OpenAI-Translator
OpenAI-Translator 市场需求分析
翻译:一个长期存在的沟通需求
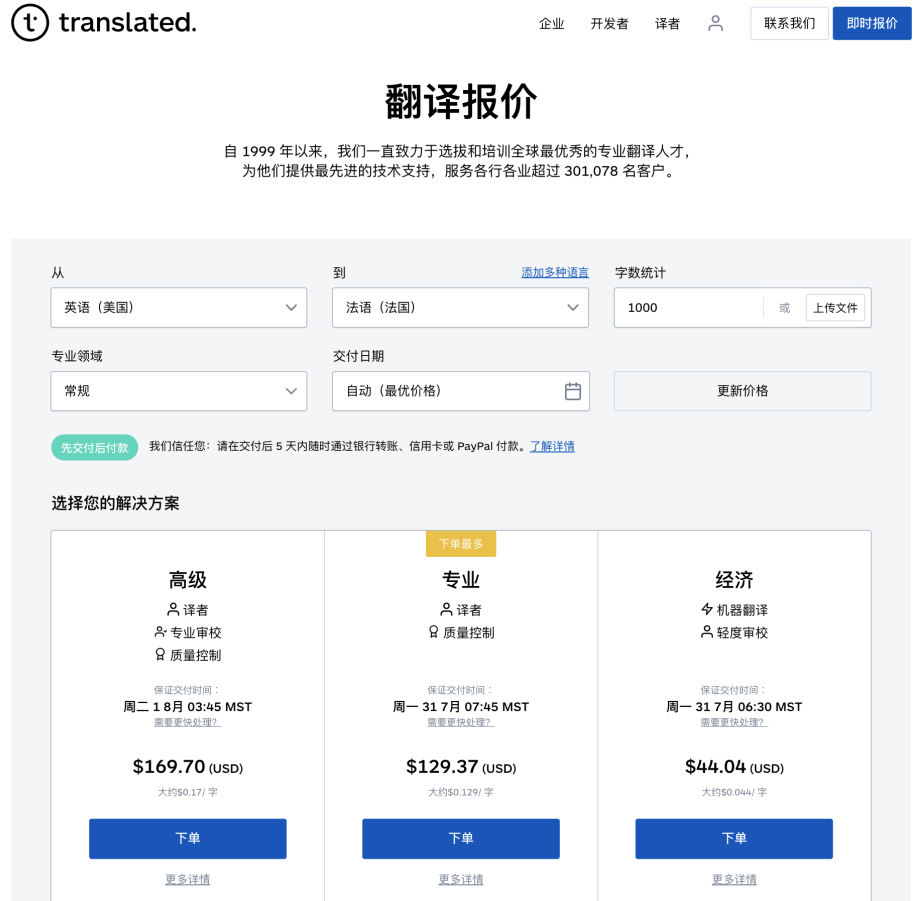
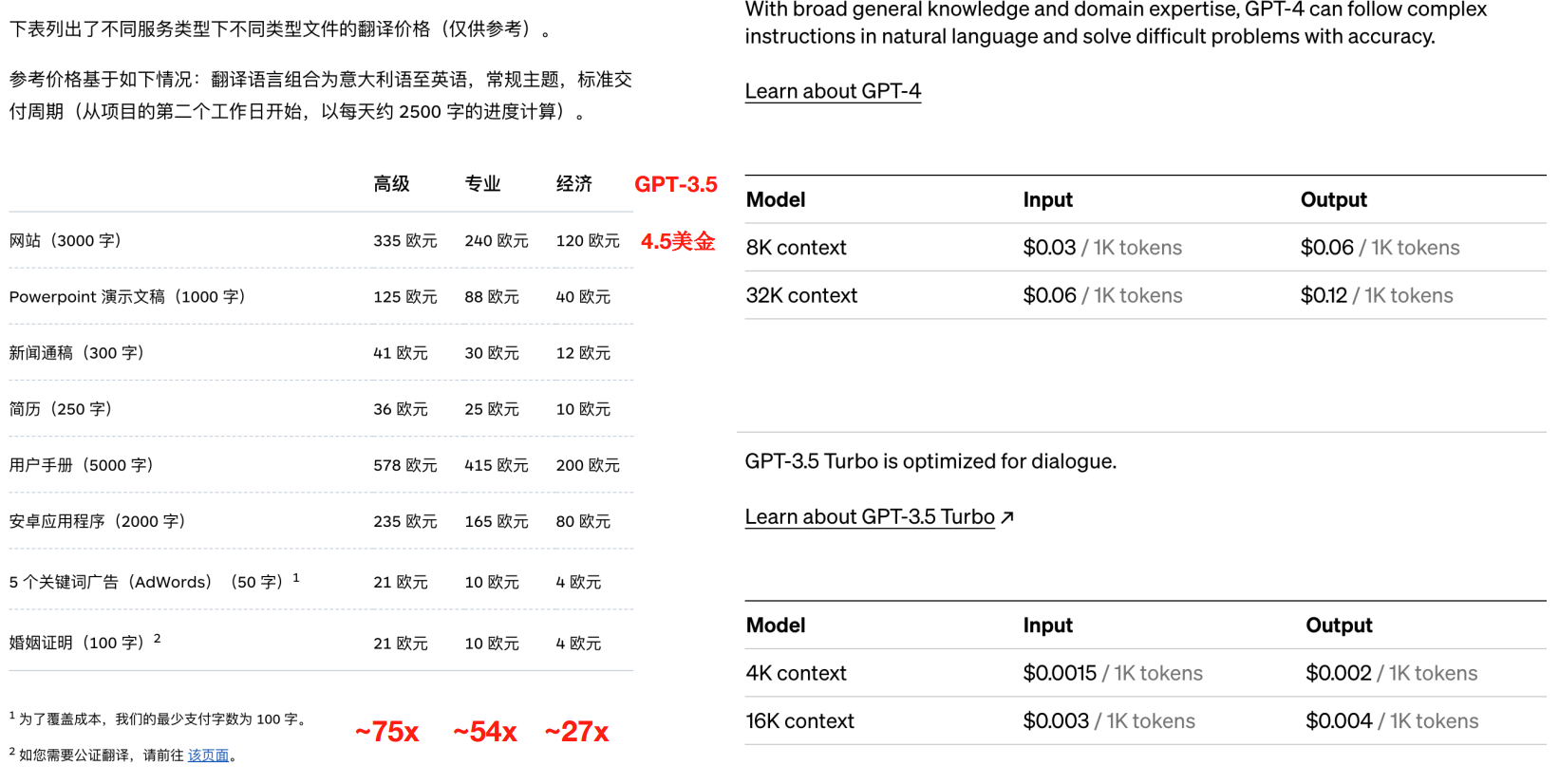
成本分析:人力 vs GPT
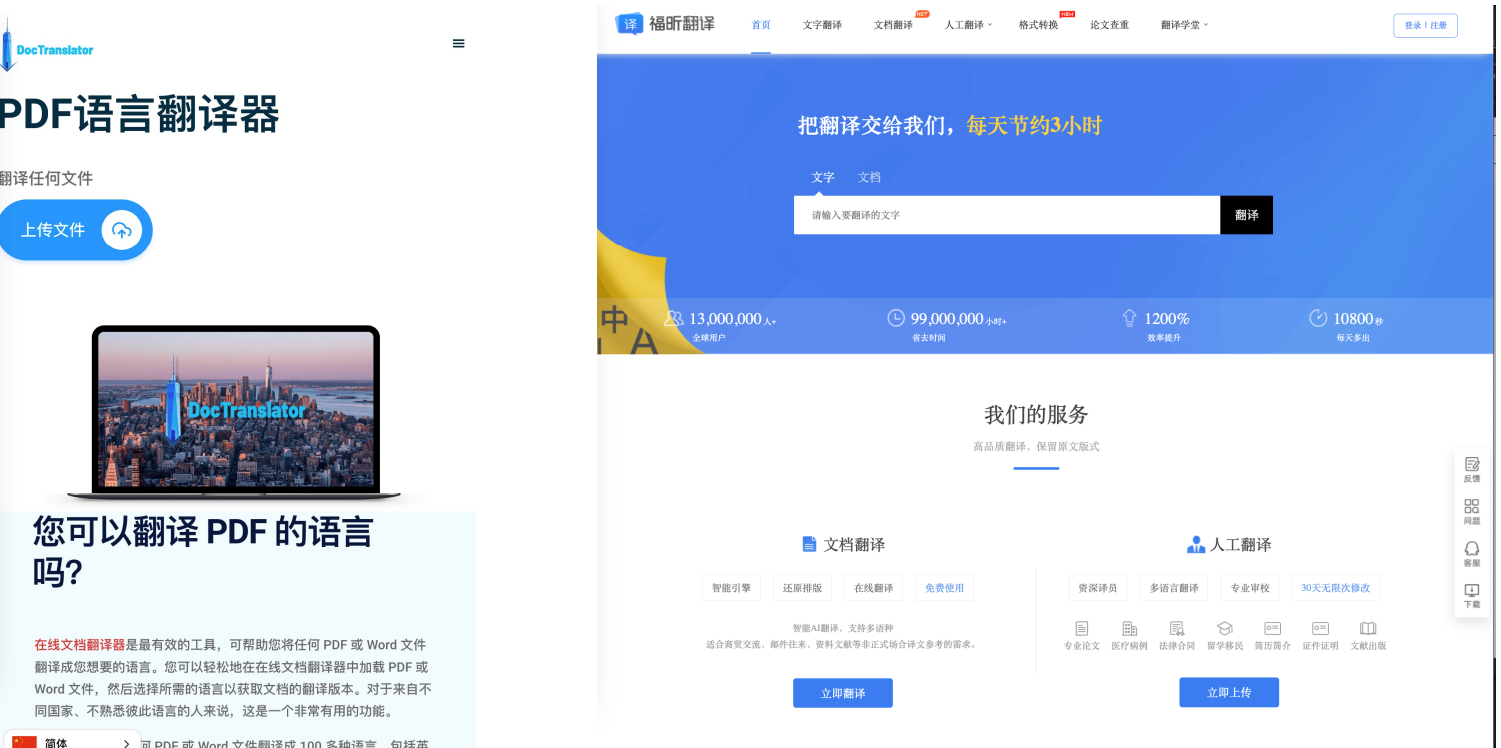
数据安全:在线翻译需上传整个文件
数据安全:大模型
-
GPT 服务方式:一定程度上解决了完整文件上传问题
-
API调用方式:拆分文档,无需上传整份文件
-
OpenAI 隐私协议:具有相对可靠的契约精神和法律保障
-
私有化大模型:端到端解决隐私安全问题
OpenAI-Translator 产品定义与功能规划
产品规划(v1.0)
Feat List
-
支持 PDF 文件格式解析
-
支持英文翻译成中文。
-
支持 OpenAI 和 ChatGLM 模型。
-
通过 YAML 文件或命令行参数灵活配置。
-
模块化和面向对象的设计,易于定制和扩展。
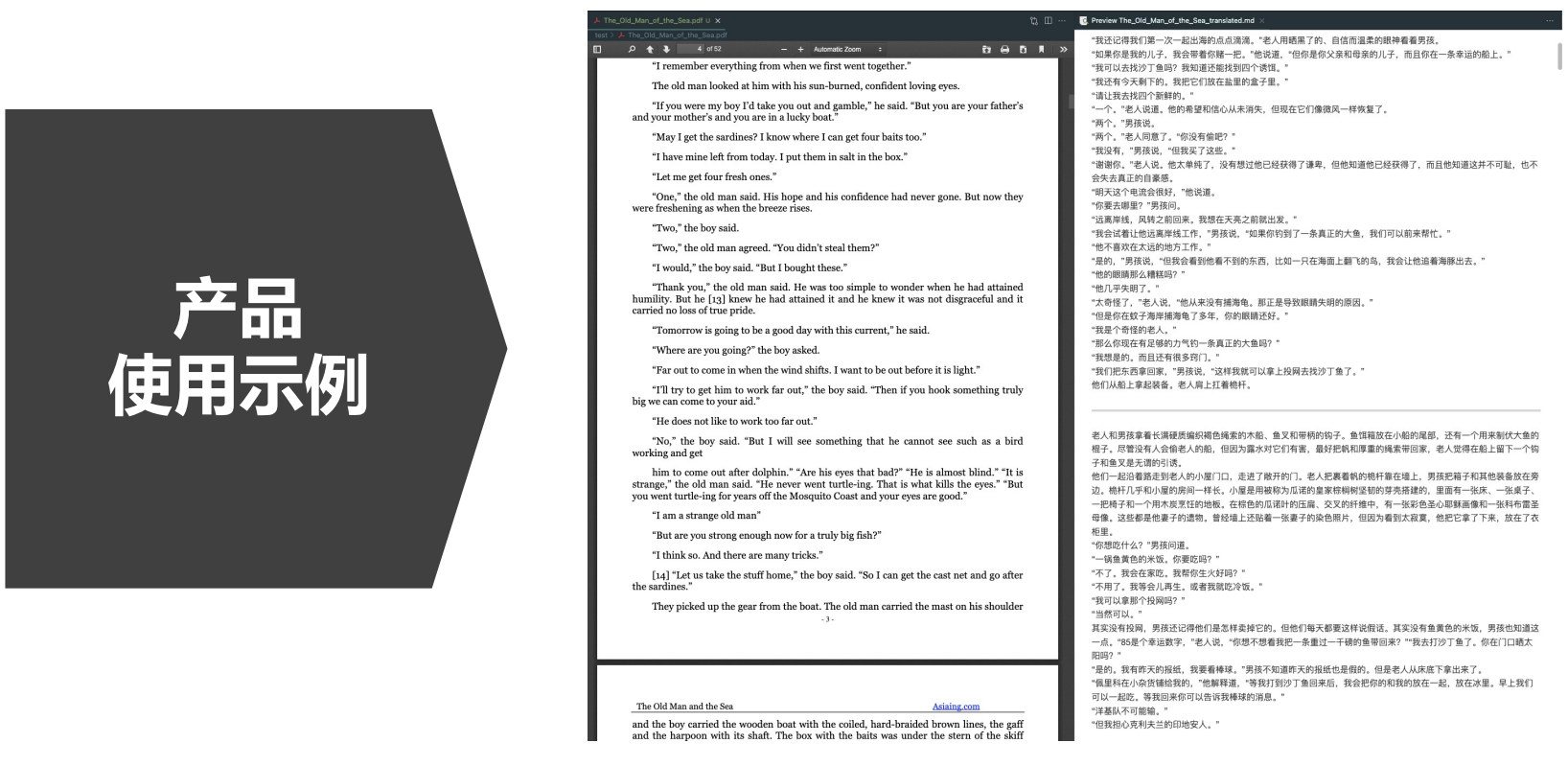
产品规划v2.0
Feat List
-
支持图形用户界面 (GUI), 提升易用性。
-
添加对保留源 PDF 的原始布局的支持。
-
服务化:以API形式提供翻译服务支持。
-
添加对其他语言的支持
OpenAI-Translator 技术方案
架构设计思路
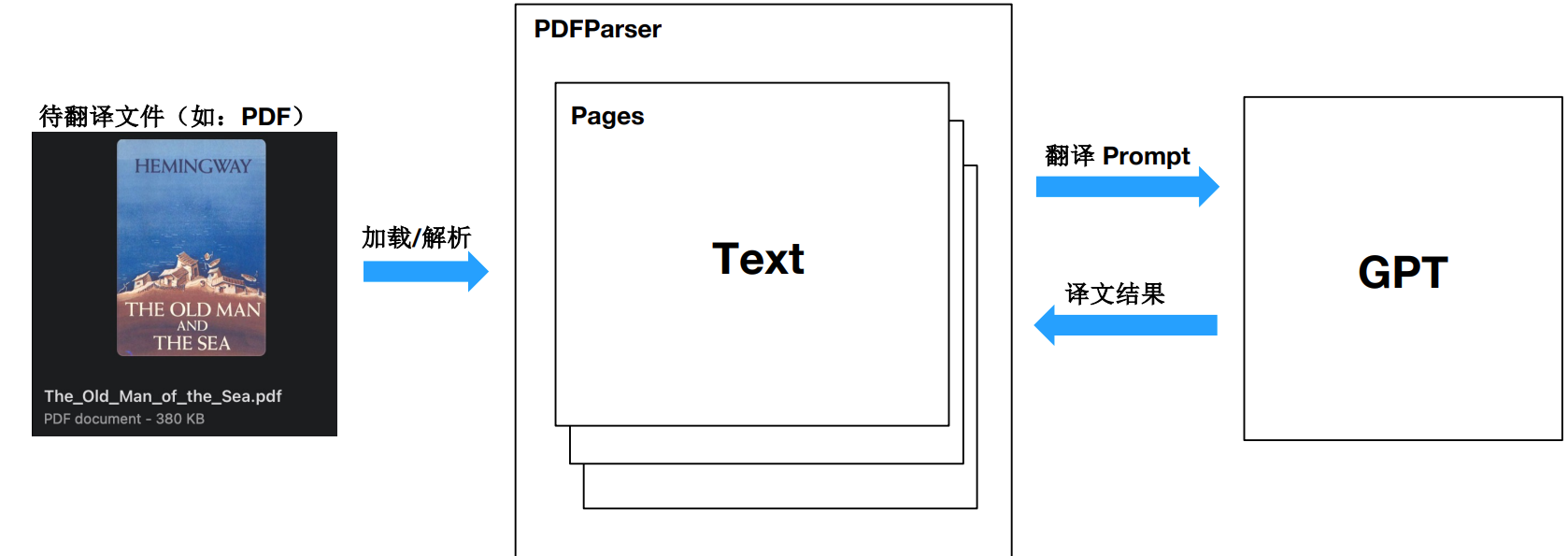
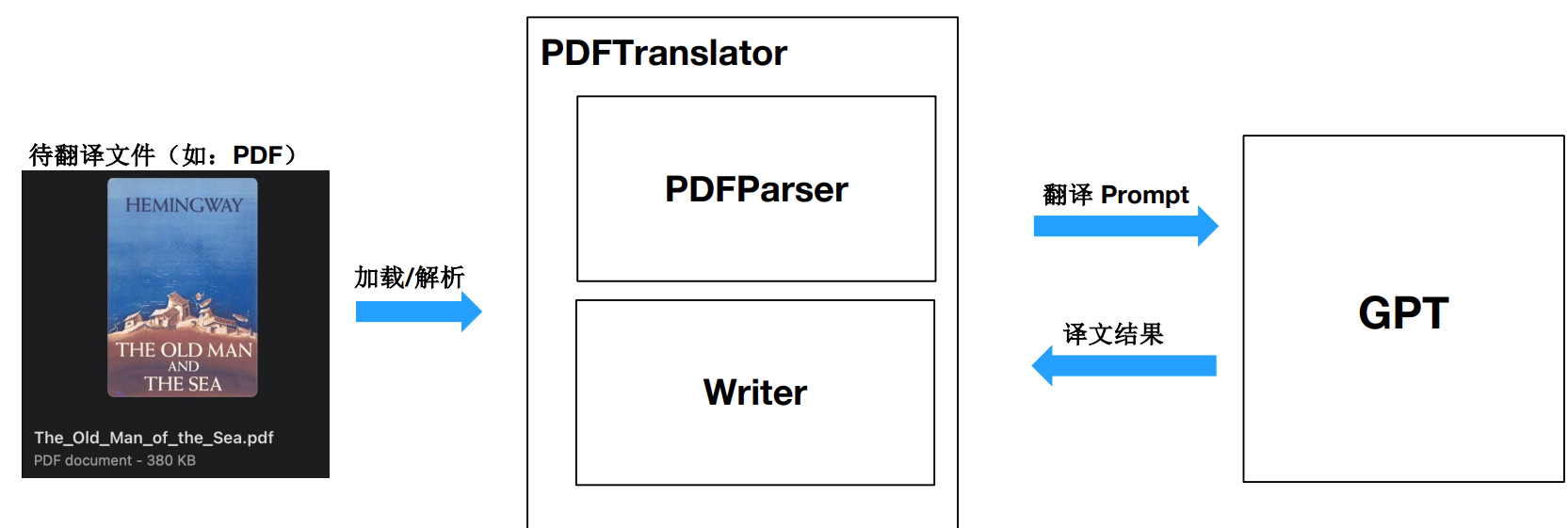
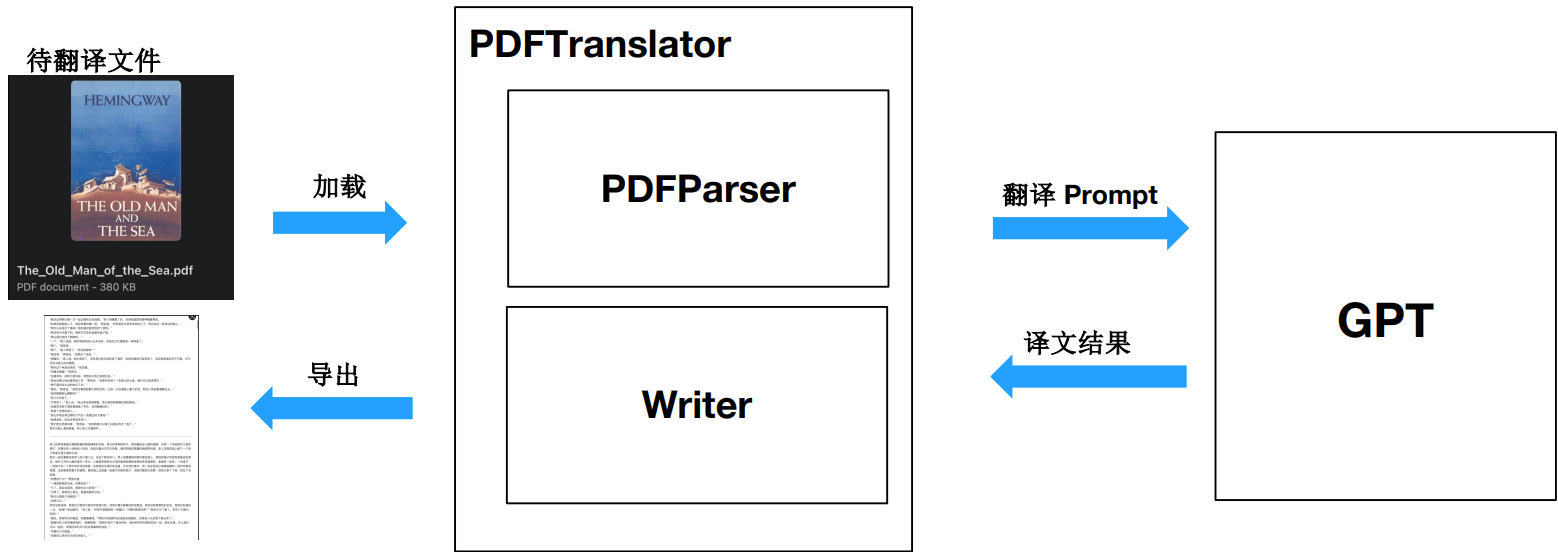
实战 PDF 解析库 pdfplumber
pdfplumber 项目(基于pdfminer.six开发),支持解析PDF文件,获取每个文本字符、矩形和线条的详细信息。此外还支持表格提取和可视化调试。
