nacos高可用 (史上最全 + 图解+秒懂)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
nacos高可用 (史上最全 + 图解+秒懂)
背景:
下一个视频版本,从架构师视角,尼恩为大家打造高可用、高并发中间件的原理与实操。
目标:通过视频和博客的方式,为各位潜力架构师,彻底介绍清楚架构师必须掌握的高可用、高并发环境,包括但不限于:
-
高可用、高并发nginx架构的原理与实操
-
高可用、高并发mysql架构的原理与实操
-
高可用、高并发nacos架构的原理与实操
-
高可用、高并发rocketmq架构的原理与实操
-
高可用、高并发es架构的原理与实操
-
高可用、高并发minio架构的原理与实操
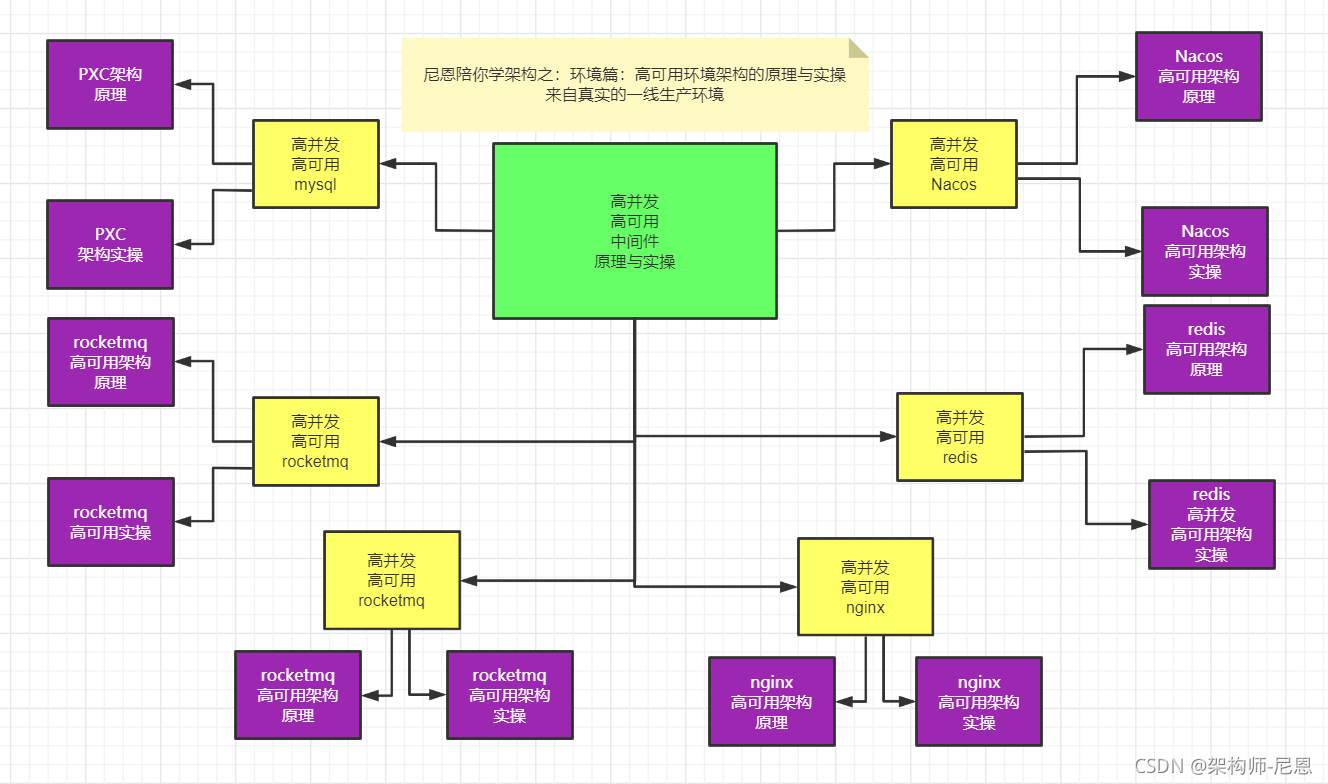
why 高可用、高并发中间件的原理与实操:
实际的开发过程中,很多小伙伴聚焦crud开发,环境出了问题,都不能启动。
作为架构师,或者未来想走向高端开发,或者做架构,必须掌握高可用、高并发中间件的原理,掌握其实操。
本系列博客的具体内容,请参见 Java 高并发 发烧友社群:疯狂创客圈
Nacos 高可用介绍
当我们在聊高可用时,我们在聊什么?
