节点在右边
if (isRed(sibling)) { // 兄弟节点是红色
black(sibling);
red(parent);
rotateLeft(parent, hash);
// 更换兄弟
sibling = parent.right;
}
// 兄弟节点必然是黑色
if (isBlack(sibling.left) && isBlack(sibling.right)) {
// 兄弟节点没有1个红色子节点,父节点要向下跟兄弟节点合并
boolean parentBlack = isBlack(parent);
black(parent);
red(sibling);
if (parentBlack) {
fixAfterRemove(parent, hash);
}
} else { // 兄弟节点至少有1个红色子节点,向兄弟节点借元素
// 兄弟节点的左边是黑色,兄弟要先旋转
if (isBlack(sibling.right)) {
rotateRight(sibling, hash);
sibling = parent.right;
}
color(sibling, colorOf(parent));
black(sibling.right);
black(parent);
rotateLeft(parent, hash);
}
} else { // 被删除的节点在右边,兄弟节点在左边
if (isRed(sibling)) { // 兄弟节点是红色
black(sibling);
red(parent);
rotateRight(parent, hash);
// 更换兄弟
sibling = parent.left;
}
// 兄弟节点必然是黑色
if (isBlack(sibling.left) && isBlack(sibling.right)) {
// 兄弟节点没有1个红色子节点,父节点要向下跟兄弟节点合并
boolean parentBlack = isBlack(parent);
black(parent);
red(sibling);
if (parentBlack) {
fixAfterRemove(parent, hash);
}
} else { // 兄弟节点至少有1个红色子节点,向兄弟节点借元素
// 兄弟节点的左边是黑色,兄弟要先旋转
if (isBlack(sibling.left)) {
rotateLeft(sibling, hash);
sibling = parent.left;
}
color(sibling, colorOf(parent));
black(sibling.left);
black(parent);
rotateRight(parent, hash);
}
}
}
熟背JDK的hashMap源码剖析
最终,要想让面试官五体投地,咱们还是的熟背hashMap源码。
(hashmap 的源码剖析是jdk1.8的)
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。

HashMap 的实现不是同步的,这意味着它是线程不安全的。
它的key、value都可以为null。此外,HashMap中的映射是无序的。
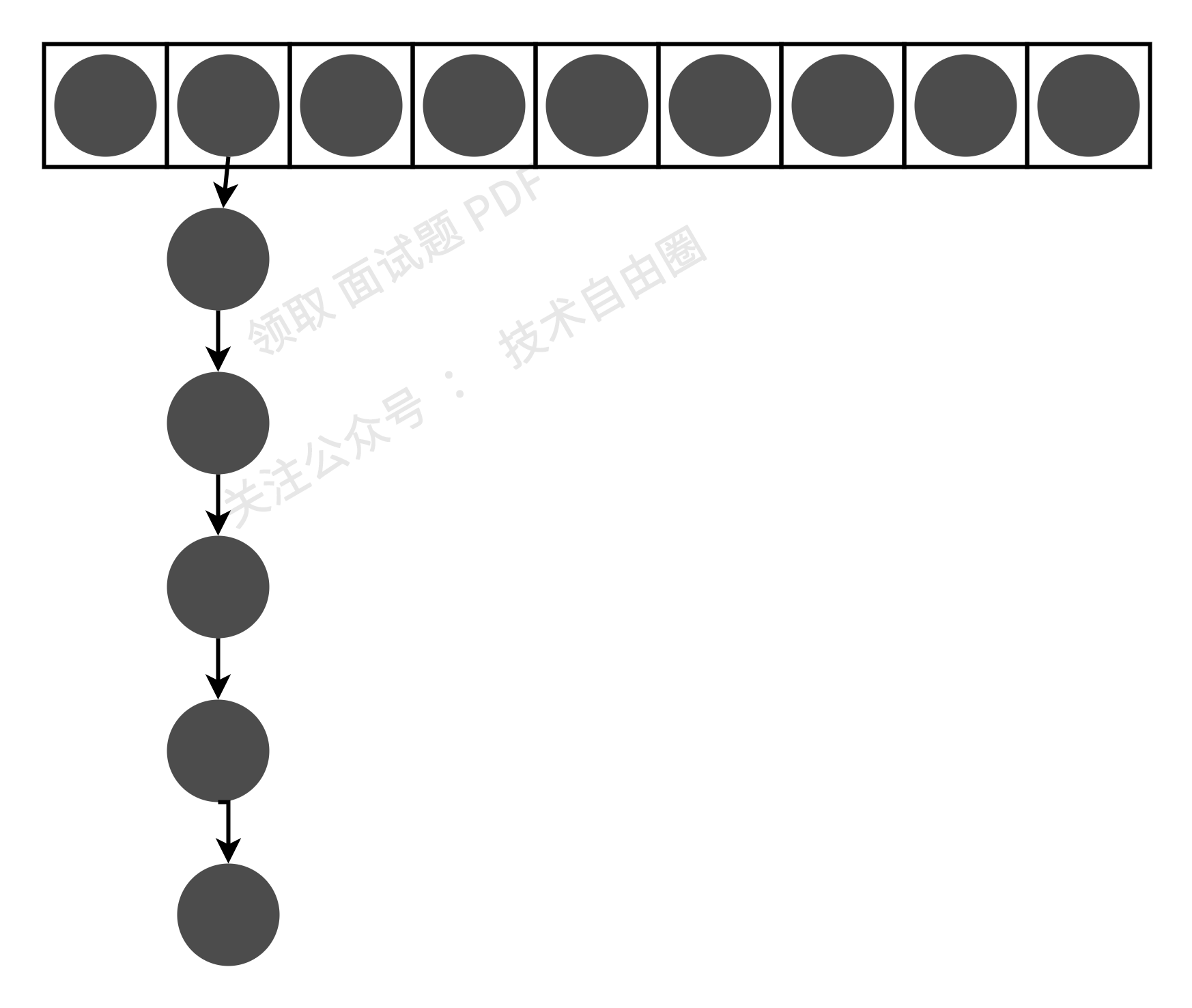
Jdk1.7中HashMap的实现的基础数据结构是数组+链表,每一对key->value的键值对组成Entity类以双向链表的形式存放到这个数组中;
元素在数组中的位置由key.hashCode()的值决定,如果两个key的哈希值相等,即发生了哈希碰撞,则这两个key对应的Entity将以链表的形式存放在数组中。如下图所示
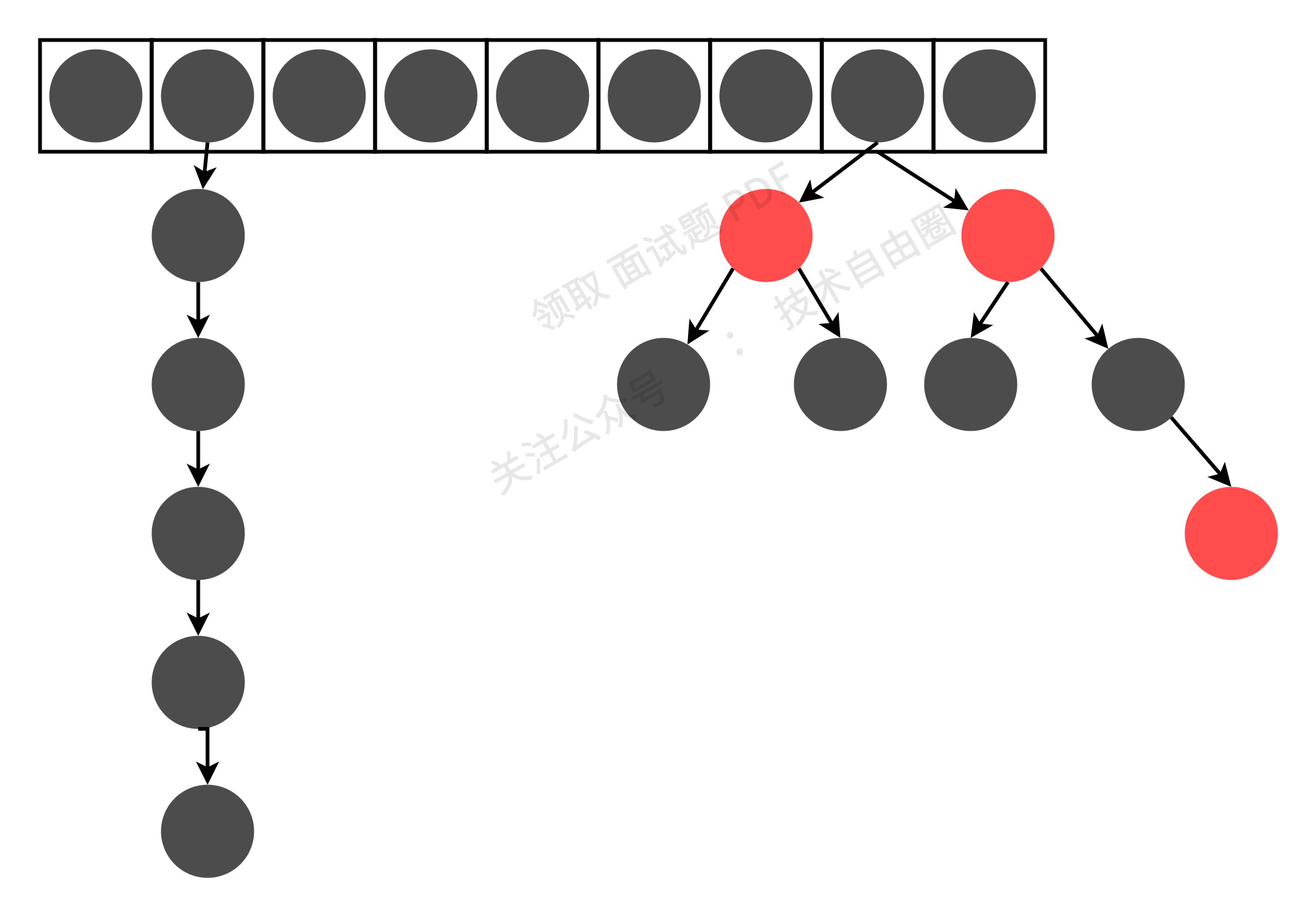
在jdk1.8及以后的版本,HashMap的实现的基础数据结构是数组+链表+红黑树;
为了提高hashmap的效率,新增了红黑树,如果链表的长度超过8,且table的容量必须大于64时,会将链表转换成红黑树。
如下图所示:
既然红黑树的效率高,为什么不直接用红黑树?为什么链表超过8转换为红黑树?
