美团一面:InndoDB 单表最多 2000W,为什么?小伙伴竟然面挂
在疯狂创客圈 的社群面试交流中,有很多小伙伴在面大厂, 经常遇到下面的问题:
问题1:在实际生产环境中,InnoDB 中一棵 B+ 树索引一般有多少层?
问题2:在实际生产环境中,InnoDB一棵B+树可以存放多少行数据?
问题3:MySQL 对于千万级的大表,为啥要优化?
问题4:mysql 单表最好不要超过2000w?
问题5:单表超过2000w 就要考虑数据迁移了,这个是为啥?
问题6:你这个表数据都马上要到2000w 了,难怪查询速度慢,为什么?
问题N: ... 第100个变种
前段时间,有一个小伙伴在面美团里的时候,又遇到了此问题。
其实,这些问题,都是在考察大家对 B+树底层原理的理解
尼恩在这里,给大家做一个系统化、起底式、全方位的梳理。
按照下面的套路去答,基本可以拿到120分。
大家收藏起来,多度几遍,一定能让面试官刮目相看。
现在把这个 题目以及参考答案,收入咱们的 《尼恩Java面试宝典》,
供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
要回答这些问题,在回答的时候,首先从 InnoDB 索引数据结构、数据组织方式说起。
InnoDB 索引数据结构、数据组织方式
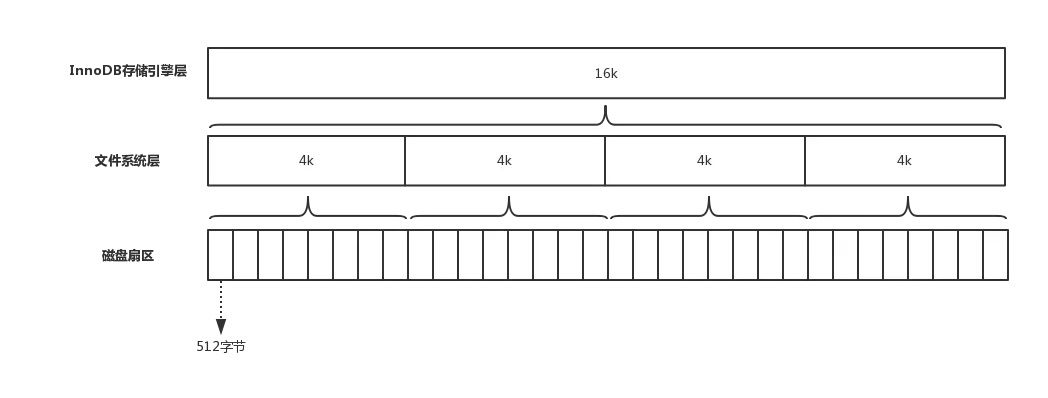
磁盘扇区、文件系统、InnoDB 存储引擎都有各自的最小存储单元。
来看看三个重要的最小单元
- 磁盘上,存储数据最小单元是扇区,一个扇区的大小是 512 字节,
- 文件系统(例如EXT4),最小单元是块 (block),一个block 块的大小是 4k,
- InnoDB 存储引擎 的最小储存单元——页(Page),一个页的大小是 16K。
来一个图,更清楚:
以上三个数据,非常重要,一定要背下来, 并且在面试的时候, 找个机会背出来。
面试官一听,感觉你的计算机底层知识是多么的扎实,好感慢慢。这是来自 老架构师的 尼恩 衷心提示。
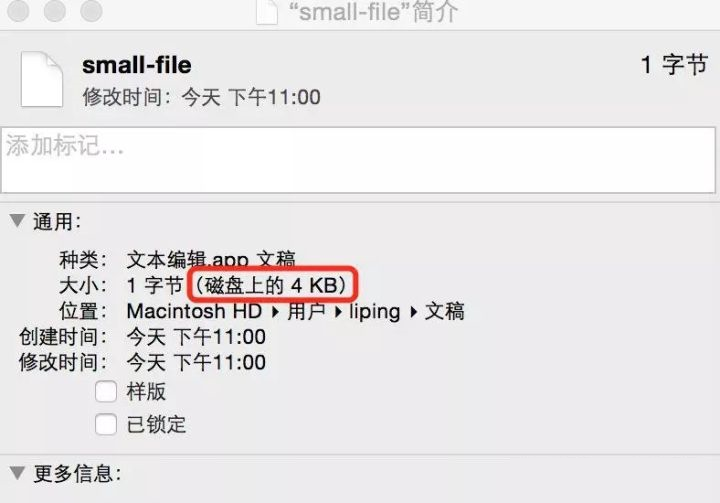
由于文件系统(例如EXT4)的最小单元是块 (block),一个block 块的大小是 4k,
