3- 非结构化数据与结构化数据提取
正则表达式匹配规则
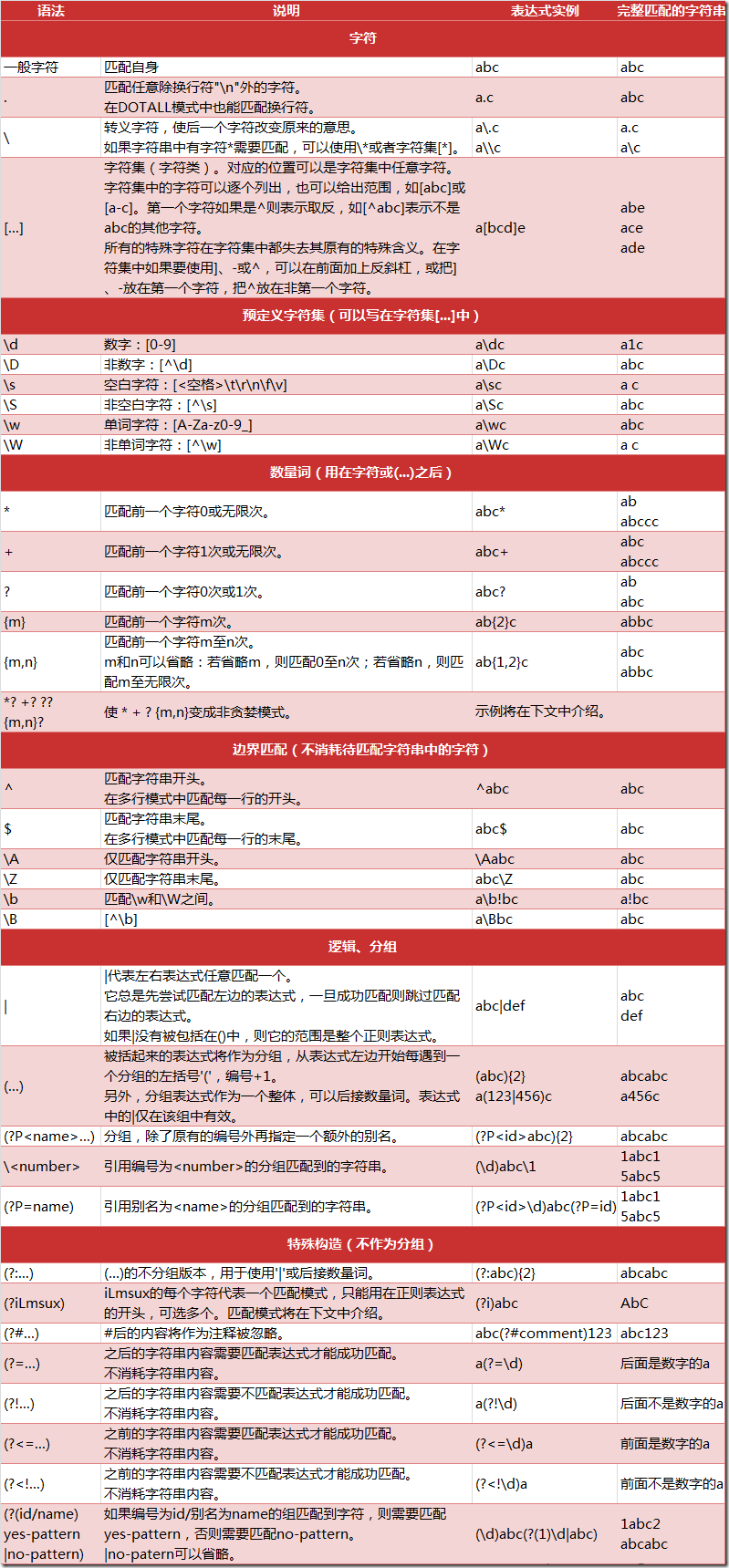
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
r'chuanzhiboke\t\.\tpython'
re 模块的一般使用步骤如下:
-
使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象 -
通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。 -
最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
import re # 将正则表达式编译成 Pattern 对象 pattern = re.compile(r'\d+')
match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
match(string[, pos[, endpos]])
>>> import re >>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字 >>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配 >>> print (m) None >>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配 >>> print (m) None >>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配 >>> print (m) # 返回一个 Match 对象 <_sre.SRE_Match object at 0x10a42aac0> >>> m.group(0) # 可省略 0 '12'
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
import re >>> pattern = re.compile('\d+') >>> m = pattern.search('one12twothree34four') # 这里如果使用 match 方法则不匹配 >>> m <_sre.SRE_Match object at 0x10cc03ac0> >>> m.group() '12' >>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间 >>> m <_sre.SRE_Match object at 0x10cc03b28> >>> m.group() '34'
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
import re pattern = re.compile(r'\d+') # 查找数字 result1 = pattern.findall('hello 123456 789') result2 = pattern.findall('one1two2three3four4', 0, 10) print (result1) print (result2)
执行结果:
['123456', '789'] ['1', '2']
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r'[\s\,\;]+')
print (p.split('a,b;; c d'))
执行结果:
['a', 'b', 'c', 'd']
sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
-
如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
-
如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
-
count 用于指定最多替换次数,不指定时全部替换。
