

史上最全:高可用Myql+rocketmq+es+redis+minio+keepalive+haproxy 实操
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Docker Swarm
Docker Swarm 是 Docker 官方三剑客项目之一,提供 Docker 容器集群服务,是 Docker 官方对容器云生态进行支持的核心方案。使用它,用户可以将多个 Docker 主机封装为单个大型的虚拟 Docker 主机,快速打造一套容器云平台。
Docker 1.12 Swarm mode 已经内嵌入 Docker 引擎,成为了 docker 子命令 docker swarm。请注意与旧的 Docker Swarm 区分开来。
Swarm mode内置kv存储功能,提供了众多的新特性,比如:具有容错能力的去中心化设计、内置服务发现、负载均衡、路由网格、动态伸缩、滚动更新、安全传输等。使得 Docker 原生的 Swarm 集群具备与 Mesos、Kubernetes 竞争的实力。
基本概念
Swarm 是使用 SwarmKit 构建的 Docker 引擎内置(原生)的集群管理和编排工具。
节点:
运行 Docker 的主机可以主动初始化一个 Swarm 集群或者加入一个已存在的 Swarm 集群,这样这个运行 Docker 的主机就成为一个 Swarm 集群的节点 (node)
节点分为管理 (manager) 节点和工作 (worker) 节点
- 管理节点:用于 Swarm 集群的管理,
docker swarm命令基本只能在管理节点执行(节点退出集群命令docker swarm leave可以在工作节点执行)。一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为leader,leader 通过 raft 协议实现。 - 工作节点:是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。也可以通过配置让服务只运行在管理节点。
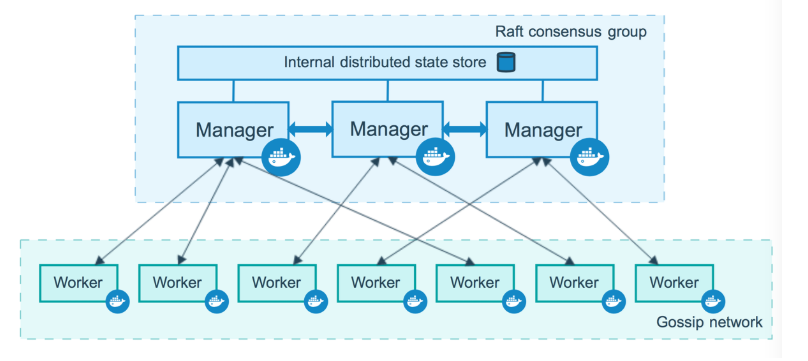
集群中管理节点与工作节点的关系如下所示:
服务和任务:
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。
服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式:
replicated services按照一定规则在各个工作节点上运行指定个数的任务。global services每个工作节点上运行一个任务。
两种模式通过 docker service create 的 --mode 参数指定。
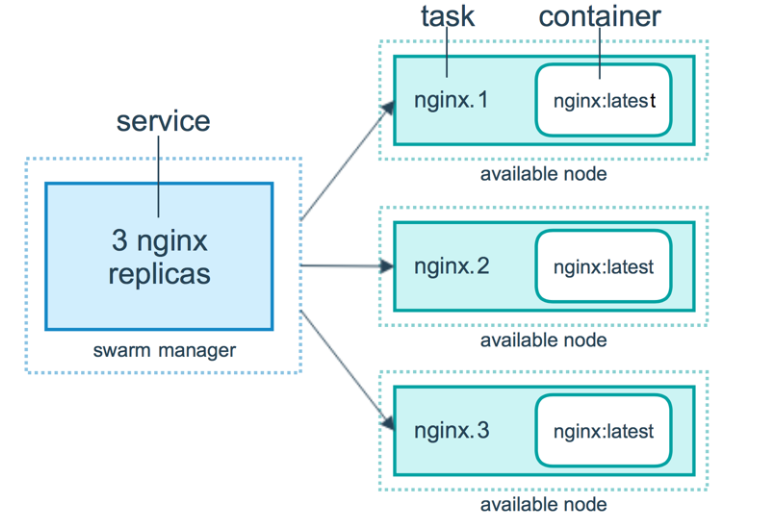
容器、任务、服务的关系如下所示:
swarm:
从 v1.12 开始,集群管理和编排功能已经集成进 Docker Engine。
当 Docker Engine 初始化了一个 swarm 或者加入到一个存在的 swarm 时,它就启动了 swarm mode。没启动 swarm mode 时,Docker 执行的是容器命令;运行 swarm mode 后,Docker 增加了编排 service 的能力。
Docker 允许在同一个 Docker 主机上既运行 swarm service,又运行单独的容器。
node:
swarm 中的每个 Docker Engine 都是一个 node,有两种类型的 node:manager 和 worker。
为了向 swarm 中部署应用,我们需要在 manager node 上执行部署命令,manager node 会将部署任务拆解并分配给一个或多个 worker node 完成部署。
manager node 负责执行编排和集群管理工作,保持并维护 swarm 处于期望的状态。swarm 中如果有多个 manager node,它们会自动协商并选举出一个 leader 执行编排任务。
woker node 接受并执行由 manager node 派发的任务。默认配置下 manager node 同时也是一个 worker node,不过可以将其配置成 manager-only node,让其专职负责编排和集群管理工作。work node 会定期向 manager node 报告自己的状态和它正在执行的任务的状态,这样 manager 就可以维护整个集群的状态。
service:
service 定义了 worker node 上要执行的任务。
swarm 的主要编排任务就是保证 service 处于期望的状态下。
举一个 service 的例子:在 swarm 中启动一个 http 服务,使用的镜像是 httpd:latest,副本数为 3。manager node 负责创建这个 service,经过分析知道需要启动 3 个 httpd 容器,根据当前各 worker node 的状态将运行容器的任务分配下去,比如 worker1 上运行两个容器,worker2 上运行一个容器。运行了一段时间,worker2 突然宕机了,manager 监控到这个故障,于是立即在 worker3 上启动了一个新的 httpd 容器。这样就保证了 service 处于期望的三个副本状态。
默认配置下 manager node 也是 worker node,所以 swarm-manager 上也运行了副本。如果不希望在 manager 上运行 service,可以执行如下命令:
docker node update --availability drain master
应用案例
集群最擅长的就是解决多服务问题,只要在同一 network 之下,服务之间默认可以直接通过 service_name 互通有无。但为了避免混乱,各服务与外部的通信最好统一交给一个代理服务转发。因对 nginx 比较熟悉,所以我最初选择的代理是“jwilder/nginx-proxy”:
部署架构
众所周知,compose 就是 docker提供给我们用来进行编排的利器,那么我们应该如何使用她呢?
在解析docker-compose.yml之前,我想先说明一下我的业务,在熟悉业务之后,我们再来看看具体的"code".
业务需求:我们要在两个host (swarm node)上面分别建立一组服务,为了简单起见,我将nodes命名为nodeDB和nodeService;顾名思义,我们就是要在nodeDB上面建立database的服务(我这里是部署oracle server),在nodeService上面部署我们的程序(containers). 而 containers 之间的通信就是通过Swarm的Overlay网络来完成的。
准备工作
首先是通过 Swarm 创建 nodes,并且创建Overlay网络模式.
Docker的原生overlay网络的实现原理
Docker版本信息
manager node: Docker version 18.09.4, build d14af54266
worker node: Docker version 19.03.1, build 74b1e89
Docker Swarm系统环境
manager node: 192.168.246.194
worker node: 192.168.246.195
创建 docker swarm集群前的网络
manager node:
docker network ls
NETWOrk ID NAME DRIVER SCOPE
e01d59fe00e5 bridge bridge local
15426f623c37 host host local
dd5d570ac60e none null local
worker node:
docker network ls
NETWOrk ID NAME DRIVER SCOPE
70ed15a24acd bridge bridge local
e2da5d928935 host host local
a7dbda3b96e8 none null local
创建 docker swarm 集群
初始化 docker swarm 集群
manager node执行:
docker swarm init
执行结果如下
[root@localhost ~]# docker swarm init
Swarm initialized: current node (45mgl95ewnkovrl62nzcgg39i) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-58420uvva5gq6muv4r8swp2ftojhccwdiss9in0jhsagqdk8cm-9c193wz4ye2sucdxv2enofmwh 172.18.8.101:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
初始化swarm或将Docker主机加入现有swarm时,会在该Docker主机上创建两个新网络:
- 名称为ingress的overlay网络,处理与swarm集群服务相关的控制和数据流量。swarm群组服务并不会将其连接到用户定义的overlay网络时,而是连接到默认的ingress网络,若要连接到用户自定义的overlay网络需要使用--network指定(但创建该用户自定义的overlay网络时必须使用--attachable选项)。
- 名为docker_gwbridge的桥接网络,它将参与到该swarm群集的各个Docker守护程序连接连接起来。
加入 docker swarm 集群
worker node执行:
docker swarm join --token SWMTKN-1-58420uvva5gq6muv4r8swp2ftojhccwdiss9in0jhsagqdk8cm-9c193wz4ye2sucdxv2enofmwh 172.18.8.101:2377
node2 执行结果如下
[root@localhost ~]# docker swarm join --token SWMTKN-1-58420uvva5gq6muv4r8swp2ftojhccwdiss9in0jhsagqdk8cm-9c193wz4ye2sucdxv2enofmwh 172.18.8.101:2377
This node joined a swarm as a worker.
node3 执行结果如下
[root@k8s-master ~]# docker swarm join --token SWMTKN-1-58420uvva5gq6muv4r8swp2ftojhccwdiss9in0jhsagqdk8cm-9c193wz4ye2sucdxv2enofmwh 172.18.8.101:2377
This node joined a swarm as a worker.