官方给出的解释如下:
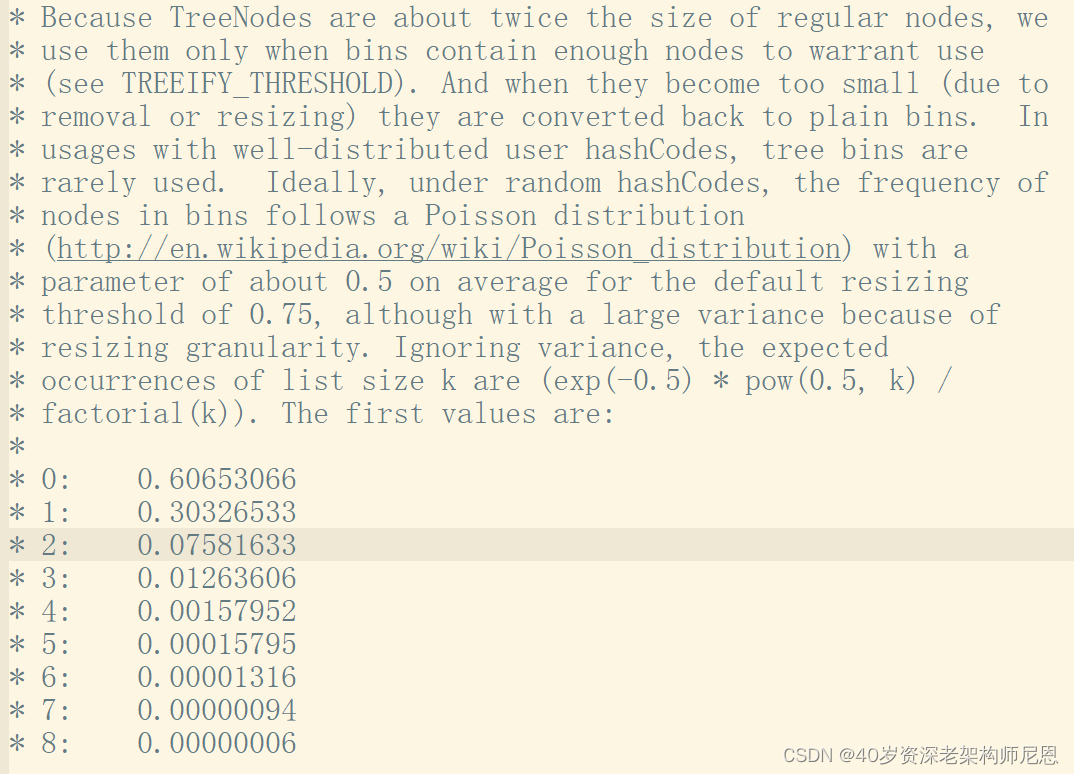
这段话的意思提现了时间和空间平衡的思想。
最开始使用链表的时候,空间占用是比较少的,而且由于链表短,所以查询时间也没有太大的问题。
可是当链表越来越长,需要用红黑树的形式来保证查询的效率。
对于何时应该从链表转化为红黑树,需要确定一个阈值,这个阈值默认为 8,链表长度达到 8 就转成红黑树,而当长度降到 6 就转换回链表。
如果 hashCode 分布良好,也就是hash计算的结果离散好的话,那么红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现链表很长的情况。
在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为8的时候,概率仅为0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。
事实上,链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低,而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
除了jdk1.8中新增了红黑树外,从jdk1.8开始,链表节点的插入使用尾插入替换了jdk1.7的头插入,替换的原因是在并发情况下,头插法会出现链表成环的问题,
数组下标获取
为了利用数组索引进行快速查找,hashMap采取hash算法的是先将 key值映射成数组下标。
hash()算法的源码如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
从源码中可以看到,没有直接使用hashCode返回hash值,是因为hashCode返回的是int值,它的范围是在-2147483648-2147483647。如果存的元素并不多的情况,创建int范围的的数组空间太过于浪费。
hash()分为两个步骤:
①先得到扰动后的key的hashCode:(h = key.hashCode() )^ (h >>> 16)
首先 h = key.hashCode()是key对象的一个hashCode,每个不同的对象其哈希值都不相同,其实底层是对象的内存地址的散列值,所以最开始的h是key对应的一个整数类型的哈希值;右移16位(h>>>16),然后高位补0是为了让高16位参与进来。
②再将hashCode映射成有限的数组下标index:(n - 1) & hash;
采用异或(^)运算是为了让h的低16位更有散列性。 为什么异或运算的散列性更好呢?我们来看组运算例子;

上面的计算过程如下:
与运算:其中1&1=1,其他三种情况1&0=0, 0&0=0, 0&1=0 都等于0,可以看到与运算的结果更多趋向于0,这种散列效果就不好了,运算结果会比较集中在小的值
或运算:其中0&0=0,其他三种情况 1&0=1, 1&1=1, 0&1=1 都等于1,可以看到或运算的结果更多趋向于1,散列效果也不好,运算结果会比较集中在大的值
异或运算:其中0&0=0, 1&1=0,而另外0&1=1, 1&0=1 ,可以看到异或运算结果等于1和0的概率是一样的,这种运算结果出来当然就比较分散均匀了
总的来说,与运算的结果趋向于得到小的值,或运算的结果趋向于得到大的值,异或运算的结果大小值比较均匀分散,这就是我们想要的结果。
右移16位,然后再与原hashcode做异或运算,是为了高低位二进制特征混合起来,使该hashCode映射成数组下标时可以更均匀。更好地均匀散列,从而减少碰撞,进一步降低hash冲突的几率。
所以计算的过程如下:
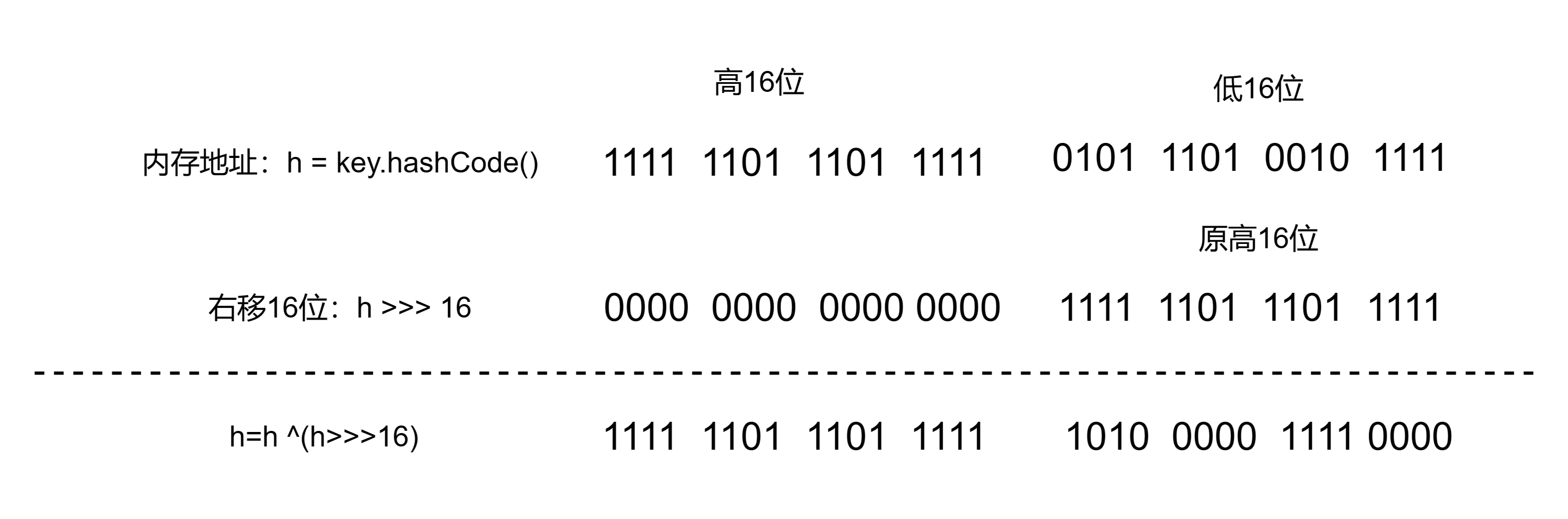
这部分产生的hash值是h,这个数有可能很大,不能直接拿来当数组下标,那么接下来就需要进行第二部分的内容(n - 1) & hash,这部分内容就是hashMap中获取数组下标的代码,n=table.length 新数组长度。 hash是参数h(上一步计算返回的hash结果)。
HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同。想到的办法就是取模运算:hash%length,但是在计算机中取模运算效率与远不如位移运算(&)高。主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。所以官方决定采用使用位运算(&)来实现取模运算(%),也就是源码中优化为:hash&(length-1)。
(n - 1) & hash的计算过程如下: 假设数组长度为16,经过(h = key.hashCode() )^ (h >>> 16)得到的hash值的低16位是1101001010100110(一般数hashmap数组长度都在2^16范围内,所以就用低16位演示了);
首先,n-1 = 15,转换成二进制是1111.然后与hash值进行与运算(当两个数字对应的二进位均为1时,结果位为1,否则为0。参与运算的数以补码出现).计算过程如下:
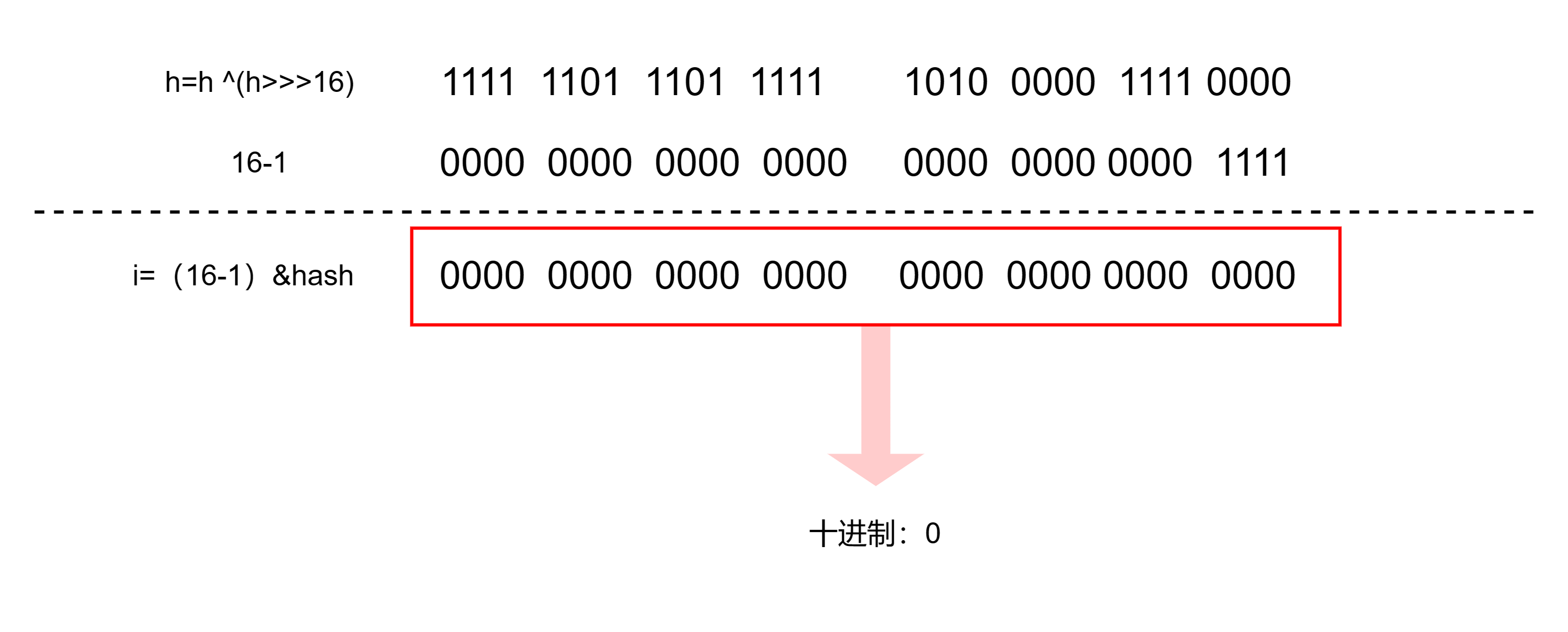
结果是0000,换算成十进制就是0,对应的数组下标就是0;
这样两步就完成了key对象映射到指定数组索引上了。
table桶的扩容机制
哈希桶数组的大小, 在空间成本和时间成本之间权衡,时间和空间之间进行权衡:
- 如果哈希桶数组很大,即使较差的Hash算法也会比较分散, 空间换时间
- 如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞, 时间换空间
其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。
在剖析table扩容之前,我们先来了解hashMap中几个比较重要的属性。
HashMap中有两个比较重要的属性:加载因子(loadFactor)和边界值(threshold),在HashMap时,就会涉及到这两个关键初始化参数,loadFactor和threshold的源码如下:
final float loadFactor;
int threshold;
Node[] table的初始化长度length(默认值是16),length大小必须为2的n次方,主要是为了方便扩容。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
loadFactor 为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node 个数。threshold 、length 、loadFactor 三者之间的关系:
threshold = length * Load factor
默认情况下 threshold = 16 * 0.75 =12。
threshold就是允许的哈希数组最大元素数目,超过这个数目就重新resize(扩容),扩容后的哈希数组 容量length 是之前容量length 的两倍。
threshold是通过初始容量和LoadFactor计算所得,在初始HashMap不设置参数的情况下,默认边界值为12。
如果HashMap中Node的数量超过边界值,HashMap就会调用resize()方法重新分配table数组。这将会导致HashMap的数组复制,迁移到另一块内存中去,从而影响HashMap的效率。
loadFactor默认值是0.75,官方给的解释如下:

大概意思是:作为一般规则,默认负载因子 (.75) 在时间和空间成本之间提供了良好的折衷。较高的值会减少空间开销,但会增加查找成本(反映在HashMap类的大多数操作中,包括get和put )。在设置其初始容量时,应考虑映射中的预期条目数及其负载因子,以尽量减少重新哈希操作的次数。 如果初始容量大于最大条目数除以负载因子,则不会发生重新哈希操作。
loadFactor 也是可以调整的,建议大家尽量不要修改,除非在时间和空间比较特殊的情况:
- 如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;
- 如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以
大于1
接下来我们再来看一个size属性。
size属性是HashMap中实际存在的键值对数量;而length是哈希桶数组table的长度。
当HashMap中的元素越来越多的时候,碰撞的几率也就越来越高,所以为了提高查询的效率,就要对HashMap的数组进行扩容,其实数组扩容这个操作在ArrayList中也出现了,所以这是一个通用的操作,