- 系统可用性达到 99.99%
- 在分布式系统中,部分节点宕机,依旧不影响系统整体运行
- 服务端集群化部署多个节点
Nacos 高可用,则是 Nacos 为了提升系统稳定性而采取的一系列手段。
Nacos 的高可用不仅仅存在于服务端,同时也存在于客户端,以及一些与可用性相关的功能特性中,这些点组装起来,共同构成了 Nacos 的高可用。
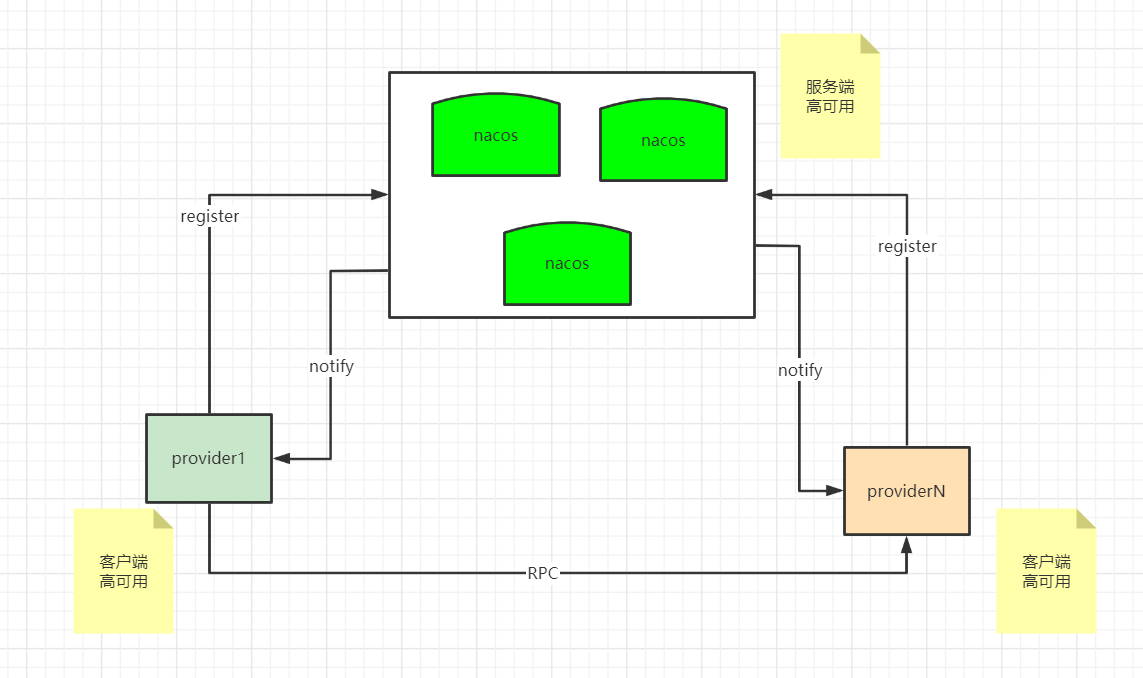
客户端高可用
先统一一下语义,在微服务架构中一般会有三个角色:
-
Consumer
-
Provider
-
Registry
以上的registry 角色是 nacos-server,而 Consumer 角色和 Provider 角色都是 nacos-client。
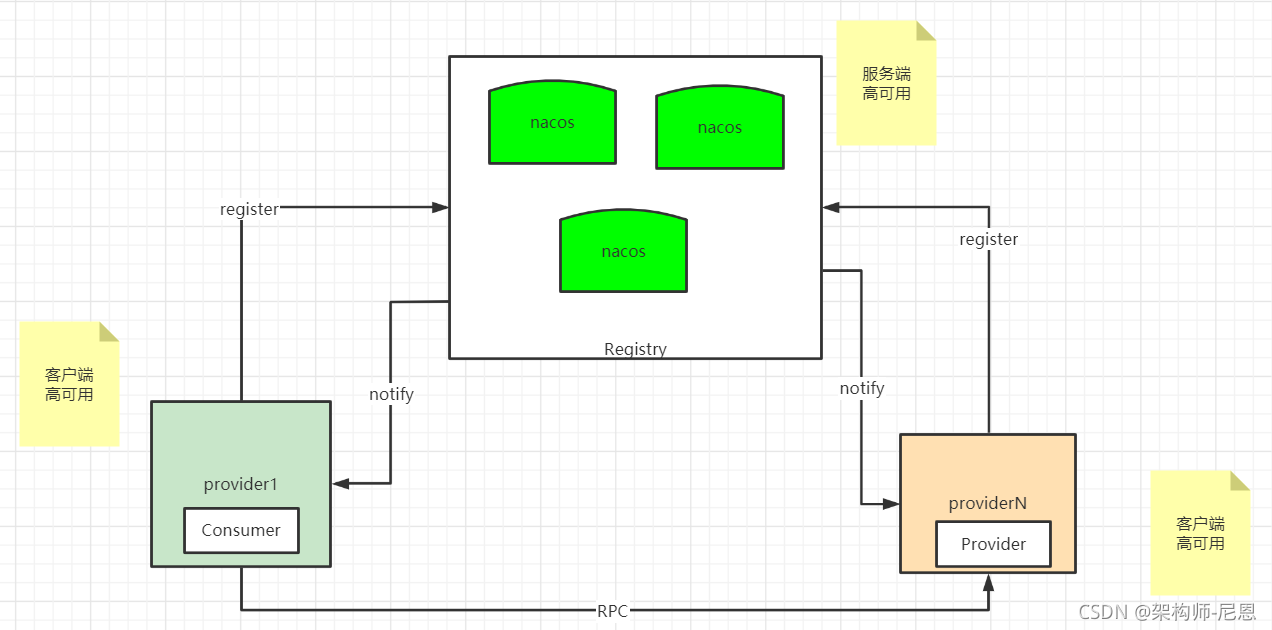
客户端高可用的方式一:配置多个nacos-server
在生产环境,我们往往需要搭建 Nacos 集群,代码中,是这样配置的:
server:
port: 8081
spring:
cloud:
nacos:
server-addr: 127.0.0.1:8848,127.0.0.1:8848,127.0.0.1:8848
当其中一台Nacos server机器宕机时,为了不影响整体运行,客户端会存在重试机制。
package com.alibaba.nacos.client.naming.net;
/**
* @author nkorange
*/
public class NamingProxy {
//api注册
public String reqAPI(String api, Map<String, String> params, String body, List<String> servers, String method) throws NacosException {
params.put(CommonParams.NAMESPACE_ID, getNamespaceId());
if (CollectionUtils.isEmpty(servers) && StringUtils.isEmpty(nacosDomain)) {
throw new NacosException(NacosException.INVALID_PARAM, "no server available");
}
NacosException exception = new NacosException();
if (servers != null && !servers.isEmpty()) {
Random random = new Random(System.currentTimeMillis());
int index = random.nextInt(servers.size());
//拿到地址列表,在请求成功之前逐个尝试,直到成功为止
for (int i = 0; i < servers.size(); i++) {
String server = servers.get(index);
try {
return callServer(api, params, body, server, method);
} catch (NacosException e) {
