clickhouse 超底层原理& 高可用集群 实操(史上最全)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
本文背景
这段时间给大家 做简历指导,发现大家都缺少优质实操项目,所以打算介绍一个《100W级别qps日志平台实操》,基于clickhouse+netty,于是,就写了此文
此文涉及到大量的底层原理,和高并发的实操知识,建议大家慢慢读,
并且强烈建议大家,对着此文,实操一下。
MPP数据库简介
什么是OLTP与OLAP?
OLTP(OnLine Transaction Processing ) 联机事务处理 系统
例如mysql。
擅长事务处理,在数据操作中保持着很强的一致性和原子性 ,能够很好的支持频繁的数据插入和修改 ,但是,一旦数据量过大,OLTP便力不从心了。
OLAP(On-Line Analytical Processing)联机分析处理 系统
例如clickhouse,greenplum,Doris。
不特别关心对数据进行输入、修改等事务性处理,而是关心对已有 的大量数据进行多维度的、复杂的分析的一类数据系统 。
ClickHouse 简介
ClickHouse的全称是Click Stream,Data WareHouse。
ClickHouse 是俄罗斯的 Yandex (俄罗斯第一大搜索引擎) 于 2016 年开源的用于在线分析处理查询(OLAP :Online Analytical Processing)MPP架构的列式存储数据库(DBMS:Database Management System),能够使用 SQL 查询实时生成分析数据报告。
ClickHouse 使用 C++ 语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报
告。
clickhouse可以做用户行为分析,流批一体
clickhouse没有走hadoop生态,采用 Local attached storage 作为存储
令人惊喜的是,ClickHouse 的性能大幅超越了很多商业 MPP 数据库软件,比如 Vertica,InfiniDB.
相比传统的数据库软件,ClickHouse 要快 100-1000X:
100Million 数据集:
ClickHouse 比 Vertica 约快 5 倍,比 Hive 快 279 倍,比 My SQL 快 801 倍
1Billion 数据集:
ClickHouse 比 Vertica 约快 5 倍,MySQL 和 Hive 已经无法完成任务了
Greenplum简介
Greenplum是一家总部位于美国加利福尼亚州,为全球大型企业用户提供新型企业级数据仓库(EDW)、企业级数据云(EDC)和商务智能(BI)提供解决方案和咨询服务的公司,
在全球已有:[纳斯达克,[纽约证券交易所,Skype. FOX,T-Mobile;
中国已有:中信实业银行,东方航空公司,阿里巴巴,华泰保险,中国远洋,李宁公司等大型企业用户选择Greenplum的产品。
Greenplum的架构采用了MPP(大规模并行处理)。
Greenplum名字来源
Greenplum的大中华区总裁Stanley Chen告诉我们:“Greenplum这个名字是一个7岁小女孩无意中脱口而出的。”起初几个创始人在斟酌公司名字的时候都很没头绪,于是他们去问了朋友的孩子,一个年仅7岁的可爱小姑娘告诉他们叫“Apple”,但是爸爸告诉她,这个名字已经被别人用了,还有其他的么?很快孩子便随口说了“Greenplum”,于是“Greenplum”公司的名字就这样诞生了。**
Doris简介
Doris由百度大数据部研发 ,之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 doris
Doris是一个MPP的OLAP系统,以较低的成本提供在大数据集上的高性能分析和报表查询功能。

StoneDB介绍
此处的介绍,目的是 推广国产软件, 国产软件,不容易呀
StoneDB是国内首款基于MySQL的实时HTAP数据库产品, 由杭州石原子科技有限公司自主设计、研发的 基于 MySQL 内核打造的开源 HTAP(Hybrid Transactional and Analytical Processing)融合型数据库产品,可实现与 MySQL 的无缝切换。StoneDB 具备高性能、实时分析等特点,为用户提供一站式HTAP解决方案。StoneDB是一款兼容 MySQL的 HTAP 数据库,可以实现从MySQL到StonDB的无缝切换。
StoneDB 是基于 MySQL 内核打造的开源 HTAP (Hybrid Transactional and Analytical Processing) 融合型数据库,可实现与 MySQL 的无缝切换。StoneDB 具备超高性能、实时分析等特点,为用户提供一站式 HTAP 解决方案。
StoneDB 包含 100% 兼容 MySQL 5.6、5.7 协议,以及 MySQL 生态等重要特性,支持 MySQL 常用的功能及语法,支持 MySQL 生态中的系统工具和客户端,如 Navicat、Workbench、mysqldump、mydumper。由于 100% 兼容 MySQL,因此 StoneDB 的所有工作负载都可以继续使用 MySQL 数据库体系运行。
StoneDB 专门针对 OLAP 应用程序进行了设计和优化,支持百亿数据场景下进行高性能、多维度字段组合的复杂查询。
StoneDB 采用基于知识网格技术和列式存储引擎,该存储引擎为海量数据背景下 OLAP 应用而设计,通过列式存储数据、知识网格过滤、高效数据压缩等技术,为应用系统提供低成本和高性能的数据查询支持。
什么是MPP 系统
什么是 大规模并行处理 MPP架构?(Massively Parallel Processing)
MPP架构是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
采用MPP架构的数据库称为MPP数据库。

在 MPP 系统中,每个 单节点也可以运行自己的操作系统、数据库等。
换言之,每个节点内的 CPU 不能访问另一个节点的内存。
节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution) 。
与传统的单体架构 明显不同,MPP系统因为 要在不同处理单元之间传送信息,
- 当数据规模很小的时候,MPP的效率要比单体架构要差一点,
- 但是当数据规模上来之后,MPP的效率要比 单体架构 好。
这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反,如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。
为什么需要MPP数据库?
海量数据的分析需求
传统数据库无法支持大规模集群与PB级别数据量
单台机器性能受限、成本高昂,扩展性受限
支持复杂的结构化查询(这里是重点)
复杂查询经常使用多表联结、全表扫描等,牵涉的数据量往往十分庞大;
支持复杂sql查询和支持大数据规模;
Hadoop技术的先天不足
Hive等sql-on-hadoop性能太慢,分析场景不一样,SQL兼容性与支持不足
MPP数据库应用领域
大数据分析:
MPP数据库做大数据计算或分析平台非常适合,例如:数据仓库系统、历史数据管理系统、数据集市等。
MPP数据库有很强的并行数据计算能力和海量数据存储能力,、
所以,报表统计分析、运维统计数据,快速生成报表展示都可以使用mpp数据库。
符合几个条件:不需要更新数据,不需要频繁重复离线计算,不需要并发大。
有上百亿以上离线数据,不更新,结构化,需要各种复杂分析的sql语句,那就可以选择他。
几秒、几十秒立即返回你想要的分析结果。
例如sum,count,group by,order,好几层查询嵌套,在几百亿数据里分分钟出结果
这类的数据库:,clickhouse,greenplum,Doris
MPP数据库不擅长高频的小规模数据插入、修改、删除,每次事务处理的数据量不大。
这类数据衡量指标是TPS,适用的系统是OLTP数据库。
Clickhouse特性
Clickhouse是一个列式数据库管理系统,在OLAP领域像一匹黑马一样,以其超高的性能受到业界的青睐。
Clickhouse的优势特性:
数据分区与线程级并行
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,
比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区。
分区条件查询,只能读取包含适当分区数据块,而不扫描过多的数据。
灵活的使用,可以大大提升查询的性能。
ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index granularity(索引粒度),
然后通过多个 CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条 Query 就能利用整机所有 CPU。
极致的并行处理能力,极大的降低了查询延时。
所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。
但是有一个弊端就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务,ClickHouse 并不是强项。
采用列式存储,数据类型一致,压缩性能更高
在一些列式数据库管理系统中(例如InfiniDB CE和MonetDB) 并没有使用数据压缩。>
InfiniDB Community Edition(社区版)提供一个可伸缩的分析型数据库引擎,主要为数据仓库、商业智能、以及对实时性要求不严格的应用而开发。基于MySQL搭建。包括对查询、事务处理以及大数据量加载的支持。
MonetDB是一个开源的面向列的数据库管理系统。MonetDB被设计用来为较大规模数据(如几百万行和数百列的数据库表)提供高性能查询的支持。
但是, 若想达到比较优异的性能,数据压缩确实起到了至关重要的作用。
提供 LZ4、ZSTD 两种数据压缩格式
硬件利用率高,连续IO,提高了磁盘驱动器的效率
许多的列式数据库(如 SAP HANA, Google PowerDrill)只能在内存中工作,这种方式会造成比实际更多的设备预算。
ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果有可以使用SSD和内存,它也会合理的利用这些资源
向量化引擎与SIMD提高了CPU利用率,多核多节点并行化大查询
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU
ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询
支持SQL
ClickHouse支持基于SQL的声明式查询语言,该语言大部分情况下是与SQL标准兼容的。几乎覆盖了标准SQL的大部分语法,包括DDL和DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复
支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询。
绝大部分查询基本和常用的mysql一样,可以省去大部分同学的学习成本。不仅如此提供了强大的函数支查询能力,更丰富的存储格式,例如array多维数组、json、tuple、set等。
支持近似计算
ClickHouse提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
用于近似计算的各类聚合函数,如:distinct values, medians, quantiles
基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据。
不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用。
索引
- 主键索引
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,会为每个数据片段创建一个索引文件,索引文件包含每个索引行(『标记』)的主键值。
索引行号定义为 n * index_granularity 。当数据被插入到表中时,会分成数据片段并按主键的字典序排序。例如,主键是 (CounterID, Date) 时,片段中数据按 CounterID 排序,具有相同 CounterID 的部分按 Date 排序。
但是值得注意的是:ClickHouse 不要求主键惟一。
所以,你可以插入多条具有相同主键的行。
要想实现去重效果,需要结合具体的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree实现。
-
稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。其中被索引的value可以是任意的合法SQL Expression,并不仅仅局限于对column value本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index granularity(默认8192行)的统计信息,并不会具体记录每一行在文件中的位置。
支持近似计算
ClickHouse提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
- 用于近似计算的各类聚合函数,如:distinct values, medians, quantiles
- 基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据。
- 不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用。
丰富的表引擎
ClickHouse和MySQL类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。
目前包括合并树,日志,接口和其他四大类20多种引擎。
clickhouse 不仅拥有自己强大的MergeTree家族的多种本地引擎外,还提供了丰富的外部引擎供我们选择,包括但不限于:kafka、HDFS、Mysql。
但是使用外部引擎的时,性能自然会不如本地存储。
MergeTree引擎家族中很有很多优秀的引擎
比如:
适合人物画像的AggregatingMergeTree引擎
可自定义去重的SummingMergeTree引擎
折叠树CollapsingMergeTree
用于Graphite监控的GraphiteMergeTree引擎
。。。
这些都具有数据副本的能力 Replicated*
官方推荐的适合大多数场景的依然是MergeTree引擎,其家族中其他引擎大多也是在其基础上做的封装。
除此之外,还有分布式的表引擎Distributed。 Distributed是一种逻辑表引擎,并不存储数据。
创建该表引擎时,会指向已配置的分片集,要查询的时候,它会向每个分片发起查询并最终汇总集合然后返回。
这里配置分片集可超灵活的配置,不用的时候可以删除。以后会单独来介绍该引擎的使用。
基于shard+replica实现的线性扩展和高可靠
clickhouse高吞吐写入能力
ClickHouse 采用类 LSM Tree的结构,数据写入后定期在后台 Compaction。
通过类 LSM tree的结构,ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,
在后台compaction 时也是多个段 merge sort 后顺序写回磁盘。
顺序写的特性,充分利用了磁盘的吞吐能力,即便在 HDD 上也有着优异的写入性能。
官方公开 benchmark 测试显示能够达到 50MB-200MB/s 的写入吞吐能力,按照每行100Byte 估算,大约相当于 50W-200W 条/s 的写入速度。
LSM结构(Log Structured Merge Tree)解读
1996年,一篇名为 Thelog-structured merge-tree(LSM-tree)的论文创造性地提出了日志结构合并树( Log-Structured Merge-Tree)的概念,该方法既吸收了日志结构方法的优点,又通过将数据文件预排序克服了日志结构方法随机读性能较差的问题。
尽管当时 LSM-tree新颖且优势鲜明,但它真正声名鹊起却是在 10年之后的 2006年,
2006年,Google 发表了 BigTable 的论文。这篇论文提到 BigTable 单机上所使用的数据结构就是 LSM。
那年谷歌的一篇使用了 LSM-tree技术的论文 Bigtable: A Distributed Storage System for Structured Data横空出世,在分布式数据处理领域掀起了一阵旋风,
随后两个声名赫赫的大数据开源组件( 2007年的 HBase与 2008年的 Cassandra,目前两者同为 Apache顶级项目)直接在其思想基础上破茧而出,彻底改变了大数据基础组件的格局,同时也极大地推广了 LSM-tree技术。
目前,LSM 被很多存储产品作为存储结构,比如 Apache HBase, Apache Cassandra, MongoDB 的 Wired Tiger 存储引擎, LevelDB 存储引擎, RocksDB 存储引擎等。
简单地说,LSM 的设计目标是提供比传统的 B+ 树更好的写性能。
LSM 通过将磁盘的随机写转化为顺序写来提高写性能 ,而付出的代价就是牺牲部分读性能、写放大(B+树同样有写放大的问题)。
LSM-tree最大的特点是同时使用了两部分类树的数据结构来存储数据,并同时提供查询。
其中一部分数据结构( C0树)存在于内存缓存(通常叫作 memtable)中,负责接受新的数据插入更新以及读请求,并直接在内存中对数据进行排序;
另一部分数据结构( C1树)存在于硬盘上 (这部分通常叫作 sstable),它们是由存在于内存缓存中的 C0树冲写到磁盘而成的,主要负责提供读操作,特点是有序且不可被更改。
LSM 相比 B+ 树能提高写性能的本质原因是:
外存——无论磁盘还是 SSD,其随机读写都要慢于顺序读写。
hash表和B+树
在了解LSM树之前,我们需要对hash表和B+树有所了解。
hash表就不用说了,通过key值经过hash算法,直接定位到数据存储地址,然后取出value值。
时间复杂度O(1),找数据和存数据就需要那么一下子,就给找到了
hash存储方式支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。
对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,
如果不需要有序的遍历数据,哈希表就是最佳选择
B+树我们常用的数据库Mysql的底层数据结构,例如我们的索引就是B+树结构。
B+树是一种专门针对磁盘存储而优化的N叉排序树,以树节点为单位存储在磁盘中,从根开始查找所需数据所在的节点编号和磁盘位置,将起加载到内存中然后继续查找,直到找到所需的数据。
B+树既有排序树的优点,能够很快沿着树枝找打目标节点,又能防止树的高度过高,大大减少磁盘IO次数。还能进行快速全表扫描遍历。
B+ 树的三个特点:
- 节点的子树数和关键字数相同
- 非叶子节点仅用作索引,它的关键字和子节点有重复元素
- 叶子节点形成有序链表,包含了全部数据,同时符合左小右大的顺序

B+树改进了B树, 让内结点只作索引使用, 去掉了其中指向data record的指针, 使得每个结点中能够存放更多的key, 因此能有更大的出度.
这有什么用? 这样就意味着存放同样多的key, 树的层高能进一步被压缩, 使得检索的时间更短。
B树和B+树的对比介绍
首先从二叉树说起,
因为 二叉树 会产生退化现象,提出了平衡二叉树,
在平衡二叉树基础上, 再提出怎样让每一层放的节点多一些,来减少遍历高度,引申出m叉树,
m叉搜索树同样会有退化现象,引出m叉平衡树,也就是B树,这时候每个节点既放了key也放了value,
怎样使每个节点放尽可能多的key值,以减少遍历高度呢(访问磁盘次数),
可以将每个节点只放key值,将value值放在叶子结点,在叶子结点的value值增加指向相邻节点指针,这就是优化后的B+树。所有叶子节点形成有序链表,便于范围查询,不用每次要检索树。
目前数据库多采用两级索引的B+树,树的层次最多三层,因此可能需要5次磁盘访问才能更新一条记录(三次磁盘访问获得数据索引以及行id,然后再进行一次数据文件读操作及一次数据文件写操作)
B~树(平衡多路二叉树)
B树,又叫平衡多路查找树。一棵m阶的B树 (m叉树)的特性如下:
-
树中每个结点至多有m个孩子;
-
除根结点和叶子结点外,其它每个结点至少有[m/2]个孩子;
-
若根结点不是叶子结点,则至少有2个孩子;
-
所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);
-
每个非终端结点中包含有n个关键字信息: (n,A0,K1,A1,K2,A2,......,Kn,An)。其中,
a) Ki (i=1...n)为关键字,且关键字按顺序排序Ki < K(i-1)。
b) Ai为指向子树根的接点,且指针A(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [m/2]-1 <= n <= m-1