所以,假设一个文件大小只有1个字节,那么,这个文件在磁盘上,还是不得不占4KB的空间。
具体如下图:
要知道,Innodb 的所有数据文件(后缀为 ibd 的文件),也是存储在磁盘的,当然也是由block组成,
所以,Innodb 的所有数据文件,全部都是 16384(16k)的整数倍。
具体如下图:

InnoDB 存储引擎 的最小储存单元——页(Page),一个页的大小是 16K,
在 MySQL 中我们的InnoDB 页的大小当然也可以通过参数设置的,具体如下图:
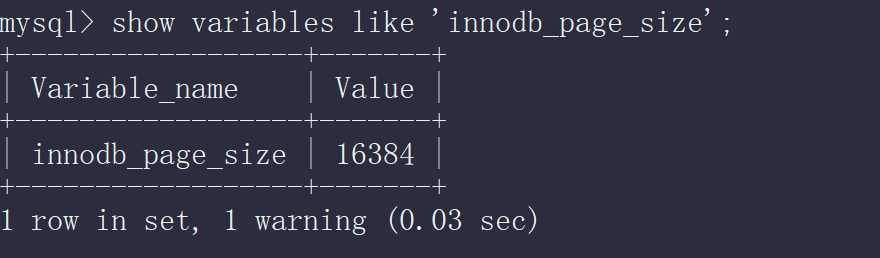
通过上图,可以看到,在 MySQL 中我们的 InnoDB 页的大小默认是 16k
InnoDB一棵B+树的查找流程
数据表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?
先做一个假设:
假设一行数据的大小是1k,
那么一个16K页,可以存放16行这样的数据。
如果数据库只按这样的方式存储,那么如何查找数据就成为一个问题
因为我们不知道要查找的数据存在哪个页中,也不可能把所有的页遍历一遍,那样太慢了。
所以人们想了一个办法,用B+树的方式组织这些数据。
- B+ 树的叶子节点存储真正的记录,对应的文件系统 page页面,可以叫做 数据页
- B+ 树的非叶子节点存放的是键值 + 指针,其对应的文件系统 page页面,可以叫做 索引页
这里用指针来描其实述不是太准确,准确来说是页的偏移量,不过借用指针一词,更好理解
如图所示:
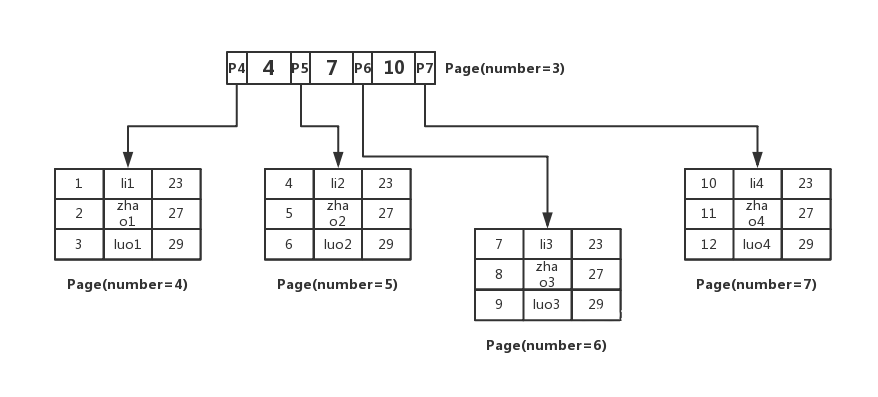
InnoDB中主键索引B+树是如何组织数据、查询数据的?
我们总结一下:
1、在B+树中叶子节点存放数据,非叶子节点存放键值+指针。
InnoDB存储引擎的最小存储单元是页,页可以用于存放数据也可以用于存放键值+指针,
2、页内的记录是有序的,所以可以使用二分查找在页内到下一层的目标页面的指针
- 从根页开始,首先通过非叶子节点的二分查找法,
- 确定数据在下一层哪个页之后,一层一层往下找,一直到非叶子节点,
- 进而在非叶子节(数据页)中查找到需要的数据;
那么回到我们开始的问题,通常一棵B+树可以存放多少行数据?
