Reactor3 中文文档(用户手册)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Reactor 3 参考文档
Stephane Maldini @smaldini Simon Baslé @simonbasle3.2.0.BUILD-SNAPSHOT
(译者加)本文档的一些典型的名词如下:Publisher(发布者)、Subscriber(订阅者)、Subscription(订阅 n.)、subscribe(订阅 v.)。event/signal(事件/信号,原文常甚至在一个句子将两个词来回用,但表示的意思是基本相同的, 因此如果你看到本文翻译有时候用事件,有时候用信号,在本文档内基本可以认为一个意思)。sequence/stream(序列/流,两个词意思相似,本文介绍的是响应式流的内容,但是出现比较多的是 sequence这个词,主要翻译为“序列”,有些地方为了更加契合且方便理解翻译为“流序列”)。element/item(主要指序列中的元素,文中两个词基本翻译为“元素”)。emit/produce/generate(发出/产生/生成,文中这三个英文词也有相似之处,对于 emit 多翻译为 “发出”,对于后两个多翻译为“生成”)、consume(消费)。Processor(未做翻译,保留英文)。operator(译作操作符,声明式的可组装的响应式方法,其组装成的链译作“操作链”)。 |
|
|---|---|
1. 关于本文档
本节是对 Reactor参考文档(译者加:原文估计是多个人写的,时而“document”时而“guide”,不影响理解的情况下, 翻译就一律用“文档”了) 的简要概述。你并不需要从头到尾阅读该文档。每一节的内容都是独立的,不过会有其他章节的链接。
1.1. 最新版本 & 版权说明
本Reactor参考文档也提供HTML形式。最新版本见 http://projectreactor.io/docs/core/release/reference/docs/index.html。
本文档的副本你可以自用,亦可分发给他人。不过无论是打印版还是电子版,请免费提供。
1.2. 贡献本文档
本参考文档用 Asciidoc 编写, 其源码见 https://github.com/reactor/reactor-core/tree/master/src/docs/asciidoc (译者加:本翻译源码见 https://github.com/get-set/reactor-core/tree/master-zh/src/docs/asciidoc )。
如有任何补充,欢迎你提交 pull request。
我们建议你将源码 checkout 到本地,这样可以使用 gradle 的 asciidoctor 任务检查文档渲染效果。 有些章节会包含其他文件,Github 并不一定能够渲染出来。
| 为了方便读者的反馈,多数章节在结尾都提供一个链接,这个链接可以打开一个 Github 上的 编辑界面,从而可以编辑相应章节的源码。这些链接在 HTML5 的版本中能够看到,就像这样: 翻译建议 - 关于本文档。 | |
|---|---|
1.3. 获取帮助
Reactor项目有多种方式希望能帮助到你:
- 与社区沟通: Gitter。
- 在 stackoverflow.com 的
project-reactor进行提问。 - 在 Github issues 提交 bug 。下边这几个库我们会一直关注: reactor-core (涉及 Reactor 的核心功能) 以及 reactor-addons (涉及 reactor-test 和 adapters issues)。
| 所有 Reactor 项目都是开源的, 包括本文档。 如果你发现本文档有问题,或希望补充一些内容,请参考 这里 进行了解。 | |
|---|---|
1.4. 如何开始阅读本文档
- 如果你想直接写代码请参考 快速上手 。
- 如果你对 响应式编程(Reactive Programming) 比较陌生,最好从 响应式编程 开始。
- 如果你对 Reactor 的理念比较熟悉,只是在编写程序时查找合适的操作符, 请参考附录 我需要哪个操作符? 。
- 如果你想深入了解 Reactor 的核心功能,请参考 Reactor 核心特性,以便了解:
- 关于 Reactor 的响应式类型 "
Flux, 包含 0-N 个元素的异步序列" 和 "Mono, 异步的 0-1 结果"; - 如何调整执行的线程环境: 调度器;
- 如何处理问题: 处理错误。
- 关于 Reactor 的响应式类型 "
- 单测的内容主要来自
reactor-test项目,参考 测试。 - 可编程式地创建一个序列 提供了更加丰富的创建响应式源(reactive source)的方式。
- 其他高级主题请看参考 高级特性与概念。
2. 快速上手
这一节的内容能够帮助你上手使用 Reactor。包括如下内容:
2.1. 介绍 Reactor
Reactor 是一个用于JVM的完全非阻塞的响应式编程框架,具备高效的需求管理(即对 “背压(backpressure)”的控制)能力。它与 Java 8 函数式 API 直接集成,比如 CompletableFuture, Stream, 以及 Duration。它提供了异步序列 API Flux(用于[N]个元素)和 Mono(用于 [0|1]个元素),并完全遵循和实现了“响应式扩展规范”(Reactive Extensions Specification)。
Reactor 的 reactor-ipc 组件还支持非阻塞的进程间通信(inter-process communication, IPC)。 Reactor IPC 为 HTTP(包括 Websockets)、TCP 和 UDP 提供了支持背压的网络引擎,从而适合 应用于微服务架构。并且完整支持响应式编解码(reactive encoding and decoding)。
2.2. 前提
Reactor Core 运行于 Java 8 及以上版本。
依赖 org.reactive-streams:reactive-streams:1.0.2。
| Andriod 支持方面:Reactor 3 并不正式支持 Andorid(如果需要可以考虑使用 RxJava 2)。但是,在 Android SDK 26(Android 0)及以上版本应该没问题。我们希望能够最大程度兼顾对 Android 的支持,但是我们并不能作出保证,具体情况具体分析。 | |
|---|---|
2.3. 了解 BOM
自从 reactor-core 3.0.4,随着 Aluminium 版本发布上车(release train)以来,Reactor 3 使用了 BOM(Bill of Materials,一种标准的 Maven artifact)。
使用 BOM 可以管理一组良好集成的 maven artifacts,从而无需操心不同版本组件的互相依赖问题。
BOM 是一系列有版本信息的 artifacts,通过“列车发布”(release train)的发布方式管理, 每趟发布列车由一个“代号+修饰词”组成,比如:
Aluminium-RELEASE
Carbon-BUILD-SNAPSHOT
Aluminium-SR1
Bismuth-RELEASE
Carbon-SR32
代号替代了传统的“主版本.次版本”的数字形式。这些代号主要来自 Periodic Table of Elements, 按首字母顺序依次选取。
修饰词有(按照时间顺序):
BUILD-SNAPSHOTM1..N: 里程碑号RELEASE: 第一次 GA (General Availability) 发布SR1..N: 后续的 GA 发布(类似于 PATCH 号或 SR(Service Release))。
2.4. 获取 Reactor
前边提到,使用 Reactor 的最简单方式是在你的项目中配置 BOM 以及相关依赖。 注意,当你这样添加依赖的时候,要省略版本(
当然,如果你希望使用某个版本的 artifact,仍然可以指定。甚至完全不使用 BOM,逐个配置 artifact 的版本也是可以的。
2.4.1. Maven 配置
Maven 原生支持 BOM。首先,你需要在 pom.xml 内通过添加下边的代码引入 BOM。如果 (dependencyManagement) 已经存在,只需要添加其内容即可。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>Bismuth-RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
注意 dependencyManagement 标签用来补充通常使用的 dependencies 配置。 |
|
|---|---|
然后,在 dependencies 中添加相关的 reactor 项目,省略 <version>,如下:
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
| 依赖 Core 库 | |
|---|---|
| 没有 version 标签 | |
reactor-test 提供了对 reactive streams 的单测 |
2.4.2. Gradle 配置
Gradle 没有对 Maven BOM 的支持,但是你可以使用 Spring 的 gradle-dependency-management 插件。
首先,apply 插件。
plugins {
id "io.spring.dependency-management" version "1.0.1.RELEASE"
}
| 编写本文档时,插件最新版本为 1.0.1.RELEASE,请自行使用合适的版本。 | |
|---|---|
然后用它引入 BOM:
dependencyManagement {
imports {
mavenBom "io.projectreactor:reactor-bom:Bismuth-RELEASE"
}
}
Finally add a dependency to your project, without a version number:
dependencies {
compile 'io.projectreactor:reactor-core'
}
无需第三个 : 添加版本号。 |
|
|---|---|
2.4.3. Milestones 和 Snapshots
里程碑版(Milestones)和开发预览版(developer previews)通过 Spring Milestones repository 而不是 Maven Central 来发布。 需要添加到构建配置文件中,如:
Milestones in Maven
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones Repository</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories>
gradle 使用下边的配置:
Milestones in Gradle
repositories {
maven { url 'http://repo.spring.io/milestone' }
mavenCentral()
}
类似的,snapshot 版也需要配置专门的库:
BUILD-SNAPSHOTs in Maven
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshot Repository</name>
<url>https://repo.spring.io/snapshot</url>
</repository>
</repositories>
BUILD-SNAPSHOTs in Gradle
repositories {
maven { url 'http://repo.spring.io/snapshot' }
mavenCentral()
}
3. 响应式编程
Reactor 是响应式编程范式的实现,总结起来有如下几点:
响应式编程是一种关注于数据流(data streams)和变化传递(propagation of change)的异步编程方式。 这意味着它可以用既有的编程语言表达静态(如数组)或动态(如事件源)的数据流。
在响应式编程方面,微软跨出了第一步,它在 .NET 生态中创建了响应式扩展库(Reactive Extensions library, Rx)。接着 RxJava 在JVM上实现了响应式编程。后来,在 JVM 平台出现了一套标准的响应式 编程规范,它定义了一系列标准接口和交互规范。并整合到 Java 9 中(使用 Flow 类)。
响应式编程通常作为面向对象编程中的“观察者模式”(Observer design pattern)的一种扩展。 响应式流(reactive streams)与“迭代子模式”(Iterator design pattern)也有相通之处, 因为其中也有 Iterable-Iterator 这样的对应关系。主要的区别在于,Iterator 是基于 “拉取”(pull)方式的,而响应式流是基于“推送”(push)方式的。
使用 iterator 是一种“命令式”(imperative)编程范式,即使访问元素的方法是 Iterable 的唯一职责。关键在于,什么时候执行 next() 获取元素取决于开发者。在响应式流中,相对应的 角色是 Publisher-Subscriber,但是 当有新的值到来的时候 ,却反过来由发布者(Publisher) 通知订阅者(Subscriber),这种“推送”模式是响应式的关键。此外,对推送来的数据的操作 是通过一种声明式(declaratively)而不是命令式(imperatively)的方式表达的:开发者通过 描述“控制流程”来定义对数据流的处理逻辑。
除了数据推送,对错误处理(error handling)和完成(completion)信号的定义也很完善。 一个 Publisher 可以推送新的值到它的 Subscriber(调用 onNext 方法), 同样也可以推送错误(调用 onError 方法)和完成(调用 onComplete 方法)信号。 错误和完成信号都可以终止响应式流。可以用下边的表达式描述:
onNext x 0..N [onError | onComplete]
这种方式非常灵活,无论是有/没有值,还是 n 个值(包括有无限个值的流,比如时钟的持续读秒),都可处理。
那么我们为什么需要这样的异步响应式开发库呢?
3.1. 阻塞是对资源的浪费
现代应用需要应对大量的并发用户,而且即使现代硬件的处理能力飞速发展,软件性能仍然是关键因素。
广义来说我们有两种思路来提升程序性能:
- 并行化(parallelize) :使用更多的线程和硬件资源。
- 基于现有的资源来 提高执行效率 。
通常,Java开发者使用阻塞式(blocking)编写代码。这没有问题,在出现性能瓶颈后, 我们可以增加处理线程,线程中同样是阻塞的代码。但是这种使用资源的方式会迅速面临 资源竞争和并发问题。
更糟糕的是,阻塞会浪费资源。具体来说,比如当一个程序面临延迟(通常是I/O方面, 比如数据库读写请求或网络调用),所在线程需要进入 idle 状态等待数据,从而浪费资源。
所以,并行化方式并非银弹。这是挖掘硬件潜力的方式,但是却带来了复杂性,而且容易造成浪费。
3.2. 异步可以解决问题吗?
第二种思路——提高执行效率——可以解决资源浪费问题。通过编写 异步非阻塞 的代码, (任务发起异步调用后)执行过程会切换到另一个 使用同样底层资源 的活跃任务,然后等 异步调用返回结果再去处理。
但是在 JVM 上如何编写异步代码呢?Java 提供了两种异步编程方式:
- 回调(Callbacks) :异步方法没有返回值,而是采用一个
callback作为参数(lambda 或匿名类),当结果出来后回调这个callback。常见的例子比如 Swings 的EventListener。 - Futures :异步方法 立即 返回一个
Future<T>,该异步方法要返回结果的是T类型,通过Future封装。这个结果并不是 立刻 可以拿到,而是等实际处理结束才可用。比如,ExecutorService执行Callable<T>任务时会返回Future对象。
这些技术够用吗?并非对于每个用例都是如此,两种方式都有局限性。
回调很难组合起来,因为很快就会导致代码难以理解和维护(即所谓的“回调地狱(callback hell)”)。
考虑这样一种情景:在用户界面上显示用户的5个收藏,或者如果没有任何收藏提供5个建议。这需要3个 服务(一个提供收藏的ID列表,第二个服务获取收藏内容,第三个提供建议内容):
回调地狱(Callback Hell)的例子
userService.getFavorites(userId, new Callback<List<String>>() {
public void onSuccess(List<String> list) {
if (list.isEmpty()) {
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) {
UiUtils.submitOnUiThread(() -> {
list.stream()
.limit(5)
.forEach(uiList::show);
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)
.forEach(favId -> favoriteService.getDetails(favId,
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
基于回调的服务使用一个匿名 Callback 作为参数。后者的两个方法分别在异步执行成功 或异常时被调用。 |
|
|---|---|
获取到收藏ID的list后调用第一个服务的回调方法 onSuccess。 |
|
如果 list 为空, 调用 suggestionService。 |
|
服务 suggestionService 传递 List<Favorite> 给第二个回调。 |
|
| 既然是处理 UI,我们需要确保消费代码运行在 UI 线程。 | |
使用 Java 8 Stream 来限制建议数量为5,然后在 UI 中显示。 |
|
| 在每一层,我们都以同样的方式处理错误:在一个 popup 中显示错误信息。 | |
回到收藏 ID 这一层,如果返回 list,我们需要使用 favoriteService 来获取 Favorite 对象。由于只想要5个,因此使用 stream 。 |
|
再一次回调。这次对每个ID,获取 Favorite 对象在 UI 线程中推送到前端显示。 |
这里有不少代码,稍微有些难以阅读,并且还有重复代码,我们再来看一下用 Reactor 实现同样功能:
使用 Reactor 实现以上回调方式同样功能的例子
userService.getFavorites(userId)
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
| 我们获取到收藏ID的流 | |
|---|---|
我们 异步地转换 它们(ID) 为 Favorite 对象(使用 flatMap),现在我们有了 Favorite流。 |
|
一旦 Favorite 为空,切换到 suggestionService。 |
|
| 我们只关注流中的最多5个元素。 | |
| 最后,我们希望在 UI 线程中进行处理。 | |
通过描述对数据的最终处理(在 UI 中显示)和对错误的处理(显示在 popup 中)来触发(subscribe)。 |
如果你想确保“收藏的ID”的数据在800ms内获得(如果超时,从缓存中获取)呢?在基于回调的代码中, 会比较复杂。但 Reactor 中就很简单,在处理链中增加一个 timeout 的操作符即可。
Reactor 中增加超时控制的例子
userService.getFavorites(userId)
.timeout(Duration.ofMillis(800))
.onErrorResume(cacheService.cachedFavoritesFor(userId))
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
| 如果流在超时时限没有发出(emit)任何值,则发出错误(error)。 | |
|---|---|
一旦收到错误,交由 cacheService 处理。 |
|
| 处理链后边的内容与上例类似。 |
Futures 比回调要好一点,但即使在 Java 8 引入了 CompletableFuture,它对于多个处理的组合仍不够好用。 编排多个 Futures 是可行的,但却不易。此外,Future 还有一个问题:当对 Future 对象最终调用 get() 方法时,仍然会导致阻塞,并且缺乏对多个值以及更进一步对错误的处理。
考虑另外一个例子,我们首先得到 ID 的列表,然后通过它进一步获取到“对应的 name 和 statistics” 为元素的列表,整个过程用异步方式来实现。
CompletableFuture 处理组合的例子
CompletableFuture<List<String>> ids = ifhIds();
CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> {
Stream<CompletableFuture<String>> zip =
l.stream().map(i -> {
CompletableFuture<String> nameTask = ifhName(i);
CompletableFuture<Integer> statTask = ifhStat(i);
return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat);
});
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList());
CompletableFuture<String>[] combinationArray = combinationList.toArray(new CompletableFuture[combinationList.size()]);
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray);
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()));
});
List<String> results = result.join();
assertThat(results).contains(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121");
| 以一个 Future 开始,其中封装了后续将获取和处理的 ID 的 list。 | |
|---|---|
| 获取到 list 后边进一步对其启动异步处理任务。 | |
| 对于 list 中的每一个元素: | |
| 异步地得到相应的 name。 | |
| 异步地得到相应的 statistics。 | |
| 将两个结果一一组合。 | |
我们现在有了一个 list,元素是 Future(表示组合的任务,类型是 CompletableFuture),为了执行这些任务, 我们需要将这个 list(元素构成的流) 转换为数组(List)。 |
|
将这个数组传递给 CompletableFuture.allOf,返回一个 Future ,当所以任务都完成了,那么这个 Future 也就完成了。 |
|
有点麻烦的地方在于 allOf 返回的是 CompletableFuture<Void>,所以我们遍历这个 Future 的List, ,然后使用 join() 来手机它们的结果(不会导致阻塞,因为 AllOf 确保这些 Future 全部完成) |
|
| 一旦整个异步流水线被触发,我们等它完成处理,然后返回结果列表。 |
由于 Reactor 内置许多组合操作,因此以上例子可以简单地实现:
Reactor 实现与 Future 同样功能的代码
Flux<String> ids = ifhrIds();
Flux<String> combinations =
ids.flatMap(id -> {
Mono<String> nameTask = ifhrName(id);
Mono<Integer> statTask = ifhrStat(id);
return nameTask.zipWith(statTask,
(name, stat) -> "Name " + name + " has stats " + stat);
});
Mono<List<String>> result = combinations.collectList();
List<String> results = result.block();
assertThat(results).containsExactly(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121"
);
这一次,我们从一个异步方式提供的 ids 序列(Flux<String>)开始。 |
|
|---|---|
对于序列中的每一个元素,我们异步地处理它(flatMap 方法内)两次。 |
|
| 获取相应的 name。 | |
| 获取相应的 statistic. | |
| 异步地组合两个值。 | |
随着序列中的元素值“到位”,它们收集一个 List 中。 |
|
在生成流的环节,我们可以继续异步地操作 Flux 流,对其进行组合和订阅(subscribe)。 最终我们很可能得到一个 Mono 。由于是测试,我们阻塞住(block()),等待流处理过程结束, 然后直接返回集合。 |
|
| Assert 结果。 |
回调或 Future 遇到的窘境是类似的,这也是响应式编程要通过 Publisher-Suscriber 方式来解决的。
3.3. 从命令式编程到响应式编程
类似 Reactor 这样的响应式库的目标就是要弥补上述“经典”的 JVM 异步方式所带来的不足, 此外还会关注一下几个方面:
- 可编排性(Composability) 以及 可读性(Readability)
- 使用丰富的 操作符 来处理形如 流 的数据
- 在 订阅(subscribe) 之前什么都不会发生
- 背压(backpressure) 具体来说即 消费者能够反向告知生产者生产内容的速度的能力
- 高层次 (同时也是有高价值的)的抽象,从而达到 并发无关 的效果
3.3.1. 可编排性与可读性
可编排性,指的是编排多个异步任务的能力。比如我们将前一个任务的结果传递给后一个任务作为输入, 或者将多个任务以分解再汇总(fork-join)的形式执行,或者将异步的任务作为离散的组件在系统中 进行重用。
这种编排任务的能力与代码的可读性和可维护性是紧密相关的。随着异步处理任务数量和复杂度 的提高,编写和阅读代码都变得越来越困难。就像我们刚才看到的,回调模式是简单的,但是缺点 是在复杂的处理逻辑中,回调中会层层嵌入回调,导致 回调地狱(Callback Hell) 。你能猜到 (或有过这种痛苦经历),这样的代码是难以阅读和分析的。
Reactor 提供了丰富的编排操作,从而代码直观反映了处理流程,并且所有的操作保持在同一层次 (尽量避免了嵌套)。
3.3.2. 就像装配流水线
你可以想象数据在响应式应用中的处理,就像流过一条装配流水线。Reactor 既是传送带, 又是一个个的装配工或机器人。原材料从源头(最初的 Publisher)流出,最终被加工为成品, 等待被推送到消费者(或者说 Subscriber)。
原材料会经过不同的中间处理过程,或者作为半成品与其他半成品进行组装。如果某处有齿轮卡住, 或者某件产品的包装过程花费了太久时间,相应的工位就可以向上游发出信号来限制或停止发出原材料。
