5-scrapy框架入门
爬取斗鱼所有的房间信息:
爬取斗鱼直播的内容包括: 房间的分类,房间的名字,房间的链接地址,房主的名字.,观看的人数
主要的逻辑:
构造初始话的数据
def __init__(self): self.url = 'https://www.douyu.com/directory/all' self.driver=webdriver.Chrome()
1 发送请求获取响应
self.driver.get(self.url)
2 提取数据,获取下一页的a标签
1 获取每个房间的分组信息
2 遍历每个房间,获取想要的数据,存入字典,把每个房间的数据存入字典中
3 判断有没有下一页的链接,有则返回,没有则返回None
4 返回所有保存的数据和下一页的链接
3 保存数据
4 判断有没有下一页,如果有下一页,则重复上面的步奏
5 退出


import requests from selenium import webdriver import time class douyu(object): # 构造初始化数据 def __init__(self): self.url = 'https://www.douyu.com/directory/all' self.driver=webdriver.Chrome() # 提取数据,返回下一页的a标签 def get_content_list(self): # 获取每页的分组信息 list_li=self.driver.find_elements_by_xpath('//ul[@id="live-list-contentbox"]/li') content_list=[] # 所有的信息保存在这个列表中 # 遍历分组的信息获取,每个分组要提取的数据 for li in list_li: # 把每个信息保存在字典中 item = {} # 获取直播的分类 item['category']= li.find_element_by_xpath('//div[@class="mes-tit"]/span').text # 获取房间的名字 item['room_name']= li.find_element_by_xpath('.//h3').text # 获取房间的链接地址 item['room_href']= li.find_element_by_xpath('.//a').get_attribute('href') # 获取作者的名字 item['auth_name'] = li.find_element_by_xpath('.//div[@class="mes"]/p/span[1]').text item['watch_num'] = li.find_element_by_xpath('.//div[@class="mes"]/p/span[2]').text print(item) content_list.append(item) # 获取下一页的链接 next_url = self.driver.find_elements_by_xpath('//a[@class="shark-pager-next"]') next_url= next_url[0] if len(next_url)>0 else None return content_list,next_url def save(self,content_list): pass def del_chrome(self): self.driver.quit() def run(self): # 发送响应获取响应 self.driver.get(self.url) # 提取数据,获取下一页的a标签 content_list,next_url=self.get_content_list() # 保存数据 self.save(content_list) # 如果有下一页,则重复上面的步奏,没有则退出 while next_url is not None: # 发送下一页的请求 next_url.click() time.sleep(5) # 提取数据 content_list,next_url=self.get_content_list() # 保存数据 self.save(content_list) self.del_chrome() if __name__=="__main__": dou = douyu() dou.run()
利用selennium控制浏览器模拟豆瓣登陆
from selenium import webdriver
import time
driver= webdriver.Chrome()
driver.get("https://www.douban.com")
driver.find_element_by_id("form_email").send_keys('18001225173')
driver.find_element_by_id("form_password").send_keys('zhangbiao')
# 延时主要是有可能要输入验证码
time.sleep(20)
driver.find_element_by_class_name("bn-submit").click()
time.sleep(10)
driver.quit()
简单的设置log日志
创建一个base_logger.py的文件
import logging ''' asctime: 时间(2017-11-03 23:43:43,146) filename: 当前文件的名字(base_logger.py) lineno :日志所在的行 levelname:等级 message:日志的内容 ''' logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') logger = logging.getLogger(__name__) if __name__ == '__main__': logger.info("这是douban.py")

创建一个.py的文件引用上面的日志模块
from base_logger import logger if __name__ == '__main__': logger.warning("这是03——try_logging。py")

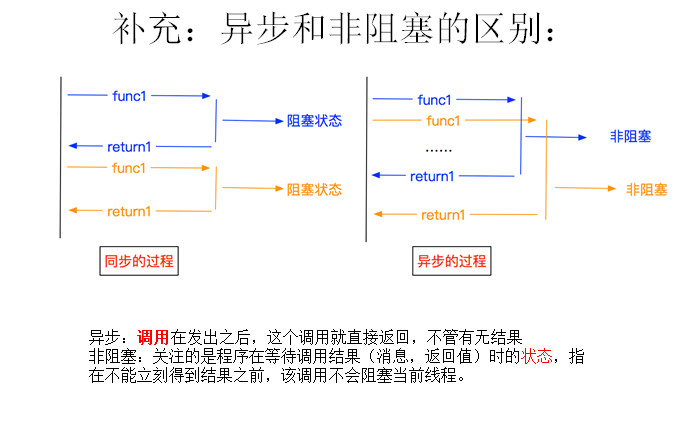
Scrapy 框架
-
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
-
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
-
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图(绿线是数据流向):

