7 中间键和模拟登陆
Spider和CrawlSpiders的混用
rules = (
#博客专家地址
Rule(LinkExtractor(allow=r'blog.csdn.net/\w+$') ,follow=True),
#博客专家地址 翻页
Rule(LinkExtractor(allow=r'channelid=\d+&page=\d+$'), follow=True),
#博客列表页 翻页,这里有想要提取的数据,提取这里的数据使用 CrawlS
Rule(LinkExtractor(allow=r'/\w+/article/list/\d+$'), follow=True,callback='temp'),
)
# scrawlSpider提取博客列表页的数据
def temp(self,response):
item = {}
......
......
......
# 然后使用spider提取每个博客的详情页的数据
yield scrapy(
url,
callback = self.parse_detail,
meta = {'item':item}
)
# spider提取详情页的数据
def parse_detail(self,response):
pass
设置下载中间件(Downloader Middlewares)
下载中间件是处于引擎(crawler.engine)和下载器(crawler.engine.download())之间的一层组件,可以有多个下载中间件被加载运行。
-
当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等);
-
在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)
通过添加中间键实现随机添加User_Agents
在sering中添加一个列表,里面包含了不同的User-Agents
USER_AGENTS = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ]
在middlewares.py中自定义一个在请求的时候实现随机获取User-Agent的中间键的类
import random
class RandomUA(object):
def process_request(self,request,spider):
UA = spider.settings.get("USER_AGENTS")
request.headers["User-Agent"] = random.choice(UA)
在settings中把随机中间键的注释打开,(设置优先级,这个是可选的)
DOWNLOADER_MIDDLEWARES = {
'book.middlewares.RandomUA': 10,
}
在每次发送请求的时候打印请求中的User_Agent
print(response.request.headers["User-Agent"])
scrapy模拟登陆
那么对于scrapy来说,也是有两个方法模拟登陆:
1、直接携带cookie
2、找到发送post请求的url地址,带上信息,发送请求
scrapy模拟登陆之携带cookie
应用场景:
1、cookie过期时间很长,常见于一些不规范的网站
2、能在cookie过期之前把搜有的数据拿到
3、配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
模拟登陆人人网
scrapy startproject login cd login scrapy genspider renren renren.com
重写start_request方法,手动发送start_Url地址中url的请求
如果想要携带cookies进行登录的话,必须参加字典形式的cookies到请求中,cookie放在headers中是无效的
在创建的爬虫renren.py中
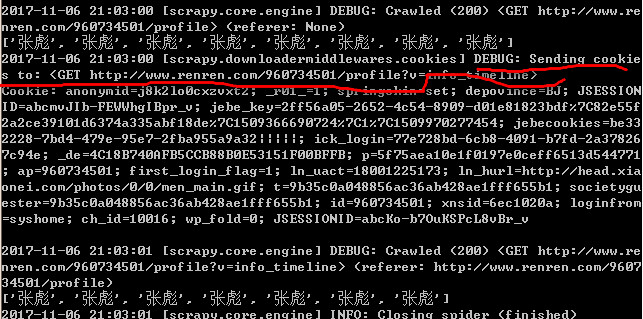
class RenrenSpider(scrapy.Spider): name = 'renren' allowed_domains = ['renren.com'] start_urls = ['http://www.renren.com/960734501/profile'] # 重写start_request方法,手动发送start_Url地址中url的请求 def start_requests(self): cookies = "anonymid=j8k2lo0cxzvxt2; _r01_=1; springskin=set; depovince=BJ; JSESSIONID=abcmvJIb-FEWWhgIBpr_v; jebe_key=2ff56a05-2652-4c54-8909-d01e81823bdf%7C82e55f2a2ce39101d6374a335abf18de%7C1509366690724%7C1%7C1509970277454; jebecookies=be332228-7bd4-479e-95e7-2fba955a9a32|||||; ick_login=77e728bd-6cb8-4091-b7fd-2a378267c94e; _de=4C18B740AFB5CCB88B0E53151F00BFFB; p=5f75aea10e1f0197e0ceff6513d544771; ap=960734501; first_login_flag=1; ln_uact=18001225173; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; t=9b35c0a048856ac36ab428ae1fff655b1; societyguester=9b35c0a048856ac36ab428ae1fff655b1; id=960734501; xnsid=6ec1020a; loginfrom=syshome; ch_id=10016; wp_fold=0" cookies_dict = {i.split("=")[0]:i.split("=")[-1] for i in cookies.split("; ")} for url in self.start_urls: yield scrapy.Request( url, callback=self.parse, cookies=cookies_dict #如果想要携带cookies进行登录的话,必须参加字典形式的cookies到请求中 ) def parse(self, response): print(re.findall("张彪",response.body.decode()))
执行爬虫的程序
scrapy crawl renren