3.3.3. 操作符(Operators)
在 Reactor 中,操作符(operator)就像装配线中的工位(操作员或装配机器人)。每一个操作符 对 Publisher 进行相应的处理,然后将 Publisher 包装为一个新的 Publisher。就像一个链条, 数据源自第一个 Publisher,然后顺链条而下,在每个环节进行相应的处理。最终,一个订阅者 (Subscriber)终结这个过程。请记住,在订阅者(Subscriber)订阅(subscribe)到一个 发布者(Publisher)之前,什么都不会发生。
理解了操作符会创建新的 Publisher 实例这一点,能够帮助你避免一个常见的问题, 这种问题会让你觉得处理链上的某个操作符没有起作用。相关内容请参考 item 。 |
|
|---|---|
虽然响应式流规范(Reactive Streams specification)没有规定任何操作符, 类似 Reactor 这样的响应式库所带来的最大附加价值之一就是提供丰富的操作符。包括基础的转换操作, 到过滤操作,甚至复杂的编排和错误处理操作。
3.3.4. subscribe() 之前什么都不会发生
在 Reactor 中,当你创建了一条 Publisher 处理链,数据还不会开始生成。事实上,你是创建了 一种抽象的对于异步处理流程的描述(从而方便重用和组装)。
当真正“订阅(subscrib)”的时候,你需要将 Publisher 关联到一个 Subscriber 上,然后 才会触发整个链的流动。这时候,Subscriber 会向上游发送一个 request 信号,一直到达源头 的 Publisher。
3.3.5. 背压()
向上游传递信号这一点也被用于实现 背压 ,就像在装配线上,某个工位的处理速度如果慢于流水线 速度,会对上游发送反馈信号一样。
在响应式流规范中实际定义的机制同刚才的类比非常接近:订阅者可以无限接受数据并让它的源头 “满负荷”推送所有的数据,也可以通过使用 request 机制来告知源头它一次最多能够处理 n 个元素。
中间环节的操作也可以影响 request。想象一个能够将每10个元素分批打包的缓存(buffer)操作。 如果订阅者请求一个元素,那么对于源头来说可以生成10个元素。此外预取策略也可以使用了, 比如在订阅前预先生成元素。
这样能够将“推送”模式转换为“推送+拉取”混合的模式,如果下游准备好了,可以从上游拉取 n 个元素;但是如果上游元素还没有准备好,下游还是要等待上游的推送。
3.3.6. 热(Hot) vs 冷(Cold)
在 Rx 家族的响应式库中,响应式流分为“热”和“冷”两种类型,区别主要在于响应式流如何 对订阅者进行响应:
- 一个“冷”的序列,指对于每一个
Subscriber,都会收到从头开始所有的数据。如果源头 生成了一个 HTTP 请求,对于每一个订阅都会创建一个新的 HTTP 请求。 - 一个“热”的序列,指对于一个
Subscriber,只能获取从它开始 订阅 之后 发出的数据。不过注意,有些“热”的响应式流可以缓存部分或全部历史数据。 通常意义上来说,一个“热”的响应式流,甚至在即使没有订阅者接收数据的情况下,也可以 发出数据(这一点同 “Subscribe()之前什么都不会发生”的规则有冲突)。
更多关于 Reactor 中“热”vs“冷”的内容,请参考 this reactor-specific section。
4. Reactor 核心特性
Reactor 项目的主要 artifact 是 reactor-core,这是一个基于 Java 8 的实现了响应式流规范 (Reactive Streams specification)的响应式库。
Reactor 引入了实现 Publisher 的响应式类 Flux 和 Mono,以及丰富的操作方式。 一个 Flux 对象代表一个包含 0..N 个元素的响应式序列,而一个 Mono 对象代表一个包含 零/一个(0..1)元素的结果。
这种区别为这俩类型带来了语义上的信息——表明了异步处理逻辑所面对的元素基数。比如, 一个 HTTP 请求产生一个响应,所以对其进行 count 操作是没有多大意义的。表示这样一个 结果的话,应该用 Mono<HttpResponse> 而不是 Flux<HttpResponse>,因为要置于其上的 操作通常只用于处理 0/1 个元素。
有些操作可以改变基数,从而需要切换类型。比如,count 操作用于 Flux,但是操作 返回的结果是 Mono<Long>。
4.1. Flux, 包含 0-N 个元素的异步序列

Flux<T> 是一个能够发出 0 到 N 个元素的标准的 Publisher<T>,它会被一个“错误(error)” 或“完成(completion)”信号终止。因此,一个 flux 的可能结果是一个 value、completion 或 error。 就像在响应式流规范中规定的那样,这三种类型的信号被翻译为面向下游的 onNext,onComplete和onError方法。
由于多种不同的信号可能性,Flux 可以作为一种通用的响应式类型。注意,所有的信号事件, 包括代表终止的信号事件都是可选的:如果没有 onNext 事件但是有一个 onComplete 事件, 那么发出的就是 空的 有限序列,但是去掉 onComplete 那么得到的就是一个 无限的 空序列。 当然,无限序列也可以不是空序列,比如,Flux.interval(Duration) 生成的是一个 Flux<Long>, 这就是一个无限地周期性发出规律 tick 的时钟序列。
4.2. Mono, 异步的 0-1 结果
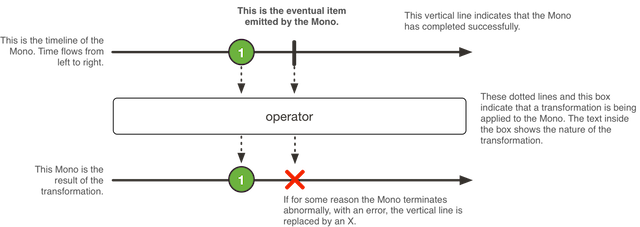
Mono<T> 是一种特殊的 Publisher<T>, 它最多发出一个元素,然后终止于一个 onComplete 信号或一个 onError 信号。
它只适用其中一部分可用于 Flux 的操作。比如,(两个 Mono 的)结合类操作可以忽略其中之一 而发出另一个 Mono,也可以将两个都发出,对于后一种情况会切换为一个 Flux。
例如,Mono#concatWith(Publisher) 返回一个 Flux,而 Mono#then(Mono) 返回另一个 Mono。
注意,Mono 可以用于表示“空”的只有完成概念的异步处理(比如 Runnable)。这种用 Mono<Void> 来创建。
4.3. 简单的创建和订阅 Flux 或 Mono 的方法
最简单的上手 Flux 和 Mono 的方式就是使用相应类提供的多种工厂方法之一。
比如,如果要创建一个 String 的序列,你可以直接列举它们,或者将它们放到一个集合里然后用来创建 Flux,如下:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(iterable);
工厂方法的其他例子如下:
Mono<String> noData = Mono.empty();
Mono<String> data = Mono.just("foo");
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);
| 注意,即使没有值,工厂方法仍然采用通用的返回类型。 | |
|---|---|
| 第一个参数是 range 的开始,第二个参数是要生成的元素个数。 |
在订阅(subscribe)的时候,Flux 和 Mono 使用 Java 8 lambda 表达式。 .subscribe() 方法有多种不同的方法签名,你可以传入各种不同的 lambda 形式的参数来定义回调。如下所示:
基于 lambda 的对 Flux 的订阅(subscribe)
subscribe();
subscribe(Consumer<? super T> consumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer);
| 订阅并触发序列。 | |
|---|---|
| 对每一个生成的元素进行消费。 | |
| 对正常元素进行消费,也对错误进行响应。 | |
| 对正常元素和错误均有响应,还定义了序列正常完成后的回调。 | |
对正常元素、错误和完成信号均有响应, 同时也定义了对该 subscribe 方法返回的 Subscription 执行的回调。 |
以上方法会返回一个 Subscription 的引用,如果不再需要更多元素你可以通过它来取消订阅。 取消订阅时, 源头会停止生成新的数据,并清理相关资源。取消和清理的操作在 Reactor 中是在 接口 Disposable 中定义的。 |
|
|---|---|
4.3.1. subscribe 方法示例
这一小节包含了对 subscribe 的5个不同签名的方法的示例,如下是一个无参的基本方法的使用:
Flux<Integer> ints = Flux.range(1, 3);
ints.subscribe();
配置一个在订阅时会产生3个值的 Flux。 |
|
|---|---|
| 最简单的订阅方式。 |
第二行代码没有任何输出,但是它确实执行了。Flux 产生了3个值。如果我们传入一个 lambda, 我们就可以看到这几个值,如下一个列子:
Flux<Integer> ints = Flux.range(1, 3);
ints.subscribe(i -> System.out.println(i));
配置一个在订阅时会产生3个值的 Flux。 |
|
|---|---|
| 订阅它并打印值。 |
第二行代码会输入如下内容:
1
2
3
为了演示下一个方法签名,我们故意引入一个错误,如下所示:
Flux<Integer> ints = Flux.range(1, 4)
.map(i -> {
if (i <= 3) return i;
throw new RuntimeException("Got to 4");
});
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error: " + error));
配置一个在订阅时会产生4个值的 Flux。 |
|
|---|---|
| 为了对元素进行处理,我们需要一个 map 操作。 | |
| 对于多数元素,返回值本身。 | |
| 对其中一个元素抛出错误。 | |
| 订阅的时候定义如何进行错误处理。 |
现在我们有两个 lambda 表达式:一个是用来处理正常数据,一个用来处理错误。 刚才的代码输出如下:
1
2
3
Error: java.lang.RuntimeException: Got to 4
下一个 subscribe 方法的签名既有错误处理,还有一个完成后的处理,如下:
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> {System.out.println("Done");});
配置一个在订阅时会产生4个值的 Flux。 |
|
|---|---|
| 订阅时定义错误和完成信号的处理。 |
错误和完成信号都是终止信号,并且二者只会出现其中之一。为了能够最终全部正常完成,你必须处理错误信号。
用于处理完成信号的 lambda 是一对空的括号,因为它实际上匹配的是 Runnalbe 接口中的 run 方法, 不接受参数。刚才的代码输出如下:
1
2
3
4
Done
最后一个 subscribe 方法签名包含一个自定义的 subscriber(下一节会介绍到):
SampleSubscriber<Integer> ss = new SampleSubscriber<Integer>();
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> {System.out.println("Done");},
s -> ss.request(10));
ints.subscribe(ss);
上面这个例子中,我们把一个自定义的 Subscriber 作为 subscribe 方法的最后一个参数。 下边的例子是这个自定义的 Subscriber,这是一个对 Subscriber 的最简单实现:
package io.projectreactor.samples;
import org.reactivestreams.Subscription;
import reactor.core.publisher.BaseSubscriber;
public class SampleSubscriber<T> extends BaseSubscriber<T> {
public void hookOnSubscribe(Subscription subscription) {
System.out.println("Subscribed");
request(1);
}
public void hookOnNext(T value) {
System.out.println(value);
request(1);
}
}
SampleSubscriber 类继承自 BaseSubscriber,在 Reactor 中, 推荐用户扩展它来实现自定义的 Subscriber。这个类提供了一些 hook 方法,我们可以通过重写它们来调整 subscriber 的行为。 默认情况下,它会触发一个无限个数的请求,但是当你想自定义请求元素的个数的时候,扩展 BaseSubscriber 就很方便了。
扩展的时候通常至少要覆盖 hookOnSubscribe(Subscription subscription) 和 hookOnNext(T value) 这两个方法。这个例子中, hookOnSubscribe 方法打印一段话到标准输出,然后进行第一次请求。 然后 hookOnNext 同样进行了打印,同时逐个处理剩余请求。
SampleSubscriber 输出如下:
Subscribed
1
2
3
4
建议你同时重写 hookOnError、hookOnCancel,以及 hookOnComplete 方法。 你最好也重写 hookFinally 方法。SampleSubscribe 确实是一个最简单的实现了 请求有限个数元素的 Subscriber。 |
|
|---|---|
本文档后边还会再讨论 BaseSubscriber。
响应式流规范定义了另一个 subscribe 方法的签名,它只接收一个自定义的 Subscriber, 没有其他的参数,如下所示:
subscribe(Subscriber<? super T> subscriber);
如果你已经有一个 Subscriber,那么这个方法签名还是挺有用的。况且,你可能还会用到它 来做一些订阅相关(subscription-related)的回调。比如,你想要自定义“背压(backpressure)” 并且自己来触发请求。
在这种情况下,使用 BaseSubscriber 抽象类就很方便,因为它提供了很好的配置“背压” 的方法。
使用 BaseSubscriber 来配置“背压”
Flux<String> source = someStringSource();
source.map(String::toUpperCase)
.subscribe(new BaseSubscriber<String>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
request(1);
}
@Override
protected void hookOnNext(String value) {
request(1);
}
});
BaseSubscriber 是一个抽象类,所以我们创建一个匿名内部类。 |
|
|---|---|
BaseSubscriber 定义了多种用于处理不同信号的 hook。它还定义了一些捕获 Subscription 对象的现成方法,这些方法可以用在 hook 中。 |
|
request(n) 就是这样一个方法。它能够在任何 hook 中,通过 subscription 向上游传递 背压请求。这里我们在开始这个流的时候请求1个元素值。 |
|
| 随着接收到新的值,我们继续以每次请求一个元素的节奏从源头请求值。 | |
其他 hooks 有 hookOnComplete, hookOnError, hookOnCancel, and hookFinally (它会在流终止的时候被调用,传入一个 SignalType 作为参数)。 |
当你修改请求操作的时候,你必须注意让 subscriber 向上提出足够的需求, 否则上游的 Flux 可能会被“卡住”。所以 BaseSubscriber 在进行扩展的时候要覆盖 hookOnSubscribe 和 onNext,这样你至少会调用 request 一次。 |
|
|---|---|
BaseSubscriber 还提供了 requestUnbounded() 方法来切换到“无限”模式(等同于 request(Long.MAX_VALUE))。
4.4. 可编程式地创建一个序列
在这一小节,我们介绍如何通过定义相对应的事件(onNext、onError和onComplete) 创建一个 Flux 或 Mono。所有这些方法都通过 API 来触发我们叫做 sink(池) 的事件。 sink 的类型不多,我们快速过一下。
4.4.1. Generate
最简单的创建 Flux 的方式就是使用 generate 方法。
这是一种 同步地, 逐个地 产生值的方法,意味着 sink 是一个 SynchronousSink 而且其 next() 方法在每次回调的时候最多只能被调用一次。你也可以调用 error(Throwable) 或者 complete(),不过是可选的。
最有用的一种方式就是同时能够记录一个状态值(state),从而在使用 sink 发出下一个元素的时候能够 基于这个状态值去产生元素。此时生成器(generator)方法就是一个 BiFunction<S, SynchronousSink<T>, S>, 其中 <S> 是状态对象的类型。你需要提供一个 Supplier<S> 来初始化状态值,而生成器需要 在每一“回合”生成元素后返回新的状态值(供下一回合使用)。
例如我们使用一个 int 作为状态值。
基于状态值的 generate 示例
Flux<String> flux = Flux.generate(
() -> 0,
(state, sink) -> {
sink.next("3 x " + state + " = " + 3*state);
if (state == 10) sink.complete();
return state + 1;
});
| 初始化状态值(state)为0。 | |
|---|---|
| 我们基于状态值 state 来生成下一个值(state 乘以 3)。 | |
| 我们也可以用状态值来决定什么时候终止序列。 | |
| 返回一个新的状态值 state,用于下一次调用。 |
上面的代码生成了“3 x”的乘法表:
3 x 0 = 0
3 x 1 = 3
3 x 2 = 6
3 x 3 = 9
3 x 4 = 12
3 x 5 = 15
3 x 6 = 18
3 x 7 = 21
3 x 8 = 24
3 x 9 = 27
3 x 10 = 30
我们也可以使用可变(mutable)类型(译者注:如上例,原生类型及其包装类,以及String等属于不可变类型) 的 <S>。上边的例子也可以用 AtomicLong 作为状态值,在每次生成后改变它的值。
可变类型的状态变量
Flux<String> flux = Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state;
});
| 这次我们初始化一个可变类型的状态值。 | |
|---|---|
| 改变状态值。 | |
| 返回 同一个 实例作为新的状态值。 |
如果状态对象需要清理资源,可以使用 generate(Supplier<S>, BiFunction, Consumer<S>) 这个签名方法来清理状态对象(译者注:Comsumer 在序列终止才被调用)。 |
|
|---|---|
下面是一个在 generate 方法中增加 Consumer 的例子:
Flux<String> flux = Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state;
}, (state) -> System.out.println("state: " + state));
}
| 同样,初始化一个可变对象作为状态变量。 | |
|---|---|
| 改变状态。 | |
| 返回 同一个 实例作为新的状态。 | |
我们会看到最后一个状态值(11)会被这个 Consumer lambda 输出。 |
如果 state 使用了数据库连接或者其他需要最终进行清理的资源,这个 Consumer lambda 可以用来在最后关闭连接或完成相关的其他清理任务。
4.4.2. Create
作为一个更高级的创建 Flux 的方式, create 方法的生成方式既可以是同步, 也可以是异步的,并且还可以每次发出多个元素。
该方法用到了 FluxSink,后者同样提供 next,error 和 complete 等方法。 与 generate 不同的是,create 不需要状态值,另一方面,它可以在回调中触发 多个事件(即使是在未来的某个时间)。
create 有个好处就是可以将现有的 API 转为响应式,比如监听器的异步方法。 |
|
|---|---|
假设你有一个监听器 API,它按 chunk 处理数据,有两种事件:(1)一个 chunk 数据准备好的事件;(2)处理结束的事件。如下:
interface MyEventListener<T> {
void onDataChunk(List<T> chunk);
void processComplete();
}
你可以使用 create 方法将其转化为响应式类型 Flux<T>:
Flux<String> bridge = Flux.create(sink -> {
myEventProcessor.register(
new MyEventListener<String>() {
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s);
}
}
public void processComplete() {
sink.complete();
}
});
});
桥接 MyEventListener。 |
|
|---|---|
每一个 chunk 的数据转化为 Flux 中的一个元素。 |
|
processComplete 事件转换为 onComplete。 |
|
所有这些都是在 myEventProcessor 执行时异步执行的。 |
此外,既然 create 可以是异步地,并且能够控制背压,你可以通过提供一个 OverflowStrategy 来定义背压行为。
IGNORE: 完全忽略下游背压请求,这可能会在下游队列积满的时候导致IllegalStateException。ERROR: 当下游跟不上节奏的时候发出一个IllegalStateException的错误信号。DROP:当下游没有准备好接收新的元素的时候抛弃这个元素。LATEST:让下游只得到上游最新的元素。BUFFER:(默认的)缓存所有下游没有来得及处理的元素(这个不限大小的缓存可能导致OutOfMemoryError)。
Mono 也有一个用于 create 的生成器(generator)—— MonoSink,它不能生成多个元素, 因此会抛弃第一个元素之后的所有元素。 |
|
|---|---|
推送(push)模式
create 的一个变体是 push,适合生成事件流。与 create类似,push 也可以是异步地, 并且能够使用以上各种溢出策略(overflow strategies)管理背压。每次只有一个生成线程可以调用 next,complete 或 error。
Flux<String> bridge = Flux.push(sink -> {
myEventProcessor.register(
new SingleThreadEventListener<String>() {
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s);
}
}
public void processComplete() {
sink.complete();
}
public void processError(Throwable e) {
sink.error(e);
}
});
});
桥接 SingleThreadEventListener API。 |
|
|---|---|
在监听器所在线程中,事件通过调用 next 被推送到 sink。 |
|
complete 事件也在同一个线程中。 |
|
error 事件也在同一个线程中。 |
推送/拉取(push/pull)混合模式
不像 push,create 可以用于 push 或 pull 模式,因此适合桥接监听器的 的 API,因为事件消息会随时异步地到来。回调方法 onRequest 可以被注册到 FluxSink 以便跟踪请求。这个回调可以被用于从源头请求更多数据,或者通过在下游请求到来 的时候传递数据给 sink 以实现背压管理。这是一种推送/拉取混合的模式, 因为下游可以从上游拉取已经就绪的数据,上游也可以在数据就绪的时候将其推送到下游。
Flux<String> bridge = Flux.create(sink -> {
myMessageProcessor.register(
new MyMessageListener<String>() {
public void onMessage(List<String> messages) {
for(String s : messages) {
sink.next(s);
}
}
});
sink.onRequest(n -> {
List<String> messages = myMessageProcessor.request(n);
for(String s : message) {
sink.next(s);
}
});
| 当有请求的时候取出一个 message。 | |
|---|---|
| 如果有就绪的 message,就发送到 sink。 | |
| 后续异步到达的 message 也会被发送给 sink。 |
清理(Cleaning up)
onDispose 和 onCancel 这两个回调用于在被取消和终止后进行清理工作。 onDispose 可用于在 Flux 完成,有错误出现或被取消的时候执行清理。 onCancel 只用于针对“取消”信号执行相关操作,会先于 onDispose 执行。
Flux<String> bridge = Flux.create(sink -> {
sink.onRequest(n -> channel.poll(n))
.onCancel(() -> channel.cancel())
.onDispose(() -> channel.close())
});
onCancel 在取消时被调用。 |
|
|---|---|
onDispose 在有完成、错误和取消时被调用。 |
4.4.3. Handle
handle 方法有些不同,它在 Mono 和 Flux 中都有。然而,它是一个实例方法 (instance method),意思就是它要链接在一个现有的源后使用(与其他操作符一样)。
它与 generate 比较类似,因为它也使用 SynchronousSink,并且只允许元素逐个发出。 然而,handle 可被用于基于现有数据源中的元素生成任意值,有可能还会跳过一些元素。 这样,可以把它当做 map 与 filter 的组合。handle 方法签名如下:
handle(BiConsumer<T, SynchronousSink<R>>)
举个例子,响应式流规范允许 null 这样的值出现在序列中。假如你想执行一个类似 map 的操作,你想利用一个现有的具有映射功能的方法,但是它会返回 null,这时候怎么办呢?
