K8S圣经12:SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布
文章很长,持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布
尼恩的技术社群中(50+),尼恩一直到指导大家面试, 指导大家做简历优化。
生产环境 ,如何进行SpringCloud+Jenkins+ K8s Ingress 灰度发布, 是很多小伙伴都没有实操过的难题。
但是,灰度实操,又是高级开发,和架构师的必须课。 很多小伙伴,由于不懂灰度,不懂云原生,错失了高级开发或者架构师岗位,实在非常可惜。
所以,尼恩基于《K8S学习圣经》, 为大家系统化从原理到实操,介绍一下SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布。作为《K8S学习圣经》的12部分。
《K8S学习圣经》的组成
- 第一部分:云原生(Cloud Native)的原理与演进
- 第二部分:穿透K8S的8大宏观架构
- 第三部分:最小化K8s环境实操
- 第四部分:Kubernetes 基本概念
- 第五部分:Kubernetes 工作负载
- 第六部分:Kubernetes 的资源控制
- 第七部分: SVC负载均衡底层原理
- 第八部分: Ingress底层原理和实操
- 第九部分: 蓝绿发布、金丝雀发布、滚动发布、A/B测试 实操
- 第十部分: 服务网格Service Mesh 宏观架构模式和实操
- 第十一部分: 使用K8S+Harber 手动部署 Springboot 应用
- 第十二部分: SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布
- 第十三部分: k8s springboot 生产实践(高可用部署、基于qps动态扩缩容、prometheus监控)
- 第十四部分:k8s生产环境容器内部JVM参数配置解析及优化
米饭要一口一口的吃,不能急。
结合《K8S学习圣经》,尼恩从架构师视角出发,左手云原生+右手大数据 +SpringCloud Alibaba 微服务 核心原理做一个宏观的介绍。由于内容确实太多, 所以写多个pdf 电子书:
(1) 《 Docker 学习圣经 》PDF (V1已经完成)
(2) 《 SpringCloud Alibaba 微服务 学习圣经 》PDF (V1已经完成)
(3) 《 K8S 学习圣经 》PDF (coding…)
(4) 《 flink + hbase 学习圣经 》PDF (planning …)
以上学习圣经,并且后续会持续升级,从V1版本一直迭代发布。 就像咱们的《 尼恩 Java 面试宝典 》一样, 已经迭代到V60啦。
40岁老架构师尼恩的掏心窝: 通过一系列的学习圣经,带大家穿透“左手云原生+右手大数据 +SpringCloud Alibaba 微服务“ ,实现技术 自由 ,走向颠覆人生,让大家不迷路。
本PDF 《K8S 学习圣经》完整版PDF的 V1版本,后面会持续迭代和升级。供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
以上学习圣经的 基础知识是 尼恩的 《高并发三部曲》,建议在看 学习圣经之前,一定把尼恩的《 Java高并发三部曲 》过一遍,切记,切记。
本部分目录(第12部分)
如何进行 SpringCloud+Jenkins+ K8s Ingress 灰度发布?
生产环境 ,如何进行SpringCloud+Jenkins+ K8s Ingress 灰度发布, 是很多小伙伴都没有实操过的难题。
但是,这些又是高级开发,和架构师的必须课。
在 Kubernetes 上的应用实现灰度发布,最简单的方案是引入官方的 Nginx-ingress 来实现。我们通过部署两套 deployment 和 services,分别代表灰度环境和生产环境,通过负载均衡算法,实现对两套环境的按照灰度比例进行分流,进而实现灰度发布。
通常的做法是当项目打包新镜像后,通过修改 yaml 文件的镜像版本,执行 kubectl apply 的方式来更新服务。
如果发布流程还需要进行灰度发布,那么可以通过调整两套服务的配置文件权重来控制灰度发布,这种方式离不开人工执行。
那么,有没有一种方式能够实现逐步灰度呢?比如自动将灰度比例从 10% 权重提高到 100%,且并且出现问题秒级回退.
答案是肯定的,利用 jenkins 就能够满足此类需求。
本文,为大家介绍一下,SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布
回顾 Nginx-ingress 架构和原理
回顾一下 Nginx-ingress 的架构和实现原理:

Nginx-ingress 通过前置的 Loadbalancer 类型的 Service 接收集群流量,将流量转发至 Nginx-ingress Pod 内并对配置的策略进行检查,再转发至目标 Service,最终将流量转发至业务容器。
传统的 Nginx 需要我们配置 conf 文件策略。
但 Nginx-ingress 通过实现 Nginx-ingress-Controller 将原生 conf 配置文件和 yaml 配置文件进行了转化,当我们配置 yaml 文件的策略后,Nginx-ingress-Controller 将对其进行转化,并且动态更新策略,动态 Reload Nginx Pod,实现自动管理。
那么 Nginx-ingress-Controller 如何能够动态感知集群的策略变化呢?
方法有很多种,可以通过 webhook admission 拦截器,也可以通过 ServiceAccount 与 Kubernetes Api 进行交互,动态获取。
Nginx-ingress-Controller 使用后者来实现。所以在部署 Nginx-ingress 我们会发现 Deployment 内指定了 Pod 的 ServiceAccount,以及实现了 RoleBinding ,最终达到 Pod 能够与 Kubernetes Api 交互的目的。
灰度实操之前的准备
部署一套稳定版本的 deployment 和 svc
然后再部署一套灰度版本的 deployment 和 svc
在进行流量的分发测试
部署和测试 stable 版本的 deployment 和 svc
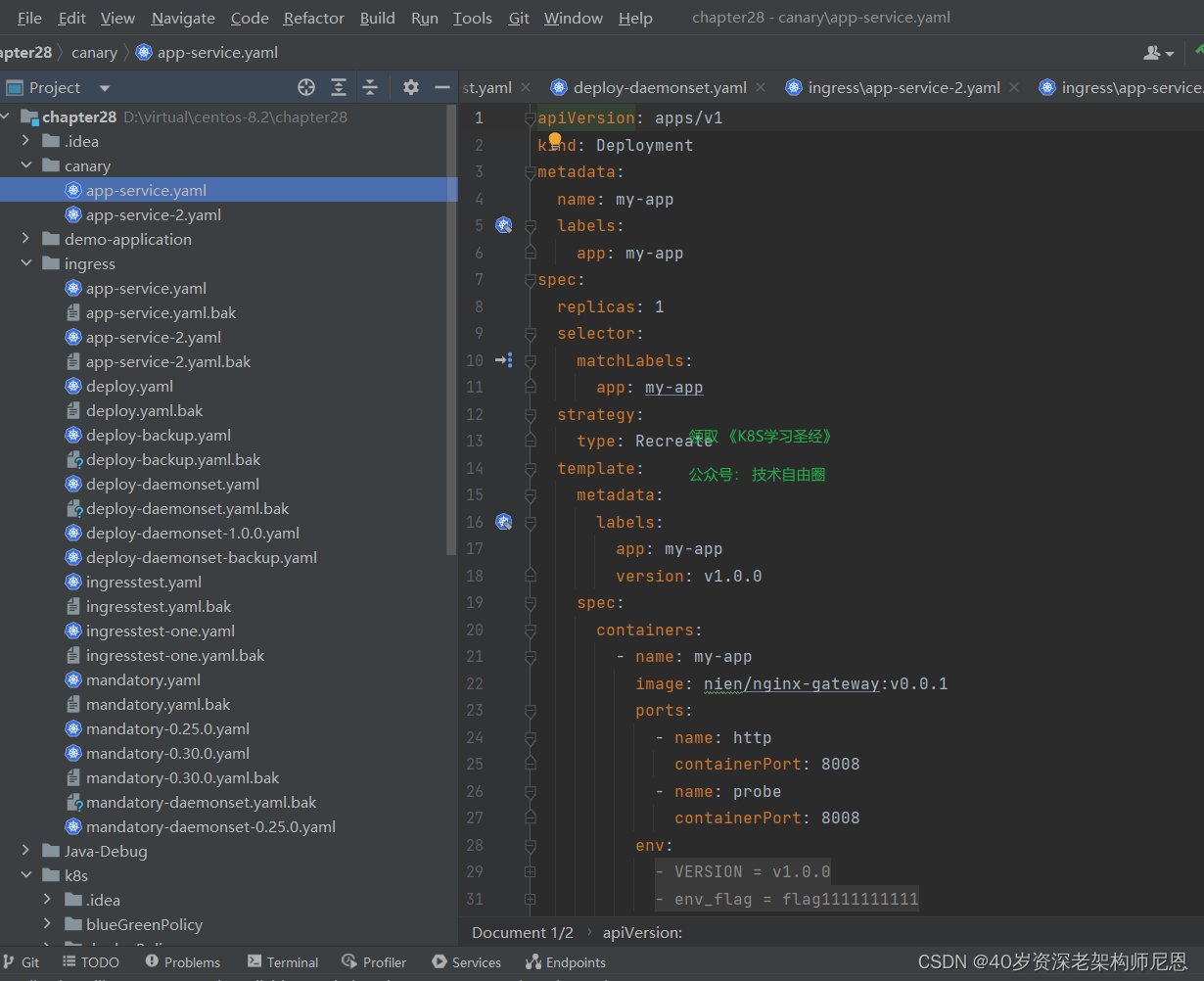
kubectl apply -f app-service.yaml 部署一下

访问一下
curl http://192.168.49.2:30808
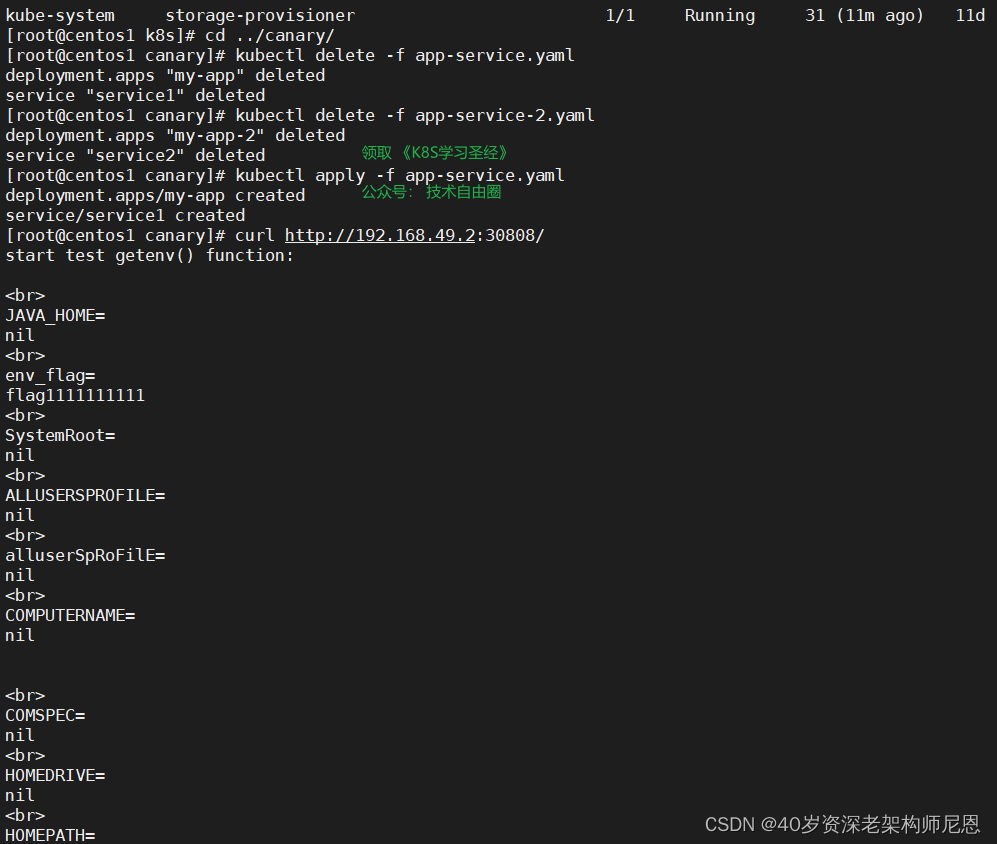
部署和测试 canary版本的 deployment 和 svc
canary版本 的 deployment 和 svc