table是一个Node<K,V>类型的数组,其定义如下:
transient Node<K,V>[] table;
Node 类作为 HashMap 中的一个内部类,除了 key、value 两个属性外,还定义了一个next 指针,当有哈希冲突时,HashMap 会用之前数组当中相同哈希值对应存储的 Node 对象,通过指针指向新增的相同哈希值的Node 对象的引用。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
}
table在首次使用put的时候初始化,并根据需求调整大小。
当table中的Node<K,V>个数超过数组大小*loadFactor时,就会触发扩容机制。每次扩容的容量都是之前容量的 2 倍。HashMap 的容量是有上限的,必须小于 1<<30,即 1073741824。如果容量超出了这个数,则不再增长,且阈值会被设置为 Integer.MAX_VALUE。
JDK7 中的扩容机制
(1)空参数的构造函数:以默认容量、默认负载因子、默认阈值初始化数组。内部数组是空数组。
(2)有参构造函数:根据参数确定容量、负载因子、阈值等。
(3)第一次 put 时会初始化数组,其容量变为不小于指定容量的 2 的幂数,然后根据负载因子确定阈值。
(4)如果不是第一次扩容,则 新容量=旧容量 x 2 ,新阈值=新容量 x 负载因子 。
JDK8 的扩容机制
(1)空参数的构造函数:实例化的 HashMap 默认内部数组是 null,即没有实例化。第一次调用 put 方法时,则会开始第一次初始化扩容,长度为 16。
(2)有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的 2 的幂数,
哈希桶数组table的扩容核心是resize()方法。在resize的时候会将原来的数组rehash重新计算hash值转移到新数组上。在HashMap数组扩容之后,最消耗性能的点是原数组中的数据必须重新计算其在新数组中的位置,并放进去。
resize()方法扩容流程如下:
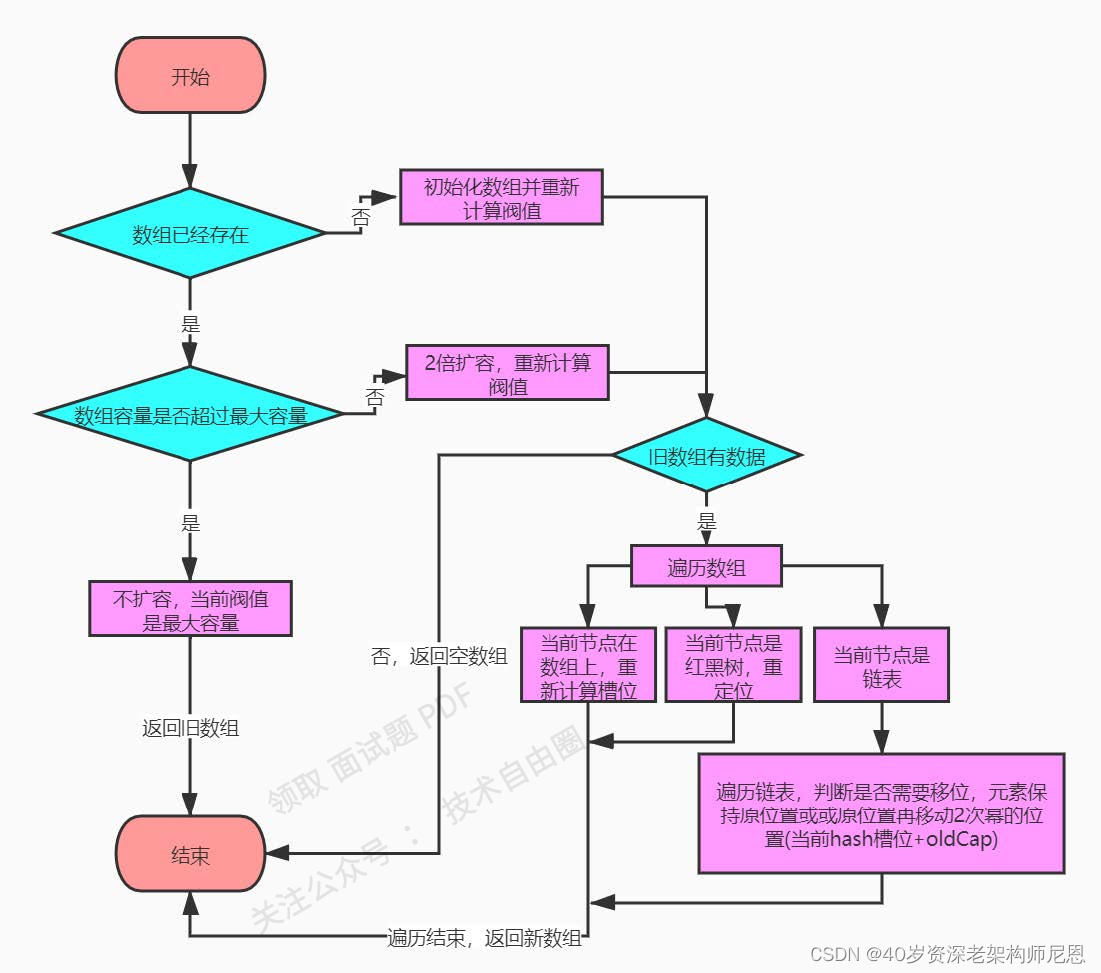
那接下来我们就来看下resize()方法中是如何初始化table数组和table扩容的。源码如下:
final Node<K,V>[] resize() {
//保存原数组
Node<K,V>[] oldTab = table;
//保存原数组长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//保存原阈值(没有初始化的时候是0)
int oldThr = threshold;
//定义成员变量 新数组长度,新阈值
int newCap, newThr = 0;
//如果原数组长度>0
if (oldCap > 0) {
//如果原数组长度大于最大容量
if (oldCap >= MAXIMUM_CAPACITY) {
//增加阈值
threshold = Integer.MAX_VALUE;
//返回
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 把数组长度变为原的两倍看是否小于最大容量,且原数组长度大于默认初始容量16
//阈值也扩大到原来的2倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
//如果原阈值>0,将原阈值赋给新数组长度
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 零初始阈值表示使用默认值,新容量为16.
newCap = DEFAULT_INITIAL_CAPACITY;
//新阈值为0.75*16=12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//新阈值为0
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//新阈值赋值给成员变量threshold
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//创建一个长度确定的新节点数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//新数组赋值给成员变量table
table = newTab;
//原数组不为空
if (oldTab != null) {
//对数组进行遍历
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果元素组上元素不为空
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//e下一个元素如果为空,说明只有单节点
if (e.next == null)
//把e放到新数组中,e要么在原来的位置,要么在 原来的位置+旧容量
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) //如果e是树节点
//用拆分树的方式进行转移
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order 低位表示:原位置 高位表示:原位置+旧容量
// 非单节点和树节点情况,也就是有链表结构
//低位的头节点和尾节点
Node<K,V> loHead = null, loTail = null;
// 高位的头节点和尾节点
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//如果放到新数组原位置上
if ((e.hash & oldCap) == 0) {
//如果低位尾节点为null,说明位置上没有节点
if (loTail == null)
//e作为头节点
loHead = e;
else //低位尾节点不为空,说明位置上右节点
// 让低位尾节点下一位指向e
loTail.next = e;
//e成为高位尾节点
loTail = e;
}
else { //放的位置为 原位置+原容量
//若高位尾节点没有元素
if (hiTail == null)
//e作为高位头结点
hiHead = e;
else //高位已有元素时
//让高位尾节点next指向e
hiTail.next = e;
//所以e成为了高位位节点
hiTail = e;
}
} while ((e = next) != null);
//如果低位尾节点不为空
if (loTail != null) {
//让低位下一位为空
loTail.next = null;
//将原来下标指向低位的链表
newTab[j] = loHead;
}
//如果高位尾节点不为空
if (hiTail != null) {
//让高位下一位为空
hiTail.next = null;
////将原来下标指向高位的链表
newTab[j + oldCap] = hiHead;
}
}
}
}
}
//返回新数组
return newTab;
}
从源码中我们知道,默认的数组长度length 是16.这个主要是为了实现均匀分布。因为在使用2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
table的threshold 阈值是通过初始容量和 loadFactor计算所得,在初始HashMap 不设置参数的情况下,默认边界值为12(160.75)。当HashMap中元素个数超过160.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置。
table的扩容分为两步:
第一步:扩容——创建一个新的Entry空数组,长度是原数组的2倍。
第二步:ReHash——遍历原Entry数组,把所有的Entry重新Hash到新数组。
扩容的后重新计算hash的原因是因为长度扩大以后,Hash的规则也随之改变。
put(K key, V value) 添加key-value
首先我们来看下put(K key, V value)的源码下:
public V put(K key, V value) {
//返回putVal方法, 给key进行了一次rehash
return putVal(hash(key), key, value, false, true);
}