查看集群节点信息
manager node 执行:
docker node ls
manager node 执行结果如下
[root@localhost ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
ijhuv473dmmfo518szfryaiz4 k8s-master Ready Active 19.03.6
45mgl95ewnkovrl62nzcgg39i * localhost.localdomain Ready Active Leader 19.03.6
e2v9g0f7fvp448amvtcwbh2ur localhost.localdomain Ready Active 19.03.6
查看集群网络信息
manager node 执行:
docker network ls
manager node 执行结果如下
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
d640a4069a2c bridge bridge local
769df470937b docker_gwbridge bridge local
b95c88a0643f flowable-ui_default bridge local
e86bdbb89c2a host host local
fgw2irojkxus ingress overlay swarm
d2d2adc84539 kafka_default bridge local
5963708cf3f5 mysql5733_default bridge local
70a8f84aba79 nacos132_default bridge local
b5c13b4d6f08 none null local
7a07f786100b pg96_default bridge local
c6fba23185fd pg114_default bridge local
2a7d23e666cb redis608_default bridge local
worker node执行:
docker network ls
执行结果如下
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
f7c823f5555a bridge bridge local
5d99c0e15044 docker_gwbridge bridge local
994c662e2c74 host host local
fgw2irojkxus ingress overlay swarm
7286f698b35f kafka_default bridge local
96a79b1a8e68 nacos_default bridge local
4797f82b5944 none null local
cf17d1eaa60f rmq bridge local
查看节点的网络空间
在docker swarm集群创建的开始,docker 会给每台host创建除了docker0以外的两个网络,分是bridge类型(docker_gwbridge网桥)和overlay类型(ingress)的网络,
docker 会创建一个过渡的命名空间ingress_sbox,如下是 node2 上的网络命名空间:
[root@k8s-master ~]# ip netns ls
[root@k8s-master ~]# cd /run/docker/netns/
[root@k8s-master netns]# ls
02a9055f4fd8 1885e369908f 21ed1da98c33 437047e9edd6 85492903d17c a3aff3ee377d bbe1ade3a6ee default
05eea38af954 1-fgw2irojkx 28e7ea276af9 63f184ecf905 8de9ada0c101 a4a7b1a4fc59 c7f2929f0121 ingress_sbox
0609a84c2a7d 21e63d02ea43 37e6ab5abee1 7c1e39933366 986c4f4289b7 ac8c98ffd1e4 c906d37da694
manager节点自建overlay网络
创建用户自定义的用于swarm服务的overlay网络,使用如下命令:
docker network create -d overlay my-overlay
创建可由swarm群集服务或独立容器用于与在其他Docker守护程序上运行的其他独立容器通信的overlay网络,请添加--attachable标志:
docker network create -d overlay --attachable my-attachable-overlay
可以使用如下命令在 manager节点自建overlay网络,结果如下:
docker network create -d overlay --attachable ha-network-overlay
执行结果如下
[root@localhost ~]# docker network create -d overlay ha_network
kj0qk79lkuhcvz7ovrp71c6jo
再次查看 manager 和 worker 两台主机 docker swarm 集群网络:
manager node:
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
d640a4069a2c bridge bridge local
769df470937b docker_gwbridge bridge local
b95c88a0643f flowable-ui_default bridge local
7x41wgxztm8z ha-network-overlay overlay swarm
kj0qk79lkuhc ha_network overlay swarm
e86bdbb89c2a host host local
fgw2irojkxus ingress overlay swarm
d2d2adc84539 kafka_default bridge local
5963708cf3f5 mysql5733_default bridge local
70a8f84aba79 nacos132_default bridge local
b5c13b4d6f08 none null local
7a07f786100b pg96_default bridge local
c6fba23185fd pg114_default bridge local
2a7d23e666cb redis608_default bridge local
worker node:
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
f7c823f5555a bridge bridge local
5d99c0e15044 docker_gwbridge bridge local
994c662e2c74 host host local
fgw2irojkxus ingress overlay swarm
7286f698b35f kafka_default bridge local
96a79b1a8e68 nacos_default bridge local
4797f82b5944 none null local
cf17d1eaa60f rmq bridge local
我们会发现在 worker node上并没有ha_network 网络。
这是因为只有当运行中的容器连接到覆盖网络的时候,该网络才变为可用状态。这种延迟生效策略通过减少网络梳理,提升了网络的扩展性。
先决条件
创建一个overlay网络Prerequisites:先决条件
你需要开放以下端口,以便和参与overlay网络的每个Docker主机进行通信:
- TCP port 2377 for cluster management communications(用于群集管理通信的TCP端口2377)
- TCP and UDP port 7946 for communication among nodes(用于节点间通信的TCP和UDP端口7946)
- UDP port 4789 for overlay network traffic(overlay网络流量的UDP端口4789)
在创建覆盖网络之前,您需要使用docker swarm init将Docker守护程序初始化为swarm manager, 或者使用docker swarm join将其连接到现有的swarm。
其中任何一个都会创建默认的ingress overlay网络, swarm服务默认使用该网络。即使你从未打算使用swarm服务,你也需要这么做。之后,可以创建其他用户定义的覆盖网络。
在work节点让网络生效
如果网络没有生效,直接运行"docker-compose up"会报错,内容大致为找不到指定的网络。。。
这是因为只有当运行中的容器连接到覆盖网络的时候,该网络才变为可用状态。
所以我们需要先在 worknode 上面运行一个container让其加入网络 “ha_network “
例如
scp /root/ha-nginx.tar root@172.18.8.104:/root
docker load -i /root/ha-nginx.tar
docker run -itd --name=test-ha-nginx --network=ha-network-overlay custom/ha-nginx:1.0 /bin/sh
输入结果如下:
[root@localhost ~]# docker stop abb54723b8b3a09c7103edba84e4341a2bd9a45ac902c1c098b98a22c3c2187d
abb54723b8b3a09c7103edba84e4341a2bd9a45ac902c1c098b98a22c3c2187d
[root@localhost ~]# docker rm abb54723b8b3a09c7103edba84e4341a2bd9a45ac902c1c098b98a22c3c2187d
abb54723b8b3a09c7103edba84e4341a2bd9a45ac902c1c098b98a22c3c2187d
[root@localhost ~]# docker run -itd --name=test-ha-nginx --network=ha-network-overlay custom/ha-nginx:1.0 /bin/sh
fd4d197d4e111a1caf64cbda5e09d82ecbd2858a57ccb0ca80fd36f7e26d7e56
worker node看网络:
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
f7c823f5555a bridge bridge local
5d99c0e15044 docker_gwbridge bridge local
7x41wgxztm8z ha-network-overlay overlay swarm
994c662e2c74 host host local
fgw2irojkxus ingress overlay swarm
7286f698b35f kafka_default bridge local
96a79b1a8e68 nacos_default bridge local
4797f82b5944 none null local
cf17d1eaa60f rmq bridge local
在work节点让 ha-network-overlay 网络生效
查看网络命名空间
由于容器和overlay的网络的网络命名空间文件不再操作系统默认的/var/run/netns下,在/var/run/docker/netns 下,
[root@localhost ~]# ll /var/run/docker/netns
total 0
-r--r--r-- 1 root root 0 Sep 9 19:22 019a382e24bc
-r--r--r-- 1 root root 0 Nov 2 11:47 1-7x41wgxztm
-r--r--r-- 1 root root 0 Nov 2 10:12 1-fgw2irojkx
-r--r--r-- 1 root root 0 Sep 9 19:23 316692258e98
-r--r--r-- 1 root root 0 Sep 9 19:23 326000d15579
-r--r--r-- 1 root root 0 Sep 9 19:23 3e27e6ae976d
-r--r--r-- 1 root root 0 Sep 9 19:22 40a3d5256892
-r--r--r-- 1 root root 0 Sep 9 19:22 60eff8e6cd57
-r--r--r-- 1 root root 0 Sep 9 19:22 80d2ed3639de
-r--r--r-- 1 root root 0 Nov 2 11:47 97748869b254
-r--r--r-- 1 root root 0 Sep 9 19:23 b0464dcf7025
-r--r--r-- 1 root root 0 Apr 27 2021 default
-r--r--r-- 1 root root 0 Nov 2 10:12 ingress_sbox
-r--r--r-- 1 root root 0 Nov 2 11:47 lb_7x41wgxzt
只能手动通过软连接的方式查看。
ln -s /var/run/docker/netns /var/run/netns
master node:
[root@localhost ~]# ln -s /var/run/docker/netns /var/run/netns
[root@localhost ~]# ip netns
1-fgw2irojkx (id: 5)
ingress_sbox (id: 6)
ab71193396d7 (id: 4)
e63422517d09 (id: 3)
7d3903712aea (id: 0)
8902a33e8595 (id: 2)
227fbb39c26d (id: 1)
worker node:
[root@localhost ~]# ln -s /var/run/docker/netns /var/run/netns
[root@localhost ~]# ip netns
97748869b254 (id: 12)
1-7x41wgxztm (id: 10)
lb_7x41wgxzt (id: 11)
1-fgw2irojkx (id: 8)
ingress_sbox (id: 9)
316692258e98 (id: 0)
3e27e6ae976d (id: 4)
b0464dcf7025 (id: 5)