-
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 -
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 -
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理, -
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器), -
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方. -
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。 -
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
-
引擎:Hi!Spider, 你要处理哪一个网站? -
Spider:老大要我处理xxxx.com。 -
引擎:你把第一个需要处理的URL给我吧。 -
Spider:给你,第一个URL是xxxxxxx.com。 -
引擎:Hi!调度器,我这有request请求你帮我排序入队一下。 -
调度器:好的,正在处理你等一下。 -
引擎:Hi!调度器,把你处理好的request请求给我。 -
调度器:给你,这是我处理好的request -
引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求 -
下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载) -
引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的) -
Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。 -
引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。 -
管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
一. 新建项目
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject 项目的名字
scrapy startproject mySpider
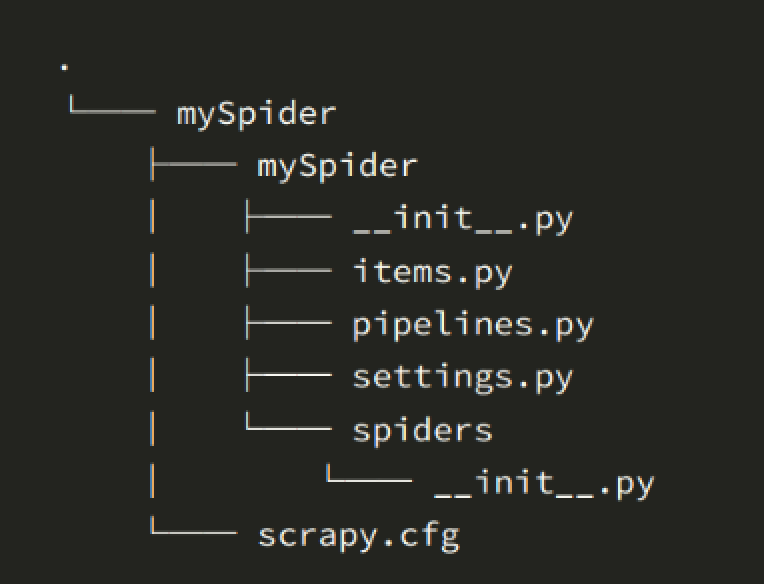
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
我们打算抓取:http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息。
在当前目录下输入命令,将在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
cd mySpider scrapy genspider itcast "itcast.cn"

- 打开 mySpider/spider目录里的 itcast.py,默认增加了下列代码:
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://itcast.cn/']
def parse(self, response):
pass
其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
-
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。 -
allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。 -
start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。 -
parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下: -
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
-
生成需要下一页的URL请求。
在itcast.py中将start_urls的值修改为需要爬取的第一个url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改parse()方法
def parse(self, response):
temp_list = response.xpath('//div[@class="tea_con"]//h3/text()')
print(temp_list)
然后运行一下看看,在mySpider目录下执行:
scrapy crawl itcast
是的,就是 itcast,看上面代码,它是 ItcastSpider 类的 name 属性,也就是使用 scrapy genspider命令的爬虫名。
一个Scrapy爬虫项目里,可以存在多个爬虫。各个爬虫在执行时,就是按照 name 属性来区分。
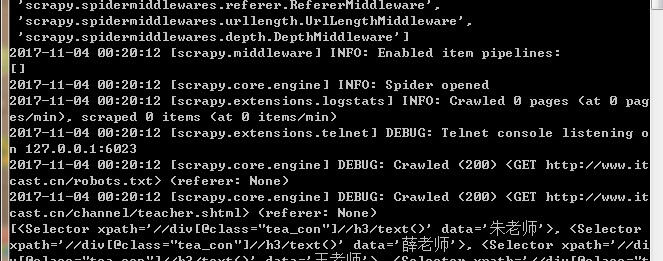
出现好多的日志信息,这是我们不想要的,在setting文件中设置日志的等级,不重要的日志就不显示了
LOG_LEVEL="WARNING"
然后运行一下看看
scrapy crawl itcast
返回一个对象的列表:
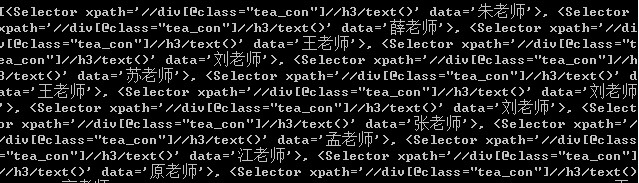
通过extract()方法,只提取我们想要的数据,老师的姓名
修改parse()方法
def parse(self, response):
temp_list = response.xpath('//div[@class="tea_con"]//h3/text()').extract()
print(temp_list)
运行爬虫
scrapy crawl itcast
返回一个列表只包含我们通过xpath获取的老师姓名
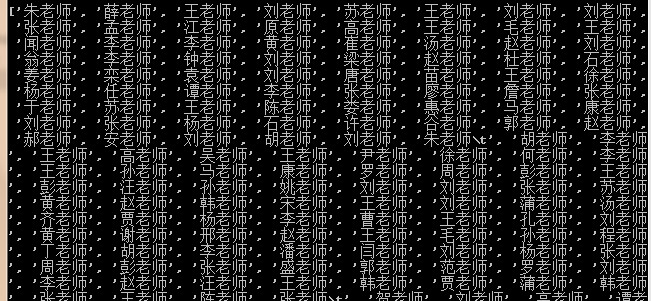
爬取当前页所有老师的信息
修改parse()方法
def parse(self, response):
# temp_list = response.xpath('//div[@class="tea_con"]//h3/text()').extract()
# print(temp_list)
li_list = response.xpath("//div[@class='tea_con']/div/ul/li")
for li in li_list:
item = {}
#value值是一个列表
item["name"] = li.xpath('.//h3/text()')
item["title"] = li.xpath(".//h4/text()")
item["profile"] = li.xpath(".//p/text()")
print(item)
运行爬虫
scrapy crawl itcast
注意: 这里的value值是一个列表

