Redis Cluster 原理与实战- 图解- 秒懂
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Redis Cluster 原理与实战- 图解- 秒懂
Redis 集群的几种架构
Redis发展到现在,几种常见的部署架构有:
- 主从模式;
- 哨兵模式;
- 集群模式;
主从模式/哨兵模式都不具备集群的在线扩容(动态收缩),集群模式是最适合动态收缩场景的模式。
无论是开发者还是架构师,都必须掌握这种模式的原理和使用。
有关Redis 集群的几种架构,请参见另外一篇理论与实际,都兼备的博文:
Redis集群 - 图解 - 秒懂(史上最全) 10W长文
Redis Cluster 介绍
Redis Cluster是Redis的分布式解决方案,在Redis 3.0版本正式推出的,有效解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构达到负载均衡的目的。
Redis集群提供了一种运行Redis设备的方式,并且数据可以在多个Redis节点间自动分配的。Redis集群在分区期间也能提供一定程度的可用性,实际上,就是说当某些节点发生故障或无法通信时,集群能够继续运行。但是,如果发生较大故障(例如,大多数主站服务器不可用时),群集会停止运行。
那么从实际角度而言,您使用RedisCluster能获得什么呢?
1、在多个节点之间自动分割数据集的能力。
2、在节点子集遇到故障或无法与集群其余部分通信时继续运行的能力。
创建和使用Redis群集
注意:手动部署Redis群集,这对了解集群的操作细节方面是非常重要的。
要创建一个集群,我们需要做的第一件事是在集群模式下运行几个空的Redis实例。
这就意味着群集不是使用普通的Redis实例创建的,因为需要配置特殊模式,以便Redis实例启用群集特定的功能和命令。
请注意,按预期工作的最小群集需要至少包含三个主节点。
对于第一次测试,强烈建议启动一个由三个主服务器节点和三个从服务器节点组成的六个节点群集。
我们通过以下步骤来一步一步的搭建Redis的Cluster集群环境。
部署 Redis Cluster的主节点
搭建Redis Cluster主要步骤
- 1.配置开启节点
- 2.meet握手
- 4.主从关系分配
- 3.指派槽
虚拟机节点准备
Redis 集群一般由多个节点组成,节点数量为6个才能保证组成完整高可用的集群。这里使用俩虚拟机,每个虚拟机3个redis 节点,端口分别为 7000 、7001 、7002。
两台虚拟机操作系统均为,64位CentOS ,主机地址分别为:
-
cdh1
-
cdh2
虚拟机系统安装说明, 具体请参见 另一篇博文:
编译安装Redis, 具体请参见 另一篇博文:

如果已经运行了redis,则需要 查看redis的版本
[root@cdh1 ~]# /usr/local/redis/bin/redis-server -v
Redis server v=5.0.2 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=9dd76fe83d6d9ef0
两台虚拟机的三个redis 7000,7001,7002端口搭建三主三从的Redis Cluster,其中
- cdh1主机三个端口启动的Redis Server为主节点
- cdh2主机三个端口启动的Redis Server为从节点

注意:集群内部的通信端口,为客户端通信端口+10000
创建好目录:
[root@cdh1 redis]# mkdir -p /usr/local/redis/logs
[root@cdh1 redis]# mkdir -p /usr/local/redis/cluster
[root@cdh1 redis]# mkdir -p /usr/local/redis/db
[root@cdh1 redis]# chmod 777 /usr/local/redis
准备一个配置文件
#自定义每个redis实例端口
port 7000
#默认保护模式yes,修改为no
protected-mode no
#bind 127.0.0.1 #默认安全保护,只能访问本机
#开启集群模式
cluster-enabled yes
#记录集群信息,不用手动维护,Redis Cluster 会自动维护
cluster-config-file nodes_7000.conf
#节点超时时间,单位毫秒
cluster-node-timeout 15000
# 其他配置和单机模式相同
# 修改no为yes,后台运行redis
daemonize yes
logfile '/usr/local/redis/logs/redis_7000.log'
dir '/usr/local/redis/db/'
dbfilename 'redis_7000.rdb'
appendonly yes
appendfilename "appendonly_7000.aof"
启动集群节点并且查看日志
启动一个节点:
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/redis_7000.conf
查看日志:
cat /usr/local/redis/logs/redis_7000.log
[root@cdh1 cluster]# cd /usr/local/redis/cluster/
[root@cdh1 cluster]# sed 's/7000/7001/g' redis_7000.conf > redis_7001.conf
[root@cdh1 cluster]# sed 's/7000/7002/g' redis_7000.conf > redis_7002.conf
[root@cdh1 cluster]# ll
total 12
-rw-r--r-- 1 root root 710 Apr 23 09:38 redis_7000.conf
-rw-r--r-- 1 root root 710 Apr 23 09:41 redis_7001.conf
-rw-r--r-- 1 root root 710 Apr 23 09:41 redis_7002.conf
[root@cdh1 cluster]# cat redis_7002.conf
#自定义每个redis实例端口
port 7002
#默认保护模式yes,修改为no
protected-mode no
#bind 127.0.0.1 #默认安全保护,只能访问本机
#开启集群模式
cluster-enabled yes
#记录集群信息,不用手动维护,Redis Cluster 会自动维护
cluster-config-file nodes_7002.conf
#节点超时时间,单位毫秒
cluster-node-timeout 15000
# 其他配置和单机模式相同
# 修改no为yes,后台运行redis
daemonize yes
logfile '/usr/local/redis/logs/redis_7002.log'
dir '/usr/local/redis/db/'
dbfilename 'redis_7002.rdb'
appendonly yes
appendfilename "appendonly_7002.aof"
[root@cdh1 cluster]# /usr/local/redis/bin/redis-server /usr/local/redis/cluster/redis_7001.conf
[root@cdh1 cluster]# /usr/local/redis/bin/redis-server /usr/local/redis/cluster/redis_7002.conf
[root@cdh1 cluster]# ps aux | grep redis-server
root 871 0.3 0.0 153820 7696 ? Ssl 05:22 0:55 /usr/local/redis/bin/redis-server *:6379
root 5443 0.2 0.0 156892 7700 ? Ssl 09:38 0:00 /usr/local/redis/bin/redis-server *:7000 [cluster]
root 5466 0.2 0.0 153820 7676 ? Ssl 09:43 0:00 /usr/local/redis/bin/redis-server *:7001 [cluster]
root 5471 0.3 0.0 153820 7676 ? Ssl 09:43 0:00 /usr/local/redis/bin/redis-server *:7002 [cluster]
操作Redis Cluster集群的客户端命令
这里列出一个操作Redis Cluster集群的客户端命令的清单,统一供参考。
以下命令是Redis Cluster集群所独有的,执行下面命令需要先登录redis:
登录的客户端命令为:redis-cli -c -p port -h ip
[root@manage redis]# redis-cli -c -p 6382 -h 192.168.10.12
192.168.10.12:6382>
登录redis后,在里面可以进行下面命令操作Redis Cluster集群:
集群
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
节点
cluster meet
cluster forget <node_id> :从集群中移除 node_id 指定的节点。
cluster replicate <master_node_id> :将当前从节点设置为 node_id 指定的master节点的slave节点。只能针对slave节点操作。
cluster saveconfig :将节点的配置文件保存到硬盘里面。
槽(slot)
cluster addslots
cluster delslots
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot
另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot
cluster setslot
cluster setslot
键
cluster keyslot
cluster countkeysinslot
cluster getkeysinslot
redis参数配置
redis参数的配置可以通过config get命令来获取redis参数配置的信息,通过config set 命令来设置相关参数。以下是10点redis命令配置是redis在开发过程中经常要用到的相关配置:
1、port:6379
指定访问redis服务端的端口。
2、bind:127.0.0.1
指定redis绑定的主机地址。
3、timeout:
指定客户端连接redis服务器时,当闲置的时间为多少(如300)时,关闭连接。
4、loglevel:
指定redis数据库的日志级别,常用的日志级别有debug、verbose、notice、warning,不进行修改的情况下默认的是notice;
5、save <s><c>:
指定redis数据库多长时间内(s)有多少次(c)更新操作时就把缓存中的数据同步到本地库,
比如,指的是10分钟内有2次更新操作,就同步到本地库:
> save 600 2
6、dir :
指定redis本地数据文件存放的目录。
7、requirepass:
指定redis的访问密码。
8、maxmemory:
指定redis的最大内存。由于Redis 在启动时会把数据加载到内存中,当数据达到最大内存时,redis会自动把已经到期和即将到期的key值。所以可以根据需求调整自己的所需的最大内存。
9、appendonly :
指定redis是否开启日志记录功能。由于redis是利用什么save命令异步的方式更新数据到本地库,所以不开启日志记录功能,可能会导致在出现生产事故时,导致部分数据未更新到本地库。
10、vw-enabled:
指定redis是否启用虚拟内存机制,vw的机制是将数据进行分页,把不经常使用(即访问量较少的)的页swap到磁盘当中,把访问较多的数据,从磁盘自动转换到内存当中。
RDB和AOF
redis提供了两种数据持久化方式:
- RDB:redis的数据存储在内存中,不定期的将数据异步同步到磁盘上(半持久化)
- AOF:记录redis的所有写操作到aof(append only file)文件中(全持久化)
默认情况下,redis中使用的事RDB实现数据持久化
RDB: SNAPSHOTING(快照)
这种方式是就是将内存中数据以快照的方式写入到一种称为RDB格式的二进制文件中,默认的文件名为dump.rdb(可以通过配置进行更改)。

可以通过配置,设置自动快照的周期。主要的方式为:
配置redis在n秒内如果超过m个key被修改就自动做快照,
下面是默认的快照保存配置
save 900 1 #900秒内如果超过1个key被修改,则发起快照保存
save 300 10 #300秒内容如超过10个key被修改,则发起快照保存
save 60 10000
RDB快照保存的过程:
- redis会创建(fork)一个子进程来进行持久化。
- 父进程继续处理client请求,子进程负责将内存中的内容写入到临时文件。由于OS的写时复制机制(copy on write),父子进程会共享相同的物理页面,当父进程处理写请求时,OS会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程的地址空间内的数据是fork时整个数据库的一个快照。
- 当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。
整个过程,主进程不进行任何IO操作,确保了极高的性能。如果需要进行大规模数据的回复,且对数据回复的完整性不是非常敏感的话,使用RDB方式要比AOF方式更加高效。
除了按照默认策略的自动快照,也可以手动执行save或者bgsave(异步)做快照。还可以通过shutdown 等命令触发快照。
触发RDB快照的多种方式:
1、在指定的时间间隔内,执行指定次数的写操作
2、执行save(阻塞, 只管保存快照,其他的等待) 或者是bgsave (异步)命令
3、执行flushall 命令,清空数据库所有数据,意义不大。flushall命令也会产生dump.rdb文件,但是文件内容为空
4、执行shutdown 命令,保证服务器正常关闭且不丢失任何数据,意义...也不大。
手动保存快照手动
保存RDB数据的命令:有两种,一个是save,一个是bgsave,一般用的都是bgsave命令。
1、save命令:save命令会阻塞redis服务器的进程,直到RDB文件创建完,在该期间,redis不能处理任何的命令请求,这就是save命令最大的缺陷。
2、bgsave命令:与save命令不同的是,bgsave在生成RDB文件时,会派生出一个子进程,子进程负责创建RDB文件,在此期间,主进程和子进程是同时存在的,因此不会阻塞redis服务器进程。
说明:(可用lastsave命令查看生成RDB文件是否成功),lastsave命令获取最后一次成功执行快照的时间
通过RDB文件恢复数据:
将dump.rdb 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可。在实际开发中,一般会考虑到物理机硬盘损坏情况,选择备份dump.rdb 。
RDB相关配置:
RDB相关的配置对应redis.conf中的SNAPSHOT模块

