Netty 高并发 (长文)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
写在前面
大家好,我是作者尼恩。本文的内容只是一个初稿、初稿,本文的知识,在《Netty Zookeeper Redis 高并发实战》一书时,进行大篇幅的完善和更新,并且进行的源码的升级。 博客和书不一样,书的内容更加系统化、全面化,更加层层升入、层次分明、更多次的错误排查,请大家以书的内容为准。
本文的最终内容, 具体请参考疯狂创客圈 倾力编著,机械工业出版社出版的 《Netty Zookeeper Redis 高并发实战》一书 。

下面结合Netty + Zookeeper,介绍一下亿级流量的IM的架构和部分实现。
1. 高并发IM架构与部分实现
1.1. 高并发的学习和应用价值
1.1.1. 高并发IM实战的价值
为什么要开始一个高并发IM的实战呢?
首先,实战完成一个分布式、高并发的IM系统,具有相当的技术挑战性。这一点,对于从事传统的企业级WEB开发的兄弟来说,相当于进入了一片全新的天地。企业级WEB,QPS峰值可能在1000以内,甚至在100以内,没有多少技术挑战性和含金量,属于重复性的CRUD的体力活。
而一个分布式、高并发的IM系系统,面临的QPS峰值可能在十万、百万、千万,甚至上亿级别。如果此纵深的层次化递进的高并发需求,直接无极限的考验着系统的性能。需要不断的从通讯的协议、到系统的架构进行优化,对技术能力是一种非常极致的考验和训练。
其次,不同的QPS峰值规模的IM系统,所处的用户需求环境是不一样的。这就造成了不同用户规模的IM系统,都具有一定的实际需求和市场需要,不一定需要所有的系统,都需要上亿级的高并发。但是,作为一个顶级的架构师,就应该具备全栈式的架构能力。需要能适应不同的用户规模的、差异化的技术场景,提供和架构出和对应的场景相互匹配的高并发IM系统。也就是说,IM系统综合性相对较强,相关的技术需要覆盖到满足各种不同场景的网络传输、分布式协调、分布式缓存、服务化架构等等。
来具体看看高并发IM的应用场景吧。
1.1.2. 高并发IM的应用场景
一切高实时性通讯、消息推送的场景,都需要高并发 IM 。
随着移动互联网、AI的飞速发展,高性能高并发IM(即时通讯),有着非常广泛的应用场景。
典型的应用场景如下:私信、聊天、大规模推送、视频会议、弹幕、抽奖、互动游戏、基于位置的应用(Uber、滴滴司机位置)、在线教育、智能家居等。
尤其是对于APP开发的小伙伴们来说,即时通讯,已经成为大多数APP标配。移动互联网时代,推送(Push)服务成为App应用不可或缺的重要组成部分,推送服务可以提升用户的活跃度和留存率。我们的手机每天接收到各种各样的广告和提示消息等大多数都是通过推送服务实现的。
随着5G时代物联网的发展,未来所有接入物联网的智能设备,都将是IM系统的客户端,这就意味着推送服务未来会面临海量的设备和终端接入。为了支持这些千万级、亿级终端,一定是需要强悍的后台系统。
有这么多的应用场景,对于想成长为JAVA高手的小伙伴们,高并发IM 都绕不开一个话题。
对于想在后台有所成就的小伙伴们来说,高并发IM实战,更是在终极BOSS PK之前的一场不可或缺的打怪练手。
总之,真刀真枪的完成一个高并发IM的实战,既可以积累到非常全面的高并发经验,又可以获得更多的挑战机会。
1.2. 高并发IM的架构
1.2.1. 支撑亿级流量的IM整体架构
整体的架构如下图:
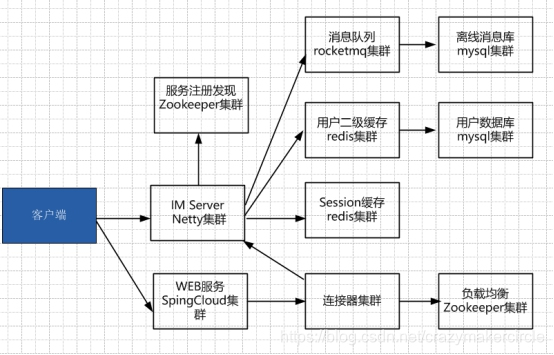
主要的集群介绍如下:
(1)Netty 服务集群
主要用来负责维持和客户端的TCP连接
(2)连接器集群
负责 Netty Server 集群的管理,包括注册、路由、负载均衡。集群IP注册和节点ID分配。主要在基于Zookeeper集群提供底层服务,来完成。
(3)缓存集群
负责用户、用户绑定关系、用户群组关系、用户远程会话等等数据的缓存。缓存临时数据、加快读速度。
(4)DB持久层集群
存在用户、群组、离线消息等等
(5)消息队列集群
用户状态广播,群组消息广播等等。
并没有完全涉及全部的集群介绍。只是介绍其中的部分核心功能。 如果全部的功能感兴趣,请关注疯狂创客圈的亿级流量实战学习项目。
理论上,以上集群具备完全的扩展能力,进行合理的横向扩展和局部的优化,支撑亿级流量,没有任何问题。
为什么这么说呢