import re p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9] s = 'hello 123, hello 456' print (p.sub(r'hello world', s)) # 使用 'hello world' 替换 'hello 123' 和 'hello 456' print (p.sub(r'\2 \1', s)) # 引用分组
执行结果:
hello world, hello world 123 hello, 456 hello
匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = u'你好,hello,世界' 中的中文提取出来,可以这么做:
import re title = '你好,hello,世界' pattern = re.compile(r'[\u4e00-\u9fa5]+') result = pattern.findall(title) print (result)
注意到,我们在正则表达式前面加上了两个前缀 ur,其中 r 表示使用原始字符串,u 表示是 unicode 字符串。
执行结果:
['你好', '世界']
注意:贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
主要通过正则匹配里面P标签的内容爬取内涵段子吧的笑话
<h1 class="title"> <p>晴交了个男朋友,极为帅气。在父母旅游回来后,带他回了家。不料二老一见,竟十分反对。
在男友走后,母亲苦口婆心地告诉晴:“那个男人肯定靠不住!分手吧!”晴反驳:“你怎么知道!”遂和母亲赌气离家出走同居。母亲哭道:他爸,要不然告诉她实话吧!父亲吃了根蜡烛:只能这样了! </p> </h1>
这里需要注意一个是re.S是正则表达式中匹配的一个参数,,默认是不能匹配换行的,加上re.S上之后就可以了
import re
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"}
r = requests.get("http://neihanshequ.com/",headers=headers)
result=r.content.decode()
data = re.findall(r'<h1 class="title">.*?<p>(.*?)</p>.*?</h1>',result,re.S)
print(data)
with open('xiaohua','a',encoding='utf-8') as f:
for i in data:
f.write(i)
f.write('\n')
爬取豆瓣美剧和国产剧
json返回的数据如下:
我们只需要
"subject_collection_items"和"total"



import requests from retrying import retry import json class doubaspider(): def __init__(self): self.url_list = [ { "url": "https://m.douban.com/rexxar/api/v2/subject_collection/filter_tv_domestic_hot/items?for_mobile=1&start={}&count=18", "country": "CN" }, { "url": "https://m.douban.com/rexxar/api/v2/subject_collection/filter_tv_american_hot/items?for_mobile=1&start={}&count=18", "country": "US" } ] self.headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"} # 发送请求 @retry(stop_max_attempt_number=3) def send_request(self,url): print('正在请求',url) r=requests.get(url,headers=self.headers) assert r.status_code==200 return r.content.decode() # 获取响应 def