exception = e;
if (NAMING_LOGGER.isDebugEnabled()) {
NAMING_LOGGER.debug("request {} failed.", server, e);
}
}
index = (index + 1) % servers.size();
}
}
...
该可用性保证存在于 nacos-client 端。
Nacos Java Client通用参数
| 参数名 | 含义 | 可选值 | 默认值 | 支持版本 |
|---|---|---|---|---|
| endpoint | 连接Nacos Server指定的连接点,可以参考文档 | 域名 | 空 | >= 0.1.0 |
| endpointPort | 连接Nacos Server指定的连接点端口,可以参考文档 | 合法端口号 | 空 | >= 0.1.0 |
| namespace | 命名空间的ID | 命名空间的ID | config模块为空,naming模块为public | >= 0.8.0 |
| serverAddr | Nacos Server的地址列表,这个值的优先级比endpoint高 | ip:port,ip:port,... | 空 | >= 0.1.0 |
| JM.LOG.PATH(-D) | 客户端日志的目录 | 目录路径 | 用户根目录 | >= 0.1.0 |
客户端高可用的方式二:本地缓存文件 Failover 机制
注册中心发生故障最坏的一个情况是整个 Server 端宕机,如果三个Server 端都宕机了,怎么办呢?
这时候 Nacos 依旧有高可用机制做兜底。
本地缓存文件 Failover 机制
一道经典的 高可用的面试题:
当 springcloud 应用运行时,Nacos 注册中心宕机,会不会影响 RPC 调用。
这个题目大多数人,应该都不能回答出来.
Nacos 存在本地文件缓存机制,nacos-client 在接收到 nacos-server 的服务推送之后,会在内存中保存一份,随后会落盘存储一份快照snapshot 。有了这份快照,本地的RPC调用,还是能正常的进行。
关键是,这个本地文件缓存机制,默认是关闭的。
Nacos 注册中心宕机,Dubbo /springcloud 应用发生重启,会不会影响 RPC 调用。如果了解了 Nacos 的 Failover 机制,应当得到和上一题同样的回答:不会。
客户端Naming通用参数
| 参数名 | 含义 | 可选值 | 默认值 | 支持版本 |
|---|---|---|---|---|
| namingLoadCacheAtStart | 启动时是否优先读取本地缓存 | true/false | false | >= 1.0.0 |
| namingClientBeatThreadCount | 客户端心跳的线程池大小 | 正整数 | 机器的CPU数的一半 | >= 1.0.0 |
| namingPollingThreadCount | 客户端定时轮询数据更新的线程池大小 | 正整数 | 机器的CPU数的一半 | >= 1.0.0 |
| com.alibaba.nacos.naming.cache.dir(-D) | 客户端缓存目录 | 目录路径 | {user.home}/nacos/naming | >= 1.0.0 |