对于机器生成的PDF而言效果最佳,不适用于扫描得到的PDF。
支持:Python 3.8~3.11
加载PDF文件
要开始处理PDF,请调用pdfplumber.open(x)方法,其中x可以是:
- PDF 文件路径
- 作为字节加载的文件对象
- 作为字节加载的类似文件的对象
open方法将返回一个pdfplumber.PDF类的实例。
高级加载参数
要加载受密码保护的PDF,请传递password关键字参数,例如:pdfplumber.open("file.pdf", password="test")。
要设置布局分析参数到pdfminer.six的布局引擎中,请传递laparams关键字参数,例如:pdfplumber.open("file.pdf", laparams={"line_overlap": 0.7})。
pdfplumber.PDF类表示一个独立的PDF文件,两个主要成员变量:
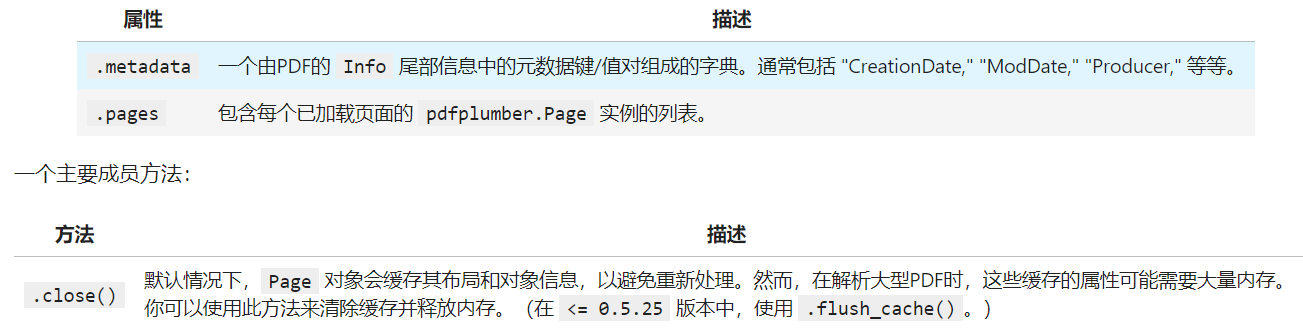
import pdfplumber
pdf = pdfplumber.open("The_Old_Man_of_the_Sea.pdf")
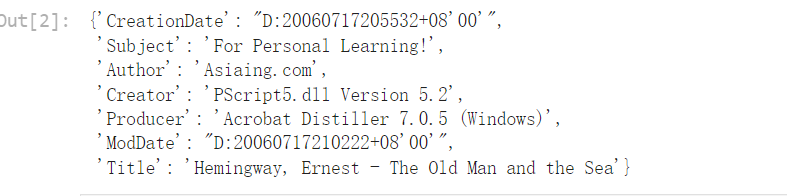
pdf.metadata
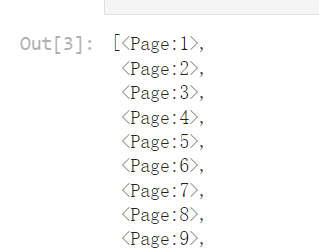
pdf.pages
type(pdf.pages[0])
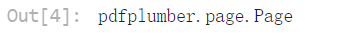
pdfplumber.Page 类
pdfplumber.Page 类是 pdfplumber 的核心,表示PDF文件中一页单独的内容。
当我们使用 pdfplumber 时,大部分操作都会围绕这个类展开。
主要成员变量如下:

pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
print(pages)
[<Page:1>, <Page:2>]
pages[0].page_number
1
print(pages[0].width, pages[0].height)
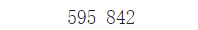
# 可视化第1页 pages[0].to_image()
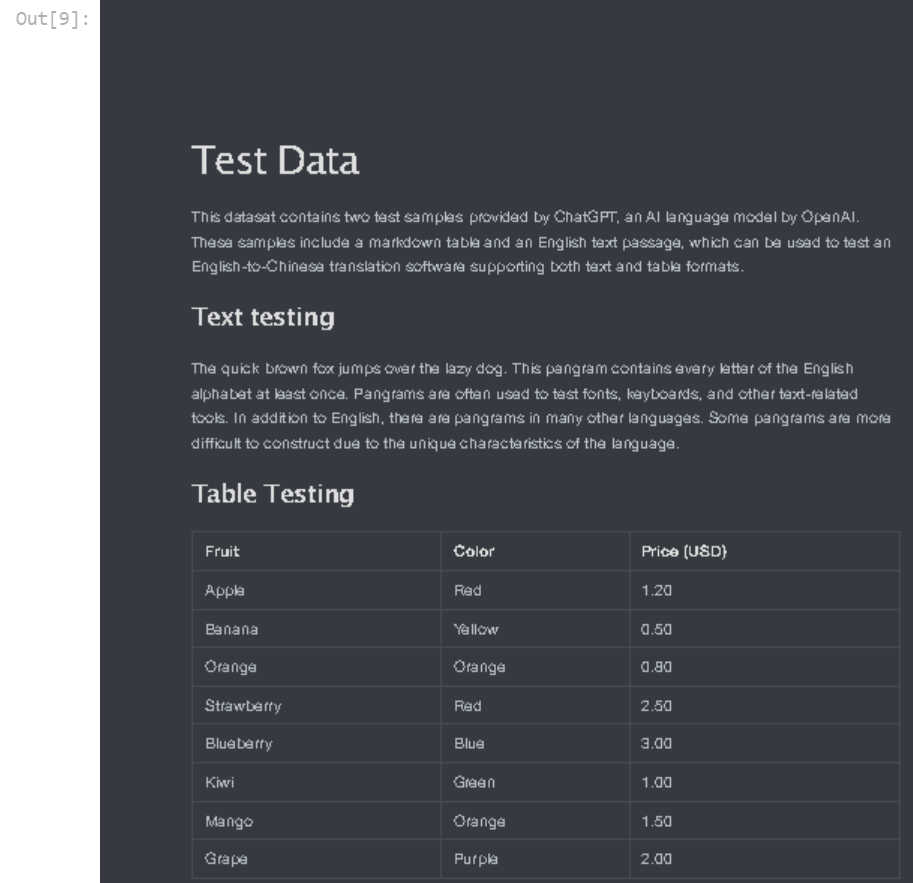
# 可视化第2页(尝试调整分辨率和抗锯齿) pages[1].to_image()

提取单页文本
pdfplumber库支持从任何给定的页面(pdfplumber.Page)中提取文本(包括裁剪和派生页面)。
在提取文本的基础功能外,同时支持保留文本布局,识别单词和搜索页面中的文本
文本提取方法
pdfplumber.Page 对象可以调用以下方法:
| 方法 | 描述 |
|---|---|
.extract_text(x_tolerance=3, y_tolerance=3, layout=False, x_density=7.25, y_density=13, **kwargs) |
将页面的所有字符对象汇集成一个单一的字符串。
|
.extract_text_simple(x_tolerance=3, y_tolerance=3) |
.extract_text(...) 的稍快但不太灵活的版本,使用更简单的逻辑。 |
.extract_words(x_tolerance=3, y_tolerance=3, keep_blank_chars=False, use_text_flow=False, horizontal_ltr=True, vertical_ttb=True, extra_attrs=[], split_at_punctuation=False, expand_ligatures=True) |