B+树
B+树:是应文件系统所需而产生的一种B~树的变形树。
一棵m阶的B+树和m阶的B-树的差异在于:
-
有n棵子树的结点中含有n个关键字; (B~树是n棵子树有n+1个关键字)
-
所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (B~树的叶子节点并没有包括全部需要查找的信息)
-
所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (B~树的非终节点也包含需要查找的有效信息)

a、B+树的磁盘读写代价更低
我们都知道磁盘时可以块存储的,也就是同一个磁道上同一盘块中的所有数据都可以一次全部读取。
而B+树的内部结点并没有指向关键字具体信息的指针(比如文件内容的具体地址 , 比如说不包含B~树结点中的FileHardAddress[filenum]部分) 。
因此其内部结点相对B~树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。
这样,一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B树(一个结点最多8个关键字)的内部结点需要2个盘快。而B+树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B树就比B+数多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
b、B+树的查询效率更加稳定。
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。
所以任何关键字的查找必须走一条从根结点到叶子结点的路。
所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
什么是LSM树
LSM树,即日志结构合并树(Log-Structured Merge-Tree)。
其实它并不属于一个具体的数据结构,它更多是一种数据结构的设计思想。
大多NoSQL数据库核心思想都是基于LSM来做的,只是具体的实现不同。
LSM树诞生背景
传统关系型数据库使用btree或一些变体作为存储结构,能高效进行查找。
但保存在磁盘中时它也有一个明显的缺陷,那就是逻辑上相离很近但物理却可能相隔很远,这就可能造成大量的磁盘随机读写。
随机读写比顺序读写慢很多,为了提升IO性能,我们需要一种能将随机操作变为顺序操作的机制,于是便有了LSM树。
为啥 随机读写比顺序读写慢很多呢?
磁盘读写时涉及到磁盘上数据查找,地址一般由柱面号、盘面号和块号三者构成。
也就是说:
step1:移动臂先根据柱面号移动到指定柱面,
step2: 然后根据 盘面号 确定盘面
step3:最后 块号 确定磁道,最后将指定的磁道段移动到磁头下,便可开始读写。
整个过程主要有三部分时间消耗,查找时间(seek time) +等待时间(latency time)+传输时间(transmission time) 。分别表示定位柱面的耗时、将块号指定 磁道段 移到磁头的耗时、将数据传到内存的耗时。
整个磁盘IO最耗时的地方在查找时间,所以减少查找时间能大幅提升性能。
LSM树原理
LSM树能让我们进行顺序写磁盘,从而大幅提升写操作,作为代价的是牺牲了一些读性能。
LSM树由两个或以上的存储结构组成,
最简单的两个存储结构:
-
一个存储结构常驻内存中,称为C0 tree,具体可以是任何方便健值查找的数据结构,比如红黑树、map之类,甚至可以是跳表。
-
另外一个存储结构常驻在硬盘中,称为C1 tree,具体结构类似B树。
C1所有节点都是100%满的,节点的大小为磁盘块大小。

LSMTree和SSTable
什么是SSTable呢? SSTable (Sorted String Table) 是排序字符串表的简称,
正如名字本身所包含的意思一样,SSTable是一个简单的抽象,用来高效地存储大量的键-值对数据,同时做了优化来实现顺序读/写操作的高吞吐量。
- SStable在功能上,只是对hash加入了一个按键值排序。
- 由于是排序数据,我们不必像hash索引一样记录所有数据的位置,索引可以是稀疏的,例如对于段文件中的上千条数据,只保留一个索引
例如:
对于数据键1~100000,我们每隔1000个数据保留一个索引,当查找5500时,对应索引应该是5000,之后向后查找500条(或者使用二分)。
使用方法似乎很好理解,麻烦的是构建和维护SStable。
SStable基本工作流程是:
- 写入时将内容插入内存中的排序数据结构(例如红黑树)
- 当内存大于一定阈值时将其写入磁盘,作为磁盘的一部分
- 如果接收到新的读取请求,要先尝试在内存中读取,其次是磁盘的最新排序部分,然后是次新的,依次类推
- 后台进程周期性将各个排序部分归并,并且出现相同数据时只会保留最新值。
如果使用sstable,先进行内存写,所以我们也要考虑日志系统,类似innodb里redolog方式来保证持久性。
LSM-Tree 全名叫Log-Structured Merge Tree,最早建立在日志结构文件之上,现在基于合并和压缩排序文件原理的存储引擎都统称为LSM存储引擎。
我们通常把LSM看成一种思想:保存在后台合并的一系列SStable
这种思想简单且有效:
- 即使数据集远大于内存,LSM-tree也能正常工作
- 由于键值有序,范围查询相比于hash表有很大优势
- 由于写入是顺序的(归并是后台线程在空闲时间做的)LSM-tree可以提供非常高的写入吞吐量
查找的性能优化:
在LSM系统中查找一个不存在的键时会导致查询时间长,因为要从最新的数据一直往前查找,所以lsm一般会使用布隆过滤器进行优化
接下来,详细说说 SSTable
SSTable的定义
SSTable (Sorted String Table) 是排序字符串表的简称,来源于大名鼎鼎的 Google Bigtable 论文。
它用于 Bigtable 内部数据文件的存储,它是一个种高效的 key-value 型文件存储格式。
要解释这个术语的真正含义,最好的方法就是从它的出处找答案,所以重新翻开BigTable的论文。
在这篇论文中,最初对SSTable是这么描述的(第三页末和第四页初):
SSTable
The Google SSTable file format is used internally to store Bigtable data.
An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk.
简单的非直译:
SSTable是Bigtable内部用于数据的文件格式,它的格式为文件本身就是一个排序的、不可变的、持久的Key/Value对Map,其中Key和value都可以是任意的byte字符串。
使用Key来查找Value,或通过给定Key范围遍历所有的Key/Value对。
每个SSTable包含一系列的Block(一般Block大小为64KB,但是它是可配置的),在SSTable的末尾是Block索引,用于定位Block,这些索引在SSTable打开时被加载到内存中,在查找时首先从内存中的索引二分查找找到Block,然后一次磁盘寻道即可读取到相应的Block。
还有一种方案是将这个SSTable加载到内存中,从而在查找和扫描中不需要读取磁盘。
HBase中的SSTable
这个貌似就是HFile第一个版本的格式么,贴张图感受一下:
在HBase使用过程中,对这个版本的HFile遇到以下一些问题(参考这里):
- 解析时内存使用量比较高。
- Bloom Filter和Block索引会变的很大,而影响启动性能。具体的,Bloom Filter可以增长到100MB每个HFile,而Block索引可以增长到300MB,如果一个HRegionServer中有20个HRegion,则他们分别能增长到2GB和6GB的大小。HRegion需要在打开时,需要加载所有的Block索引到内存中,因而影响启动性能;而在第一次Request时,需要将整个Bloom Filter加载到内存中,再开始查找,因而Bloom Filter太大会影响第一次请求的延迟。
而HFile在版本2中对这些问题做了一些优化,具体会在HFile解析时详细说明。
LevelDB 中的SSTable
先看看SSTable文件的结构
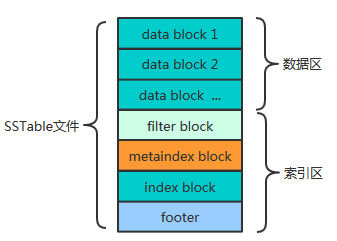
整体上看 SSTable文件分为数据区与索引区,
尾部的footer指出了meta index block与data index block的偏移与大小,
index block指出了各data block的偏移与大小,metaindex block指出了filter block的偏移与大小。
1)data block:存储key-value记录,分为Data、type、CRC三部分
2)filter block:默认没有使用,用于快速从data block 判断key-value是否存在
3)metaindex block :记录filter block的相关信息
4)Index block:描述一个data block,存储着对应data block的最大Key值,以及data block在文件中的偏移量和大小
5)footer:索引的索引,记录metaindex block和Index block在SSTable中的偏移量了和大小
下面再具体看看各个部分物理结构
1、block
sstable中data block 、metaindex block、index block都用这种block这种结构。
对于data block,当block大小(record、restarts数组、以及num_restarts)超过4k时,就切换一个新的block继续往SSTable写数据,
而metaindex block、index block就只有一个block,所以上图看起来data block有多个。
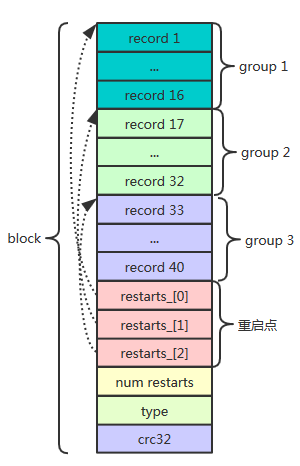
block主要由数据区record和restarts组成。 为什么是这种结构?
data block主要是存储数据,block内给一定数量(默认16)key-value分组,
每组又用restarts数组记录起始位置,因此可以根据restarts读取每组起始位置key-value,
由于block内的数据是从小到大有序存储的,所以可以通过restarts数组,获取每组起始key-value,比较起始key key(n)与查找的key大小,如果key(n)>key,那么key一定在序号>=n组之后,否则在 < n组之前。
因此可以通过二分查找思想通过restarts获取起始key,来定位key的位置,避免线性查找低效。
因此,restarts的思想就是:提高block内key-value查找效率,直接定位key所在group。
下面再来看看record结构。
record相对有意思,不是简单的用key-length | key-data | value-length|value-data存储。

data block中的key是有序存储的,相邻的key之间可能有重复,因此存储时采用前缀压缩,后一个key只存储与前一个key不同的部分。
重启点指出的位置即每组起始位置的key不按前缀压缩,而是完整存储该key。
type是表示数据是否压缩,以怎样的方式压缩,crc32是该block校验码。
2、index block
index block 的结构也是block 结构,是data block的索引,记录每个data block 最大key 和 起始位置以及大小。
具体的存储方式是以每个data block最大key 为key,以data block 起始位置和大小为value。因此可以根据每个
block的最大key与查询key比较,直接定位查询key所在的位置。
这是理论上key的存储方式,但是在sstable二次压缩的过程对key做了一个优化,它并不保存最大key,而是保存一个能分隔两个data block的最短Key,如:假定data block1的最大一个key为“abcdefg”,data block2最大key为“abzxcv”,则index可以记录data block1的索引key为“abd”;这样的分割串可以有很多,只要保证data block1中的所有Key都小于等于此索引,data block2中的所有Key都大于此索引即可。
这种优化缩减了索引长度,查询时可以有效减小比较次数。
因此,index block的思想是提高SSTable内key-value查找效率,直接定位key所在block。
3、metaindex_block
也是block结构。就只有一条记录,其key是filter. + filter_policy的name,value是filter大小和起始位置。
4、filter block
filter block就是一个bloom filter,关于bloom filter原理概念可以百度。
每个bloom filter是对data block 的key 经过hash num 次形成的字节数组,多少个data block对应多少个bloom filter。
bloom filter实质就是一个bit 数组,对block 内key hash,将相应的位置设为1,这种设计关键在于能提高不存在的key判断效率,通过filter 计算,如果不存在,就不用通过data block内的restarts方式读取文件查找key是否存在,但是如果filter判断存在,还需通过restarts方式确定。
5、footer
footer位于SSTable文件尾部,占用空间固定为48个字节。其末尾8个字节是一个magic_number。metaindex_block_handle与index_block_handle物理上占用了40个字节,metaindex_block_handle和index_block_handle是BlockHandle数据类型, 这种结构用于记录metaindex block 和index block的起始位置和大小。
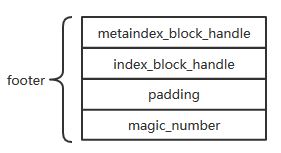
对于BlockHandle ,其实可以看作文件内容指针实现方式,BlockHandle记录数据位置及大小,与c/c++指针 思想类似,通过地址和大小可以读取数据。
BlockHandle格式
varint64 offset | varint64 size_
采用变长存储,所以实际上存储可能连32字节都不到,剩余填充0。
总结:
SSTable其实就是通过二次索引,先读取footer,
根据footer中index_block_handler记录的index_block起始位置和大小,读取index block,
通过index block 查询key所在data block,再在data block内部通过restarts 进一步确定key所在group。
下面是完整的SSTable结构图
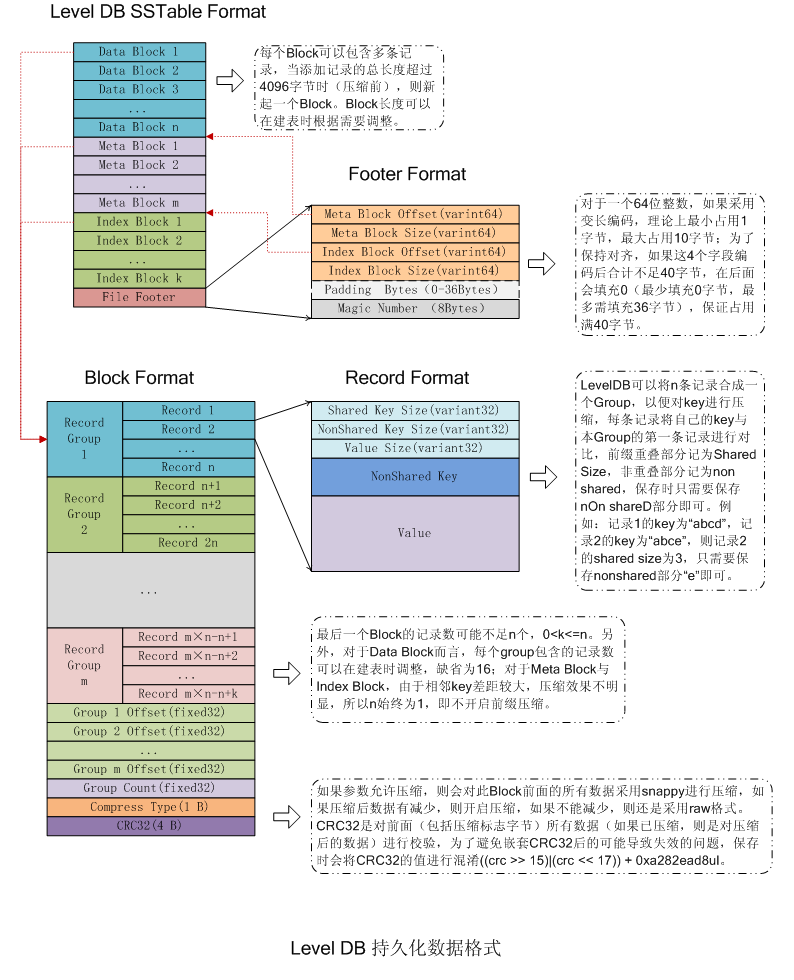
LSM插入步骤
插入一条新纪录时,首先在日志文件中插入操作日志,以便后面恢复使用,日志是以append形式插入,所以速度非常快;
将新纪录的索引插入到C0中,这里在内存中完成,不涉及磁盘IO操作;
当C0大小达到某一阈值时或者每隔一段时间,将C0中记录滚动合并到磁盘C1中;
对于多个存储结构的情况,当C1体量越来越大就向C2合并,以此类推,一直往上合并Ck。
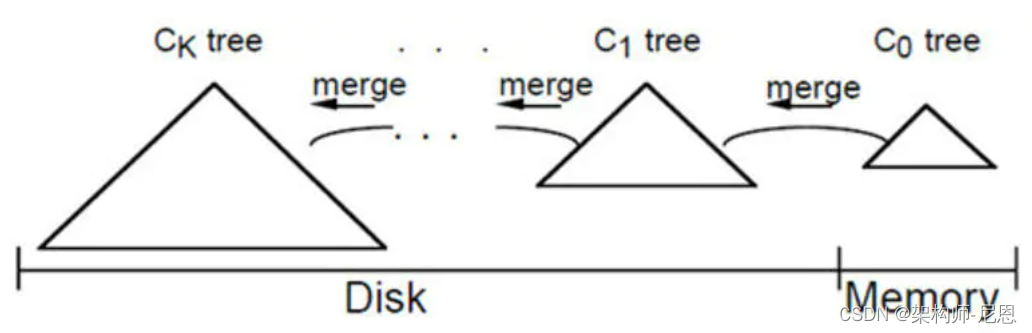
LSM合并步骤
合并过程中会使用两个块:emptying block 和 filling block。
- 从C1中读取未合并叶子节点,放置内存中的emptying block中。
- 从小到大找C0中的节点,与emptying block进行合并排序,合并结果保存到filling block中,并将C0对应的节点删除。
- 不断执行第2步操作,合并排序结果不断填入filling block中,当其满了则将其追加到磁盘的新位置上,注意是追加而不是改变原来的节点。合并期间如故宫emptying block使用完了则再从C1中读取未合并的叶子节点。
- C0和C1所有叶子节点都按以上合并完成后,即完成一次合并。
LSM插入案例
向LSM树中插入 A E L R U ,首先会插入到内存中的C0树上,
这里使用AVL树,插入“A”,
当然,得先WAL, 预先写入日志,向磁盘日志文件追加记录,然后再插入C0,