| com.alibaba.nacos.naming.log.level(-D) | Naming客户端的日志级别 | info,error,warn等 | info | >= 1.0.0 |
| com.alibaba.nacos.client.naming.tls.enable(-D) | 是否打开HTTPS | true/false | false |
snapshot 默认的存储路径为:{USER_HOME}/nacos/naming/ 中:
这份文件有两种价值,一是用来排查服务端是否正常推送了服务;二是当客户端加载服务时,如果无法从服务端拉取到数据,会默认从本地文件中加载。
在生产环境,推荐开启该参数,以避免注册中心宕机后,导致服务不可用,在服务注册发现场景,可用性和一致性 trade off 时,我们大多数时候会优先考虑可用性。
另外:{USER_HOME}/nacos/naming/{namespace} 下除了缓存文件之外还有一个 failover 文件夹,里面存放着和 snapshot 一致的文件夹。
这是 Nacos 的另一个 failover 机制,snapshot 是按照某个历史时刻的服务快照恢复恢复,而 failover 中的服务可以人为修改,以应对一些极端场景。
该可用性保证存在于 nacos-client 端。
Nacos两种健康检查模式
agent上报模式
客户端(注册在nacos上的其它微服务实例)健康检查。
客户端通过心跳上报方式告知服务端(nacos注册中心)健康状态;
默认心跳间隔5秒;
nacos会在超过15秒未收到心跳后将实例设置为不健康状态;
超过30秒将实例删除;
服务端主动检测
服务端健康检查。
nacos主动探知客户端健康状态,默认间隔为20秒;
健康检查失败后实例会被标记为不健康,不会被立即删除。
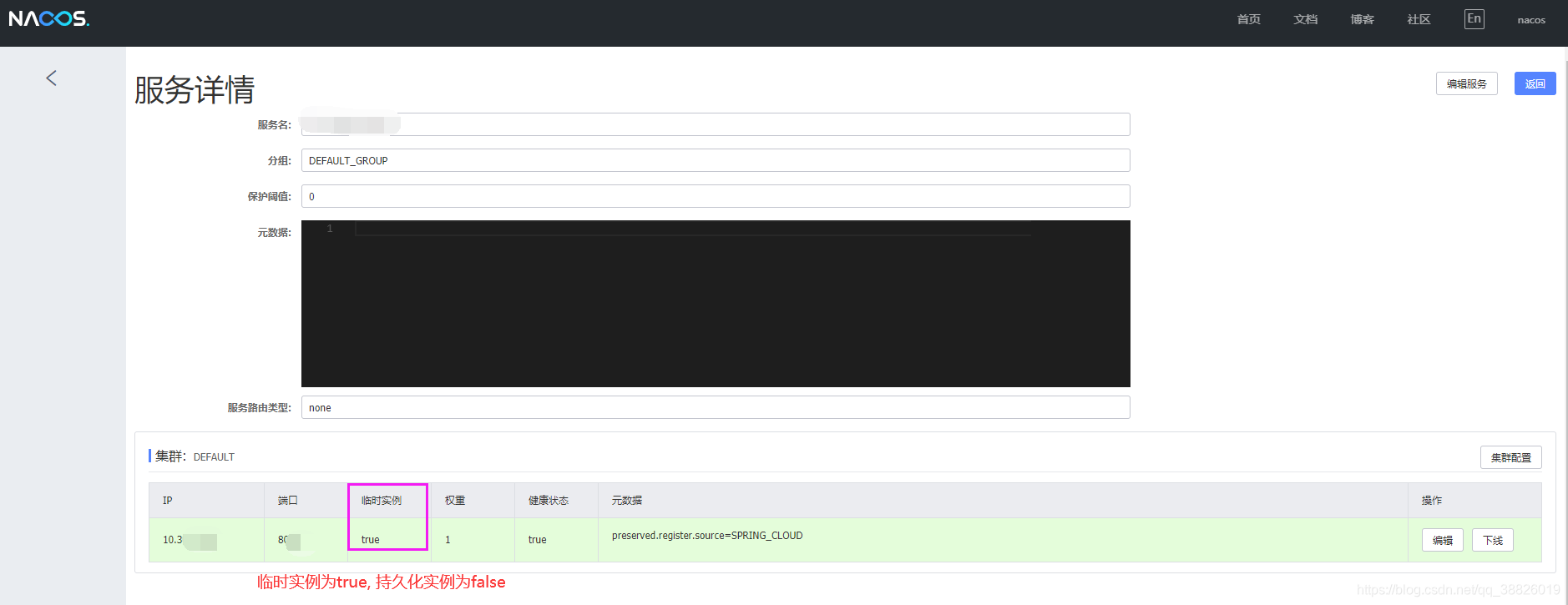
临时实例
临时实例通过agent上报模式实现健康检查。
Nacos 在 1.0.0版本 instance级别增加了一个ephemeral字段,该字段表示注册的实例是否是临时实例还是持久化实例。
微服务注册为临时实例:
# 默认true
spring:
cloud:
nacos:
discovery:
ephemeral: true
注意: 默认为临时实例,表示为临时实例。

注册实例支持ephemeral字段
如果是临时实例,则instance不会在 Nacos 服务端持久化存储,需要通过上报心跳的方式进行包活,
如果instance一段时间内没有上报心跳,则会被 Nacos 服务端摘除。
在被摘除后如果又开始上报心跳,则会重新将这个实例注册。
持久化实例则会持久化被 Nacos 服务端,此时即使注册实例的客户端进程不在,这个实例也不会从服务端删除,只会将健康状态设为不健康。
同一个服务下可以同时有临时实例和持久化实例,这意味着当这服务的所有实例进程不在时,会有部分实例从服务上摘除,剩下的实例则会保留在服务下。
使用实例的ephemeral来判断,ephemeral为true对应的是服务健康检查模式中的 client 模式,为false对应的是 server 模式。
Nacos 1.0.0 之前服务的健康检查模式有三种:client、server 和none, 分别代表客户端上报、服务端探测和取消健康检查。在控制台操作的位置如下所示:
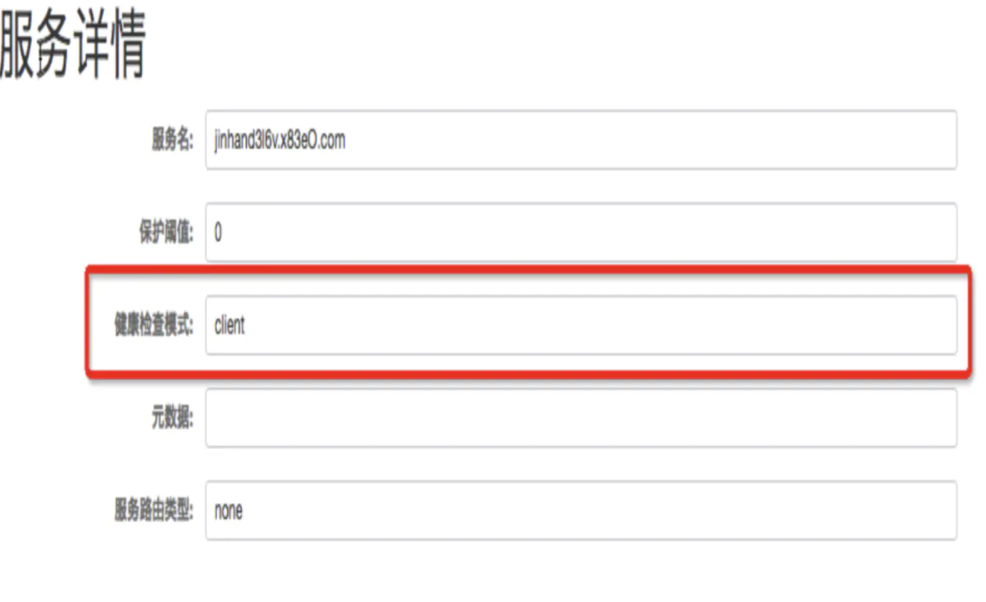
在 Nacos 1.0.0 中将把这个配置去掉,改为使用实例的ephemeral来判断,ephemeral为true对应的是服务健康检查模式中的 client 模式,为false对应的是 server 模式。
临时实例和持久化实例区别
临时和持久化的区别主要在健康检查失败后的表现,持久化实例健康检查失败后会被标记成不健康,而临时实例会直接从列表中被删除。
这个特性比较适合那些需要应对流量突增,而弹性扩容的服务,当流量降下来后这些实例自己销毁自己就可以了,不用再去nacos里手动调用注销实例。持久化以后,可以实时看到健康状态,便于做后续的告警、扩容等一系列处理。
Nacos Server运行模式
Server的运行模式,是指 Nacos Server 可以运行在多种模式下,当前支持三种模式:
- AP、
- CP
- MIXED 。
这里的运行模式,使用的是CAP理论里的C、A和P概念。
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
CAP原则的精髓就是要么AP,要么CP,要么AC,但是不存在CAP。如果在某个分布式系统中数据无副本, 那么系统必然满足强一致性条件, 因为只有独一数据,不会出现数据不一致的情况,此时C和P两要素具备,但是如果系统发生了网络分区状况或者宕机,必然导致某些数据不可以访问,此时可用性条件就不能被满足,即在此情况下获得了CP系统,但是CAP不可同时满足 。
基于CAP理论,在分布式系统中,数据的一致性、服务的可用性和网络分区容忍性只能三者选二。一般来说分布式系统需要支持网络分区容忍性,那么就只能在C和A里选择一个作为系统支持的属性。C 的准确定义应该是所有节点在同一时间看到的数据是一致的,而A的定义是所有的请求都会收到响应。
Nacos 支持 AP 和 CP 模式的切换,这意味着 Nacos 同时支持两者一致性协议。这样,Nacos能够以一个注册中心管理这些生态的服务。不过在Nacos中,AP模式和CP模式的具体含义,还需要再说明下。
AP模式为了服务的可能性而减弱了一致性,因此AP模式下只支持注册临时实例。AP 模式是在网络分区下也能够注册实例。在AP模式下也不能编辑服务的元数据等非实例级别的数据,但是允许创建一个默认配置的服务。同时注册实例前不需要进行创建服务的操作,因为这种模式下,服务其实降级成一个简单的字符创标识,不在存储任何属性,会在注册实例的时候自动创建。
CP模式下则支持注册持久化实例,此时则是以 Raft 协议为集群运行模式,因此网络分区下不能够注册实例,在网络正常情况下,可以编辑服务器别的配置。改模式下注册实例之前必须先注册服务,如果服务不存在,则会返回错误。
MIXED 模式可能是一种比较让人迷惑的模式,这种模式的设立主要是为了能够同时支持临时实例和持久化实例的注册。这种模式下,注册实例之前必须创建服务,在服务已经存在的前提下,临时实例可以在网络分区的情况下进行注册。
Nacos CP/AP模式设定
使用如下请求进行Server运行模式的设定:
curl -X PUT
'$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP'
Nacos CP/AP模式切换
Nacos 集群默认支持的是CAP原则中的AP原则.