返回所有看起来像单词的东西及其边界框的列表。单词被认为是字符序列,其中(对于"直立"字符)一个字符的 x1 和下一个字符的 x0 之间的差异小于或等于 x_tolerance 并且 一个字符的 doctop 和下一个字符的 doctop 之间的差异小于或等于 y_tolerance。对于非直立字符,采取类似的方法,但是测量它们之间的垂直距离,而不是水平距离。参数 horizontal_ltr 和 vertical_ttb 表示是否应从左到右阅读单词(对于水平单词)/从上到下(对于垂直单词)。将 keep_blank_chars 更改为 True 将意味着空白字符被视为单词的一部分,而不是单词之间的空格。将 use_text_flow 更改为 True 将使用PDF的底层字符流作为排序和划分单词的指南,而不是预先按x/y位置排序字符。(这模仿了在PDF中拖动光标突出显示文本的方式;就像那样,顺序并不总是看起来逻辑。)传递 extra_attrs 列表(例如,["fontname", "size"] 将限制每个单词的字符具有完全相同的值,对于这些属性,并且结果的单词dicts将指示这些属性。将 split_at_punctuation 设置为 True 将在 string.punctuation 指定的标点处强制分割标记;或者你可以通过传递一个字符串来指定分隔标点的列表,例如,split_at_punctuation='!"&'()*+,.:;<=>?@[]^`{|}~'。除非你设置 expand_ligatures=False,否则将展开诸如 fi 之类的连字成其组成字母(例如,fi)。 |
.extract_text_lines(layout=False, strip=True, return_chars=True, **kwargs) |