我们有时候想获取的值是字符串,便于操作,可以调用extract_first()方法把value值转成字符串,并只取第一个,如果第一个为空,则自动设置为None
修改parse()方法
def parse(self, response):
# temp_list = response.xpath('//div[@class="tea_con"]//h3/text()').extract()
# print(temp_list)
li_list = response.xpath("//div[@class='tea_con']/div/ul/li")
for li in li_list:
item = {}
# value值是一个列表
item["name"] = li.xpath('.//h3/text()').extract_first()
item["title"] = li.xpath(".//h4/text()").extract_first()
item["profile"] = li.xpath(".//p/text()").extract_first()
print(item)
运行爬虫
scrapy crawl itcast
value值变成了字符串

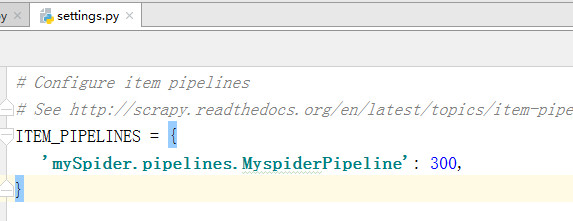
通过yield把响应数据传给管道,在setting中把ITEM_PIPELINES的注释打开
修改parse()方法
def parse(self, response):
# temp_list = response.xpath('//div[@class="tea_con"]//h3/text()').extract()
# print(temp_list)
li_list = response.xpath("//div[@class='tea_con']/div/ul/li")
for li in li_list:
item = {}
# value值是一个列表
item["name"] = li.xpath('.//h3/text()').extract_first()
item["title"] = li.xpath(".//h4/text()").extract_first()
item["profile"] = li.xpath(".//p/text()").extract_first()
# print(item)
yield item
在pipelines.py中打印接受的响应
class MyspiderPipeline(object):
def process_item(self, item, spider):
print(item)
return item
运行爬虫
scrapy crawl itcast
因为有时候会爬不同的网站对网站的处理方式也是不一样的,这时候可以设置分别对应的管道,处理对应的网站数据
管道权重越高的越最后处理数据如下一个管道的权重是200,另一个是300,这时候200执行完会把数据传给300再次处理
在pipelines.py中在定义一个管道
class ItcastPipeline(object):
def process_item(self, item, spider):
# print(item)
item['hello']= 'world'
return item
#新增的管道ItcastPipeline2
class ItcastPipeline2(object):
def process_item(self, item, spider):
print(item)
return item
在setting中配置新增的管道ItcastPipeline2响应的权重
ITEM_PIPELINES = {
'itcast.pipelines.ItcastPipeline': 300,
'itcast.pipelines.ItcastPipeline2': 600,
}
运行爬虫
scrapy crawl itcast
管道200的权重先执行,把每个字典增加['hello']= 'world'的键值对后,在交给权重为600的管道输出

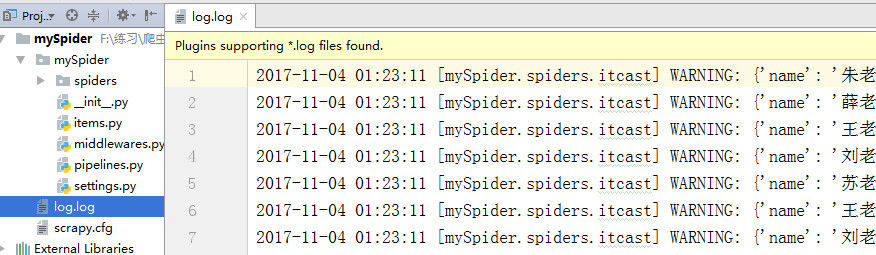
把log日志的信息保存到本地存储
在setting中配置
LOG_FILE='./log.log'
在parse()方法增加以下的内容
import logging logger = logging.getLogger(__name__) #要保存的数据写入log文件中 logger.warning(item)
完整程序
# -*- coding: utf-8 -*- import scrapy import logging logger = logging.getLogger(__name__) class ItcastSpider(scrapy.Spider): name = 'itcast' allowed_domains = ['itcast.cn'] start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] def parse(self, response): # temp_list = response.xpath('//div[@class="tea_con"]//h3/text()').extract() # print(temp_list) li_list = response.xpath("//div[@class='tea_con']/div/ul/li") for li in li_list: item = {} item["name"] = li.xpath('.//h3/text()').extract_first() item["title"] = li.xpath(".//h4/text()").extract_first() item["profile"] = li.xpath(".//p/text()").extract_first() # print(item) # yield item logger.warning(item)
运行爬虫
LOG_FILE='./log.log'
项目目录下会生成一个log.log的文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号