从源码可以看到,put()方法首先调用hash()算法计算hash值,然后调用putVal()对添加的key-value键值对进行存储。
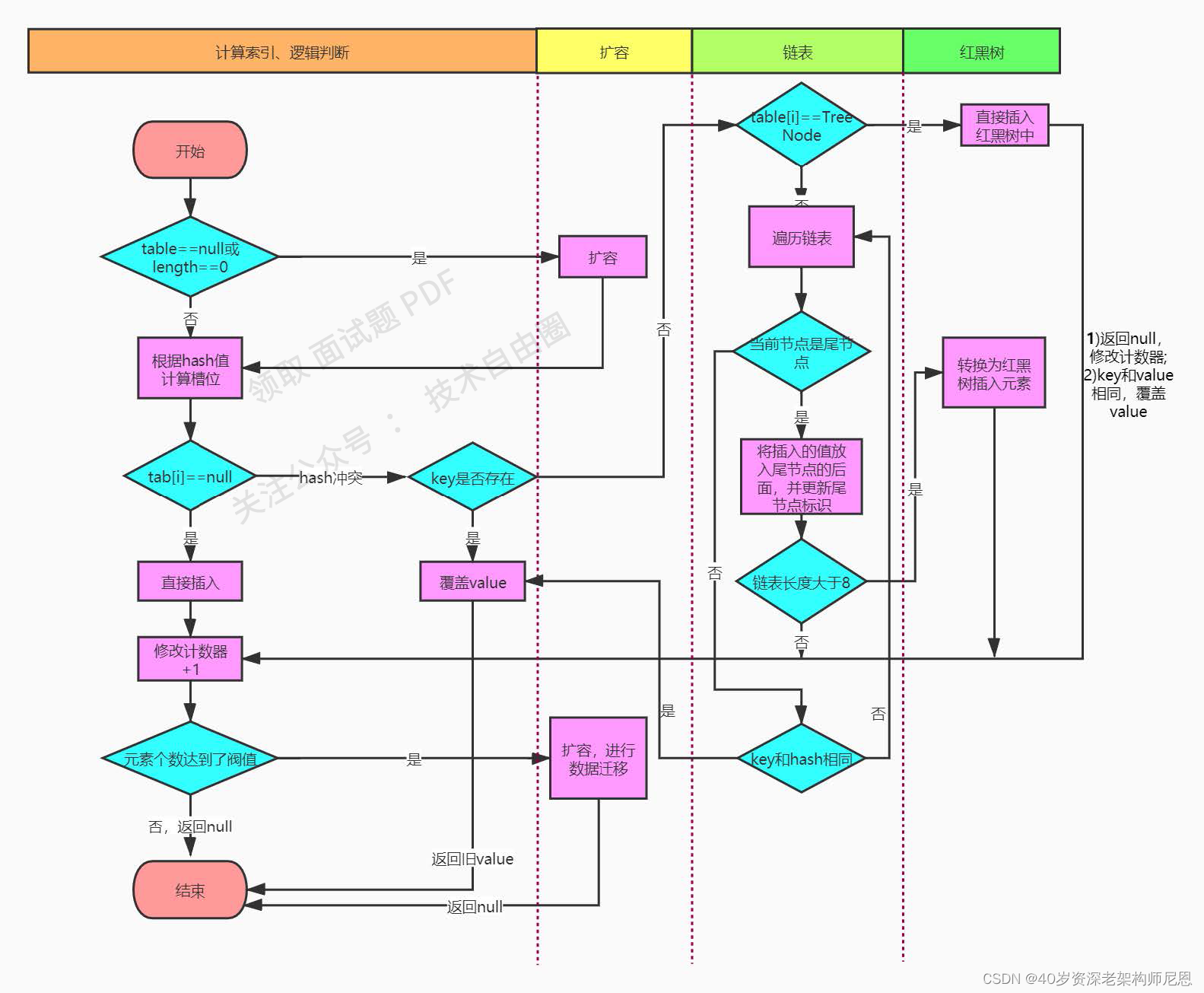
在putVal()中主要完成了一下几件事:
(1)如果发现当前的桶数组为null,则调用resize()方法进行初始化
(2)如果没有发生哈希碰撞,则直接放到对应的桶中
(3)如果发生哈希碰撞,且节点已经存在,就替换掉相应的value
(4)如果发生哈希碰撞,且桶中存放的是树状结构,则挂载到树上
(5)如果碰撞后为链表,添加到链表尾,如果链表长度超过TREEIFY_THRESHOLD默认是8,则将链表转换为树结构
(6)数据put完成后,如果HashMap的总数超过threshold就要resize
putVal的执行流程如下:
我们来看下添加树节点的方法putTreeVal()的源码;
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//tab:引用hashMap的散列表
//p:表示当前散列表的元素
// n :表示散列表数组的长度
//i:表示路由寻址的结果
Node<K,V>[] tab; Node<K,V> p; int n, i;
//延迟初始化逻辑,当第一次调用putVal的时候,才去初始化HashMap对象的散列表大小
if ((tab = table) == null || (n = tab.length) == 0)
//进入此处表示第一次调用put方法
//第一次put时,调用resize()进行桶数组初始化
n = (tab = resize()).length;
//(n-1)&hash 计算 Node 的存储位置,如果判断 Node 不在哈希表中(链表的第一个节
//点位置),新增一个 Node,并加入到哈希表中
if ((p = tab[i = (n - 1) & hash]) == null)
//如果没有哈希碰撞,直接放入数组中
tab[i] = newNode(hash, key, value, null);
else {
//hash 冲突了
//e:不为null时,找到一个与当前要插入的key-val一致的key对象
//k:临时的一个key
Node<K,V> e; K k;
//表示数组中的该元素,与你当前插入的元素key一致,后续会有替换操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//判断key的条件是key的hash相同和eqauls方法符合,p.key等于插入 的key,将p的引用赋给e
e = p;
else if (p instanceof TreeNode)
//p是红黑树节点,插入后仍然是红黑树节点,所以直接强制转型p后调用putTreeVal,返回的引用赋给e
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//哈希碰撞,链表结构
//循环,直到链表中的某个节点为null,或者某个节点hash值和给定的hash值一致且key也相同,则停止循环。
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//next为空,将添加的元素置为next
p.next = newNode(hash, key, value, null);
////插入成功后,要判断是否需要转换为红黑树,因为插入后链表长度+1>8,就转成红黑树,
//而binCount并不包含新节点,所以判断时要将临界阀值-1.【链表长度达到了阀值
//TREEIFY_THRESHOLD=8,即链表长度达到了7】
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 如果链表长度达到了8,且数组长度小于64,那么就重新散列 resize(),如果大于64,则创建红黑树,将链表转换为红黑树
treeifyBin(tab, hash);
break;
}
//节点hash值和给定的hash值一致且key也相同,停止循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
//如果节点已存在,则跳出循环
break;
//如果给定的hash值不同或者key不同。将next值赋给p,为下次循环做铺垫。即结束当前节点,对下一节点进行判断
p = e;
}
}
//如果e不是null,该元素存在了(也就是key相等)
if (e != null) { // existing mapping for key
// 取出该元素的值
V oldValue = e.value;
// 如果 onlyIfAbsent 是 true,就不用改变已有的值;如果是false(默认),或者value是null,将新的值替换老的值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//什么都不做
afterNodeAccess(e);
//返回旧值
return oldValue;
}
}
//修改计数器+1,为迭代服务
++modCount;
//达到了边界值,需要扩容
if (++size > threshold)
//超过阈值,进行扩容
resize();
//什么都不做
afterNodeInsertion(evict);
return null;
}
那接下来我们来看下是如何把节点添加到红黑树上的,调用的是putTreeVal()方法,源码如下:
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
//找到根节点
TreeNode<K,V> root = (parent != null) ? root() : this;
//遍历树节点元素
for (TreeNode<K,V> p = root;;) {
//节点位置,当前遍历到的节点hash值;key值
int dir, ph; K pk;
//如果树上元素的hash值大于添加进来元素的hash值
if ((ph = p.hash) > h)
//表示添加元素应在数的左节点
dir = -1;
else if (ph < h)
// 表示添加元素应在树的右节点
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk))) // 看key是否相同,是则代表找到要覆盖的节点位置
//返回当前树节点,返回后会赋值给e,最终对value进行覆盖
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) { // 到此说明当前节点的hash值和指定key的hash值是相等的,但equals不等
if (!searched) { //如果还没有比对完成当前节点的所有子节点
//继续遍历数进行寻找,如果还是没有找到key相同的,说明需要创建一个新节点
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
//找到就返回
return q;
}
// 最后的比较方法,调用System.identityHashCode()对k和要比较结点的key进行比较
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
// 根据方向dir决定
if ((p = (dir <= 0) ? p.left : p.right) == null) {
//是去左节点还是右节点,如果是null表示整棵树找完了,但还没有找到符合的节点,就要添加新节点了.
// xpn作为新节点的next
Node<K,V> xpn = xp.next;
//创建新树节点
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
//根据方向判断,新节点是在树左边还是右边
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//当前链表中的next节点指向到这个新的树节点
xp.next = x;
//新的树节点的父节点,前节点均设置为当前的树节点
x.parent = x.prev = xp;
//如果原来xp的next节点不为空
if (xpn != null)
//那么原来的next节点的前节点指向到新的树节点;
((TreeNode<K,V>)xpn).prev = x;
// 平衡树,确保不会太深,确保树的根节点在数组上
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