单体的Netty服务器,远远不止支持10万并发,在CPU 、内存还不错的情况下,如果配置得当,甚至能撑到100万级别。所以,通过合理的高并发架构,能够让系统动态扩展到成百上千的Netty节点,支撑亿级流量,是没有任何问题的。
单体的Netty服务器,如何支撑100万高并发,请查询疯狂创客圈社群的文章《Netty 100万级高并发服务器配置》
1.2.2. IM通讯协议介绍
IM通讯协议,属于数据交换协议。IM系统的客户端和服务器节点之间,需要按照同一种数据交换协议,进行数据的交换。
数据交换协议的功能,简单的说:就是规定网络中的字节流数据,如何与应用程序需要的结构化数据相互转换。
数据交换协议主要的工作分为两步:结构化数据到二进制数据的序列化和反序列化。
数据交换协议按序列化类型:分为文本协议和二进制协议。
常见的文本协议包括XML、JSON。文本协议序列化之后,可读性好,便于调试,方便扩展。但文本协议的缺点在于解析效率一般,有很多的冗余数据,这一点主要体现在XML格式上。
常见的二进制协议包括PrototolBuff、Thrift,这些协议都自带了数据压缩,编解码效率高,同时兼具扩展性。二进制协议的优势很明显,但是劣势也非常的突出。和文本协议相反,序列化之后的二进制协议报文数据,基本上没有什么可读性,很显然,这点不利于大家开发和调试。
因此,在协议的选择上,对于并发度不高的IM系统,建议使用文本协议,比如JSON。对于并发度非常之高,QPS在千万级、亿级的通讯系统,尽量选择二进制的协议。
据说,微信所使用的数据交换协议,就是 PrototolBuff二进制协议。
1.2.3. 长连接和短连接
什么是长连接呢?
客户端client向server发起连接,server接受client连接,双方建立连接。Client与server完成一次读写之后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。
大家知道,TCP协议的连接过程是比较繁琐的,建立连接是需要三次握手的,而释放则需要4次握手,所以说每个连接的建立都是需要资源消耗和时间消耗的。
在高并发的IM系统中,客户端和服务器之间,需要大量的发送通讯的消息,如果每次发送消息,都去建立连接,客户端的和服务器的连接建立和断开的开销是非常巨大的。所以,IM消息的发送,肯定是需要长连接。
什么是短连接呢?
客户端client向server发起连接,server接受client连接,在三次握手之后,双方建立连接。Client与server完成一次读写,发送数据包并得到返回的结果之后,通过客户端和服务端的四次握手进行关闭断开。
短连接适用于数据请求频度较低的场景。比如网站的浏览和普通的web请求。短连接的优点是:管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段。
在高并发的IM系统中,客户端和服务器之间,除了消息的通讯外,还需要用户的登录与认证、好友的更新与获取等等一些低频的请求,这些都使用短连接来实现。
综上所述,在这个高并发IM系统中,存在两个类的服务器。一类短连接服务器和一个长连接服务器。
短连接服务器也叫Web服务服务器,主要是功能是实现用户的登录鉴权和拉取好友、群组、数据档案等相对低频的请求操作。
长连接服务器也叫IM即时通讯服务器,主要作用就是用来和客户端建立并维持长连接,实现消息的传递和即时的转发。并且,分布式网络非常复杂,长连接管理是重中之重,需要考虑到连接保活、连接检测、自动重连等方方面面的工作。
短连接Web服务器和长连接IM服务器之间,是相互配合的。在分布式集群的环境下,用户首先通过短连接登录Web服务器。Web服务器在完成用户的账号/密码验证,返回uid和token时,还需要通过一定策略,获取目标IM服务器的IP地址和端口号列表,返回给客户端。客户端开始连接IM服务器,连接成功后,发送鉴权请求,鉴权成功则授权的长连接正式建立。
如果用户规模庞大,无论是短连接Web服务器,还是长连接IM服务器,都需要进行横向的扩展,都需要扩展到上十台、百台、甚至上千台机器。只有这样,才能有良好性能,提高良好的用户体验。因此,需要引入一个新的角色,短连接网关(WebGate)。
WebGate短连接网关的职责,首先是代理大量的Web服务器,从而无感知的实现短连接的高并发。在客户端登录时和进行其他短连接时,不直接连接Web服务器,而是连接Web网关。围绕Web网关和Web高并发的相关技术,目前非常成熟,可以使用SpringCloud 或者 Dubbo 等分布式Web技术,也很容易扩展。
除此之外,大量的IM服务器,又如何协同和管理呢?