例如,下边的方法可以用于 Integer 序列,映射为字母或 null 。
public String alphabet(int letterNumber) {
if (letterNumber < 1 || letterNumber > 26) {
return null;
}
int letterIndexAscii = 'A' + letterNumber - 1;
return "" + (char) letterIndexAscii;
}
我们可以使用 handle 来去掉其中的 null。
将 handle 用于一个 "映射 + 过滤 null" 的场景
Flux<String> alphabet = Flux.just(-1, 30, 13, 9, 20)
.handle((i, sink) -> {
String letter = alphabet(i);
if (letter != null)
sink.next(letter);
});
alphabet.subscribe(System.out::println);
| 映射到字母。 | |
|---|---|
| 如果返回的是 null … | |
就不会调用 sink.next 从而过滤掉。 |
输出如下:
M
I
T
4.5. 调度器(Schedulers)
Reactor, 就像 RxJava,也可以被认为是 并发无关(concurrency agnostic) 的。意思就是, 它并不强制要求任何并发模型。更进一步,它将选择权交给开发者。不过,它还是提供了一些方便 进行并发执行的库。
在 Reactor 中,执行模式以及执行过程取决于所使用的 Scheduler。 Scheduler 是一个拥有广泛实现类的抽象接口。 Schedulers 类提供的静态方法用于达成如下的执行环境:
- 当前线程(
Schedulers.immediate()) - 可重用的单线程(
Schedulers.single())。注意,这个方法对所有调用者都提供同一个线程来使用, 直到该调度器(Scheduler)被废弃。如果你想使用专一的线程,就对每一个调用使用Schedulers.newSingle()。 - 弹性线程池(
Schedulers.elastic()。它根据需要创建一个线程池,重用空闲线程。线程池如果空闲时间过长 (默认为 60s)就会被废弃。对于 I/O 阻塞的场景比较适用。Schedulers.elastic()能够方便地给一个阻塞 的任务分配它自己的线程,从而不会妨碍其他任务和资源,见 如何包装一个同步阻塞的调用?。 - 固定大小线程池(
Schedulers.parallel())。所创建线程池的大小与 CPU 个数等同。
此外,你还可以使用 Schedulers.fromExecutorService(ExecutorService) 基于现有的 ExecutorService 创建 Scheduler。(虽然不太建议,不过你也可以使用 Executor 来创建)。你也可以使用 newXXX 方法来创建不同的调度器。比如 Schedulers.newElastic(yourScheduleName) 创建一个新的名为 yourScheduleName 的弹性调度器。
| 操作符基于非阻塞算法实现,从而可以利用到某些调度器的工作窃取(work stealing) 特性的好处。 | |
|---|---|
一些操作符默认会使用一个指定的调度器(通常也允许开发者调整为其他调度器)例如, 通过工厂方法 Flux.interval(Duration.ofMillis(300)) 生成的每 300ms 打点一次的 Flux<Long>, 默认情况下使用的是 Schedulers.parallel(),下边的代码演示了如何将其装换为 Schedulers.single():
Flux.interval(Duration.ofMillis(300), Schedulers.newSingle("test"))
Reactor 提供了两种在响应式链中调整调度器 Scheduler 的方法:publishOn 和 subscribeOn。 它们都接受一个 Scheduler 作为参数,从而可以改变调度器。但是 publishOn 在链中出现的位置 是有讲究的,而 subscribeOn 则无所谓。要理解它们的不同,你首先要理解 nothing happens until you subscribe()。
在 Reactor 中,当你在操作链上添加操作符的时候,你可以根据需要在 Flux 和 Mono 的实现中包装其他的 Flux 和 Mono。一旦你订阅(subscribe)了它,一个 Subscriber 的链 就被创建了,一直向上到第一个 publisher 。这些对开发者是不可见的,开发者所能看到的是最外一层的 Flux (或 Mono)和 Subscription,但是具体的任务是在中间这些跟操作符相关的 subscriber 上处理的。
基于此,我们仔细研究一下 publishOn 和 subscribeOn 这两个操作符:
publishOn的用法和处于订阅链(subscriber chain)中的其他操作符一样。它将上游 信号传给下游,同时执行指定的调度器Scheduler的某个工作线程上的回调。 它会 改变后续的操作符的执行所在线程 (直到下一个publishOn出现在这个链上)。subscribeOn用于订阅(subscription)过程,作用于那个向上的订阅链(发布者在被订阅 时才激活,订阅的传递方向是向上游的)。所以,无论你把subscribeOn至于操作链的什么位置, 它都会影响到源头的线程执行环境(context)。 但是,它不会影响到后续的publishOn,后者仍能够切换其后操作符的线程执行环境。
只有操作链中最早的 subscribeOn 调用才算数。 |
|
|---|---|
4.6. 线程模型
Flux 和 Mono 不会创建线程。一些操作符,比如 publishOn,会创建线程。同时,作为一种任务共享形式, 这些操作符可能会从其他任务池(work pool)——如果其他任务池是空闲的话——那里“偷”线程。因此, 无论是 Flux、Mono 还是 Subscriber 都应该精于线程处理。它们依赖这些操作符来管理线程和任务池。
publishOn 强制下一个操作符(很可能包括下一个的下一个…)来运行在一个不同的线程上。 类似的,subscribeOn 强制上一个操作符(很可能包括上一个的上一个…)来运行在一个不同的线程上。 记住,在你订阅(subscribe)前,你只是定义了处理流程,而没有启动发布者。基于此,Reactor 可以使用这些规则来决定如何执行操作链。然后,一旦你订阅了,整个流程就开始工作了。
下边的例子演示了支持任务共享的多线程模型:
Flux.range(1, 10000)
.publishOn(Schedulers.parallel())
.subscribe(result)
创建一个有 10,000 个元素的 Flux。 |
|
|---|---|
| 创建等同于 CPU 个数的线程(最小为4)。 | |
subscribe() 之前什么都不会发生。 |
Scheduler.parallel() 创建一个基于单线程 ExecutorService 的固定大小的任务线程池。 因为可能会有一个或两个线程导致问题,它总是至少创建 4 个线程。然后 publishOn 方法便共享了这些任务线程, 当 publishOn 请求元素的时候,会从任一个正在发出元素的线程那里获取元素。这样, 就是进行了任务共享(一种资源共享方式)。Reactor 还提供了好几种共享资源的方式,请参考 Schedulers。
Scheduler.elastic() 也能创建线程,它能够很方便地创建专门的线程(以便跑一些可能会阻塞资源的任务, 比如一个同步服务),请见 如何包装一个同步阻塞的调用?。
内部机制保证了这些操作符能够借助自增计数器(incremental counters)和警戒条件(guard conditions) 以线程安全的方式工作。例如,如果我们有四个线程处理一个流(就像上边的例子),每一个请求会让计数器自增, 这样后续的来自不同线程的请求就能拿到正确的元素。
4.7. 处理错误
| 如果想了解有哪些可用于错误处理的操作符,请参考 the relevant operator decision tree。 | |
|---|---|
在响应式流中,错误(error)是终止(terminal)事件。当有错误发生时,它会导致流序列停止, 并且错误信号会沿着操作链条向下传递,直至遇到你定义的 Subscriber 及其 onError 方法。
这样的错误还是应该在应用层面解决的。比如,你可能会将错误信息显示在用户界面,或者通过某个 REST 端点(endpoint)发出。因此,订阅者(subscriber)的 onError 方法是应该定义的。
如果没有定义,onError 会抛出 UnsupportedOperationException。你可以接下来再 检测错误,并通过 Exceptions.isErrorCallbackNotImplemented 方法捕获和处理它。 |
|
|---|---|
Reactor 还提供了其他的用于在链中处理错误的方法,即错误处理操作(error-handling operators)。
在你了解错误处理操作符之前,你必须牢记 响应式流中的任何错误都是一个终止事件。 即使用了错误处理操作符,也不会让源头流序列继续。而是将 onError 信号转化为一个 新的 序列 的开始。换句话说,它代替了被终结的 上游 流序列。 |
|
|---|---|
现在我们来逐个看看错误处理的方法。需要的时候我们会同时用到命令式编程风格的 try 代码块来作比较。
4.7.1. “错误处理”方法
你也许熟悉在 try-catch 代码块中处理异常的几种方法。常见的包括如下几种:
- 捕获并返回一个静态的缺省值。
- 捕获并执行一个异常处理方法。
- 捕获并动态计算一个候补值来顶替。
- 捕获,并再包装为某一个
业务相关的异常,然后再抛出业务异常。 - 捕获,记录错误日志,然后继续抛出。
- 使用
finally来清理资源,或使用 Java 7 引入的 "try-with-resource"。
以上所有这些在 Reactor 都有相应的基于 error-handling 操作符处理方式。
在开始研究这些操作符之前,我们先准备好响应式链(reactive chain)方式和 try-catch 代码块方式(以便对比)。
当订阅的时候,位于链结尾的 onError 回调方法和 catch 块类似,一旦有异常,执行过程会跳入到 catch:
Flux<String> s = Flux.range(1, 10)
.map(v -> doSomethingDangerous(v))
.map(v -> doSecondTransform(v));
s.subscribe(value -> System.out.println("RECEIVED " + value),
error -> System.err.println("CAUGHT " + error)
);
| 执行 map 转换,有可能抛出异常。 | |
|---|---|
| 如果没问题,执行第二个 map 转换操作。 | |
| 所有转换成功的值都打印出来。 | |
| 一旦有错误,序列(sequence)终止,并打印错误信息。 |
这与 try/catch 代码块是类似的:
try {
for (int i = 1; i < 11; i++) {
String v1 = doSomethingDangerous(i);
String v2 = doSecondTransform(v1);
System.out.println("RECEIVED " + v2);
}
} catch (Throwable t) {
System.err.println("CAUGHT " + t);
}
| 如果这里抛出异常… | |
|---|---|
| …后续的代码跳过… | |
| …执行过程直接到这。 |
既然我们准备了两种方式做对比,我们就来看一下不同的错误处理场景,以及相应的操作符。
静态缺省值
与第 (1) 条(捕获并返回一个静态的缺省值)对应的是 onErrorReturn:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn("RECOVERED");
你还可以通过判断错误信息的内容,来筛选哪些要给出缺省值,哪些仍然让错误继续传递下去:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn(e -> e.getMessage().equals("boom10"), "recovered10");
异常处理方法
如果你不只是想要在发生错误的时候给出缺省值,而是希望提供一种更安全的处理数据的方式, 可以使用 onErrorResume。这与第 (2) 条(捕获并执行一个异常处理方法)类似。
假设,你会尝试从一个外部的不稳定服务获取数据,但仍然会在本地缓存一份 可能 有些过期的数据, 因为缓存的读取更加可靠。可以这样来做:
Flux.just("key1", "key2")
.flatMap(k -> callExternalService(k))
.onErrorResume(e -> getFromCache(k));
| 对于每一个 key, 异步地调用一个外部服务。 | |
|---|---|
如果对外部服务的调用失败,则再去缓存中查找该 key。注意,这里无论 e 是什么,都会执行异常处理方法。 |
就像 onErrorReturn,onErrorResume 也有可以用于预先过滤错误内容的方法变体,可以基于异常类或 Predicate 进行过滤。它实际上是用一个 Function 来作为参数,还可以返回一个新的流序列。
Flux.just("timeout1", "unknown", "key2")
.flatMap(k -> callExternalService(k))
.onErrorResume(error -> {
if (error instanceof TimeoutException)
return getFromCache(k);
else if (error instanceof UnknownKeyException)
return registerNewEntry(k, "DEFAULT");
else
return Flux.error(error);
});
| 这个函数式允许开发者自行决定如何处理。 | |
|---|---|
| 如果源超时,使用本地缓存。 | |
| 如果源找不到对应的 key,创建一个新的实体。 | |
| 否则, 将问题“重新抛出”。 |
动态候补值
有时候并不想提供一个错误处理方法,而是想在接收到错误的时候计算一个候补的值。这类似于第 (3) 条(捕获并动态计算一个候补值)。
例如,如果你的返回类型本身就有可能包装有异常(比如 Future.complete(T success) vs Future.completeExceptionally(Throwable error)),你有可能使用流中的错误包装起来实例化 返回值。
这也可以使用上一种错误处理方法的方式(使用 onErrorResume)解决,代码如下:
erroringFlux.onErrorResume(error -> Mono.just(
myWrapper.fromError(error)
));
在 onErrorResume 中,使用 Mono.just 创建一个 Mono。 |
|
|---|---|
| 将异常包装到另一个类中。 |
捕获并重新抛出
在“错误处理方法”的例子中,基于 flatMap 方法的最后一行,我们可以猜到如何做到第 (4) 条(捕获,包装到一个业务相关的异常,然后抛出业务异常):
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorResume(original -> Flux.error(
new BusinessException("oops, SLA exceeded", original)
);
然而还有一个更加直接的方法—— onErrorMap:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorMap(original -> new BusinessException("oops, SLA exceeded", original));
记录错误日志
如果对于错误你只是想在不改变它的情况下做出响应(如记录日志),并让错误继续传递下去, 那么可以用 doOnError 方法。这对应第 (5) 条(捕获,记录错误日志,并继续抛出)。 这个方法与其他以 doOn 开头的方法一样,只起副作用("side-effect")。它们对序列都是只读, 而不会带来任何改动。
如下边的例子所示,我们会记录错误日志,并且还通过变量自增统计错误发生个数。
LongAdder failureStat = new LongAdder();
Flux<String> flux =
Flux.just("unknown")
.flatMap(k -> callExternalService(k))
.doOnError(e -> {
failureStat.increment();
log("uh oh, falling back, service failed for key " + k);
})
.onErrorResume(e -> getFromCache(k));
| 对外部服务的调用失败… | |
|---|---|
| …记录错误日志… | |
| …然后回调错误处理方法。 |
使用资源和 try-catch 代码块
最后一个要与命令式编程对应的对比就是使用 Java 7 "try-with-resources" 或 finally 代码块清理资源。这是第 (6) 条(使用 finally 代码块清理资源或使用 Java 7 引入的 "try-with-resource")。在 Reactor 中都有对应的方法: using 和 doFinally:
AtomicBoolean isDisposed = new AtomicBoolean();
Disposable disposableInstance = new Disposable() {
@Override
public void dispose() {
isDisposed.set(true);
}
@Override
public String toString() {
return "DISPOSABLE";
}
};
Flux<String> flux =
Flux.using(
() -> disposableInstance,
disposable -> Flux.just(disposable.toString()),
Disposable::dispose
);
第一个 lambda 生成资源,这里我们返回模拟的(mock) Disposable。 |
|
|---|---|
第二个 lambda 处理资源,返回一个 Flux<T>。 |
|
第三个 lambda 在 2) 中的资源 Flux 终止或取消的时候,用于清理资源。 |
|
在订阅或执行流序列之后, isDisposed 会置为 true。 |
另一方面, doFinally 在序列终止(无论是 onComplete、onError还是取消)的时候被执行, 并且能够判断是什么类型的终止事件(完成、错误还是取消?)。
LongAdder statsCancel = new LongAdder();
Flux<String> flux =
Flux.just("foo", "bar")
.doFinally(type -> {
if (type == SignalType.CANCEL)
statsCancel.increment();
})
.take(1);
我们想进行统计,所以用到了 LongAdder。 |
|
|---|---|
doFinally 用 SignalType 检查了终止信号的类型。 |
|
| 如果只是取消,那么统计数据自增。 | |
take(1) 能够在发出 1 个元素后取消流。 |
演示终止方法 onError
为了演示当错误出现的时候如何导致上游序列终止,我们使用 Flux.interval 构造一个更加直观的例子。 这个 interval 操作符会在每 x 单位的时间发出一个自增的 Long 值。
Flux<String> flux =
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.onErrorReturn("Uh oh");
flux.subscribe(System.out::println);
Thread.sleep(2100);
注意 interval 默认基于一个 timer Scheduler 来执行。 如果我们想在 main 方法中运行, 我们需要调用 sleep,这样程序就可以在还没有产生任何值的时候就退出了。 |
|
|---|---|
每 250ms 打印出一行信息,如下:
tick 0
tick 1
tick 2
Uh oh
即使多给了 1 秒钟时间,也没有更多的 tick 信号由 interval 产生了,所以序列确实被错误信号终止了。
重试
还有一个用于错误处理的操作符你可能会用到,就是 retry,见文知意,用它可以对出现错误的序列进行重试。
问题是它对于上游 Flux 是基于重订阅(re-subscribing)的方式。这实际上已经一个不同的序列了, 发出错误信号的序列仍然是终止了的。为了验证这一点,我们可以在继续用上边的例子,增加一个 retry(1) 代替 onErrorReturn 来重试一次。
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.elapsed()
.retry(1)
.subscribe(System.out::println, System.err::println);
Thread.sleep(2100);
elapsed 会关联从当前值与上个值发出的时间间隔(译者加:如下边输出的内容中的 259/249/251…)。 |
|
|---|---|
我们还是要看一下 onError 时的内容。 |
|
| 确保我们有足够的时间可以进行 4x2 次 tick。 |
输出如下:
259,tick 0
249,tick 1
251,tick 2
506,tick 0
248,tick 1
253,tick 2
java.lang.RuntimeException: boom
一个新的 interval 从 tick 0 开始。多出来的 250ms 间隔来自于第 4 次 tick, 就是导致出现异常并执行 retry 的那次(译者加:我在机器上测试的时候 elapsed “显示”的时间间隔没有加倍,但是确实有第 4 次的间隔)。 |
|
|---|---|
可见, retry(1) 不过是再一次从新订阅了原始的 interval,从 tick 0 开始。第二次, 由于异常再次出现,便将异常传递到下游了。
还有一个“高配版”的 retry (retryWhen),它使用一个伴随("companion") Flux 来判断对某次错误是否要重试。这个伴随 Flux 是由操作符创建的,但是由开发者包装它, 从而实现对重试操作的配置。
这个伴随 Flux 是一个 Flux<Throwable>,它作为 retryWhen 的唯一参数被传递给一个 Function,你可以定义这个 Function 并让它返回一个新的 Publisher<?>。重试的循环 会这样运行:
- 每次出现错误,错误信号会发送给伴随
Flux,后者已经被你用Function包装。 - 如果伴随
Flux发出元素,就会触发重试。 - 如果伴随
Flux完成(complete),重试循环也会停止,并且原始序列也会 完成(complete)。 - 如果伴随
Flux产生一个错误,重试循环停止,原始序列也停止 或 完成,并且这个错误会导致 原始序列失败并终止。
了解前两个场景的区别是很重要的。如果让伴随 Flux 完成(complete)等于吞掉了错误。如下代码用 retryWhen 模仿了 retry(3) 的效果:
Flux<String> flux = Flux
.<String>error(new IllegalArgumentException())
.doOnError(System.out::println)
.retryWhen(companion -> companion.take(3));
| 持续产生错误。 | |
|---|---|
在 retry 之前 的 doOnError 可以让我们看到错误。 |
|
这里,我们认为前 3 个错误是可以重试的(take(3)),再有错误就放弃。 |
事实上,上边例子最终得到的是一个 空的 Flux,但是却 成功 完成了。反观对同一个 Flux 调用 retry(3) 的话,最终是以最后一个 error 终止 Flux,故而 retryWhen 与之不同。
实现同样的效果需要一些额外的技巧:
Flux<String> flux =
Flux.<String>error(new IllegalArgumentException())
.retryWhen(companion -> companion
.zipWith(Flux.range(1, 4),
(error, index) -> {
if (index < 4) return index;
else throw Exceptions.propagate(error);
})
);
技巧一:使用 zip 和一个“重试个数 + 1”的 range。 |
|
|---|---|
zip 方法让你可以在对重试次数计数的同时,仍掌握着原始的错误(error)。 |
|
| 允许三次重试,小于 4 的时候发出一个值。 | |
| 为了使序列以错误结束。我们将原始异常在三次重试之后抛出。 |
| 类似的代码也可以被用于实现 exponential backoff and retry 模式 (译者加:重试指定的次数, 且每一次重试之间停顿的时间逐渐增加),参考 FAQ。 | |
|---|---|
4.7.2. 在操作符或函数式中处理异常
总体来说,所有的操作符自身都可能包含触发异常的代码,或自定义的可能导致失败的代码, 所以它们都自带一些错误处理方式。
一般来说,一个 不受检异常(Unchecked Exception) 总是由 onError 传递。例如, 在一个 map 方法中抛出 RuntimeException 会被翻译为一个 onError 事件,如下:
Flux.just("foo")
.map(s -> { throw new IllegalArgumentException(s); })
.subscribe(v -> System.out.println("GOT VALUE"),
e -> System.out.println("ERROR: " + e));
上边代码输出如下:
ERROR: java.lang.IllegalArgumentException: foo
Exception 可以在其被传递给 onError 之前,使用 hook 进行调整。 |
|
|---|---|
Reactor,定义了一系列的能够导致“严重失败”的错误(比如 OutOfMemoryError),也可参考 Exceptions.throwIfFatal 方法。这些错误意味着 Reactor 无力处理只能抛出,无法传递下去。
还有些情况下不受检异常仍然无法传递下去(多数处于subscribe 和 request 阶段), 因为可能由于多线程竞争导致两次 onError 或 onComplete 的情况。当这种竞争发生的时候, 无法传递下去的错误信号就被“丢弃”了。这些情况仍然可以通过自定义的 hook 来搞定,见 丢弃事件的 Hooks。 |
|
|---|---|
你可能会问:“那么 受检查异常(Checked Exceptions)?”