RDB持久化数据的优缺点:

1、优点:
(1)、采用子线程创建RDB文件,不会对redis服务器性能造成大的影响;
(2)、快照生成的RDB文件是一种压缩的二进制文件,可以方便的在网络中传输和保存。通过RDB文件,可以方便的将redis数据恢复到某一历史时刻,可以提高数据安全性,避免宕机等意外对数据的影响。
(3)、适合大规模的数据恢复。
(4)、如果业务对数据完整性和一致性要求不高,RDB是很好的选择。
2、缺点:
(1)、在redis文件在时间点A生成,之后产生了新数据,还未到达另一次生成RDB文件的条件,redis服务器崩溃了,那么在时间点A之后的数据会丢失掉,数据一致性不是完美的好,如果可以接受这部分丢失的数据,可以用生成RDB的方式;
(2)、快照持久化方法通过调用fork()方法创建子线程。fork时,内存中的数据被克隆一份,大致2倍的数据膨胀需要考虑。具体来说,当redis内存的数据量比较大时,创建子线程和生成RDB文件会占用大量的系统资源和处理时间,对 redis处理正常的客户端请求造成较大影响。
(3)、数据的完整性和一致性不高,因为RDB可能在最后一次备份时宕机了。
(4)、备份时占用内存,因为Redis 在备份时会独立创建一个子进程,将数据写入到一个临时文件(此时内存中的数据是原来的两倍哦),最后再将临时文件替换之前的备份文件。所以Redis 的持久化和数据的恢复要选择在夜深人静的时候执行是比较合理的。
AOF: append only file 只增不改的日志文件
AOF是redis对将所有的写命令保存到一个aof文件中,根据这些写命令,实现数据的持久化和数据恢复。
1.追加写操作:
AOF以日志的形式来记录每个写操作,将Redis执行过的所有写操作记录下来,只追加文件但不修改文件,所以叫做append only file (只增不改的文件)

2.redis启动时会读取该文件重新构建数据。redis重启时会根据日志文件的内容将写指令全部重新执行以恢复数据。

AOF文件Redis 默认不开启,它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。
如果开启了Aof,Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF在redis.conf中的配置:

redis中AOF默认是关闭的,修改配置:appendonly yes,即可开启redis的AOF功能,且默认的记录文件为appendonly.aof,通过appendfilename 选项进行修改。
截图中并不包含所有的aof相关配置,下面就来说一下redis.conf中aof相关的配置:
-
appendonly yes:
开启redis AOF功能
-
appendfilename "appendonly.aof":
aof的记录文件名
-
appendfsync always/everysec/no:
aof记录频率,always表示每次收到记录就立即写入磁盘,性能损耗大;
everysec表示每秒钟写入磁盘一次,性能和持久化折中;
no不同步,完全依赖os,性能好,但持久化没有保证。
-
no-appendfsync-on-rewrite no:
重写时是否可以运用appendfsync,默认no,保证数据安全。
-
auto-aof-rewrite-percentage 100:
设置重写的标准值,即上次文件大小的百分比
-
auto-aof-rewrite-min-size 64mb:
当aof文件最小达到64mb大小时,开始重写aof文件
-
aof-load-truncated yes:
aof文件损坏时,是否自动修复文件。选择no时,需要手动redis-check-aof 修复文件
-
aof-use-rdb-preamble no:
重写aof文件时,是否使用混合持久化。
混合持久化方式
edis4.0相对与3.X版本其中一个比较大的变化是4.0添加了新的混合持久化方式。
当开启混合持久化时(aof-use-rdb-preamble为true),fork出的子进程先将共享的内存副本全量的以RDB方式写入aof文件,然后在将缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。
简单的说:
新的AOF文件前半段是RDB格式的全量数据,后半段是AOF格式的增量数据
如下图:

混合持久化方式的数据恢复
当我们开启了混合持久化时,启动redis依然优先加载aof文件,aof文件加载可能有两种情况如下:
-
aof文件开头是rdb的格式, 先加载 rdb内容再加载剩余的 aof。
-
aof文件开头不是rdb的格式,直接以aof格式加载整个文件。
AOF LOG Rewrite:
AOF采用文件追加的方式,文件会越来越大。为了避免这种情况,新增了重写机制,即当AOF文件大小超过指定阀值时,Redis会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,也可以使用bgrewriteaof命令,手动压缩文件。
redis会记录上次重写的aof文件的大小,在默认配置中,当aof文件和上次rewrite的文件大小相同,且文件大小大于最小值(默认为64mb)时,会触发重写机制。对应的默认配置为:
- auto-aof-rewrite-percentage 100:设置重写的标准值,即上次文件大小的百分比
- auto-aof-rewrite-min-size 64mb:当aof文件最小达到64mb大小时,开始重写aof文件
AOF LOG Rewrite的过程为:redis会fork出一条新进程来进行aof文件重写(先写临时文件最后再rename),遍历新进程的内存中的数据,每条记录有一条的set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个aof文件,这点类似于快照。
AOF优缺点:
优点:
1、提供了多种同步命令的方式,默认1秒同步一次写命令,做多会丢失1秒内的数据;
2、如果AOF文件有错误,比如在写AOF文件时redis崩溃了,redis提供了多种恢复AOF文件的方式,
例如使用redis-check-aof工具修正AOF文件(一般都是最后一条写命令有问题,可以手动取出最后一条写命令);
3、AOF文件可读性交强,也可手动操作写命令。
4、数据的完整性和一致性更高
缺点:
1、AOF文件比RDB文件较大;
2、redis负载较高时,RDB文件比AOF文件具有更好的性能;
3、RDB使用快照的方式持久化整个redis数据,而aof只是追加写命令,因此从理论上来说,RDB比AOF方式更加健壮,另外,官方文档也指出,在某些情况下,AOF的确也存在一些bug,
比如使用阻塞命令时,这些bug的场景RDB是不存在的。
4、因为AOF记录的内容多,文件会越来越大,数据恢复也会越来越慢。
触发AOF快照:
根据配置文件触发,可以是每次执行触发,可以是每秒触发,可以不同步。
根据AOF文件恢复数据:
正常情况下,将appendonly.aof 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可。但在实际开发中,可能因为某些原因导致appendonly.aof 文件格式异常,从而导致数据还原失败,可以通过命令redis-check-aof --fix appendonly.aof 进行修复 。
注意:当同事启用AOF和RDB持久化方案时,redis会先使用aof文件进行数据恢复。
RDB和AOF总结
1、Redis 默认开启RDB持久化方式,在指定的时间间隔内,执行指定次数的写操作,则将内存中的数据写入到磁盘中。
2、RDB 持久化适合大规模的数据恢复但它的数据一致性和完整性较差。
3、Redis 需要手动开启AOF持久化方式,默认是每秒将写操作日志追加到AOF文件中。
4、AOF 的数据完整性比RDB高,但记录内容多了,会影响数据恢复的效率。
5、Redis 针对 AOF文件大的问题,提供重写的瘦身机制。
6、若只打算用Redis 做缓存,可以关闭持久化。(RDB关闭:注释掉所有save,AOF关闭:appendonly为no)
7、若打算使用Redis 的持久化。建议RDB和AOF都开启。其实RDB更适合做数据的备份,留一后手。AOF出问题了,还有RDB。
Redis群集配置参数
介绍一下RedisCluster在redis.conf文件中引入的配置参数。有些命令的意思是显而易见的,有些命令在你阅读下面的解释后才会更加清晰。
1、cluster-enabled <yes/no>:
如果想在特定的Redis实例中启用Redis群集支持就设置为yes。否则,实例通常作为独立实例启动。
2、cluster-config-file
请注意,尽管有此选项的名称,但这不是用户可编辑的配置文件,而是Redis群集节点每次发生更改时自动保留群集配置(基本上为状态)的文件,以便能够在启动时重新读取它。该文件列出了群集中其他节点,它们的状态,持久变量等等。由于某些消息的接收,通常会将此文件重写并刷新到磁盘上。
3、cluster-node-timeout
Redis群集节点可以不可用的最长时间,而不会将其视为失败。如果主节点超过指定的时间不可达,它将由其从属设备进行故障切换。此参数控制Redis群集中的其他重要事项。值得注意的是,每个无法在指定时间内到达大多数主节点的节点将停止接受查询。
4、cluster-slave-validity-factor
如果设置为0,无论主设备和从设备之间的链路保持断开连接的时间长短,从设备都将尝试故障切换主设备。如果该值为正值,则计算最大断开时间作为节点超时值乘以此选项提供的系数,如果该节点是从节点,则在主链路断开连接的时间超过指定的超时值时,它不会尝试启动故障切换。例如,如果节点超时设置为5秒,并且有效因子设置为10,则与主设备断开连接超过50秒的从设备将不会尝试对其主设备进行故障切换。请注意,如果没有从服务器节点能够对其进行故障转移,则任何非零值都可能导致Redis群集在主服务器出现故障后不可用。在这种情况下,只有原始主节点重新加入集群时,集群才会返回可用。
5、cluster-migration-barrier
主设备将保持连接的最小从设备数量,以便另一个从设备迁移到不受任何从设备覆盖的主设备。有关更多信息,请参阅本教程中有关副本迁移的相应部分。
6、cluster-require-full-coverage <yes/no>:
如果将其设置为yes,则默认情况下,如果key的空间的某个百分比未被任何节点覆盖,则集群停止接受写入。如果该选项设置为no,则即使只处理关于keys子集的请求,群集仍将提供查询。
Redis集群内部P2P通信原理
启动所有的节点
[root@cdh1 cluster]# ps aux | grep redis-server
root 871 0.3 0.0 153820 7696 ? Ssl 05:22 0:55 /usr/local/redis/bin/redis-server *:6379
root 5443 0.2 0.0 156892 7700 ? Ssl 09:38 0:00 /usr/local/redis/bin/redis-server *:7000 [cluster]
root 5466 0.2 0.0 153820 7676 ? Ssl 09:43 0:00 /usr/local/redis/bin/redis-server *:7001 [cluster]
root 5471 0.3 0.0 153820 7676 ? Ssl 09:43 0:00 /usr/local/redis/bin/redis-server *:7002 [cluster]
可以查看日志文件
[root@cdh1 cluster]# cat /usr/local/redis/logs/redis_7000.log
5343:C 23 Apr 2021 09:28:32.455 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
5343:C 23 Apr 2021 09:28:32.455 # Redis version=5.0.2, bits=64, commit=00000000, modified=0, pid=5343, just started
5343:C 23 Apr 2021 09:28:32.455 # Configuration loaded
5343:M 23 Apr 2021 09:28:32.456 * No cluster configuration found, I'm 96f9337a510af4719a5f716aa8598c07e7c64106
有日志文件可得,节点已经启动成功。这个日志文件是Redis服务器普通的日志文件。
集群配置文件
在集群模式下,第一次也会自动创建一个日志文件,由配置文件cluster-config-file指定文件。
集群配置文件的作用:当集群内节点发生信息变化时,如添加节点、节点下线、故障转移等。节点会自动保存集群的状态到配置文件中。该配置文件由Redis自行维护,不要手动修改,防止节点重启时产生集群信息错乱。
我们来查看一下,集群模式的cluster-config-file配置文件:
[root@cdh1 cluster]# cat /usr/local/redis/db/nodes_7000.conf
96f9337a510af4719a5f716aa8598c07e7c64106 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
也可以通过客户端连接该节点,通过命令CLUSTER NODES来查看:
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli -p 7000
127.0.0.1:7000> CLUSTER NODES
96f9337a510af4719a5f716aa8598c07e7c64106 :7000@17000 myself,master - 0 0 0 connected
127.0.0.1:7000>
或者通过一条完成的客户端指令去执行:
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli -p 7000 cluster nodes
96f9337a510af4719a5f716aa8598c07e7c64106 :7000@17000 myself,master - 0 0 0 connected
其效果是一样的。
节点启动的模式
启动节点即启动Redis服务器集群模式,否则只是一个普通的Redis服务器
启动Redis服务器时会根据cluster-enabled配置选项是否为yes来决定是否开启服务器的集群模式:

集群中的节点元数据
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:
-
节点负责哪些数据
-
节点的状态信息,如是否出现故障等。
集群数据结构
clusterNode:保存了一个节点的当前状态

clusterNode的link属性是一个clusterLink结构,保存了连接节点所需的有关信息

clusterState:每个节点保存一个,记录了在当前节点的视角下,集群目前所处的状态。
如集群是否在线、包含多少个节点、当前配置纪元(可以理解为年代、年号)等

例子:以127.0.0.1:7000节点为例进行观察:currentEpoch为0代表配置纪元为0,state的状态表示集群目前为下线状态、size为0代表没有任何节点在处理槽

Redis集群内部,不同的节点之间,如何进行元数据同步呢?
gossip 协议与Redis集群的Gossip消息
分布式集群转给你,常见的保持数据一致性的方式分为:
-
集中式/中心化模式
-
去中心化/P2P方式。
集中式/中心化模式
将集群元数据集中存储在一个节点上。典型代表是大数据领域的 storm。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper对所有元数据进行存储维护。

- 优点
元数据的读取和更新时效性非常好,元数据的变更都能立即更新到集中式存储节点中,其它节点读取的时候就可以感知到;
- 缺点
所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。
去中心化/P2P方式
redis 维护集群元数据采用的是gossip 协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。

- 优点
元数据的更新比较分散,不是集中在一个地方,降低了压力;
- 缺点
元数据的更新有延时,可能导致集群中的一些操作会有一些滞后。
Redis集群内采用的是P2P方式模式,没有主节点。并且采用的是Gossip协议。
Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息,这种方式类似流言传播。
gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Alan Demers)于1987年创造的。
从 gossip 单词就可以看到,其中文意思是八卦、流言等意思,我们可以想象下绯闻的传播(或者流行病的传播);gossip 协议的工作原理就类似于这个。gossip 协议利用一种随机的方式将信息传播到整个网络中,并在一定时间内使得系统内的所有节点数据一致。Gossip 其实是一种去中心化思路的分布式协议,解决状态在集群中的传播和状态一致性的保证两个问题。
[
Goosip 协议的信息传播和扩散通常需要由种子节点发起。整个传播过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
Gossip协议是一个P2P协议,所有写操作可以由不同节点发起,并且同步给其他副本。Gossip内组成的网络节点都是对等节点,是非结构化网络。
Redis集群的Gossip消息
Redis集群使用二进制协议进行节点到节点的数据交换,这更适合于使用很少的带宽和处理时间在节点之间交换信息。Gossip协议的主要职责就是信息交换。信息交换的载体就是节点彼此发送的Gossip消息。
Redis集群中每个redis实例(可能一台机部署多个实例)会使用两个Tcp端口,一个用于给客户端(redis-cli或应用程序等)使用的端口,另一个是用于集群中实例相互通信的内部总线端口,且第二个端口比第一个端口一定大10000。 内部总线端口通信使用特殊Gossip协议,以便实现集群内部高带宽低时延的数据交换。所以配置redis实例时只需要指明第一个端口就可以了。
所以,每一个Redis群集的节点都需要打开两个TCP连接,由于这两个连接就需要两个端口,分别是用于为客户端提供服务的常规RedisTCP命令端口(例如6379)以及通过将10000和命令端口相加(10000+6379)而获得的端口,就是集群端口(例如16379)。
命令端口和集群总线端口偏移量是固定的,始终为10000。第二个大号端口用于群集总线,即使用二进制协议的节点到节点通信通道。节点使用群集总线进行故障检测,配置更新,故障转移授权等。
客户端不应尝试与群集总线端口通信,为了保证Redis命令端口的正常使用,请确保在防火墙中打开这两个端口,否则Redis群集节点将无法通信。
请注意,为了让Redis群集正常工作,您需要为每个节点:
1、用于与客户端进行通信的普通客户端通信端口(通常为6379)对所有需要到达群集的客户端以及所有其他群集节点(使用客户端端口进行密钥迁移)都是开放的。
2、集群总线端口(客户端端口+10000)必须可从所有其他集群节点访问。
Redis集群常用的Gossip消息可分为:ping消息、pong消息、meet消息、fail消息。
ping消息
集群里的每个节点默认每隔一秒钟就会从已知节点列表中随机选出五个节点,然后对这五个节点中最长时间没有发送过PING消息的节点发送PING消息,以此来检测被选中的节点是否在线。
除此之外,如果节点A最后一次收到节点B发送的PONG消息的时间,距离当前时间已经超过了节点A的cluster-node-timeout选项设置时长的一半,那么节点A也会向节点B发送PING消息,这可以防止节点A因为长时间没有随机选中节点B作为PING消息的发送对象而导致对节点B的信息更新滞后

pong消息
当接收者收到发送者发来的MEET消息或者PING消息时,为了向发送者 确认这条MEET消息或者PING消息已到达,接收者会向发送者返回一条PONG消息。
另外,一个节点也可以通过向集群广播自己的PONG消息来让集群中的其他节点立即刷新关于这个节点的认识,例如当一次故障转移操作成功执行之后,新的主节点会向集群广播一条PONG消息,以此来让集群中的其他节点立即知道这个节点已经变成了主节点,并且接管了已下线节点负责的槽

meet消息
当发送者接到客户端发送的CLUSTER MEET命令时,发送者会向接收者 发送MEET消息,请求接收者加入到发送者当前所处的集群里面

fail消息
当集群里的节点A将节点B标记为已下线(FAIL)时,节点A将向集群广播一条关于节点B的FAIL消息,所有接收到这条FAIL消息的节点都会将节点B标记为已下线

fail消息演示案例
举个例子,对于包含7000、7001、7002、7003四个主节点的集群来说:
- 如果主节点7001发现主节点7000已下线,那么主节点7001将向主节点7002和主节点7003 发送FAIL消息,其中FAIL消息中包含的节点名字为主节点7000的名字,以此来表示主节点 7000已下线
- 当主节点7002和主节点7003都接收到主节点7001发送的FAIL消息时,它们也会将主节 点7000标记为已下线
- 因为这时集群已经有超过一半的主节点认为主节点7000已下线,所以集群剩下的几个主节点可以判断是否需要将该节点标记为下线,又或者开始对主节点7000进行故障转移
下图展示了节点发送和接收FAIL消息的整个过程

在集群的节点数量比较大的情况下,单纯使用Gossip协议来传播节点的已下线信息会给节点的信息更新带来一定延迟,因为Gossip协议消息通常需要一段时间才能传播至整个集群,而发送FAIL消息可以让集群里的所有节点立即知道某个主节点已下线,从而尽快判断是 否需要将集群标记为下线,又或者对下线主节点进行故障转移
PUBLISH消息
当客户端向集群中的某个节点发送命令:
PUBLISH <channel> <message>
- 接收到PUBLISH命令的节点不仅会向channel频道发送消息message,它还会向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会向channel频道发送 message消息。换句话说,向集群中的某个节点发送PUBLISH命令,将导致集群中的所有节点都向channel频道发送message消息
- 为什么不直接向节点广播PUBLISH命令:实际上,要让集群的所有节点都执行相同的PUBLISH命令,最简单的方法就是向所有节点广播相同的PUBLISH命令,这也是Redis在复制PUBLISH命令时所使用的方法, 不过因为这种做法并不符合Redis集群的“各个节点通过发送和接收消息来进行通信”这一 规则,所以节点没有采取广播PUBLISH命令的做法
演示案例
举个例子,对于包含7000、7001、7002、7003四个节点的集群来说,如果节点7000收到
了客户端发送的PUBLISH命令,那么节点7000将向7001、7002、7003三个节点发送 PUBLISH消息,如下图所示

消息格式分析
消息格式划分:消息头+消息体
1.消息头
-
消息头包含发送节点自身状态数据,接收节点根据消息头就可以获取到发送节点的相关数据;
-
集群内所有的消息都采用相同的消息头结构clusterMsg,它包含了发送节点关键信息,如节点id、槽映射、节点标识(主从角色,是否下线)等。
- 节点发送的所有消息都由一个消息头包裹,消息头除了包含消息正文之外,还记录了消息发送者自身的一些信息,因为这些信息也会被消息接收者用到,所以严格来讲,我们可以认为消息头本身也是消息的一部分.
每个消息头都由一个cluster.h/clusterMsg结构表示://消息的长度(包括这个消息头的长度和消息正文的长度) uint32_t totlen; //消息的类型 uint16_t type; //消息正文包含的节点信息数量 //只在发送MEET 、PING 、PONG 这三种Gossip 协议消息时使用 uint16_t count; //发送者所处的配置纪元 uint64_t currentEpoch; //如果发送者是一个主节点,那么这里记录的是发送者的配置纪元 //如果发送者是一个从节点,那么这里记录的是发送者正在复制的主节点的配置纪元 uint64_t configEpoch; //发送者的名字(ID ) char sender[REDIS_CLUSTER_NAMELEN]; //发送者目前的槽指派信息 unsigned char myslots[REDIS_CLUSTER_SLOTS/8]; //如果发送者是一个从节点,那么这里记录的是发送者正在复制的主节点的名字 //如果发送者是一个主节点,那么这里记录的是REDIS_NODE_NULL_NAME //(一个40 字节长,值全为0 的字节数组) char slaveof[REDIS_CLUSTER_NAMELEN]; //发送者的端口号 uint16_t port; //发送者的标识值 uint16_t flags; //发送者所处集群的状态 unsigned char state; //消息的正文(或者说,内容) union clusterMsgData data; } clusterMsg; ```
2.消息体
- 消息体在Redis内部采用clusterMsgData结构声明。
- 消息体clusterMsgData定义发送消息的数据,其中ping、meet、pong都采用cluster MsgDataGossip数组作为消息体数据,实际消息类型使用消息头的 type 属性区分。每个消息体包含该节点的多个clusterMsgDataGossip结构数据,用于信息交换。
clusterMsg.data属性指向联合cluster.h/clusterMsgData,这个联合就是消息的正文:
// MEET 、PING 、PONG 消息的正文 struct { //每条MEET 、PING 、PONG 消息都包含两个 // clusterMsgDataGossip 结构 clusterMsgDataGossip gossip[1]; } ping; // FAIL 消息的正文 struct { clusterMsgDataFail about; } fail; // PUBLISH 消息的正文 struct { clusterMsgDataPublish msg; } publish; //其他消息的正文... }; ```
集群元数据的自动更新:
clusterMsg结构的currentEpoch、sender、myslots等属性记录了发送者自身的节点信息,接收者会根据这些信息,在自己的clusterState.nodes字典里找到发送者对应的clusterNode结 构,并对本地保存的集群元数据进行自动更新
举个例子,通过对比接收者为发送者记录的槽指派信息,以及发送者在消息头的my slots 属性记录的槽指派信息,接收者可以知道发送者的槽指派信息是否发生了变化
又举个例子,通过对比接收者为发送者记录的标识值,以及发送者在消息头的flags属性记录的标识值,接收者可以知道发送者的状态和角色是否发生了变化,例如节点状态由原来的在线变成了下线,或者由主节点变成了从节点等等
消息处理流程
接收节点收到ping/meet消息时,执行解析消息头和消息体流程:

解析消息头过程
消息头包含了发送节点的信息,如果发送节点是新 节点且消息是meet类型,则加入到本地节点列表;如果是已知节点,则尝试更新发送节点的状态,如槽映射关系、主从角色等状态。
解析消息体过程
如果消息体的clusterMsgDataGossip数组包含的节点是新节点,则尝试发起与新节点的meet握手流程;如果是已知节点,则根据 cluster MsgDataGossip中的flags字段判断该节点是否下线,用于故障转移。
消息处理完后回复pong消息,内容同样包含消息头和消息体,发送节点接收到回复的pong消息后,采用类似的流程解析处理消息并更新与接收节点最后通信时间,完成一次消息通信。
ping 时的节点选择
Redis集群的Gossip协议需要兼顾信息交换实时性和成本开销。
-
ping 时要携带一些元数据,如果很频繁,可能会加重网络负担。因此,Redis集群内节点通信采用固定频率(定时任务每秒执行10次),一般每个节点每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。
-
当然如果发现某个节点通信延时达到了 cluster_node_timeout / 2,那么立即发送 ping,避免数据交换延时过长导致信息严重滞后。
比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以 cluster_node_timeout 可以调节,如果调得比较大,那么会降低 ping 的频率。
-
每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。至少包含 3 个其它节点的信息,最多包含 总节点数减 2 个其它节点的信息。
因此节点每次选择需要通信的节点列表变得非常重要。通信节点选择过多虽然可以做到信息及时交换但是成本过高。节点选择过少会降低集群内所有节点彼此信息交互频率,从而影响故障判定、新节点发现等需求的速度。ping 时,通信节点选择的规则如图所示:

根据通信节点选择的流程可以看出:
消息交换的成本主要体现在单位时间选择发送消息的节点数量和每个消息携带的数据量。
选择发送消息的节点数量:
-
集群内每个节点维护定时任务默认每秒执行10次,每秒会随机选取5个节点找出最久没有通信的节点发送ping消息,用于保证Gossip信息交换的随机性。每100毫秒都会扫描本地节点列表,如果发现节点最近一次接受pong消息的时间大于 cluster_node_timeout / 2,则立刻发送ping消息,防止该节点信息太长时间未更新。根据以上规则得出每个节点每秒需要发送ping消息的数量,由此,根据以上规则得出每个节点每秒需要发送ping消息的数量:
5+10*num(node.pong_received>cluster_node_timeout/2)
所以: cluster_node_timeout参数对消息发送的节点数量影响非常大。
-
当我们的带宽资源紧张时,可以适当调大这个参数,如从默认15秒改为30秒来降低带宽占用率。
-
过度调大cluster_node_timeout会影响消息交换的频率从而影响故障转移、槽信息更新、新节点发现的速度。
-
需要根据业务容忍度和资源消耗进行平衡,同时整个集群消息总交换量也跟节点数成正比。
消息数据量:
- 每个ping消息的数据量体现在消息头和消息体中,其中消息头主要占用 空间的字段是myslots[CLUSTER_SLOTS/8],占用2KB,这块空间占用相对固定。
- 消息体会携带一定数量的其他节点信息用于信息交换。消息体携带数据量跟集群的节点数息息相关,更大的集群每次消息通信的成本也就更高,因此对于Redis集群来说并不是大而全的集群更好。
总结一下:Redis集群通信流程
- 集群中的每个节点都会单独开辟一个TCP通道,用于节点之间彼此通信,通信端口号在基础端口上加10000
- 每个节点在固定周期内通过特定规则选择几个节点发送ping消息
- 接收到ping消息的节点用pong消息作为响应
集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终它们会达到一致的状态。当节点出故障、新节点加入、主从角色变化、槽信息变更等事件发生时,通过不断的ping/pong消息通信,经过一段时间后所有的节点都会知道整个集群全部节点的最新状态,从而达到集群状态同步的目的。
实战:节点握手
为什么需要握手?
redis 集群是去中心的P2P集群,节点启动之后,节点与节点之间是没有关系的。
[root@cdh1 cluster]# ps aux | grep redis-server
root 871 0.3 0.0 153820 7696 ? Ssl 05:22 0:55 /usr/local/redis/bin/redis-server *:6379
root 5443 0.2 0.0 156892 7700 ? Ssl 09:38 0:00 /usr/local/redis/bin/redis-server *:7000 [cluster]
root 5466 0.2 0.0 153820 7676 ? Ssl 09:43 0:00 /usr/local/redis/bin/redis-server *:7001 [cluster]
root 5471 0.3 0.0 153820 7676 ? Ssl 09:43 0:00 /usr/local/redis/bin/redis-server *:7002 [cluster]
集群配置文件
我们来查看一下,7000节点的的cluster-config-file配置文件:
[root@cdh1 cluster]# cat /usr/local/redis/db/nodes_7000.conf
96f9337a510af4719a5f716aa8598c07e7c64106 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
7001节点的的cluster-config-file配置文件:
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli -p 7000 cluster nodes
96f9337a510af4719a5f716aa8598c07e7c64106 :7000@17000 myself,master - 0 0 0 connected
其结果是一样的。
什么是节点握手?
节点握手是指一批运行在集群模式的节点通过Gossip协议彼此通信,达到感知对方的过程。
CLUSTER MEET 命令被用来连接不同的开启集群支持的 Redis 节点,以进入工作集群。
基本的思想是每个节点默认都是相互不信任的,并且被认为是未知的节点,以便万一因为系统管理错误或地址被修改,而不太可能将多个不同的集群节点混成一个集群。
因此,为了使给定的节点能将另一个节点接收到组成 Redis Cluster 的节点列表中,这里只有两种方法:
- 系统管理员发送一个CLUSTER MEET 命令强制一个节点去会面另一个节点。
- 一个已知的节点发送一个保存在 gossip 部分的节点列表,包含着未知的节点。如果接收的节点已经将发送节点信任为已知节点,它会处理 gossip 部分并且发送一个握手消息给未知的节点。
请注意,Redis Cluster 需要形成一个完整的网络(每个节点都连接着其他每个节点),但是为了创建一个集群,不需要发送形成网络所需的所有CLUSTER MEET命令。
发送CLUSTER MEET消息以便每个节点能够到达其他每个节点只需通过一条已知的节点连接就足够了。由于在心跳包中会交换 gossip 信息,将会创建节点间缺失的连接。
所以,如果我们通过CLUSTER MEET连接了节点 A 和节点 B ,并且节点 B 和 C 有连接,那么节点 A 和节点 C 会有他们握手和创建链接的方法。
另一个例子:如果我们想象一个由四个分别叫 A,B,C,和D 的节点组成,我们可能只发送以下一组命令给节点 A :
- CLUSTER MEET B-ip B-port
- CLUSTER MEET C-ip C-port
- CLUSTER MEET D-ip D-port
作为A知道和被其他所有节点知道的副作用,它将会在发送的心跳包中包含gossip部分,这将允许其他每个节点彼此都创建一个链接,即使集群很大,也能在数秒钟之内形成一个完整的网络。
而且CLUSTER MEET不必相互执行,如果发送命令给 A 以加入B ,那么就不必也发送给 B 以加入 A 。
cluster meet命令的原理
cluster meet
- 节点 A 会为节点 B 创建一个 clusterNode 结构, 并将该结构添加到自己的 clusterState.nodes 字典里面。
- 节点A根据CLUSTER MEET命令给定的IP地址和端口号,向节点B发送一条MEET消息。
- 节点B接收到节点A发送的MEET消息,节点B会为节点A创建一个clusterNode结构,并将该结构添加到自己的clusterState.nodes字典里面。
- 节点B向节点A返回一条PONG消息。
- 节点A将受到节点B返回的PONG消息,通过这条PONG消息节点A可以知道节点B已经成功的接收了自己发送的MEET消息。
- 之后,节点A将向节点B返回一条PING消息。
- 节点B将接收到的节点A返回的PING消息,通过这条PING消息节点B可以知道节点A已经成功的接收到了自己返回的PONG消息,握手完成。
- 之后,节点A会将节点B的信息通过Gossip协议传播给集群中的其他节点,让其他节点也与节点B进行握手,最终,经过一段时间后,节点B会被集群中的所有节点。
节点握手命令执行
节点握手是集群彼此通信的第一步,由客户端发起命令:
cluster meet
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli -p 7000
127.0.0.1:7000> CLUSTER MEET 127.0.0.1 7001
OK
// 发送CLUSTER NODES可以查看到已经感知到 7001 端口的节点了。
127.0.0.1:7000> CLUSTER NODES
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 127.0.0.1:7001@17001 master - 0 1619245666239 0 connected
96f9337a510af4719a5f716aa8598c07e7c64106 127.0.0.1:7000@17000 myself,master - 0 0 1 connected
让所有的节点都互相感知,7000给7002发个握手消息:
127.0.0.1:6379> CLUSTER MEET 127.0.0.1 7002
OK
// 已经全部感知到所有的节点
127.0.0.1:7000> CLUSTER NODES
1939fff03e1133de208743f71501b6eabef657e8 127.0.0.1:7002@17002 master - 0 1619245786594 2 connected
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 127.0.0.1:7001@17001 master - 0 1619245785000 0 connected
96f9337a510af4719a5f716aa8598c07e7c64106 127.0.0.1:7000@17000 myself,master - 0 0 1 connected
当前已经使这3个节点,已经组成集群。
但是现在还无法工作,因为集群节点还没有分配槽(slot)。
部署 Redis Cluster的从节点
因为虚拟机挺耗费内存的,除了做特殊的实验,所以平时只启动了cdh1.
启动虚拟机cdh2
MINGW64 /e/virtual/workcluster
$ vagrant up cdh2
Bringing machine 'cdh2' up with 'virtualbox' provider...
==> cdh2: Importing base box 'springcloud-dev'...
==> cdh2: Matching MAC address for NAT networking...
==> cdh2: Setting the name of the VM: workcluster_cdh2_1619251843115_13982
==> cdh2: Fixed port collision for 22 => 2222. Now on port 2200.
==> cdh2: Vagrant has detected a configuration issue which exposes a
==> cdh2: vulnerability with the installed version of VirtualBox. The
==> cdh2: current guest is configured to use an E1000 NIC type for a
==> cdh2: network adapter which is vulnerable in this version of VirtualBox.
....
因为与cdh1是同一个镜像,预装了redis。
创建目录
[root@cdh1 redis]# mkdir -p /usr/local/redis/logs
[root@cdh1 redis]# mkdir -p /usr/local/redis/cluster
[root@cdh1 redis]# mkdir -p /usr/local/redis/db
[root@cdh1 redis]# chmod 777 /usr/local/redis
复制主节点的 redis集群节点配置文件
scp root@cdh1:/usr/local/redis/cluster/* /usr/local/redis/cluster
redis_7000.conf 100% 707 0.7KB/s 00:00
redis_7001.conf 100% 707 0.7KB/s 00:00
redis_7002.conf 100% 707 0.7KB/s 00:00
启动并且查看日志
启动一个节点:
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/redis_7000.conf
查看日志:
cat /usr/local/redis/logs/redis_7000.log
启动剩余的两个节点
[root@cdh2 cluster]# /usr/local/redis/bin/redis-server /usr/local/redis/cluster/redis_7001.conf
[root@cdh2cluster]# /usr/local/redis/bin/redis-server /usr/local/redis/cluster/redis_7002.conf
[root@cdh2 cluster]# ps aux | grep redis-server
root 871 0.3 0.0 153820 7696 ? Ssl 05:22 0:55 /usr/local/redis/bin/redis-server *:6379
root 5443 0.2 0.0 156892 7700 ? Ssl 09:38 0:00 /usr/local/redis/bin/redis-server *:7000 [cluster]
root 5466 0.2 0.0 153820 7676 ? Ssl 09:43 0:00 /usr/local/redis/bin/redis-server *:7001 [cluster]
root 5471 0.3 0.0 153820 7676 ? Ssl 09:43 0:00 /usr/local/redis/bin/redis-server *:7002 [cluster]
节点握手命令执行
使用下面的命令,和cdh1虚拟机上的节点握手,组成集群:
/usr/local/redis/bin/redis-cli -p 7000 CLUSTER MEET 192.168.56.121 7000
/usr/local/redis/bin/redis-cli -p 7000 CLUSTER MEET 192.168.56.121 7001
/usr/local/redis/bin/redis-cli -p 7000 CLUSTER MEET 192.168.56.121 7002
/usr/local/redis/bin/redis-cli -p 7000 CLUSTER NODES
执行的过程如下:
[root@cdh2 ~]# cat /etc/hosts
127.0.0.1 localhost
192.168.56.121 cdh1
192.168.56.122 cdh2
192.168.56.123 cdh3
[root@cdh2 ~]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER MEET 192.168.56.121 7000
OK
[root@cdh2 ~]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER MEET 192.168.56.121 7001
OK
[root@cdh2 ~]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER MEET 192.168.56.121 7002
OK
[root@cdh2 ~]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER NODES
96f9337a510af4719a5f716aa8598c07e7c64106 192.168.56.121:7000@17000 master - 0 1619253092540 1 connected
f0ca7f905b7581c4005dbd0a490b44bebaed26d2 192.168.56.122:7000@17000 myself,master - 0 1619253093000 5 connected
8d1b4222dc3e4794974bbd6fe3770ede284464ae 127.0.0.1:7002@17002 master - 0 1619253094555 3 connected
44c862cc9bead60c1b2ecac6af434db0ce9b70be 127.0.0.1:7001@17001 master - 0 1619253093547 4 connected
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 192.168.56.121:7001@17001 master - 0 1619253093000 0 connected
1939fff03e1133de208743f71501b6eabef657e8 192.168.56.121:7002@17002 master - 0 1619253092000 2 connected
可以看到6个节点,不够6个都是主节点。
实战:建立主从关系
主从关系的规划,如下:
-
使cdh1:7000端口运行的redis server做为cdh2:7000的master
-
使cdh1:7001端口运行的redis server做为cdh2:7001的master
-
使cdh1:7002端口运行的redis server做为cdh2:7001的master
使用cluster replicate 命令建立主从关系
建立主从关系使用的命令为:
cluster replicate <master_node_id> :将当前从节点设置为 node_id 指定的master节点的slave节点。只能针对slave节点操作。
在cdh2上,执行下面的脚本:
/usr/local/redis/bin/redis-cli -p 7000 cluster replicate 96f9337a510af4719a5f716aa8598c07e7c64106
96f9337a510af4719a5f716aa8598c07e7c64106 为 cdh1上7000节点的node_id
/usr/local/redis/bin/redis-cli -p 7001 cluster replicate f85c768859e88ab86cfb8b0c677d91ef48ac4d2d
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 为 cdh1上7002节点的node_id
/usr/local/redis/bin/redis-cli -p 7002 cluster replicate 1939fff03e1133de208743f71501b6eabef657e8
1939fff03e1133de208743f71501b6eabef657e8 为 cdh1上7002节点的node_id
再一次查看集群节点的元数据
[root@cdh2 ~]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER NODES
96f9337a510af4719a5f716aa8598c07e7c64106 192.168.56.121:7000@17000 master - 0 1619256428503 1 connected
f0ca7f905b7581c4005dbd0a490b44bebaed26d2 127.0.0.1:7000@17000 myself,slave 96f9337a510af4719a5f716aa8598c07e7c64106 0 1619256427000 5 connected
8d1b4222dc3e4794974bbd6fe3770ede284464ae 127.0.0.1:7002@17002 slave 1939fff03e1133de208743f71501b6eabef657e8 0 1619256427000 3 connected
44c862cc9bead60c1b2ecac6af434db0ce9b70be 127.0.0.1:7001@17001 slave f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 0 1619256427496 4 connected
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 192.168.56.121:7001@17001 master - 0 1619256424463 0 connected
1939fff03e1133de208743f71501b6eabef657e8 192.168.56.121:7002@17002 master - 0 1619256428000 2 connected
可以看到,三主三次的集群,已经搭建成功。
这样就完成了一个3主3从的Redis集群搭建。如下图所示:
使用cluster create 创建集群主从节点
/redis-cli --cluster create 192.168.56.121:7000 192.168.56.121:7001 192.168.56.121:7002 192.168.56.122:7000 192.168.56.122:7001 192.168.56.122:7002 --cluster-replicas 1
说明:--cluster-replicas 参数为数字,1表示每个主节点需要1个从节点。
使用 cluster 命令管理集群
Redis Cluster 在5.0之后取消了ruby脚本 redis-trib.rb的支持(手动命令行添加集群的方式不变),集合到redis-cli里,避免了再安装ruby的相关环境。直接使用redis-clit的参数--cluster 来取代。为方便自己后面查询就说明下如何使用该命令进行Cluster的创建和管理,
说明:redis-cli --cluster help
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from <arg> #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
help
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
注意:Redis Cluster最低要求是3个主节点,如果需要集群需要认证,则在最后加入 -a xx 即可。
① 创建集群主节点
redis-cli --cluster create 192.168.163.132:6379 192.168.163.132:6380 192.168.163.132:6381
② 创建集群主从节点
/redis-cli --cluster create 192.168.163.132:6379 192.168.163.132:6380 192.168.163.132:6381 192.168.163.132:6382 192.168.163.132:6383 192.168.163.132:6384 --cluster-replicas 1
说明:--cluster-replicas 参数为数字,1表示每个主节点需要1个从节点。
通过该方式创建的带有从节点的机器不能够自己手动指定主节点,所以如果需要指定的话,需要自己手动指定,先使用①或③创建好主节点后,再通过④来处理。
③ 添加集群主节点
redis-cli --cluster add-node 192.168.163.132:6382 192.168.163.132:6379
说明:为一个指定集群添加节点,需要先连到该集群的任意一个节点IP(192.168.163.132:6379),再把新节点加入。该2个参数的顺序有要求:新加入的节点放前
④ 添加集群从节点
redis-cli --cluster add-node 192.168.163.132:6382 192.168.163.132:6379 --cluster-slave --cluster-master-id 117457eab5071954faab5e81c3170600d5192270
说明:把6382节点加入到6379节点的集群中,并且当做node_id为 117457eab5071954faab5e81c3170600d5192270 的从节点。如果不指定 --cluster-master-id 会随机分配到任意一个主节点。
⑤ 删除节点
redis-cli --cluster del-node 192.168.163.132:6384 f6a6957421b80409106cb36be3c7ba41f3b603ff
说明:指定IP、端口和node_id 来删除一个节点,从节点可以直接删除,有slot分配的主节点不能直接删除。删除之后,该节点会被shutdown。
注意:当被删除掉的节点重新起来之后不能自动加入集群,但其和主的复制还是正常的,也可以通过该节点看到集群信息(通过其他正常节点已经看不到该被del-node节点的信息)。
如果想要再次加入集群,则需要先在该节点执行cluster reset,再用add-node进行添加,进行增量同步复制。
⑥ 检查集群
redis-cli --cluster check 192.168.163.132:6384 --cluster-search-multiple-owners
说明:任意连接一个集群节点,进行集群状态检查
⑦ 集群信息查看
redis-cli --cluster info 192.168.163.132:6384
说明:检查key、slots、从节点个数的分配情况
/redis-cli --cluster info 192.168.163.132:6384
192.168.163.132:6380 (815da844...) -> 0 keys | 5462 slots | 1 slaves.
192.168.163.132:6381 (56005b94...) -> 0 keys | 5461 slots | 1 slaves.
192.168.163.132:6379 (117457ea...) -> 2 keys | 5461 slots | 1 slaves.
[OK] 2 keys in 3 masters.
0.00 keys per slot on average.
⑧ 修复集群
redis-cli --cluster fix 192.168.163.132:6384 --cluster-search-multiple-owners
说明:修复集群和槽的重复分配问题
⑨ 设置集群的超时时间
redis-cli --cluster set-timeout 192.168.163.132:6382 10000
说明:连接到集群的任意一节点来设置集群的超时时间参数cluster-node-timeout
redis-cli --cluster set-timeout 192.168.163.132:6382 10000
>>> Reconfiguring node timeout in every cluster node...
*** New timeout set for 192.168.163.132:6382
*** New timeout set for 192.168.163.132:6384
*** New timeout set for 192.168.163.132:6383
*** New timeout set for 192.168.163.132:6379
*** New timeout set for 192.168.163.132:6381
*** New timeout set for 192.168.163.132:6380
>>> New node timeout set. 6 OK, 0 ERR.
⑩ 集群中执行相关命令
redis-cli --cluster call 192.168.163.132:6381 config set requirepass cc
redis-cli -a cc --cluster call 192.168.163.132:6381 config set masterauth cc
redis-cli -a cc --cluster call 192.168.163.132:6381 config rewrite
说明:连接到集群的任意一节点来对整个集群的所有节点进行设置。
redis-cli --cluster call 192.168.163.132:6381 config set cluster-node-timeout 12000
>>> Calling config set cluster-node-timeout 12000
192.168.163.132:6381: OK
192.168.163.132:6383: OK
192.168.163.132:6379: OK
192.168.163.132:6384: OK
192.168.163.132:6382: OK
192.168.163.132:6380: OK......
到此,相关集群的基本操作已经介绍完,现在说明集群迁移的相关操作。
Redis 6.0 新增了几个命令:
1,fix 的子命令:--cluster-fix-with-unreachable-masters
2,call的子命令:--cluster-only-masters、--cluster-only-replicas
3,集群节点备份:backup
迁移相关
① 在线迁移slot :
在线把集群的一些slot从集群原来slot节点迁移到新的节点,即可以完成集群的在线横向扩容和缩容。有2种方式进行迁移
一是根据提示来进行操作:
直接连接到集群的任意一节点
redis-cli -a cc --cluster reshard 192.168.163.132:6379
二是根据参数进行操作:
redis-cli -a cc --cluster reshard 192.168.163.132:6379 --cluster-from 117457eab5071954faab5e81c3170600d5192270 --cluster-to 815da8448f5d5a304df0353ca10d8f9b77016b28 --cluster-slots 10 --cluster-yes --cluster-timeout 5000 --cluster-pipeline 10 --cluster-replace
说明:连接到集群的任意一节点来对指定节点指定数量的slot进行迁移到指定的节点。
② 平衡(rebalance)slot :
1)平衡集群中各个节点的slot数量
redis-cli -a cc --cluster rebalance 192.168.163.132:6379
2)根据集群中各个节点设置的权重等平衡slot数量(不执行,只模拟)
redis-cli -a cc --cluster rebalance --cluster-weight 117457eab5071954faab5e81c3170600d5192270=5 815da8448f5d5a304df0353ca10d8f9b77016b28=4 56005b9413cbf225783906307a2631109e753f8f=3 --cluster-simulate 192.168.163.132:6379
③ 导入集群
redis-cli --cluster import 192.168.163.132:6379 --cluster-from 192.168.163.132:9021 --cluster-replace
说明:外部Redis实例(9021)导入到集群中的任意一节点。
注意:测试下来发现参数--cluster-replace没有用,如果集群中已经包含了某个key,在导入的时候会失败,不会覆盖,只有清空集群key才能导入。
*** Importing 97847 keys from DB 0
Migrating 9223372011174675807 to 192.168.163.132:6381: Source 192.168.163.132:9021 replied with error:
ERR Target instance replied with error: BUSYKEY Target key name already exists
并且发现如果集群设置了密码,也会导入失败,需要设置集群密码为空才能进行导入(call)。通过monitor(9021)的时候发现,在migrate的时候需要密码进行auth认证。
总结:
Redis Cluster 通过redis-cli --cluster来创建和管理集群的方式和 **redis-trib.rb**脚本绝大部分都是一样的,所以对于比较熟悉 redis-trib.rb 脚本的,使用--cluster也非常顺手。
数据分片原理
为什么要做数据分片(或者分区)
全量数据,单机Redis节点无法满足要求,按照分区规则把数据分片到若干个数据子集(片段)当中