实验性功能,返回代表页面上文本行的字典列表。strip 参数类似于Python的 str.strip() 方法,并返回没有周围空白的 text 属性。(只有当 layout = True 时才相关。)将 return_chars 设置为 False 将排除从返回的文本行dicts中添加单个字符对象。剩余的 **kwargs 是你将传递给 .extract_text(layout=True, ...) 的参数。 |
.search(pattern, regex=True, case=True, main_group=0, return_groups=True, return_chars=True, layout=False, **kwargs) |
实验性功能,允许你搜索页面的文本,返回匹配查询的所有实例的列表。对于每个实例,响应字典对象包含匹配的文本、任何正则表达式组匹配、边界框坐标和字符对象本身。pattern 可以是编译的正则表达式、未编译的正则表达式或非正则字符串。如果 regex 是 False,则将模式视为非正则字符串。如果 case 是 False,则以不区分大小写的方式执行搜索。设置 main_group 将结果限制为 pattern 中的特定正则组(0 的默认值表示整个匹配)。将 return_groups 和/或 return_chars 设置为 False 将排除添加匹配的正则组和/或字符的列表(作为 "groups" 和 "chars" 添加到返回的dicts)。layout 参数的操作方式与 .extract_text(...) 相同。剩余的 **kwargs 是你将传递给 .extract_text(layout=True, ...) 的参数。 __注意__:零宽度和全空白匹配被丢弃,因为它们(通常)在页面上没有明确的位置。 |
.dedupe_chars(tolerance=1) |
返回页面的版本,其中删除了重复的字符 — 那些与其他字符共享相同的文本、字体名、大小和位置(在 tolerance x/y 内)的字符。(参见 Issue #71 以理解动机。) |