如果你需要调用一个声明为 throws 异常的方法,你仍然需要使用 try-catch 代码块处理异常。 有几种方式:
- 捕获异常,并修复它,流序列正常继续。
- 捕获异常,并把它包装(wrap)到一个 不受检异常 中,然后抛出(中断序列)。工具类
Exceptions可用于这种方式(我们马上会讲到)。 - 如果你气我返回一个
Flux(例如在flatMap中),将异常包装在一个产生错误的Flux中:return Flux.error(checkedException)(流序列也会终止)。
Reactor 有一个工具类 Exceptions,可以确保在收到受检异常的时候将其包装(wrap)起来。
- 如果需要,可以使用
Exceptions.propagate方法来包装异常,它同样会首先调用throwIfFatal, 并且不会包装RuntimeException。 - 使用
Exceptions.unwrap方法来得到原始的未包装的异常(追溯最初的异常)。
下面是一个 map 的例子,它使用的 convert 方法会抛出 IOException:
public String convert(int i) throws IOException {
if (i > 3) {
throw new IOException("boom " + i);
}
return "OK " + i;
}
现在想象你将这个方法用于一个 map 中,你必须明确捕获这个异常,并且你的 map 方法不能再次抛出它。 所以你可以将其以 RuntimeException 的形式传递给 onError:
Flux<String> converted = Flux
.range(1, 10)
.map(i -> {
try { return convert(i); }
catch (IOException e) { throw Exceptions.propagate(e); }
});
当后边订阅上边的这个 Flux 并响应错误(比如在用户界面)的时候,如果你想处理 IOException, 你还可以再将其转换为原始的异常。如下:
converted.subscribe(
v -> System.out.println("RECEIVED: " + v),
e -> {
if (Exceptions.unwrap(e) instanceof IOException) {
System.out.println("Something bad happened with I/O");
} else {
System.out.println("Something bad happened");
}
}
);
4.8. Processors
Processors 既是一种特别的发布者(Publisher)又是一种订阅者(Subscriber)。 那意味着你可以 订阅一个 Processor(通常它们会实现 Flux),也可以调用相关方法来手动 插入数据到序列,或终止序列。
Processor 有多种类型,它们都有特别的语义规则,但是在你研究它们之前,最好问一下 自己如下几个问题:
4.8.1. 我是否需要使用 Processor?
多数情况下,你应该进行避免使用 Processor,它们较难正确使用,主要用于一些特殊场景下。
如果你觉得 Processor 适合你的使用场景,请首先看一下是否尝试过以下两种替代方式:
- 是否有一个或多个操作符的组合能够满足需求?(见 我需要哪个操作符?)
- "generator" 操作符是否能解决问题?(通常这些操作符 可以用来桥接非响应式的 API,它们提供了一个“sink”,在生成数据流序列方面, 概念上类似于
Processor)
如果看了以上替代方案,你仍然觉得需要一个 Processor,阅读 现有的 Processors 总览 这一节来了解一下不同的实现吧。
4.8.2. 使用 Sink 门面对象来线程安全地生成流
比起直接使用 Reactor 的 Processors,更好的方式是通过调用一次 sink() 来得到 Processor 的 Sink。
FluxProcessor 的 sink 是线程安全的“生产者(producer)”,因此能够在应用程序中 多线程并发地生成数据。例如,一个线程安全的序列化(serialized)的 sink 能够通过 UnicastProcessor 创建:
UnicastProcessor<Integer> processor = UnicastProcessor.create();
FluxSink<Integer> sink = processor.sink(overflowStrategy);
多个生产者线程可以并发地生成数据到以下的序列化 sink。
sink.next(n);
根据 Processor 及其配置,next 产生的溢出有两种可能的处理方式:
- 一个无限的 processor 通过丢弃或缓存自行处理溢出。
- 一个有限的 processor 阻塞在
IGNORE策略,或将overflowStrategy应用于sink。
4.8.3. 现有的 Processors 总览
Reactor Core 内置多种 Processor。这些 processor 具有不同的语法,大概分为三类。 下边简要介绍一下这三种 processor:
- 直接的(direct) (
DirectProcessor和UnicastProcessor):这些 processors 只能通过直接 调用Sink的方法来推送数据。 - 同步的(synchronous) (
EmitterProcessor和ReplayProcessor):这些 processors 既可以 直接调用Sink方法来推送数据,也可以通过订阅到一个上游的发布者来同步地产生数据。 - 异步的(asynchronous) (
WorkQueueProcessor和TopicProcessor):这些 processors 可以将从多个上游发布者得到的数据推送下去。由于使用了RingBuffer的数据结构来 缓存多个来自上游的数据,因此更加有健壮性。
异步的 processor 在实例化的时候最复杂,因为有许多不同的选项。因此它们暴露出一个 Builder 接口。 而简单的 processors 有静态的工厂方法。
DirectProcessor
DirectProcessor 可以将信号分发给零到多个订阅者(Subscriber)。它是最容易实例化的,使用静态方法 create() 即可。另一方面,它的不足是无法处理背压。所以,当 DirectProcessor 推送的是 N 个元素,而至少有一个订阅者的请求个数少于 N 的时候,就会发出一个 IllegalStateException。
一旦 Processor 终止(通常通过调用它的 Sink 的 error(Throwable) 或 complete() 方法), 虽然它允许更多的订阅者订阅它,但是会立即向它们重新发送终止信号。
UnicastProcessor
UnicastProcessor 可以使用一个内置的缓存来处理背压。代价就是它最多只能有一个订阅者。
UnicastProcessor 有多种选项,因此提供多种不同的 create 静态方法。例如,它默认是 无限的(unbounded) :如果你在在订阅者还没有请求数据的情况下让它推送数据,它会缓存所有数据。
可以通过提供一个自定义的 Queue 的具体实现传递给 create 工厂方法来改变默认行为。如果给出的队列是 有限的(bounded), 并且缓存已满,而且未收到下游的请求,processor 会拒绝推送数据。
在上边 有限的 例子中,还可以在构造 processor 的时候提供一个回调方法,这个回调方法可以在每一个 被拒绝推送的元素上调用,从而让开发者有机会清理这些元素。
EmitterProcessor
EmitterProcessor 能够向多个订阅者发送数据,并且可以对每一个订阅者进行背压处理。它本身也可以订阅一个 Publisher 并同步获得数据。
最初如果没有订阅者,它仍然允许推送一些数据到缓存,缓存大小由 bufferSize 定义。 之后如果仍然没有订阅者订阅它并消费数据,对 onNext 的调用会阻塞,直到有订阅者接入 (这时只能并发地订阅了)。
因此第一个订阅者会收到最多 bufferSize 个元素。然而之后, processor 不会重新发送(replay) 数据给后续的订阅者。这些后续接入的订阅者只能获取到它们开始订阅 之后 推送的数据。这个内部的 缓存会继续用于背压的目的。
默认情况下,如果所有的订阅者都取消了(基本意味着它们都不再订阅(un-subscribed)了), 它会清空内部缓存,并且不再接受更多的订阅者。这一点可以通过 create 静态工厂方法的 autoCancel 参数来配置。
ReplayProcessor
ReplayProcessor 会缓存直接通过自身的 Sink 推送的元素,以及来自上游发布者的元素, 并且后来的订阅者也会收到重发(replay)的这些元素。
可以通过多种配置方式创建它:
- 缓存一个元素(
cacheLast)。 - 缓存一定个数的历史元素(
create(int)),所有的历史元素(create())。 - 缓存基于时间窗期间内的元素(
createTimeout(Duration))。 - 缓存基于历史个数和时间窗的元素(
createSizeOrTimeout(int, Duration))。
TopicProcessor
TopicProcessor 是一个异步的 processor,它能够重发来自多个上游发布者的元素, 这需要在创建它的时候配置 shared (见 build() 的 share(boolean) 配置)。
注意,如果你企图在并发环境下通过并发的上游 Publisher 调用 TopicProcessor 的 onNext、 onComplete,或 onError 方法,就必须配置 shared。
否则,并发调用就是非法的,从而 processor 是完全兼容响应式流规范的。
TopicProcessor 能够对多个订阅者发送数据。它通过对每一个订阅者关联一个线程来实现这一点, 这个线程会一直执行直到 processor 发出 onError 或 onComplete 信号,或关联的订阅者被取消。 最多可以接受的订阅者个数由构造者方法 executor 指定,通过提供一个有限线程数的 ExecutorService 来限制这一个数。
这个 processor 基于一个 RingBuffer 数据结构来存储已发送的数据。每一个订阅者线程 自行管理其相关的数据在 RingBuffer 中的索引。
这个 processor 也有一个 autoCancel 构造器方法:如果设置为 true (默认的),那么当 所有的订阅者取消之后,源 Publisher(s) 也就被取消了。
WorkQueueProcessor
WorkQueueProcessor 也是一个异步的 processor,也能够重发来自多个上游发布者的元素, 同样在创建时需要配置 shared (它多数构造器配置与 TopicProcessor 相同)。
它放松了对响应式流规范的兼容,但是好处就在于相对于 TopicProcessor 来说需要更少的资源。 它仍然基于 RingBuffer,但是不再要求每一个订阅者都关联一个线程,因此相对于 TopicProcessor 来说更具扩展性。
代价在于分发模式有些区别:来自订阅者的请求会汇总在一起,并且这个 processor 每次只对一个 订阅者发送数据,因此需要循环(round-robin)对订阅者发送数据,而不是一次全部发出的模式。
| 无法保证完全公平的循环分发。 | |
|---|---|
WorkQueueProcessor 多数构造器方法与 TopicProcessor 相同,比如 autoCancel、share, 以及 waitStrategy。下游订阅者的最大数目同样由构造器 executor 配置的 ExecutorService 决定。
你最好注意不要有太多订阅者订阅 WorkQueueProcessor,因为这 会锁住 processor。 如果你需要限制订阅者数量,最好使用一个 ThreadPoolExecutor 或 ForkJoinPool。这个 processor 能够检测到(线程池)容量并在订阅者过多时抛出异常。 |
|
|---|---|
翻译建议 - "Reactor 核心特性"
5. 对 Kotlin 的支持
5.1. 简介
Kotlin 是一种运行于 JVM(及其他平台)上的静态(statically-typed)语言。 使用它可以在拥有与现有 Java 库良好https://kotlinlang.org/docs/reference/java-interop.html[互操作性] 的同时编写简介优雅的代码。
本小节介绍了 Reactor 3.1 如何能够完美支持 Kotlin。
5.2. 前提
Kotlin 支持 Kotlin 1.1+ 及依赖 kotlin-stdlib (或 kotlin-stdlib-jre7 / kotlin-stdlib-jre8 之一)
5.3. 扩展
多亏了其良好的 Java 互操作性 以及 Kotlin 扩展(extensions), Reactor Kotlin APIs 既可使用 Java APIs,还能够收益于一些 Reactor 内置的专门支持 Kotlin 的 APIs。
注意 Kotlin 的扩展需要 import 才能够使用。所以比如 Throwable.toFlux 的 Kotlin 扩展必须在 import reactor.core.publisher.toFlux 后才可使用。多数场景下 IDE 应该能够自动给出这种类似 static import 的建议。 |
|
|---|---|
例如,https://kotlinlang.org/docs/reference/inline-functions.html#reified-type-parameters[Kotlin 参数类型推导(reified type parameters)] 对于 JVM 的 通用类型擦除(generics type erasure)提供了一种变通解决方案, Reactor 就可以通过扩展(extension)来应用到这种特性。
下面是对“Reactor with Java”和“Reactor with Kotlin + extensions”的比较:
| Java | Kotlin + extensions |
|---|---|
Mono.just("foo") |
"foo".toMono() |
Flux.fromIterable(list) |
list.toFlux() |
Mono.error(new RuntimeException()) |
RuntimeException().toMono() |
Flux.error(new RuntimeException()) |
RuntimeException().toFlux() |
flux.ofType(Foo.class) |
flux.ofType<Foo>() or flux.ofType(Foo::class) |
StepVerifier.create(flux).verifyComplete() |
flux.test().verifyComplete() |
可参考 Reactor KDoc API 中详细的关于 Kotlin 扩展的文档。
5.4. Null 值安全
Kotlin的一个关键特性就是 null 值安全 ——从而可以在编译时处理 null 值,而不是在运行时抛出著名的 NullPointerException。 这样,通过“可能为空(nullability)”的声明,以及能够表明“有值或空值”的语法(避免使用类似 Optional 来进行包装),使得应用程序更加安全。(Kotlin允许在函数参数中使用可能为空的值, 请参考 comprehensive guide to Kotlin null-safety)
尽管 Java 的类型系统不允许这样的 null 值安全的表达方式, Reactor now provides null-safety 对所有 Reactor API 通过工具友好的(tooling-friendly)注解(在 reactor.util.annotation 包中定义)来支持。 默认情况下,Java APIs 用于 Kotlin 的话会被作为 平台类型(platform types) 而放松对 null 的检查。 Kotlin 对 JSR 305 注解的支持 + Reactor 可为空(nullability)的注解,为所有 Reactor API 和 Kotlin 开发者确保“null 值安全”的特性 (在编译期处理 null 值)。
JSR 305 的检查可以通过增加 -Xjsr305 编译参数进行配置: -Xjsr305={strict|warn|ignore}。
对于 kotlin 1.1.50+,默认的配置为 -Xjsr305=warn。如果希望 Reactor API 能够全面支持 null 值安全 则需要配置为 strict。不过你可以认为这是实验性的(experimental),因为 Reactor API “可能为空” 的声明可能甚至在小版本的发布中都会不断改进,而且将来也可能增加新的检查。
| 目前尚不支持通用类型参数、可变类型以及数组元素的“可为空”。不过应该包含在接下来的发布中,最新信息请看 这个issues。 | |
|---|---|
翻译建议 - "对 Kotlin 的支持"
6. 测试
无论你是编写了一个简单的 Reactor 操作链,还是开发了自定义的操作符,对它进行 自动化的测试总是一个好主意。
Reactor 内置一些专门用于测试的元素,放在一个专门的 artifact 里: reactor-test。 你可以在 on Github 的 reactor-core 库里找到这个项目。
如果要用它来进行测试,添加 scope 为 test 的依赖。
reactor-test 用 Maven 配置 <dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
如果你使用了 BOM,你不需要指定 <version>。 |
|
|---|---|
reactor-test 用 Gradle 配置 dependencies
dependencies {
testCompile 'io.projectreactor:reactor-test'
}
reactor-test 的两个主要用途:
- 使用
StepVerifier一步一步地测试一个给定场景的序列。 - 使用
TestPublisher生成数据来测试下游的操作符(包括你自己的operator)。
6.1. 使用 StepVerifier 来测试
最常见的测试 Reactor 序列的场景就是定义一个 Flux 或 Mono,然后在订阅它的时候测试它的行为。
当你的测试关注于每一次的事件的时候,就非常容易转化为使用 StepVerifier 的测试场景: 下一个期望的事件是什么?你是否期望使用 Flux 来发出一个特别的值?或者接下来 300ms 什么都不做?所有这些都可以使用 StepVerifier API 来表示。
例如,你可能会使用如下的工具方法来包装一个 Flux:
public <T> Flux<T> appendBoomError(Flux<T> source) {
return source.concatWith(Mono.error(new IllegalArgumentException("boom")));
}
要测试它的话,你需要校验如下内容:
我希望这个
Flux先发出foo,然后发出bar,然后 生成一个内容为 boom 的错误。 最后订阅并校验它们。
使用 StepVerifier API 来表示以上的验证过程:
@Test
public void testAppendBoomError() {
Flux<String> source = Flux.just("foo", "bar");
StepVerifier.create(
appendBoomError(source))
.expectNext("foo")
.expectNext("bar")
.expectErrorMessage("boom")
.verify();
}
由于被测试方法需要一个 Flux,定义一个简单的 Flux 用于测试。 |
|
|---|---|
创建一个 StepVerifier 构造器来包装和校验一个 Flux。 |
|
传进来需要测试的 Flux(即待测方法的返回结果)。 |
|
第一个我们期望的信号是 onNext,它的值为 foo。 |
|
最后我们期望的是一个终止信号 onError,异常内容应该为 boom。 |
|
不要忘了使用 verify() 触发测试。 |
API 是一个构造器,通过传入一个要测试的序列来创建一个 StepVerifier。从而你可以:
- 表示你 期望 发生的下一个信号。如果收到其他信号(或者信号与期望不匹配),整个测试就会 失败(
AssertionError)。例如你可能会用到expectNext(T...)或expectNextCount(long)。 - 消费 下一个信号。当你想要跳过部分序列或者当你想对信号内容进行自定义的
assertion的时候会用到它(比如要校验是否有一个onNext信号,并校验对应发出的元素是否是一个 size 为 5 的 List)。你可能会用到consumeNextWith(Consumer<T>)。 - 更多样的操作 比如暂停或运行一段代码。比如,你想对测试状态或内容进行调整或处理, 你可能会用到
thenAwait(Duration)和then(Runnable)。
对于终止事件,相应的期望方法(expectComplete()、expectError(),及其所有的变体方法) 使用之后就不能再继续增加别的期望方法了。最后你只能对 StepVerifier 进行一些额外的配置并 触发校验(通常调用 verify() 及其变体方法)。
从 StepVerifier 内部来看,它订阅了待测试的 Flux 或 Mono,然后将序列中的每个信号与测试 场景的期望进行比对。如果匹配的话,测试成功。如果有不匹配的情况,则抛出 AssertionError 异常。
请记住是 verify() 触发了校验过程。这个 API 还有一些结合了 verify() 与期望的终止信号 的方法:verifyComplete()、verifyError()、verifyErrorMessage(String) 等。 |
|
|---|---|
注意,如果有一个传入 lambda 的期望方法抛出了 AssertionError,会被报告为测试失败。 这可用于自定义 assertion。
默认情况下,verify() 方法(及同源的 verifyThenAssertThat、verifyComplete()等) 没有超时的概念。它可能会永远阻塞住。你可以使用 StepVerifier.setDefaultTimeout(Duration) 来设置一个全局的超时时间,或使用 verify(Duration) 指定。 |
|
|---|---|
6.2. 操控时间
StepVerifier 可以用来测试基于时间的操作符,从而避免测试的长时间运行。可以使用构造器 StepVerifier.withVirtualTime 达到这一点。
示例如下:
StepVerifier.withVirtualTime(() -> Mono.delay(Duration.ofDays(1)))
//... 继续追加期望方法
虚拟时间(virtual time) 的功能会在 Reactor 的调度器(Scheduler)工厂方法中插入一个自定义的 调度器。这些基于时间的操作符通常默认使用 Schedulers.parallel() 调度器。(虚拟时间的) 技巧在于使用一个 VirtualTimeScheduler 来代替默认调度器。然而一个重要的前提就是,只有在初始化 虚拟时间调度器之后的操作符才会起作用。
为了提高 StepVerifier 正常起作用的概率,它一般不接收一个简单的 Flux 作为输入,而是接收 一个 Supplier,从而可以在配置好订阅者 之后 “懒创建”待测试的 flux。
要注意的是,Supplier<Publisher<T>> 可用于“懒创建”,否则不能保证虚拟时间 能完全起作用。尤其要避免提前实例化 Flux,要在 Supplier 中用 lambda 创建并返回 Flux 变量。 |
|
|---|---|
有两种处理时间的期望方法,无论是否配置虚拟时间都是可用的:
thenAwait(Duration)暂停校验步骤(允许信号延迟发出)。expectNoEvent(Duration)同样让序列持续一定的时间,期间如果有 任何 信号发出则测试失败。
两个方法都会基于给定的持续时间暂停线程的执行,如果是在虚拟时间模式下就相应地使用虚拟时间。
expectNoEvent 将订阅(subscription)也认作一个事件。假设你用它作为第一步,如果检测 到有订阅信号,也会失败。这时候可以使用 expectSubscription().expectNoEvent(duration) 来代替。 |
|
|---|---|
为了快速校验前边提到的 Mono.delay,我们可以这样完成代码:
StepVerifier.withVirtualTime(() -> Mono.delay(Duration.ofDays(1)))
.expectSubscription()
.expectNoEvent(Duration.ofDays(1))
.expectNext(0)
.verifyComplete();
| 如上 tip。 | |
|---|---|
| 期待一天内没有信号发生。 | |
然后期待一个 next 信号为 0。 |
|
| 然后期待完成(同时触发校验)。 |
我们也可以使用 thenAwait(Duration.ofDays(1)),但是 expectNoEvent 的好处是 能够验证在此之前不会发生什么。
注意 verify() 返回一个 Duration,这是整个测试的 真实时间。
虚拟时间并非银弹。请记住 所有的 调度器都会被替换为 VirtualTimeScheduler。 有些时候你可以锁定校验过程,因为虚拟时钟在遇到第一个期望校验之前并不会开始,所以对于 “无数据“的期望校验也必须能够运行在虚拟时间模式下。在无限序列中,虚拟时间模式的发挥 空间也很有限,因为它可能导致线程(序列的发出和校验的运行都在这个线程上)卡住。 |
|
|---|---|
6.3. 使用 StepVerifier 进行“后校验”
当配置完你测试场景的最后的期望方法后,你可以使用 verifyThenAssertThat() 来代替 verify() 触发执行后的校验。
verifyThenAssertThat() 返回一个 StepVerifier.Assertions 对象,你可以用它来校验 整个测试场景成功刚结束后的一些状态(它也会调用 verify())。典型应用就是校验有多少 元素被操作符丢弃(参考 Hooks)。
6.4. 测试 Context
更多关于 Context 的内容请参考 增加一个 Context 到响应式序列。
StepVerifier 有一些期望方法可以用来测试 Context:
expectAccessibleContext: 返回一个ContextExpectations对象,你可以用它来在Context上配置期望校验。一定记住要调用then()来返回到对序列的期望校验上来。expectNoAccessibleContext: 是对“没有Context”的校验。通常用于 被测试的Publisher并不是一个响应式的,或没有任何操作符能够传递Context(比如一个generate的Publisher).