但是Nacos 集群可切换为CP原则,切换命令如下:
curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP'
同时微服务的bootstrap.properties 需配置如下选项指明注册为临时/永久实例
AP模式不支持数据一致性,所以只支持服务注册的临时实例,CP模式支持服务注册的永久实例,满足配置文件的一致性
#false为永久实例,true表示临时实例开启,注册为临时实例
spring.cloud.nacos.discovery.ephemeral=true
AP/CP的配套一致性协议
介绍一致性模型之前,需要回顾 Nacos 中的两个概念:临时服务和持久化服务。
- 临时服务(Ephemeral):临时服务健康检查失败后会从列表中删除,常用于服务注册发现场景。
- 持久化服务(Persistent):持久化服务健康检查失败后会被标记成不健康,常用于 DNS 场景。
两种模式使用的是不同的一致性协议:
-
临时服务使用的是 Nacos 为服务注册发现场景定制化的私有协议 distro,其一致性模型是 AP;
-
而持久化服务使用的是 raft 协议,其一致性模型是 CP。
AP模式下的distro 协议
distro 协议的工作流程如下:
- Nacos 启动时首先从其他远程节点同步全部数据。
- Nacos 每个节点是平等的都可以处理写入请求,同时把新数据同步到其他节点。
- 每个节点只负责部分数据,定时发送自己负责数据的校验值到其他节点来保持数据一致性。
如图所示,每个节点负责一部分服务的写入。
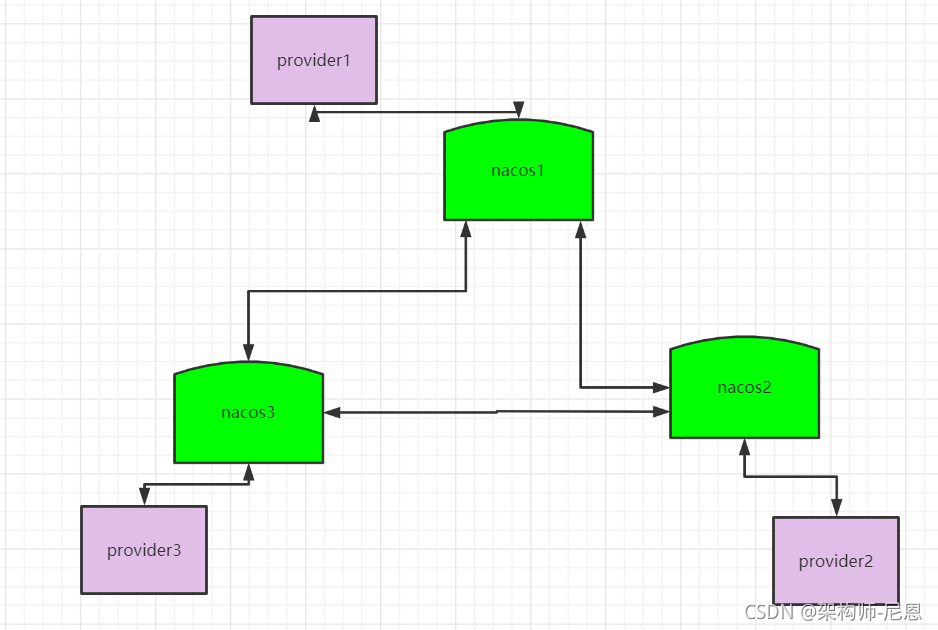