在HashMap的红黑树中不是直接以key作为排序关键字来判断key的大小,而是以key的hash值作为排序的关键字来判断key的大小;当key的hash值相同时(hash 冲突),有2大类情况:
(1)key实现了Comparable接口,比较key大小,决定搜索分支;
(2)key没有实现Comparable接口,没法直接比较key大小,因此会搜索当前节点的左右分支;
putTreeVal()方法调用了find()方法从左右子树搜寻Key,find()源码实现如下:
/**
* 从左右子树搜寻K
* K 搜索目标
* h 目标key的hash值
* kc key的class对象
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
//获取当前节点
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
//pl:当前节点的左子节点
//pr :当前节点的右子节点
TreeNode<K,V> pl = p.left, pr = p.right, q;
//ph:当前节点的hash
if ((ph = p.hash) > h)
//case1 : 小于当前hash,继续在左子节点搜索
p = pl;
else if (ph < h)
//case 2 :大于当前hash,继续在右子节点中搜索
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
// case 3:等于当前hash值,并且(当前节点key值)pk == k(目标key);直接返回当前节点
return p;
else if (pl == null) //该节点没有左子节点
p = pr;
else if (pr == null) //该节点没有右子节点
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0) //利用key的class类实现的比大小的方法,比较key的大小,然后决定查找的分支
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
//没有实现Comparable接口,或者实现了接口但是比较结果dir=0都会检测左右分支,
// q = pr.find(h, k, kc)检查右分支;q,是右分支查询结果;q!=null在右分支中找到了目标key,
return q;
else
//q==null,查询左分支;
p = pl;
} while (p != null);
return null;
}
红黑树插入新节点后,会出现不平衡的情况,在putTreeVal中调用了balanceInsertion()方法平衡红黑树,关于红黑树的如何平衡的可参考前文。balanceInsertion()源码如下:
/**
* 红黑树添加平衡
* @param root
* @param x
* @param <K>
* @param <V>
* @return
*/
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
//新插入树节点默认红色
x.red = true;
//x是新插入节点、xp是新插入节点的父节点、xpp是新插入节点的祖父节点、
//xppl是新插入节点的左叔叔节点、xppr是新插入节点的右叔叔节点
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
//1.空树
if ((xp = x.parent) == null) {
//新插入节点颜色变为黑色
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
//2.父节点黑色或祖父节点为空
return root;
if (xp == (xppl = xpp.left)) { //3.父节点红色 3.1父节点是祖父节点的左儿子
if ((xppr = xpp.right) != null && xppr.red) { //3.1.1叔叔节点红色
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else { //3.1.2叔叔节点不存在
if (x == xp.right) { //3.1.2.1新插入节点是父节点右儿子
//左旋
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
//3.1.2.2新插入节点是父节点左儿子
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else { //3.2父节点是祖父节点右儿子
//3.2.1叔叔节点红色
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else { //3.2.2叔叔节点不存在
//3.2.2.1新插入节点是父节点左儿子
if (x == xp.left) {
//右旋
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) { //3.2.2.2新插入节点是父节点右儿子
xp.red = false;
if (xpp != null) {
xpp.red = true;
//左旋
root = rotateLeft(root, xpp);
}
}
}
}
}
}
/**
* 左旋
*
* @param root 整个红黑树的根节点
* @param p 旋转的根节点
*/
static <K, V> HashMap.TreeNode<K, V> rotateLeft(HashMap.TreeNode<K, V> root, HashMap.TreeNode<K, V> p) {
/**
* 以节点P为根节点进行左旋
* 1、p的右节点指向r的左孩子(即rl),如果rl不为空,其父节点指向p;
* 2、r的父节点指向p的父节点(即PP),
* 2.1、如果pp为null,说明p节点为根节点,直接root指向r,同时颜色置为黑色(根节点颜色都为黑色);
* 2.2、如果pp的右孩子为p,则将pp的右孩子指向r;
* 2.3、如果pp的左孩子为p,则将pp的左孩子指向r;
* 3、将r的左孩子指向p;
* 4、将p的父节点指向r;
*/
// r-支点的右孩子节点,pp-支点的父节点,rl-支点右孩子的左节点
HashMap.TreeNode<K,V> r, pp, rl;
// 如果支点为NULL或者支点的右孩子节点为NULL,无法进行旋转,直接返回
if (p != null && (r = p.right) != null) {
if ((rl = p.right = r.left) != null)
rl.parent = p;
if ((pp = r.parent = p.parent) == null)
(root = r).red = false;
else if (pp.left == p)
pp.left = r;
else
pp.right = r;
r.left = p;
p.parent = r;
}
// 返回树的根节点
return root;
}
/**
* 右旋
*
* @param root 整个红黑树的根节点
* @param p 旋转的根节点
*/
static <K, V> HashMap.TreeNode<K, V> rotateRight(HashMap.TreeNode<K, V> root,
HashMap.TreeNode<K, V> p) {
/**
* 以节点P为根节点进行左旋
* 1、p的左节点指向l的右孩子(即lr),如果lr不为空,其父节点指向p;
* 2、l的父节点指向p的父节点(即PP),
* 2.1、如果pp为null,说明p节点为根节点,直接root指向l,同时颜色置为黑色(根节点颜色都为黑色);
* 2.2、如果pp的右孩子为p,则将pp的右孩子指向l;
* 2.3、如果pp的左孩子为p,则将pp的左孩子指向l;
* 3、将l的右孩子指向p;
* 4、将p的父节点指向l;
*/
// l-支点的右孩子节点,pp-支点的父节点,lr-支点左孩子的右节点
HashMap.TreeNode<K, V> l, pp, lr;
// 如果支点为NULL或者支点的左孩子节点为NULL,无法进行旋转,直接返回
if (p != null && (l = p.left) != null) {
if ((lr = p.left = l.right) != null)
