3 数据分析之Numpy模块(2)
数组函数
通用元素级数组函数通用函数(即ufunc)是一种对ndarray中的数据执行元素级的运算。我们可以将其看做是简单的函数(接收一个或多个参数,返回一个或者多个返回值).
常用一元ufunc:
| 函数 | 说明 |
|---|---|
| abs | 计算整数、浮点数的绝对值。 |
| sqrt | 计算各元素的平方根。相当于arr ** 0.5 |
| square | 计算各元素的平方。相当于arr ** 2 |
| sign | 计算各元素的正负号,1(正数)、0(零)、-1(负数) |
| ceil | 计算各元素的celling值,即大于该值的最小整数。 |
| floor | 计算各元素的floor值,即小于等于该值的最大整数。 |
| rint | 将各元素值四舍五入到最近的整数,保留dtype |
| modf | 将数组的小数和整数部分以两个独立数组的形式返回 |
| isnan | 返回一个表示“那些是NaN(这不是一个数字)”的布尔类型数组. |
常用二元ufunc
| 函数 | 说明 |
|---|---|
| add | 将数组中对应的元素相加. |
| subtract | 从第一个数组中减去第二个数组中的元素. |
| multiply | 数组元素相乘 |
| divide、floor_divide | 除法、向下整除法(丢弃余数) |
| power | 对第一个数组中的元素A,根据第二数组中的相应元素B,计算A的B次方。 |
| maximum、fmax | 元素级的最大值计算。fmax将忽略NaN |
| minimum、fmin | 元素级的最小值计算。fmin将忽略NaN |
| mod | 元素级的求模计算. |
| copysign | 将第二个数组中的值的符号复制给第一个数组中的值. |
| greater、greater_equal | 执行元素级的运算比较,最终产生布尔类型数组 |
练习
import numpy as np arr1 = np.random.randint(1, 10, (4, 5)) arr2 = np.random.randint(-10, -1, (4, 5)) arr1
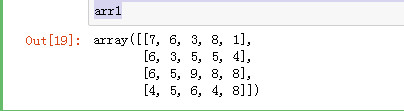
arr2
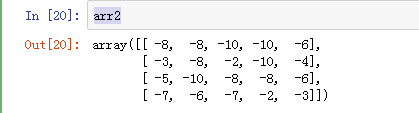
把数组2的符号复制给数组1
np.copysign(arr1, arr2)

arr3 = np.array([1, 2, np.nan, 3]) arr3

判断是不是NAN
np.isnan(arr3)

一元运算符练习
ndarray1 = np.array([3.5, 1.7, 2.2, -7.8, np.nan, 4.6, -3.4])
ndarray1

abs 计算整数、浮点数的绝对值
np.abs(ndarray1)

sqrt 计算各元素的平方根。相当于arr ** 0.5
np.square(ndarray1)

sign 计算各元素的正负号,1(正数)、0(零)、-1(负数)
np.sign(ndarray1)

ceil 计算各元素的celling值,即大于该值的最小整数
np.floor(ndarray1)

rint 将各元素值四舍五入到最近的整数,保留dtype
np.rint(ndarray1)

isnan 返回一个表示“那些是NaN(这不是一个数字)”的布尔类型数组.
np.isnan(ndarray1)

二元运算符
ndarray2 = np.random.randint(1, 20, (4, 5)) ndarray3 = np.random.randint(-10, 10, (4, 5)) ndarray3 = np.where(ndarray3 == 0, 1, ndarray3)
ndarray2
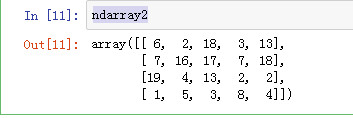
ndarray3
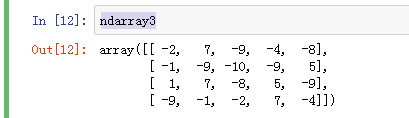
add 将数组中对应的元素相加
np.add(ndarray2, ndarray3)