此外,还可以用 StepVerifierOptions 方法传入一个测试用的初始 Context 给 StepVerifier, 从而可以创建一个校验(verifier)。
这些特性通过下边的代码演示:
StepVerifier.create(Mono.just(1).map(i -> i + 10),
StepVerifierOptions.create().withInitialContext(Context.of("foo", "bar")))
.expectAccessibleContext()
.contains("foo", "bar")
.then()
.expectNext(11)
.verifyComplete();
使用 StepVerifierOptions 创建 StepVerifier 并传入初始 Context。 |
|
|---|---|
开始对 Context 进行校验,这里只是确保 Context 正常传播了。 |
|
对 Context 进行校验的例子:比如验证是否包含一个 "foo" - "bar" 键值对。 |
|
使用 then() 切换回对序列的校验。 |
|
不要忘了用 verify() 触发整个校验过程。 |
6.5. 用 TestPublisher 手动发出元素
对于更多高级的测试,如果能够完全掌控源发出的数据就会方便很多,因为这样就可以在测试的 时候更加有的放矢地发出想测的数据。
另一种情况就是你实现了自己的操作符,然后想校验它的行为——尤其是在源不稳定的时候——是否符合响应式流规范。
reactor-test 提供了 TestPublisher 类来应对这两种需求。这个类本质上是一个 Publisher<T>, 你可以通过可编程的方式来用它发出各种信号:
next(T)以及next(T, T...)发出 1-n 个onNext信号。emit(T...)起同样作用,并且会执行complete()。complete()会发出终止信号onComplete。error(Throwable)会发出终止信号onError。
使用 create 工厂方法就可以得到一个正常的 TestPublisher。而使用 createNonCompliant 工厂方法可以创建一个“不正常”的 TestPublisher。后者需要传入由 TestPublisher.Violation 枚举指定的一组选项,这些选项可用于告诉 publisher 忽略哪些问题。枚举值有:
REQUEST_OVERFLOW: 允许next在请求不足的时候也可以调用,而不会触发IllegalStateException。ALLOW_NULL: 允许next能够发出一个null值而不会触发NullPointerException。CLEANUP_ON_TERMINATE: 可以重复多次发出终止信号,包括complete()、error()和emit()。
最后,TestPublisher 还可以用不同的 assert* 来跟踪其内部的订阅状态。
使用转换方法 flux() 和 mono() 可以将其作为 Flux 和 Mono 来使用。
6.6. 用 PublisherProbe 检查执行路径
当构建复杂的操作链时,可能会有多个子序列,从而导致多个执行路径。
多数时候,这些子序列会生成一个足够明确的 onNext 信号,你可以通过检查最终结果 来判断它是否执行。
考虑下边这个方法,它构建了一条操作链,并使用 switchIfEmpty 方法在源为空的情况下, 替换成另一个源。
public Flux<String> processOrFallback(Mono<String> source, Publisher<String> fallback) {
return source
.flatMapMany(phrase -> Flux.fromArray(phrase.split("\\s+")))
.switchIfEmpty(fallback);
}
很容易就可以测试出 switchIfEmpty 的哪一个逻辑分支被使用了,如下:
@Test
public void testSplitPathIsUsed() {
StepVerifier.create(processOrFallback(Mono.just("just a phrase with tabs!"),
Mono.just("EMPTY_PHRASE")))
.expectNext("just", "a", "phrase", "with", "tabs!")
.verifyComplete();
}
@Test
public void testEmptyPathIsUsed() {
StepVerifier.create(processOrFallback(Mono.empty(), Mono.just("EMPTY_PHRASE")))
.expectNext("EMPTY_PHRASE")
.verifyComplete();
}
但是如果例子中的方法返回的是一个 Mono<Void> 呢?它等待源发送结束,执行一个额外的任务, 然后就结束了。如果源是空的,则执行另一个备用的类似于 Runnable 的任务,如下:
private Mono<String> executeCommand(String command) {
return Mono.just(command + " DONE");
}
public Mono<Void> processOrFallback(Mono<String> commandSource, Mono<Void> doWhenEmpty) {
return commandSource
.flatMap(command -> executeCommand(command).then())
.switchIfEmpty(doWhenEmpty);
}
then() 方法会忽略 command,它只关心是否结束。 |
|
|---|---|
| 两个都是空序列,这个时候如何区分(哪边执行了)呢? |
为了验证执行路径是经过了 doWhenEmpty 的,你需要编写额外的代码,比如你需要一个这样的 Mono<Void>:
- 能够捕获到它被订阅的事实。
- 以上事实需要在整个执行结束 之后 再进行验证。
在 3.1 版本以前,你需要为每一种状态维护一个 AtomicBoolean 变量,然后在相应的 doOn* 回调中观察它的值。这需要添加不少的额外代码。好在,版本 3.1.0 之后可以使用 PublisherProbe来做, 如下:
@Test
public void testCommandEmptyPathIsUsed() {
PublisherProbe<Void> probe = PublisherProbe.empty();
StepVerifier.create(processOrFallback(Mono.empty(), probe.mono()))
.verifyComplete();
probe.assertWasSubscribed();
probe.assertWasRequested();
probe.assertWasNotCancelled();
}
| 创建一个探针(probe),它会转化为一个空序列。 | |
|---|---|
在需要使用 Mono<Void> 的位置调用 probe.mono() 来替换为探针。 |
|
| 序列结束之后,你可以用这个探针来判断序列是如何使用的,你可以检查是它从哪(条路径)被订阅的… | |
| …对于请求也是一样的… | |
| …以及是否被取消了。 |
你也可以在使用 Flux<T> 的位置通过调用 .flux() 方法来放置探针。如果你既需要用探针检查执行路径 还需要它能够发出数据,你可以用 PublisherProbe.of(Publisher) 方法包装一个 Publisher<T> 来搞定。
7. 调试 Reactor
从命令式和同步式编程切换到响应式和异步式编程有时候是令人生畏的。 学习曲线中最陡峭的异步就是出错时如何分析和调试。
在命令式世界,调试通常都是非常直观的:直接看 stack trace 就可以找到问题出现的位置, 以及:是否问题责任全部出在你自己的代码?问题是不是发生在某些库代码?如果是, 那你的哪部分代码调用了库,是不是传参不合适导致的问题?
7.1. 典型的 Reactor Stack Trace
当你切换到异步代码,事情就变得复杂的多了。
看一下下边的 stack trace:
一段典型的 Reactor stack trace
java.lang.IndexOutOfBoundsException: Source emitted more than one item
at reactor.core.publisher.MonoSingle$SingleSubscriber.onNext(MonoSingle.java:120)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.emitScalar(FluxFlatMap.java:380)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.onNext(FluxFlatMap.java:349)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.onNext(FluxMapFuseable.java:119)
at reactor.core.publisher.FluxRange$RangeSubscription.slowPath(FluxRange.java:144)
at reactor.core.publisher.FluxRange$RangeSubscription.request(FluxRange.java:99)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.request(FluxMapFuseable.java:172)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.onSubscribe(FluxFlatMap.java:316)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.onSubscribe(FluxMapFuseable.java:94)
at reactor.core.publisher.FluxRange.subscribe(FluxRange.java:68)
at reactor.core.publisher.FluxMapFuseable.subscribe(FluxMapFuseable.java:67)
at reactor.core.publisher.FluxFlatMap.subscribe(FluxFlatMap.java:98)
at reactor.core.publisher.MonoSingle.subscribe(MonoSingle.java:58)
at reactor.core.publisher.Mono.subscribeWith(Mono.java:2668)
at reactor.core.publisher.Mono.subscribe(Mono.java:2629)
at reactor.core.publisher.Mono.subscribe(Mono.java:2604)
at reactor.core.publisher.Mono.subscribe(Mono.java:2582)
at reactor.guide.GuideTests.debuggingCommonStacktrace(GuideTests.java:722)
这里边有好多信息,我们得到了一个 IndexOutOfBoundsException,内容是 "源发出了 不止一个元素"。
我们也许可以很快假定这个源是一个 Flux/Mono,并通过下一行提到的 MonoSingle 确定是 Mono。 看上去是来自一个 single 操作符的抱怨。
查看 Javadoc 中关于操作符 Mono#single 的说明,我们看到 single 有一个规定: 源必须只能发出一个元素。看来是有一个源发出了多于一个元素,从而违反了这一规定。
我们可以更进一步找出那个源吗?下边的这些内容帮不上什么忙,只是打印了一些内部的似乎是一个响应式链的信息, 主要是一些 subscribe 和 request 的调用。
粗略过一下这些行,我们至少可以勾画出一个大致的出问题的链:大概涉及一个 MonoSingle、一个 FluxFlatMap,以及一个 FluxRange(每一个都对应 trace 中的几行,但总体涉及这三个类)。 所以难道是 range().flatMap().single() 这样的链?
但是如果在我们的应用中多处都用到这一模式,那怎么办?通过这些还是不能确定什么, 搜索 single 也找不到问题所在。最后一行指向了我们的代码。我们似乎终于接近真相了。
不过,等等… 当我们找到源码文件,我们只能找到一个已存在的 Flux 被订阅了,如下:
toDebug.subscribe(System.out::println, Throwable::printStackTrace);
所有这些都发生在订阅时,但是 Flux 本身没有在这里 声明 。更糟的是, 当我们找到变量声明的地方,我们看到:
public Mono<String> toDebug; //请忽略 public 的属性
变量声明的地方并没有 实例化 。我们必须做最坏的打算,那就是在这个应用中, 可能在几个不同的代码路径上对这个变量赋了值,但我们不确定是哪一个导致了问题。
| 这是一种 Reactor 运行时错误,而不是编译错误。 | |
|---|---|
我们希望找到的是操作符在哪里添加到操作链上的 —— 也就是 Flux 在哪里 声明的。我们通常说这个 Flux 是被 组装(assembly) 的。
7.2. 开启调试模式
即便 stack trace 能够对有些许经验的开发者传递一些信息,但是在一些复杂的情况下, 这并不是一种理想的方式。
幸运的是,Reactor 内置了一种面向调试的能力—— 操作期测量(assembly-time instrumentation)。
这通过 在应用启动的时候 (或至少在有问题的 Flux 或 Mono 实例化之前) 加入自定义的 Hook.onOperator 钩子(hook),如下:
Hooks.onOperatorDebug();
这行代码——通过包装操作符的构造方法,并在此捕捉 stack trace——来监测对这个 Flux(或 Mono)的操作符的调用(也就是“组装”链的地方)。由于这些在 操作链被声明的地方就搞定,这个 hook 应该在 早于 声明的时候被激活, 最保险的方式就是在你程序的最开始就激活它。
之后,如果发生了异常,导致失败的操作符能够找到捕捉点并补充 stack trace。
在下一小节,我们看一下 stack trace 会有什么不同,以及如何对其进行分析。
7.3. 阅读调试模式的 Stack Trace
我们在对上边的例子激活 operatorStacktrace 调试功能后,stack trace 如下:
java.lang.IndexOutOfBoundsException: Source emitted more than one item
at reactor.core.publisher.MonoSingle$SingleSubscriber.onNext(MonoSingle.java:120)
at reactor.core.publisher.FluxOnAssembly$OnAssemblySubscriber.onNext(FluxOnAssembly.java:314)
...
...
at reactor.core.publisher.Mono.subscribeWith(Mono.java:2668)
at reactor.core.publisher.Mono.subscribe(Mono.java:2629)
at reactor.core.publisher.Mono.subscribe(Mono.java:2604)
at reactor.core.publisher.Mono.subscribe(Mono.java:2582)
at reactor.guide.GuideTests.debuggingActivated(GuideTests.java:727)
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Assembly trace from producer [reactor.core.publisher.MonoSingle] :
reactor.core.publisher.Flux.single(Flux.java:5335)
reactor.guide.GuideTests.scatterAndGather(GuideTests.java:689)
reactor.guide.GuideTests.populateDebug(GuideTests.java:702)
org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:55)
org.junit.rules.RunRules.evaluate(RunRules.java:20)
Error has been observed by the following operator(s):
|_ Flux.single(TestWatcher.java:55)
| 这一条是新的:可以发现外层操作符捕捉到了 stack trace。 | |
|---|---|
| 第一部分的 stack trace 多数与上边一样,显示了操作符内部的信息(所以省略了这一块)。 | |
| 从这里开始,是在调试模式下显示的内容。 | |
| 首先我们获得了关于操作符组装的信息。 | |
| 以及错误沿着操作链传播的轨迹(从错误点到订阅点)。 | |
| 每一个看到这个错误的操作符都会列出,包括类和行信息。如果操作符是在 Reactor 源码内部组装的,行信息会被忽略。 |
可见,捕获的 stack trace 作为 OnAssemblyException 添加到原始错误信息的之后。有两部分, 但是第一部分更加有意思。它显示了操作符触发异常的路径。这里显示的是 scatterAndGather 方法中的 single 导致的问题,而 scatterAndGather 方法是在 JUnit 中被 populateDebug 方法调用的。
既然我们已经有足够的信息来查出罪魁祸首,我们就来看一下 scatterAndGather 方法吧:
private Mono<String> scatterAndGather(Flux<String> urls) {
return urls.flatMap(url -> doRequest(url))
.single();
}
找到了,就是这个 single。 |
|
|---|---|
现在我们可以发现错误的根源是将多个 HTTP 请求转化为 URLs 的 flatMap 方法后边接的是 single, 这太严格了。使用 git blame 找到代码作者,并同他讨论过后,发现他是本来是想用不那么严格的 take(1) 方法的。
我们解决了问题。
错误被以下这些操作符观察(observed)了:
调试信息的第二部分在这个例子中意义不大,因为错误实际发生在最后一个操作符上(离 subscribe 最近的一个)。 另一个例子可能更加清楚:
FakeRepository.findAllUserByName(Flux.just("pedro", "simon", "stephane"))
.transform(FakeUtils1.applyFilters)
.transform(FakeUtils2.enrichUser)
.blockLast();
现在想象一下在 findAllUserByName 内部有个 map 方法报错了。我们可能会看到如下的 trace:
Error has been observed by the following operator(s):
|_ Flux.map(FakeRepository.java:27)
|_ Flux.map(FakeRepository.java:28)
|_ Flux.filter(FakeUtils1.java:29)
|_ Flux.transform(GuideDebuggingExtraTests.java:41)
|_ Flux.elapsed(FakeUtils2.java:30)
|_ Flux.transform(GuideDebuggingExtraTests.java:42)
这与链上收到错误通知的操作符是一致:
- 异常源自第一个
map。 - 被第二个
map看到(都在findAllUserByName方法中)。 - 接着被一个
filter和一个transform看到,说明链的这部分是由一个可重复使用的转换方法组装的 (这里是applyFilters工具方法)。 - 最后被一个
elapsed和一个transform看到,类似的,elapsed由第二个转换方法(enrichUser) 组装。
用这种形式的检测方式构造 stack trace 是成本较高的。也因此这种调试模式作为最终大招, 只应该在可控的方式下激活。
7.3.1. 用 checkpoint() 方式替代
调试模式是全局性的,会影响到程序中每一个组装到一个 Flux 或 Mono 的操作符。好处在于可以进行 事后调试(after-the-fact debugging):无论错误是什么,我们都会得到足够的调试信息。
就像前边见到的那样,这种全局性的调试会因为成本较高而影响性能(其影响在于生成的 stack traces 数量)。 如果我们能大概定位到疑似出问题的操作符的话就可以不用花那么大的成本。然而,问题出现后, 我们通常无法定位到哪一个操作符可能存在问题,因为缺少一些 trace 信息,我们得修改代码, 打开调试模式,期望能够复现问题。
这种情况下,我们需要切换到调试模式,并进行一些必要的准备工作以便能够更好的发现复现的问题, 并捕捉到所有的信息。(译者加:这两段感觉有点废话。。。)
如果你能确定是在你的代码中组装的响应式链存在问题,而且程序的可服务性又是很重要的, 那么你可以 使用 checkpoint() 操作符,它有两种调试技术可用。
你可以把这个操作符加到链中。这时 checkpoint 操作符就像是一个 hook,但只对它所在的链起作用。
还有一个 checkpoint(String) 的方法变体,你可以传入一个独特的字符串以方便在 assembly traceback 中识别信息。 这样会省略 stack trace,你可以依赖这个字符串(以下改称“定位描述符”)来定位到组装点。checkpoint(String) 比 checkpoint 有更低的执行成本。
checkpoint(String) 在它的输出中包含 "light" (可以方便用于搜索),如下所示:
...
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Assembly site of producer [reactor.core.publisher.FluxElapsed] is identified by light checkpoint [light checkpoint identifier].