kubectl apply -f app-service.yaml 部署一下

访问一下
curl http://192.168.49.2:30909

以上具体的实操过程, 请参见 尼恩的 《穿透云原生视频》
基于用户的灰度场景
简单的基于用户的发布场景, ingress 需要加上注解:
nginx.ingress.kubernetes.io/canary:"true"
nginxingress.kubernetes.io/canary-by-header:"canary"
用户的Request Header 的值有一个 canary header,当 canary header的值:
当 设置为 always时,请求将会被一直发送到 Canary 版本;
当 设置为 never时,请求不会被发送到 Canary 入口;
对于任何其他 Header 值,将忽略 Header,并通过优先级将请求与其他金丝雀规则进行优先级的比较。
具体如下图:

如果用户要自定义 Request Header 的值,必须与canary-by-header 注解(annotation )一起使用。
这里的例子,使用 nginx.ingress.kubernetes.io/canary-by-header,自定义 Request Header 进行流量切分,适用于灰度发布以及 A/B 测试。
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "region"
nginx.ingress.kubernetes.io/canary-by-header-value: "beijing"
此灰度规则为:要匹配的 Request Header 的值,用于通知 Ingress 将请求路由到 Canary Ingress 中指定的服务。

如果按照的配置,
当 Request Header的 region 设置为 beijing时,请求将会被一直发送到 Canary 版本;
当 Request Header 没有 region,或者 设置为非 beijing时,请求不会被发送到 Canary 入口;
接下来,开始基于 用户的灰度实操
配置stable版本的ingress

配置canary版本的ingress

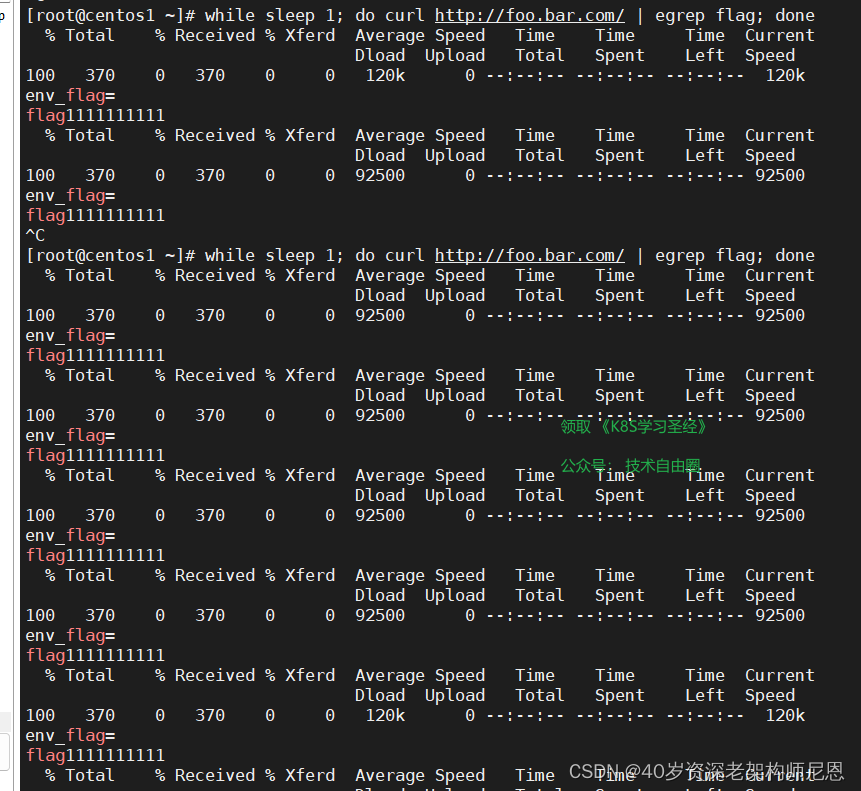
当我们访问的时候不带header,则只会访问stable版本应用,如下:
while sleep 1; do curl http://foo.bar.com/ | egrep flag; done
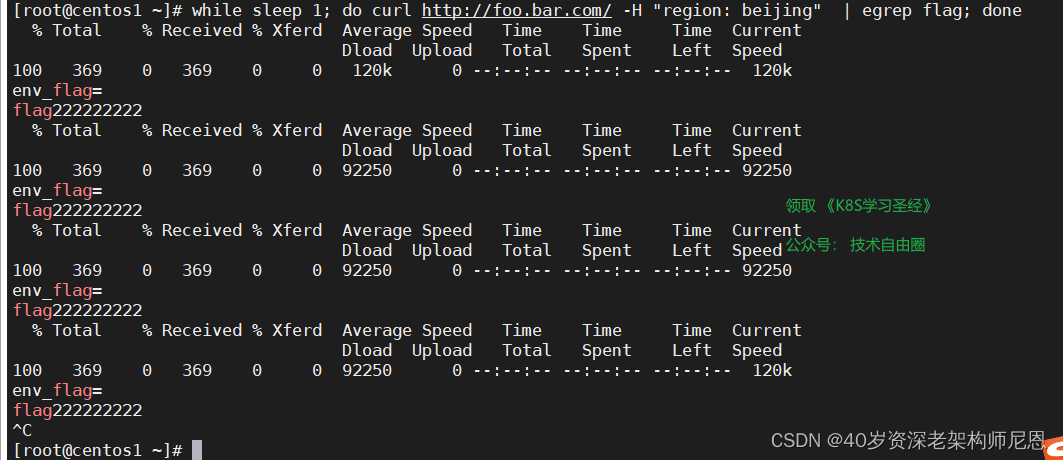
如果我们在访问的时候带上region: sichuan 的header,则只会访问到canary版本应用,如下:
while sleep 1; do curl http://foo.bar.com/ -H "region: beijing" | egrep flag; done
以上具体的实操过程, 请参见 尼恩的 《穿透云原生视频》
基于权重的灰度场景
基于权重的 Canary 规则
使用 nginx.ingress.kubernetes.io/canary-weight 注解:
基于服务权重的流量切分,适用于蓝绿部署,权重范围 0 - 100 按百分比将请求路由到 Canary Ingress 中指定的服务。
权重为 0 意味着该金丝雀规则不会向 Canary 入口的服务发送任何请求。
权重为 100 意味着所有请求都将被发送到 Canary 入口。