获取单页文本
p1_text = pages[0].extract_text() print(p1_text)

获取单页文本(保留布局)
p1_text = pages[0].extract_text(layout=True) print(p1_text)
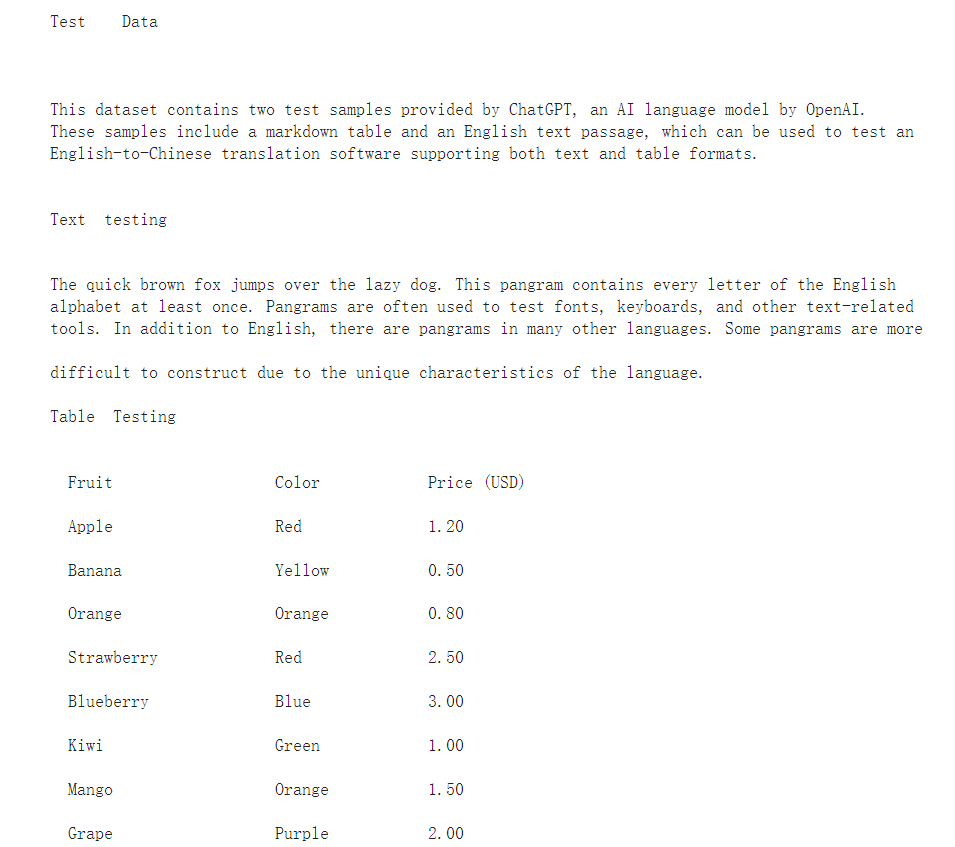
注意:表格也被文本解析出来了
提取单页表格
pdfplumber 对表格提取的方法大量借鉴了 Anssi Nurminen 的硕士论文,并受到 Tabula 的启发。
它的工作原理如下:
- 对于任何给定的PDF页面,找到那些(a)明确定义的线条和/或(b)由页面上单词的对齐方式暗示的线条。
- 合并重叠的,或几乎重叠的,线条。
- 找到所有这些线条的交点。
- 找到使用这些交点作为顶点的最精细的矩形集合(即,单元格)。
- 将连续的单元格分组成表格。
表格提取方法
提取单页表格
pdfplumber 对表格提取的方法大量借鉴了 Anssi Nurminen 的硕士论文,并受到 Tabula 的启发。
它的工作原理如下:
- 对于任何给定的PDF页面,找到那些(a)明确定义的线条和/或(b)由页面上单词的对齐方式暗示的线条。
- 合并重叠的,或几乎重叠的,线条。
- 找到所有这些线条的交点。
- 找到使用这些交点作为顶点的最精细的矩形集合(即,单元格)。
- 将连续的单元格分组成表格。
表格提取方法
pdfplumber 对表格提取的方法大量借鉴了 Anssi Nurminen 的硕士论文,并受到 Tabula 的启发。
它的工作原理如下:
- 对于任何给定的PDF页面,找到那些(a)明确定义的线条和/或(b)由页面上单词的对齐方式暗示的线条。
- 合并重叠的,或几乎重叠的,线条。
- 找到所有这些线条的交点。
