awk 条件及循环语句和字符串函数
条件语句
if(条件表达式)
动作1
else if(条件表达式)
动作2
else
动作3
循环语句:
while循环:
while(条件表达式)
动作
do while循环:
do
动作
while(条件表达式)
for循环:
for(初始化计数器;计数器测试;计数器变更)
动作
以:为分隔符,只打印/etc/passwd中第3个字段的数值在50-100范围内的行信息
awk 'BEGIN{FS=":"}{if($3>50 && $3<100) print $0}' passwd

if.awk
BEGIN{
FS=":"
}
{
if($3<50)
{
printf "%-20s%-20s%-10d\n","UID<50",$1,$3
}
else if ($3>50 && $3<100)
{
printf "%-20s%-20s%-10d\n","50<UID<100",$1,$3
}
else
{
printf "%-20s%-20s%-10d\n","UID>100",$1,$3
}
}
输出 以 UID 以50位为分界点的用户,-f 将条件表达式写到文本中读取
awk -f if.awk passwd

计算下列每个同学的平均分数,并且只打印平均分数大于90的同学姓名和分数信息
Allen 80 90 96 98
Mike 93 98 92 91
Zhang 78 76 87 92
Jerry 86 89 68 92
Han 85 95 75 90
Li 78 88 98 100
算出平局成绩
awk 'BEGIN{printf "%-20s%-20s%-20s%-20s%-20s%-20s\n","Name","Chinese","English","Math","Physical","Average"}{sum=$2+$3+$4+$5;avg=sum/4}
{printf "%-20s%-20d%-20d%-20d%-20d%-0.2f\n",$1,$2,$3,$4,$5,avg}' student.txt

加入条件判断,如果平均分数大于90才打印
awk 'BEGIN{printf "%-20s%-20s%-20s%-20s%-20s%-20s\n","Name","Chinese","English","Math","Physical","Average"}{sum=$2+$3+$4+$5;avg=sum/4}{if(avg>90)
printf "%-20s%-20d%-20d%-20d%-20d%-0.2f\n",$1,$2,$3,$4,$5,avg}' student.txt

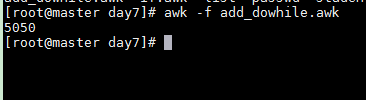
计算1+2+3+4+...+100的和,请使用while、do while、for三种循环方式实现
通过读取文件的方式载入awk的条件
add_while.awk
BEGIN{
while(i<=100)
{
# 一个变量不赋值,默认为0或者空
sum+=i
i++
}
print sum
}
do while循环
awk -f add_dowhile.awk
for循环
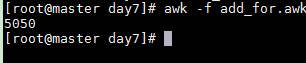
add_for.awk
BEGIN{
for(i=0;i<=100;i++)
{
sum+=i
}
print sum
}
字符串函数对照表


案例演示
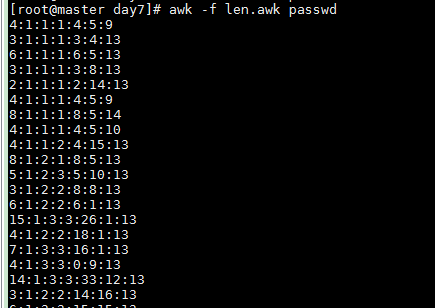
以 : 为分隔符, 返回/etc/passwd中每行中每个字段的长度
len.wak
BEGIN{
FS=":"
}
{
i=1
while(i<=NF)
{
if (i==NF)
{
printf "%d",length($i)
}
else
{
printf "%d:",length($i)
}
i++
}
print ""
}
awk -f len.awk passwd
搜索字符串"I have a dream"中出现"ea"字符串的位置
awk 'BEGIN{str="I have a gream";printf "%d\n",index(str,"ea")}'

将字符串"Hadoop is a bigdata Framework"全部转换为小写
awk 'BEGIN{str="Hadoop is a bigdata Framework";print tolower(str)}'

将字符串"Hadoop is a bigdata Framework"全部转换为大写
awk 'BEGIN{str="Hadoop is a bigdata Framework";print toupper(str)}'

将字符串"Hadoop Kafka Spark Storm HDFS YARN Zookeeper",按照空格为分隔符,分隔
awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr);for (i in arr) print arr[i];}'

搜索字符串"Transaction 2345 Start:Select * from master"第一个数字出现的位置
awk 'BEGIN{str="Transaction 2345 Start:Select * from master";print match(str,/[0-9]/)}'

截取字符串"transaction start"的子串,截取条件从第4个字符开始,截取5位
awk 'BEGIN{str="transaction start";print substr(str,4,5)}'

替换字符串"Transaction 243 Start,Event ID:9002"中第一个匹配到的数字串替换为$符号
awk 'BEGIN{str="Transaction 243 Start,Event ID:9002";count=sub(/[0-9]+/,"$",str);print count;print str}'

gsub是替换全部匹配到的数字 (通过 // 写正则表达式 )
awk 'BEGIN{str="Transaction 243 Start,Event ID:9002";count=gsub(/[0-9]+/,"$",str);print count;print str}'

在awk中数组下标从1开始
awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");print arr[0]}'

awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");for(i in arr) {print arr[i]}}'


 浙公网安备 33010602011771号
浙公网安备 33010602011771号