lr.parent = p;
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
// 返回树的根节点
return root;
}
看完红黑树节点的插入,接下来我们来看下hashMap是如何把链表转换成红黑树的, 核心方法是treeify()方法,调用treeify()方法的是treeifyBin()方法,当链表的长度超过8的时候,就会调用treeifyBin()方法链表转化为以树节点存在的双向链表。treeifyBin()源码如下:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//如果当前数组长度小于树化阈值
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
//将数组扩容为原来2倍
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) { //如果链表的头节点不为空
//定义头节点、尾节点
TreeNode<K,V> hd = null, tl = null;
/**
* 先将树节点全部用双向链表连接起来
*/
do {
//将链表节点转换为树节点
TreeNode<K,V> p = replacementTreeNode(e, null);
//将链表节点转换为树节点
if (tl == null)
//把p节点赋值给列表头
hd = p;
else {
//新节点前一个结点设置为尾部
p.prev = tl;
//尾部下一个节点设置为新节点
tl.next = p;
}
//p节点赋值给尾部tl
tl = p;
} while ((e = e.next) != null);
//链表头节点放到到数组索引上
if ((tab[index] = hd) != null)
//树化
hd.treeify(tab);
}
}
treeify()将该双向链表转换为红黑树结构,源码如下:
final void treeify(Node<K,V>[] tab) {
//树的根节点
TreeNode<K,V> root = null;
//声明树节点x和next,先把当前节点赋值给x,开始循环
for (TreeNode<K,V> x = this, next; x != null; x = next) {
//next节点作为x的下一个节点
next = (TreeNode<K,V>)x.next;
//x左右孩子为空
x.left = x.right = null;
//如果根节点为空,x作为根节点
if (root == null) {
// 根节点无父节点
x.parent = null;
//节点颜色设置为黑色
x.red = false;
root = x;
}
/*
*以下部分和putTreeVal()添加树节点元素代码是类似的,找到方向,然后进行插入
* */
else { // 除首次循环外其余均走这个分支
// 除首次循环外其余均走这个分支
K k = x.key;
int h = x.hash;
// 定义key的Class对象kc
Class<?> kc = null;
// 循环,每次循环从根节点开始,寻找位置
for (TreeNode<K,V> p = root;;) {
// 定义节点相对位置、节点p的hash值
int dir, ph;
// 获取节点p的key
K pk = p.key;
//如果root节点的hash值大于
if ((ph = p.hash) > h)
// 当前节点在节点p的左子树
dir = -1;
else if (ph < h)
// 当前节点在节点p的右子树
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
// 当前节点与节点p的hash值相等,当前节点key并没有实现Comparable接口
// 或者实现Comparable接口并且与节点pcompareTo相等,该方法是为了保证在特殊情况下节点添加的一致性用于维持红黑树的平衡
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
// 根据dir判断添加位置也是节点p的左右节点,是否为空,若不为null在p的子树上进行下次循环
if ((p = (dir <= 0) ? p.left : p.right) == null) {
// 若添加位置为null,建立当前节点x与父节点xp之间的联系
x.parent = xp;
// 确定当前节点时xp的左节点还是右节点
if (dir <= 0)
xp.left = x;
else
xp.right = x;
// 对红黑是进行平衡操作并结束循环
root = balanceInsertion(root, x);
break;
}
}
}
}
// 将红黑树根节点复位至数组头结点
moveRootToFront(tab, root);
}
以上代码就是hashmap 基于数组+链表+红黑树实现的Key-Value键值对的存储,最后用一种流程图总结一下put()方法:
remove() 删除Key-Value
接下来我们来看下删除key-value键值对。hashMap的删除方法是remove(Object key)方法,执行流程如下:
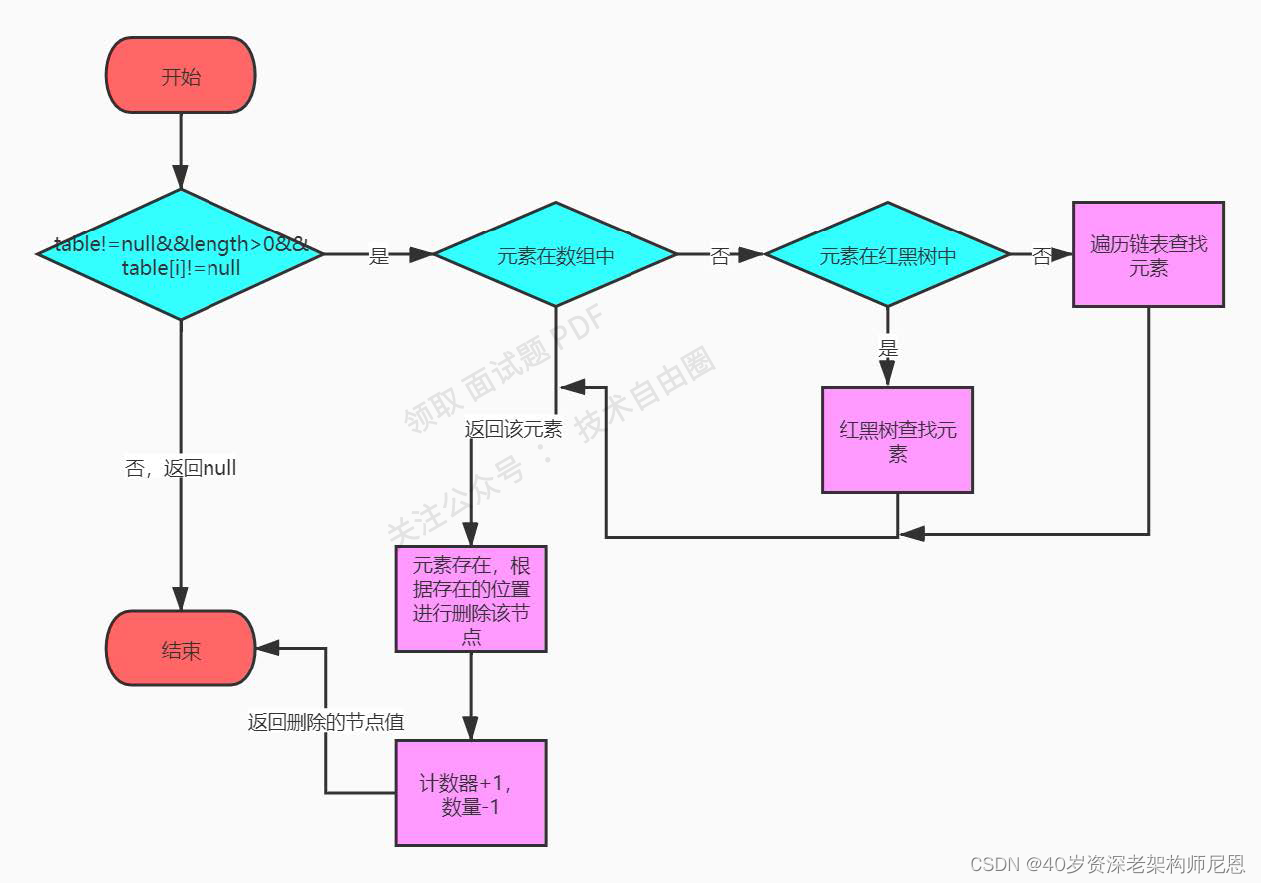
源码如下:
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* @param hash key对应的hash值
* @param key key
* @param value key对应的值
* @param matchValue 是否需要对值进行匹配操作
* @param movable 是否将根节点移动到链表顶端
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//数组不为null,数组长度大于0,要删除的元素计算的槽位有元素
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//当前元素在数组中
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) { //在链表中
if (p instanceof TreeNode) //元素在红黑树或链表中
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
//hash相同,并且key相同,找到节点并结束
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) { //找到节点了,并且值也相同
if (node instanceof TreeNode) //是树节点,从树中移除
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p) //节点在数组中,
tab[index] = node.next;
else //节点在链表中
p.next = node.next; //将节点删除
//修改计数器+1,为迭代服务
++modCount;
--size;
//什么都不做
afterNodeRemoval(node);
//返回删除的节点
return node;
}
}
return null;
}
如果节点在红黑树中,就需要到树中进行删除,调用removeTreeNode()方法删除,源码如下:
/**
* 这个方法是HashMap.TreeNode的内部方法,调用该方法的节点为待删除节点
*
* @param map 删除操作的map
* @param tab map存放数据的链表
* @param movable 是否移动跟节点到头节点
*/
final void removeTreeNode(HashMap<K, V> map, HashMap.Node<K, V>[] tab, boolean movable) {
int n;
if (tab == null || (n = tab.length) == 0)
return;
// 获取索引值
int index = (n - 1) & hash;
/**
* first-头节点,数组存放数据索引位置存在存放的节点值
* root-根节点,红黑树的根节点,正常情况下二者是相等的
* rl-root节点的左孩子节点,succ-后节点,pred-前节点
*/