326000d15579 (id: 2)
60eff8e6cd57 (id: 3)
019a382e24bc (id: 7)
80d2ed3639de (id: 6)
40a3d5256892 (id: 1)
default
有时候网络的网络命名空间名称前面会带上1-、2-等序号,有时候不带。但不影响网络的通信和操作。
查看网络信息
docker network inspect ha-network-overlay
master node:
[root@localhost ~]# docker network inspect ha-network-overlay
[
{
"Name": "ha-network-overlay",
"Id": "7x41wgxztm8zs7n4gslsfdd80",
"Created": "2021-11-02T03:42:57.663035559Z",
"Scope": "swarm",
"Driver": "overlay",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "10.0.3.0/24",
"Gateway": "10.0.3.1"
}
]
},
"Internal": false,
"Attachable": true,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": null,
"Options": {
"com.docker.network.driver.overlay.vxlanid_list": "4099"
},
"Labels": null
}
]
worker node:
[root@localhost ~]# docker network inspect ha-network-overlay
[
{
"Name": "ha-network-overlay",
"Id": "7x41wgxztm8zs7n4gslsfdd80",
"Created": "2021-11-02T11:47:33.993144209+08:00",
"Scope": "swarm",
"Driver": "overlay",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "10.0.3.0/24",
"Gateway": "10.0.3.1"
}
]
},
"Internal": false,
"Attachable": true,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"fd4d197d4e111a1caf64cbda5e09d82ecbd2858a57ccb0ca80fd36f7e26d7e56": {
"Name": "test-ha-nginx",
"EndpointID": "a8640e972a159086c2554e69368c0ce1eee4f9327d595c6820003057cb2bc29f",
"MacAddress": "02:42:0a:00:03:02",
"IPv4Address": "10.0.3.2/24",
"IPv6Address": ""
},
"lb-ha-network-overlay": {
"Name": "ha-network-overlay-endpoint",
"EndpointID": "c3cecdd88456052244e522064c5f56c602043d74654c3a243db5b18f7569623d",
"MacAddress": "02:42:0a:00:03:03",
"IPv4Address": "10.0.3.3/24",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.driver.overlay.vxlanid_list": "4099"
},
"Labels": {},
"Peers": [
{
"Name": "f9c3fce6f5b9",
"IP": "172.18.8.103"
}
]
}
]
网络的使用
version: '3.5'
services:
ha-pxc01:
restart: always
image: percona/percona-xtradb-cluster:5.7.28-2
container_name: ha-pxc01
privileged: true
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=123456
- CLUSTER_NAME=ha-pxc
volumes:
- ../data/v1:/var/lib/mysql
networks:
- ha-network-overlay
networks:
ha-network-overlay:
external: true
部署架构
集群最擅长的就是解决多服务问题,只要在同一 network 之下,服务之间默认可以直接通过 service_name 互通有无。但为了避免混乱,各服务与外部的通信最好统一交给一个反向代理服务转发。
部署mysql 的PXC集群
第一个节点
version: '3.5'
services:
ha-pxc01:
restart: always
image: percona/percona-xtradb-cluster:5.7.28-2
container_name: ha-pxc01
privileged: true
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=123456
- CLUSTER_NAME=ha-pxc
volumes:
- ../data/v1:/var/lib/mysql
networks:
- ha-network-overlay
networks:
ha-network-overlay:
external: true
第2/3个节点
version: '3.5'
services:
ha-pxc02:
restart: always
image: percona/percona-xtradb-cluster:5.7.28-2
container_name: ha-pxc02
privileged: true
ports:
- 3307:3306
environment:
- MYSQL_ROOT_PASSWORD=123456
- CLUSTER_NAME=ha-pxc
- CLUSTER_JOIN=ha-pxc01
volumes:
- ../data/v2:/var/lib/mysql
networks:
- ha-network-overlay
networks:
ha-network-overlay:
external: true
导入镜像和创建目录
导入镜像
scp /root/percona-xtradb-cluster.tar root@172.18.8.101:/root
scp /root/percona-xtradb-cluster.tar root@172.18.8.103:/root
docker load -i /root/percona-xtradb-cluster.tar
创建目录
# 创建数据卷
mkdir -p /home/docker-compose/pxc-ha/data/{v1,v2,v3}/
chmod 777 /home/docker-compose/pxc-ha/data/{v1,v2,v3}/
mkdir -p /home/docker-compose/pxc-ha/pxc{01,02,03}
chmod 777 /home/docker-compose/pxc-ha/pxc{01,02,03}
复制文件,启动节点
第1个节点
[root@localhost pxc-ha]# sh start_node1.sh
===========stoping myql .....================
Network ha-network-overlay is external, skipping
Network ha-network-overlay is external, skipping
Network ha-network-overlay is external, skipping
===========starting myql pxc01.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating ha-pxc01 ... done
=========== myql pxc01 starting.....================
第2个节点
[root@localhost pxc-ha]# sh start_node2.sh
===========stoping myql .....================
Network ha-network-overlay is external, skipping
Network ha-network-overlay is external, skipping
Network ha-network-overlay is external, skipping
sed: can't read /home/docker-compose/pxc-ha/data/v1//grastate.dat: No such file or directory
===========starting myql pxc02.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating ha-pxc02 ... done
=========== myql pxc02 starting.....================
第三个节点
[root@k8s-master pxc-ha]# sh start_node3.sh
===========stoping myql .....================
Network ha-network-overlay is external, skipping
Network ha-network-overlay is external, skipping
Network ha-network-overlay is external, skipping
sed: can't read /home/docker-compose/pxc-ha/data/v1//grastate.dat: No such file or directory
===========starting myql pxc03.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating ha-pxc03 ... done
=========== myql pxc03 starting.....================
访问pxc节点和集群
第1个节点
172.18.8.101 3303
show status like 'wsrep_cluster%'
第2个节点
172.18.8.103 3303
show status like 'wsrep_cluster%'
第3个节点
172.18.8.104 3303
show status like 'wsrep_cluster%'
部署hapoxy
导入镜像和复制文件
导入镜像
scp /root/ha-nginx.tar root@172.18.8.101:/root
scp /root/ha-nginx.tar root@172.18.8.103:/root
scp /root/ha-nginx.tar root@172.18.8.104:/root
docker load -i /root/ha-nginx.tar
scp /root/haproxy.tar root@172.18.8.101:/root
scp /root/haproxy.tar root@172.18.8.103:/root
docker load -i /root/haproxy.tar
复制 haproxy-ha的配置文件,和编排文件过去
编排文件
然后启动
启动之后测试
第1个节点的proxy
172.18.8.101 23303
show status like 'wsrep_cluster%'
部署高可用nacos集群
修改数据库的配置
初始化数据库 nacos_dev, 使用 init.sql脚本创建库
在nacos.env 环境变量文件中
TZ=Asia/Shanghai
JVM_XMS=256m
JVM_XMX=512m
JVM_XMN=128m
MODE=cluster
#PREFER_HOST_MODE=hostname
#NACOS_SERVERS=nacos1:8848 nacos2:8848 nacos3:8848
PREFER_HOST_MODE=ip
NACOS_AUTH_ENABLE=true
MYSQL_SERVICE_HOST=172.18.8.101
MYSQL_SERVICE_PORT=23303
MYSQL_SERVICE_DB_NAME=nacos_dev
MYSQL_SERVICE_USER=root
MYSQL_SERVICE_PASSWORD=123456
## pwd
NACOS_USER=nacos
NACOS_PASSWORD=nacos
## env
ORDER_ENV=dev
USER_ENV=dev
创建文件目录结构
批量创建目录的命令
# 创建数据卷
mkdir -p /home/docker-compose/nacos-ha/data_{01,02,03}/
chmod 777 /home/docker-compose/nacos-ha/data_{01,02,03}/
mkdir -p /home/docker-compose/nacos-ha/logs_{01,02,03}/
chmod 777 /home/docker-compose/nacos-ha/logs_{01,02,03}/
导入镜像
scp /root/nacos.tar root@172.18.8.101:/root
scp /root/nacos.tar root@172.18.8.103:/root
scp /root/nacos.tar root@172.18.8.104:/root
docker load -i /root/nacos.tar
复制文件,启动节点
[root@localhost nacos-ha]# sh start_node1.sh
===========stoping nacos .....================
WARNING: Some services (nacos1, nacos2, nacos3) use the 'deploy' key, which will be ignored. Compose does not support 'deploy' configuration - use `docker stack deploy` to deploy to a swarm.