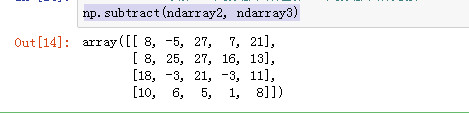
subtract 从第一个数组中减去第二个数组中的元素.
np.subtract(ndarray2, ndarray3)
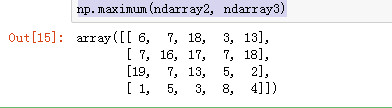
maximum、fmax 从两个数组中取出最大值。fmax将忽略NaN
np.maximum(ndarray2, ndarray3)
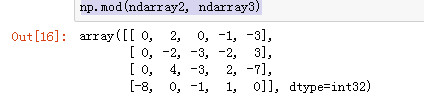
mod 元素级的求模计算.
np.mod(ndarray2, ndarray3)
copysign 将第二个数组中的值的符号复制给第一个数组中的值.
np.copysign(ndarray2, ndarray3)

greater、greater_equal 执行元素级的运算比较,最终产生布尔类型数组。
np.greater(ndarray2, ndarray3)

数组统计函数
可以通过数组上的一组数学函数对整个数组或某些数据进行统计计算。 基本的数组统计方法:
| 方法 | 说明 |
|---|---|
| mean | 算数平均数。零长度的数组的mean为NaN. |
| sum | 所有元素的和. |
| max、min | 所有元素的最大值,所有元素的最小值 |
| std、var | 所有元素的标准差,所有元素的方差 |
| argmax、argmin | 最大值的下标索引值,最小值的下标索引值 |
| cumsum、cumprod | 所有元素的累计和、所有元素的累计积 |
多维数组默认统计全部维度,axis参数可以按指定轴心统计,值为0则按列统计,值为1则按行统计。
示例代码:
import numpy as np
ndarray1 = np.random.randint(1, 10, (4, 5))
ndarray1
1. sum求元素和
# 0-列 1-行
# sum-计算所有元素和
np.sum(ndarray1)
# sum-计算每一列的元素和
np.sum(ndarray1, axis=0)
# sum-计算每一行的元素和
np.sum(ndarray1, axis=1)
2. argmax求最大值索引
# argmax-默认情况下按照一维数组索引
np.argmax(ndarray1)
# argmax-统计每一列最大
np.argmax(ndarray1, axis=0)
# argmax-统计每一行最大
np.argmax(ndarray1, axis=1)
3. mean求平均数
# mean-求所有元素的平均值
np.mean(ndarray1)
# mean-求每一列元素的平均值
np.mean(ndarray1, axis=0)
# mean-求每一行元素的平均值
np.mean(ndarray1, axis=1)
4. cumsum求元素累计和
# cumsum-前面元素的累计和
np.cumsum(ndarray1)
# cumsum-每一列元素的累计和
np.cumsum(ndarray1, axis=0)
# cumsum-每一行元素的累计和
np.cumsum(ndarray1, axis=1)
练习代码2
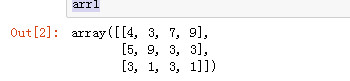
import numpy as np arr1 = np.random.randint(1, 10, (3, 4)) arr1
算数平均数
arr1.mean()
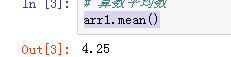
axis 轴
axis=0 求列的平均数
axis=1 求行的平均数
axis=0 求列的平均数
arr1.mean(axis=0)

axis=1 求行的平均数
arr1.mean(axis=1)
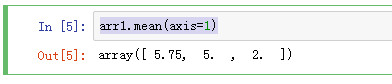
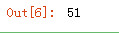
sum函数求和
arr1.sum()
求列的和
arr1.sum(axis=0)

求行的和
arr1.sum(axis=1)

累积和 cumsum
每个元素都是前边所有的想加
arr1.cumsum()

all和any函数
import numpy as np ndarray1 = np.arange(6).reshape((2, 3)) ndarray2 = np.arange(6).reshape((2, 3)) ndarray3 = np.array([[ 0, 1, 2], [ 8, 9, 10]])

if (ndarray1 == ndarray2).all():
print('相等')
else:
print('不相等')

(ndarray1 == ndarray3).all()

if (ndarray1 == ndarray3).any():
print('两个数组中有元素相等!')
else:
print('都不相等!')