HashMap.TreeNode<K, V> first = (HashMap.TreeNode<K, V>) tab[index], root = first, rl;
// succ-调用这个方法的节点(待删除节点)的后驱节点,prev-调用这个方法的节点(待删除节点)的前驱节点
HashMap.TreeNode<K, V> succ = (HashMap.TreeNode<K, V>) next, pred = prev;
/**
* 维护双向链表(map在红黑树数据存储的过程中,除了维护红黑树之外还对双向链表进行了维护)
* 从链表中将该节点删除
* 如果前驱节点为空,说明删除节点是头节点,删除之后,头节点直接指向了删除节点的后继节点
*/
if (pred == null)
tab[index] = first = succ;
else
pred.next = succ;
if (succ != null)
succ.prev = pred;
// 如果头节点(即根节点)为空,说明该节点删除后,红黑树为空,直接返回
if (first == null)
return;
// 如果父节点不为空,说明删除后,调用root方法重新获取当前树的根节点
if (root.parent != null)
root = root.root();
/**
* 当以下三个条件任一满足时,当满足红黑树条件时,说明该位置元素的长度少于6(UNTREEIFY_THRESHOLD),需要对该位置元素链表化
* 1、root == null:根节点为空,树节点数量为0
* 2、root.right == null:右孩子为空,树节点数量最多为2
* 3、(rl = root.left) == null || rl.left == null):
* (rl = root.left) == null:左孩子为空,树节点数最多为2
* rl.left == null:左孩子的左孩子为NULL,树节点数最多为6
*/
if (root == null || root.right == null ||
(rl = root.left) == null || rl.left == null) {
// 链表化,因为前面对链表节点完成了删除操作,故在这里完成之后直接返回,即可完成节点的删除
tab[index] = first.untreeify(map);
return;
}
/**
* p-调用此方法的节点(待删除节点),pl-待删除节点的左子节点,pr-待删除节点的右子节点,replacement-替换节点
* 以下是对红黑树进行维护
*/
HashMap.TreeNode<K, V> p = this, pl = left, pr = right, replacement;
// 1、删除节点有两个子节点
if (pl != null && pr != null) {
// 第一步:找到当前节点的后继节点(注意与后驱节点的区别,值大于当前节点值的最小节点,以右子树为根节点,查找它对应的最左节点)
HashMap.TreeNode<K, V> s = pr, sl;
// 循环右子树中查找后继节点(大于当前节点的最小值)
while ((sl = s.left) != null) // find successor
s = sl;
// 第二步:交换后继节点和删除节点的颜色,最终的删除是删除后继节点,故平衡是否是以后继节点的颜色来判断的
boolean c = s.red;
s.red = p.red;
p.red = c; // swap colors
// sr-后继节点的右孩子(后继节点是肯定不存在左孩子的,如果存在的话,那么它肯定不是后继节点)
HashMap.TreeNode<K, V> sr = s.right;
// pp-待删除节点的父节点
HashMap.TreeNode<K, V> pp = p.parent;
// 第三步:修改当前节点和后继节点的父节点
// 如果后继节点与当前节点的右孩子相等,类似于当前节点只有一个右孩子
if (s == pr) { // p was s's direct parent
// 交换两个节点的位置,父节点变子节点,子节点变父节点
p.parent = s;
s.right = p;
} else {
// 如果当前节点的右子树不止一个节点,记录sp-后继节点的父节点
HashMap.TreeNode<K, V> sp = s.parent;
// 交换待删除节点和后继节点的的父节点,如果后继节点父节点不为null,指定后继节点父节点的孩子节点
if ((p.parent = sp) != null) {
// 如果前后节点是其父节点的左孩子,修改父节点左孩子值
if (s == sp.left)
sp.left = p;
// 如果后继节点是其父节点的右孩子,修改父节点右孩子值
else
sp.right = p;
}
// 修改后继节点的右孩子值,如果不为null,同时指定其父节点的值
if ((s.right = pr) != null)
pr.parent = s;
}
// 第四步:修改当前节点和后继节点的孩子节点,当前节点现在变成后继节点了,故其左孩子为null.
p.left = null;
// 修改当前节点的右孩子值,如果其不为空,同时修改其父节点指向当前节点
if ((p.right = sr) != null)
sr.parent = p;
// 修改后继节点的左孩子值,如果其不为空,同时修改其父节点指向后继节点
if ((s.left = pl) != null)
pl.parent = s;
// 修改后继节点的父节点值,如果其为null,说明后继节点现在变成了root节点
if ((s.parent = pp) == null)
root = s;
// 当前节点是其父节点的左孩子
else if (p == pp.left)
pp.left = s;
// 当前节点是其父节点的右孩子
else
pp.right = s;
/**
* sr-后继节点的右孩子节点(有一个孩子节点),
* 如果右孩子节点不为空,删除节点后,替代节点就是其右孩子节点
* 如果为空,那么替代节点就是其本身
*/
if (sr != null)
replacement = sr;
else
replacement = p;
// 2、删除节点有一个左子节点,左子节点作为替代节点
} else if (pl != null)
replacement = pl;
// 3、删除节点有一个右子节点,右子节点作为替代节点
else if (pr != null)
replacement = pr;
// 4、删除节点没有子节点,直接删除当前节点
else
replacement = p;
/**
* 如果删除节点存在两个孩子节点,最终与后继节点交换后,删除的节点的位置位于后继节点的位置,那么此时删除节点所处的位置演变成:
* a、只有一个孩子节点:(replacement = p.right) != p
* b、没有孩子节点:replacement == p
* 只有当删除节点与替换节点不相等的时候,才对删除节点进行删除操作
*/
if (replacement != p) {
// 从红黑树中将待删除节点(即当前节点移除)
HashMap.TreeNode<K, V> pp = replacement.parent = p.parent;
// 是否为根节点
if (pp == null)
root = replacement;
// 其父节点的左子节点
else if (p == pp.left)
pp.left = replacement;
// 其父节点的右子节点
else
pp.right = replacement;
// 节点的指向全部置NULL
p.left = p.right = p.parent = null;
}
/**
* 如果删除节点的颜色是红色,不会影响整棵树的黑色高度,毋需自平衡,根节点不会变化,如果是黑色,则需要进行自平衡,重新获取根节点
* 注意:
* 自平衡的时候 替代节点可能与删除节点相等:replacement == p
* 自平衡的时候 替代节点可能与删除节点不相等:replacement != p
*/
HashMap.TreeNode<K, V> r = p.red ? root : balanceDeletion(root, replacement);
/**
* 当 replacement == p 时,是先进行了红黑树的进行了平衡操作,再将这个节点从红黑树中移除
* 这个地方我也没明白原理是什么,但是我按照这个步骤去走了一遍,确实这样操作来完成平衡,如果有哪位大神明白的,麻烦指导一下,谢谢!
