从excel中读取美国人口信息做一个简单的统计
假定你有一张电子表格的数据,来自于 2010 年美国人口普查。你有一个无聊的任 务,要遍历表中的几千行,计算总的人口,以及每个县的普查区的数目(普查区就是一 个地理区域,是为人口普查而定义的)。每行表示一个人口普查区。我们将这个电子表格 文件命名为 censuspopdata.xlsx,它的 内容下图 所示。 尽管 Excel 是要能够计算多个选中单元格的和,你仍然需要选中 3000 个以上县 的单元格。即使手工计算一个县的人口只需要几秒钟,整张电子表格也需要几个小 时时间。
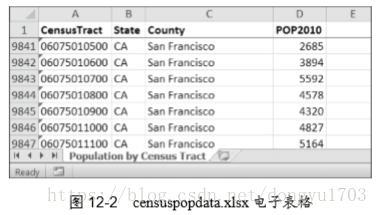
在这个项目中,你要编写一个脚本,从人口普查电子表格文件中读取数据,并 在几秒钟内计算出每个县的统计值。 下面是程序要做的事:
• 从 Excel 电子表格中读取数据。
• 计算每个县中普查区的数目。
• 计算每个县的总人口。
• 打印结果。
这意味着代码需要完成下列任务:
• 用 openpyxl 模块打开 Excel 文档并读取单元格。
• 计算所有普查区和人口数据,将它保存到一个数据结构中。
• 利用 pprint 模块可以把字典转换成字符串,将该数据结构写入一个扩展名为.py的文本文件。
import openpyxl, pprint
# Read the spreadsheet data
print('Opening workbook')
wb = openpyxl.load_workbook('censuspopdata.xlsx')
sheet = wb.active
countryData = {}
# Fill in countryData with each city's pop and tracts
for row in range(2, sheet.max_row+1):
# Each row in the spreasheet has data
state = sheet['B' + str(row)].value
country = sheet['C' + str(row)].value
pop = sheet['D' + str(row)].value
# make sure the key state exists
countryData.setdefault(state, {})
# make sure the key for country in state exists
countryData[state].setdefault(country,{'tracts':0, 'pop':0})
# Each row represents one census tract, so increment by one
countryData[state][country]['tracts'] += 1
# Increase the country pop by the pop in this census tract
countryData[state][country]['pop'] += int(pop)
# Open a new text file and write the contents fo countryData to it
print('Writing results...')
resultFile = open('census2010.py', 'w')
resultFile.write('allData = ' + pprint.pformat(countryData))
census2010.py中的内如如下所示

为什么使用pprint和生成一个以py结尾的文件呢,因为在另外一个文件中,我们可以直接使用
import census2010 print(census2010.allData["AK"])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号