基于Zookeeper或者其他的分布式协调中间件,可以非常方便、轻松的实现一个IM服务器集群的管理,包括而且不限于命名服务、服务注册、服务发现、负载均衡等管理。
当用户登录成功的时候,WebGate短连接网关可以通过负载均衡技术,从Zookeeper集群中,找出一个可用的IM服务器的地址,返回给用户,让用户来建立长连接。
1.2.4. 技术选型
(1)核心:
Netty4.x + spring4.x + zookeeper 3.x + redis 3.x + rocketMQ 3.x
(2)短连接服务:spring cloud
基于restful 短连接的分布式微服务架构, 完成用户在线管理、单点登录系统。
(3)长连接服务:Netty
Netty就不用太多介绍了。
(4)消息队列:
rocketMQ 高速队列。整流作用。
(5)底层数据库:mysql+mongodb
mysql做业务还是很方便的,用来存储结构化数据,如用户数据。
mongodb 很重要,用来存储非结构化离线消息。
(6)协议 Protobuf + JSON
Protobuf 是最高效的IM二进制协议,用于长连接。
JSON 是最紧凑的文本协议,用于短连接。
文本协议 Gson + fastjson。 Gson 谷歌的东西,fastjson 淘宝的东西,两者互补,结合使用。
1.3. 分布式IM命名服务
前面提到,一个高并发系统会有很多的节点组成,而且,节点的数量是不断动态变化的。
在一个即时消息通讯系统中,从0到1到N,用户量可能会越来越多,或者说由于某些活动影响,会不断的出现流量洪峰。这时需要动态加入大量的节点。另外,由于机器或者网络的原因,一些节点主动的离开的集群。如何为大量的动态节点命名呢?最好的办法是使用分布式命名服务,按照一定的规则,为动态上线和下线的工作节点命名。
疯狂创客圈的高并发IM实战学习项目,基于Zookeeper构建分布式命名服务,为每一个IM工作服务器节点动态命名。
1.3.1. IM节点的POJO类
首先定义一个POJO类,保存IM worker节点的基础信息如Netty 服务IP、Netty 服务端口,以及Netty的服务连接数。
具体如下:
/**
* create by 尼恩 @ 疯狂创客圈
**/
@Data
public class ImNode implements Comparable<ImNode> {
//worker 的Id,由Zookeeper负责生成
private long id;
//Netty 服务 的连接数
private AtomicInteger balance;
//Netty 服务 IP
private String host;
//Netty 服务 端口
private String port;
//...