高为2的B+树可以存放多少行数据
首先,需要计算出非叶子节点能存放多少指针?
页作为 InnoDB 磁盘管理的最小单位,不仅可以用来存放具体的行数据,还可以存放键值和指针。
回到文题,我们先从简单的入手,
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么 B+ 树只有两层。
如下图:
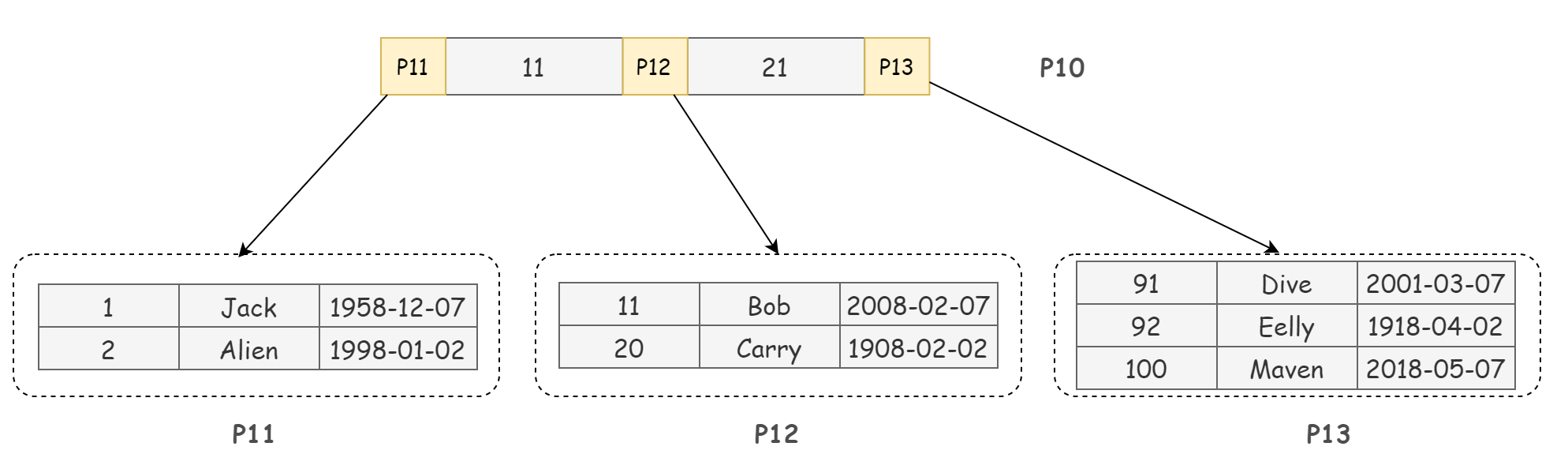
那么对于这棵 B+ 树能够存放多少行数据,其实问的就是这棵 B+ 树的非叶子节点中存放的数据量,
那么,这棵简单的 B+ 树能够存放多少行数据,其实问的就是这棵 B+ 树的非叶子节点中存放的数据量,
这棵B+树的存放总记录数为, 是一个简单的公式:
非叶子节点指针数 * 每个叶子节点存放的行记录数
每个叶子节点存放的行记录数就是每页存放的记录数,由于各个数据表中的字段数量都不一样,
这里我们就不深究叶子节点的存储结构了,
简单按照一行记录的数据大小为 1k 来算的话(实际上现在很多互联网业务数据记录大小通常就是 1K 左右),
一页(16K)或者说一个叶子节点可以存放 16 行这样的数据。
那么 ,这颗B+ 树 的非叶子节点( 唯一的)能够存储多少数据呢?