插入“E”,同样先追加日志再写内存,

继续插入“L”,旋转后如下,

插入“R”“U”,旋转后最终如下。

假设此时触发合并,
则因为C1还没有树,所以emptying block为空,直接从C0树中依次找最小的节点。
filling block长度为4,这里假设磁盘块大小为4。
开始找最小的节点,并放到filling block中,

继续找第二个节点,

以此类推,填满filling block,

开始写入磁盘,C1树,

继续插入 B F N T ,先分别写日志,然后插入到内存的C0树中,

假如此时进行合并,先加载C1的最左边叶子节点到emptying block,

接着对C0树的节点和emptying block进行合并排序,首先是“A”进入filling block,

然后是“B”,

合并排序最终结果为,

将filling block追加到磁盘的新位置,将原来的节点删除掉,

继续合并排序,再次填满filling block,

将filling block追加到磁盘的新位置,上一层的节点也要以磁盘块(或多个磁盘块)大小写入,尽量避开随机写。另外由于合并过程可能会导致上层节点的更新,可以暂时保存在内存,后面在适当时机写入。

LSM查找操作
查找总体思想是先找内存的C0树,找不到则找磁盘的C1树,然后是C2树,以此类推。
假如要找“B”,先找C0树,没找到。

接着找C1树,从根节点开始,

找到“B”。

LSM删除操作
删除操作为了能快速执行,主要是通过标记来实现,在内存中将要删除的记录标记一下,后面异步执行合并时将相应记录删除。
比如要删除“U”,假设标为#的表示删除,则C0树的“U”节点变为,

而如果C0树不存在的记录,
则在C0树中生成一个节点,并标为#,查找时就能再内存中得知该记录已被删除,无需去磁盘找了。
比如要删除“B”,那么没有必要去磁盘执行删除操作,直接在C0树中插入一个“B”节点,并标为#。

LSM树的特点:用牺牲读性能,来换取写性能
优化写性能
如果我们对写性能特别敏感,我们最好怎么做?
—— Append Only:所有写操作都是将数据添加到文件末尾。这样做的写性能是最好的,大约等于磁盘的理论速度(200 ~ 300 MB/s)。
但是 Append Only 的方式带来的问题是:
- 读操作不方便。
- 很难支持范围操作。
- 需要垃圾回收(合并过期数据)。
所以, 纯粹的 Append Only 方式只能适用于一些简单的场景:
- 数据库的 WAL(预写日志)。
- 能知道明确的 offset,比如 Bitcask。
如果要优化读性能
如果我们对读性能特别敏感,一般我们有两种方式:
- 有序存储,比如 B+ 树,SkipList 等。
- Hash 存储 —— 不支持范围操作,适用范围有限。
读写性能的权衡
如何获得(接近) Append Only 的写性能,而又能拥有不错的读性能呢?
以 LevelDB 为代表的 LSM 存储引擎给出了一个参考答案。
注意,LevelDB 实现的是优化后的 LSM,原始的 LSM 可以参考论文。
以 LevelDB 例子, LevelDB 的写操作主要由两步组成:
- 写日志并持久化(Append Only)。
- Apply 到内存中的 memtable(SkipList)。
所以,LevelDB 的写速度非常快。
memtable 写“满”后,会转换为 immutable memtable,
然后被后台线程 compaction 成按 Key 有序存储的 sst 文件(顺序写)。
由于 sst 文件会有多个,所以 LevelDB 的读操作可能会有多次磁盘 IO(LevelDB 通过 table cache、block cache 和 bloom filter 等优化措施来减少读操作的磁盘 IO 次数)。
基于 LSM 数据结构的 NO SQL的适用场景:
- 写请求多。
- 写性能要求高:(高吞吐+低延迟)。
LSM-tree的另一大特点是除了使用两部分类树的数据结构外,还会使用日志文件(通常叫作 commit log)来为数据恢复做保障。
这三类数据结构的协作顺序一般是:所有的新插入与更新操作都首先被记录到 commit log中——该操作叫作 WAL(Write Ahead Log),然后再写到 memtable,最后当达到一定条件时数据会从 memtable冲写到 sstable,并抛弃相关的 log数据; memtable与 sstable可同时供查询;当 memtable出问题时,可从 commit log与 sstable中将 memtable的数据恢复。
理论上,可以是内存中树的一部分和磁盘中第一层树做合并,对于磁盘中的树直接做update操作有可能会破坏物理block的连续性,但是实际应用中,一般LSM树有多层,当磁盘中的小树合并成一个大树的时候,可以重新排好顺序,使得block连续,优化读性能。

LSM树的特点:用读性能来换取写性能,将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘
LSM树的核心思想:放弃部分读性能,提高写性能
代表数据库:nessDB、LevelDB、HBase等非关系型数据库
我们可以参考 HBase的架构来体会其架构中基于 LSM-tree的部分特点。
按照 WAL的原则,数据首先会写到 HBase的 HLog(相当于 commit log)里,然后再写到 MemStore(相当于 memtable)里,最后会冲写到磁盘 StoreFile(相当于 sstable)中。
这样 HBase的 HRegionServer就通过 LSM-tree实现了数据文件的生成。
HBase LSM-tree架构示意图如下图。

LSM-tree的这种结构非常有利于数据的快速写入(理论上可以接近磁盘顺序写速度),
但是,LSM-tree不利于读——因为理论上读的时候可能需要同时从 memtable和所有硬盘上的 sstable中查询数据,这样显然会对性能造成较大的影响。
为了解决这个问题, LSM-tree采取了以下主要的相关措施。
- 定期将硬盘上小的 sstable合并(通常叫作 Merge或 Compaction操作)成大的 sstable,以减少 sstable的数量。而且,平时的数据更新删除操作并不会更新原有的数据文件,只会将更新删除操作加到当前的数据文件末端,只有在 sstable合并的时候才会真正将重复的操作或更新去重、合并。
- 对每个 sstable使用布隆过滤器( Bloom Filter),以加速对数据在该 sstable的存在性进行判定,从而减少数据的总查询时间。
LSM树和B+树的差异主要在于读性能和写性能进行权衡,在牺牲的读性能的同时,寻找其余补救方案。
B+树存储引擎,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库。但随着写入操作增多,为了维护B+树结构,节点分裂,读磁盘的随机读写概率会变大,读性能会逐渐减弱。
LSM树(Log-Structured MergeTree)存储引擎和B+树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。
当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
什么是vectorization?
向量化计算(vectorization),也叫vectorized operation,也叫array programming,
说的是一个事情:将多次for循环计算变成一次计算。

上图中,左侧为vectorization,右侧为寻常的For loop计算。
vectorization 将多次for循环计算变成一次计算,
vectorization 完全仰仗于CPU的SIMD指令集,
SIMD指令可以在一条cpu指令上处理2、4、8或者更多份的数据。
在Intel处理器上,这个称之为SSE, 以及后来的AVX,在Arm处理上,这个称之为NEON。
因此简单来说,
for循环计算是将一个loop——处理一个array(N个数据)的时候,每次处理1个数据,共处理N次,
向量化计算就 转化为vectorization——处理一个array的时候每次同时处理8个数据,共处理N/8次。
vectorization如何让速度更快?
介绍SSE 指令集 / AVX指令集之前,先要引入一个向量的概念。所谓向量,
就是多个标量的组合,通常意味着SIMD(单指令多数据),就是一个指令同时对多个数据进行处理,达到很大的吞吐量。
早在1996年,Intel就在X86架构上应用了MMX(多媒体扩展)指令集,那时候还仅仅是64位向量。
到了1999年,SSE(流式SIMD扩展)指令集出现了,这时候的向量提升到了128位。
SIMD
SIMD(Single Instruction Multiple Data,单指令多数据流),是一种实现空间上的并行性的技术。
这种技术使用一个控制器控制多个处理单元,同时对一组数据中的每一个数据执行相同的操作。
在 SIMD 指令执行期间,任意时刻都只有一个进程在运行,即 SIMD 没有并发性,仅仅只是同时进行计算。
在 Intel 的 x86 微架构处理器中,SIMD 指令集有 MMX、SSE、SSE2、SSE3、SSSE3、SSE4.1、SSE4.2、AVX、AVX2、AVX512。
我们以x86指令集为例,
1997年,x86扩展出了MMX指令集,伴随着80-bit的vector寄存器,首开向量化计算的先河。
之后,x86又扩展出了SSE指令集 (有好几个版本, 从SSE1到SEE4.2),伴随着128-bit寄存器。
而在2011年,Intel发布了Sandy Bridge架构——扩展出了AVX指令集(256-bit寄存器)。
在2016年,第一个带有AVX-512寄存器的CPU发布了(512-bit寄存器,可以同时处理16个32-bit的float数)。
SSE和AVX各有16个寄存器。
SSE的16个寄存器为XMM0-XMM15,AVX的16个寄存器为YMM0-YMM15。
XMM 寄存器 registers 每个为128 bits,
YMM寄存器 registers 每个为256bit
AVX-512 寄存器 registers 每个为512bit。
AVX
AVX 是 SSE 架构的延伸,将 SSE 的 XMM 128bit 寄存器升级成了 YMM 256bit 寄存器,同时浮点运算命令扩展至 256 位,运算效率提升了一倍。
另外,AVX 还添加了三操作数指令,以减少在编码时先复制再运算的动作。
AVX2 将大多数整数运算命令扩展至 256 位,同时支持 FMA(Fused Multiply-Accumulate,融合乘法累加)运算,可以在提高运算效率的同时减少运算时的精度损失。
AVX512 将 AVX 指令进一步扩展至 512 位。
AVX指令介绍, 参考该网站:Crunching Numbers with AVX and AVX2 - CodeProject
SSE有3个数据类型:__m128 , __m128d 和 m128i,分别代表Float、double (d) 和integer (i)。
AVX有3个数据类型: m256 , m256d 和 m256i,分别代表Float、double (d) 和 integer (i)。

SSE指令的数据类型
SSE指令有3种数据类型,分别为:
__m256、__m256i、__m256d。
每一种类型都以"__"+"m"+“vector的位长度”构成。
__m256
包含8个float类型数据的向量
__m256i
包含若干个整型数据的向量,如char、short、int、unsigned long long等。
例如256位的vector可以32个char、16个short、8个int,这些整型既可以是有符号的也可以是无符号的。
__m256d
包含4个double类型数据的向量。
指令
SSE指令命名约定
_mm256_<name>_<data_type>
<name>:描述了内联函数的算术操作。
<data_type>:标识函数主要参数的数据类型
从内存中加载数据
指令:_m256i _mm256_loadu_si256 (__m256i const * mem_addr)
从内存中读入一个256位的整型数据放到dst中(32字节地址无需对齐)。
dst[255:0] := MEM[mem_addr+255:mem_addr]
dst[MAX:256] := 0
指令:_m256i _mm256_load_si256 (__m256i const * mem_addr):
从内存中读入一个256位的整型数据放到dst中(32字节地址必需对齐)。
dst[255:0] := MEM[mem_addr+255:mem_addr]
dst[MAX:256] := 0
指令:_m256 _mm256_load_ps (float const * mem_addr):
从内存中读入8个float型数据放入dst(32字节地址必需对齐)。
dst[255:0] := MEM[mem_addr+255:mem_addr]
dst[MAX:256] := 0
指令:_m128 _mm_maskload_ps (float const * mem_addr, m128i mask) :
从内存中读入128位(4个float),根据mask的真假赋值。
FOR j := 0 to 3
i := j*32
IF mask[i+31]
dst[i+31:i] := MEM[mem_addr+i+31:mem_addr+i]
ELSE
dst[i+31:i] := 0
FI
ENDFOR
dst[MAX:128] := 0
指令:_m256 _mm256_maskload_ps (float const * mem_addr, m256i mask):
根据掩码载入8个float数据
FOR j := 0 to 7
i := j*32
IF mask[i+31]
dst[i+31:i] := MEM[mem_addr+i+31:mem_addr+i]
ELSE
dst[i+31:i] := 0
FI
ENDFOR
dst[MAX:256] := 0
指令:_m256 _mm256_add_ps (__m256 a, __m256 b):
将 a+b 操作按32位float进行处理,其中32位不能有溢出。
FOR j := 0 to 7
i := j*32
dst[i+31:i] := a[i+31:i] + b[i+31:i]
ENDFOR
dst[MAX:256] := 0
指令:_m256i _mm256_add_epi8 (__m256i a, __m256i b):
将 a+b 操作按8位整型进行处理,其中8位不能有溢出。
FOR j := 0 to 31
i := j*8
dst[i+7:i] := a[i+7:i] + b[i+7:i]
ENDFOR
dst[MAX:256] := 0
指令:_m256i _mm256_adds_epi8 (__m256i a, __m256i b):
将 a+b 操作按8位整型进行处理,考虑饱和问题。
FOR j := 0 to 31 i := j*8 dst[i+7:i] := Saturate8( a[i+7:i] + b[i+7:i] )ENDFORdst[MAX:256] := 0
指令:_m256i _mm256_adds_epu8 (__m256i a, __m256i b):
将 a+b 操作按8位无符号整型进行处理,考虑饱和问题。
FOR j := 0 to 31
i := j*8
dst[i+7:i] := SaturateU8( a[i+7:i] + b[i+7:i] )
ENDFOR
dst[MAX:256] := 0
指令:_mm256_fmadd_ps (__m256 a, __m256 b, __m256 c)
将a*b+c操作按32位float型进行。不要溢出。
FOR j := 0 to 7
i := j*32
dst[i+31:i] := (a[i+31:i] * b[i+31:i]) + c[i+31:i]
ENDFOR
dst[MAX:256] := 0
指令:_m256 _mm256_fnmadd_ps (__m256 a, __m256 b, __m256 c)
将 -(a*b)+c 操作按32位float型进行。不要溢出。
FOR j := 0 to 7
i := j*32
dst[i+31:i] := -(a[i+31:i] * b[i+31:i]) + c[i+31:i]
ENDFOR
dst[MAX:256] := 0
指令:_m256 _mm256_fmaddsub_ps (__m256 a, __m256 b, __m256 c)
将a*b+c操作按32位float型进行,偶数做减法,奇数做加法。
FOR j := 0 to 7
i := j*32
IF ((j & 1) == 0)
dst[i+31:i] := (a[i+31:i] * b[i+31:i]) - c[i+31:i]
ELSE
dst[i+31:i] := (a[i+31:i] * b[i+31:i]) + c[i+31:i]
FI
ENDFOR
dst[MAX:256] := 0
AVX指令_mm256_fmadd_ps使用案例
下面一小段C++程序来展示一下AVX带来的计算速度:
#include <immintrin.h>
#include <iostream>
#include <chrono>
#include <ctime>
const int N = 8;
const int loop_num = 100000000;
float gemfield_i[8] = {1.1,2.2,3.3,4.4,5.5,6.6,7.7,8.8};
float gemfield_m[8] = {2.2,3.3,4.4,5.5,6.6,7.7,8.8,9.9};
float gemfield_a[8] = {11.1,12.2,13.3,14.4,15.5,16.6,17.7,18.8};
float gemfield_o[8] = {0};
__m256 gemfield_v_i = _mm256_set_ps(8.8,7.7,6.6,5.5,4.4,3.3,2.2,1.1);
__m256 gemfield_v_m = _mm256_set_ps(9.9,8.8,7.7,6.6,5.5,4.4,3.3,2.2);
__m256 gemfield_v_a = _mm256_set_ps(18.8,17.7,16.6,15.5,14.4,13.3,12.2,11.1);
__m256 gemfield_v_o = _mm256_set_ps(0,0,0,0,0,0,0,0);
void syszuxMulAndAddV() {
auto start = std::chrono::system_clock::now();
for(int j=0; j<loop_num; j++){
gemfield_v_o += _mm256_fmadd_ps(gemfield_v_i, gemfield_v_m, gemfield_v_a);
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> elapsed_seconds = end-start;
std::cout << "resultV: ";
// float* f = (float*)&gemfield_v_o;
for(int i=0; i<N; i++){
std::cout<<gemfield_v_o[i]<<" ";
}
std::cout<< "\nelapsed time: " << elapsed_seconds.count() << "s\n";
}
void syszuxMulAndAdd(){
auto start = std::chrono::system_clock::now();
for(int j=0; j<loop_num; j++){
for(int i=0; i<N; i++){
gemfield_o[i] += gemfield_i[i] * gemfield_m[i] + gemfield_a[i];
}
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> elapsed_seconds = end-start;
std::cout << "result: ";
for(int i=0; i<8; i++){
std::cout<<gemfield_o[i]<<" ";
}
std::cout<< "\nelapsed time: " << elapsed_seconds.count() << "s\n";
}
int main() {
syszuxMulAndAdd();
syszuxMulAndAddV();
return 0;
}
编译并运行:
#compile civilnet.cpp
gemfield@ThinkPad-X1C:~$ g++ -march=skylake-avx512 civilnet.cpp -o civilnet
#run civilnet
gemfield@ThinkPad-X1C:~$ ./civilnet
result: 2.68435e+08 5.36871e+08 5.36871e+08 1.07374e+09 1.07374e+09 2.14748e+09 2.14748e+09 2.14748e+09
elapsed time: 2.39723s
resultV: 2.68435e+08 5.36871e+08 5.36871e+08 1.07374e+09 1.07374e+09 2.14748e+09 2.14748e+09 2.14748e+09
elapsed time: 0.325577s
速度比对
for loop计算消耗了2.39723秒,
而vectorization计算消耗了0.325577s,
可以看到AVX的计算速度远超for loop,因为AVX使用了下面这样的并行方式:

除了vectorization,还有什么可以让CPU计算速度更快?
如今的CPU并不是大多数程序员所想象的那个黑盒子——按照PC寄存器指向的地址load指令一条一条的执行,这样的CPU在486之后就灭绝了。
现代CPU(Intel Core2后,AMDBulldozer后)的管线宽度为4个uops,一个时钟周期内最多可以执行4条指令(如果同时有loads、stores和single-uop的ALU指令)。
因此,vectorization并不是CPU唯一一种并行计算的方式 。
指令层面同样有并行机制
在指令与指令层面同样有并行机制,可以让一个单独的CPU core在同一时间内执行多条CPU指令。
当排队中的多条CPU指令包含了loads、stores、ALU,多数现代的CPU可以在一个时钟周期内同时执行4条指令。平均下来,CPU在每个时钟周期内同时执行2条指令甚至更好——这仰仗于程序如何更好的优化。
多核的并行机制
比如,一个 cpu型号为“Core(TM) i9-9820X CPU”,cpu核为10个,使用超线程技术将CPU核扩展为20个逻辑核/线程数:
gemfield@AI3:~$ cat /proc/cpuinfo | grep -i "processor"
processor : 0
processor : 1
processor : 2
processor : 3
processor : 4
processor : 5
processor : 6
processor : 7
processor : 8
processor : 9
processor : 10
processor : 11
processor : 12
processor : 13
processor : 14
processor : 15
processor : 16
processor : 17
processor : 18
processor : 19
gemfield@AI3:~$ cat /proc/cpuinfo | grep -i "processor" | wc -l
20
在这台机器上,我们可以同时运行20个线程(因为20个核是由HT扩展出来的,真正能同时运行的线程数量位于10个到20个之间)。
只不过20个超线程对计算密集型的加速并非20倍(也即并非超线程数),而是10倍(也即cpu核数),
因此,假如一个CPU拥有20个逻辑核、10个CPU核,每个核的每个时钟周期平均执行2个vector计算,每个vector计算可以同时操作8个float数。
因此,至少在理论上,这个的机器可以在一个时钟周期内执行10 * 2 * 8 = 160个操作(当前,不同的指令有不同的吞吐量)。
系统维度的的并行机制
接下来,应用层的程序员还会熟悉这一点:多线程——在多个处理器核上同时运行多个指令序列。
这是 微观层面的cpu的时间片 调度方案。
ClickHouse中的列式存储
clickhouse就是列式储存
从数据存储讲起
我们最先接触的数据库系统,大部分都是行存储系统。
大学的时候学数据库,老师让我们将数据库想象成一张表格,每条数据记录就是一行数据,每行数据包含若干列。
所以我们对大部分数据存储的思维也就是一个复杂一点的表格管理系统。
我们在一行一行地写入数据,然后按查询条件查询过滤出我们想要的行记录。
大部分传统的关系型数据库,都是面向行来组织数据的。
如 Mysql,Postgresql。近几年,也越来越多传统数据库加入了列存储的能力。虽然列存储的技术在十几年前就已经出现,却从来没有像现在这样成为一种流行的存储组织方式。
行存储和列存储,是数据库底层组织数据的方式。(和文档型、K-V 型,时序型等概念不在一个层次)
列式存储与行式存储
首先先来看看,行式存储是怎么样的,下面那张表

当我们是行式存储的时候,数据是一行一行的存储的,如下图

但是当我们是列式存储的时候就不一样了,是一列一列存储的,如下图

Row-Store与 Column-Store对比
而clickhouse就是列式储存,但是行式存储跟列式存储有什么区别吗,或者说双方的优缺点是什么?
行式存储的优缺点:
- 优点:
- 数据都被保存到一起
- 添加,修改,删除操作相对比较容易
- 缺点:
- 当你只是想要查询一条记录中的几列的时候,会把一条记录所有列的数据搜索出来,导致搜索太慢
- 应用场景:
- 适合随机的增删改查操作
- 需要在行中选取所有属性的查询操作
- 需要频繁插入或更新的操作,其操作与索引和行的大小更为相关
列式存储的优缺点:
- 优点:
- 查询时,只有涉及到的列会被读取,所以查询速度会相对较快
- 投影很高效
- 任何列都可以作为索引
- 缺点:
- 选择完成时,被选择的列要重新组装
- 添加,修改,删除操作相对比较麻烦
- 应用场景:
- 查询需要大量行但是少数几个列
- 用于存储海量数据,并且修改操作不多的场景
| Row-Store | Column-Store |
|---|---|
| 因为按一行一行写和读取数据,因此读取数据时往往需要读取那些不必要的列 | 可以只读取必要的列 |
| 易于按记录读写数据 | 对一个一个记录的数据写入和读取都较慢 |
| 适合 OLTP 系统 | 适合 OLAP 系统 |
| 不利于大数据集的聚合统计操作 | 利于大数据集的数据聚合操作 |
| 不利于压缩数据 | 利于压缩数据 |
列存储优势
基于列模式的存储,天然就会具备以下几个优点:
-
自动索引
因为基于列存储,所以每一列本身就相当于索引。所以在做一些需要索引的操作时,就不需要额外的数据结构来为此列创建合适的索引。
-
利于数据压缩
利于压缩有两个原因。一来你会发现大部分列数据基数其实是重复的,这就可以做数据压缩。列式存储具有数据压缩特性,数据压缩比率是由压缩算法、列的数据类型、数据重复度等决定的。如果列有唯一约束,那么列中每行的数据都是唯一的,数据压缩比率就低。在InnoDB和StoneDB下,分别向具有唯一值的列插入6000万条数据,InnoDB表大小16G多,StoneDB表大小5G多,压缩比率为3:1多,而一般情况下是可以达到10:1以上的。
Apache Druid 底层数据存储就是基于列模式,另外 HBase 是一个比较有代表性的列存储模式数据库。
ClickHouse的安装和使用
环境准备
从事服务器开发工作的都会遇到,linux下open_file的值默认是1024;max user processes(用户的线程数)的值默认是4096,在实际用于中,这两个值严重不足,常常需要调整这两个值。

具体的参数介绍,请参见视频
Clickhouse stack有一个单节点的Clickhouse服务容器和一个TabixUI作为Clickhouse的客户端。
Clickhouse官方暂时没有图形化界面操作,只支持命令行下操作很不方便,不过官网提到了几个第三方的图形化界面,包括Tabix。
官网:https://tabix.io/ Tabix是一个第三方的开源Clickhouse图形化界面,免费而且是基于浏览器访问。
注,ClickHouse需要使用的端口包括用于HTTP通信的8123端口和用于主机间通信的9000端口。
SSE4.2验证
验证是否支持SSE 4.2指令集,因为向量化执行需要用到这项特性
[root@cdh1 clickhouse-alone]# grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
SSE 4.2 supported
如果不支持SSE指令集,则不能直接使用先前下载的预编译安装包,需要通过源
码编译特定的版本进行安装
Docker默认是不开启 IPv6 支持的,但是我们某些业务往往又需要 IPv6 的支持,特别是 IPv6 普及大势所趋,本文主要介绍的是如何开启 Docker 桥接网络 IPv6 支持
编辑 Docker 配置文件 /etc/docker/daemon.json,如果该文件不存在,请手动建立。配置文件内容如下,如果你已有的配置文件缺少相应的配置项,添加上即可,没有必要完全覆盖内容。
cat >/etc/docker/daemon.json <<EOF
{
"registry-mirrors":["https://almtd3fa.mirror.aliyuncs.com"]
}
EOF
vi /etc/docker/daemon.json
{
"experimental": true,
"ipv6": true,
"ip6tables": true,
"fixed-cidr-v6": "2607:f0d0:1002:51::/66"
}
ipv6设置为true,启用对ipv6的支持。
ip6tables,启用ip6tables,docker会在ip6tables中配置docker网络相关的规则链。
experimental,启用实验特性,ip6tables是docker的一个实验功能,所以需要设为true。
fixed-cidr-v6,配置ipv6子网。
添加之后
[root@cdh1 udemy-single-test]# cat /etc/docker/daemon.json
{
"registry-mirrors":["https://almtd3fa.mirror.aliyuncs.com"],
"experimental": true,
"ipv6": true,
"ip6tables": true,
"fixed-cidr-v6": "2607:f0d0:1002:51::/66"
}
这里ip6tables是指由 Docker 自动配置 IPv6 的防火墙规则,如果你希望自己手动配置,请改为 false 或者移除此项,否则容器将无法连接 IPv6 网络;fixed-cidr-v6 则是我们划分的子网段的第一个,这里仅作示例请读者根据实际情况修改。
完成配置后请使用 systemctl restart docker 重启docker服务生效。完成此步后 Docker 算是完成对于 IPv6 的支持了
ClickHouse的安装
部署代码如下:
version: '3.5'
services:
clickhouse-alone:
container_name: clickhouse-alone
image: yandex/clickhouse-server:20.4
volumes:
- ./data:/var/lib/clickhouse/
- ./config.xml:/etc/clickhouse-server/config.xml
- ./users.xml:/etc/clickhouse-server/users.xml
ports:
- "8123:8123"
- "9000:9000"
- "9009:9009"
- "9004:9004"
ulimits:
nproc: 65535
nofile:
soft: 262144
hard: 262144
healthcheck:
test: ["CMD", "wget", "--spider", "-q", "localhost:8123/ping"]
interval: 30s
timeout: 5s
retries: 3
deploy:
resources:
limits:
cpus: '4'
memory: 4096M
reservations:
memory: 4096M
networks:
ha-network-overlay:
aliases:
- clickhouse-alone
web-client:
container_name: web-client
image: spoonest/clickhouse-tabix-web-client
environment:
- CH_NAME=dev
- CH_HOST=127.0.0.1:8123
- CH_LOGIN=default
ports:
- "18080:80"
depends_on:
- clickhouse-alone
deploy:
resources:
limits:
cpus: '0.1'
memory: 128M
reservations:
memory: 128M
networks:
ha-network-overlay:
aliases:
- web-client
networks:
ha-network-overlay:
name: ha-network-overlay
driver: bridge
具体的安装过程,请参见视频
[root@cdh1 clickhouse-alone]# tail -f /home/docker-compose/clickhouse/clickhouse-alone/log/clickhouse-server.err.log
2022.09.21 19:51:31.083714 [ 1 ] {} <Warning> Access(disk): File /var/lib/clickhouse/access/users.list doesn't exist
2022.09.21 19:51:31.083739 [ 1 ] {} <Warning> Access(disk): Recovering lists in directory /var/lib/clickhouse/access/
^C
[root@cdh1 clickhouse-alone]# tail -f /home/docker-compose/clickhouse/clickhouse-alone/log/clickhouse-server.log
连接ClickHouse
ClickHouse提供了两个种接口:
- HTTP 易于直接使用。
- 本机TCP 开销较小。
建议使用适当的工具或库来连接,Yandex官方支持以下方式:
- 命令行客户端
- JDBC驱动程序
- ODBC驱动程序
- C ++客户端库
非官方的第三方库工具:
这个就太多了,支持Java、Python、PHP、Go、C等各种语言的客户端库
0 三个默认的端口:
首先看下ClickHouse配置文件,默认对外开放以下端口:
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<mysql_port>9004</mysql_port>
clickhouse-client
docker exec -it clickhouse-alone clickhouse-client --host 127.0.0.1 --port 9000 --database default --user clickhouse --password='123456'

DBeaver
免费和开源的 DBeaver ,支持几乎所有的数据库,这当然也包括ch,而且是Yandex官方推荐哦。

创建连接,可以在分析数据库中找到ch

配置好JCDB方式的连接

查看数据库对象和数据没有任何问题。

Tabix
Tabix 也是ch官方推荐的数据库管理工具,他的好处是单独部署一套web服务,用户通过浏览器就可以连接ch数据库,无需额外安装任何客户端,支持SQL语法。