- 找到使用这些交点作为顶点的最精细的矩形集合(即,单元格)。
- 将连续的单元格分组成表格。
表格提取方法
pdfplumber.Page 对象可以调用以下方法:
| 方法 | 描述 |
|---|---|
.find_tables(table_settings={}) |
返回一个 Table 对象的列表。Table 对象提供对 .cells,.rows,和 .bbox 属性的访问,以及 .extract(x_tolerance=3, y_tolerance=3) 方法。 |
.find_table(table_settings={}) |
类似于 .find_tables(...),但返回页面上 最大 的表格,作为一个 Table 对象。如果多个表格的大小相同 —— 以单元格数量衡量 —— 此方法返回最接近页面顶部的表格。 |
.extract_tables(table_settings={}) |
返回从页面上找到的 所有 表格中提取的文本,表示为一个列表的列表的列表,结构为 table -> row -> cell。 |
.extract_table(table_settings={}) |
返回从页面上 最大 的表格中提取的文本(参见上面的 .find_table(...)),表示为一个列表的列表,结构为 row -> cell。 |
.debug_tablefinder(table_settings={}) |
返回 TableFinder 类的一个实例,可以访问 .edges,.intersections,.cells,和 .tables 属性。 |
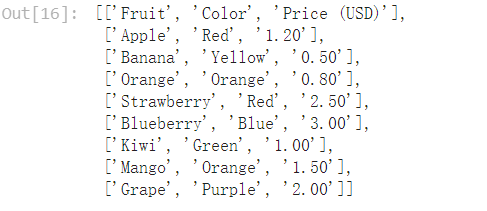
获取单页表格
p1_table = pages[0].extract_table() p1_table
获取单页所有表格
tables = pages[0].extract_tables() len(tables) 1 tables