}
这个POJO类的IP、端口、balance负载,和每一个节点的Netty服务器相关。而id属性,则由利用Zookeeper的中Znode子节点能顺序编号的性质,由Zookeeper生成。
1.3.2. IM节点的ImWorker类
命名服务的思路是:所有的工作节点,都在Zookeeper的同一个的父节点下,创建顺序节点。然后从返回的临时路径上,取得属于自己的那个后缀的编号。
主要的代码如下:
package com.crazymakercircle.imServer.distributed;
import com.crazymakercircle.imServer.server.ServerUtils;
import com.crazymakercircle.util.ObjectUtil;
import com.crazymakercircle.zk.ZKclient;
import org.apache.curator.framework.CuratorFramework;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;
/**
* create by 尼恩 @ 疯狂创客圈
**/
public class ImWorker {
//Zk curator 客户端
private CuratorFramework client = null;
//保存当前Znode节点的路径,创建后返回
private String pathRegistered = null;
private ImNode node = ImNode.getLocalInstance();
private static ImWorker singleInstance = null;
//取得单例
public static ImWorker getInst() {
if (null == singleInstance) {
singleInstance = new ImWorker();
singleInstance.client =
ZKclient.instance.getClient();
singleInstance.init();
}
return singleInstance;
}
private ImWorker() {
}
// 在zookeeper中创建临时节点
public void init() {
createParentIfNeeded(ServerUtils.MANAGE_PATH);
// 创建一个 ZNode 节点
// 节点的 payload 为当前worker 实例
try {
byte[] payload = ObjectUtil.Object2JsonBytes(node);
pathRegistered = client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(ServerUtils.pathPrefix, payload);
//为node 设置id
node.setId(getId());
} catch (Exception e) {
e.printStackTrace();
}
}
public long getId() {
String sid = null;
if (null == pathRegistered) {
throw new RuntimeException("节点注册失败");
}
int index = pathRegistered.lastIndexOf(ServerUtils.pathPrefix);
if (index >= 0) {
index += ServerUtils.pathPrefix.length();
sid = index <= pathRegistered.length() ? pathRegistered.substring(index) : null;
}
if (null == sid) {
throw new RuntimeException("节点ID生成失败");
}
return Long.parseLong(sid);
}
public boolean incBalance() {
if (null == node) {
throw new RuntimeException("还没有设置Node 节点");
}
// 增加负载:增加负载,并写回zookeeper
while (true) {
try {
node.getBalance().getAndIncrement();
byte[] payload = ObjectUtil.Object2JsonBytes(this);
client.setData().forPath(pathRegistered, payload);
return true;
} catch (Exception e) {
return false;
}
}
}
public boolean decrBalance() {
if (null == node) {
throw new RuntimeException("还没有设置Node 节点");
}
// 增加负载:增加负载,并写回zookeeper
while (true) {
try {
int i = node.getBalance().decrementAndGet();
if (i < 0) {
node.getBalance().set(0);
}
byte[] payload = ObjectUtil.Object2JsonBytes(this);
client.setData().forPath(pathRegistered, payload);
return true;
} catch (Exception e) {
return false;
}
}
}
private void createParentIfNeeded(String managePath) {
try {
Stat stat = client.checkExists().forPath(managePath);
if (null == stat) {
client.create()
.creatingParentsIfNeeded()
.withProtection()
.withMode(CreateMode.PERSISTENT)
.forPath(managePath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
注意,这里有三个Znode相关的路径:
(1)MANAGE_PATH
(2)pathPrefix
(3)pathRegistered
第一个MANAGE_PATH是一个常量。为所有临时工作Worker节点的父亲节点的路径,在创建Worker节点之前,首先要检查一下,父亲Znode节点是否存在,否则的话,先创建父亲节点。父亲节点的创建方式是:持久化节点,而不是临时节点。
检查和创建父亲节点的代码如下:
private void createParentIfNeeded(String managePath) {
try {
Stat stat = client.checkExists().forPath(managePath);
if (null == stat) {
client.create()
.creatingParentsIfNeeded()
.withProtection()
.withMode(CreateMode.PERSISTENT)
.forPath(managePath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
第二路径pathPrefix是所有临时节点的前缀。例子的值“/im/Workers/”,是在工作路径后,加上一个“/”分割符。也可是在工作路径的后面,加上“/”分割符和其他的前缀字符,如:“/im/Workers/id-”,“/im/Workers/seq-”等等。
第三路径pathRegistered是临时节点的创建成功之后,返回的完整的路径。比如:/im/Workers/0000000000,/im/Workers/0000000001 等等。后边的编号是顺序的。
创建节点成功后,截取后边的数字,放在POJO对象中,供后边使用:
//为node 设置id
node.setId(getId());
1.4. 即时通讯消息的路由和转发
如果连接在不同的Netty工作站点的客户端之间,需要相互进行消息的发送,那么,就需要在不同的Worker节点之间进行路由和转发。
Worker节点路由是指,根据消息需要转发的目标用户,找到用户的连接所在的Worker节点。由于节点和节点之间,都有可能需要相互转发,所以,节点之间的关系是一种网状结构。每一个节点,都需要具备路由的能力。
1.4.1. IM路由器WorkerRouter
为每一个Worker节点增加一个IM路由器类,叫做WorkerRouter 。为了能够转发到所有的节点,需要一是要订阅到集群中所有的在线Netty服务器,并且保存起来,二是要其他的Netty服务器建立一个长连接,用于转发消息。
WorkerRouter 核心代码,节选如下:
/**
\* create by 尼恩 @ 疯狂创客圈
**/
@Slf4j
public class WorkerRouter {
//Zk客户端
private CuratorFramework client = null;
//单例模式
private static WorkerRouter singleInstance = null;
//监听路径
private static final String path =
"/im/Workers";
//节点的容器
private ConcurrentHashMap<Long, WorkerReSender> workerMap =
new ConcurrentHashMap<>();
public static WorkerRouter getInst() {
if (null == singleInstance) {
singleInstance = new WorkerRouter();
singleInstance.client = ZKclient.instance.getClient();
singleInstance.init();
}
return singleInstance;
}
private void init() {
try {
//订阅节点的增加和删除事件
TreeCache treeCache = new TreeCache(client, path);
TreeCacheListener l = new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client,
TreeCacheEvent event) throws Exception
{
ChildData data = event.getData();
if (data != null) {
switch (event.getType()) {
case NODE_REMOVED:
processNodeRemoved(data);
break;
case NODE_ADDED:
processNodeAdded(data);
break;
default:
break;
}
}
}
};
treeCache.getListenable().addListener(l);
treeCache.start();
} catch (Exception e) {
e.printStackTrace();
}
//...