*/
if (replacement == p) { // detach
// pp-存储当前节点的父节点值
HashMap.TreeNode<K, V> pp = p.parent;
// 当前节点的父节点指向NULL
p.parent = null;
// 如果父节点不为空,根据当前节点位于父节点的不同子节点,修改父节点的孩子节点值
if (pp != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
}
}
// movable为true,需要将根节点移动到头节点,即数组所以位置指向的节点
if (movable)
moveRootToFront(tab, r);
}
/**
* 红黑树删除节点后,平衡红黑树的方法
*
* @param root 根节点
* @param x 节点删除后,替代其位置的节点,这个节点可能是一个节点,也可能是一棵平衡的红黑树,在此处就当作一个节点,在该节点以上部分需要自平衡
* @return 返回新的根节点
*/
static <K, V> HashMap.TreeNode<K, V> balanceDeletion(HashMap.TreeNode<K, V> root, HashMap.TreeNode<K, V> x) {
/**
* 进入这个方法,说明被替代的节点之前是黑色的,如果是红色的不会影响黑色高度,黑色的会影响以其作为根节点子树的黑色高度
* xp-父节点,xpl-父节点的左孩子,xpr-父节点的右孩子节点
* 注意:
* 进入该方法的时候 替代节点可能与删除节点相等:x == replacement == p
* 替代节点可能与删除节点不相等:x == replacement != p
*/
for (HashMap.TreeNode<K, V> xp, xpl, xpr; ; ) {
/**
* 1、x == null,当 replacement == p 时,删除节点不存在,返回;
* 因为当 replacement != p 时,replacement 肯定不会为null.在移除节点的方法中有三个地方对 replacement 进行赋值。
* 1、if (sr != null) replacement = sr;
* 2、if (pl != null) replacement = pl;
* 3、if (pr != null) replacement = pr;
* 2、x == root,如果替代完成后,该节点就是整棵红黑树的根节点,本身就是平衡的,直接返回
*/
if (x == null || x == root)
return root;
else if ((xp = x.parent) == null) {
// 如果父节点为空,说明当前节点就是根节点,设置根节点的颜色为黑色,返回
x.red = false;
return x;
} else if (x.red) {
/**
* 被替换节点(删除节点)的颜色是黑色的,删除之后黑色高度减1,如果替换节点是红色,将其设置为黑色,可以保证
* 1、与替换之前的黑色高度相等
* 2、满足红黑树的所有特性
* 达到平衡返回
*/
x.red = false;
return root;
/**
* 如果替换节点是黑色的,替换之前的节点也是黑色的,替换之后,以替换节点作为根节点子树黑色高度减少1,需要进行相关的自平衡操作
* 1、替换节点是父节点的左孩子
*/
// 前提是X为黑色,左侧分支
} else if ((xpl = xp.left) == x) {
/**
* 情况1、父节点的右孩子(兄弟节点)存在且为红色
* 处理方式:兄弟节点变黑,父节点变红,以父节点为支点进行左旋,重新获取兄弟节点,继续参与自平衡
*/
if ((xpr = xp.right) != null && xpr.red) {
xpr.red = false;
xp.red = true;
root = rotateLeft(root, xp);
// 重新获取XPR
xpr = (xp = x.parent) == null ? null : xp.right;
}
// 不存在兄弟节点,x指向父节点,向上调整
if (xpr == null)
x = xp;
else {
// sl-兄弟节点的左孩子,sr-兄弟节点的右孩子
HashMap.TreeNode<K, V> sl = xpr.left, sr = xpr.right;
/**
* 情况2-1:兄弟节点存在,且两个孩子的颜色均为黑色
* 1、sr == null || !sr.red:兄弟的右孩子为黑色(空节点的颜色其实也是黑色)
* 2、sl == null || !sl.red:兄弟的左孩子为黑色(空节点的颜色其实也是黑色)
* 处理方式:兄弟节点为红色,替换节点指向父节点,继续参与自平衡
*/
if ((sr == null || !sr.red) && (sl == null || !sl.red)) {
xpr.red = true;
x = xp;
} else {
/**
* 该条件综合评价为:兄弟节点的右孩子为黑色
* 1、sr == null:兄弟的右孩子为黑色(空节点的颜色其实也是黑色)
* 2、!sr.red:兄弟节点的右孩子颜色为黑色
*/
if (sr == null || !sr.red) {
/**
* sl != null:兄弟的左孩子是存在且颜色是红色的
* 情况2-2、兄弟节点右孩子为黑色、左孩子为红色
* 处理方式:兄弟节点的左孩子设为黑色,兄弟节点设为红色,以兄弟节点为支点进行右旋,重新设置x的兄弟节点,继续参与自平衡
*/
if (sl != null)
sl.red = false;
xpr.red = true;
root = rotateRight(root, xpr);
xpr = (xp = x.parent) == null ? null : xp.right;
}
/**
* 情况2-3、兄弟节点的右孩子是红色
* 处理方式:
* 1、如果兄弟节点存在,兄弟节点的颜色设置为父节点的颜色
* 2、兄弟节点的右孩子存在,颜色设为黑色
* 3、如果父节点存在,将父节点的颜色设为黑色
* 4、以父节点为支点进行左旋
*/
if (xpr != null) {
xpr.red = (xp == null) ? false : xp.red;
if ((sr = xpr.right) != null)
sr.red = false;
}
// 父节点不为空
if (xp != null) {
xp.red = false;
root = rotateLeft(root, xp);
}
// 替换节点指向根节点,平衡完成
x = root;
}
}
} else {
// X为黑色 右侧分支
/**
* 替换节点是父节点的右孩子节点
* 情况1、兄弟节点存在且为红色
* 处理方式:兄弟节点变黑,父节点变红,以父节点为支点进行左旋,重新获取兄弟节点,继续参与自平衡
*/
if (xpl != null && xpl.red) {
xpl.red = false;
xp.red = true;
root = rotateRight(root, xp);
xpl = (xp = x.parent) == null ? null : xp.left;
}
// 不存在兄弟节点,x指向父节点,向上调整
if (xpl == null)
x = xp;
else {
// sl-兄弟节点的左孩子,sr-兄弟节点的右孩子
HashMap.TreeNode<K, V> sl = xpl.left, sr = xpl.right;
/**
* 情况2-1:兄弟节点存在,且两个孩子的颜色均为黑色
* 1、sr == null || !sr.red:兄弟的右孩子为黑色(空节点的颜色其实也是黑色)
* 2、sl == null || !sl.red:兄弟的左孩子为黑色(空节点的颜色其实也是黑色)
* 处理方式:兄弟节点为红色,替换节点指向父节点,继续参与自平衡
*/
if ((sl == null || !sl.red) && (sr == null || !sr.red)) {
xpl.red = true;
x = xp;
} else {
/**
* 该条件综合评价为:兄弟节点的左孩子为黑色
* 1、sr == null:兄弟的左孩子为黑色(空节点的颜色其实也是黑色)
* 2、!sr.red:兄弟节点的左孩子颜色为黑色
*/
if (sl == null || !sl.red) {
/**
* sl != null:兄弟的右孩子是存在且颜色是红色的
* 情况2-2、兄弟节点左孩子为黑色、右孩子为红色
* 处理方式:兄弟节点的右孩子设为黑色,兄弟节点设为红色,以兄弟节点为支点进行左,重新设置x的兄弟节点,继续参与自平衡
*/
if (sr != null)
sr.red = false;
xpl.red = true;
root = rotateLeft(root, xpl);
xpl = (xp = x.parent) == null ? null : xp.left;
}
/**
* 情况2-3、兄弟节点的左孩子是红色
* 处理方式:
* 1、如果兄弟节点存在,兄弟节点的颜色设置为父节点的颜色
* 2、兄弟节点的左孩子存在,颜色设为黑色
* 3、如果父节点存在,将父节点的颜色设为黑色
* 4、以父节点为支点进行右旋
*/
if (xpl != null) {
xpl.red = (xp == null) ? false : xp.red;
if ((sl = xpl.left) != null)
sl.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateRight(root, xp);
}
// 替换节点指向根节点,平衡完成
x = root;
}
}
}
}
}
get(Object key)方法
当 HashMap 只存在数组,而数组中没有Node链表时,是HashMap查询数据性能最好的时候。
一旦发生大量的哈希冲突,就会产生 Node 链表,这个时候每次查询元素都可能遍历 Node 链表,从而降低查询数据的性能。
特别是在链表长度过长的情况下,性能明显下降,使用红黑树就很好地解决了这个问题,红黑树使得查询的平均复杂度降低到了O(log(n)),链表越长,使用红黑树替换后的查询效率提升就越明显。
get(Object key)方法执行流程如下:
get(Object key)源码如下:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//数组不为null,数组长度大于0,根据hash计算出来的槽位的元素不为null
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//查找的元素在数组中,返回该元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) { //查找的元素在链表或红黑树中
if (first instanceof TreeNode) //在红黑树中查找
//遍历链表,元素在链表中,返回该元素
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
//遍历链表,元素在链表中,返回该元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
关于红黑树
HashMap使用了数组+链表+红黑树三种数据结构相互结合的形式存储键值对,提升了查询键值对的效率。
关于红黑树的知识,非常重要,尼恩专门写了一篇长长的文章,也是结合面试题写的,作为尼恩Java面试宝典的 专题33。
该PDF的名字为:
《尼恩Java面试宝典专题33:BST、AVL、RBT红黑树、三大核心数据结构(卷王专供+ 史上最全 + 2023面试必备》
很多小伙伴评价,通过此文,终于搞懂了红黑树。 建议大家去看看。
最后总结一下本文:
本文通过首先hashmap的学习,重点是要学会hashMap的思想,在实际开发中如何去引用hashMap的思路去解决问题,如何更好的使用HashMap,优化HashMap的性能。
尼恩提示:要想拿高薪,首先hashmap、手写 线程池,都是必须课哈。
作者介绍:
本文1作: 唐欢,资深架构师, 《Java 高并发核心编程 加强版》作者之1 。
本文2作: 尼恩,40岁资深老架构师, 《Java 高并发核心编程 加强版 卷1、卷2、卷3》创世作者, 著名博主 。 《K8S学习圣经》《Docker学习圣经》等11个PDF 圣经的作者。
参考文献:
清华大学出版社《Java高并发核心编程 卷2 加强版》
《尼恩Java面试宝典专题33:BST、AVL、RBT红黑树、三大核心数据结构(卷王专供+ 史上最全 + 2023面试必备》
技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
免费获取11个技术圣经PDF:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号