Network ha-network-overlay is external, skipping
===========starting nacos node01================
WARNING: Some services (nacos1, nacos2, nacos3) use the 'deploy' key, which will be ignored. Compose does not support 'deploy' configuration - use `docker stack deploy` to deploy to a swarm.
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating nacos1 ... done
=========== starting nacos node01 .....================
清理一下内存
如果内存不够,清理一下内存
[root@localhost nacos-ha]# free -h
total used free shared buff/cache available
Mem: 15G 8.1G 925M 177M 6.5G 6.9G
Swap: 7.9G 22M 7.9G
[root@localhost nacos-ha]# echo 1 > /proc/sys/vm/drop_caches
[root@localhost nacos-ha]# free -h
total used free shared buff/cache available
Mem: 15G 8.0G 6.4G 177M 1.1G 7.0G
Swap: 7.9G 22M 7.9G
访问单个的nacos
http://172.18.8.101:8001/nacos/#/login
http://172.18.8.103:8002/nacos/#/login
http://172.18.8.104:8003/nacos/
用户名:nacos ,密码 nacos
增加代理的配置
global
log 127.0.0.1 local0 info # 设置日志文件输出定向
daemon
maxconn 20000
defaults
log global
option tcplog
option dontlognull
retries 5
option redispatch
mode tcp
timeout queue 1m
timeout connect 10s
timeout client 1m #客户端空闲超时时间
timeout server 1m #服务端空闲超时时间
timeout check 5s
maxconn 10000
#listen http_front #haproxy的客户页面
# bind 0.0.0.0:1080
# stats uri /haproxy?stats
listen stats
mode http
log global
bind 0.0.0.0:1080
stats enable
stats refresh 30s
stats uri /haproxy-stats
# stats hide-version
listen nacos-cluster
bind 0.0.0.0:8848
mode tcp
balance roundrobin
server nacos_01 172.18.8.164:8001 check
server nacos_02 172.18.8.164:8002 check
server nacos_03 172.18.8.164:8003 check
# server nacos_01 nacos1:8848 check
# server nacos_02 nacos2:8848 check
# server nacos_03 nacos3:8848 check
在103上部署代理,然后启动
访问高可用代理的nacos
高可用代理
http://172.18.8.103:28848/nacos/#/configurationManagement?dataId=&group=&appName=&namespace=
用户名:nacos ,密码 nacos
部署高可用redis集群
修改编排文件
version: '3.5'
services:
redis-ha-1:
image: publicisworldwide/redis-cluster
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster-ha/conf/6001/data:/data
environment:
- REDIS_PORT=6001
redis-ha-2:
image: publicisworldwide/redis-cluster
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster-ha/conf/6002/data:/data
environment:
- REDIS_PORT=6002
redis-ha-3:
image: publicisworldwide/redis-cluster
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster-ha/conf/6003/data:/data
environment:
- REDIS_PORT=6003
redis-ha-4:
image: publicisworldwide/redis-cluster
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster-ha/conf/6004/data:/data
environment:
- REDIS_PORT=6004
redis-ha-5:
image: publicisworldwide/redis-cluster
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster-ha/conf/6005/data:/data
environment:
- REDIS_PORT=6005
redis-ha-6:
image: publicisworldwide/redis-cluster
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster-ha/conf/6006/data:/data
environment:
- REDIS_PORT=6006
创建文件目录结构
批量创建目录的命令
mkdir -p /home/docker-compose/redis-cluster-ha/conf/{7001,7002,7003,7004,7005,7006}/data
导入镜像
scp /root/redis-cluster.tar root@172.18.8.101:/root
scp /root/redis-cluster.tar root@172.18.8.103:/root
scp /root/redis-cluster.tar root@172.18.8.104:/root
docker load -i /root/redis-cluster.tar
scp /root/redis-trib.tar root@172.18.8.101:/root
scp /root/redis-trib.tar root@172.18.8.103:/root
scp /root/redis-trib.tar root@172.18.8.104:/root
docker load -i /root/redis-trib.tar
复制文件,启动节点
启动虚拟机节点1
[root@localhost redis-cluster-ha]# sh start_node1.sh
===========stoping redis-cluster-ha .....================
===========starting redis 01 02.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current no
To deploy your application across the swarm, use `docker stack deploy`.
Creating redis-cluster-ha_redis-ha-1_1 ... done
Creating redis-cluster-ha_redis-ha-2_1 ... done
=========== starting redis 01 02.....================
查看进程
[root@localhost redis-cluster-ha]# ps -ef | grep redis
polkitd 1142 1109 0 10:01 ? 00:00:00 redis-server *:6001 [cluster]
polkitd 1145 1110 0 10:01 ? 00:00:00 redis-server *:6002 [cluster]
root 1335 130010 0 10:02 pts/0 00:00:00 grep --color=auto redis
polkitd 2614 2547 0 Jun23 ? 10:43:10 redis-server *:6379
[
启动虚拟机节点2
[root@localhost redis-cluster-ha]# sh start_node2.sh
===========stoping redis-cluster-ha .....================
===========starting redis 03 04.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating redis-cluster-ha_redis-ha-3_1 ... done
Creating redis-cluster-ha_redis-ha-4_1 ... done
=========== starting redis 03 04.....================
[root@localhost redis-cluster-ha]# ps -ef | grep redis
polkitd 22080 22062 0 Sep09 ? 06:22:27 redis-server *:6001 [cluster]
polkitd 22165 22148 0 Sep09 ? 06:48:27 redis-server *:6006 [cluster]
polkitd 22254 22238 0 Sep09 ? 06:38:52 redis-server *:6005 [cluster]
polkitd 22346 22329 0 Sep09 ? 06:19:08 redis-server *:6003 [cluster]
polkitd 22440 22423 0 Sep09 ? 06:20:51 redis-server *:6002 [cluster]
polkitd 22532 22515 0 Sep09 ? 06:47:53 redis-server *:6004 [cluster]
polkitd 130049 130017 1 10:20 ? 00:00:00 redis-server *:7003 [cluster]
polkitd 130053 130021 1 10:20 ? 00:00:00 redis-server *:7004 [cluster]
root 130124 124951 0 10:20 pts/0 00:00:00 grep --color=auto redis
查看进程如上
启动虚拟机节点3
[root@k8s-master ~]# cd /home/docker-compose/redis-cluster-ha/
[root@k8s-master redis-cluster-ha]# cd ..
[root@k8s-master docker-compose]# rm -rf redis-cluster-ha/
[root@k8s-master docker-compose]# mkdir -p /home/docker-compose/redis-cluster-ha/conf/{7001,7002,7003,7004,7005,7006}/data
[root@k8s-master docker-compose]#
[root@k8s-master docker-compose]# cd /home/docker-compose/redis-cluster-ha/
[root@k8s-master redis-cluster-ha]# sh start_node3.sh
===========stoping redis-cluster-ha .....================
===========starting redis 05 06.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating redis-cluster-ha_redis-ha-5_1 ... done
Creating redis-cluster-ha_redis-ha-6_1 ... done
查看进程
[root@k8s-master redis-cluster-ha]# ps -ef | grep redis
root 19366 19339 0 Sep13 ? 00:00:00 sudo -u redis redis-server /etc/redis.conf
polkitd 19696 19366 0 Sep13 ? 04:53:51 redis-server *:6379
polkitd 69926 69862 0 10:20 ? 00:00:00 redis-server *:7006 [cluster]
polkitd 69945 69878 0 10:20 ? 00:00:00 redis-server *:7005 [cluster]
root 74218 120247 0 10:21 pts/0 00:00:00 grep --color=auto redis
清理一下内存
如果内存不够,清理一下内存
[root@localhost nacos-ha]# free -h
total used free shared buff/cache available
Mem: 15G 8.1G 925M 177M 6.5G 6.9G
Swap: 7.9G 22M 7.9G
[root@localhost nacos-ha]# echo 1 > /proc/sys/vm/drop_caches
[root@localhost nacos-ha]# free -h
total used free shared buff/cache available
Mem: 15G 8.0G 6.4G 177M 1.1G 7.0G
Swap: 7.9G 22M 7.9G
使用redis-trib.rb创建redis 集群
上面只是启动了6个redis容器,并没有设置集群,通过下面的命令可以设置集群。
使用 redis-trib.rb create 命令完成节点握手和槽分配过程
docker run --rm -it inem0o/redis-trib create --replicas 1 hostip:6001 hostip:6002 hostip:6003 hostip:6004 hostip:6005 hostip:6006
#hostip 换成 主机的ip
docker run --rm -it inem0o/redis-trib create --replicas 1 172.18.8.101:7001 172.18.8.101:7002 172.18.8.103:7003 172.18.8.103:7004 172.18.8.104:7005 172.18.8.104:7006
–replicas 参数指定集群中每个主节点配备几个从节点,这里设置为1,
redis-trib.rb 会尽可能保证主从节点不分配在同一机器下,因此会重新排序节点列表顺序。
节点列表顺序用于确定主从角色,先主节点之后是从节点。
创建过程中首先会给出主从节点角色分配的计划,并且会生成报告
日志如下:
[root@localhost redis-cluster-ha]# docker run --rm -it inem0o/redis-trib create --replicas 1 172.18.8.101:7001 172.18.8.101:7002 172.18.8.103:7003 172.18.8.103:7004 172.18.8.104:7005 172.18.8.104:7006
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