}
在上一小节中,我们已经知道,一个节点上线时,首先要通过命名服务,加入到Netty 集群中。上面的代码中,WorkerRouter 路由器使用curator的TreeCache 缓存,订阅了节点的NODE_ADDED节点新增消息。当一个新的Netty节点加入是,通过processNodeAdded(data) 方法, 在本地保存一份节点的POJO信息,并且建立一个消息中转的Netty客户连接。
处理节点新增的方法 processNodeAdded(data)比较重要,代码如下:
private void processNodeAdded(ChildData data) {
log.info("[TreeCache]节点更新端口, path={}, data={}",
data.getPath(), data.getData());
byte[] payload = data.getData();
String path = data.getPath();
ImNode imNode =
ObjectUtil.JsonBytes2Object(payload, ImNode.class);
long id = getId(path);
imNode.setId(id);
WorkerReSender reSender = workerMap.get(imNode.getId());
//重复收到注册的事件
if (null != reSender && reSender.getNode().equals(imNode)) {
return;
}
//服务器重新上线
if (null != reSender) {
//关闭老的连接
reSender.stopConnecting();
}
//创建一个消息转发器
reSender = new WorkerReSender(imNode);
//建立转发的连接
reSender.doConnect();
workerMap.put(id, reSender);
}
router路由器有一个容器成员workerMap,用于封装和保存所有的在线节点。当一个节点新增时,router取到新增的Znode路径和负载。Znode路径中有新节点的ID,Znode的payload负载中,有新节点的Netty服务的IP和端口,这个三个信息共同构成新节点的POJO信息 —— ImNode节点信息。 router在检查完和确定本地不存在该节点的转发器后,新增一个转发器 WorkerReSender,将新节点的转发器,保存在自己的容器中。
这里有一个问题,为什么在router路由器中,不简单、直接、干脆的保存新节点的POJO信息呢?
因为router路由器的主要作用,除了路由节点,还需要方便的进行消息的转发,所以,router路由器保存的是转发器 WorkerReSender,而新增的远程Netty节点的POJO信息,封装在转发器中。
1.4.2. IM转发器WorkerReSender
IM转发器,封装了远程节点的IP、端口、以及ID消息,具体是在ImNode类型的成员中。另外,IM转发器还维持一个到远程节点的长连接。也就是说,它是一个Netty的NIO客户端,维护了一个到远程节点的Netty Channel 通道成员,通过这个通道,将消息转发给远程的节点。
IM转发器的核心代码,如下:
package com.crazymakercircle.imServer.distributed;
import com.crazymakercircle.im.common.bean.User;
import com.crazymakercircle.im.common.codec.ProtobufEncoder;
import io.netty.bootstrap.Bootstrap;
import io.netty.buffer.PooledByteBufAllocator;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.util.concurrent.GenericFutureListener;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import java.util.Date;
import java.util.concurrent.TimeUnit;
/**
* create by 尼恩 @ 疯狂创客圈
**/
@Slf4j
@Data
public class WorkerReSender {
//连接远程节点的Netty 通道
private Channel channel;
//连接远程节点的POJO信息
private ImNode remoteNode;
/**
* 连接标记
*/
private boolean connectFlag = false;
GenericFutureListener<ChannelFuture> closeListener = (ChannelFuture f) ->
{
log.info(": 分布式连接已经断开……", remoteNode.toString());
channel = null;
connectFlag = false;
WorkerRouter.getInst().removeWorkerById(remoteNode);
};
private GenericFutureListener<ChannelFuture> connectedListener = (ChannelFuture f) ->
{
final EventLoop eventLoop
= f.channel().eventLoop();
if (!f.isSuccess()) {
log.info("连接失败!在10s之后准备尝试重连!");
eventLoop.schedule(
() -> WorkerReSender.this.doConnect(),
10,
TimeUnit.SECONDS);
connectFlag = false;
} else {
connectFlag = true;
log.info("分布式IM节点连接成功:", remoteNode.toString());
channel = f.channel();
channel.closeFuture().addListener(closeListener);
}
};
private Bootstrap b;
private EventLoopGroup g;
public WorkerReSender(ImNode n) {
this.remoteNode = n;
/**
* 客户端的是Bootstrap,服务端的则是 ServerBootstrap。