常用数据分片方式
顺序分布
比如:1到100个数字,要保存在3个节点上,按照顺序分区,把数据平均分配成三个片段
-
1号到33号数据为 片段1
-
34号到66号数据为 片段2
-
67号到100号数据为 片段3

顺序分区常用在关系型数据库的设计
哈希分片
例如1到100个数字,对每个数字进行哈希运算,然后对每个数的哈希结果除以节点数进行取余,余数为1则保存在第1个节点上,余数为2则保存在第2个节点上,余数为0则保存在第3个节点,这样可以保证数据被打散,同时保证数据分布的比较均匀

哈希分布方式分为三个分区方式:
-
节点取余分区
-
一致性哈希分区
-
虚拟槽分区
哈希分片1:节点取余分片
数据哈希值进行节点取余方式是非常简单的一种分区方式
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上

节点取余分区方式有一个问题:
即当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分片。
所以,节点取余分区方式在扩容时:
建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。
数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据

节点取余方式优点:
客户端分片
配置简单:对数据进行哈希,然后取余
节点取余方式缺点:
数据节点伸缩时,导致数据迁移
迁移数量和添加节点数据有关,建议翻倍扩容
哈希分片2:一致性哈希分区
一致性哈希算法基本原理大致可以通过几个步骤来解释:构造一致性哈希环、节点映射、路由规则。
1)构造一致性哈希环
一致性哈希算法中首先有一个哈希函数,哈希函数产生hash值,所有可能的哈希值构成一个哈希空间,哈希空间为[0,232-1],这本来是一个“线性”的空间,但是在算法中通过恰当逻辑控制,使其首尾相衔接,也即是0=232,这样就构造一个逻辑上的环形空间。
2)节点映射
将集群中的各节点映射到环上的某个一位置。比如集群中有三个节点,那么可以大致均匀的将其分布在环上。
3)路由规则
路由规则包括存储(setX)和取值(getX)规则。
当需要存储一个
将所有的数据当做一个token环,token环中的数据范围是0到2的32次方。
然后为每一个数据节点(服务节点),分配一个token范围值,这个节点就负责保存这个范围内的数据。

对每一个key,进行hash运算,被哈希后的结果在哪个token的范围内,则按顺时针去找最近的节点,这个key将会被保存在这个节点上。


在上面的图中:
有4个key被hash之后的值在在n1节点和n2节点之间,按照顺时针规则,这4个key都会被保存在n2节点上
如果发生节点的添加,比如在n1节点和n2节点之间添加n5节点,当下次有key被hash之后的值在n1节点和n5节点之间,这些key就会被保存在n5节点上面了
在上面的例子里:
添加n5节点之后,数据迁移会在n1节点和n2节点之间进行,n3节点和n4节点不受影响,数据迁移范围被缩小很多。节点伸缩时,只影响邻近节点。
节点伸缩时,只影响邻近节点。
同理,如果有1000个节点,此时添加一个节点,受影响的节点范围最多只有千分之2
一致性哈希分区优点:
- 采用客户端分片方式:哈希 + 顺时针(优化取余)
- 节点伸缩时,只影响邻近节点,但是还是有数据迁移
- 一致性哈希一般用在节点比较多的时候
一致性哈希分区缺点:
假设:集群中有三个节点(Node1、Node2、Node3),五个键(key1、key2、key3、key4、key5),其路由规则为:
key1 -> Node1
key2、key3 -> Node2
key4、key5 -> Node3

不难发现,基本的一致性哈希算法有一些地方不太让人满意。
当集群中增加节点时,比如当在Node2和Node3之间增加了一个节点Node4,此时再访问节点key4时,不能在Node4中命中,也就是说,介于Node2和Node4之间的key均失效,这样的失效方式太过于“集中”和“暴力”。
如下图所示:

特别是当集群中节点本身比较少时,因增删节点导致的不命中现象比较明显。
问题:增删一个节点后,如何保障key的失效更加的“平滑”和“分散”。
第二个问题:新节点不能对其他的节点有负载的分担
除了上面的问题,还有一个比较明显的问题是负载问题:
增加节点只能对下一个相邻节点有比较好的负载分担效果,不能对其他的节点有负载的分担。
例如上图中增加了节点Node4只能够对Node3分担部分负载,对集群中其他的节点基本没有起到负载分担的效果;类似地,删除节点会导致下一个相邻节点负载增加,而其他节点却不能有效分担负载压力。
针对以上两个主要的问题,特别是如何解决各节点负载动态均衡的问题,出现了一种通过增加虚拟槽分区的改进算法。
第三个问题:一致性哈希的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题。比如只有 2 台机器,这 2 台机器离的很近,那么顺时针第一个机器节点上将存在大量的数据,第二个机器节点上数据会很少。
哈希分片3:虚拟槽分区
虚拟节点解决数据倾斜问题
为了在增删节点的时候,各节点能够保持动态的均衡,将每个真实节点虚拟出若干个虚拟节点,再将这些虚拟节点随机映射到环上。此时每个真实节点不再映射到环上,真实节点只是用来存储键值对,它负责接应各自的一组环上虚拟节点。当对键值对进行存取路由时,首先路由到虚拟节点上,再由虚拟节点找到真实的节点。
如下图所示,三个节点真实节点:Node1、Node2和Node3,每个真实节点虚拟出三个虚拟节点:X#V1、X#V2和X#V3。如下图所示:

优点:
这样每个真实节点所负责的hash空间不再是连续的一段,而是分散在环上的各处,这样就可以将局部的压力均衡到不同的节点,虚拟节点越多,分散性越好,理论上负载就越倾向均匀,
通俗的理解,增加虚拟节点其实是减小了路由规则过程中的粒度,使每个真实节点可以分摊局部压力。
Redis Cluster采用的分区方式
Redis 集群与虚拟节点一致性哈希的区别;
-
Redis 集群并没有直接使用一致性哈希,而是使用了哈希槽 (slot)的概念.
-
Redis 没有直接使用哈希算法 hash(),而是使用了crc16校验算法。
槽位其实就是一个个的空间的单位。其实哈希槽的本质和一致性哈希算法非常相似,不同点就是对于哈希空间的定义。
一致性哈希的空间是一个圆环,节点分布是基于圆环的,无法很好的控制数据分布,可能会产生数据倾斜问题。
而 Redis 的槽位空间是自定义分配的,类似于Windows盘分区的概念。这种分区是可以自定义大小,自定义位置的。
Redis 集群包含了 16384 个哈希槽,每个 Key 经过计算后会落在一个具体的槽位上,而槽位具体在哪个机器上是用户自己根据自己机器的情况配置的,机器硬盘小的可以分配少一点槽位,硬盘大的可以分配多一点。如果节点硬盘都差不多则可以平均分配。所以哈希槽这种概念很好地解决了一致性哈希的弊端。
另外在容错性和扩展性上与一致性哈希一样,都是对受影响的数据进行转移而不影响其它的数据。而哈希槽本质上是对槽位的转移,把故障节点负责的槽位转移到其他正常的节点上。扩展节点也是一样,把其他节点上的槽位转移到新的节点上。
需要注意的是,对于槽位的转移和分派,Redis集群是不会自动进行的,而是需要人工配置的。所以Redis集群的高可用是依赖于节点的主从复制与主从间的自动故障转移。

Redis Cluster虚拟槽分片
Redis Cluster采用的分区方式——虚拟槽分片
Redis Cluster采用虚拟槽分区,所有的键根据哈希函数映射到0 ~ 16383,计算公式:slot = CRC16(key)&16383。每一个节点负责维护一部分槽以及槽所映射的键值数据。
预设虚拟槽,每个槽映射一个数据子集,Redis Cluster中预设虚拟槽的范围为0到16383

步骤:
1.把16384槽按照节点数量进行平均分配,由节点进行管理
2.对每个key按照CRC16规则进行hash运算
3.把hash结果对16383进行取余
4.把余数发送给Redis节点
5.节点接收到数据,验证是否在自己管理的槽编号的范围
如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
虚拟槽分区特点:
使用服务端管理节点,槽,数据:例如Redis Cluster
可以对数据打散,又可以保证数据分布均匀
虚拟槽分片举例
下图展现一个三个节点构成的集群,每个节点平均大约负责5462个槽,以及通过计算公式映射到对应节点的对应槽的过程。

下图展现一个五个节点构成的集群,每个节点平均大约负责3276个槽,以及通过计算公式映射到对应节点的对应槽的过程。
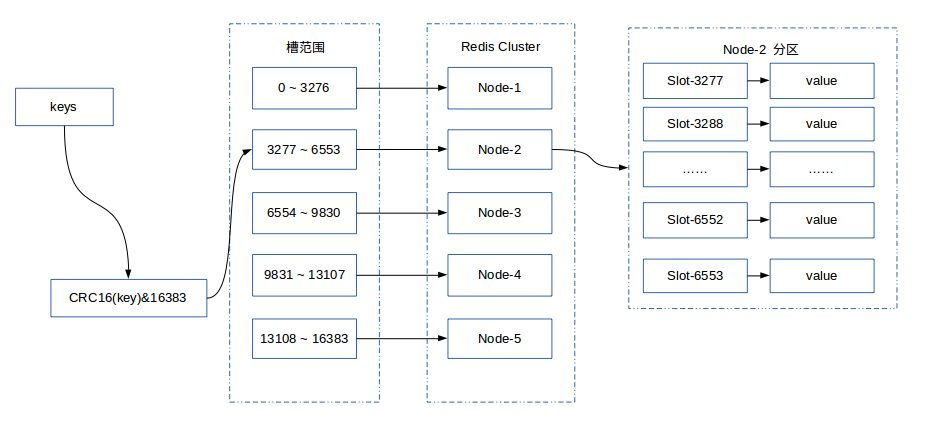
Redis虚拟槽分区的特定:
- 解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。
- 支持节点、槽、键之间的映射查询,用于数据路由、在线伸缩等场景。
顺序分片与哈希分片的对比