非叶子节点里面存的是主键值 + 指针
为了方便分析,这里我们把一个主键值 + 一个指针称为一个单元,
- 我们假设主键的类型是 BigInt,长度为 8 字节,
- 而指针大小在 InnoDB 中设置为 6 字节,
这样一个单元,一共 14 字节。
这样的话,一页或者说一个非叶子节点能够存放 16384 / 14=1170 个这样的单元。
也就是说一个非叶子节点中能够存放 1170 个指针,即对应 1170 个叶子节点,
所以对于这样一棵高度为 2 的 B+ 树,能存放 1170(一个非叶子节点中的指针数) * 16(一个叶子节点中的行数)= 18720 行数据。
当然,这样分析其实不是很严谨,InnoDB 数据页结构,不全是 主键值 + 一个指针,还有其他的一些 元数据。
按照 《MySQL 技术内幕:InnoDB 存储引擎》中的定义,InnoDB 数据页结构包含如下几个部分:

高为3的B+树可以存放多少行数据
分析完高度为 2 的 B+ 树,同样的道理,我们来看高度为 3 的:

根页(page10)可以存放 1170 个指针,
然后第二层的每个页(page:11,12,13)也都分别可以存放1170个指针。
这样一共可以存放 1170 * 1170 个指针,
即对应的有 1170 * 1170 个非叶子节点,
所以,高为3的B+树一共可以存放 1170 * 1170 * 16 = 21902400 行记录。
回到问题,InnoDB 一棵 B+ 树可以存放多少行数据?
这个问题的简单回答是:约 2 千万。
怎么得到InnoDB主键索引B+树的高度?
在InnoDB 引擎中,实际的情况如何呢?
在InnoDB的表空间文件中,约定page number为3的代表主键索引的根页,而在根页偏移量为64的地方存放了该B+树的page level。
如果page level为1,树高为2,page level为2,则树高为3。
即B+树的高度=page level+1;
下面我们将从实际环境中尝试找到这个page level。
实验环境中,这三张表的数据量如下:
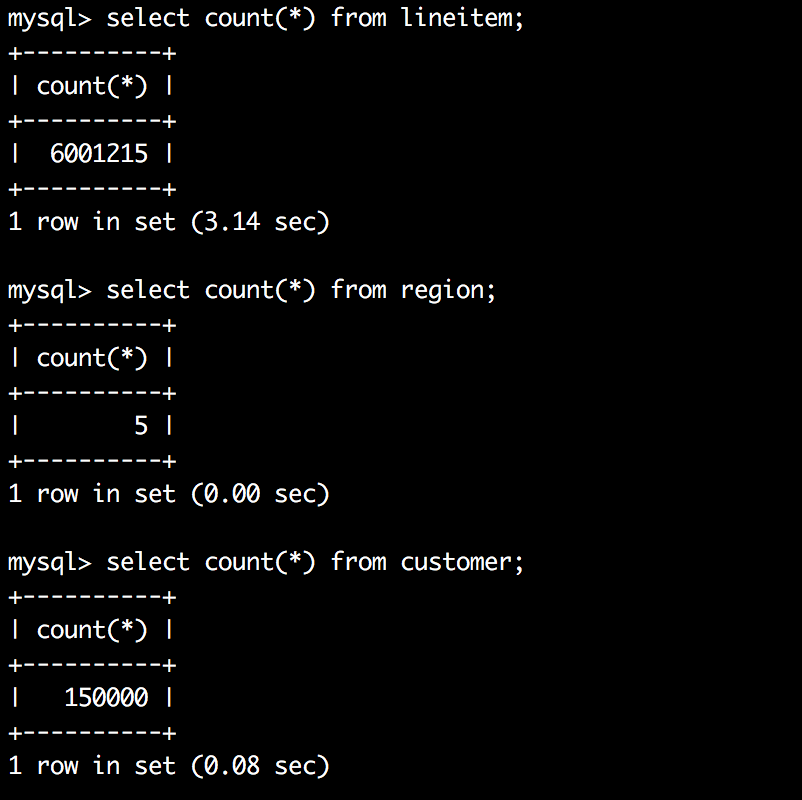
从图中可以看到,一个表600W,一个表 15W,一个表5行数据。
在实际操作之前,你可以通过InnoDB元数据表确认主键索引根页的page number为3,你也可以从《InnoDB存储引擎》这本书中得到确认。
SELECT
b.name, a.name, index_id, type, a.space, a.PAGE_NO
FROM
information_schema.INNODB_SYS_INDEXES a,
information_schema.INNODB_SYS_TABLES b
WHERE
a.table_id = b.table_id AND a.space <> 0;
说明:
information_schema是mysql自带的一个信息数据库,其保存着关于mysql服务器所维护的所有其他数据库的信息,如数据库名,数据库的表,表栏的数据类型与访问权限等。
- innodb_sys_indexes:innodb表的索引的相关信息
- innodb_sys_tables:表格的格式和存储特性,包括行格式,压缩页面大小位级别的信息
执行结果:

可以看出数据库dbt3下的customer表、lineitem表主键索引根页的page number均为3,而其他的二级索引page number为4。
在进行深入分析之前,首先回顾一下基础知识
回顾:主键索引和二级索引
什么是主键索引(Primary Key)?