基于权重的发布实操
(1)配置stable版本的ingress
同基于用户的灰度场景,这里不做赘述
(2)配置canary版本的ingress
具体如下。 源文件可以找尼恩获取。

(3) 启动 基于权重的灰度 ingress

(4)然后我们通过访问测试,效果如下:
while sleep 1; do curl http://foo.bar.com/ | egrep flag; done
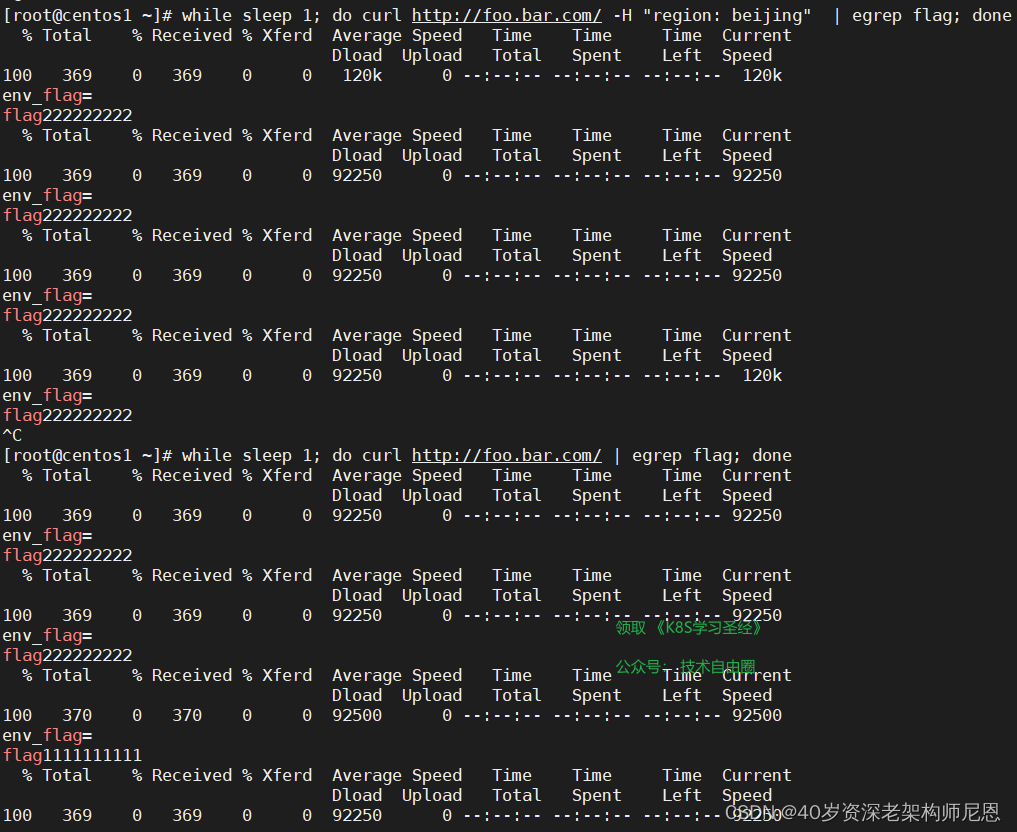