实战:Redis Cluster虚拟槽
理论性的知识介绍完了,下面开始Redis Cluster虚拟槽实战。
Redis Cluster虚拟槽有关的命令
cluster addslots
cluster delslots
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot
另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot
cluster setslot
cluster setslot
查看slot个数
可以看一下7000端口的槽个数
/usr/local/redis/bin/redis-cli -p 7000 CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:0 // 被分配槽的个数为0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:479
cluster_stats_messages_received:479
为节点分配槽空间
接下来为节点分配槽空间。
槽位空间可以手工的规划和分配,例如:
- {0..5461} 分配给 7000节点
- {5462..10922}分配给 7001节点
- {10923..16383} 分配给 7002节点
具体如下图:
在主节点(这里是cdh1)上,通过cluster addslots命令进行槽位分配:
/usr/local/redis/bin/redis-cli -h 127.0.0.1 -p 7000 cluster addslots {0..5461}
OK
/usr/local/redis/bin/redis-cli -h 127.0.0.1 -p 7001 cluster addslots {5462..10922}
OK
/usr/local/redis/bin/redis-cli -h 127.0.0.1 -p 7002 cluster addslots {10923..16383}
OK
通过从节点查看slot信息
我们将16383个槽平均分配给7000、7001、7002端口的节点。
在从节点上,可以再次看一下7000端口的槽个数:
/usr/local/redis/bin/redis-cli -p 7000 CLUSTER INFO
cluster_state:ok // 集群状态OK
cluster_slots_assigned:16384 // 已经分配了所有的槽
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:1212
cluster_stats_messages_received:1212
在从节点上,可以通过CLUSTER NODES来查看分配情况:
[root@cdh2 ~]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER NODES
96f9337a510af4719a5f716aa8598c07e7c64106 192.168.56.121:7000@17000 master - 0 1619258203310 1 connected 0-5461
f0ca7f905b7581c4005dbd0a490b44bebaed26d2 192.168.56.122:7000@17000 myself,slave 96f9337a510af4719a5f716aa8598c07e7c64106 0 1619258203000 5 connected
8d1b4222dc3e4794974bbd6fe3770ede284464ae 127.0.0.1:7002@17002 slave 1939fff03e1133de208743f71501b6eabef657e8 0 1619258204000 3 connected
44c862cc9bead60c1b2ecac6af434db0ce9b70be 127.0.0.1:7001@17001 slave f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 0 1619258205343 4 connected
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 192.168.56.121:7001@17001 master - 0 1619258206356 0 connected 5462-10922
1939fff03e1133de208743f71501b6eabef657e8 192.168.56.121:7002@17002 master - 0 1619258205000 2 connected 10923-16383
作为一个完整的集群,每个负责处理槽的节点应该具有从节点,保证当主节点出现故障时,可以自动进行故障转移。从节点负责复制主节点槽的信息和相关数据。
动态扩容
今天就写到这里了,做一个小小的总结。主从复制和哨兵模式这两个集群模式由于不能动态扩容,而且主节点之间(有多个主节点的情况)数据完全一样,导致了主节点的容量成了整个集群的瓶颈,如果想扩展集群容量,必须扩展主节点的容量。
由于以上的问题,redis在3.0开始Cluster集群模式,这个模式在主节点之间数据是不一样的,数据也可以根据需求自动转向其他节点。这样就可以实现横向动态扩容,新增加的主从节点,用于存储新的数据则可,对以前的节点的数据不会有任何影响。再者说,配置也很简单,这才是我们所需要的集群模式。
Redis提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以对下线节点进行缩容。
注意:集群内部的通信端口,为客户端通信端口+10000
实战提前:搭建了Redis的Cluster集群环境
前面的内容,我们一步一步的教大家搭建了Redis的Cluster集群环境,形成了3个主节点和3个从节点的Cluster的环境。当然,大家可以使用 Cluster info 命令查看Cluster集群的状态,也可以使用Cluster Nodes 命令来详细了解Cluster集群每个节点的详细信息和关系。我们可以在主节点上增加数据、操作数据,也可以在从节点上读取数据,这些操作当然都没有问题。
对应的主节点负责的槽位信息,如下图所示:
接下来,主要是讲解一下如何在不停掉Cluster集群环境的情况下,动态的往集群环境中增加主、从节点和动态的从集群环境中删除节点。
redis-trib.rb脚本
先要说明一下,redis 5.0 之前的版本,动态扩容操作都是通过redis-trib.rb脚本文件来完成的,所以我们先需要安装好ruby和gem,具体请参见后面的内容。
在看看对这个脚本文件的说明,效果如图:
[root@linux redis] # ruby redis-trib.rb

