9- scrapy-redis分布式开发
Scrapy_redis之RedisSpider
分析myspider_redis.py和我们以前的spider的区别,用绿色的标记渲染出来,而我们用的时候只需改变绿色的部分内容即可
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'myspider_redis'
redis_key = 'myspider:start_urls' #start_url在redis中所在的键
allow_domain = ["jd.com","p.3.cn"]
# 下面注释的部分是可以不要的
# def __init__(self, *args, **kwargs):
# # Dynamically define the allowed domains list.
# domain = kwargs.pop('domain', '')
# self.allowed_domains = filter(None, domain.split(','))
# super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
# 下面的注释也是可以不要的
# return {
# 'name': response.css('title::text').extract_first(),
# 'url': response.url,
# }
pass

下面通过RedisSpider抓取当当图书的信息
需求:抓取当当图书的信息
目标:抓取当当图书又有图书的名字、封面图片地址、图书url地址、作者、出版社、出版时间、价格、图书所属大分类、图书所属小的分类、分类的url地址
url:http://book.dangdang.com/
创建项目和爬虫
scrapy startproject book cd book scrapy genspider dangdang dangdang.com
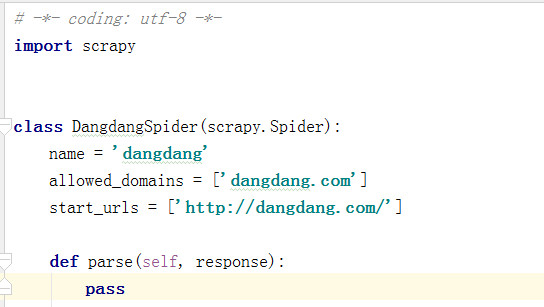
dangdang.py中的原文件创建的代码:
在settings.py中配置分布式爬虫,添加以下的代码
#srapy_redis的配置
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
REDIS_URL = "redis://127.0.0.1:6379"
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
#如果要把提取的数据存在redis中,可以把下面的注释打开
# 'scrapy_redis.pipelines.RedisPipeline': 400,
}
我们只需对它稍微的做一些修改,即可实现redisspider的分布式爬虫
修改的东西: 导入的模块,继承 ,start__urls改成键的形式,通过在redis中 动态的添加 lpush dangdang http://book.dangdang.com/
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
class DangdangSpider(RedisSpider):
name = 'dangdang'
allowed_domains = ['dangdang.com']
# start_urls = ['http://book.dangdang.com/']
redis_key = "dangdang"
def parse(self, response):
pass
完整的代码:


# -*- coding: utf-8 -*- import scrapy from copy import deepcopy from scrapy_redis.spiders import RedisSpider class DangdangSpider(RedisSpider): name = 'dangdang' allowed_domains = ['dangdang.com'] # start_urls = ['http://book.dangdang.com/'] redis_key = "dangdang" def parse(self, response): div_list = response.xpath("//div[@class='con flq_body']/div") for div in div_list: #大 item = {} item["b_cate"] = div.xpath("./dl//a/text()").extract() dl_list = div.xpath("./div//dl[@class='inner_dl']") for dl in dl_list: #中 item["m_cate"] = dl.xpath("./dt/a/text()").extract_first() a_list = dl.xpath("./dd/a") for a in a_list: #小 item["s_cate"] = a.xpath("./@title").extract_first() item["s_href"] = a.xpath("./@href").extract_first() if item["s_href"] is not None: yield scrapy.Request( #发送图书列表页的请求 item["s_href"], callback=self.parse_book_list, meta = {"item":deepcopy(item)} ) def parse_book_list(self,response): item = deepcopy(response.meta["item"]) li_list = response.xpath("//ul[@class='bigimg']/li") for li in li_list: item["book_img"] = li.xpath("./a/img/@data-original").extract_first() if item["book_img"] is None: item["book_img"] = li.xpath("./a/img/@src").extract_first() item["book_href"] = li.xpath("./a/@href").extract_first() item["book_name"] = li.xpath("./p[@class='name']/a/@title").extract_first() item["book_detail"] = li.xpath("./p[@class='detail']/text()").extract_first() item["book_price"] = li.xpath(".//span[@class='search_now_price']/text()").extract_first() item["book_author"] = li.xpath("./p[@class='search_book_author']/span[1]/a/text()").extract() item["book_publish_date"] = li.xpath("./p[@class='search_book_author']/span[2]/text()").extract_first() item["book_press"] = li.xpath("./p[@class='search_book_author']/span[3]/a/text()").extract_first() print(item) yield item #获取下一页: next_url_temp = response.xpath("//li[@class='next']/a/@href").extract_first() if next_url_temp is not None: next_url = "http://category.dangdang.com/" + next_url_temp yield scrapy.Request( next_url, callback=self.parse_book_list, meta = {"item":response.meta["item"]} )
运行爬虫,可以在多个终端上执行, 这个时候它会,等待redis中的start_urls,程序会卡主,
scrapy crawl dangdang
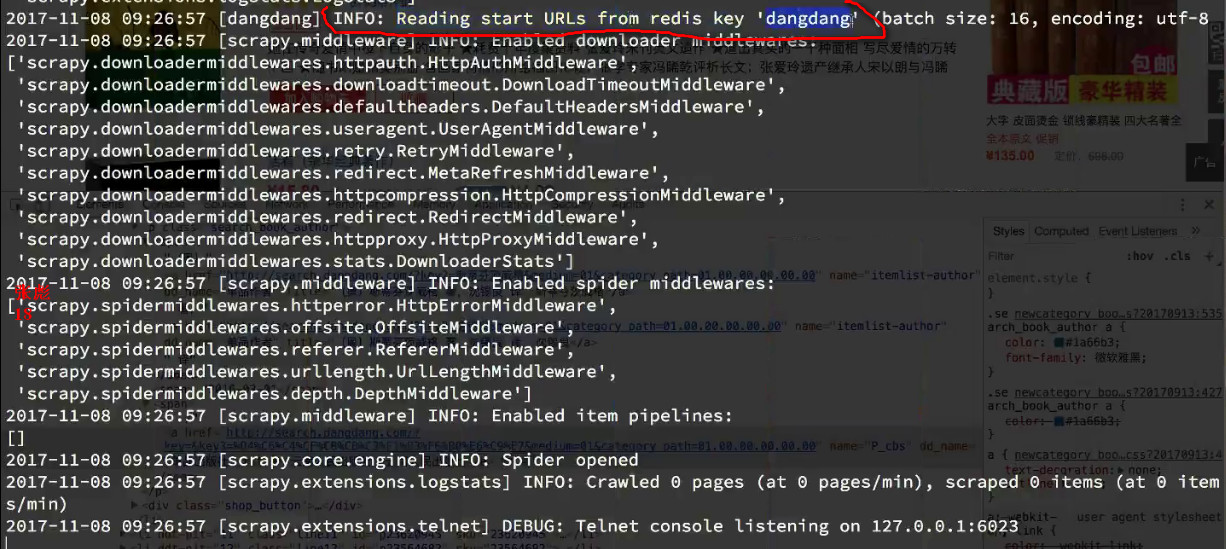
在redis中添加start_url后,程序就会抓取想要的数据
lpush dangdang http://book.dangdang.com/

当在redis中添加start_urls后,多个终端会立即执行程序,实现分布式爬虫的效果

Scrapy_redis之RedisCrawlSpider
分析源码mycrawler_redis.py和我们以前的crawlSpider的区别,用绿色的标记渲染出来,而我们用的时候只需改变绿色的部分内容即可
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisCrawlSpider
class MyCrawler(RedisCrawlSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'mycrawler_redis'
redis_key = 'mycrawler:start_urls'
allow_domain = ["",""]
rules = (
# follow all links
Rule(LinkExtractor(), callback='parse_page', follow=True),
)