最后的但同样重要的是,如果你既想通过 checkpoint 添加定位描述符,同时又依赖于 stack trace 来定位组装点,你可以使用 checkpoint("description", true) 来实现这一点。这时回溯信息又出来了, 同时附加了定位描述符,如下例所示:
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Assembly trace from producer [reactor.core.publisher.ParallelSource], described as [descriptionCorrelation1234] :
reactor.core.publisher.ParallelFlux.checkpoint(ParallelFlux.java:174)
reactor.core.publisher.FluxOnAssemblyTest.parallelFluxCheckpointDescription(FluxOnAssemblyTest.java:159)
Error has been observed by the following operator(s):
|_ ParallelFlux.checkpointnull
descriptionCorrelation1234 是通过 checkpoint 给出的定位描述符。 |
|
|---|---|
定位描述符可以是静态的字符串、或人类可读的描述、或一个 correlation ID(例如, 来自 HTTP 请求头的信息)。
当全局调试模式和 checkpoint() 都开启的时候,checkpoint 的 stacks 输出会作为 suppressed 错误输出,按照声明顺序添加在操作符图(graph)的后面。 |
|
|---|---|
7.4. 记录流的日志
除了基于 stack trace 的调试和分析,还有一个有效的工具可以跟踪异步序列并记录日志。
就是 log() 操作符。将其加到操作链上之后,它会读(只读,peek)每一个 在其上游的 Flux 或 Mono 事件(包括 onNext、onError、 onComplete, 以及 订阅、 取消、和 请求)。
边注:关于 logging 的具体实现
log 操作符通过 SLF4J 使用类似 Log4J 和 Logback 这样的公共的日志工具, 如果 SLF4J 不存在的话,则直接将日志输出到控制台。
控制台使用 System.err 记录 WARN 和 ERROR 级别的日志,使用 System.out 记录其他级别的日志。
如果你喜欢使用 JDK java.util.logging,在 3.0.x 你可以设置 JDK 的系统属性 reactor.logging.fallback。
假设我们配置并激活了 logback,以及一个形如 range(1,10).take(3) 的操作链。通过将 log() 放在 take 之前, 我们就可以看到它内部是如何运行的,以及什么样的事件会向上游传播给 range,如下所示:
Flux<Integer> flux = Flux.range(1, 10)
.log()
.take(3);
flux.subscribe();
输出如下(通过 logger 的 console appender):
10:45:20.200 [main] INFO reactor.Flux.Range.1 - | onSubscribe([Synchronous Fuseable] FluxRange.RangeSubscription)
10:45:20.205 [main] INFO reactor.Flux.Range.1 - | request(unbounded)
10:45:20.205 [main] INFO reactor.Flux.Range.1 - | onNext(1)
10:45:20.205 [main] INFO reactor.Flux.Range.1 - | onNext(2)
10:45:20.205 [main] INFO reactor.Flux.Range.1 - | onNext(3)
10:45:20.205 [main] INFO reactor.Flux.Range.1 - | cancel()
这里,除了 logger 自己的格式(时间、线程、级别、消息),log() 操作符 还输出了其他一些格式化的东西:
reactor.Flux.Range.1 是自动生成的日志 类别(category),以防你在操作链中多次使用 同一个操作符。通过它你可以分辨出来是哪个操作符的事件(这里是 range 的)。 你可以调用 log(String) 方法用自定义的类别替换这个标识符。在几个用于分隔的字符之后, 打印出了实际的事件。这里是一个 onSubscribe 调用、一个 request 调用、三个 onNext 调用, 以及一个 cancel 调用。对于第一行的 onSubscribe,我们知道了 Subscriber 的具体实现, 通常与操作符指定的实现是一致的,在方括号内有一些额外信息,包括这个操作符是否能够 通过同步或异步融合(fusion,具体见附录 [microfusion])的方式进行自动优化。 |
|
|---|---|
| 第二行,我们可以看到是一个由下游传播上来的个数无限的请求。 | |
| 然后 range 一下发出三个值。 | |
最后一行,我们看到了 cancel()。 |
最后一行,(4),最有意思。我们看到 take 在这里发挥作用了。在它拿到足够的元素之后, 就将序列切断了。简单来说,take() 导致源在发出用户请求的数量后 cancel() 了。
翻译建议 - "调试 Reactor"
8. 高级特性与概念
这一章涉及如下的 Reactor 的高级特性与概念:
- 打包重用操作符
- Hot vs Cold
- 使用
ConnectableFlux对多个订阅者进行广播 - 三种分批处理方式
- 使用
ParallelFlux进行并行处理 - 替换默认的
Schedulers - 使用全局的 Hooks
- 增加一个 Context 到响应式序列
- 空值安全
8.1. 打包重用操作符
从代码整洁的角度来说,重用代码是一个好办法。Reactor 提供了几种帮你打包重用代码的方式, 主要通过使用操作符或者常用的“操作符组合”的方法来实现。如果你觉得一段操作链很常用, 你可以将这段操作链打包封装后备用。
8.1.1. 使用 transform 操作符
transform 操作符可以将一段操作链封装为一个函数式(function)。这个函数式能在操作期(assembly time) 将被封装的操作链中的操作符还原并接入到调用 transform 的位置。这样做和直接将被封装的操作符 加入到链上的效果是一样的。示例如下:
Function<Flux<String>, Flux<String>> filterAndMap =
f -> f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.transform(filterAndMap)
.subscribe(d -> System.out.println("Subscriber to Transformed MapAndFilter: "+d));
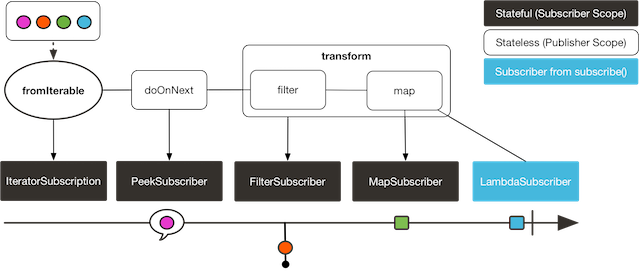
上边例子的输出如下:
blue
Subscriber to Transformed MapAndFilter: BLUE
green
Subscriber to Transformed MapAndFilter: GREEN
orange
purple
Subscriber to Transformed MapAndFilter: PURPLE
8.1.2. 使用 compose 操作符
compose 操作符与 transform 类似,也能够将几个操作符封装到一个函数式中。 主要的区别就是,这个函数式作用到原始序列上的话,是 基于每一个订阅者的(on a per-subscriber basis) 。这意味着它对每一个 subscription 可以生成不同的操作链(通过维护一些状态值)。 如下例所示:
AtomicInteger ai = new AtomicInteger();
Function<Flux<String>, Flux<String>> filterAndMap = f -> {
if (ai.incrementAndGet() == 1) {
return f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
}
return f.filter(color -> !color.equals("purple"))
.map(String::toUpperCase);
};
Flux<String> composedFlux =
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.compose(filterAndMap);
composedFlux.subscribe(d -> System.out.println("Subscriber 1 to Composed MapAndFilter :"+d));
composedFlux.subscribe(d -> System.out.println("Subscriber 2 to Composed MapAndFilter: "+d));
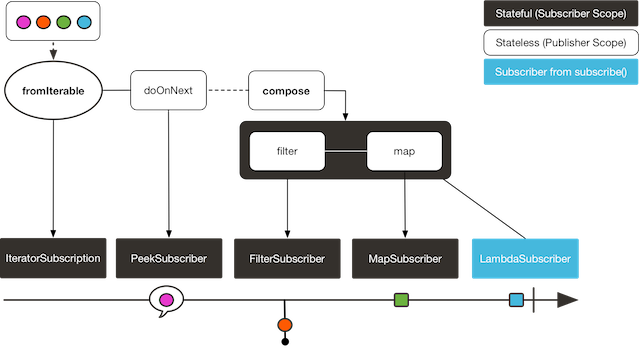
上边的例子输出如下:
blue
Subscriber 1 to Composed MapAndFilter :BLUE
green
Subscriber 1 to Composed MapAndFilter :GREEN
orange
purple
Subscriber 1 to Composed MapAndFilter :PURPLE
blue
Subscriber 2 to Composed MapAndFilter: BLUE
green
Subscriber 2 to Composed MapAndFilter: GREEN
orange
Subscriber 2 to Composed MapAndFilter: ORANGE
purple
8.2. Hot vs Cold
到目前为止,我们一直认为 Flux(和 Mono)都是这样的:它们都代表了一种异步的数据序列, 在订阅(subscribe)之前什么都不会发生。
但是实际上,广义上有两种发布者:“热”与“冷”(hot and cold)。
(本文档)到目前介绍的其实都是 cold 家族的发布者。它们为每一个订阅(subscription) 都生成数据。如果没有创建任何订阅(subscription),那么就不会生成数据。
试想一个 HTTP 请求:每一个新的订阅者都会触发一个 HTTP 调用,但是如果没有订阅者关心结果的话, 那就不会有任何调用。
另一方面,热 发布者,不依赖于订阅者的数量。即使没有订阅者它们也会发出数据, 如果有一个订阅者接入进来,那么它就会收到订阅之后发出的元素。对于热发布者, 在你订阅它之前,确实已经发生了什么。
just 是 Reactor 中少数几个“热”操作符的例子之一:它直接在组装期(assembly time) 就拿到数据,如果之后有谁订阅它,就重新发送数据给订阅者。再拿 HTTP 调用举例,如果给 just 传入的数据是一个 HTTP 调用的结果,那么之后在初始化 just 的时候才会进行唯一的一次网络调用。
如果想将 just 转化为一种 冷 的发布者,你可以使用 defer。它能够将刚才例子中对 HTTP 的请求延迟到订阅时(这样的话,对于每一个新的订阅来说,都会发生一次网络调用)。
Reactor 中多数其他的 热 发布者是扩展自 Processor 的。 |
|
|---|---|
考虑其他两个例子,如下是第一个例子:
Flux<String> source = Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.filter(s -> s.startsWith("o"))
.map(String::toUpperCase);
source.subscribe(d -> System.out.println("Subscriber 1: "+d));
source.subscribe(d -> System.out.println("Subscriber 2: "+d));
第一个例子输出如下:
blue
green
orange
Subscriber 1: ORANGE
purple
blue
green
orange
Subscriber 2: ORANGE
purple
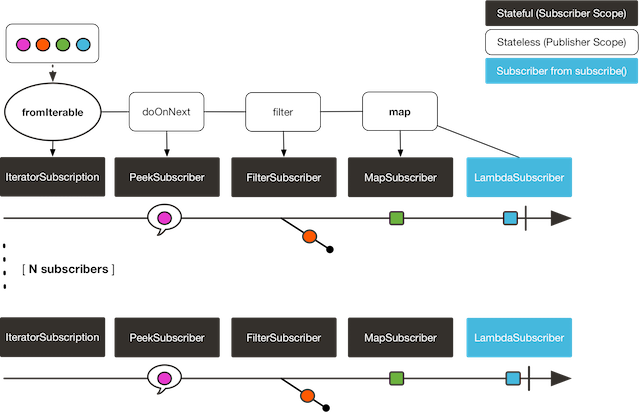
两个订阅者都触发了所有的颜色,因为每一个订阅者都会让构造 Flux 的操作符运行一次。
将下边的例子与第一个例子对比:
UnicastProcessor<String> hotSource = UnicastProcessor.create();
Flux<String> hotFlux = hotSource.publish()
.autoConnect()
.map(String::toUpperCase);
hotFlux.subscribe(d -> System.out.println("Subscriber 1 to Hot Source: "+d));
hotSource.onNext("blue");
hotSource.onNext("green");
hotFlux.subscribe(d -> System.out.println("Subscriber 2 to Hot Source: "+d));
hotSource.onNext("orange");
hotSource.onNext("purple");
hotSource.onComplete();
第二个例子输出如下:
Subscriber 1 to Hot Source: BLUE
Subscriber 1 to Hot Source: GREEN
Subscriber 1 to Hot Source: ORANGE
Subscriber 2 to Hot Source: ORANGE
Subscriber 1 to Hot Source: PURPLE
Subscriber 2 to Hot Source: PURPLE

第一个订阅者收到了所有的四个颜色,第二个订阅者由于是在前两个颜色发出之后订阅的, 故而收到了之后的两个颜色,在输出中有两次 "ORANGE" 和 "PURPLE"。从这个例子可见, 无论是否有订阅者接入进来,这个 Flux 都会运行。
8.3. 使用 ConnectableFlux 对多个订阅者进行广播
有时候,你不仅想要延迟到某一个订阅者订阅之后才开始发出数据,可能还希望在多个订阅者 到齐 之后 才开始。
ConnectableFlux 的用意便在于此。Flux API 中有两种主要的返回 ConnectableFlux 的方式:publish 和 replay。
publish会尝试满足各个不同订阅者的需求(背压),并综合这些请求反馈给源。 尤其是如果有某个订阅者的需求为0,publish 会 暂停 它对源的请求。replay将对第一个订阅后产生的数据进行缓存,最多缓存数量取决于配置(时间/缓存大小)。 它会对后续接入的订阅者重新发送数据。
ConnectableFlux 提供了多种对下游订阅的管理。包括:
connect当有足够的订阅接入后,可以对 flux 手动执行一次。它会触发对上游源的订阅。autoConnect(n)与 connect 类似,不过是在有n个订阅的时候自动触发。refCount(n)不仅能够在订阅者接入的时候自动触发,还会检测订阅者的取消动作。如果订阅者数量不够, 会将源“断开连接”,再有新的订阅者接入的时候才会继续“连上”源。refCount(int, Duration)增加了一个 "优雅的倒计时":一旦订阅者数量太低了,它会等待Duration的时间,如果没有新的订阅者接入才会与源“断开连接”。
示例如下:
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
ConnectableFlux<Integer> co = source.publish();
co.subscribe(System.out::println, e -> {}, () -> {});
co.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("done subscribing");
Thread.sleep(500);
System.out.println("will now connect");
co.connect();
The preceding code produces the following output:
done subscribing
will now connect
subscribed to source
1
1
2
2
3
3
使用 autoConnect:
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
Flux<Integer> autoCo = source.publish().autoConnect(2);
autoCo.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("subscribed first");
Thread.sleep(500);
System.out.println("subscribing second");
autoCo.subscribe(System.out::println, e -> {}, () -> {});
以上代码输出如下:
subscribed first
subscribing second
subscribed to source
1
1
2
2
3
3
8.4. 三种分批处理方式
当你有许多的元素,并且想将他们分批处理,Reactor 总体上有三种方案:分组(grouping)、 窗口(windowing)(译者注:感觉这个不翻译更明白。。。)、缓存(buffering)。 这三种在概念上类似,因为它们都是将 Flux<T> 进行聚集。分组和分段操作都会创建一个 Flux<Flux<T>>,而缓存操作得到的是一个 Collection<T>(译者注:应该是一个 Flux<Collection<T>>)。
8.4.1. 用 Flux<GroupedFlux<T>> 进行分组
分组能够根据 key 将源 Flux<T> 拆分为多个批次。
对应的操作符是 groupBy。
每一组用 GroupedFlux<T> 类型表示,使用它的 key() 方法可以得到该组的 key。
在组内,元素并不需要是连续的。当源发出一个新的元素,该元素会被分发到与之匹配的 key 所对应的组中(如果还没有该 key 对应的组,则创建一个)。
这意味着组:
- 是互相没有交集的(一个元素只属于一个组)。
- 会包含原始序列中任意位置的元素。
- 不会为空。
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.groupBy(i -> i % 2 == 0 ? "even" : "odd")
.concatMap(g -> g.defaultIfEmpty(-1) //如果组为空,显示为 -1
.map(String::valueOf) //转换为字符串
.startWith(g.key())) //以该组的 key 开头
)
.expectNext("odd", "1", "3", "5", "11", "13")
.expectNext("even", "2", "4", "6", "12")
.verifyComplete();
分组操作适用于分组个数不多的场景。而且所有的组都必须被消费,这样 groupBy 才能持续从上游获取数据。有时候这两种要求在一起——比如元素数量超多, 但是并行的用来消费的 flatMap 又太少的时候——会导致程序卡死。 |
|
|---|---|
8.4.2. 使用 Flux<Flux<T>> 进行 window 操作
window 操作是 根据个数、时间等条件,或能够定义边界的发布者(boundary-defining Publisher), 把源 Flux<T> 拆分为 windows。
对应的操作符有 window、windowTimeout、windowUntil、windowWhile,以及 windowWhen。
与 groupBy 的主要区别在于,窗口操作能够保持序列顺序。并且同一时刻最多只能有两个 window 是开启的。
它们 可以 重叠。操作符参数有 maxSize 和 skip,maxSize 指定收集多少个元素就关闭 window,而 skip 指定收集多数个元素后就打开下一个 window。所以如果 maxSize > skip 的话, 一个新的 window 的开启会先于当前 window 的关闭, 从而二者会有重叠。
重叠的 window 示例如下:
StepVerifier.create(
Flux.range(1, 10)
.window(5, 3) //overlapping windows
.concatMap(g -> g.defaultIfEmpty(-1)) //将 windows 显示为 -1
)
.expectNext(1, 2, 3, 4, 5)
.expectNext(4, 5, 6, 7, 8)
.expectNext(7, 8, 9, 10)
.expectNext(10)
.verifyComplete();
如果将两个参数的配置反过来(maxSize < skip),序列中的一些元素就会被丢弃掉, 而不属于任何 window。 |
|
|---|---|
对基于判断条件的 windowUntil 和 windowWhile,如果序列中的元素不匹配判断条件, 那么可能导致 空 windows,如下例所示:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.windowWhile(i -> i % 2 == 0)
.concatMap(g -> g.defaultIfEmpty(-1))
)
.expectNext(-1, -1, -1) //分别被奇数 1 3 5 触发
.expectNext(2, 4, 6) // 被 11 触发
.expectNext(12) // 被 13 触发
.expectNext(-1) // 空的 completion window,如果 onComplete 前的元素能够匹配上的话就没有这个了
.verifyComplete();
8.4.3. 使用 Flux<List<T>> 进行缓存
缓存与窗口类似,不同在于:缓存操作之后会发出 buffers (类型为Collection<T>, 默认是 List<T>),而不是 windows (类型为 Flux<T>)。
缓存的操作符与窗口的操作符是对应的:buffer、bufferTimeout、bufferUntil、bufferWhile, 以及bufferWhen。
如果说对于窗口操作符来说,是开启一个窗口,那么对于缓存操作符来说,就是创建一个新的集合, 然后对其添加元素。而窗口操作符在关闭窗口的时候,缓存操作符则是发出一个集合。
缓存操作也会有丢弃元素或内容重叠的情况,如下:
StepVerifier.create(
Flux.range(1, 10)
.buffer(5, 3) // 缓存重叠
)
.expectNext(Arrays.asList(1, 2, 3, 4, 5))
.expectNext(Arrays.asList(4, 5, 6, 7, 8))
.expectNext(Arrays.asList(7, 8, 9, 10))
.expectNext(Collections.singletonList(10))
.verifyComplete();
不像窗口方法,bufferUntil 和 bufferWhile 不会发出空的 buffer,如下例所示:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.bufferWhile(i -> i % 2 == 0)
)
.expectNext(Arrays.asList(2, 4, 6)) // 被 11 触发
.expectNext(Collections.singletonList(12)) // 被 13 触发
.verifyComplete();
8.5. 使用 ParallelFlux 进行并行处理
如今多核架构已然普及,能够方便的进行并行处理是很重要的。Reactor 提供了一种特殊的类型 ParallelFlux 来实现并行,它能够将操作符调整为并行处理方式。
你可以对任何 Flux 使用 parallel() 操作符来得到一个 ParallelFlux. 不过这个操作符本身并不会进行并行处理,而是将负载划分到多个“轨道(rails)”上 (默认情况下,轨道个数与 CPU 核数相等)。
为了配置 ParallelFlux 如何并行地执行每一个轨道,你需要使用 runOn(Scheduler)。 注意,Schedulers.parallel() 是推荐的专门用于并行处理的调度器。
下边有两个用于比较的例子,第一个如下:
Flux.range(1, 10)
.parallel(2)
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));
| 我们给定一个轨道数字,而不是依赖于 CPU 核数。 | |
|---|---|
下边是第二个例子:
Flux.range(1, 10)
.parallel(2)
.runOn(Schedulers.parallel())
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));
第一个例子输出如下:
main -> 1
main -> 2
main -> 3
main -> 4
main -> 5
main -> 6
main -> 7
main -> 8
main -> 9
main -> 10
第二个例子在两个线程中并行执行,输出如下:
parallel-1 -> 1
parallel-2 -> 2
parallel-1 -> 3
parallel-2 -> 4
parallel-1 -> 5
parallel-2 -> 6
parallel-1 -> 7
parallel-1 -> 9
parallel-2 -> 8
parallel-2 -> 10
如果在并行地处理之后,需要退回到一个“正常”的 Flux 而使后续的操作链按非并行模式执行, 你可以对 ParallelFlux 使用 sequential() 方法。
注意,当你在对 ParallelFlux 使用一个 Subscriber 而不是基于 lambda 进行订阅(subscribe()) 的时候,sequential() 会自动地被偷偷应用。
注意 subscribe(Subscriber<T>) 会合并所有的执行轨道,而 subscribe(Consumer<T>) 会在所有轨道上运行。 如果 subscribe() 方法中是一个 lambda,那么有几个轨道,lambda 就会被执行几次。
你还可以使用 groups() 作为 Flux<GroupedFlux<T>> 进入到各个轨道或组里边, 然后可以通过 composeGroup() 添加额外的操作符。
8.6. 替换默认的 Schedulers
就像我们在 调度器(Schedulers) 这一节看到的那样, Reactor Core 内置许多 Scheduler 的具体实现。 你可以用形如 new* 的工厂方法来创建调度器,每一种调度器都有一个单例对象,你可以使用单例工厂方法 (比如 Schedulers.elastic() 而不是 Schedulers.newElastic())来获取它。