172.18.8.101:7001
172.18.8.103:7003
172.18.8.104:7005
Adding replica 172.18.8.103:7004 to 172.18.8.101:7001
Adding replica 172.18.8.101:7002 to 172.18.8.103:7003
Adding replica 172.18.8.104:7006 to 172.18.8.104:7005
M: 50be2ff38c47cd8e0d32ecfc701e77401a75f3d0 172.18.8.101:7001
slots:0-5460 (5461 slots) master
S: 8c07f7dc329e2a527a3e2d660178386f398fc19f 172.18.8.101:7002
replicates cb5a8030b8dbc39056a3c7cf1e36b1fed06ee769
M: cb5a8030b8dbc39056a3c7cf1e36b1fed06ee769 172.18.8.103:7003
slots:5461-10922 (5462 slots) master
S: d1b0e02f58bef1546489a59a646bc32841605f1d 172.18.8.103:7004
replicates 50be2ff38c47cd8e0d32ecfc701e77401a75f3d0
M: 7df8a1c9695c8099f4e3155b8cb0e9133e3cb815 172.18.8.104:7005
slots:10923-16383 (5461 slots) master
S: b7877dfeda5a8bfeb0b4648a76284cff71a522e0 172.18.8.104:7006
replicates 7df8a1c9695c8099f4e3155b8cb0e9133e3cb815
Can I set the above configuration? (type 'yes' to accept):
注意:出现Can I set the above configuration? (type ‘yes’ to accept): 是要输入yes 不是Y
[root@localhost redis-cluster-ha]# docker run --rm -it inem0o/redis-trib create --replicas 1 172.18.8.101:7001 172.18.8.101:7002 172.18.8.103:7003 172.18.8.103:7004 172.18.8.104:7005 172.18.8.104:7006
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
172.18.8.101:7001
172.18.8.103:7003
172.18.8.104:7005
Adding replica 172.18.8.103:7004 to 172.18.8.101:7001
Adding replica 172.18.8.101:7002 to 172.18.8.103:7003
Adding replica 172.18.8.104:7006 to 172.18.8.104:7005
M: 50be2ff38c47cd8e0d32ecfc701e77401a75f3d0 172.18.8.101:7001
slots:0-5460 (5461 slots) master
S: 8c07f7dc329e2a527a3e2d660178386f398fc19f 172.18.8.101:7002
replicates cb5a8030b8dbc39056a3c7cf1e36b1fed06ee769
M: cb5a8030b8dbc39056a3c7cf1e36b1fed06ee769 172.18.8.103:7003
slots:5461-10922 (5462 slots) master
S: d1b0e02f58bef1546489a59a646bc32841605f1d 172.18.8.103:7004
replicates 50be2ff38c47cd8e0d32ecfc701e77401a75f3d0
M: 7df8a1c9695c8099f4e3155b8cb0e9133e3cb815 172.18.8.104:7005
slots:10923-16383 (5461 slots) master
S: b7877dfeda5a8bfeb0b4648a76284cff71a522e0 172.18.8.104:7006
replicates 7df8a1c9695c8099f4e3155b8cb0e9133e3cb815
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join....
>>> Performing Cluster Check (using node 172.18.8.101:7001)
M: 50be2ff38c47cd8e0d32ecfc701e77401a75f3d0 172.18.8.101:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: b7877dfeda5a8bfeb0b4648a76284cff71a522e0 172.18.8.104:7006@17006
slots: (0 slots) slave
replicates 7df8a1c9695c8099f4e3155b8cb0e9133e3cb815
M: cb5a8030b8dbc39056a3c7cf1e36b1fed06ee769 172.18.8.103:7003@17003
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: d1b0e02f58bef1546489a59a646bc32841605f1d 172.18.8.103:7004@17004
slots: (0 slots) slave
replicates 50be2ff38c47cd8e0d32ecfc701e77401a75f3d0
S: 8c07f7dc329e2a527a3e2d660178386f398fc19f 172.18.8.101:7002@17002
slots: (0 slots) slave
replicates cb5a8030b8dbc39056a3c7cf1e36b1fed06ee769
M: 7df8a1c9695c8099f4e3155b8cb0e9133e3cb815 172.18.8.104:7005@17005
slots:10923-16383 (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
访问单个的redis
http://172.18.8.101:7001/
http://172.18.8.103:7002
http://172.18.8.104:7005
来一波客户端连接操作,随便哪个节点,看看可否通过外部访问 Redis Cluster 集群。


至此使用多机环境基于 Docker Compose 搭建 Redis Cluster 就到这里。
Docker Compose 简化了集群的搭建,之前的方式就需要一个个去操作,而 Docker Compose 只需要一个 docker-compose up/down 命令的操作即可。
部署高可用rocketmq集群
部署架构
创建rocketmq文件目录结构
批量创建目录的命令
rm -rf /home/docker-compose/rocketmq-ha
mkdir -p /home/docker-compose/rocketmq-ha/data/{broker-ha-a,broker-ha-b,namesrv-ha-a,namesrv-ha-b}/{logs,store}
chmod 777 /home/docker-compose/rocketmq-ha/data/{broker-ha-a,broker-ha-b,namesrv-ha-a,namesrv-ha-b}/{logs,store}
导入rocketmq镜像
scp /root/rocketmq.tar root@172.18.8.101:/root
scp /root/rocketmq.tar root@172.18.8.103:/root
scp /root/rocketmq.tar root@172.18.8.104:/root
scp /root/rocketmq-console-ng.tar root@172.18.8.101:/root
scp /root/rocketmq-console-ng.tar root@172.18.8.103:/root
scp /root/rocketmq-console-ng.tar root@172.18.8.104:/root
docker load -i /root/rocketmq.tar
docker load -i /root/rocketmq-console-ng.tar
编排文件
version: '3.5'
services:
rmqnamesrv-ha-a:
image: apacherocketmq/rocketmq:4.6.0
container_name: rmqnamesrv-ha-a
ports:
- 19876:9876
restart: always
environment:
TZ: Asia/Shanghai
JAVA_OPTS: "-Duser.home=/opt"
JAVA_OPT_EXT: "-server -Xms256m -Xmx1024m"
volumes:
- /home/docker-compose/rocketmq-ha/data/namesrv-ha-a/logs:/opt/logs
- /home/docker-compose/rocketmq-ha/data/namesrv-ha-a/store:/opt/store
command: sh mqnamesrv
networks:
- ha-network-overlay
rmqnamesrv-ha-b:
image: apacherocketmq/rocketmq:4.6.0
container_name: rmqnamesrv-ha-b
restart: always
ports:
- 19877:9876
volumes:
- /home/docker-compose/rocketmq-ha/data/namesrv-ha-b/logs:/opt/logs
- /home/docker-compose/rocketmq-ha/data/namesrv-ha-b/store:/opt/store
command: sh mqnamesrv
environment:
TZ: Asia/Shanghai
JAVA_OPTS: "-Duser.home=/opt"
JAVA_OPT_EXT: "-server -Xms256m -Xmx1024m"
networks:
- ha-network-overlay
rmqbroker-ha-a:
image: apacherocketmq/rocketmq:4.6.0
container_name: rmqbroker-ha-a
restart: always
ports:
- 20911:20911
- 20912:20912
volumes:
- /home/docker-compose/rocketmq-ha/data/broker-ha-a/logs:/opt/logs
- /home/docker-compose/rocketmq-ha/data/broker-ha-a/store:/opt/store
- /home/docker-compose/rocketmq-ha/conf/broker-ha-a.conf:/opt/rocketmq-4.6.0/conf/broker.conf
environment:
TZ: Asia/Shanghai
NAMESRV_ADDR: "rmqnamesrv-ha-a:9876"
JAVA_OPTS: "-Duser.home=/opt"
JAVA_OPT_EXT: "-server -Xms256m -Xmx1024m"
command: sh mqbroker -c /opt/rocketmq-4.6.0/conf/broker.conf autoCreateTopicEnable=true &
depends_on:
- rmqnamesrv-ha-a
networks:
- ha-network-overlay
rmqbroker-ha-b:
image: apacherocketmq/rocketmq:4.6.0
container_name: rmqbroker-ha-b
restart: always
ports:
- 20921:20921
- 20922:20922
volumes:
- /home/docker-compose/rocketmq-ha/data/broker-ha-b/logs:/opt/logs
- /home/docker-compose/rocketmq-ha/data/broker-ha-b/store:/opt/store
- /home/docker-compose/rocketmq-ha/conf/broker-ha-b.conf:/opt/rocketmq-4.6.0/conf/broker.conf
environment:
TZ: Asia/Shanghai
NAMESRV_ADDR: "rmqnamesrv-ha-b:9876"
JAVA_OPTS: "-Duser.home=/opt"
JAVA_OPT_EXT: "-server -Xms256m -Xmx512m -Xmn128m"
command: sh mqbroker -c /opt/rocketmq-4.6.0/conf/broker.conf autoCreateTopicEnable=true &
depends_on:
- rmqnamesrv-ha-b
networks:
- ha-network-overlay
rmqconsole-ha:
image: styletang/rocketmq-console-ng
container_name: rmqconsole-ha
restart: always
ports:
- 29001:9001
environment:
TZ: Asia/Shanghai
JAVA_OPTS: "-Duser.home=/opt"
JAVA_OPT_EXT: "-server -Xms256m -Xmx1024m"
environment:
JAVA_OPTS: "-Drocketmq.namesrv.addr=172.18.8.103:19876;172.18.8.104:19877 -Dcom.rocketmq.sendMessageWithVIPChannel=false -Dserver.port=9001"
networks:
- ha-network-overlay
networks:
ha-network-overlay:
external: true
配置文件
第1个节点
brokerClusterName = rocketmq-cluster
brokerName = broker-ha-a
brokerId = 0
#当前 broker 监听的 IP,broker所在宿主机的IP
brokerIP1 = 172.18.8.103
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH
#namesrvAddr的地址
namesrvAddr = 172.18.8.103:19876;172.18.8.104:19877
autoCreateTopicEnable = true
#接受客户端连接的监听端⼝,要跟后面docker-compose.yml中的ports配置匹配
listenPort = 20911
第2个节点
brokerClusterName = rocketmq-cluster
brokerName = broker-ha-b
brokerId = 0
#当前 broker 监听的 IP,broker所在宿主机的IP
brokerIP1 = 172.18.8.104
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH
#namesrvAddr的地址
namesrvAddr = 172.18.8.103:19876;172.18.8.104:19877
autoCreateTopicEnable = true
#接受客户端连接的监听端⼝,要跟后面docker-compose.yml中的ports配置匹配
listenPort = 20921
启动节点