数据表的主键列使用的就是主键索引。一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
什么是二级索引(辅助索引)?
二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。常用的二级索引包括:
- 唯一索引(Unique Key) :唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
- 普通索引(Index) :普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。
回顾:表空间文件
从物理意义上来讲,InnoDB表由共享表空间文件(ibdata1)、独占表空间文件(ibd)、表结构文件(.frm)、以及日志文件(redo文件等)组成。
1、表结构文件
在MYSQL中建立任何一张数据表,在其数据目录对应的数据库目录下都有对应表的.frm文件
.frm文件是用来保存每个数据表的元数据(meta)信息,包括表结构的定义等,
.frm文件跟数据库存储引擎无关,也就是任何存储引擎的数据表都必须有.frm文件,
命名方式为数据表名.frm,如user.frm. , .frm文件可以用来在数据库崩溃时恢复表结构。
2、表空间文件
(1)表空间结构分析
以下为InnoDB的表空间结构图:

数据段即B+树的叶子节点,索引段即为B+树的非叶子节点InnoDB存储引擎的管理是由引擎本身完成的,
表空间(Tablespace)是由分散的段(Segment)组成。一个段(Segment)包含多个区(Extent)。
区(Extent)由64个连续的页(Page)组成,每个页大小为16K,即每个区大小为1MB,创建新表时,先使用32页大小的碎片页存放数据,使用完后才是区的申请(InnoDB最多每次申请4个区,保证数据的顺序性能)
页类型有:数据页、Undo页、系统页、事务数据页、插入缓冲位图页、以及插入缓冲空闲列表页。
(2)独占表空间文件
若将innodb_file_per_table设置为on,则系统将为每一个表单独的生成一个table_name.ibd的文件,
在此文件中,存储与该表相关的数据、索引、表的内部数据字典信息。
(3)共享表空间文件
在InnoDB存储引擎中,默认表空间文件是ibdata1(主要存储的是共享表空间数据),初始化为10M,且可以扩展,如下图所示:
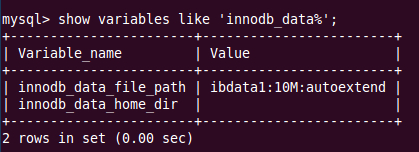
实际上,InnoDB的表空间文件是可以修改的,使用以下语句就可以修改:
Innodb_data_file_path=ibdata1:370M;ibdata2:50M:autoextend
使用共享表空间存储方式时,Innodb的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制,而是其自身的限制。
从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单表限制基本上也在64TB左右了,当然这个大小是包括这个表的所有索引等其他相关数据。
而在使用单独表空间存储方式时,每个表的数据以一个单独的文件来存放,这个时候的单表限制,又变成文件系统的大小限制了。
数据库表空间文件的实操分析
了解了这些基础知识之后,下面我们对数据库表空间文件做相关的解析, 主要是针对独占独占表空间文件(ibd)
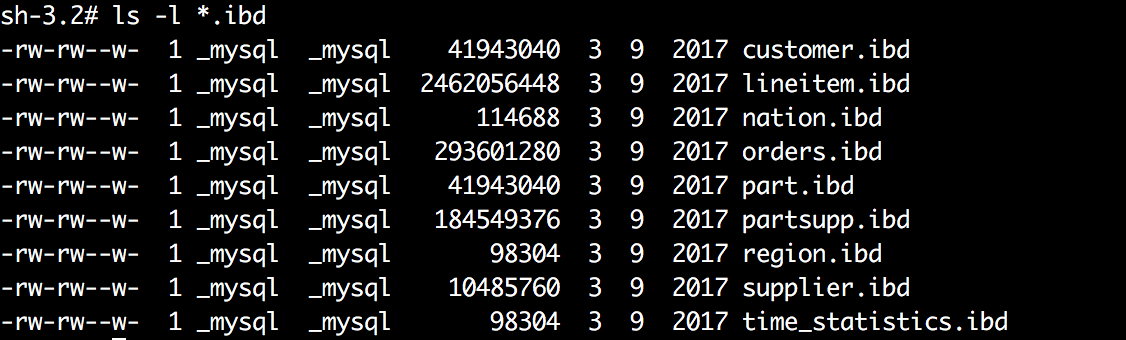
因为主键索引B+树的根页,在整个表空间文件中的第3个页开始,所以可以算出它在文件中的偏移量:
16384*3=49152(16384为页大小)。
另外根据《InnoDB存储引擎》中描述在根页的64偏移量位置前2个字节,保存了page level的值,
因此我们想要的page level的值在整个文件中的偏移量为:16384*3+64=49152+64=49216,前2个字节中。
接下来我们用hexdump工具,查看表空间文件指定偏移量上的数据:

linetem表的page level为2,B+树高度为page level+1=3;