当你不明确指定调度器的时候,那些需要调度器的操作符会使用这些默认的单例调度器对象。例如, Flux#delayElements(Duration) 使用的是 Schedulers.parallel() 调度器对象。
然而有些情况下,你可能需要“一刀切”(就不用对每一个操作符都传入你自己的调度器作为参数了) 地调整这些默认调度器。 一个典型的例子就是,假设你需要对每一个被调度的任务统计执行时长, 就想把默认的调度器包装一下,然后添加计时功能。
那么可以使用 Schedulers.Factory 类来改变默认的调度器。默认情况下,一个 Factory 会使用一些“命名比较直白” 的方法来创建所有的标准 Scheduler。每一个方法你都可以用自己的实现方式来重写。
此外,Factory 还提供一个额外的自定义方法 decorateExecutorService。它会在创建每一个 reactor-core 调度器——内部有一个 ScheduledExecutorService(即使是比如用 Schedulers.newParallel() 方法创建的这种非默认的调度器)——的时候被调用。
你可以通过调整 ScheduledExecutorService 来改变调度器:(译者加:decorateExecutorService 方法)通过一个 Supplier 参数暴露出来,你可以直接绕过这个 supplier 返回你自己的调度器实例,或者用 (译者加: Schedulers.ScheduledExecutorService 的)get() 得到默认实例,然后包装它, 这取决于配置的调度器类型。
当你搞定了一个定制好的 Factory 后,你必须使用 Schedulers.setFactory(Factory) 方法来安装它。 |
|
|---|---|
最后,对于调度器来说,有一个可自定义的 hook:onHandleError。这个 hook 会在提交到这个调度器的 Runnable 任务抛出异常的时候被调用(注意,如果还设置了一个 UncaughtExceptionHandler, 那么它和 hook 都会被调用)。
8.7. 使用全局的 Hooks
Reactor 还有另外一类可配置的应用于多种场合的回调,它们都在 Hooks 类中定义,总体来说有三类:
8.7.1. 丢弃事件的 Hooks
当生成源的操作符不遵从响应式流规范的时候,Dropping hooks(用于处理丢弃事件的 hooks)会被调用。 这种类型的错误是处于正常的执行路径之外的(也就是说它们不能通过 onError 传播)。
典型的例子是,假设一个发布者即使在被调用 onCompleted 之后仍然可以通过操作符调用 onNext。 这种情况下,onNext 的值会被 丢弃,如果有多余的 onError 的信号亦是如此。
相应的 hook,onNextDropped 以及 onErrorDropped,可以提供一个全局的 Consumer, 以便能够在丢弃的情况发生时进行处理。例如,你可以使用它来对丢弃事件记录日志,或进行资源清理 (使用资源的值可能压根没有到达响应式链的下游)。
连续设置两次 hook 的话都会起作用:提供的每一个 consumer 都会被调用。使用 Hooks.resetOn*Dropped() 方法可以将 hooks 全部重置为默认。
8.7.2. 内部错误 Hook
如果操作符在执行其 onNext、onError 以及 onComplete 方法的时候抛出异常,那么 onOperatorError 这一个 hook 会被调用。
与上一类 hook 不同,这个 hook 还是处在正常的执行路径中的。一个典型的例子就是包含一个 map 函数式的 map 操作符抛出的异常(比如零作为除数),这时候还是会执行到 onError 的。
首先,它会将异常传递给 onOperatorError。利用这个 hook 你可以检查这个错误(以及有问题的相关数据), 并可以 改变 这个异常。当然你还可以做些别的事情,比如记录日志或返回原始异常。
注意,onOperatorError hook 也可以被多次设置:你可以提供一个 String 为一个特别的 BiFunction 类型的函数式设置识别符,不同识别符的函数式都会被执行,当然,重复使用一个识别符的话, 则后来的设置会覆盖前边的设置。
因此,默认的 hook 可以使用 Hooks.resetOnOperatorError() 方法重置,而提供识别符的 hook 可以使用 Hooks.resetOnOperatorError(String) 方法来重置。
8.7.3. 组装 Hooks
这些组装(assembly) hooks 关联了操作符的生命周期。它们会在一个操作链被组装起来的时候(即实例化的时候) 被调用。每一个新的操作符组装到操作链上的时候,onEachOperator 都会返回一个不同的发布者, 从而可以利用它动态调整操作符。onLastOperator 与之类似,不过只会在被操作链上的最后一个 (subscribe 调用之前的)操作符调用。
类似于 onOperatorError,也可以叠加,并且通过识别符来标识。也是用类似的方式重置全部或部分 hooks。
8.7.4. 预置 Hooks
Hooks 工具类还提供了一些预置的 hooks。利用他们可以改变一些默认的处理方式,而不用自己 编写 hook:
onNextDroppedFail():onNextDropped通常会抛出Exceptions.failWithCancel()异常。 现在它默认还会以 DEBUG 级别对被丢弃的值记录日志。如果想回到原来的只是抛出异常的方式,使用onNextDroppedFail()。onOperatorDebug(): 这个方法会激活 debug mode。它与onOperatorErrorhook 关联,所以调用resetOnOperatorError()同时也会重置它。不过它内部也用到了特别的识别符, 你可以通过resetOnOperatorDebug()方法来重置它。
8.8. 增加一个 Context 到响应式序列
当从命令式编程风格切换到响应式编程风格的时候,一个技术上最大的挑战就是线程处理。
与习惯做法不同的是,在响应式编程中,一个线程(Thread)可以被用于处理多个同时运行的异步序列 (实际上是非阻塞的)。执行过程也会经常从一个线程切换到另一个线程。
这样的情况下,对于开发者来说,如果依赖线程模型中相对“稳定”的特性——比如 ThreadLocal ——就会变得很难。因为它会让你将数据绑定到一个 线程 上,所以在响应式环境中使用就变得 比较困难。因此,将使用了 ThreadLocal 的库应用于 Reactor 的时候就会带来新的挑战。通常会更糟, 它用起来效果会更差,甚至会失败。 比如,使用 Logback 的 MDC 来存储日志关联的 ID,就是一个非常符合 这种情况的例子。
通常的对 ThreadLocal 的替代方案是将环境相关的数据 C,同业务数据 T 一起置于序列中, 比如使用 Tuple2<T, C>。这种方案看起来并不好,况且会在方法和 Flux 泛型中暴露环境数据信息。
自从版本 3.1.0,Reactor 引入了一个类似于 ThreadLocal 的高级功能:Context。它作用于一个 Flux 或一个 Mono 上,而不是应用于一个线程(Thread)。
为了说明,这里有个读写 Context 的简单例子:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World")
.verifyComplete();
接下来的几个小节,我们来了解 Context 是什么以及如何用,从而最终可以理解上边的例子。
这是一个主要面向库开发人员的高级功能。这需要开发者对 Subscription 的生命周期 充分理解,并且明白它主要用于 subscription 相关的库。 |
|
|---|---|
8.8.1. Context API
Context 是一个类似于 Map(这种数据结构)的接口:它存储键值(key-value)对,你需要通过 key 来获取值:
- key 和 value 都是
Object类型,所以Context可以包含任意数量的任意对象。 Context是 不可变的(immutable)。- 用
put(Object key, Object value)方法来存储一个键值对,返回一个新的Context对象。 你也可以用putAll(Context)方法将两个 context 合并为一个新的 context。 - 用
hasKey(Object key)方法检查一个 key 是否已经存在。 - 用
getOrDefault(Object key, T defaultValue)方法取回 key 对应的值(类型转换为T), 或在找不到这个 key 的情况下返回一个默认值。 - 用
getOrEmpty(Object key)来得到一个Optional<T>(context 会尝试将值转换为T)。 - 用
delete(Object key)来删除 key 关联的值,并返回一个新的Context。
创建一个 Context 时,你可以用静态方法 Context.of 预先存储最多 5 个键值对。 它接受 2, 4, 6, 8 或 10 个 Object 对象,两两一对作为键值对添加到 Context。 你也可以用 Context.empty() 方法来创建一个空的 Context。 |
|
|---|---|
8.8.2. 把 Context 绑定到 Flux and Writing
为了使用 context,它必须要绑定到一个指定的序列,并且链上的每个操作符都可以访问它。 注意,这里的操作符必须是 Reactor 内置的操作符,因为 Context 是 Reactor 特有的。
实际上,一个 Context 是绑定到每一个链中的 Subscriber 上的。 它使用 Subscription 的传播机制来让自己对每一个操作符都可见(从最后一个 subscribe 沿链向上)。
为了填充 Context ——只能在订阅时(subscription time)——你需要使用 subscriberContext 操作符。
subscriberContext(Context) 方法会将你提供的 Context 与来自下游(记住,Context 是从下游 向上游传播的)的 Context合并。 这通过调用 putAll 实现,最后会生成一个新的 Context 给上游。
你也可以用更高级的 subscriberContext(Function<Context, Context>)。它接受来自下游的 Context,然后你可以根据需要添加或删除值,然后返回新的 Context。你甚至可以返回一个完全不同 的对象,虽然不太建议这样(这样可能影响到依赖这个 Context 的库)。 |
|
|---|---|
8.8.3. 读取 Context
填充 Context 是一方面,读取数据同样重要。多数时候,添加内容到 Context 是最终用户的责任, 但是利用这些信息是库的责任,因为库通常是客户代码的上游。
读取 context 数据使用静态方法 Mono.subscriberContext()。
8.8.4. 简单的例子
本例的初衷是为了让你对如何使用 Context 有个更好的理解。
让我们先回头看一下最初的例子:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World")
.verifyComplete();
操作链以调用 subscriberContext(Function) 结尾,将 "World" 作为 "message" 这个 key 的 值添加到 Context 中。 |
|
|---|---|
对源调用 flatMap 用 Mono.subscriberContext() 方法拿到 Context。 |
|
然后使用 map 读取关联到 "message" 的值,然后与原来的值连接。 |
|
最后 Mono<String> 确实发出了 "Hello World"。 |
上边的数字顺序并不是按照代码行顺序排的,这并非错误:它代表了执行顺序。虽然 subscriberContext 是链上的最后一个环节,但确实最先执行的(原因在于 subscription 信号 是从下游向上的)。 |
|
|---|---|
注意在你的操作链中,写入 与 读取 Context 的 相对位置 很重要:因为 Context 是不可变的,它的内容只能被上游的操作符看到,如下例所示:
String key = "message";
Mono<String> r = Mono.just("Hello")
.subscriberContext(ctx -> ctx.put(key, "World"))
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.getOrDefault(key, "Stranger")));
StepVerifier.create(r)
.expectNext("Hello Stranger")
.verifyComplete();
写入 Context 的位置太靠上了… |
|
|---|---|
所以在 flatMap 就没有 key 关联的值,使用了默认值。 |
|
结果 Mono<String> 发出了 "Hello Stranger"。 |
下面的例子同样说明了 Context 的不可变性(Mono.subscriberContext() 总是返回由 subscriberContext 配置的 Context):
String key = "message";
Mono<String> r = Mono.subscriberContext()
.map( ctx -> ctx.put(key, "Hello"))
.flatMap( ctx -> Mono.subscriberContext())
.map( ctx -> ctx.getOrDefault(key,"Default"));
StepVerifier.create(r)
.expectNext("Default")
.verifyComplete();
拿到 Context。 |
|
|---|---|
在 map 方法中我们尝试修改它。 |
|
在 flatMap 中再次获取 Context。 |
|
读取 Context 中可能的值。 |
|
值从来没有被设置为 "Hello"。 |
类似的,如果多次对 Context 中的同一个 key 赋值的话,要看 写入的相对顺序 : 读取 Context 的操作符只能拿到下游最近的一次写入的值,如下例所示:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "Reactor"))
.subscriberContext(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello Reactor")
.verifyComplete();
写入 "message" 的值。 |
|
|---|---|
另一次写入 "message" 的值。 |
|
map 方法值能拿到下游最近的一次写入的值: "Reactor"。 |
这里,首先 Context 中的 key 被赋值 "World"。然后订阅信号(subscription signal)向上游 移动,又发生了另一次写入。这次生成了第二个不变的 Context,里边的值是 "Reactor"。之后, 数据开始流动, flatMap 拿到最近的 Context ,也就是第二个值为 Reactor 的 Context。
你可能会觉得 Context 是与数据信号一块传播的。如果是那样的话,在两次写入操作中间加入的一个 flatMap 会使用最上游的这个 Context。但并不是这样的,如下:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "Reactor"))
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello Reactor World")
.verifyComplete();
| 这里是第一次赋值。 | |
|---|---|
| 这里是第二次赋值。 | |
第一个 flatMap 看到的是第二次的赋值。 |
|
第二个 flatMap 将上一个的结果与 第一次赋值 的 context 值连接。 |
|
Mono 发出的是 "Hello Reactor World"。 |
原因在于 Context 是与 Subscriber 关联的,而每一个操作符访问的 Context 来自其下游的 Subscriber。
最后一个有意思的传播方式是,对 Context 的赋值也可以在一个 flatMap 内部,如下:
String key = "message";
Mono<String> r =
Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))
)
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))
.subscriberContext(ctx -> ctx.put(key, "Reactor"))
)
.subscriberContext(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World Reactor")
.verifyComplete();
这个 subscriberContext 不会影响所在 flatMap 之外的任何东西。 |
|
|---|---|
这个 subscriberContext 会影响主序列的 Context。 |
上边的例子中,最后发出的值是 "Hello World Reactor" 而不是 "Hello Reactor World",因为赋值 "Reactor" 的 subscriberContext 是作用于第二个 flatMap 的内部序列的。所以不会在主序列可见/ 传播,第一个 flatMap 也看不到它。传播(Propagation) + 不可变性(immutability)将类似 flatMap 这样的操作符中的创建的内部序列中的 Context 与外部隔离开来。
8.8.5. 完整的例子
让我们来看一个实际的从 Context 中读取值的例子:一个响应式的 HTTP 客户端将一个 Mono<String> (用于 PUT 请求)作为数据源,同时通过一个特定的 key 使用 Context 将关联的ID信息放入请求头中。
从用户角度,是这样调用的:
doPut("www.example.com", Mono.just("Walter"))
为了传播一个关联ID,应该这样调用:
doPut("www.example.com", Mono.just("Walter"))
.subscriberContext(Context.of(HTTP_CORRELATION_ID, "2-j3r9afaf92j-afkaf"))
由上可见,用户代码使用了 subscriberContext 来为 Context 的 HTTP_CORRELATION_ID 赋值。上游的操作符是一个由 HTTP 客户端库返回的 Mono<Tuple2<Integer, String>> (一个简化的 HTTP 响应)。所以能够正确将信息从用户代码传递给库代码。
下边的例子演示了从库的角度由 context 读取值的模拟代码,如果能够找到关联ID,则“增加请求”:
static final String HTTP_CORRELATION_ID = "reactive.http.library.correlationId";
Mono<Tuple2<Integer, String>> doPut(String url, Mono<String> data) {
Mono<Tuple2<String, Optional<Object>>> dataAndContext =
data.zipWith(Mono.subscriberContext()
.map(c -> c.getOrEmpty(HTTP_CORRELATION_ID)));
return dataAndContext
.<String>handle((dac, sink) -> {
if (dac.getT2().isPresent()) {
sink.next("PUT <" + dac.getT1() + "> sent to " + url + " with header X-Correlation-ID = " + dac.getT2().get());
}
else {
sink.next("PUT <" + dac.getT1() + "> sent to " + url);
}
sink.complete();
})
.map(msg -> Tuples.of(200, msg));
}
用 Mono.subscriberContext() 拿到 Context。 |
|
|---|---|
提取出关联ID的值——是一个 Optional。 |
|
| 如果值存在,那么就将其加入请求头。 |
在这段库代码片段中,你可以看到它是如何将 Mono 和 Mono.subscriberContext() zip 起来的。 返回的是一个 Tuple2<String, Context>,这个 Context 包含来自下游的 HTTP_CORRELATION_ID 的值。
库代码接着用 map 读取出那个 key 的值 Optional<String>,如果值存在,将其作为 X-Correlation-ID 请求头。 最后一块而用 handle 来处理。
用来验证上边的库代码的测试程序如下:
@Test
public void contextForLibraryReactivePut() {
Mono<String> put = doPut("www.example.com", Mono.just("Walter"))
.subscriberContext(Context.of(HTTP_CORRELATION_ID, "2-j3r9afaf92j-afkaf"))
.filter(t -> t.getT1() < 300)
.map(Tuple2::getT2);
StepVerifier.create(put)
.expectNext("PUT <Walter> sent to www.example.com with header X-Correlation-ID = 2-j3r9afaf92j-afkaf")
.verifyComplete();
}
8.9. 空值安全
虽然 Java 的类型系统没有表达空值安全(null-safety)的机制,但是 Reactor 现在提供了基于注解的用于声明 “可能为空(nullability)”的 API,类似于 Spring Framework 5 中提供的 API。
Reactor 自身就用到了这些注解,你也可以将其用于任何基于 Reactor 的自己的空值安全的 Java API 中。 不过,在 方法体内部 对“可能为空”的类型的使用就不在这一特性的范围内了。
这些注解是基于 JSR 305 的注解(是受类似 IntelliJ IDEA 这样的工具支持的 JSR)作为元注解(meta-annotated)的。当 Java 开发者在编写空值安全的代码时, 它们能够提供有用的警告信息,以便避免在运行时(runtime)出现 NullPointerException 异常。 JSR 305 元注解使得工具提供商可以以一种通用的方式提供对空值安全的支持,从而 Reactor 的注解就不用重复造轮子了。
| 对于 Kotlin 1.1.5+,需要(同时也推荐)在项目 classpath 中添加对 JSR 305 的依赖。 | |
|---|---|
它们也可在 Kotlin 中使用,Kotlin 原生支持 空值安全。具体请参考 this dedicated section 。
reactor.util.annotation 包提供以下注解:
@NonNull表明一个具体的参数、返回值或域值不能为null。 (如果参数或返回值应用了@NonNullApi则无需再加它)。@Nullable表明一个参数、返回值或域值可以为null。@NonNullApi是一个包级别的注解,表明默认情况下参数或返回值不能为null。
| (Reactor 的空值安全的注解)对于通用类型参数(generic type arguments)、可变参数(varargs),以及数组元素(array elements) 尚不支持。参考 issue #878 查看最新信息。 | |
|---|---|
Appendix A: 我需要哪个操作符?
TIP:在这一节,如果一个操作符是专属于 Flux 或 Mono 的,那么会给它注明前缀。 公共的操作符没有前缀。如果一个具体的用例涉及多个操作符的组合,这里以方法调用的方式展现, 会以一个点(.)开头,并将参数置于圆括号内,比如: .methodCall(parameter)。
我想搞定:
A.1. 创建一个新序列,它…
- 发出一个
T,我已经有了:just- …基于一个
Optional<T>:Mono#justOrEmpty(Optional<T>) - …基于一个可能为
null的 T:Mono#justOrEmpty(T)
- …基于一个
- 发出一个
T,且还是由just方法返回- …但是“懒”创建的:使用
Mono#fromSupplier或用defer包装just
- …但是“懒”创建的:使用
- 发出许多
T,这些元素我可以明确列举出来:Flux#just(T...) - 基于迭代数据结构:
- 一个数组:
Flux#fromArray - 一个集合或 iterable:
Flux#fromIterable - 一个 Integer 的 range:
Flux#range - 一个
Stream提供给每一个订阅:Flux#fromStream(Supplier<Stream>)
- 一个数组:
- 基于一个参数值给出的源:
- 一个
Supplier<T>:Mono#fromSupplier - 一个任务:
Mono#fromCallable,Mono#fromRunnable - 一个
CompletableFuture<T>:Mono#fromFuture
- 一个
- 直接完成:
empty - 立即生成错误:
error- …但是“懒”的方式生成
Throwable:error(Supplier<Throwable>)
- …但是“懒”的方式生成
- 什么都不做:
never - 订阅时才决定:
defer - 依赖一个可回收的资源:
using - 可编程地生成事件(可以使用状态):
- 同步且逐个的:
Flux#generate - 异步(也可同步)的,每次尽可能多发出元素:
Flux#create(Mono#create也是异步的,只不过只能发一个)
- 同步且逐个的:
A.2. 对序列进行转化
- 我想转化一个序列:
- 1对1地转化(比如字符串转化为它的长度):
map- …类型转化:
cast - …为了获得每个元素的序号:
Flux#index
- …类型转化:
- 1对n地转化(如字符串转化为一串字符):
flatMap+ 使用一个工厂方法 - 1对n地转化可自定义转化方法和/或状态:
handle - 对每一个元素执行一个异步操作(如对 url 执行 http 请求):
flatMap+ 一个异步的返回类型为Publisher的方法- …忽略一些数据:在 flatMap lambda 中根据条件返回一个
Mono.empty() - …保留原来的序列顺序:
Flux#flatMapSequential(对每个元素的异步任务会立即执行,但会将结果按照原序列顺序排序) - …当 Mono 元素的异步任务会返回多个元素的序列时:
Mono#flatMapMany
- …忽略一些数据:在 flatMap lambda 中根据条件返回一个
- 1对1地转化(比如字符串转化为它的长度):
- 我想添加一些数据元素到一个现有的序列:
- 在开头添加:
Flux#startWith(T...) - 在最后添加:
Flux#concatWith(T...)