以上具体的灰度实操过程, 请参见 尼恩的 《穿透云原生视频》
如何进行自动化灰度?
在生产环境,通过上面的手工命令,一行一行的执行是不现实的
需要借助自动化的流水线
jenkins 安装和 pipeline 流水线的使用
Jenkins pipeline是基于Groovy语言实现的DSL,用于描述流水线如何进行,包括编译、打包、部署、测试等等步骤
此处我们使用离线安装包方式安装/docker-compose 的方式安装
Jenkins 官网:https://www.jenkins.io
官方安装文档指导:https://www.jenkins.io/doc/book/installing/
下载和启动 jenkins
这里简单介绍一下 Jenkins 的本机部署方式.
一般都是下载一个 Jenkins 的 war, 修改配置文件中的 JDK 路径, 然后 service start 就可以正常使用了.
我们在服务器上执行如下命令进行jenkins可运行包下载
mkdir -p /usr/local/jenkins
cd /usr/local/jenkins
下载这个包 https://get.jenkins.io/war-stable/2.375.1/jenkins.war
复制Jenkins war包到 安装目录
cp /vagrant/chapter28/jenkins.2.375.1.war .
找一个 start-jenkins.sh 脚本去启动jenkins。这个shell 和springboot的启动脚本一样,启动命令可以接参数start|restart|stop 分别标识启动,重启,停止服务
复制启动脚本到 安装目录
cp /vagrant/chapter28/deploy_jenkins.sh .
脚本内容如下:

给启动脚本执行权限,并启动jenkins
chmod +x start-jenkins.sh
sh start-jenkins start
查看日志
tail -f nohup.out

这种方式部署简单, 但是容易将我们的服务器环境变得十分复杂.
所以下面介绍本节docker-compose 搭建 Jenkins.
尼恩的环境,首先使用的这种方式。但是发现一个问题,新版本的 jenkins 需要依赖 jdk11, jkd8 不能用了
而尼恩的 公司有要求,一定要用jkd8
所以只能用 docker 安装 jenkins ,实现jdk的隔离。
docker-compose 编排文件 如下:

volumes:
#Jenkins 工作目录,主要存储数据( /user/data/jenkins,安装后初始化密码也在此处 /secrets/initialAdminPassword )
- ./data:/var/jenkins_home'
#将主机的Docker套接字装入容器中,这将允许Jenkins容器使用主机的Docker守护进程来构建映像并运行容器。
- '/var/run/docker.sock:/var/run/docker.sock'
#容器内可共享宿主机的 docker
- '/usr/bin/docker:/usr/bin/docker'
#容器内享有 宿主机的docker-compose 环境
- '/usr/local/bin/docker-compose:/usr/local/bin/docker-compose'
使用尼恩的一键启动shell脚本,一键启动
具体实操,请参见尼恩视频

首次登录需要查看初始化密码:( 挂载数据文件内可以查看 )
cat ./secrets/initialAdminPassword

需要修改插件的镜像源地址为
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
具体的修改方式为,修改

修改后,重新启动,就可以从清华大学的插件镜像站,下载插件了

接下来访问 jenkins
登录 jenkins
查看启动日志,看到初始化管理员密码数据即表示启动成功,
copy对应的密码,通过ip+port方式进行访问,
上面shell 脚本中指定的端口为8980,我们在启动日志中也能够看到启动的端口为8090。
在浏览器中输入:
http://cdh1:8980
终于看到jenkins的登录界面

输入密码后,安装插件

点击选择插件来安装,然后取消掉几个默认安装的插件

插件安装完毕,有几个失败的,无所谓
关键是 pipeline 插件安装好了就行
接下来,创建第一个管理员用户
全部填 admin

进行一下实例配置

保存后完成

使用 pipeline 插件
Jenkins Pipeline是一套插件,支持在Jenkins中实施和集成持续交付管道。pipeline是部署流水线,它支持脚本和声明式语法,能够比较高自由度的构建jenkins任务.个人推荐使用这种方式去构建jenkins。
Pipeline在Jenkins上增加了一套强大的自动化工具,支持从简单的持续集成到全面的CD管道的用例。通过对一系列相关任务建模,用户可以利用Pipeline的更多功能,如:
- 可维护:管道是在代码中实现的,并且通常会被签入源代码管理,从而使团队能够编辑,审阅和迭代他们的交付管道。
- 可能出现:在继续进行管道运行之前,管道可以选择停止并等待人员输入或批准。
- 复杂场景:管道支持复杂的实际CD需求,包括分叉/连接,循环和并行执行工作的能力。
- 可扩展性:Pipeline插件支持对其DSL的定制扩展 。
一次持续交付(CD)管道是从用户到版本控制软件的自动化表达。对软件的每一次改变(在源代码控制中提交)都会在发布过程中经历一个复杂的过程。
这个过程包括以可靠和可重复的方式构建软件,以及通过测试和部署的多个阶段来推进构建的软件(称为“构建”)。
Pipeline提供了一套可扩展的工具,用于通过管道域特定语言(DSL)语法将“简单到复杂”的交付管道使用“代码”建模 。
安装 Pipeline 插件
如果没有安装 Pipeline 插件,那么还需要单独安装 Jenkins Pipeline 插件
注意,默认 Jenkins 使用 https://updates.jenkins.io/update-center.json 下载并安装扩展,但是速度较慢。
我们可以修改为使用国内镜像站点,比如清华大学镜像站点:
1)Manage Jenkins / Manage Plugins / Advanced
2)Update Site / URL https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
3)Submit
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
pipeline 的 hello world
pipeline是部署流水线,它支持脚本和声明式语法。
通过界面手动配置来配置CD过程,想要配置一些复杂度高的任务,只能选择自由风格的项目,通过选项等操作进行配置,让jenkins可以下载代码、编译构建、然后部署到远程服务器,这样显然是不方便管理和移植的。
pipeline可以创建一个jenkinsfile来申明一个任务,方便管理和移植。
接下来我们创建一个最简单的pipeline。
登录jenkins,点击创建item:

在流水线中选择hello world 生成代码:

以上便是一个最简单的流水线。
点击build now (立即构建),jenkins任务开始执行,运行完成后点击查看执行记录:
在console output 中可以看到运行记录:

为了提高流水线的复用性以及便于流水线代码的管理,更多的是将pipeline的脚本在远程git仓库,当我们修改了远程仓库的流水线脚本,jenkins就会加载到最新的脚本执行。
在流水线配置中选择pipeline script from SCM:

按照提示配置好脚本git仓库地址,访问仓库的凭证,流水线脚本文件的名称(默认是Jenkinsfile),分支(默认是master)等。
配置完成后在仓库中添加文件Jenkinsfile把脚本提交并push, 最后执行任务,发现执行成功。
通过这个特性,我们可以把我们的流水线脚本和项目代码本身放到一个仓库中管理,达到多版本控制并和代码版本统一的效果。
如果我们编写jenkinsfile需要语法提示相关的编辑器,可以使用jenkins官方提供的vscode插件Jenkins Pipeline Linter Connector 。
使用idea Groovy 也能提示部分语法。
idea 设置jenkinsfile 语法提示方法 settings > editor > File Types > Groovy 新增一列Jenkinsfile.
pipeline 语法介绍
jenkins pipeline有2种语法:脚本式(Scripted)语法和声明式(Declar-ative)语法。
pipeline插件从2.5版本开始同时支持两种语法,官方推荐的是使用申明式语法,
在这里也只对申明式语法进行介绍。
申明式语法demo:
pipeline {
agent any
stages {
stage('pull') {
steps {
echo '拉取代码'
}
}
stage('build') {
steps {
echo '构建代码'
}
}
}
}
声明式语法中,以下结构是必须的,缺少就会报错:
- pipeline:固定语法,代表整条流水线
- agent 执行代理人:指定流水线在哪执行,
默认any即可,也可以指定在docker、虚拟机等等里执行
- environment 环境变量,类似全局变量
environment {
//构建执行者
BUILD_USER = ""
}
- triggers 构建触发器,Jenkins自动构建条件
triggers{
//每3分钟判断一次代码是否有变化
pollSCM('H/3 * * * *')
}
-
stages:流水线阶段集合节点
该节点中至少有一个stage
-
stage:流水线的阶段节点
每个阶段中至少包含一个steps
-
steps:执行步骤集合
每个集合至少包含一个step。
-
step: 执行步骤。
下面是一个比较大的例子
pipeline {
//代理,通常是一个机器或容器
agent any
//环境变量,类似全局变量
environment {
//构建执行者
BUILD_USER = ""
}
//构建触发器,Jenkins自动构建条件
triggers{
//每3分钟判断一次代码是否有变化
pollSCM('H/3 * * * *')
}
stages {
//构建阶段
stage('Build') {
//使用build user vars插件,获取构建执行者
steps {
wrap([$class: 'BuildUser']) {
script {
//将构建执行者注入到环境变量中,方便最后通知使用
BUILD_USER = "${env.BUILD_USER}"
}
}
/* 从Bitbucket上拉取分支
* @url git地址
* @branch 分支名称
* @credentialsId Jenkins凭证Id,用于远程访问
*/
git(url: 'https://demo@bitbucket.org/demo/demo.git', branch: 'master', credentialsId: 'Bitbucket')
//执行maven打包
//-B --batch-mode 在非交互(批处理)模式下运行(该模式下,当Mven需要输入时,它不会停下来接受用户的输入,而是使用合理的默认值);
//打包时跳过JUnit测试用例,
//-DskipTests 不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下
//-Dmaven.test.skip=true,不执行测试用例,也不编译测试用例类
sh 'npm install && npm run build'
}
}
//部署阶段
stage('Deliver') {
steps {
//执行脚本
sh '''
cd /var/lib/jenkins/workspace/demo/
tar -cvf dist.tar.gz ./dist
'''
}
}
stage('SSH') {
steps {
script {
def remote = [:]
remote.name = 'test'
remote.host = '192.168.12.12'
remote.allowAnyHosts = true
withCredentials([usernamePassword(credentialsId: '192.168.12.12', passwordVariable: 'password', usernameVariable: 'username')]) {
remote.user = "${username}"
remote.password = "${password}"
}
sshCommand remote: remote, command: "pwd"
sshRemove remote: remote, path: '/usr/share/nginx/html/demo/dist'
sshPut remote: remote, from: '/var/lib/jenkins/workspace/demo/dist.tar.gz', into: '/usr/share/nginx/html/test-monitor/'
sshCommand remote: remote, command: "cd /usr/share/nginx/html/demo/ && tar -xvf ./dist.tar.gz"
}
}
}
}
}
Jenkins 插件 SSH Pipeline Steps
安装插件 SSH Pipeline Steps, 以支持 跨机器执行脚本。
此插件可通过SSH在远程服务器执行命令和传输文件。
sshCommand 在远程节点上执行给定的命令并响应输出
node {
def remote = [:]