添加和删除函数
| 方法 | 描述 |
|---|---|
| delete | Return a new array with sub-arrays along an axis deleted. |
| insert(arr, obj, values[, axis]) | Insert values along the given axis. |
| append(arr, values[, axis]) | Append values to the end of an array. |
| resize(a, new_shape) | Return a new array with the specified shape. |
| concatenate((a1,a2,...), axis=0) | Join a sequence of arrays along an existing axis. |
reshape:有返回值,即不对原始多维数组进行修改; resize:无返回值,即会对原始多维数组进行修改;
import numpy as np arr1 = np.random.randint(1, 10, (5, 5)) arr1
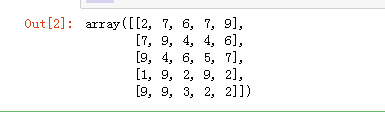
delete方法删除一行或者一列元素
# 如果没有指定行列,默认删除位置元素(将二维数组当做一维数组来计算位置)
np.delete(arr1, 0)

按照行删除
删除每一列的第1个位置的元素
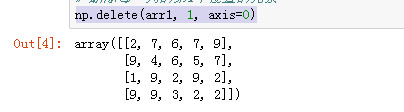
np.delete(arr1, 1, axis=0)
按照列删除
删除每一行的第1个位置的元素
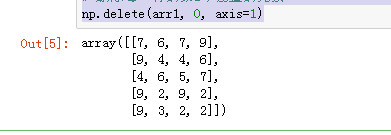
np.delete(arr1, 0, axis=1)
. insert插入一行或者一列元素
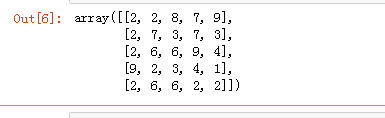
arr2 = np.random.randint(1, 10, (5, 5)) arr2
插入一行元素
np.insert(arr2, 0, [100, 200, 300, 400, 500], axis=0)

插入一列元素
np.insert(arr2, 1, [11, 22, 33, 44, 55], axis=1)

append追加元素
把二维数组变成一维数组
np.append(arr2, 100)

concatenate合并
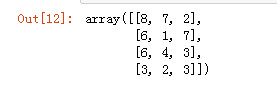
arr3 = np.random.randint(1, 10, (4, 3)) arr3
arr4 = np.random.randint(1, 10, (4, 3)) arr4
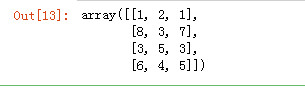
默认将第二个数组合并到第一个数组的垂直下面
np.concatenate([arr3, arr4])

横向合并两个数组
np.concatenate([arr3, arr4], axis=1)

唯一化和集合函数
Numpy提供了一些针对一维ndarray的基本集合运算。最常用的就是np.unique了,它用于找出数组中的唯一值并返回已排序的结果。
| 方法 | 说明 |
|---|---|
| unique(x) | 计算x中的唯一元素,并返回有序结果. |
| intersect1d(x, y) | 计算x和y中的公共元素,并返回有序结果. |
| union1d(x, y) | 计算x和y的并集,并返回有序结果. |
| in1d(x, y) | 得到一个表示“x的元素是否包含于y”的布尔型数组. |
| setdiff1d(x, y) | 集合的差,即元素在x中且不再y中. |
import numpy as np arr1 = np.random.randint(1, 3, 10) arr1

去除重复元素
np.unique(arr1)
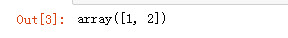
arr2 = np.arange(10) arr3 = np.arange(5, 15) arr2

arr3
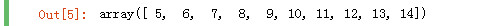
求两个一维数组的交集
np.intersect1d(arr2, arr3)

数组A中的元素是否在数组B中存在
np.in1d(arr2, arr3)

随机数生成函数
numpy.random模块对Python内置的random进行了补充。我们使用numpy.random可以很方便根据需要产生大量样本值。而python内置的random模块则一次生成一个样本值.
| 函数 | 说明 |
|---|---|
| permutation | 如果给的数字,则生成指定个数随机数 ,如果是数组,则打乱数组返回. |
| shuffle | 打乱一个序列的原有顺序. |
| randint | 从给定的上下限随机选取整数. |
import numpy as np arr1 = np.arange(10) arr1
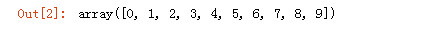
如果permutation参数是数组,那么打乱数组元素顺序
如果参数是数字,随机生成指定个数的随机数
打乱数组之后,返回打乱之后的元素序列副本
打乱数组的顺序
np.random.permutation(arr1)