脚本说明:
停止所有的服务
sh stop_node.sh
启动第1个节点
sh ./start_node1.sh
启动第二个节点
sh start_node2.sh
查看日志
docker-compose logs -f
启动第1个节点
[root@localhost rocketmq-ha]# sh ./start_node1.sh
===========stoping rocketmq-ha .....================
Network ha-network-overlay is external, skipping
===========starting nameserver 01 brocker01 rmqconsole.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating rmqnamesrv-ha-a ... done
Creating rmqconsole-ha ... done
Creating rmqbroker-ha-a ... done
=========== starting rocketmq in node 01================
启动第二个节点
[root@k8s-master rocketmq-ha]# sh start_node2.sh
===========stoping rocketmq-ha .....================
Network ha-network-overlay is external, skipping
===========starting nameserver 02 brocker02 rmqconsole.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating rmqconsole-ha ... done
Creating rmqnamesrv-ha-b ... done
Creating rmqbroker-ha-b ... done
=========== starting rocketmq in node 02================
访问rockermq
访问rockermq 的控制台
http://172.18.8.103:29001/
http://172.18.8.104:29001/
部署高可用minio集群
修改minio编排文件
version: '3.5'
# starts 4 docker containers running minio server instances.
# using haproxy reverse proxy, load balancing, you can access
# it through port 9000.
services:
minio1:
image: minio/minio:RELEASE.2020-05-16T01-33-21Z
hostname: minio1
volumes:
- ./data1-1:/data1
- ./data1-2:/data2
expose:
- "9000"
- "9991"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_ACCESS_KEY: AKIAIOSFODNN7EXAMPLE
MINIO_SECRET_KEY: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
command: server --address ":9991" http://minio{1...6}:9991/data{1...2}
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9991/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
networks:
- ha-network-overlay
minio2:
image: minio/minio:RELEASE.2020-05-16T01-33-21Z
hostname: minio2
volumes:
- ./data2-1:/data1
- ./data2-2:/data2
expose:
- "9000"
- "9991"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_ACCESS_KEY: AKIAIOSFODNN7EXAMPLE
MINIO_SECRET_KEY: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
command: server --address ":9991" http://minio{1...6}/data{1...2}
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9991/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
networks:
- ha-network-overlay
minio3:
image: minio/minio:RELEASE.2020-05-16T01-33-21Z
hostname: minio3
volumes:
- ./data3-1:/data1
- ./data3-2:/data2
expose:
- "9991"
- "9000"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_ACCESS_KEY: AKIAIOSFODNN7EXAMPLE
MINIO_SECRET_KEY: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
command: server --address ":9991" http://minio{1...6}:9991/data{1...2}
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9991/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
networks:
- ha-network-overlay
minio4:
image: minio/minio:RELEASE.2020-05-16T01-33-21Z
hostname: minio4
volumes:
- ./data4-1:/data1
- ./data4-2:/data2
expose:
- "9000"
- "9991"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_ACCESS_KEY: AKIAIOSFODNN7EXAMPLE
MINIO_SECRET_KEY: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
command: server --address ":9991" http://minio{1...6}:9991/data{1...2}
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9991/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
networks:
- ha-network-overlay
minio5:
image: minio/minio:RELEASE.2020-05-16T01-33-21Z
hostname: minio5
volumes:
- ./data5-1:/data1
- ./data5-2:/data2
expose:
- "9991"
- "9000"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_ACCESS_KEY: AKIAIOSFODNN7EXAMPLE
MINIO_SECRET_KEY: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
command: server --address ":9991" http://minio{1...6}:9991/data{1...2}
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9991/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
networks:
- ha-network-overlay
minio6:
image: minio/minio:RELEASE.2020-05-16T01-33-21Z
hostname: minio6
volumes:
- ./data6-1:/data1
- ./data6-2:/data2
expose:
- "9000"
- "9991"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_ACCESS_KEY: AKIAIOSFODNN7EXAMPLE
MINIO_SECRET_KEY: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
command: server --address ":9991" http://minio{1...6}:9991/data{1...2}
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9991/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
networks:
- ha-network-overlay
networks:
ha-network-overlay:
external: true
创建minio文件目录结构
批量创建目录的命令
mkdir -p /home/docker-compose/minio-ha/data{1,2,3,4,5,6}-{1,2}
导入镜像
scp /root/minio.tar root@172.18.8.101:/root
scp /root/minio.tar root@172.18.8.103:/root
scp /root/minio.tar root@172.18.8.104:/root
docker load -i /root/minio.tar
启动节点
cd /home/docker-compose/minio-ha/
sh ./start_node1.sh
sh ./start_node2.sh
sh ./start_node3.sh
docker-compose logs -f
启动第一个节点
[root@localhost minio-ha]# sh ./start_node1.sh
===========stoping minio-ha .....================
Network ha-network-overlay is external, skipping
===========starting minio 01 02.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating minio-ha_minio1_1 ... done
Creating minio-ha_minio2_1 ... done
=========== starting minio1 minio2.....================
启动第2个节点
[root@localhost rocketmq-ha]# cd /home/docker-compose/minio-ha/
[root@localhost minio-ha]# sh ./start_node2.sh
===========stoping minio-ha .....================
Network ha-network-overlay is external, skipping
===========starting minio 03 04.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating minio-ha_minio4_1 ... done
Creating minio-ha_minio3_1 ... done
=========== starting minio 03 minio 04.....================
启动第3个节点
[root@localhost minio-ha]# sh ./start_node1.sh
===========stoping minio-ha .....================
Network ha-network-overlay is external, skipping
===========starting minio 05 06.....================
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating minio-ha_minio5_1 ... done
Creating minio-ha_minio6_1 ... done
=========== starting minio1 minio2.....================
部署高可用ES集群
创建ES文件目录结构
批量创建目录的命令
mkdir -p /home/docker-compose/elasticsearch7-ha/{coordinate1,coordinate2,coordinate3}-{logs,data}
mkdir -p /home/docker-compose/elasticsearch7-ha/{master1,master2,master3}-{logs,data}
chmod -R 777 /home/docker-compose/elasticsearch7-ha
导入镜像
scp /root/elasticsearch-with-ik-icu.tar root@172.18.8.101:/root
scp /root/elasticsearch-with-ik-icu.tar root@172.18.8.103:/root
scp /root/elasticsearch-with-ik-icu.tar root@172.18.8.104:/root
scp /root/kibana.tar root@172.18.8.101:/root
scp /root/kibana.tar root@172.18.8.103:/root
scp /root/kibana.tar root@172.18.8.104:/root
docker load -i /root/kibana.tar
docker load -i /root/elasticsearch-with-ik-icu.tar
docker load -i /root/rocketmq.tar
docker load -i /root/rocketmq-console-ng.tar
docker load -i /root/minio.tar
docker load -i /root/elasticsearch-with-ik-icu.tar
docker load -i /root/kibana.tar
修改编排文件
version: '3.5'
services:
master-ha1:
image: andylsr/elasticsearch-with-ik-icu:7.14.0
container_name: master-ha1
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
nproc: 65535
memlock:
soft: -1
hard: -1
cap_add:
- ALL
privileged: true
deploy:
mode: global
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
volumes:
- ./master1-data:/usr/share/elasticsearch/data:rw
- ./config/master1.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./master1-logs:/user/share/elasticsearch/logs:rw
ports:
- 29201:9200
- 29301:9300
networks:
- ha-network-overlay
master-ha2:
image: andylsr/elasticsearch-with-ik-icu:7.14.0