remote.name = 'root'
remote.host = 'cdh1'
remote.user = 'root'
remote.password = 'vagrant'
remote.allowAnyHosts = true
stage('Remote SSH') {
sshCommand remote: remote, command: "ls -lrt"
sshCommand remote: remote, command: "for i in {1..5}; do echo -n \"Loop \$i \"; date ; sleep 1; done"
}
}
sshGet 从远程主机获取文件或目录
node {
def remote = [:]
remote.name = 'test'
remote.host = 'test.domain.com'
remote.user = 'root'
remote.password = 'password'
remote.allowAnyHosts = true
stage('Remote SSH') {
sshGet remote: remote, from: 'abc.sh', into: 'abc_get.sh', override: true
}
}
sshPut 将文件或目录放入远程主机
node {
def remote = [:]
remote.name = 'test'
remote.host = 'test.domain.com'
remote.user = 'root'
remote.password = 'password'
remote.allowAnyHosts = true
stage('Remote SSH') {
writeFile file: 'abc.sh', text: 'ls -lrt'
sshPut remote: remote, from: 'abc.sh', into: '.'
}
}
sshRemove 删除远程主机上的文件或目录
node {
def remote = [:]
remote.name = 'test'
remote.host = 'test.domain.com'
remote.user = 'root'
remote.password = 'password'
remote.allowAnyHosts = true
stage('Remote SSH') {
sshRemove remote: remote, path: "abc.sh"
}
}
sshScript 在远程节点上执行给定的脚本(文件)并响应输出
node {
def remote = [:]
remote.name = 'test'
remote.host = 'test.domain.com'
remote.user = 'root'
remote.password = 'password'
remote.allowAnyHosts = true
stage('Remote SSH') {
writeFile file: 'abc.sh', text: 'ls -lrt'
sshScript remote: remote, script: "abc.sh"
}
}
结合 withCredentials 从 Jenkins 凭证存储中读取私钥
为了提高安全性,可以用Credentials Plugin屏蔽用户名密码。
def remote = [:]
remote.name = "node-1"
remote.host = "10.000.000.153"
remote.allowAnyHosts = true
node {
withCredentials([sshUserPrivateKey(credentialsId: 'sshUser', keyFileVariable: 'identity', passphraseVariable: '', usernameVariable: 'userName')]) {
remote.user = userName
remote.identityFile = identity
stage("SSH Steps Rocks!") {
writeFile file: 'abc.sh', text: 'ls'
sshCommand remote: remote, command: 'for i in {1..5}; do echo -n \"Loop \$i \"; date ; sleep 1; done'
sshPut remote: remote, from: 'abc.sh', into: '.'
sshGet remote: remote, from: 'abc.sh', into: 'bac.sh', override: true
sshScript remote: remote, script: 'abc.sh'
sshRemove remote: remote, path: 'abc.sh'
}
}
}
pipeline支持的指令
pipeline的基本结构满足不了现实多变的需求。所以,jenkins pipeline通过各种指令(directive)来丰富自己。
Jenkins pipeline支持的指令有:
- environment:用于设置环境变量,可定义在stage或pipeline部分
- tools:可定义在pipeline或stage部分。它会自动下载并安装我们指定的工具,并将其加入PATH变量中
- input:定义在stage部分,会暂停pipeline,提示你输入内容
- options:用于配置jenkins pipeline本身的选项,比如options { retry(3) }表示,当pipeline失败时再重试2次。options指令可定义在stage或pipeline部分
- parallel:并行执行多个step。
- parameters:与input不同,parameters是执行pipeline前传入的一些参数
- triggers:用于定义执行pipeline的触发器
- when:当满足when定义的条件时,阶段才执行。
ingress 灰度发布流水线设计
在使用ingress 进行灰度之前,直接使用service+deployment的方式进行灰度。这种场景下,可以 通过不同的镜像(含deployment)来进行灰度大概的流程如下:
- 发布canary版本应用进行测试
- 测试完成将canary版本替换成stable版本
- 删除canary版本的ingress配置
- 删除老的stable版本
整个过程中,对于已经部署好的deployment是不能直接修改labels标签的。
所以,在canary版本测试完成后,还要更新stable版本的镜像。当然,可以使用滚动更新的方式去完成。那我们流水线可以这样设计,如下:

在使用ingress 进行灰度之后,灰度测试通过之后,就使用灰度镜像作为new stable 镜像使用,不需要重新的打包镜像,
但是在发布期间,线上同时会存在旧的 old stable 和 canary 两套镜像, 虽然浪费一些资源,但是好处随时可以回退。
其实尼恩告大家,版本的发布是惊心动魄, 回退的概率非常大。 同时存在两套版本,实现s级回退, 也是一件非常爽的事情。
在使用ingress 进行灰度之后,灰度的流程,可以变得更加灵活,更加丰富,更加稳健。
在使用ingress 进行灰度 ,总体流程为3部分,大致如下:

CICD 流水线预览
为了实现以上目标,我们设计了以下持续部署流水线。

AB测试和灰度,部署流水线主要实现了以下几个步骤:
1、自动化的制品发布,通过gitlab进行自动化打包之后,通过钩子方法触发流水线,打包镜像到harber仓库
2、生产环境进行 A/B 测试
3、生产环境自动灰度发布(自动进行4次逐渐提升灰度比例)
4、生产环境进行版本正式切换
step1:自动化的制品发布
自动化的制品发布流程图:

从 Gitlab 提交代码到自动触发持续集成的步骤:
1、提交代码后触发持续集成,自动构建镜像
2、镜像构建完成后,自动推送镜像到制品库
3、触发持续部署
在gitlab上, 有回调jenkins的hook 链接设置,设置之后,可以触发 jenkins 的 自动化制品构建流水线。
这里的制品就是docker 镜像。 制品的 仓库就是harber。
模拟的 制品构建流水线如下
具体的步骤,大概如下:
1、克隆 springboot代码项目到本地
stage('Clone') {
echo "1.Clone Stage"
git url: "https://gitee.com/xujk-27400861/springboot-dubbo.git"
script {
build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
}
echo "${build_tag}"
}
2、maven构建springboot代码项目
编写脚本,因为我们要编译构建项目的子项目,所以需要跳转到子目录去构建
stage('执行构建') {
container('maven')
{
sh "mvn --version"
sh 'pwd'
sh '''cd provider/
mvn clean package -DskipTests'''
//sh 'mvn package'
echo '构建完成'
}
}
provider/为项目子目录,我们要编译的项目;-DskipTests参数,表示跳过代码测试
3、构建docker镜像
编写脚本,构建docker镜像;
stage('Build') {
echo "3.Build Stage"
container('docker') {
sh "docker -v"
sh 'pwd'
sh """cd /home/jenkins/agent/workspace/linetest/provider/
ls
docker build -t xjk27400861/springbootapp:${build_tag} ."""
}
}
4、推送docker镜像到harber上,完成制品发布
编写脚本,推送docker镜像;
stage('Push') {
echo "4.Push Docker Image Stage"
container('docker') {
sh "docker login --username=xjk27400861 -p xujingkun@123"
sh "docker push xjk27400861/springbootapp:${build_tag}"
}
}
具体的实操,请参见 尼恩的云原生视频。
step2:生产环境进行 A/B 测试
进行 A/B 测试流程如下:

进行 A/B 测试时,只有 Header 包含 location=beijing 可以访问新版本,其他用户访问生产环境仍然为旧版本。
或者header可以设置为其他的参数。
这里要注意,可以把参与 A/B 测试 的用户,在数据库里边进行配置, 前端能带有AB测试的标志。

AB测试手动触发,流水线比较简单。

发布AB测试的ingress之后, 流量分发的架构图如下:

A/B 测试原理:
部署了两套应用,一套旧的稳定的stable应用,一套新版canary 灰度应用。
新旧的应用都配置了ingress相同的host。
而新的ingress还添加了注解canary:true 代表开启使用灰度发布
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "region"
nginx.ingress.kubernetes.io/canary-by-header-value: "beijing"
只有 Header 包含 location=beijing 的流量是会从new-ingress这个ingress进来访问新版本应用。
其他流量从old-ingress的ingress去访问老版本的应用。
具体的实操,请参见 尼恩的云原生视频。
step3:生产环境进行 A/B 测试
在AB测试通过之后,可以结束ab测试的ingress,通过 流水线结束。

接下来,开始灰度,一共四轮灰度
第一次灰度:新版本 30% 的灰度比例,此时访问生产环境大约有 30% 的流量进入新版本灰度环境:

30s 后自动进行第二轮灰度:新版本 60% 的灰度比例:
60s 后自动进行第三轮灰度:新版本 90% 的灰度比例:
60s 后自动进行第四轮灰度:新版本 100% 的灰度比例:
每一轮灰度,可以两种方式步进:
(1) 人工确认:是否自动灰度发布, 流水线上设置确认按钮, 单击确认进入下一步
(2) 定时步进:流水线上设置时间,比如每轮间隔 30s
本案例中,配置了定时步进方式,渐进式进行,每次持续 30s 后自动进入下一个灰度阶段。
灰度过程中的流量架构图,大致如下:
 在不同的灰度阶段,会发现请求新版本出现的概率越来越高。
在不同的灰度阶段,会发现请求新版本出现的概率越来越高。
灰度流水线的示意图如下;

如果过程当中需要回退,可以结束流水线,然后执行 灰度撤销流水线。
灰度撤销流水线的示意图,大致如下

jenkins 流水线上,更多的是shell脚本的编写
由此可见,shell脚本的编写能力,是多么重要
具体的实操,请参见 尼恩的云原生视频。
step4:生产环境进行版本正式切换
灰度版本稳定一段时间之后, 进行善后的工作
把老的稳定版本去掉, 完成生产环境进行版本正式切换
流程图如下:

步骤:
1、把stable-service指向访问cannary-deloyment
应为canary 已经足够稳定了
2、删除canary-ingress
不需要 灰度的ingress 了
3、删除canary-service
不需要灰度的svc 了
4、删除stable-deployment
不需要 老的stable-deployment 了
canary deployment 已经足够稳定了,已经编程新的stable deployment
具体的实操,请参见 尼恩的云原生视频。
最后总结一下
上面的灰度流程, 很多环节也是手动的,需要人工参与的。
如果不需要手动参与,可以使用argo-rollouts结合argocd进行灰度发布,argo-rollouts自定义了一套CRD用于控制发布流程,可以省去很多手动操作过程,argocd是基于gitops实现的一套软件,便于我们进行CD控制,也提供了UI面板进行操作。
但是线上发布, 是非常重要,非常谨慎的一个操作。
而且很容易出问题,及时有预发布环境, 也容易出问题, 常常出现紧急回退的场景。
在尼恩亲手尽力的几百次发布过程中, 回退是大概率事件。
常常进行版本回退。
所以,不建议使用全自动的发布流程,全自动无值守,往往意味着高风险。
一句话:背锅的滋味,不好受呀。
技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
以上尼恩 架构笔记、面试题 的PDF文件,请到《技术自由圈》公众号领取


 浙公网安备 33010602011771号
浙公网安备 33010602011771号