但每个节点都可以接收到写入请求,这时就存在两种情况:
- 当该节点接收到属于该节点负责的服务时,直接写入。
- 当该节点接收到不属于该节点负责的服务时,将在集群内部路由,转发给对应的节点,从而完成写入。
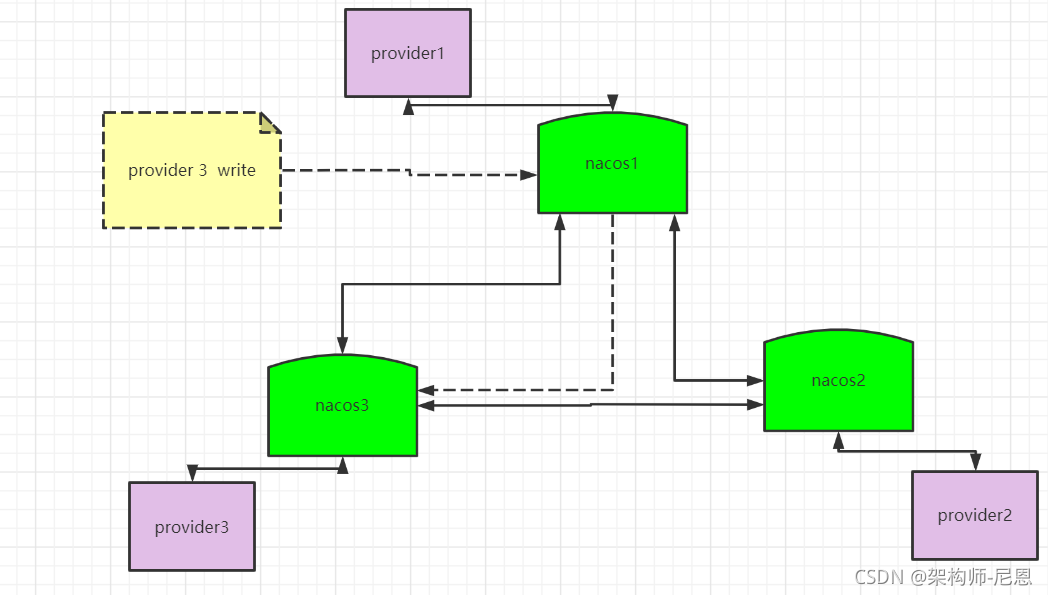
读取操作则不需要路由,因为集群中的各个节点会同步服务状态,每个节点都会有一份最新的服务数据。
而当节点发生宕机后,原本该节点负责的一部分服务的写入任务会转移到其他节点,从而保证 Nacos 集群整体的可用性。
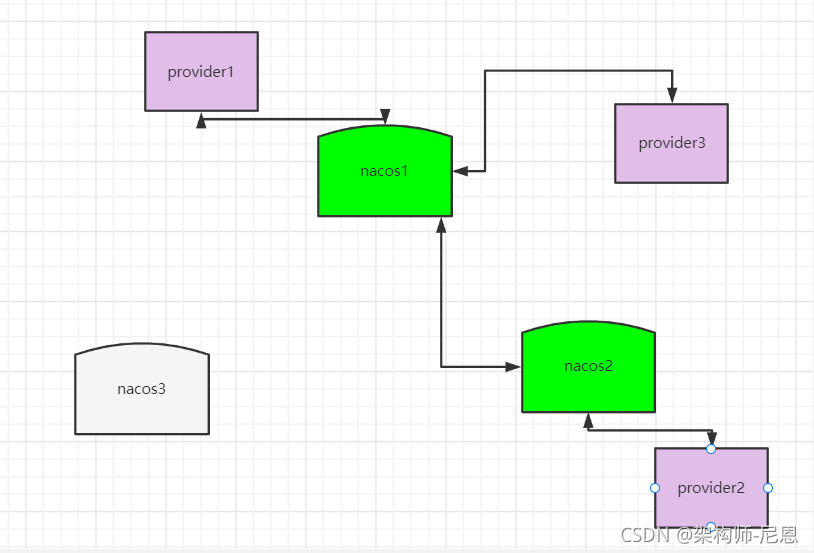
一个比较复杂的情况是,节点没有宕机,但是出现了网络分区,即下图所示:
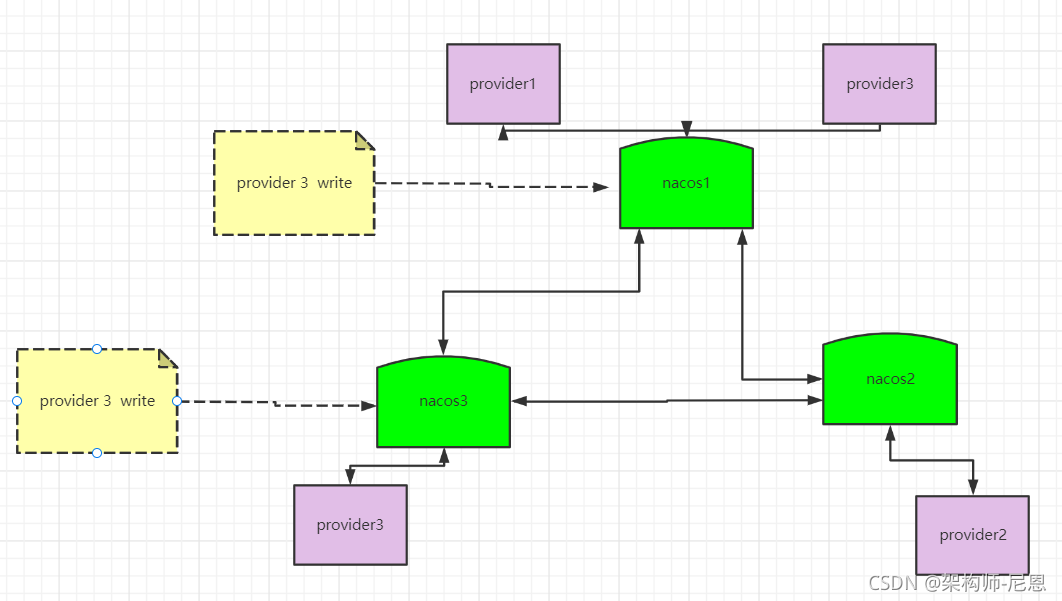
这个情况会损害可用性,客户端会表现为有时候服务存在有时候服务不存在。
综上,Nacos 的 distro 一致性协议可以保证在大多数情况下,集群中的机器宕机后依旧不损害整体的可用性。
Nacos 有两个一致性协议:distro 和 raft,distro 协议不会有脑裂问题。
CP模式下的raft协议
此文还是聚焦于介绍nacos的高可用, raft协议,请参考尼恩的架构师视频。
集群内部的特殊的心跳同步服务
心跳机制一般广泛存在于分布式通信领域,用于确认存活状态。
一般心跳请求和普通请求的设计是有差异的,心跳请求一般被设计的足够精简,这样在定时探测时可以尽可能避免性能下降。
而在 Nacos 中,出于可用性的考虑,一个心跳报文包含了全部的服务信息,这样相比仅仅发送探测信息降低了吞吐量,而提升了可用性,怎么理解呢?