* 都是AbstractBootstrap的子类。
**/
b = new Bootstrap();
/**
* 通过nio方式来接收连接和处理连接
*/
g = new NioEventLoopGroup();
}
// 连接和重连
public void doConnect() {
// 服务器ip地址
String host = remoteNode.getHost();
// 服务器端口
int port = Integer.parseInt(remoteNode.getPort());
try {
if (b != null && b.group() == null) {
b.group(g);
b.channel(NioSocketChannel.class);
b.option(ChannelOption.SO_KEEPALIVE, true);
b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
b.remoteAddress(host, port);
// 设置通道初始化
b.handler(
new ChannelInitializer<SocketChannel>() {
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new ProtobufEncoder());
}
}
);
log.info(new Date() + "开始连接分布式节点", remoteNode.toString());
ChannelFuture f = b.connect();
f.addListener(connectedListener);
// 阻塞
// f.channel().closeFuture().sync();
} else if (b.group() != null) {
log.info(new Date() + "再一次开始连接分布式节点", remoteNode.toString());
ChannelFuture f = b.connect();
f.addListener(connectedListener);
}
} catch (Exception e) {
log.info("客户端连接失败!" + e.getMessage());
}
}
public void stopConnecting() {
g.shutdownGracefully();
connectFlag = false;
}
public void writeAndFlush(Object pkg) {
if (connectFlag == false) {
log.error("分布式节点未连接:", remoteNode.toString());
return;
}
channel.writeAndFlush(pkg);
}
}
IM转发器中,主体是与Netty相关的代码,比较简单。至少,IM转发器比Netty服务器的代码,简单太多了。
转发器有一个消息转发的方法,直接通过Netty channel通道,将消息发送到远程节点。
public void writeAndFlush(Object pkg) {
if (connectFlag == false) {
log.error("分布式节点未连接:", remoteNode.toString());
return;
}
channel.writeAndFlush(pkg);
}
1.5. Worker集群的负载均衡
理论上来说,负载均衡是一种手段,用来把对某种资源的访问分摊给不同的服务器,从而减轻单点的压力。
在高并发的IM系统中,负载均衡就是需要将IM长连接分摊到不同的Netty服务器,防止单个Netty服务器负载过大,而导致其不可用。
前面讲到,当用户登录成功的时候,短连接网关WebGate需要返回给用户一个可用的Netty服务器的地址,让用户来建立Netty长连接。而每台Netty工作服务器在启动时,都会去zookeeper的“/im/Workers”节点下注册临时节点。
因此,短连接网关WebGate可以在用户登录成功之后,去“/im/Workers”节点下取得所有可用的Netty服务器列表,并通过一定的负载均衡算法计算得出一台Netty工作服务器,并且返回给客户端。
1.5.1. ImLoadBalance 负载均衡器
短连接网关WebGate 获得Netty服务器的地址,通过查询Zookeeper集群来实现。定义一个负载均衡器,ImLoadBalance类 ,将计算最佳服务器的算法,放在负载均衡器中。
ImLoadBalance类 的核心代码,如下:
package com.crazymakercircle.Balance;
import com.crazymakercircle.ObjectUtil;
import com.crazymakercircle.util.ImNode;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.curator.framework.CuratorFramework;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* create by 尼恩 @ 疯狂创客圈
**/
@Data
@Slf4j
public class ImLoadBalance {
//Zk客户端
private CuratorFramework client = null;
//工作节点的路径
private String mangerPath = "/im/Workers";
public ImLoadBalance() {
}
public ImLoadBalance(CuratorFramework client, String mangerPath)
{
this.client = client;
this.mangerPath = mangerPath;
}
public static ImLoadBalance instance() {
}
public ImNode getBestWorker()
{
List<ImNode> workers =getWorkers();
ImNode best= balance(workers);
return best;
}
protected ImNode balance(List<ImNode> items) {
if (items.size() > 0) {
// 根据balance值由小到大排序
Collections.sort(items);
// 返回balance值最小的那个
return items.get(0);
} else {
return null;
}
}
///....