container_name: master-ha2
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
nproc: 65535
memlock:
soft: -1
hard: -1
cap_add:
- ALL
privileged: true
deploy:
mode: global
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
volumes:
- ./master2-data:/usr/share/elasticsearch/data:rw
- ./config/master2.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./master2-logs:/user/share/elasticsearch/logs:rw
ports:
- 29202:9200
- 29302:9300
networks:
- ha-network-overlay
master-ha3:
image: andylsr/elasticsearch-with-ik-icu:7.14.0
container_name: master-ha3
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
nproc: 65535
memlock:
soft: -1
hard: -1
cap_add:
- ALL
privileged: true
deploy:
mode: global
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
volumes:
- ./master3-data:/usr/share/elasticsearch/data:rw
- ./config/master3.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./master3-logs:/user/share/elasticsearch/logs:rw
ports:
- 29203:9200
- 29303:9300
networks:
- ha-network-overlay
coordinate1:
image: andylsr/elasticsearch-with-ik-icu:7.14.0
container_name: coordinate1
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
nproc: 65535
memlock:
soft: -1
hard: -1
cap_add:
- ALL
privileged: true
deploy:
mode: global
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
volumes:
- ./coordinate1-data:/usr/share/elasticsearch/data:rw
- ./config/coordinate1.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./coordinate1-logs:/user/share/elasticsearch/logs:rw
ports:
- 29204:9200
- 29304:9300
networks:
- ha-network-overlay
coordinate2:
image: andylsr/elasticsearch-with-ik-icu:7.14.0
container_name: coordinate2
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
nproc: 65535
memlock: -1
cap_add:
- ALL
privileged: true
deploy:
mode: global
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
volumes:
- ./coordinate2-data:/usr/share/elasticsearch/data:rw
- ./config/coordinate2.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./coordinate2-logs:/user/share/elasticsearch/logs:rw
ports:
- 29205:9200
- 29305:9300
networks:
- ha-network-overlay
coordinate3:
image: andylsr/elasticsearch-with-ik-icu:7.14.0
container_name: coordinate3
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
nproc: 65535
memlock: -1
cap_add:
- ALL
privileged: true
deploy:
mode: global
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
volumes:
- ./coordinate3-data:/usr/share/elasticsearch/data:rw
- ./config/coordinate3.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./coordinate3-logs:/user/share/elasticsearch/logs:rw
ports:
- 29206:9200
- 29306:9300
networks:
- ha-network-overlay
kibana:
image: docker.elastic.co/kibana/kibana:7.14.0
container_name: kibana
volumes:
- ./config/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- 15601:5601
ulimits:
nproc: 65535
memlock: -1
cap_add:
- ALL
deploy:
mode: global
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
networks:
- ha-network-overlay
networks:
ha-network-overlay:
external: true
修改系统配置
查看一下内存映射的上限配置
cat /etc/sysctl.conf
如果没有,则在/etc/sysctl.conf文件最后添加一行:
vi /etc/sysctl.conf
vm.max_map_count=262144
立即生效, 执行:
/sbin/sysctl -p
启动节点
cd /home/docker-compose/elasticsearch7-ha/
sh ./start_node1.sh
sh ./start_node2.sh
sh ./start_node3.sh
sh ./stop_node.sh
docker-compose logs -f
启动第一个节点
[root@localhost elasticsearch7-ha]# sh ./start_node1.sh
===========stoping elasticsearch7-ha .....================
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating coordinate1 ... done
Creating kibana ... done
Creating master-ha1 ... done
=========== starting master-ha1 coordinate1 kibana .....================
启动第2个节点
[root@k8s-master minio-ha]# cd /home/docker-compose/elasticsearch7-ha/
[root@k8s-master elasticsearch7-ha]# sh ./start_node2.sh
To deploy your application across the swarm, use `docker stack deploy`.
Creating coordinate3 ... done
Creating master-ha3 ... done
=========== starting master-ha2 coordinate2 .....================
[root@k8s-master elasticsearch7-ha]# docker-compose logs -f
WARNING: Some services (coordinate1, coordinate2, coordinate3, kibana, master-ha1, master-ha2, master-ha3) use the 'deploy' key, which will be ignored. Compose does not support 'deploy' configuration - use `docker stack deploy` to deploy to a swarm.
Attaching to master-ha2, coordinate2
启动第3个节点
[root@k8s-master minio-ha]# cd /home/docker-compose/elasticsearch7-ha/
[root@k8s-master elasticsearch7-ha]# sh ./start_node3.sh
To deploy your application across the swarm, use `docker stack deploy`.
Creating coordinate3 ... done
Creating master-ha3 ... done
=========== starting master-ha3 coordinate3 .....================
[root@k8s-master elasticsearch7-ha]# docker-compose logs -f
WARNING: Some services (coordinate1, coordinate2, coordinate3, kibana, master-ha1, master-ha2, master-ha3) use the 'deploy' key, which will be ignored. Compose does not support 'deploy' configuration - use `docker stack deploy` to deploy to a swarm.
Attaching to master-ha3, coordinate3
访问es
访问kibana 的控制台
http://172.18.8.101:15601/
查看集群中的节点个数
# 查询API:
GET _cat/nodes?v
响应信息如下:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.14/security-minimal-setup.html to enable security.
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.22.0.7 67 98 7 0.20 0.82 1.39 cdfhilmrstw - master1
172.22.0.2 77 98 8 0.20 0.82 1.39 cdfhilmrstw * master3
172.22.0.3 20 98 7 0.20 0.82 1.39 lr - coordinate1
172.22.0.4 68 98 7 0.20 0.82 1.39 cdfhilmrstw master2
172.22.0.5 19 98 7 0.20 0.82 1.39 lr - coordinate2
增加pxc/es/minio的负载均衡代理配置
ha的配置文件如下
global
log 127.0.0.1 local0 info # 设置日志文件输出定向
daemon
maxconn 20000
defaults
log global
option tcplog
option dontlognull
retries 5
option redispatch
mode tcp
timeout queue 1m
timeout connect 10s
timeout client 1m #客户端空闲超时时间
timeout server 1m #服务端空闲超时时间
timeout check 5s
maxconn 10000
#listen http_front #haproxy的客户页面
# bind 0.0.0.0:1080
# stats uri /haproxy?stats
listen stats
mode http
log global
bind 0.0.0.0:2080
stats enable
stats refresh 30s
stats uri /haproxy-stats
# stats hide-version
listen ha-pxc-cluster
bind 0.0.0.0:23303
mode tcp
balance roundrobin
server ha-pxc01 ha-pxc01:3306 check
server ha-pxc02 ha-pxc02:3306 check
server ha-pxc03 ha-pxc03:3306 check
listen ha-nacos-cluster
bind 0.0.0.0:8848
mode tcp
balance roundrobin
server nacos_01 nacos1:8001 check
server nacos_02 nacos2:8002 check
server nacos_03 nacos3:8003 check
listen ha-minio-cluster
bind 0.0.0.0:9991
mode tcp
balance roundrobin
server minio1 minio1:9991 check
server minio2 minio2:9991 check
server minio3 minio3:9991 check
server minio4 minio4:9991 check
server minio5 minio5:9991 check
server minio6 minio6:9991 check
listen ha-es-cluster
bind 0.0.0.0:9200
mode tcp
balance roundrobin
server coordinate1 coordinate1:9200 check
server coordinate2 coordinate2:9200 check
server coordinate3 coordinate2:9200 check
在103上部署代理,然后启动
启动节点
cd /home/docker-compose/haproxy-ha/
docker-compose up -d
docker-compose logs -f
访问minio的控制台
http://172.18.8.104:29991/minio/
http://172.18.8.103:29991/minio/
http://172.18.8.101:29991/minio/
用户名:AKIAIOSFODNN7EXAMPLE,密码:wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
访问高可用代理的nacos
高可用代理
http://172.18.8.104:28848/nacos/#/configurationManagement?dataId=&group=&appName=&namespace=
用户名:nacos ,密码 nacos
程序访问es 的client node
http://172.18.8.104:29200/
增加VIP保障高可用
Keepalived 是一款轻量级HA集群应用,它的设计初衷是为了做LVS集群的HA,即探测LVS健康情况,从而进行主备切换,不仅如此,还能够探测LVS代理的后端主机的健康状况,动态修改LVS转发规则。
当LVS进行主备切换的时候,对外提供服务的IP是如何做到切换的呢?