response(self,url): try: html_str=self.send_request(url) except: html_str=None return html_str # 提取结果,接受的是一个json的数据把json的数据转换成字典,取里面需要的subject_collection_items和total def get_content_list(self,html_str): dic_response = json.loads(html_str) content_list=dic_response['subject_collection_items'] total_num = dic_response['total'] return content_list,total_num # 保存数据,因为列表content_list里面的东西是字典,所以要遍历,把里面的字典转换成字符串 def save_data(self,content_list): with open('douba.txt','a',encoding='utf8') as f: for item in content_list: f.write(json.dumps(item,ensure_ascii=False,indent=2)) print('保存成功') def run(self): # 发送请求,遍历请求的列表拿出每个请求路径 for url_temp in self.url_list: num = 0 total_num = 100 while num < total_num: url = url_temp['url'].format(num) html_str=self.response(url) content_list,total_num=self.get_content_list(html_str) for i in content_list: i["country"]=url_temp["country"] self.save_data(content_list) if __name__=='__main__': douban_spider = doubaspider() douban_spider.run()
XPath和xlmi库
为什么要学习XPATH和LXML类库:lxml是一款高性能的 Python HTML/XML 解析器,我们可以利用XPath,来快速的定位特定元素以及获取节点信息.
什么是XPATH:XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,
可用来在 HTML\XML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp

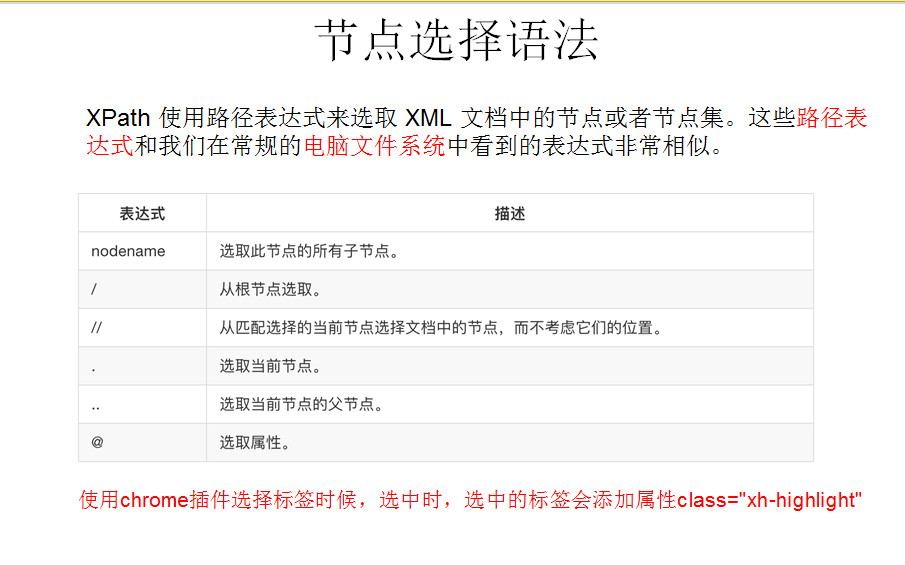
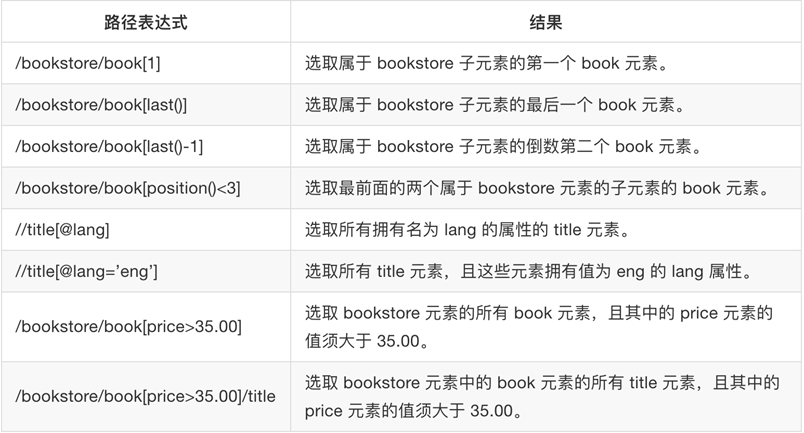
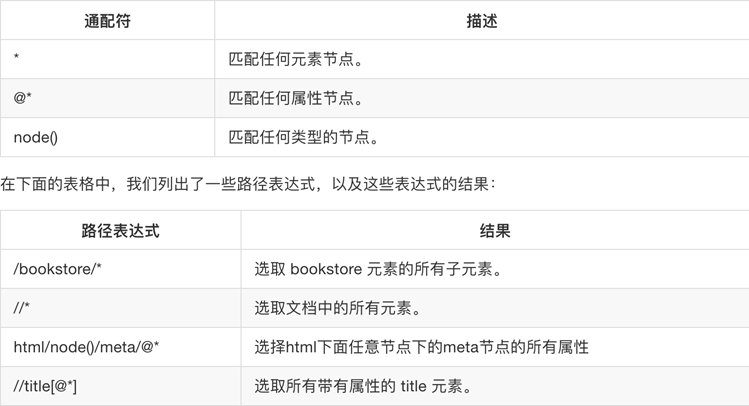


lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:
pip install lxml(或通过wheel方式安装)
初步使用
我们利用它来解析 HTML 代码,简单示例:
# 使用 lxml 的 etree 库 from lxml import etree text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签 </ul> </div> ''' #利用etree.HTML,将字符串解析为HTML文档 html = etree.HTML(text) # 按字符串序列化HTML文档 result = etree.tostring(html).decode() print(result)
输出结果:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
lxml 可以自动修正 html 代码,例子里不仅补全了 li 标签,还添加了 body,html 标签。
除了直接读取字符串,lxml还支持从文件里读取内容
文件读取:
除了直接读取字符串,lxml还支持从文件里读取内容。我们新建一个hello.html文件:
<!-- hello.html -->
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
再利用 etree.parse() 方法来读取文件。
from lxml import etree
# 读取外部文件 hello.html
html = etree.parse('./hello.html')
result = etree.tostring(html, pretty_print=True)
print(result)
输出结果与之前相同
XPath实例测试
1. 获取所有的 <li> 标签
from lxml import etree
html = etree.parse('hello.html')
print type(html) # 显示etree.parse() 返回类型
result = html.xpath('//li')
print (result) # 打印<li>标签的元素集合
print (len(result))
print (type(result))
print (type(result[0]))
输出结果:
<type 'lxml.etree._ElementTree'> [<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>] 5 <type 'list'> <type 'lxml.etree._Element'>
2. 继续获取<li> 标签的所有 class属性
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print (result)
运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
3. 继续获取<li>标签下href 为 link1.html 的 <a> 标签
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/a[@href="link1.html"]') print (result)
运行结果
[<Element a at 0x10ffaae18>]
4. 获取<li> 标签下的所有 <span> 标签
from lxml import etree html = etree.parse('hello.html') #result = html.xpath('//li/span') #注意这么写是不对的: #因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠 result = html.xpath('//li//span') print (result)
运行结果
[<Element span at 0x10d698e18>]
5. 获取 <li> 标签下的<a>标签里的所有 class
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/a//@class') print (result)
运行结果
['blod']
6. 获取最后一个 <li> 的 <a> 的 href
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li[last()]/a/@href') # 谓语 [last()] 可以找到最后一个元素 print (result)
运行结果
['link5.html']
7. 获取倒数第二个元素的内容
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li[last()-1]/a') # text 方法可以获取元素内容 print (result[0].text)
运行结果
fourth item
8. 获取 class 值为 bold 的标签名
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//*[@class="bold"]') # tag方法可以获取标签名 print (result[0].tag)
运行结果
span

 浙公网安备 33010602011771号
浙公网安备 33010602011771号