}
短连接网关WebGate 会调用getBestWorker()方法,取得最佳的IM服务器。而在这个方法中,有两个很重要的方法。 一个是取得所有的IM服务器列表,注意是带负载的。二个是通过负载信息,计算最小负载的服务器。
所有的IM服务器列表的代码如下:
/**
* 从zookeeper中拿到所有IM节点
*/
protected List<ImNode> getWorkers() {
List<ImNode> workers = new ArrayList<ImNode>();
List<String> children = null;
try {
children = client.getChildren().forPath(mangerPath);
} catch (Exception e) {
e.printStackTrace();
return null;
}
for (String child : children) {
log.info("child:", child);
byte[] payload = null;
try {
payload = client.getData().forPath(child);
} catch (Exception e) {
e.printStackTrace();
}
if (null == payload) {
continue;
}
ImNode worker = ObjectUtil.
JsonBytes2Object(payload, ImNode.class);
workers.add(worker);
}
return workers;
}
代码中,首先取得 "/im/Workers" 目录下所有的临时节点,使用的是curator的getChildren 获取子节点方法。然后,通过getData方法,取得每一个子节点的二进制负载。最后,将负载信息转成成 POJO ImNode 对象。
取到了工作节点的POJO 列表之后,通过一个简单的算法,计算出balance值最小的ImNode对象。
取得最小负载的 balance 方法的代码如下:
protected ImNode balance (List<ImNode> items) {
if (items.size() > 0) {
// 根据balance由小到大排序
Collections.sort(items);
// 返回balance值最小的那个
return items.get(0);
} else {
return null;
}
}
1.5.2. 与WebGate的整合
在用户登录的Http API 方法中,调用ImLoadBalance类的getBestWorker()方法,取得最佳的IM服务器信息,返回给登录的客户端。
核心代码如下:
@EnableAutoConfiguration
@RestController
@RequestMapping(value = "/user",
produces = MediaType.APPLICATION_JSON_UTF8_VALUE)
public class UserAction extends BaseController
{
@Resource
private UserService userService;
@RequestMapping(value = "/login/{username}/{password}")
public String loginAction(
@PathVariable("username") String username,
@PathVariable("password") String password)
{
User user = new User();
user.setUserName(username);
user.setPassWord(password);
User loginUser = userService.login(user);
ImNode best=ImLoadBalance.instance().getBestWorker();
LoginBack back =new LoginBack();
back.setImNode(best);
back.setUser(loginUser);
back.setToken(loginUser.getUserId().toString());
String r = super.getJsonResult(back);
return r;
}
//....
}
1.7. 分布式Session
什么是会话?
为了方便客户端的开发,管理与服务器的连接,这里引入一个非常重要的中间角色——Session (会话)。有点儿像Web开发中的Tomcat的服务器 Session,但是又有很大的不同。
1.7.1. SessionLocal本地会话
客户端的本地会话概念图,如下图所示:

客户端会话有两个很重的成员,一个是user,代表了拥有会话的用户。一个是channel,代表了连接的通道。两个成员的作用是:
(1)user成员 —— 通过它可以获得当前的用户信息
(2)channel成员 —— 通过它可以发送Netty消息
Session需要和 channel 相互绑定,为什么呢?原因有两点:
(1)消息发送的时候, 需要从Session 写入 Channel ,这相当于正向的绑定;
(2)收到消息的时候,消息是从Channel 过来的,所以可以直接找到 绑定的Session ,这相当于反向的绑定。
Session和 channel 相互绑定的代码如下:
//正向绑定
ClientSession session = new (channel);
//反向绑定
channel.attr(ClientSession.SESSION).set(session);
正向绑定,是直接通过ClientSession构造函数完成。反向绑定是通过channel 自身的所具备的容器能力完成。Netty的Channel类型实现了AttributeMap接口 ,它相当于一个 Map容器。 反向的绑定,利用了channel 的这个特点。
总的来说,会话Session 左手用户实例,右手服务器的channel连接通道,可以说是左拥右抱,是开发中经常使用到的类。
1.7.2. SessionDistrubuted分布式会话
在分布式环境下,本地的Session只能绑定本地的用户和通道,够不着其他Netty节点上的用户和通道。
如何解决这个难题呢? 一个简单的思路是:制作一个本地Session的副本,保存在分布式缓存Redis中。对于其他的Netty节点来说,可以取到这份Redis副本,从而进行消息的路由和转发。
基于redis进行分布式的Session 缓存,与本地Session的内容不一样,不需要保存用户的具体实例,也不需要保存用户的Netty Channel通道。只需要能够根据它找到对于的Netty服务器节点即可。
我们将这个Session,命名为 SessionDistrubuted。代码如下:
/**
\* create by 尼恩 @ 疯狂创客圈
**/
@Data
public class SessionDistrubuted implements ServerSession {
//用户ID
private String userId;
//Netty 服务器ID
private long nodeId;
//sessionId
private String sessionId;
public SessionDistrubuted(
String sessionId, String userId, long nodeId) {
this.sessionId = sessionId;
this.userId = userId;
this.nodeId = nodeId;
}
//...