这就依赖于keepalived 所应用的vrrp协议,即Virtual Reduntant Routing Protocol,虚拟冗余路由协议。简单来讲,此协议是将IP设置在虚拟接口之上,根据一定的规则实现IP在物理主机上流动,即哪台主机可以占有该IP。
而且keepalived具有脚本调用接口,可通过脚本完成拓展功能。
部署架构
目的: 进一步提高keepalived 可用性
设计:有3台keepalived 服务器 192.168.1.106 192.168.1.107 192.168.1.108。
vip 是192.168.1.249
效果:只要有一台keepalive 运行正常。vip 就可以访问
| server | hostname | ip |
|---|---|---|
| keepalived | z6 | 192.168.1.106 |
| keepalived | z7 | 192.168.1.107 |
| keepalived | z8 | 192.168.1.108 |
非抢占模式 默认 是谁先开启vip 运行在哪台机器上的。如果发生故障转移,再比较priority
离线部署keepalived
首先安装keepalived,下载离线包的命令为
yum install --downloadonly --downloaddir=./ keepalived
已经提供了安装包,上传安装包到 linux,比如root目录
keepalived_rpm.tar.gz
解压缩,然后执行命令安装
cd /root/
tar -zxvf keepalived_rpm.tar.gz
cd keepalived_rpm
rpm -Uvh --force --nodeps *rpm
输出
[root@localhost ~]# tar -zxvf keepalived_rpm.tar.gz
keepalived_rpm/
keepalived_rpm/keepalived-1.3.5-19.el7.x86_64.rpm
keepalived_rpm/lm_sensors-libs-3.4.0-8.20160601gitf9185e5.el7.x86_64.rpm
keepalived_rpm/net-snmp-agent-libs-5.7.2-49.el7_9.1.x86_64.rpm
keepalived_rpm/net-snmp-libs-5.7.2-49.el7_9.1.x86_64.rpm
安装的输出
[root@localhost ~]# cd keepalived_rpm
[root@localhost keepalived_rpm]# rpm -Uvh --force --nodeps *rpm
warning: keepalived-1.3.5-19.el7.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID f4a80eb5: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:net-snmp-libs-1:5.7.2-49.el7_9.1 ################################# [ 25%]
2:lm_sensors-libs-3.4.0-8.20160601g################################# [ 50%]
3:net-snmp-agent-libs-1:5.7.2-49.el################################# [ 75%]
4:keepalived-1.3.5-19.el7 ################################# [100%]
编写haproxy的监控脚本
vi /etc/keepalived/check_haproxy.sh
#!/bin/bash
A=`ps -C haproxy --no-header |wc -l`
if [ $A -eq 0 ];then
systemctl stop keepalived
fi
上传脚本,测试一下脚本
sh /etc/keepalived/check_haproxy.sh
修改keepalived配置
cat /etc/keepalived/keepalived.conf
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
复制 准备好的文件到离线环境,或者直接编辑。
vi /etc/keepalived/keepalived.conf
global_defs { #全局定义部分
notification_email { #设置警报邮箱
acassen@firewall.loc #邮箱1
failover@firewall.loc #邮箱2
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc #设置发件人地址
smtp_server 127.0.0.1 #设置smtp server地址
smtp_connect_timeout 30 #设置smtp超时连接时间 以上参数可以不配置
router_id HA_HAPROXY #是Keepalived服务器的路由标识在一个局域网内,这个标识(router_id)是唯一的
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
}
vrrp_instance VI_1 { #VRRP实例定义区块名字是VI_1
state BACKUP #表示当前实例VI_1的角色状态这个状态只能有MASTER和BACKUP两种状态,并且需要大写这些字符, MASTER 为正式工作的状态,BACKUP为备用的状态
interface ens33 #绑定ens33网卡
virtual_router_id 101 # VRRP 路由 ID实例,每个实例是唯一的
priority 90 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒 ,MASTER与BACKUP之间通信检查的时间间隔,
authentication { #authentication为权限认证配置不要改动,同一vrrp实例的MASTER与BACKUP使用相同的密码才能正常通信。
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #设置虚拟IP地址
# 192.168.31.60/24
172.18.8.231/24
}
track_script {
check_haproxy
}
}
离线包里边有 第一个节点的 配置文件,复制到 /etc/keepalived/ 目录就行
cp /home/docker-compose/keepalive-ha/keepalived01.conf /etc/keepalived/keepalived.conf
输出如下:
[root@localhost keepalive-ha]# pwd
/home/docker-compose/keepalive-ha
[root@localhost keepalive-ha]# cp /home/docker-compose/keepalive-ha/keepalived01.conf /etc/keepalived/keepalived.conf
cp: overwrite ‘/etc/keepalived/keepalived.conf’? yes
[root@localhost keepalive-ha]# cat /etc/keepalived/keepalived.conf
global_defs { #ȫ▒ֶ▒▒岿▒▒
notification_email { #▒▒▒þ▒▒▒▒▒▒▒
acassen@firewall.loc #▒▒▒▒1
failover@firewall.loc #▒▒▒▒2
sysadmin@firewall.loc
}
重启 keepalive服务
命令如下
# systemctl enable keepalived
# systemctl start keepalived
# systemctl restart keepalived
# systemctl status keepalived
输出如下:
[root@localhost ~]# systemctl enable keepalived
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
[root@localhost ~]# systemctl restart keepalived
[root@localhost ~]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2021-11-05 13:28:30 CST; 19s ago
Process: 48837 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48838 (keepalived)
Tasks: 3
Memory: 3.4M
CGroup: /system.slice/keepalived.service
├─48838 /usr/sbin/keepalived -D
├─48839 /usr/sbin/keepalived -D
└─48840 /usr/sbin/keepalived -D
Nov 05 13:28:34 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Nov 05 13:28:34 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Nov 05 13:28:34 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Nov 05 13:28:34 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Nov 05 13:28:39 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Nov 05 13:28:39 localhost.localdomain Keepalived_vrrp[48840]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on ens33 ...1.60
Nov 05 13:28:39 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Nov 05 13:28:39 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Nov 05 13:28:39 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Nov 05 13:28:39 localhost.localdomain Keepalived_vrrp[48840]: Sending gratuitous ARP on ens33 for 192.168.31.60
Hint: Some lines were ellipsized, use -l to show in full.
查看IP
[root@localhost ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:69:a4:84 brd ff:ff:ff:ff:ff:ff
inet 172.18.8.101/24 brd 172.18.8.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 172.18.8.231/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::b7be:346e:2f0f:859e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
访问高可用代理后的nacos
高可用代理
http://172.18.8.231:28848/nacos/#/configurationManagement?dataId=&group=&appName=&namespace=
用户名:nacos ,密码 nacos
离线部署keepalived到第2个节点,第3个节点
复制文件/并且安装
scp /root/keepalived_rpm.tar.gz root@172.18.8.103:/root
scp /root/keepalived_rpm.tar.gz root@172.18.8.104:/root
解压缩,然后执行命令安装
cd /root/
tar -zxvf keepalived_rpm.tar.gz
cd keepalived_rpm
rpm -Uvh --force --nodeps *rpm
把离线包里的 keepalive-ha 传过去,然后复制到 /etc/keepalived/
第1个节点,执行
cp /home/docker-compose/keepalive-ha/keepalived01.conf /etc/keepalived/keepalived.conf
cp /home/docker-compose/keepalive-ha/check_haproxy.sh /etc/keepalived/
cat /etc/keepalived/keepalived.conf
第二个节点,执行
cp /home/docker-compose/keepalive-ha/keepalived02.conf /etc/keepalived/keepalived.conf
cp /home/docker-compose/keepalive-ha/check_haproxy.sh /etc/keepalived/
cat /etc/keepalived/keepalived.conf
输出如下:
[root@localhost keepalive-ha]# cp /home/docker-compose/keepalive-ha/keepalived02.conf /etc/keepalived/keepalived.conf
cp: overwrite ‘/etc/keepalived/keepalived.conf’? yes
[root@localhost keepalive-ha]# cp /home/docker-compose/keepalive-ha/check_haproxy.sh /etc/keepalived/
cp: overwrite ‘/etc/keepalived/check_haproxy.sh’? yes
第3个节点,执行
cp /home/docker-compose/keepalive-ha/keepalived03.conf /etc/keepalived/keepalived.conf
cp /home/docker-compose/keepalive-ha/check_haproxy.sh /etc/keepalived/
cat /etc/keepalived/keepalived.conf
输出如下:
cp /home/docker-compose/keepalive-ha/keepalived03.conf /etc/keepalived/keepalived.conf
cp: overwrite ‘/etc/keepalived/keepalived.conf’? yes
[root@k8s-master keepalived_rpm]# cp /home/docker-compose/keepalive-ha/check_haproxy.sh /etc/keepalived/
cp: overwrite ‘/etc/keepalived/check_haproxy.sh’? yes
重启 keepalive服务
命令如下
systemctl enable keepalived
systemctl start keepalived
systemctl restart keepalived
systemctl status keepalived
systemctl stop keepalived
查看IP地址
ip a
ip a | grep ens33
ifconfig ens33
输出结果
[root@localhost ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:69:a4:84 brd ff:ff:ff:ff:ff:ff
inet 172.18.8.101/24 brd 172.18.8.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 172.18.8.231/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::b7be:346e:2f0f:859e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
测试高可用
停止101上的haproxy
sh ./stop_node.sh
sh ./start_node.sh
[root@localhost haproxy-ha]# sh ./stop_node.sh
===========stoping haproxy-ha .....================
WARNING: Some services (ha_sit_proxy) use the 'deploy' key, which will be ignored. Compose does not support 'deploy' configuration - use `docker stack deploy` to deploy to a swarm.
Stopping ha_sit_proxy ... done
Removing ha_sit_proxy ... done
Network ha-network-overlay is external, skipping
访问vip的nacos
http://172.18.8.231:28848/nacos/#/login
可以正常访问
访问高可用代理的minio
高可用代理
http://172.18.8.231:29991/minio/
用户名:nacos ,密码 nacos


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)