生成指定个数的随机数
np.random.permutation(10)

打乱数组本身元素的顺序
对原有的数组进行了修改
np.random.shuffle(arr1) arr1

数组排序函数
import numpy as np arr1 = np.random.randint(1, 10, (5, 5)) arr1
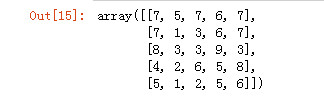
默认按行排序
arr1.sort() arr1
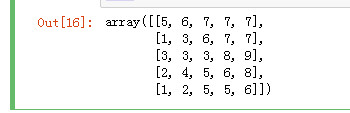
指定按列排序
arr1.sort(axis=0) arr1

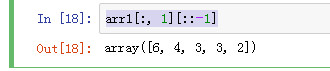
没有从大到小排序
但可以这样
arr1[:, 1][::-1]
argsort ()函数的使用,返回的是排序后的下标(不对原数组修改)
arr2 = np.random.randint(10, 100, 5) arr2

arr2.argsort()

arr2[arr2.argsort()]

arr2_index[arr2.argsort()]

argsort ()函数不对原数组进行修改,只对下标进行排序
arr2
还是原来创建的数据

数组文件输入输出
Numpy能够读写磁盘上的文本数据和二进制数据。后面的课程我们会学习pandas中用于表格型数据读取到内存的工具。
np.save和np.load是读写磁盘数组数据的两个主要函数。默认情况下,数组是以原始二进制格式保存在扩展名为.npy的文件中。如果在保存文件时没有指定扩展名.npy,则该扩展名会被自动加上。
通过np.savez可以将多个数组保存到同一个文件中,将数组以关键字参数的形式传入即可。
例如: np.savez(‘myarr.npz’, a=arr1, b=arr2) 加载文件的时候,我们会得到一个类似字典的对象。
将数组写入到文件中(np.save(文件名,保存的数组))
import numpy as np arr1 = np.arange(25).reshape((5, 5)) arr1

np.save('my_arr1', arr1)
从文件中读取数组(np.load('文件名'))
np.load('my_arr1.npy')

多个数组的读写
arr2 = np.arange(25, 50).reshape((5, 5)) arr2
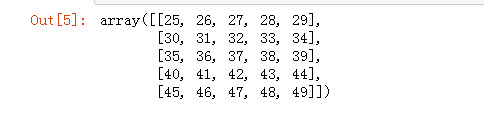
把多个数组写入文件中(np.savez('文件名', a=数组1, b=数组2))
np.savez('multi_files', a=arr1, b=arr2)
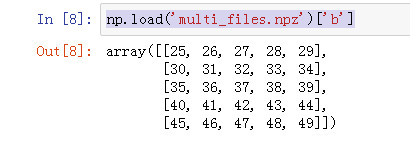
从文件中读取各个数组
np.load('multi_files.npz')['a']

np.load('multi_files.npz')['b']
读写文本文件
从文件中加载文本是一个非常标准的任务。Python中的文件读写函数的格式很容易将新手搞晕,所以我们使用np.loadtxt或者更加专门化的np.genfromtxt将数据加载到普通的Numpy数组中。 这些函数都有许多选项可供使用:指定各种分隔符、跳过行数等。我们以一个简单的逗号分割文件(csv)为例:
把数组存入文件中
np.savetxt('文件名', 数组, delimiter='分隔符', fmt='%s') %s是普通字符串
# 以逗号分割的格式为csv格式
np.savetxt('my_arr_data.txt', arr1, delimiter=',', fmt='%s')
把数组从文件中读取 -------》np.genfromtxt('文件名', delimiter=',', skip_header=1, skip_footer=1, dtype=np.str
np.genfromtxt('my_arr_data.txt', delimiter=',', skip_header=1, skip_footer=1, dtype=np.str)
以字符串类型读取,跳过首行和结尾的一行

np.genfromtxt('my_arr_data.txt', delimiter=',', skip_header=1, skip_footer=1)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号