安装很简单:
连接CH,注意用http端口 8123
这种性冷淡风格,很好。

配置文件介绍
为了降低修改配置的带来的风险和便于维护管理,我们将默认的配置文件做了如下拆解。

users.xml
users.xml默认的users.xml,可分为三个部分用户设置
users:主要配置用户信息如账号、密码、访问ip等及对应的权限映射配额设置
quotas:用于追踪和限制用户一段时间内的资源使用参数权限
profiles:读写权限、内存、线程等大多数参数配置为了统一管理权限
我们在users.xml预定义了对应权限及资源的quotas及profiles,例如default_profile、readwrite_profile、readonly_profile等,新增用户无需单独配置quotas及profiles,直接关联预定义好的配置即可
users.d/xxx.xml
按不同的用户属性设置user配置,
每一个xml对应一组用户,每个用户关联users.xml中的不同权限quotas及profiles
users_copy/xxx.xml
每次有变更用户操作时备份指定属性的xml,方便回滚
metrika.xml
默认情况下包含集群的配置、zookeeper的配置、macros的配置,
当有集群节点变动时,通常需要将修改后的配置文件同步整个集群,而macros 是每个服务器独有的配置,
metrika.xml 一般建议进行拆解,如果不拆解很容易造成配置覆盖,引起macros混乱丢失数据,所以我们在metrika.xml 中只保留每台服务器通用的配置信息,而将独立的配置拆解出去
conf.d/xxx.xml
保存每台服务器独立的配置,如macros.xml
config_copy/xxx.xml
存放每次修改主配置时的备份文件,方便回滚
CH的数据类型
- 整形:固定长度的整形,包括有符号整型或无符号整型
- 整型范围(-2n-1~2n-1-1):
- Int8 - [-128 : 127]
- Int16 - [-32768 : 32767]
- Int32 - [-2147483648 : 2147483647]
- Int64 - [-9223372036854775808 : 9223372036854775807]
- 无符号整型范围(0~2n-1):
- UInt8 - [0 : 255]
- UInt16 - [0 : 65535]
- UInt32 - [0 : 4294967295]
- UInt64 - [0 : 18446744073709551615]
- 整型范围(-2n-1~2n-1-1):
- 浮点型:一般数据值比较小,不涉及大量的统计计算,精度要求不高的时候。比如保存商品的重量
- Float32 - float
- Float64 – double
- 布尔型:没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
- Decimal 型:有符号的浮点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。
- 使用场景: 一般金额字段、汇率、利率等字段为了保证小数点精度,都使用 Decimal 进行存储。
- Decimal32(s),相当于 Decimal(9-s,s),有效位数为 1~9
- Decimal64(s),相当于 Decimal(18-s,s),有效位数为 1~18
- Decimal128(s),相当于 Decimal(38-s,s),有效位数为 1~38
- 字符串
- String:字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
- FixedString(N):固定长度 N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于 N 的字符串时候,通过在字符串末尾添加空字节来达到 N 字节长度。 当服务端读取长度大于 N 的字符串时候,将返回错误消息。与 String 相比,极少会使用 FixedString,因为使用起来不是很方便。
- 使用场景:名称、文字描述、字符型编码。 固定长度的可以保存一些定长的内容,比如一些编码,性别等但是考虑到一定的变化风险,带来收益不够明显,所以定长字符串使用意义有限。
- 枚举类型
- 包括 Enum8 和 Enum16 类型。Enum 保存 ‘string’= integer 的对应关系
- Enum8 用 ‘String’= Int8 对描述。
- Enum16 用 ‘String’= Int16 对描述。
- 包括 Enum8 和 Enum16 类型。Enum 保存 ‘string’= integer 的对应关系
- 时间类型
- Date 接受年-月-日的字符串比如 ‘2019-12-16’
- Datetime 接受年-月-日 时:分:秒的字符串比如 ‘2019-12-16 20:50:10’
- Datetime64 接受年-月-日 时:分:秒.亚秒的字符串比如‘2019-12-16 20:50:10.66’
CH表引擎
表引擎是Clickhouse 的一大特色。可以说,表引擎决定了如何存储表的数据。包括:
-
数据的存储方式和位置,写到哪里以及从哪里读取数据。
-
支持哪些查询以及如何支持。
-
并发数据访问。
-
索引的使用(如果存在)。
-
是否可以执行多线程请求。
-
数据复制参数。
-
表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关参数。
TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。
一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试使用。
Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。
读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大的场景
MergeTree
clickhouse中最强大的表引擎当属MergeTree引擎及该系列中的其他引擎,支持索引和分区,
MergeTree 地位可以相当于innodb之于Mysql。
而且基于MergeTree,还衍生除了很多小弟,也是非常有特色的引擎。
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
ReplacingMergeTree
ReplacingMergeTree 是 MergeTree 的一个变种,
它存储特性完全继承 MergeTree,只是多了一个去重的功能。
尽管 MergeTree 可以设置主键,但是 primary key 其实没有唯一约束的功能。如果你想处理掉重复的数据,可以借助这个 ReplacingMergeTree。
去重的时机:
数据的去重只会在合并的过程中出现。
合并会在未知的时间在后台进行,所以你无法预测先作出计划。有一些数据可能仍未被处理。
去重的范围:
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。所以ReplacingMergeTree只适用于在后台清楚重复的数据以节省空间,但是它不保证没有重复的数据出现
结论:
- 实际上是使用 order by 字段作为唯一键
- 去重不能跨分区
- 只有同一批插入(新版本)或合并分区时才会进行去重
- 认定重复的数据保留,版本字段值最大的
- 如果版本字段相同则按插入顺序保留最后一笔
SummingMergeTree
对于不查询明细,只关心以维度进行汇总聚合结果的场景。
如果只使用普通的MergeTree的话,无论是存储空间的开销,还是查询时临时聚合的开销都比较大。
ClickHouse 为了这种场景,提供了一种能够“预聚合”的引擎 SummingMergeTree
案例演示:

结论:
- 以 SummingMergeTree()中指定的列作为汇总数据列
- 可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数据列
- 以 order by 的列为准,作为维度列
- 其他的列按插入顺序保留第一行
- 不在一个分区的数据不会被聚合
- 只有在同一批次插入(新版本)或分片合并时才会进行聚合
CH的基本操作
DDL建表
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
-
partition by 表示的是分区,上述sql所用的就是说根据创建时间进行分区
-
primary key 代表的是主键,特点如下:
- 并不会唯一
- 索引
-
order by 代表的是根据那两个字段进行排序

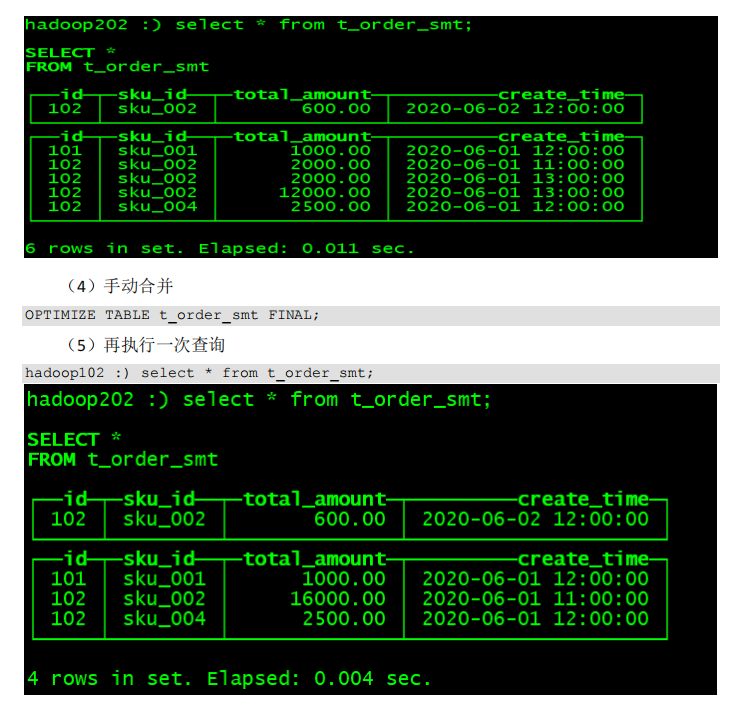
尝试插入数据
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');

通过命令执行 : SELECT * FROM t_order_mt tom

发现结果分为两部分, 是因为建表的时候,根据 create_time进行了分区
以上实操过程, 尼恩会在视频中,做详细解读
partition by 分区(可选)
作用:降低扫描的范围,优化查询速度
分区目录:
MergeTree是以列文件 + 索引文件 + 表定义文件组成的,但是如果设定了分区,那么这些文件就会保存到不同的分区目录中。
并行:
分区后,面对涉及跨分区的查询统计,Clickhouse会以分区为单位并行处理。
数据写入与分区合并:
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。
写入后的某个时刻,clickhouse会自动执行合并操作,把临时分区的数据,合并到已有分区中。
分区文件目录:
- bin文件:数据文件
- mrk文件:标记文件
- 标记文件在idx索引文件和bin数据文件之间起了桥梁作用
- 以mrk2结尾的文件,表示该表启用了自适应索引间隔
- primary.idx文件:主键索引文件,用于加快查询效率
- minmax_create_time.idx:分区键的最大最小值
- checksums.txt:校验文件,用于校验各个文件的正确性。存放各个文件的size以及hash值
分区id生成规则:
-
未定义分区键:没有定义partition by, 默认生成一个目录名为all的数据分区,所有数据均存放在all目录下。
-
整型分区键:分区键为整型,那么直接用该整型值的字符串形式做为分区ID
-
日期类分区键:分区键为日期类型,或者可以转化为日期类型。
-
其他类型分区键:String,Float类型等,通过128位的Hash算法取其Hash值作为分区ID
-
MinBlockNum:最小分区块编号,自增类型,从1开始向上递增。
-
MaxBlockNum:最大分区块编号,新创建的分区MinBlockNum等于MaxBlockNum的编号
primary key 主键(可选)
clickhouse中的主键只提供了数据的一级索引,但是却不是唯一约束。
这就意味着是可以存在相同primary key的数据的。
主键的设定主要依据: 是查询语句中的where条件
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的索引粒度(index granularity),避免了全表扫描
index granularity:索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。
Clickhouse中的MergeTree默认是8192.
官方不建议修改这个值,除非该列存在大量重复值。
稀疏索引:
是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描。

order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理(比如后面会讲的去重和汇总)。
要求:
主键必须是 order by 字段的前缀字段。
比如 order by 字段是 (id,sku_id) , 那么主键必须是 id 或者(id,sku_id)
数据TTL
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能。


SQL操作
Insert
在表内插入一条数据:
insert into [table_name] values(…),(….)
在表内插入一个表的数据:
insert into [table_name] select a,b,c from [table_name_2]
Update 和 Delete
ClickHouse 提供了 Delete 和 Update 的能力,这类操作被称为 Mutation 查询,它可以看做 Alter 的一种。
虽然可以实现修改和删除,但是和一般的 OLTP 数据库不一样,Mutation 语句是一种很“重”的操作,而且不支持事务。
“重”的原因主要是:
每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。
所以尽量做批量的变更,不要进行频繁小数据的操作。
删除操作:
alter table t_order_smt delete where sku_id =‘sku_001’;
修改操作:
alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id =102;
由于操作比较“重”,所以 Mutation 语句分两步执行,
- 同步执行的部分其实只是进行新增数据新增分区和并把旧分区打上逻辑上的失效标记。
- 直到触发分区合并的时候,才会删除旧数据释放磁盘空间,一般不会开放这样的功能给用户,由管理员完成。
查询操作
ClickHouse 基本上与标准 SQL 差别不大:
-
支持子查询
-
支持 CTE(Common Table Expression 公用表表达式 with 子句)
-
支持各种 JOIN,但是 JOIN 操作无法使用缓存,所以即使是两次相同的 JOIN 语句,ClickHouse 也会视为两条新 SQL
-
GROUP BY

-
GROUP BY 操作增加了 with rollup\with cube\with total 用来计算小计和总计。
-
GROUP BY with rollup:从右至左去掉维度进行小计
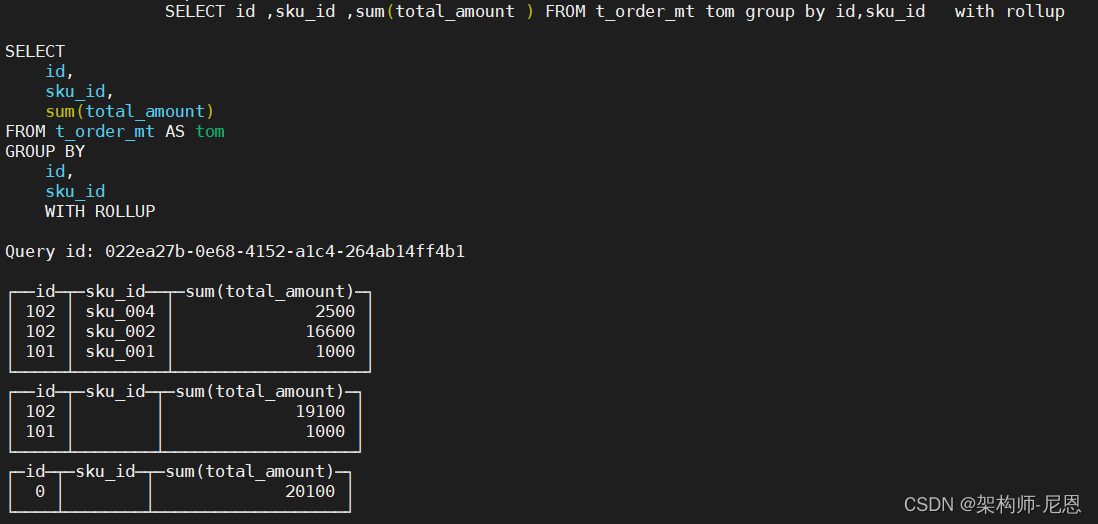
-
GROUP BY with cube : 从右至左去掉维度进行小计,再从左至右去掉维度进行小计
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gmJvnMuB-1663815310200)(C:\Users\nien\AppData\Roaming\Typora\typora-user-images\1663815123052.png)]
-
GROUP BY with totals: 只计算合计

alter 操作
- 新增字段:alter table tableName add column newcolname String after col1;
- 修改字段类型:alter table tableName modify column newcolname String;
- 删除字段:alter table tableName drop column newcolname;
以上实操过程, 尼恩会在视频中,做详细解读
CH高可用分片集群的多种架构
高可用集群的目标
高可用的目标是 4个9,甚至5个9
系统可用性(Availability)是信息工业界用来衡量一个信息系统提供持续服务的能力,它表示的是在给定时间区间内系统或者系统某一能力在特定环境中能够正常工作的概率。
简单地说, 可用性是平均故障间隔时间(MTBF)除以平均故障间隔时间(MTBF)和平均故障修复时间(MTTR)之和所得的结果, 即:

通常业界习惯用N个9来表征系统可用性,表示系统可以正常使用时间与总时间(1年)之比,比如:
- 99.9%代表3个9的可用性,意味着全年不可用时间在8.76小时以内,表示该系统在连续运行1年时间里最多可能的业务中断时间是8.76小时;
- 99.99%代表4个9的可用性,意味着全年不可用时间在52.6分钟以内,表示该系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟;
- 99.999%代表5个9的可用性,意味着全年不可用时间必须保证在5.26分钟以内,缺少故障自动恢复机制的系统将很难达到5个9的高可用性。
那么X个9里的X只代表数字35,为什么没有12,也没有大于6的呢?
我们接着往下计算:
1个9:(1-90%)*365=36.5天
*2个9:(1-99%)*365=3.65天
6个9:(1-99.9999%)*365*24*60*60=31秒
可以看到1个9和、2个9分别表示一年时间内业务可能中断的时间是36.5天、3.65天,这种级别的可靠性或许还不配使用“可靠性”这个词;
而6个9则表示一年内业务中断时间最多是31秒,那么这个级别的可靠性并非实现不了,而是要做到从“5个9” 到“6个9”的可靠性提升的话,后者需要付出比前者几倍的成本。
高可用表引擎1: Distributed 分布式表
分布式引擎本身不存储数据, 但可以在多个服务器上进行分布式查询。
Distributed 分布式引擎可以理解为ES集群中的 ClientNode
读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
我们可以引申理解它就相当于关系型数据库中的视图概念。
示例:ENGINE = Distributed(<集群名称>, <库名>, <表名>[, sharding_key])
与分布式表对应的是本地表,
也就是上面的<表名>参数,查询分布式表的时候,ClickHouse会自动查询所有分片,然后将结果汇总后返回
向分布式表插入数据
ClickHouse会根据分片权重将数据分散插入到各个分片中
默认情况下,每个分片中所有副本都会写入数据
或者通过参数internal_replication配置每个分片只写入其中一个副本,使用复制表(ReplicateMergeTree)管理数据的副本
高可用相关的表引擎2: ReplicatedMergeTree 复制表
ReplicatedMergeTree
ReplicatedSummingMergeTree
ReplicatedReplacingMergeTree
ReplicatedAggregatingMergeTree
ReplicatedCollapsingMergeTree
ReplicatedVersionedCollapsingMergetree
ReplicatedGraphiteMergeTree
注意:只有MergeTree系列引擎支持Replicated前缀
-
副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复制表和非复制表
-
副本不依赖分片。每个分片有它自己的独立副本
-
数据副本使用到Zookeeper,需要在metrika.xml中配置zk的集群信息
-
SELECT 查询并不需要借助 ZooKeeper ,副本并不影响 SELECT 的性能,查询复制表与非复制表速度是一样的
-
默认情况下,INSERT 语句仅等待一个副本写入成功后返回。
如果数据只成功写入一个副本后该副本所在的服务器不再存在,则存储的数据会丢失。
要启用数据写入多个副本才确认返回,使用 insert_quorum选项
-
数据块会去重。
对于被多次写的相同数据块(大小相同且具有相同顺序的相同行的数据块),该块仅会写入一次
示例:
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}')
大括号中的参数是metrika.xml中macros配置的,
每个节点读取自己的配置信息,统一了建表语句
第一个参数用于zk中的目录结构,用了layer-shard名称分层
第二个参数是副本名,用于标识同一个表分片的不同副本,同个分片中不同副本的副本名称要唯一
CH高可用方案1:MergeTree 本地表 + Distributed分布式表
每个分片中只有一个副本,数据存储在 本地表(MergeTree),
查询分布式表,引擎自动向所有分片查询数据并计算后返回

优势
架构简单,单机和分布式都可以用
劣势
单点问题,数据丢失风险大
CH高可用方案2:MergeTree 本地表 + Distributed 分布式 + 多副本
在方案一的基础上为每个节点增加副本

优势
在1.0的基础上,数据安全有了保障,任何一个实例或者服务器挂掉了,不影响集群查询服务
劣势
如果某个节点挂了,恢复以后可以将丢失的增量数据补全,
但是如果硬盘彻底损坏,存量数据基本无法恢复,
且这种方案不能用两个节点互为主备,会造成数据错乱
CH高可用方案3:ReplicatedMergeTree + Distributed + 多副本
把2.0方案中的数据表引擎替换成 ReplicatedMergeTree,并设置分布式写入时, 只写入分片的一个节点:
internal_replication 设置为true
实现同一个分片中,写入一个节点的数据后,自动同步到其他的副本中
下图实现的是一个节点启动多个ClickHouse实例

优势
由 ReplicatedMergeTree 表引擎管理数据副本(依赖Zookeeper),无须担心节点挂掉后数据的同步和丢失问题
劣势
集群配置比较复杂, macros配置分片和副本需要仔细
metrika.xml配置

节点扩展

在ClickHouse集群中使用复制表引擎 ReplicatedMergeTree 建立本地表,
插入的数据会在ClickHouse的副本间进行自动复制,实现数据的高可用效果
实操:CH分布式集群方案
高可用集群的架构方案
首先来看下本节内容大致的架构:

如上图,整个集群一共 4 个节点,分为两个分片,每个分片一个副本。
除了在每个节点创建 ReplicatedMergeTree 表,还会创建 Distributed 引擎的总表,
Distributed 引擎的总表是 各个节点上的本地表的总代理,写入、查询、分发等操作都经过分布式总表路由。
ClickHouse的集群层级
ClickHouse的集群层级,对应metrika.xml配置中的macros节点:
集群《layer》 => 分片《shard》 => 副本《replica》 (每个ClickHouse实例都可以看做一个副本)
| Cluster | 一个集群可以包括若干个Cluster |
|---|---|
| Shard | 一个Cluster可以包括若干个Shard |
| 一个Shard又可以包含若干个Replicate | |
| 一个Replicate就是一个特定的节点实例 |
ClickHouse集群信息基于手工编写配置文件metrika.xml,默认加载/etc/metrika.xml,
为了方便管理我们在主配置文件中引用/etc/clickhouse-server/metrika.xml,
集群搭建完毕后可查询系统表system.clusters,查看集群配置信息
metrika.xml 配置如下:
增加集群配置文件:metrika.xml文件
创建metrika.xml文件
在/etc/clickhouse-server/config.d/目录下创建metrika.xml
加入如下内容:
<yandex>
<clickhouse_remote_servers>
<!-- 自定义的集群名称 -->
<!-- 2分片1副本 -->
<!-- 数据分片1 -->
<cluster_1>
<!-- 分片信息 -->
<shard>
<weight>1</weight>
<!-- 分布式表写入数据是否只写入到一个副本,配合复制表引擎使用,默认false -->
<internal_replication>true</internal_replication>
<!-- 分片副本信息,这里指定的用户名密码只能是明文,如果需要密文密码需要将配置指向users.xml中的profile中 -->
<replica>
<host>clickhouse-01</host>
<port>9000</port>
<!-- <user>xxx</user>
<password>xxx</password> -->
</replica>
<replica>
<host>clickhouse-03</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>clickhouse-02</host>
<port>9000</port>
</replica>
<replica>
<host>clickhouse-04</host>
<port>9000</port>
</replica>
</shard>
</cluster_1>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>clickhouse-zookeeper</host>
<port>2181</port>
</node>
</zookeeper-servers>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
注意修改 zk 以及各个节点的信息。
分发到其他节点,同时修改macros标签里面的值为对应的服务器
以上配置实操过程, 尼恩会在视频中,做详细解读
引入metrika.xml
配置完metrika.xml后,我们需要将metrika.xml引入配置中。在config.xml引入metrika.xml, config.xml就是clickhouse的全局配置。
路径默认是:/etc/clickhouse-server/config.xml
在该配置文件中添加以下配置:
<!--引入metrika.xml-->
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
macros.xml宏设置
每个实例都有自己的宏设置,如服务器1:
<yandex>
<macros>
<replica>clickhouse-01</replica>
<shard>01</shard>
<layer>01</layer>
</macros>
</yandex>
确保宏设置等于metrika.xml中的远程服务器设置
启动集群
docker-compose up -d
关于集群的启动/设置/架构,请参加尼恩的视频
启动检查
1、查询当前的集群信息
select * from system.clusters;

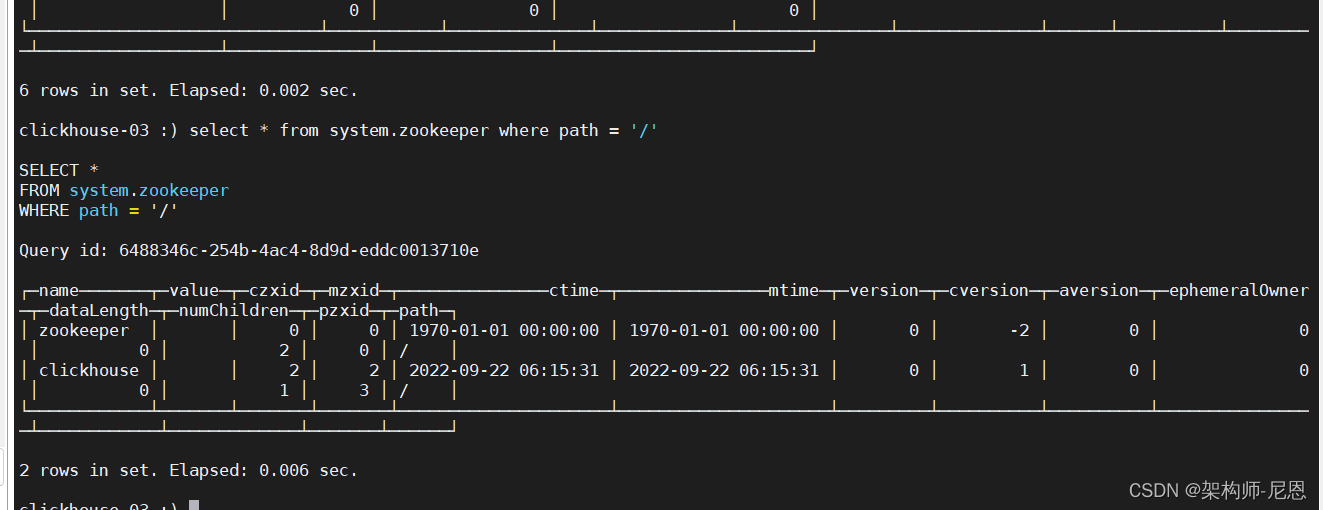
2、查询zookeeper信息
在ClickHouse系统表中,提供了一张Zookeeper代理表,
我们可以使用SQL轻松访问Zookeeper内的数据,不用再像以前一样使用客户端登录进去查看。
#查询Zookeeper根目录
select * from system.zookeeper where path = '/'
#查询ClickHouse目录
select * from system.zookeeper where path = '/clickhouse'

生产环境建议配置上Kerberos安全认证。
以上具体的实操过程, 尼恩会在视频中,做详细解读
集群数据写入
创建本地表
现在我们有了群集和副本设置。接下来,需要在每个服务器中创建ReplicatedMergeTree表作为本地表。
CREATE TABLE ttt (id Int32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/ttt', '{replica}') PARTITION BY id ORDER BY id
先解释一下 ReplicatedMergeTree 引擎用法:
ENGINE = ReplicatedMergeTree('zk_path', 'replica_name')
zk_path :
用于指定在 zk 中创建数据表的路径,一般 zk_path 建议配置成如下形式:
/clickhouse/{cluster}/{shard}/{table_name}
- {cluster} 表示集群名;
- {shard} 表示分片编号;
- {table_name} 表示数据表的名称。
需要注意的是: zk_path 的定义,同一分片不同副本,需要定义相同的路径。
replica_name
replica_name 用于设置副本名称
需要注意的是: 同一分片不同副本,需要定义不同的名称;
上面两句话如果感觉有点绕,可以对比下面这 4 个节点的本地表建表语句,应该就可以理解啦。
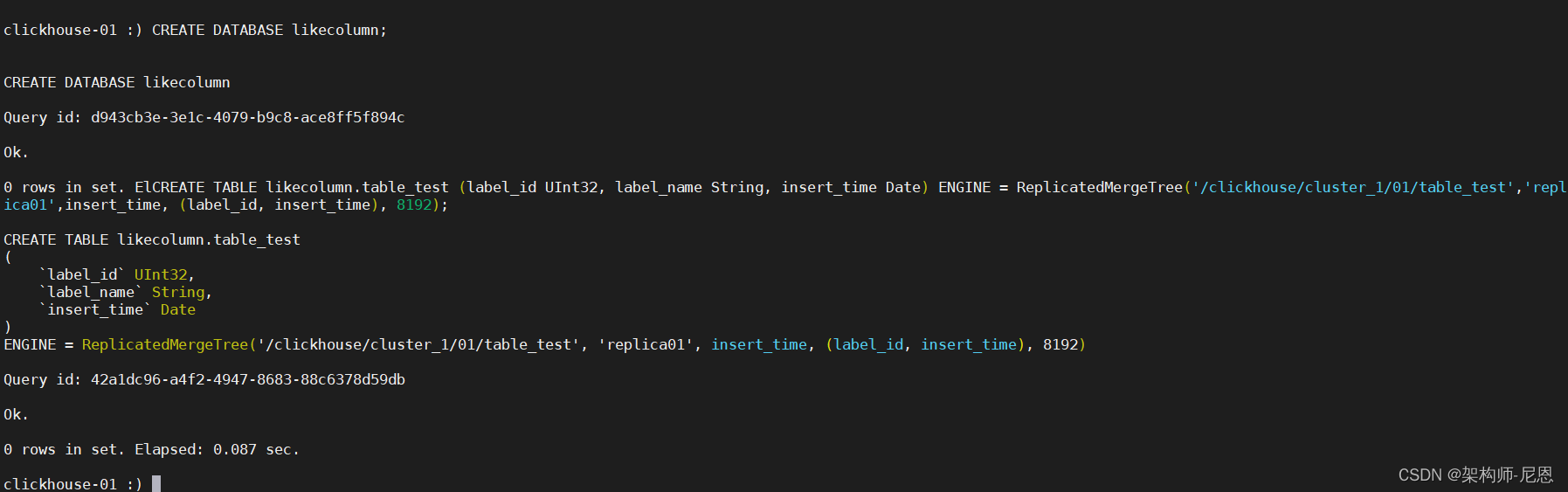
在 clickhouse-01上:
CREATE DATABASE likecolumn;
CREATE TABLE likecolumn.table_test (label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/cluster_1/01/table_test','replica01',insert_time, (label_id, insert_time), 8192)
在 clickhouse-03上:
CREATE DATABASE likecolumn;
CREATE TABLE likecolumn.table_test (label_id UInt32, label_name String, insert_time Date) ENGINE =
ReplicatedMergeTree('/clickhouse/cluster_1/01/table_test','replica02',insert_time, (label_id, insert_time), 8192)

在clickhouse-02上:
CREATE DATABASE likecolumn;
CREATE TABLE likecolumn.table_test ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/cluster_1/02/table_test','replica01',insert_time, (label_id, insert_time), 8192)

在clickhouse-04上:
CREATE DATABASE likecolumn;
CREATE TABLE likecolumn.table_test ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/cluster_1/02/table_test','replica02',insert_time, (label_id, insert_time), 8192)
创建分布式总表
任选一个集群内的节点创建分布式总表:
CREATE TABLE likecolumn.table_test_all AS likecolumn.table_test ENGINE = Distributed(cluster_1, likecolumn, table_test, rand())

这里解释一下 Distributed 引擎用法: ENGINE = Distributed(cluster, database, table, sharding_key)
- cluster:集群名
- database 和 table:库表名
- sharding_key:分片键,选填。
高可靠写入数据
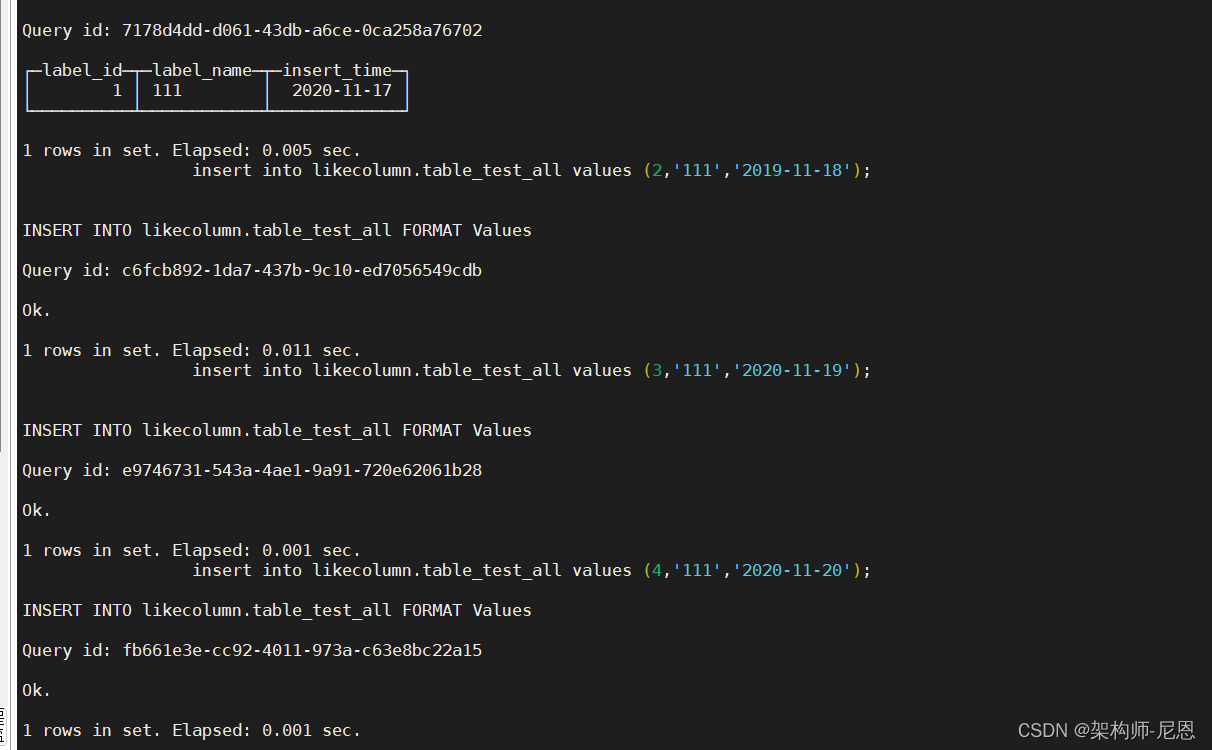
在创建了分布式总表的节点写入数据:
insert into likecolumn.table_test_all values (1,'111','2020-11-17');
insert into likecolumn.table_test_all values (2,'111','2019-11-18');
insert into likecolumn.table_test_all values (3,'111','2020-11-19');
insert into likecolumn.table_test_all values (4,'111','2020-11-20');