region表的page level为0,B+树高度为page level+1=1;
customer表的page level为2,B+树高度为page level+1=3;
总结,通过分析可以看到,实验环境的三个表:
- lineitem表的数据行数为600多万,B+树高度为3,
- customer表数据行数只有15万,B+树高度也为3。
可以看出尽管数据量差异较大,这两个表树的高度都是3,换句话说这两个表通过索引查询效率并没有太大差异,因为都只需要做3次IO。
所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。
在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。
执行一次sql的聚集索引/非聚集索引io次数
前面分析了,假设主键ID为bigint类型,长度为8字节,
而指针大小在InnoDB源码中设置为6字节,这样一共14字节。
那么一个页中能存放多少这样的组合,就代表有多少指针,即 16384 / 14 = 1170。
那么可以算出一棵高度为2 的B+树,能存放 1170 * 16 = 18720 条这样的数据记录。
同理:
高度为3的B+树可以存放的行数 = 1170 * 1170 * 16 = 21902400
所以,千万级的数据存储只需要约3层B+树,所以说,根据主键id索引查询约3次IO便可以找到目标结果。
注意:查询数据时,每加载一页(page)代表一次IO,
当然 B+树的根节点是常驻内存的,这里少了一次IO。
但是,我们为例便于分析,在分析的时候,暂时不管吧,先看一般情况。
对于一些复杂的查询,可能需要走二级索引,那么通过二级索引查找记录最多需要花费多少次IO呢?

首先,从二级索引B+树中,根据name 找到对应的主键id

然后,再根据主键id 从 聚簇索引查找到对应的记录。
如上图所示,二级索引有3层,聚簇索引有3层,那么最多花费的IO次数是:3+3 = 6 (这里,忽略根节点常驻内存这件事)
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替。
如果连这样的索引没有,InnoDB 会隐式定义一个主键来作为聚簇索引。
这也是为什么InnoDB表必须有主键,并且推荐使用整型的自增主键!!!
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上
为啥磁盘IO的性能低? 不多说啦,具体请参考 尼恩的《葵花宝典:Java 高性能超底层原理》 视频和讲义
为啥inno DB单表记录推荐2kw
通过上面的分析可以看出, 如果是 走 非聚集索引查询, 需要6次IO,
走 聚焦索引查询,需要3次磁盘IO
当然,以上分析流程,忽略了一些性能的优化措施,比如 B+树根节点 常驻内存,还有可能命中 查询缓存等等。
所以,innodb 单表推荐2kw 记录,超过了这个值可能会导致B+树层级更高,影响查询性能。
当然,凡事看场景,上面只是一般的分析。
索引结构不会影响单表最大行数,2kw也只是推荐值,最终的单表记录数最大值,受到硬件条件,和各种优化措施的影响。
后记:超乎圆满的答案
只要按照上面的 流程去作答, 你的答案不是 100分,而是 120分
面试官一定是 心满意足, 五体投地。
参考文献
https://blog.csdn.net/weixin_36586564/article/details/104000328/
https://www.cnblogs.com/leefreeman/p/8315844.html
https://www.cnblogs.com/fangdadada/p/13055589.html
https://www.jianshu.com/p/cf5d381ef637
https://www.modb.pro/db/139052
《MYSQL内核:INNODB存储引擎 卷1》
https://blog.csdn.net/LJFPHP/article/details/97133701
推荐阅读:
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号