第二次访问个人资料不需要在携带kookie,
# -*- coding: utf-8 -*- import scrapy import re class RenrenSpider(scrapy.Spider): name = 'renren' allowed_domains = ['renren.com'] start_urls = ['http://www.renren.com/960734501/profile'] # 重写start_request方法,手动发送start_Url地址中url的请求 def start_requests(self): cookies = "anonymid=j8k2lo0cxzvxt2; _r01_=1; springskin=set; depovince=BJ; JSESSIONID=abcmvJIb-FEWWhgIBpr_v; jebe_key=2ff56a05-2652-4c54-8909-d01e81823bdf%7C82e55f2a2ce39101d6374a335abf18de%7C1509366690724%7C1%7C1509970277454; jebecookies=be332228-7bd4-479e-95e7-2fba955a9a32|||||; ick_login=77e728bd-6cb8-4091-b7fd-2a378267c94e; _de=4C18B740AFB5CCB88B0E53151F00BFFB; p=5f75aea10e1f0197e0ceff6513d544771; ap=960734501; first_login_flag=1; ln_uact=18001225173; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; t=9b35c0a048856ac36ab428ae1fff655b1; societyguester=9b35c0a048856ac36ab428ae1fff655b1; id=960734501; xnsid=6ec1020a; loginfrom=syshome; ch_id=10016; wp_fold=0" cookies_dict = {i.split("=")[0]:i.split("=")[-1] for i in cookies.split("; ")} for url in self.start_urls: yield scrapy.Request( url, callback=self.parse, cookies=cookies_dict #如果想要携带cookies进行登录的话,必须参加字典形式的cookies到请求中 ) def parse(self, response): print(re.findall("张彪",response.body.decode())) yield scrapy.Request( 'http://www.renren.com/960734501/profile?v=info_timeline', callback=self.parse2 ) # 第二次访问个人资料不需要在携带kookie def parse2(self, response): print(re.findall("张彪", response.body.decode()))

可以在setting中设置cookies-debug看cookie的传递
COOKIES_DEBUG = True
scrapy模拟登陆之发送post请求
模拟登陆github
使用scrapy.Request的时候一直是发送的get请求,那么post请求就是需要使用scrapy.Formdata来携带需要的post的数据
格式: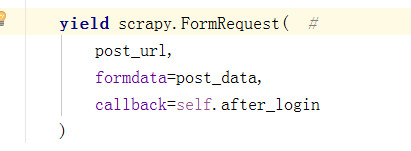
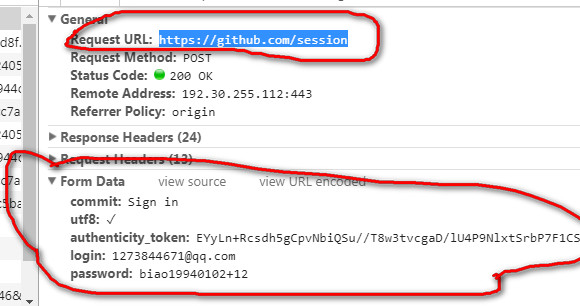
在github上输入错误的密码可以拿到以下信息,请求的地址和表单需要的数据
创建一个爬虫
scrapy genspider github github.com
在进行post提交的时候需要构造以下的数据,这些数据在登陆的页面中通过xpath可以获取 https://github.com/login

在github.py中发送post请求
# -*- coding: utf-8 -*- import scrapy import re class GithubSpider(scrapy.Spider): name = 'github' allowed_domains = ['github.com'] start_urls = ['https://github.com/login'] def parse(self, response): authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first() commit = response.xpath("//input[@name='commit']/@value").extract_first() utf8 = response.xpath("//input[@name='utf8']/@value").extract_first() post_url = "https://github.com/session" post_data = {"commit": commit, "utf8": utf8, "authenticity_token": authenticity_token, "login": "''''''", "password": "......"} # 通过post登陆 yield scrapy.FormRequest( post_url, formdata=post_data, callback=self.after_login ) def after_login(self, response): print(re.findall(r"(zb)", response.body.decode(), re.I))
运行爬虫
scrapy crawl github

scrapy模拟登陆之自动登录
scrapy.FormRequest.form_response可以帮助我们从response中自动的寻找表单进行登陆,如果响应里面有多个表单,可以多给一些限定的参数,如表达你的ID等等,具体的见源码
书写的格式
只需要输入表单中的用户名和密码就可以
yield scrapy.FormRequest.from_response( response, formdata={"login": "用户名", "password": "密码"}, callback=self.after_login )
创建一个爬虫
scrapy genspider github2 github.com
在github.py中发送post请求
# -*- coding: utf-8 -*- import scrapy import re class Github2Spider(scrapy.Spider): name = 'github2' allowed_domains = ['github.com'] start_urls = ['http://github.com/login'] def parse(self, response): yield scrapy.FormRequest.from_response( response, formdata={ "login": "'''''''''''''", "password": "'''''''"}, callback = self.after_login ) def after_login(self,response): print(re.findall('zb147',response.body.decode()),re.I)
运行爬虫
scrapy crawl github2


 浙公网安备 33010602011771号
浙公网安备 33010602011771号