考虑以下的两种场景:
- nacos-server 节点全部宕机,服务数据全部丢失。nacos-server 即使恢复运作,也无法恢复出服务,而心跳包含全部内容可以在心跳期间就恢复出服务,保证可用性。
- nacos-server 出现网络分区。由于心跳可以创建服务,从而在极端网络故障下,依旧保证基础的可用性。
调用 OpenApi 依次删除各个服务:
curl -X "DELETE mse-xxx-p.nacos-ans.mse.aliyuncs.com:8848/nacos/v1/ns/service?serviceName=providers:com.alibaba.edas.boot.EchoService:1.0.0:DUBBO&groupName=DEFAULT_GROUP"
过 5s 后刷新,服务又再次被注册了上来,符合我们对心跳注册服务的预期。
集群部署模式高可用
最后给大家分享的 Nacos 高可用特性来自于其部署架构。
节点数量
我们知道在生产集群中肯定不能以单机模式运行 Nacos。
那么第一个问题便是:我应该部署几台机器?
Nacos 有两个一致性协议:distro 和 raft,distro 协议不会有脑裂问题,所以理论来说,节点数大于等于 2 即可;raft 协议的投票选举机制则建议是 2n+1 个节点。
综合来看,选择 3 个节点是起码的,其次处于吞吐量和更吞吐量的考量,可以选择 5 个,7 个,甚至 9 个节点的集群。
多可用区部署
组成集群的 Nacos 节点,应该尽可能考虑两个因素:
- 各个节点之间的网络时延不能很高,否则会影响数据同步。
- 各个节点所处机房、可用区应当尽可能分散,以避免单点故障。
以阿里云的 ECS 为例,选择同一个 Region 的不同可用区就是一个很好的实践。
部署模式
生产环境,建议使用k8s部署或者阿里云的 ECS 部署。
考虑的中等公司,都会有运维团队,开发人员不需要参与。
所以,这里介绍的开发人员必须掌握的,docker模式的部署。
高可用nacos的部署架构
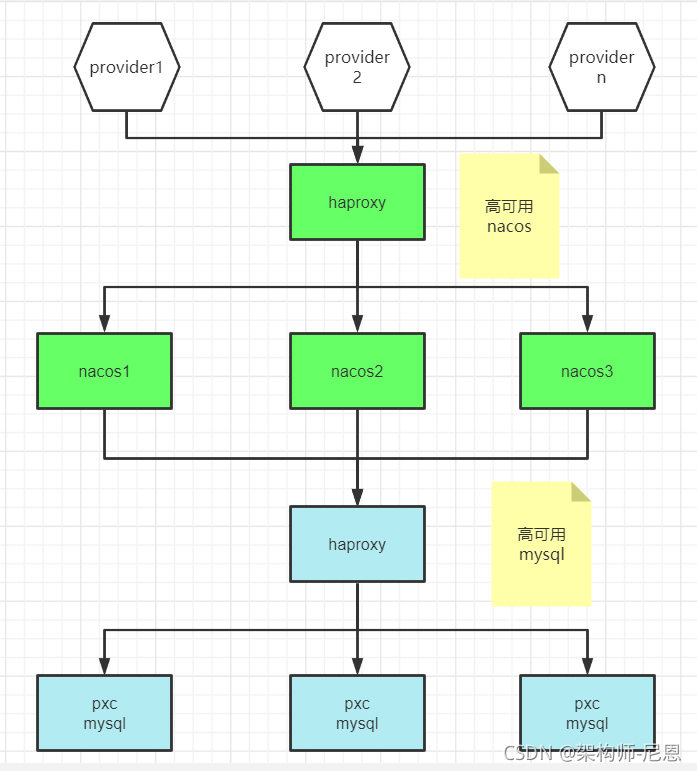
高可用nacos的部署实操
实操这块,使用视频介绍更为清晰,请参考尼恩的架构师视频。
总结
本文从多个角度出发,总结了一下 Nacos 是如何保障高可用的。
高可用特性绝不是靠服务端多部署几个节点就可以获得的,而是要结合客户端使用方式、服务端部署模式、使用场景综合来考虑的一件事。
特别是在服务注册发现场景,Nacos 为可用性做了非常多的努力,而这些保障,ZooKeeper 是不一定有的。在做注册中心选型时,可用性保障上,Nacos 绝对是优秀的。
参考文献:
https://nacos.io/zh-cn/docs/what-is-nacos.html
https://blog.csdn.net/qq_38826019/article/details/109433231

 浙公网安备 33010602011771号
浙公网安备 33010602011771号