使用 cluster add-node 命令增加节点
redis 5.0 之后的版本,使用cluster add-node增加节点。
③ 添加集群主节点
redis-cli --cluster add-node 192.168.163.132:6382 192.168.163.132:6379
说明:为一个指定集群添加节点,需要先连到该集群的任意一个节点IP(192.168.163.132:6379),再把新节点加入。该2个参数的顺序有要求:新加入的节点放前
④ 添加集群从节点
redis-cli --cluster add-node 192.168.163.132:6382 192.168.163.132:6379 --cluster-slave --cluster-master-id 117457eab5071954faab5e81c3170600d5192270
说明:把6382节点加入到6379节点的集群中,并且当做node_id为 117457eab5071954faab5e81c3170600d5192270 的从节点。如果不指定 --cluster-master-id 会随机分配到任意一个主节点。
扩容步骤
扩容集群是分布式存储最常见的需求,Redis集群扩容可以分为如下步骤:
- 准备新节点
- 加入集群
- 迁移槽和数据
准备新节点
现在正好开始我们的操作,我把增加节点和删除节点分开来写,并且增加或者删除节点,我都分了两个方面来说,一个方面是主节点的操作,另一个方面是从节点的操作,因为主、从节点在操作上会有差异,所以分来来说。增加节点的顺序是先增加Master主节点,然后在增加Slave从节点。
总的工作:
在cdh1 和cdh2 上,分别准备和启动一个节点,端口为 7003.
1.在cdh1 和cdh2 上,复制一份配置文件,名称为 redis_7003.conf
[root@cdh1 cluster]# sed 's/7000/7003/g' redis_7000.conf > redis_7003.conf
2.在cdh1 和cdh2 上,启动 redis_7003.conf的节点
[root@cdh1 cluster]# /usr/local/redis/bin/redis-server /usr/local/redis/cluster/redis_7003.conf
启动两个节点,启动后的新节点会作为孤儿节点运行,没有和其他节点与之通信。
3.查看一下,7003节点是否启动
[root@cdh1 cluster]# ps aux | grep redis-server
root 871 0.2 0.0 153820 7696 ? Ssl Apr23 4:36 /usr/local/redis/bin/redis-server *:6379
root 7113 0.3 0.1 156892 10044 ? Ssl 07:51 2:34 /usr/local/redis/bin/redis-server *:7001 [cluster]
root 7126 0.3 0.1 156892 9920 ? Ssl 07:52 2:33 /usr/local/redis/bin/redis-server *:7002 [cluster]
root 7134 0.3 0.1 164572 10124 ? Ssl 07:52 2:33 /usr/local/redis/bin/redis-server *:7000 [cluster]
root 29774 0.3 0.0 153820 7676 ? Ssl 21:49 0:00 /usr/local/redis/bin/redis-server *:7003 [cluster]
主节点加入集群
我们可以通过cluster add-node 命令将7003 节点加入到集群中。
/usr/local/redis/bin/redis-cli --cluster add-node 127.0.0.1:7003 127.0.0.1:7000
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli --cluster add-node 127.0.0.1:7003 127.0.0.1:7000
>>> Adding node 127.0.0.1:7003 to cluster 127.0.0.1:7000
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: 96f9337a510af4719a5f716aa8598c07e7c64106 127.0.0.1:7000
slots:[0-5461] (5462 slots) master
1 additional replica(s)
M: 1939fff03e1133de208743f71501b6eabef657e8 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 8d1b4222dc3e4794974bbd6fe3770ede284464ae 192.168.56.122:7002
slots: (0 slots) slave
replicates 1939fff03e1133de208743f71501b6eabef657e8
S: f0ca7f905b7581c4005dbd0a490b44bebaed26d2 192.168.56.122:7000
slots: (0 slots) slave
replicates 96f9337a510af4719a5f716aa8598c07e7c64106
S: 44c862cc9bead60c1b2ecac6af434db0ce9b70be 192.168.56.122:7001
slots: (0 slots) slave
replicates f85c768859e88ab86cfb8b0c677d91ef48ac4d2d
M: f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 127.0.0.1:7001
slots:[5462-10922] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 127.0.0.1:7003 to make it join the cluster.
[OK] New node added correctly.
查看节点的信息
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER NODES
f6cf78c46aef3264d8e4956fae7e7b409c671d42 127.0.0.1:7003@17003 master - 0 1619272465000 6 connected
1939fff03e1133de208743f71501b6eabef657e8 127.0.0.1:7002@17002 master - 0 1619272463873 2 connected 10923-16383
8d1b4222dc3e4794974bbd6fe3770ede284464ae 192.168.56.122:7002@17002 slave 1939fff03e1133de208743f71501b6eabef657e8 0 1619272464879 3 connected
96f9337a510af4719a5f716aa8598c07e7c64106 127.0.0.1:7000@17000 myself,master - 0 1619272465000 1 connected 0-5461
f0ca7f905b7581c4005dbd0a490b44bebaed26d2 192.168.56.122:7000@17000 slave 96f9337a510af4719a5f716aa8598c07e7c64106 0 1619272464000 5 connected
44c862cc9bead60c1b2ecac6af434db0ce9b70be 192.168.56.122:7001@17001 slave f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 0 1619272465886 4 connected
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 127.0.0.1:7001@17001 master - 0 1619272464000 0 connected 5462-10922
新加入的节点都是主节点,因为没有负责槽位,所以不能接受任何读写操作
对于新加入的节点,我们可以有两个操作:
- 为新节点迁移槽和数据实现扩容。
- 作为其他主节点的从节点负责故障转移。
迁移槽位和数据
使用reshard 进行数据的迁移:
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli --cluster reshard 127.0.0.1:7000
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: 96f9337a510af4719a5f716aa8598c07e7c64106 127.0.0.1:7000
slots:[0-5461] (5462 slots) master
1 additional replica(s)
M: f6cf78c46aef3264d8e4956fae7e7b409c671d42 127.0.0.1:7003
slots: (0 slots) master
M: 1939fff03e1133de208743f71501b6eabef657e8 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 8d1b4222dc3e4794974bbd6fe3770ede284464ae 192.168.56.122:7002
slots: (0 slots) slave
replicates 1939fff03e1133de208743f71501b6eabef657e8
S: f0ca7f905b7581c4005dbd0a490b44bebaed26d2 192.168.56.122:7000
slots: (0 slots) slave
replicates 96f9337a510af4719a5f716aa8598c07e7c64106
S: 44c862cc9bead60c1b2ecac6af434db0ce9b70be 192.168.56.122:7001
slots: (0 slots) slave
replicates f85c768859e88ab86cfb8b0c677d91ef48ac4d2d
M: f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 127.0.0.1:7001
slots:[5462-10922] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4000
What is the receiving node ID? f6cf78c46aef3264d8e4956fae7e7b409c671d42
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 96f9337a510af4719a5f716aa8598c07e7c64106
Source node #2: done
Ready to move 4000 slots.
Source nodes:
M: 96f9337a510af4719a5f716aa8598c07e7c64106 127.0.0.1:7000
slots:[0-5461] (5462 slots) master
1 additional replica(s)
Destination node:
M: f6cf78c46aef3264d8e4956fae7e7b409c671d42 127.0.0.1:7003
slots: (0 slots) master
Resharding plan:
Moving slot 0 from 96f9337a510af4719a5f716aa8598c07e7c64106
Moving slot 1 from 96f9337a510af4719a5f716aa8598c07e7c64106
Moving slot 2 from 96f9337a510af4719a5f716aa8598c07e7c64106
Moving slot 3 from 96f9337a510af4719a5f716aa8598c07e7c64106
Moving slot 4 from 96f9337a510af4719a5f716aa8598c07e7c64106
....
输入要分配的槽数量
How many slots do you want to move (from 1 to 16384)? 4000
输入接收槽的结点id
通过cluster nodes 查看新增的7003 的id为f6cf78c46aef3264d8e4956fae7e7b409c671d42
What is the receiving node ID? f6cf78c46aef3264d8e4956fae7e7b409c671d42
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
输入 96f9337a510af4719a5f716aa8598c07e7c64106
然后输入输入done确认
最后输入yes开始移动数据
Moving slot 3990 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3991 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3992 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3993 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3994 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3995 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3996 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3997 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3998 from 127.0.0.1:7000 to 127.0.0.1:7003:
Moving slot 3999 from 127.0.0.1:7000 to 127.0.0.1:7003:
此时再通过cluster nodes查看节点,可以看到新节点分配的槽为0-3999 4000-5461 5462-10922 10923-12255
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER NODES
f6cf78c46aef3264d8e4956fae7e7b409c671d42 127.0.0.1:7003@17003 master - 0 1619273811000 6 connected 0-3999
1939fff03e1133de208743f71501b6eabef657e8 127.0.0.1:7002@17002 master - 0 1619273812947 2 connected 10923-16383
8d1b4222dc3e4794974bbd6fe3770ede284464ae 192.168.56.122:7002@17002 slave 1939fff03e1133de208743f71501b6eabef657e8 0 1619273810000 3 connected
96f9337a510af4719a5f716aa8598c07e7c64106 127.0.0.1:7000@17000 myself,master - 0 1619273812000 1 connected 4000-5461
f0ca7f905b7581c4005dbd0a490b44bebaed26d2 192.168.56.122:7000@17000 slave 96f9337a510af4719a5f716aa8598c07e7c64106 0 1619273811938 5 connected
44c862cc9bead60c1b2ecac6af434db0ce9b70be 192.168.56.122:7001@17001 slave f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 0 1619273810927 4 connected
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 127.0.0.1:7001@17001 master - 0 1619273811000 0 connected 5462-10922
给新节点添加从节点
给cdh2:7003作为从节点,添加给cdh1:7003
/usr/local/redis/bin/redis-cli --cluster add-node 192.168.56.122:7003 192.168.56.122:7000 --cluster-slave --cluster-master-id 96f9337a510af4719a5f716aa8598c07e7c64106
到此就完成了集群的扩容。
[root@cdh1 cluster]# /usr/local/redis/bin/redis-cli -p 7000 CLUSTER NODES f6cf78c46aef3264d8e4956fae7e7b409c671d42 127.0.0.1:7003@17003 master - 0 1619274323000 6 connected 0-3999
1939fff03e1133de208743f71501b6eabef657e8 127.0.0.1:7002@17002 master - 0 1619274323582 2 connected 10923-16383
8d1b4222dc3e4794974bbd6fe3770ede284464ae 192.168.56.122:7002@17002 slave 1939fff03e1133de208743f71501b6eabef657e8 0 1619274324000 3 connected
96f9337a510af4719a5f716aa8598c07e7c64106 192.168.56.121:7000@17000 myself,master - 0 1619274321000 1 connected 4000-5461
f0ca7f905b7581c4005dbd0a490b44bebaed26d2 192.168.56.122:7000@17000 slave 96f9337a510af4719a5f716aa8598c07e7c64106 0 1619274324591 5 connected
c5dbe51782abf7ccb952b437c55c78f2c7f7a55c 192.168.56.122:7003@17003 slave f6cf78c46aef3264d8e4956fae7e7b409c671d42 0 1619274322572 6 connected
44c862cc9bead60c1b2ecac6af434db0ce9b70be 192.168.56.122:7001@17001 slave f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 0 1619274320000 4 connected
f85c768859e88ab86cfb8b0c677d91ef48ac4d2d 127.0.0.1:7001@17001 master - 0 1619274321000 0 connected 5462-10922
集群关系如下图所示:
收缩集群
收缩集群以为着缩减规模,需要从集群中安全下线部分节点。需要考虑两种情况:
- 确定下线的节点是否有负责槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个槽节点映射的完整性。
- 当下线节点不在负责槽或着本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有节点忘记该节点后就可以正常关闭。
删除节点
删除节点的指令为:
redis-cli --cluster del-node 192.168.163.132:6384 f6a6957421b80409106cb36be3c7ba41f3b603ff
说明:指定IP、端口和node_id 来删除一个节点,从节点可以直接删除,有slot分配的主节点不能直接删除。删除之后,该节点会被shutdown。
注意:当被删除掉的节点重新起来之后不能自动加入集群,但其和主的复制还是正常的,也可以通过该节点看到集群信息(通过其他正常节点已经看不到该被del-node节点的信息)。
如果想要再次加入集群,则需要先在该节点执行cluster reset,再用add-node进行添加,进行增量同步复制。
迁移槽位和数据
使用reshard 进行数据的迁移,具体的命令为:
在线把集群的一些slot从集群原来slot节点迁移到新的节点,即可以完成集群的在线横向扩容和缩容。有2种方式进行迁移
一是根据提示来进行操作:
直接连接到集群的任意一节点
redis-cli -a cc --cluster reshard 192.168.163.132:6379
二是根据参数进行操作:
redis-cli -a cc --cluster reshard 192.168.163.132:6379 --cluster-from 117457eab5071954faab5e81c3170600d5192270 --cluster-to 815da8448f5d5a304df0353ca10d8f9b77016b28 --cluster-slots 10 --cluster-yes --cluster-timeout 5000 --cluster-pipeline 10 --cluster-replace
说明:连接到集群的任意一节点来对指定节点指定数量的slot进行迁移到指定的节点。
RedisCluster的几个要点和问题
Redis集群和Docker
目前,Redis群集不支持NAT地址环境,并且在IP地址或TCP端口被重新映射的一般环境中。
Docker使用一种叫做端口映射的技术:Docker容器中运行的程序可能会暴露在与程序认为使用的端口不同的端口上。这对于在同一服务器中同时使用相同端口运行多个容器很有用。
为了使Docker与RedisCluster兼容,您需要使用Docker的主机联网模式。请查看Docker文档中的--net=host选项以获取更多信息。
Redis集群数据分片
Redis集群没有使用一致的散列,而是一种不同的分片形式,其中每个key在概念上都是我们称之为散列槽的部分。
Redis集群中有16384个散列槽,为了计算给定key的散列槽,我们简单地取16384模的CRC16。
Redis集群中的每个节点负责哈希槽的一个子集,例如,您可能有一个具有3个节点的集群,其中:
1、节点A包含从0到5500的散列槽。
2、节点B包含从5501到11000的散列槽。
3、节点C包含从11001到16383的散列槽。
这允许轻松地添加和删除集群中的节点。例如,如果我想添加一个新节点D,我需要将节点A,B,C中的一些散列槽移动到D。同样,如果我想从集群中删除节点A,我可以只移动由A使用的散列槽到B和C,当节点A将为空时,我可以将它从群集中彻底删除。
因为将散列槽从一个节点移动到另一个节点不需要停机操作,添加和移除节点或更改节点占用的散列槽的百分比也不需要任何停机时间。
只要涉及单个命令执行(或整个事务或Lua脚本执行)的所有key都属于同一散列插槽,Redis群集就支持多个key操作。用户可以使用称为散列标签的概念强制多个key成为同一个散列槽的一部分。
Hash标记记录在Redis集群规范文档中,但要点是如果在关键字{}括号内有一个子字符串,那么只有该花括号“{}”内部的内容被散列,例如this{foo}key和another{foo}key保证在同一散列槽中,并且可以在具有多个key作为参数的命令中一起使用。
Redis集群之主从模型
为了在主服务器节点的子集失败或不能与大多数节点通信时保持可用,Redis集群使用主从模型,其中每个散列槽从1(主服务器本身)到N个副本(N-1个附加从节点)。
在我们具有节点A,B,C的示例的群集中,如果节点B失败,则群集无法继续,因为我们没有办法再在5501-11000范围内提供散列槽。然而,当创建集群时(或稍后),我们为每个主服务器节点添加一个从服务器节点,以便最终集群由作为主服务器节点的A,B,C以及作为从服务器节点的A1,B1,C1组成,如果节点B发生故障,系统能够继续运行。节点B1复制B,并且B失败,则集群将促使节点B1作为新的主服务器节点并且将继续正确地操作。
但请注意,如果节点B和B1在同一时间发生故障,则Redis群集无法继续运行。
Redis集群一致性保证
Redis集群无法保证很强的一致性。实际上,这意味着在某些情况下,Redis集群可能会丢失系统向客户确认的写入。
异步复制可能会丢失写入
Redis集群可能会丢失写入的第一个原因是因为它使用异步复制。这意味着在写入期间会发生以下事情:
1、你的客户端写给主服务器节点B
2、主服务器节点B向您的客户端回复确认。
3、主服务器节点B将写入传播到它的从服务器B1,B2和B3。
正如你可以看到主服务器节点B在回复客户端之前不等待B1,B2,B3的确认,因为这会对Redis造成严重的延迟损失,所以如果你的客户端写入了某些东西,主服务器节点B确认写入,就在将写入发送给它的从服务器节点存储之前系统崩溃了,其中一个从站(没有收到写入)可以提升为主站,永远丢失写入。
这与大多数配置为每秒将数据刷新到磁盘的数据库所发生的情况非常相似,因为过去的经验与传统数据库系统有关,不会涉及分布式系统,因此您已经能够推断这种情况。同样,通过强制数据库在回复客户端之前刷新磁盘上的数据,这样可以提高一致性,但这通常会导致性能极低。这与RedisCluster中的同步复制相当。
基本上,性能和一致性之间需要权衡。
Redis集群在绝对需要时也支持同步写入,通过WAIT命令实现,这使得丢失写入的可能性大大降低,但请注意,即使使用同步复制,Redis集群也不可能实现完全的一致性:总是有可能会发生故常,在无法接受写入的从设备被选为主设备的时候。
网络分区的时候丢失数据的写入
还有另一个值得注意的情况,Redis集群也可能丢失数据的写入,这种情况发生在网络分区的时候,客户端与包含至少一个主服务器的少数实例隔离。
以A,B,C,A1,B1,C1三个主站和三个从站组成的6个节点集群为例。还有一个客户,我们会调用Z1。
分区发生后,可能在分区的一侧有A,C,A1,B1,C1,另一侧有B和Z1。
Z1仍然能够写入B,它也会接受Z1的写入。如果分区在很短的时间内恢复,则群集将正常继续。但是,如果分区使用比较长的时间将B1提升为多数侧分区的主设备,则Z1发送给B的写入操作将丢失。
请注意,Z1能够发送给B的写入量有一个最大窗口(maximumwindow):如果分区多数侧有足够的时间选择一个从设备作为主设备,那么少数侧的每个主节点将停止接受写操作。
这个时间值是Redis集群非常重要的配置指令,称为nodetimeout(节点超时)。
在节点超时过后,主节点被认为是失效的,并且可以被其副本之一替换。类似地,节点超时过后,主节点无法感知大多数其他主节点,它进入错误状态并停止接受写入。
参考文档:
图书:《Netty Zookeeper Redis 高并发实战》 图书简介 - 疯狂创...
基于Zookeeper 的分布式锁实现 - SegmentFault 思否
ZooKeeper分布式锁的实现原理 - 菜鸟奋斗史 - 博客园
https://blog.csdn.net/men_wen/article/details/72853078
问题交流:疯狂创客圈社群


 浙公网安备 33010602011771号
浙公网安备 33010602011771号