查询总表数据
select * from likecolumn.table_test_all ;

查询各个分片本地表的数据。
select * from likecolumn.table_test ;
04节点

02节点

01节点
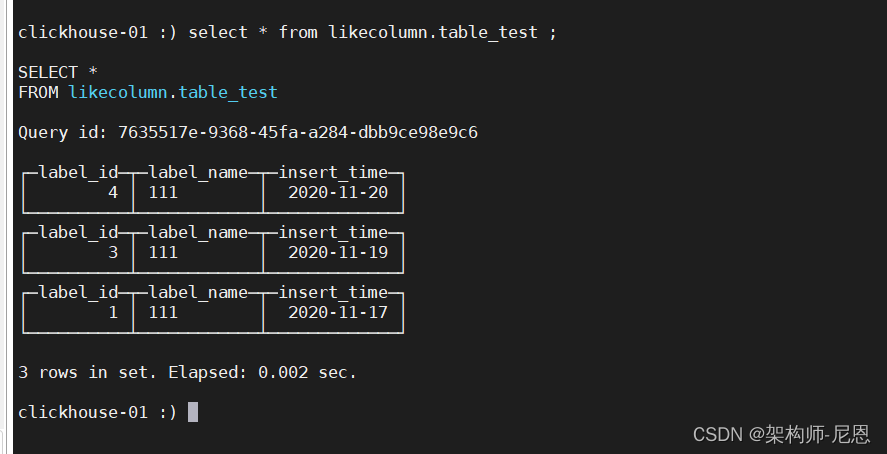
高可用测试
停掉 192.168.150.123 的 ClickHouse 服务:
docker-compose stop clickhouse-01
docker-compose start clickhouse-01

insert into likecolumn.table_test_all values (5,'111','2020-11-20');
select * from likecolumn.table_test_all ;
发现整个集群仍然可以正常写入和查询:

以上具体的实操过程, 尼恩会在视频中,做详细解读
Zookeeper在ClickHouse中的作用
Zookeeper作为一个分布式一致性存储服务,提供了丰富的读写接口和watch机制,
分布式应用基于Zookeeper可以解决很多常见问题,例如心跳管理、主备切换、分布式锁等
ClickHouse中依赖Zookeeper解决哪些问题?
(1)分布式DDL执行。
如:ClickHouse中DDL执行默认不是分布式的,
用户需要在DDL语句中加上on Cluster XXX的申明才能触发这个功能
(2)ReplicatedMergeTree表主备节点之间的状态同步
ClickHouse分布式DDL和其他完全分布式化的数据库有什么不同?
ClickHouse分布式DDL:
(1)ClickHouse对库、表的管理都是在存储节点级别独立的,集群中各节点之间的库、表元数据信息没有一致性约束
原因是:由ClickHouse的架构特色决定的
-
彻底Share Nothing,各节点之间完全没有相互依赖
-
节点完全对等,集群中的节点角色统一
ClickHouse没有传统MPP数据库中的前端节点、Worker节点、元数据节点等概念
-
ClickHouse的这种架构特色决定它可以敏捷化、小规模部署,集群可以任意进行分裂、合并。前提要求是感知数据在集群节点上的分布
(2)用户可以直接连接任意一个节点进行请求,当用户发送DDL命令时,默认只会在当前连接的节点执行命令
思考:现实中如果用户有一个100台机器的集群,为了创建一个分布式存储的表难道用户需要依次连接每台机器发送DDL命令吗?
这个问题会导致:多个DDL之间的冲突问题无法解决
举例:用户A和用户B同时创建同名表但是表字段又不一致,这肯定会让系统陷入一个诡异的不一致状态
| Cluster | 一个集群可以包括若干个Cluster |
|---|---|
| Shard | 一个Cluster可以包括若干个Shard |
| 一个Shard又可以包含若干个Replicate | |
| 一个Replicate就是一个特定的节点实例 |
实现过程
思路:用户可以通过ClickHouse启动的config.xml来配置这套节点规划逻辑
如何配置:用户可以把一个集群规划成若干个Cluster,每个Cluster可自定义Shard数量,每个Shard又可以自定义副本数量
说明:单个存储节点内部不同Cluster之间的表都是相互可见的
传统的MPP数据库与Clickhouse的MPP数据库的区别?
| 传统的MPP数据库 | 没有表级别的自定义副本数能力,只能做全库的副本数配置 |
| Clickhouse的MPP数据库 | (1)ClickHouse能做到表的Replicate数量自定义技术核心 |
| (2)是它把主备同步逻辑放到了具体的表引擎中实现,而不是在节点级别做数据复制 |
注意:当前只有ReplicatedMergeTree表引擎可以自动做主备状态同步,其他表引擎没有状态同步机制
如果用户需要在多副本Cluster下创建其他表引擎,如何做?
需要在写入链路上配置多写逻辑
ReplicatedMergeTree表引擎的同步包括哪些?
-
写入同步、
-
异步Merge同步、
-
异步Mutation同步等;
注意:它所有的同步逻辑都是强依赖Zookeeper
分布式DDL执行链路
哪些操作是可以走分布式DDL执行链路?
| ASTCreateQuery | 包括常见的建库、建表、建视图,还有ClickHouse独有的Attach Table(可以从存储文件中直接加载一个之前卸载的数据表) |
| ASTAlterQuery: | 包括ATTACH_PARTITION、FETCH_PARTITION、FREEZE_PARTITION、FREEZE_ALL等操作(对表的数据分区粒度进行操作) |
| ASTDropQuery: | 其中包含了三种不同的删除操作(Drop / Truncate / Detach),Detach Table和Attach Table对应,它是表的卸载动作,把表的存储目录整个移到专门的detach文件夹下 |
| ASTOptimizeQuery: | 这是MergeTree表引擎特有的操作命令,它可以手动触发MergeTree表的合并动作,并可以强制数据分区下的所有Data Part合并成一个 |
| ASTRenameQuery | 修改表名,可更改到不同库下 |
| ASTKillQueryQuery: | 可以Kill正在运行的Query,也可以Kill之前发送的Mutation命令 |
ES和CK的查询对比
Elasticsearch 是一个实时的分布式搜索分析引擎,它的底层是构建在 Lucene 之上的。简单来说是通过扩展 Lucene 的搜索能力,使其具有分布式的功能。
ES 通常会和其它两个开源组件 Logstash(日志采集)和 Kibana(仪表盘)一起提供端到端的日志/搜索分析的功能,常常被简称为 ELK。
Clickhouse 是俄罗斯搜索巨头 Yandex 开发的面向列式存储的关系型数据库。ClickHouse 是过去两年中 OLAP 领域中最热门的,并于 2016 年开源。
ES 是最为流行的大数据日志和搜索解决方案,但是近几年来,它的江湖地位受到了一些挑战,许多公司已经开始把自己的日志解决方案从 ES 迁移到了 Clickhouse,这里就包括:携程,快手等公司。
架构和设计的对比
ES 的底层是 Lucence,主要是要解决搜索的问题。搜索是大数据领域要解决的一个常见的问题,就是在海量的数据量要如何按照条件找到需要的数据。搜索的核心技术是倒排索引和布隆过滤器。
ES 通过分布式技术,利用分片与副本机制,直接解决了集群下搜索性能与高可用的问题。

ElasticSearch 是为分布式设计的,有很好的扩展性,在一个典型的分布式配置中,每一个节点(node)可以配制成不同的角色。

如上图所示:
Client Node,负责 API 和数据的访问的节点,不存储/处理数据。Data Node,负责数据的存储和索引。Master Node,管理节点,负责 Cluster 中的节点的协调,不存储数据。ClickHouse 是基于 MPP 架构的分布式 ROLAP(关系 OLAP)分析引擎。每个节点都有同等的责任,并负责部分数据处理(不共享任何内容)。
ClickHouse 是一个真正的列式数据库管理系统(DBMS)。
在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。
让查询变得更快,最简单且有效的方法是减少数据扫描范围,和减少数据传输时的大小,而列式存储和数据压缩就可以帮助实现上述两点。
Clickhouse 同时使用了日志合并树,稀疏索引和 CPU 功能(如 SIMD 单指令多数据)充分发挥了硬件优势,可实现高效的计算。
Clickhouse 使用 Zookeeper 进行分布式节点之间的协调。

为了支持搜索,Clickhouse 同样支持布隆过滤器。
对比的环境
ES stack
ES stack有一个单节点的Elastic的容器和一个Kibana容器组成,Elastic是被测目标之一,Kibana作为验证和辅助工具。部署代码如下:
version: '3.7'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.4.0
container_name: elasticsearch
environment:
- xpack.security.enabled=false
- discovery.type=single-node
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
cap_add:
- IPC_LOCK
volumes:
- elasticsearch-data:/usr/share/elasticsearch/data
ports:
- 9200:9200
- 9300:9300
deploy:
resources:
limits:
cpus: '4'
memory: 4096M
reservations:
memory: 4096M
kibana:
container_name: kibana
image: docker.elastic.co/kibana/kibana:7.4.0
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
ports:
- 5601:5601
depends_on:
- elasticsearch
volumes:
elasticsearch-data:
driver: local
Clickhouse stack
Clickhouse stack有一个单节点的Clickhouse服务容器和一个TabixUI作为Clickhouse的客户端。部署代码如下:
version: "3.7"
services:
clickhouse:
container_name: clickhouse
image: yandex/clickhouse-server
volumes:
- ./data/config:/var/lib/clickhouse
ports:
- "8123:8123"
- "9000:9000"
- "9009:9009"
- "9004:9004"
ulimits:
nproc: 65535
nofile:
soft: 262144
hard: 262144
healthcheck:
test: ["CMD", "wget", "--spider", "-q", "localhost:8123/ping"]
interval: 30s
timeout: 5s
retries: 3
deploy:
resources:
limits:
cpus: '4'
memory: 4096M
reservations:
memory: 4096M
tabixui:
container_name: tabixui
image: spoonest/clickhouse-tabix-web-client
environment:
- CH_NAME=dev
- CH_HOST=127.0.0.1:8123
- CH_LOGIN=default
ports:
- "18080:80"
depends_on:
- clickhouse
deploy:
resources:
limits:
cpus: '0.1'
memory: 128M
reservations:
memory: 128M
- 数据导入 stack
数据导入部分使用了Vector.dev开发的vector,该工具和fluentd类似,都可以实现数据管道式的灵活的数据导入。 - 测试控制 stack
测试控制我使用了Jupyter,使用了ES和Clickhouse的Python SDK来进行查询的测试。
用Docker compose启动ES和Clickhouse的stack后,我们需要导入数据,我们利用Vector的generator功能,生成syslog,并同时导入ES和Clickhouse,在这之前,我们需要在Clickhouse上创建表。ES的索引没有固定模式,所以不需要事先创建索引。
创建表的代码如下:
CREATE TABLE default.syslog(
application String,
hostname String,
message String,
mid String,
pid String,
priority Int16,
raw String,
timestamp DateTime('UTC'),
version Int16
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY timestamp
TTL timestamp + toIntervalMonth(1);
查询来做一个对比
ES使用自己的查询语言来进行查询,Clickhouse支持SQL,我简单测试了一些常见的查询,并对它们的功能做一些比较。
- 返回所有的记录
# ES
{
"query":{
"match_all":{}
}
}
# Clickhouse
"SELECT * FROM syslog"
- 匹配单个字段
# ES
{
"query":{
"match":{
"hostname":"for.org"
}
}
}
# Clickhouse
"SELECT * FROM syslog WHERE hostname='for.org'"
- 匹配多个字段
# ES
{
"query":{
"multi_match":{
"query":"up.com ahmadajmi",
"fields":[
"hostname",
"application"
]
}
}
}
# Clickhouse、
"SELECT * FROM syslog WHERE hostname='for.org' OR application='ahmadajmi'"
- 单词查找,查找包含特定单词的字段
# ES
{
"query":{
"term":{
"message":"pretty"
}
}
}
# Clickhouse
"SELECT * FROM syslog WHERE lowerUTF8(raw) LIKE '%pretty%'"
- 范围查询, 查找版本大于2的记录
# ES
{
"query":{
"range":{
"version":{
"gte":2
}
}
}
}
# Clickhouse
"SELECT * FROM syslog WHERE version >= 2"
查找到存在某字段的记录
ES是文档类型的数据库,每一个文档的模式不固定,所以会存在某字段不存在的情况;
而Clickhouse对应为字段为空值
# ES
{
"query":{
"exists":{
"field":"application"
}
}
}
# Clickhouse
"SELECT * FROM syslog WHERE application is not NULL"
正则表达式查询
正则表达式查询,查询匹配某个正则表达式的数据
# ES
{
"query":{
"regexp":{
"hostname":{
"value":"up.*",
"flags":"ALL",
"max_determinized_states":10000,
"rewrite":"constant_score"
}
}
}
}
# Clickhouse
"SELECT * FROM syslog WHERE match(hostname, 'up.*')"
聚合计数
统计某个字段出现的次数
# ES
{
"aggs":{
"version_count":{
"value_count":{
"field":"version"
}
}
}
}
# Clickhouse
"SELECT count(version) FROM syslog"
聚合不重复的值,查找所有不重复的字段的个数
# ES
{
"aggs":{
"my-agg-name":{
"cardinality":{
"field":"priority"
}
}
}
}
# Clickhouse
"SELECT count(distinct(priority)) FROM syslog "
ReplicatedMergeTree引擎
ReplicatedMergeTree是MergeTree的派生引擎,它在MergeTree的基础上加入了分布式协同的能力,只有使用了ReplicatedMergeTree 复制表系列引擎,才能应用副本的能力。
或者用一种更为直接的方式理解,即使用ReplicatedMergeTree的数据表就是副本。
ReplicatedMergeTree与MergeTree的逻辑关系
ReplicatedMergeTree与MergeTree的逻辑关系, 如下图所示:

在MergeTree中,一个数据分区由开始创建到全部完成,会历经两类存储区域。
-
内存:
数据首先会被写入内存缓冲区。
-
本地磁盘:
数据接着会被写入tmp临时目录分区,待全部完成后,再将临时目录重命名为正式分区。
ReplicatedMergeTree如何做到数据复制的呢?
ReplicatedMergeTree在上述MergeTree基础之上增加了ZooKeeper的部分,
它会进一步在ZooKeeper内创建一系列的监听节点,并以此实现多个实例之间的通信。
在整个通信过程中,ZooKeeper并不会涉及表数据的传输。
ReplicatedMergeTree特点
作为数据副本的主要实现载体,ReplicatedMergeTree在设计上有一些显著特点。
-
依赖ZooKeeper:在执行
INSERT和ALTER查询的时候,ReplicatedMergeTree需要借助ZooKeeper的分布式协同能力,以实现多个副本之间的同步。但是在查询副本的时候,并不需要使用ZooKeeper。
-
表级别的副本:
副本是在表级别定义的,
所以每张表的副本配置都可以按照它的实际需求进行个性化定义,包括副本的数量,以及副本在集群内的分布位置等。
-
多主架构(Multi Master):
可以在任意一个副本上执行
INSERT和ALTER查询,它们的效果是相同的。这些操作会借助ZooKeeper的协同能力被分发至每个副本以本地形式执行。
-
Block数据块:
在执行INSERT命令写入数据时,会依据 max_insert_block_size的大小(默认1048576行)将数据切分成若干个Block数据块。
所以Block数据块是数据写入的基本单元,并且具有写入的原子性和唯一性。
-
原子性:
在数据写入时,一个Block块内的数据要么全部写入成功,要么全部失败。
-
唯一性:
在写入一个Block数据块的时候,会按照当前Block数据块的数据顺序、数据行和数据大小等指标,计算Hash信息摘要并记录在案。在此之后,如果某个待写入的Block数据块与先前已被写入的Block数据块拥有相同的Hash摘要(Block数据块内数据顺序、数据大小和数据行均相同),则该Block数据块会被忽略。
ZooKeeper内的节点结构
ReplicatedMergeTree需要依靠ZooKeeper的事件监听机制以实现各个副本之间的协同。
所以,在每张ReplicatedMergeTree表的创建过程中,它会以zk_path为根路径,在ZooKeeper中为这张表创建一组监听节点。
按照作用的不同,监听节点可以大致分成如下几类:
-
元数据
- /metadata:保存元数据信息,包括主键、分区键、采样表达式等。
- /columns:保存列字段信息,包括列名称和数据类型。
- /replicas:保存副本名称,对应设置参数中的
replica_name。
-
判断标识
- /leader_election:用于主副本的选举工作,主副本会主导
MERGE和MUTATION操作(ALTER DELETE和ALTER UPDATE)。这些任务在主副本完成之后再借助ZooKeeper将消息事件分发至其他副本。 - /blocks:记录Block数据块的Hash信息摘要,以及对应的
partition_id。通过Hash摘要能够判断Block数据块是否重复;通过partition_id,则能够找到需要同步的数据分区。 - /block_numbers:按照分区的写入顺序,以相同的顺序记录
partition_id。各个副本在本地进行MERGE时,都会依照相同的block_numbers顺序进行。 - /quorum:记录
quorum的数量,当至少有quorum数量的副本写入成功后,整个写操作才算成功。quorum的数量由insert_quorum参数控制,默认值为0。
- /leader_election:用于主副本的选举工作,主副本会主导
-
操作日志
-
/log:常规操作日志节点(
INSERT、MERGE和DROP PARTITION),它是整个工作机制中最为重要的一环,保存了副本需要执行的任务指令。log使用了ZooKeeper的持久顺序型节点,每条指令的名称以log-为前缀递增,例如log-0000000000、log-0000000001等。每一个副本实例都会监听/log节点,当有新的指令加入时,它们会把指令加入副本各自的任务队列,并执行任务。 -
/mutations:MUTATION操作日志节点,作用与log日志类似,当执行
ALERT DELETE和ALERT UPDATE查询时,操作指令会被添加到这个节点。mutations同样使用了ZooKeeper的持久顺序型节点,但是它的命名没有前缀,每条指令直接以递增数字的形式保存,例如0000000000、0000000001等。 -
/replicas/{replica_name}/
*:每个副本各自的节点下的一组监听节点,用于指导副本在本地执行具体的任务指令,其中较为重要的节点有如下几个:
- /queue:任务队列节点,用于执行具体的操作任务。当副本从/log或/mutations节点监听到操作指令时,会将执行任务添加至该节点下,并基于队列执行。
- /log_pointer:log日志指针节点,记录了最后一次执行的log日志下标信息。
- /mutation_pointer:mutations日志指针节点,记录了最后一次执行的mutations日志名称。
-
Entry日志对象的数据结构
ReplicatedMergeTree在ZooKeeper中有两组非常重要的父节点,那就/log和/mutations。它们的作用犹如一座通信塔,是分发操作指令的信息通道,而发送指令的方式,则是为这些父节点添加子节点。
所有的副本实例,都会监听父节点的变化,当有子节点被添加时,它们能实时感知。这些被添加的子节点在ClickHouse中被统一抽象为Entry对象,而具体实现则由LogEntry和MutationEntry对象承载,分别对应/log和/mutations节点
- LogEntry
- source replica:发送这条Log指令的副本来源,对应replica_name。
- type:操作指令类型,主要有
get、merge和mutate三种,分别对应从远程副本下载分区、合并分区和MUTATION操作。 - block_id:当前分区的BlockID,对应/blocks路径下子节点的名称。
- partition_name:当前分区目录的名称。
- MutationEntry
- source replica:发送这条
MUTATION指令的副本来源,对应replica_name。 - commands:操作指令,主要有
ALTER DELETE和ALTER UPDATE。 - mutation_id:MUTATION操作的版本号。
- partition_id:当前分区目录的ID。
- source replica:发送这条
副本协同的核心流程
副本协同的核心流程主要有INSERT、MERGE、MUTATION和ALTER四种,分别对应了数据写入、分区合并、数据修改和元数据修改。INSERT和ALTER是分布式执行的,借助ZooKeeper的事件通知机制,多个副本之间会自动进行有效协同,但是它们不会使用ZooKeeper存储任何分区数据。而其他操作并不支持分布式执行,包括SELECT、CREATE、DROP、RENAME和ATTACH。
在下列例子中,使用ReplicatedMergeTree实现一张拥有1分片、1副本的数据表来分别执行INSERT、MERGE、MUTATION和ALTER操作,演示执行流程。
INSERT协同的核心流程
当需要在ReplicatedMergeTree中执行INSERT查询以写入数据时,即会进入INSERT核心流程,它的核心流程如下图所示

INSERT的核心执行流程
- 向副本A写入数据
- 由副本A推送Log日志
- 各个副本拉取Log日志
- 各个副本向远端副本发起下载请求
- 选择一个远端的其他副本作为数据的下载来源。远端副本的选择算法大致是这样的:
- 从
/replicas节点拿到所有的副本节点。 - 遍历这些副本,选取其中一个。选取的副本需要拥有最大的
log_pointer下标,并且/queue子节点数量最少。log_pointer下标最大,意味着该副本执行的日志最多,数据应该更加完整;而/queue最小,则意味着该副本目前的任务执行负担较小。
- 从
- 选择一个远端的其他副本作为数据的下载来源。远端副本的选择算法大致是这样的:
- 远端副本响应其它副本的数据下载
- 各个副本下载数据并完成本地写入
在INSERT的写入过程中,ZooKeeper不会进行任何实质性的数据传输。本着谁执行谁负责的原则,在这个案例中由CH5首先在本地写入了分区数据。之后,也由这个副本负责发送Log日志,通知其他副本下载数据。如果设置了insert_quorum并且insert_quorum>=2,则还会由该副本监控完成写入的副本数量。其他副本在接收到Log日志之后,会选择一个最合适的远端副本,点对点地下载分区数据。
MERGE协同的核心流程
当ReplicatedMergeTree触发分区合并动作时,即会进入这个部分的流程,它的核心流程如下图所示

MERGE的核心执行流程
无论MERGE操作从哪个副本发起,其合并计划都会交由主副本来制定。
- 创建远程连接,尝试与主副本通信
- 主副本接收通信
- 由主副本制定MERGE计划并推送Log日志
- 各个副本分别拉取Log日志
- 各个副本分别在本地执行MERGE
可以看到,在MERGE的合并过程中,ZooKeeper也不会进行任何实质性的数据传输,所有的合并操作,最终都是由各个副本在本地完成的。而无论合并动作在哪个副本被触发,都会首先被转交至主副本,再由主副本负责合并计划的制定、消息日志的推送以及对日志接收情况的监控。
MUTATION协同的核心流程
当对ReplicatedMergeTree执行ALTER DELETE或者ALTER UPDATE操作的时候(ClickHouse把DELETE和UPDATE操作也加入到了ALTER TABLE的范畴中,它并不支持裸的DELETE或者UPDATE操作),即会进入MUTATION部分的逻辑

MUTATION的核心执行流程
与MERGE类似,无论MUTATION操作从哪个副本发起,首先都会由主副本进行响应。
- 推送MUTATION日志
- 所有副本实例各自监听MUTATION日志
- 由主副本实例响应MUTATION日志并推送Log日志
- 各个副本实例分别拉取Log日志
- 各个副本实例分别在本地执行MUTATION
在MUTATION的整个执行过程中,ZooKeeper同样不会进行任何实质性的数据传输。所有的MUTATION操作,最终都是由各个副本在本地完成的。而MUTATION操作是经过/mutations节点实现分发的。CH6负责了消息的推送。但是无论MUTATION动作从哪个副本被触发,之后都会被转交至主副本,再由主副本负责推送Log日志,以通知各个副本执行最终的MUTATION逻辑。同时也由主副本对日志接收的情况实行监控。
ALTER协同的核心流程
当对ReplicatedMergeTree执行ALTER操作进行元数据修改的时候,即会进入ALTER部分的逻辑,例如增加、删除表字段等,核心流程如下图
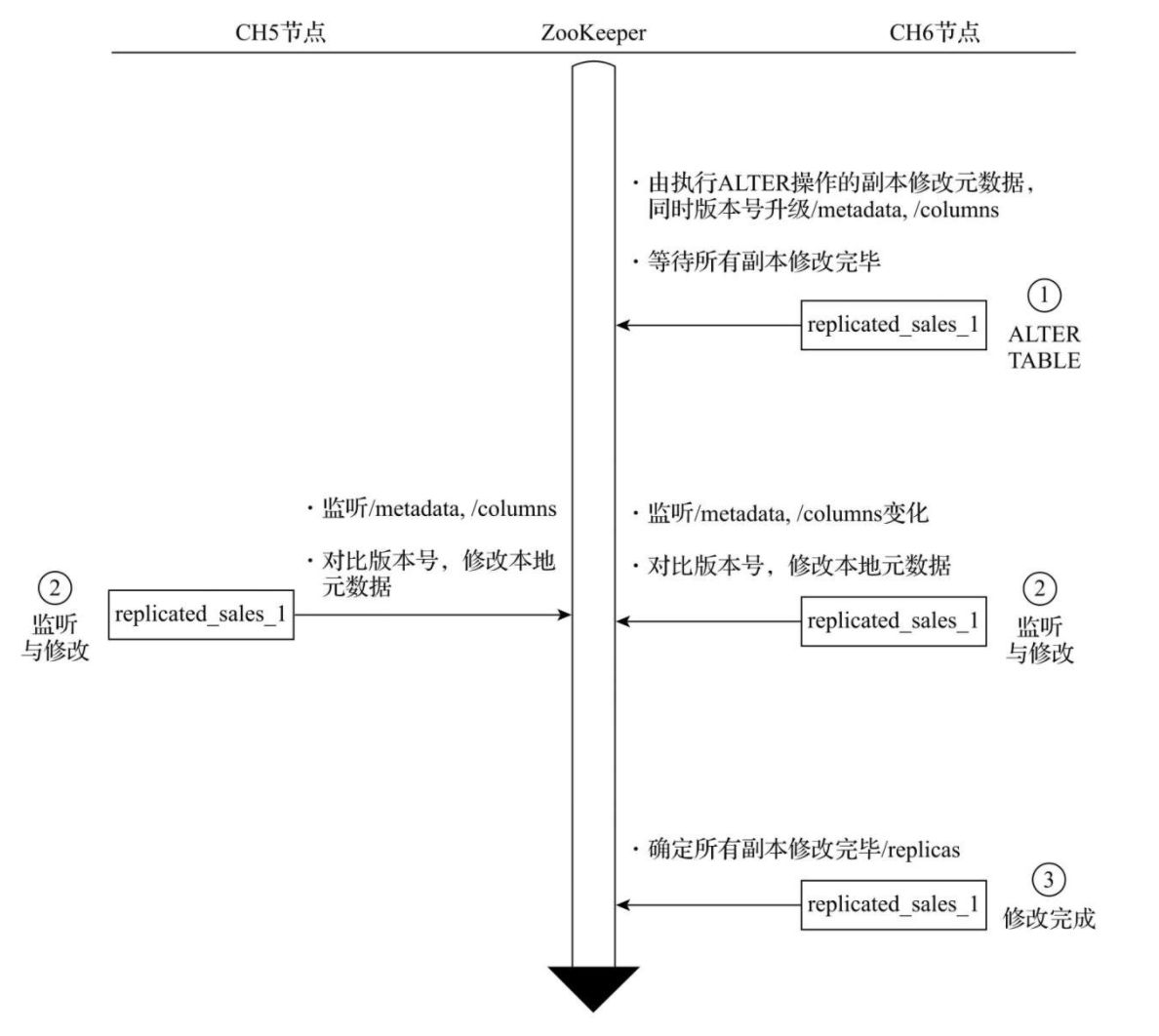
ALTER的核心执行流程
ALTER的流程与前几个相比简单很多,其执行过程中并不会涉及/log日志的分发,整个流程大致分成3个步骤
- 修改共享元数据
- 监听共享元数据变更并各自执行本地修改
- 确认所有副本完成修改
在ALTER整个的执行过程中,ZooKeeper不会进行任何实质性的数据传输。所有的ALTER操作,最终都是由各个副本在本地完成的。本着谁执行谁负责的原则,在这个案例中由CH6负责对共享元数据的修改以及对各个副本修改进度的监控。
clickhouse的优越的性能
-
与一些同类型产品对比

官网截图
-
与其他分析型数据库对比

易观数据
可以看出clickhouse在性能上有非常卓越的表现。但是这并不意味着它可以代替其他的查询数据库。
就像这样,时不时的,在使用numpy库或者各种Tensor张量库进行计算的时候,我们都会感叹这些库计算的速度之快,以至于远远超越自己写的for循环。然后,我们就会逐渐并且越来越多的听说到一个词——vectorization(向量化计算)——其带来了巨大的计算性能。
Clickhouse的不足:
没有完美的设计,只有适合的设计。
clickhouse也有自己的限制。
- 不支持事务
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据(性能不太好)
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询
- 不支持大量的并发请求。每秒上百甚至更少
Clickhouse推荐使用场景
- 数据被添加到数据库,基本不怎么修改。
- 查询并发相对不高。
- 大宽表存储,少部分字段使用。
- 批量操作,更新或者删除。
- 列值相对小,数字或者短字符串。
- 无事务处理。
比如:用于存储数据和统计数据使用/ 用户行为数据记录和分析工作 / 日志分析
参考文献
京东 ClickHouse 高可用实践 https://blog.csdn.net/wypblog/article/details/120426701
https://www.jianshu.com/p/dfbe8eb3b26c
https://zhuanlan.zhihu.com/p/366421463
https://blog.csdn.net/sinat_41207450/article/details/126777357
http://events.jianshu.io/p/5fc49abc3119
https://zhuanlan.zhihu.com/p/72953129
https://blog.csdn.net/sinat_22510827/article/details/125939191
https://blog.csdn.net/fyire/article/details/120826881
https://www.jianshu.com/p/42d9dcd4f8cd
https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
http://www.benstopford.com/2015/02/14/log-structured-merge-trees/
https://www.jianshu.com/p/a30b814ee1fc
https://seaboat.blog.csdn.net/article/details/82976862
https://blog.csdn.net/jyxmust/article/details/89803733
https://article.itxueyuan.com/AWwJJE
https://blog.csdn.net/shangsongwww/article/details/103420171
https://blog.csdn.net/ws1296931325/article/details/86635751/
https://www.cnblogs.com/yjt1993/p/14522536.html
https://oreki.blog.csdn.net/article/details/117258004
https://cloud.tencent.com/developer/article/1986902
https://blog.csdn.net/qq_41308860/article/details/120401911

 浙公网安备 33010602011771号
浙公网安备 33010602011771号