}
如何判断这个Session是否有效呢? 可以根据其nodeId,在本地路由器WorkerRouter中查找对应的消息转发器,如果没有找到,说明该Netty服务节点是不可以连接的。于是,该Session为无效。
判断Session是否有效的代码如下:
@Override
public boolean isValid() {
WorkerReSender sender = WorkerRouter.getInst()
.getRedirectSender(nodeId);
if (null == sender) {
return false;
}
return true;
}
只要该Session为有效。就可以通过它,转发消息到目的nodeId对应的Netty 服务器。
代码如下:
@Override
public void writeAndFlush(Object pkg) {
WorkerReSender sender = WorkerRouter
.getInst().getRedirectSender(nodeId);
sender.writeAndFlush(pkg);
}
在分布式环境下,结合本地Session和远程Session,发送消息也就变得非常之简单。如果在本地找到了目标的Session,就直接通过其Channel发送消息到客户端。反之,就通过远程Session,将消息转发到客户端所在的Netty服务器,由该服务器发送到目标客户端。
1.8. 分布式的在线用户统计
顾名思义,计数器是用来计数的。在分布式环境中,常规的计数器是不能使用的,在此介绍基本zookeeper实现的分布式计数器。利用ZooKeeper可以实现一个集群共享的计数器,只要使用相同的path就可以得到最新的计数器值, 这是由ZooKeeper的一致性保证的。
1.8.1. Curator的分布式计数器
Curator有两个计数器, 一个是用int来计数(SharedCount),一个用long来计数(DistributedAtomicLong)。
这里使用DistributedAtomicLong来实现高并发IM系统中的在线用户统计。
代码如下:
/**
* create by 尼恩 @ 疯狂创客圈
**/
public class OnlineCounter {
private static final int QTY = 5;
private static final String PATH = "/im/OnlineCounter";
//Zk客户端
private CuratorFramework client = null;
//单例模式
private static OnlineCounter singleInstance = null;
DistributedAtomicLong onlines = null;
public static OnlineCounter getInst() {
if (null == singleInstance) {
singleInstance = new OnlineCounter();
singleInstance.client = ZKclient.instance.getClient();
singleInstance.init();
}
return singleInstance;
}
private void init() {
//分布式计数器,失败时重试10,每次间隔30毫秒
onlines = new DistributedAtomicLong( client,
PATH, new RetryNTimes(10, 30));
}
public boolean increment() {
boolean result = false;
AtomicValue<Long> val = null;
try {
val = onlines.increment();
result = val.succeeded();
System.out.println("old cnt: " + val.preValue()
+ " new cnt : " + val.postValue()
+ " result:" + val.succeeded());
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
public boolean decrement() {
boolean result = false;
AtomicValue<Long> val = null;
try {
val = onlines.decrement();
result = val.succeeded();
System.out.println("old cnt: " + val.preValue()
+ " new cnt : " + val.postValue()
+ " result:" + val.succeeded());
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
1.8.2. 用户上线和下线统计
当用户上线的时候,使用increase方法,分布式的增加一次数量:
/**
\* 增加本地session
*/
public void addSession(String sessionId, SessionLocal s) {
localMap.put(sessionId, s);
String uid = s.getUser().getUid();
//增加用户数
OnlineCounter.getInst().increment();
//...
}
当用户下线的时候,使用decrease方法,分布式的减少一次数量:
/**
\* 删除本地session
*/
public void removeLocalSession(String sessionId) {
if (!localMap.containsKey(sessionId)) {
return;
}
localMap.remove(sessionId);
//减少用户数
OnlineCounter.getInst().decrement();
//...
}
写在最后
目前和几个小伙伴一起,组织了一个高并发的实战社群【疯狂创客圈】,完成整个项目的完整的架构和开发实战,欢迎参与。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号