- 在开头添加:
- 我想将
Flux转化为集合(一下都是针对Flux的)- 转化为 List:
collectList,collectSortedList - 转化为 Map:
collectMap,collectMultiMap - 转化为自定义集合:
collect - 计数:
count - reduce 算法(将上个元素的reduce结果与当前元素值作为输入执行reduce方法,如sum)
reduce- …将每次 reduce 的结果立即发出:
scan
- …将每次 reduce 的结果立即发出:
- 转化为一个 boolean 值:
- 对所有元素判断都为true:
all - 对至少一个元素判断为true:
any - 判断序列是否有元素(不为空):
hasElements - 判断序列中是否有匹配的元素:
hasElement
- 对所有元素判断都为true:
- 转化为 List:
- 我想合并 publishers…
- 按序连接:
Flux#concat或.concatWith(other)- …即使有错误,也会等所有的 publishers 连接完成:
Flux#concatDelayError - …按订阅顺序连接(这里的合并仍然可以理解成序列的连接):
Flux#mergeSequential
- …即使有错误,也会等所有的 publishers 连接完成:
- 按元素发出的顺序合并(无论哪个序列的,元素先到先合并):
Flux#merge/.mergeWith(other)- …元素类型会发生变化:
Flux#zip/Flux#zipWith
- …元素类型会发生变化:
- 将元素组合:
- 2个 Monos 组成1个
Tuple2:Mono#zipWith - n个 Monos 的元素都发出来后组成一个 Tuple:
Mono#zip
- 2个 Monos 组成1个
- 在终止信号出现时“采取行动”:
- 在 Mono 终止时转换为一个
Mono<Void>:Mono#and - 当 n 个 Mono 都终止时返回
Mono<Void>:Mono#when - 返回一个存放组合数据的类型,对于被合并的多个序列:
- 每个序列都发出一个元素时:
Flux#zip - 任何一个序列发出元素时:
Flux#combineLatest
- 每个序列都发出一个元素时:
- 在 Mono 终止时转换为一个
- 只取各个序列的第一个元素:
Flux#first,Mono#first,mono.or (otherMono).or(thirdMono),`flux.or(otherFlux).or(thirdFlux) - 由一个序列触发(类似于
flatMap,不过“喜新厌旧”):switchMap - 由每个新序列开始时触发(也是“喜新厌旧”风格):
switchOnNext
- 按序连接:
- 我想重复一个序列:
repeat- …但是以一定的间隔重复:
Flux.interval(duration).flatMap(tick -> myExistingPublisher)
- …但是以一定的间隔重复:
- 我有一个空序列,但是…
- 我想要一个缺省值来代替:
defaultIfEmpty - 我想要一个缺省的序列来代替:
switchIfEmpty
- 我想要一个缺省值来代替:
- 我有一个序列,但是我对序列的元素值不感兴趣:
ignoreElements- …并且我希望用
Mono来表示序列已经结束:then - …并且我想在序列结束后等待另一个任务完成:
thenEmpty - …并且我想在序列结束之后返回一个
Mono:Mono#then(mono) - …并且我想在序列结束之后返回一个值:
Mono#thenReturn(T) - …并且我想在序列结束之后返回一个
Flux:thenMany
- …并且我希望用
- 我有一个 Mono 但我想延迟完成…
- …当有1个或N个其他 publishers 都发出(或结束)时才完成:
Mono#delayUntilOther- …使用一个函数式来定义如何获取“其他 publisher”:
Mono#delayUntil(Function)
- …使用一个函数式来定义如何获取“其他 publisher”:
- …当有1个或N个其他 publishers 都发出(或结束)时才完成:
- 我想基于一个递归的生成序列的规则扩展每一个元素,然后合并为一个序列发出:
- …广度优先:
expand(Function) - …深度优先:
expandDeep(Function)
- …广度优先:
A.3. “窥视”(只读)序列
- 再不对序列造成改变的情况下,我想:
- 得到通知或执行一些操作:
- 发出元素:
doOnNext - 序列完成:
Flux#doOnComplete,Mono#doOnSuccess - 因错误终止:
doOnError - 取消:
doOnCancel - 订阅时:
doOnSubscribe - 请求时:
doOnRequest - 完成或错误终止:
doOnTerminate(Mono的方法可能包含有结果)- 但是在终止信号向下游传递 之后 :
doAfterTerminate
- 但是在终止信号向下游传递 之后 :
- 所有类型的信号(
Signal):Flux#doOnEach - 所有结束的情况(完成complete、错误error、取消cancel):
doFinally
- 发出元素:
- 记录日志:
log
- 得到通知或执行一些操作:
- 我想知道所有的事件:
- 每一个事件都体现为一个
single对象:- 执行 callback:
doOnEach - 每个元素转化为
single对象:materialize- …在转化回元素:
dematerialize
- …在转化回元素:
- 执行 callback:
- 转化为一行日志:
log
- 每一个事件都体现为一个
A.4. 过滤序列
- 我想过滤一个序列
- 基于给定的判断条件:
filter- …异步地进行判断:
filterWhen
- …异步地进行判断:
- 仅限于指定类型的对象:
ofType - 忽略所有元素:
ignoreElements - 去重:
- 对于整个序列:
Flux#distinct - 去掉连续重复的元素:
Flux#distinctUntilChanged
- 对于整个序列:
- 基于给定的判断条件:
- 我只想要一部分序列:
- 只要 N 个元素:
- 从序列的第一个元素开始算:
Flux#take(long)- …取一段时间内发出的元素:
Flux#take(Duration) - …只取第一个元素放到
Mono中返回:Flux#next() - …使用
request(N)而不是取消:Flux#limitRequest(long)
- …取一段时间内发出的元素:
- 从序列的最后一个元素倒数:
Flux#takeLast - 直到满足某个条件(包含):
Flux#takeUntil(基于判断条件),Flux#takeUntilOther(基于对 publisher 的比较) - 直到满足某个条件(不包含):
Flux#takeWhile
- 从序列的第一个元素开始算:
- 最多只取 1 个元素:
- 给定序号:
Flux#elementAt - 最后一个:
.takeLast(1)- …如果为序列空则发出错误信号:
Flux#last() - …如果序列为空则返回默认值:
Flux#last(T)
- …如果为序列空则发出错误信号:
- 给定序号:
- 跳过一些元素:
- 从序列的第一个元素开始跳过:
Flux#skip(long)- …跳过一段时间内发出的元素:
Flux#skip(Duration)
- …跳过一段时间内发出的元素:
- 跳过最后的 n 个元素:
Flux#skipLast - 直到满足某个条件(包含):
Flux#skipUntil(基于判断条件),Flux#skipUntilOther(基于对 publisher 的比较) - 直到满足某个条件(不包含):
Flux#skipWhile
- 从序列的第一个元素开始跳过:
- 采样:
- 给定采样周期:
Flux#sample(Duration)- 取采样周期里的第一个元素而不是最后一个:
sampleFirst
- 取采样周期里的第一个元素而不是最后一个:
- 基于另一个 publisher:
Flux#sample(Publisher) - 基于 publisher“超时”:
Flux#sampleTimeout(每一个元素会触发一个 publisher,如果这个 publisher 不被下一个元素触发的 publisher 覆盖就发出这个元素)
- 给定采样周期:
- 只要 N 个元素:
- 我只想要一个元素(如果多于一个就返回错误)…
- 如果序列为空,发出错误信号:
Flux#single() - 如果序列为空,发出一个缺省值:
Flux#single(T) - 如果序列为空就返回一个空序列:
Flux#singleOrEmpty
- 如果序列为空,发出错误信号:
A.5. 错误处理
- 我想创建一个错误序列:
error…- …替换一个完成的
Flux:.concat(Flux.error(e)) - …替换一个完成的
Mono:.then(Mono.error(e)) - …如果元素超时未发出:
timeout - …“懒”创建:
error(Supplier<Throwable>)
- …替换一个完成的
- 我想要类似 try/catch 的表达方式:
- 抛出异常:
error - 捕获异常:
- 然后返回缺省值:
onErrorReturn - 然后返回一个
Flux或Mono:onErrorResume - 包装异常后再抛出:
.onErrorMap(t -> new RuntimeException(t))
- 然后返回缺省值:
- finally 代码块:
doFinally - Java 7 之后的 try-with-resources 写法:
using工厂方法
- 抛出异常:
- 我想从错误中恢复…
- 返回一个缺省的:
- 的值:
onErrorReturn Publisher:Flux#onErrorResume和Mono#onErrorResume
- 的值:
- 重试:
retry- …由一个用于伴随 Flux 触发:
retryWhen
- …由一个用于伴随 Flux 触发:
- 返回一个缺省的:
- 我想处理回压错误(向上游发出“MAX”的 request,如果下游的 request 比较少,则应用策略)…
- 抛出
IllegalStateException:Flux#onBackpressureError - 丢弃策略:
Flux#onBackpressureDrop- …但是不丢弃最后一个元素:
Flux#onBackpressureLatest
- …但是不丢弃最后一个元素:
- 缓存策略(有限或无限):
Flux#onBackpressureBuffer- …当有限的缓存空间用满则应用给定策略:
Flux#onBackpressureBuffer带有策略BufferOverflowStrategy
- …当有限的缓存空间用满则应用给定策略:
- 抛出
A.6. 基于时间的操作
- 我想将元素转换为带有时间信息的
Tuple2<Long, T>…- 从订阅时开始:
elapsed - 记录时间戳:
timestamp
- 从订阅时开始:
- 如果元素间延迟过长则中止序列:
timeout - 以固定的周期发出元素:
Flux#interval - 在一个给定的延迟后发出
0:staticMono.delay. - 我想引入延迟:
- 对每一个元素:
Mono#delayElement,Flux#delayElements - 延迟订阅:
delaySubscription
- 对每一个元素:
A.7. 拆分 Flux
- 我想将一个
Flux<T>拆分为一个Flux<Flux<T>>:- 以个数为界:
window(int)- …会出现重叠或丢弃的情况:
window(int, int)
- …会出现重叠或丢弃的情况:
- 以时间为界:
window(Duration)- …会出现重叠或丢弃的情况:
window(Duration, Duration)
- …会出现重叠或丢弃的情况:
- 以个数或时间为界:
windowTimeout(int, Duration) - 基于对元素的判断条件:
windowUntil- …触发判断条件的元素会分到下一波(
cutBefore变量):.windowUntil(predicate, true) - …满足条件的元素在一波,直到不满足条件的元素发出开始下一波:
windowWhile(不满足条件的元素会被丢弃)
- …触发判断条件的元素会分到下一波(
- 通过另一个 Publisher 的每一个 onNext 信号来拆分序列:
window(Publisher),windowWhen
- 以个数为界:
- 我想将一个
Flux<T>的元素拆分到集合…- 拆分为一个一个的
List:- 以个数为界:
buffer(int)- …会出现重叠或丢弃的情况:
buffer(int, int)
- …会出现重叠或丢弃的情况:
- 以时间为界:
buffer(Duration)- …会出现重叠或丢弃的情况:
buffer(Duration, Duration)
- …会出现重叠或丢弃的情况:
- 以个数或时间为界:
bufferTimeout(int, Duration) - 基于对元素的判断条件:
bufferUntil(Predicate)- …触发判断条件的元素会分到下一个buffer:
.bufferUntil(predicate, true) - …满足条件的元素在一个buffer,直到不满足条件的元素发出开始下一buffer:
bufferWhile(Predicate)
- …触发判断条件的元素会分到下一个buffer:
- 通过另一个 Publisher 的每一个 onNext 信号来拆分序列:
buffer(Publisher),bufferWhen
- 以个数为界:
- 拆分到指定类型的 "collection":
buffer(int, Supplier<C>)
- 拆分为一个一个的
- 我想将
Flux<T>中具有共同特征的元素分组到子 Flux:groupBy(Function<T,K>)TIP:注意返回值是Flux<GroupedFlux<K, T>>,每一个GroupedFlux具有相同的 key 值K,可以通过key()方法获取。
A.8. 回到同步的世界
- 我有一个
Flux<T>,我想:- 在拿到第一个元素前阻塞:
Flux#blockFirst- …并给出超时时限:
Flux#blockFirst(Duration)
- …并给出超时时限:
- 在拿到最后一个元素前阻塞(如果序列为空则返回 null):
Flux#blockLast- …并给出超时时限:
Flux#blockLast(Duration)
- …并给出超时时限:
- 同步地转换为
Iterable<T>:Flux#toIterable - 同步地转换为 Java 8
Stream<T>:Flux#toStream
- 在拿到第一个元素前阻塞:
- 我有一个
Mono<T>,我想:- 在拿到元素前阻塞:
Mono#block- …并给出超时时限:
Mono#block(Duration)
- …并给出超时时限:
- 转换为
CompletableFuture<T>:Mono#toFuture
- 在拿到元素前阻塞:
Appendix B: FAQ,最佳实践,以及“我如何…?”
B.1. 如何包装一个同步阻塞的调用?
很多时候,信息源是同步和阻塞的。在 Reactor 中,我们用以下方式处理这种信息源:
Mono blockingWrapper = Mono.fromCallable(() -> {
return /* make a remote synchronous call */
});
blockingWrapper = blockingWrapper.subscribeOn(Schedulers.elastic());
使用 fromCallable 方法生成一个 Mono; |
|
|---|---|
| 返回同步、阻塞的资源; | |
使用 Schedulers.elastic() 确保对每一个订阅来说运行在一个专门的线程上。 |
因为调用返回一个值,所以你应该使用 Mono。你应该使用 Schedulers.elastic 因为它会创建一个专门的线程来等待阻塞的调用返回。
注意 subscribeOn 方法并不会“订阅”这个 Mono。它只是指定了订阅操作使用哪个 Scheduler。
B.2. 用在 Flux 上的操作符好像没起作用,为啥?
请确认你确实对调用 .subscribe() 的发布者应用了这个操作符。
Reactor 的操作符是装饰器(decorators)。它们会返回一个不同的(发布者)实例, 这个实例对上游序列进行了包装并增加了一些的处理行为。所以,最推荐的方式是将操作符“串”起来。
对比下边的两个例子:
没有串起来(不正确的)
Flux<String> flux = Flux.just("foo", "chain");
flux.map(secret -> secret.replaceAll(".", "*"));
flux.subscribe(next -> System.out.println("Received: " + next));
问题在这, flux 变量并没有改变。 |
|
|---|---|
串起来(正确的)
Flux<String> flux = Flux.just("foo", "chain");
flux = flux.map(secret -> secret.replaceAll(".", "*"));
flux.subscribe(next -> System.out.println("Received: " + next));
下边的例子更好(因为更简洁):
串起来(最好的)
Flux<String> secrets = Flux
.just("foo", "chain")
.map(secret -> secret.replaceAll(".", "*"))
.subscribe(next -> System.out.println("Received: " + next));
第一个例子的输出:
Received: foo
Received: chain
后两个例子的输出:
Received: ***
Received: *****
B.3. Mono zipWith/zipWhen 没有被调用
例子
myMethod.process("a") // 这个方法返回 Mono<Void>
.zipWith(myMethod.process("b"), combinator) //没有被调用
.subscribe();
如果源 Mono 为空或是一个 Mono<Void>(Mono<Void> 通常用于“空”的场景), 下边的组合操作就不会被调用。
对于类似 zipWith 的用于转换的操作符来说,这是比较典型的场景。 这些操作符依赖于数据元素来转换为输出的元素。 如果任何一个序列是空的,则返回的就是一个空序列,所以请谨慎使用。 例如在 then() 之后使用 zipWith() 就会导致这一问题。
对于以 Function 作为参数的 and 更是如此,因为返回的 Mono 是依赖于收到的数据懒加载的(而对于空序列或 Void 的序列来说是没有数据发出来的)。
你可以使用 .defaultIfEmpty(T) 将空序列替换为包含 T 类型缺省值的序列(而不是 Void 序列), 从而可以避免类似的情况出现。举例如下:
在 zipWhen 前使用 defaultIfEmpty
myMethod.emptySequenceForKey("a") // 这个方法返回一个空的 Mono<String>
.defaultIfEmpty("") // 将空序列转换为包含字符串 "" 的序列
.zipWhen(aString -> myMethod.process("b")) // 当 "" 发出时被调用
.subscribe();
B.4. 如何用 retryWhen 来实现 retry(3) 的效果?
retryWhen 方法比较复杂,希望下边的一段模拟 retry(3) 的代码能够帮你更好地理解它的工作方式:
Flux<String> flux =
Flux.<String>error(new IllegalArgumentException())
.retryWhen(companion -> companion
.zipWith(Flux.range(1, 4),
(error, index) -> {
if (index < 4) return index;
else throw Exceptions.propagate(error);
})
);
技巧一:使用 zip 和一个“重试个数 + 1”的 range。 |
|
|---|---|
zip 方法让你可以在对重试次数计数的同时,仍掌握着原始的错误(error)。 |
|
| 允许三次重试,小于 4 的时候发出一个值。 | |
| 为了使序列以错误结束。我们将原始异常在三次重试之后抛出。 |
B.5. 如何使用 retryWhen 进行 exponential backoff?
Exponential backoff 的意思是进行的多次重试之间的间隔越来越长, 从而避免对源系统造成过载,甚至宕机。基本原理是,如果源产生了一个错误, 那么已经是处于不稳定状态,可能不会立刻复原。所以,如果立刻就重试可能会产生另一个错误, 导致源更加不稳定。
下面是一段实现 exponential backoff 效果的例子,每次重试的间隔都会递增 (伪代码: delay = attempt number * 100 milliseconds):
Flux<String> flux =
Flux.<String>error(new IllegalArgumentException())
.retryWhen(companion -> companion
.doOnNext(s -> System.out.println(s + " at " + LocalTime.now()))
.zipWith(Flux.range(1, 4), (error, index) -> {
if (index < 4) return index;
else throw Exceptions.propagate(error);
})
.flatMap(index -> Mono.delay(Duration.ofMillis(index * 100)))
.doOnNext(s -> System.out.println("retried at " + LocalTime.now()))
);
| 记录错误出现的时间; | |
|---|---|
使用 retryWhen + zipWith 的技巧实现重试3次的效果; |
|
通过 flatMap 来实现延迟时间递增的效果; |
|
| 同样记录重试的时间。 |
订阅它,输出如下:
java.lang.IllegalArgumentException at 18:02:29.338
retried at 18:02:29.459
java.lang.IllegalArgumentException at 18:02:29.460
retried at 18:02:29.663
java.lang.IllegalArgumentException at 18:02:29.663
retried at 18:02:29.964
java.lang.IllegalArgumentException at 18:02:29.964
| 第一次重试延迟大约 100ms | |
|---|---|
| 第二次重试延迟大约 200ms | |
| 第三次重试延迟大约 300ms |
B.6. How do I ensure thread affinity using publishOn()?
如 Schedulers 所述,publishOn() 可以用来切换执行线程。 publishOn 能够影响到其之后的操作符的执行线程,直到有新的 publishOn 出现。 所以 publishOn 的位置很重要。
比如下边的例子, map() 中的 transform 方法是在 scheduler1 的一个工作线程上执行的, 而 doOnNext() 中的 processNext 方法是在 scheduler2 的一个工作线程上执行的。 单线程的调度器可能用于对不同阶段的任务或不同的订阅者确保线程关联性。
EmitterProcessor<Integer> processor = EmitterProcessor.create();
processor.publishOn(scheduler1)
.map(i -> transform(i))
.publishOn(scheduler2)
.doOnNext(i -> processNext(i))
.subscribe();
Appendix C: Reactor-Extra
reactor-extra 为满足 reactor-core 用户的更高级需求,提供了一些额外的操作符和工具。
由于这是一个单独的包,使用时需要明确它的依赖:
dependencies {
compile 'io.projectreactor:reactor-core'
compile 'io.projectreactor.addons:reactor-extra'
}
| 添加 reactor-extra 的依赖。参考 获取 Reactor 了解为什么使用BOM的情况下不需要指定 version。 | |
|---|---|
C.1. TupleUtils 以及函数式接口
在 Java 8 提供的函数式接口基础上,reactor.function 包又提供了一些支持 3 到 8 个值的 Function、Predicate 和 Consumer。
TupleUtils 提供的静态方法可以方便地用于将相应的 Tuple 函数式接口的 lambda 转换为更简单的接口。
这使得我们在使用 Tuple 中各成员的时候更加容易,比如:
.map(tuple -> {
String firstName = tuple.getT1();
String lastName = tuple.getT2();
String address = tuple.getT3();
return new Customer(firstName, lastName, address);
});
可以用下面的方式代替:
.map(TupleUtils.function(Customer::new));
(因为 Customer 的构造方法符合 Consumer3 的函数式接口标签) |
|
|---|---|
C.2. MathFlux 的数学操作符
Treactor.math 包的 MathFlux 提供了一些用于数学计算的操作符,如 max、min、sumInt、averageDouble…
C.3. 重复与重试工具
reactor.retry 包中有一些能够帮助实现 Flux#repeatWhen 和 Flux#retryWhen 的工具。入口点(entry points)就是 Repeat 和 Retry 接口的工厂方法。
两个接口都可用作可变的构建器(mutative builder),并且相应的实现(implementing) 都可作为 Function 用于对应的操作符。
C.4. 调度器
Reactor-extra 提供了若干专用的调度器: - ForkJoinPoolScheduler,位于 reactor.scheduler.forkjoin 包; - SwingScheduler,位于 reactor.swing 包; - SwtScheduler,位于 reactor.swing 包。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号