# def __init__(self, *args, **kwargs):
# # Dynamically define the allowed domains list.
# domain = kwargs.pop('domain', '')
# self.allowed_domains = filter(None, domain.split(','))
# super(MyCrawler, self).__init__(*args, **kwargs)
def parse_page(self, response):
# return {
# 'name': response.css('title::text').extract_first(),
# 'url': response.url,
# }
pass

下面通过RedisCrawlSpider抓取当当图书的信息
需求:抓取亚马逊图书的信息
目标:抓取亚马逊图书又有图书的名字、封面图片地址、图书url地址、作者、出版社、出版时间、价格、图书所属大分类、图书所属小的分类、分类的url地址
url:https://www.amazon.cn/%E5%9B%BE%E4%B9%A6/b/ref=sd_allcat_books_l1?ie=UTF8&node=658390051
在上面的book项目中创建爬虫
scrapy genspider -t crawl amazon amazon.com
amazon.py中的原文件创建的代码:
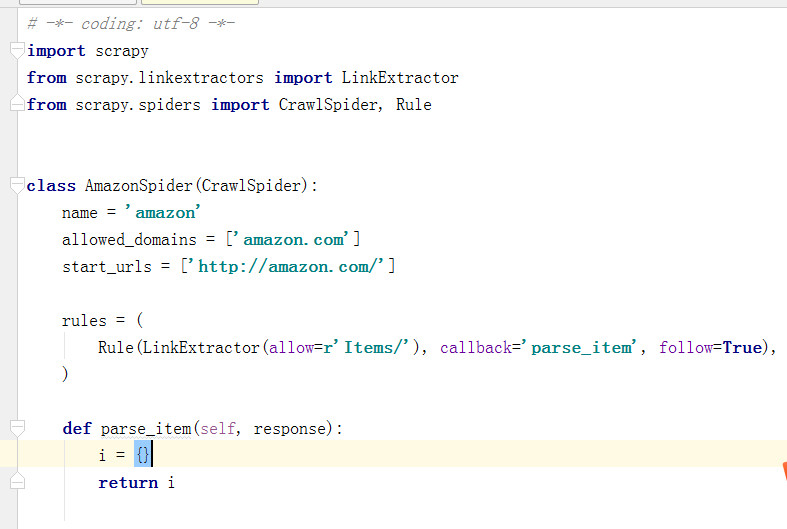
我们只需对它稍微的做一些修改,即可实现RedisCrwalSpider的分布式爬虫
修改的东西: 导入的模块,继承 ,start__urls改成键的形式,通过在redis中 动态的添加 lpush dangdang url地址
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider class AmazonSpider(RedisCrawlSpider): name = 'amazon' allowed_domains = ['amazon.com'] # start_urls = ['http://amazon.com/'] redis_key = "amazon" rules = ( Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True), ) def parse_item(self, response): i = {} return i
完整的代码:
# -*- coding: utf-8 -*- import scrapy from scrapy.spiders import Rule from scrapy.linkextractors import LinkExtractor from scrapy_redis.spiders import RedisCrawlSpider class AmazonSpider(RedisCrawlSpider): name = 'amazon' allowed_domains = ['amazon.cn'] redis_key = "amazon" # start_urls = ['http://amazon.com/'] rules = ( #从大分类到小分类,从小分类到列表页 Rule(LinkExtractor(restrict_xpaths=["//div[@class='categoryRefinementsSection']/ul/li"]),follow=True), #从列表页到详情页 Rule(LinkExtractor(restrict_xpaths=["//div[@id='mainResults']//h2/.."]),callback="parse_book_detail") ) def parse_book_detail(self, response): item = {} is_ebook_temp = response.xpath("//title/text()").extract_first() item["is_ebook"] = True if "Kindle电子书" in is_ebook_temp else False item["book_title"] = response.xpath("//span[contains(@id,'productTitle')]/text()").extract_first() item["book_publish_date"] = response.xpath("//h1[@id='title']/span[3]/text()").extract_first() item["book_author"]= response.xpath("//div[@id='byline']/span/a/text()").extract() item["book_price"] = response.xpath("//div[@id='soldByThirdParty']/span/text()").extract() if item["is_ebook"]: item["book_price"] = response.xpath("//tr[@class='kindle-price']/td/text()").extract() # item['book_img'] = response.xpath("//div[contains(@id,'img-canvas')]/img/@src").extract() item["book_press"] = response.xpath("//b[text()='出版社:']/../text()").extract_first() item["book_cate_info"] = response.xpath("//ul[@class='zg_hrsr']/li[1]/span[2]//a/text()").extract() # print(item) yield item
运行爬虫可以在多个终端上执行, 这个时候它会,等待redis中的start_urls,程序会卡主,
scrapy crawl zmazon
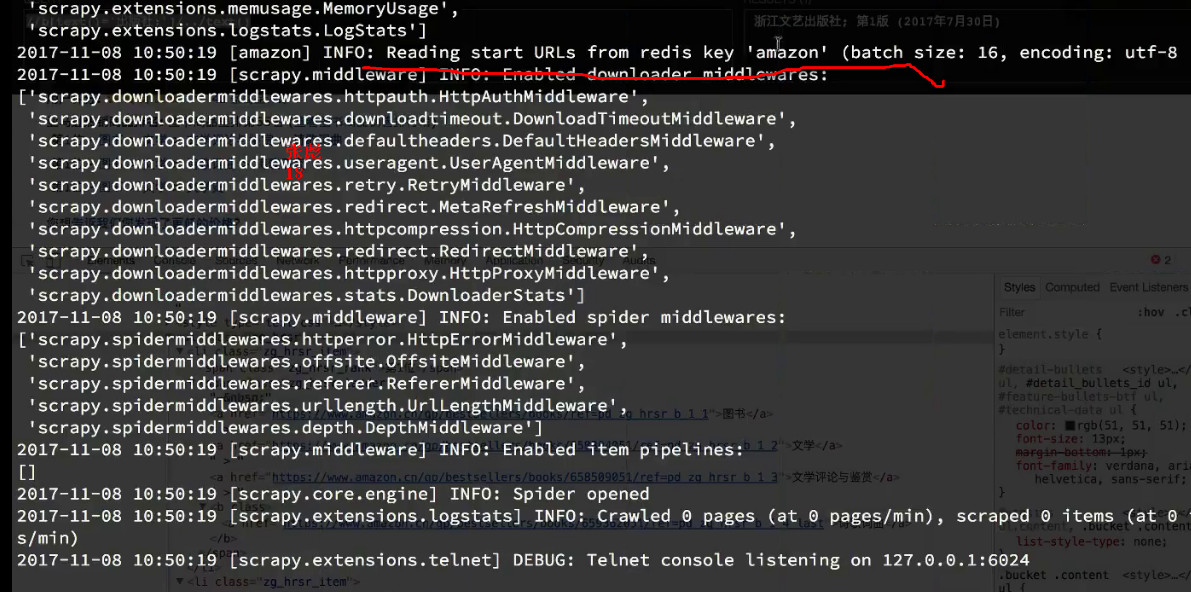
在redis中添加start_url后,程序就会抓取想要的数据,添加的是一个列表页的地址
lpush amazon https://www.amazon.cn/s/ref=lp_658390051_nr_n_4/462-2558471-4466339?fst=as%3Aoff&rh=n%3A658390051%2Cn%3A%21658391051%2Cn%3A658395051&bbn=658391051&ie=UTF8&qid=1510133121&rnid=658391051
当在redis中添加start_urls后,多个终端会立即执行程序,实现分布式爬虫的效果

crawlSpider中的restrict_xpaths的使用
restrict_xpath通过里面的xpath精确的定位到那个元素的下面,然后就会取出里面的所有的url链接进行过滤
rules = (
#从大分类到小分类,从小分类到列表页
Rule(LinkExtractor(restrict_xpaths=["//div[@class='categoryRefinementsSection']/ul/li"]),follow=True),
#从列表页到详情页
Rule(LinkExtractor(restrict_xpaths=["//div[@id='mainResults']//h2/.."]),callback="parse_book_detail")
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号