p1_debug_table = pages[0].debug_tablefinder() type(p1_debug_table) pdfplumber.table.TableFinder p1_debug_table.tables

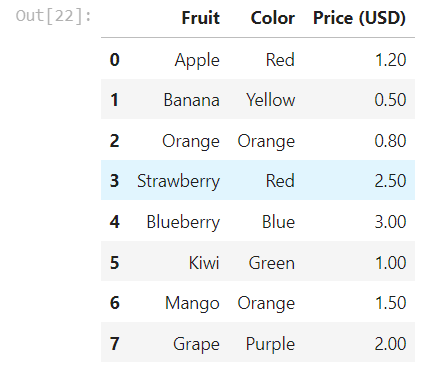
使用 Pandas.DataFrame 来展示和存储表格
import pandas as pd df = pd.DataFrame(p1_table[1:], columns=p1_table[0]) df
可视化调试页面
pdfplumber 可视化调试工具可以帮助我们理解PDF文件的内容和结构,以及从中提取出来的对象。
PageImage 类
pdfplumber.Page 对象可以使用.to_image()方法,将任何页面(包括裁剪后的页面)转换为PageImage对象。
pdfplumber.Page.to_image()方法主要参数:
- resolution:所需每英寸像素数。默认值:72。类型:整数。
- width:所需图像宽度(以像素为单位)。默认值:未设置,由分辨率确定。类型:整数。
- height:所需图像高度(以像素为单位)。默认值:未设置,由分辨率确定。类型:整数。
- antialias: 是否在创建图像时使用抗锯齿。将其设置为True可以创建具有较少锯齿的文本和图形,但文件大小会更大。默认值:False。类型:布尔值。
可视化第一页
pages[0].to_image()

可视化第二页(尝试调整分辨率和抗锯齿)
pages[1].to_image()

提取页面图像
pdfplumber.Page 对象没有 extract_images 方法,所以不能直接从 PDF 页面中提取图像。
但是,可以通过页面操作来截取和获取图像,pdfplumber.Page类相关成员变量如下:
| 属性 | 描述 |
|---|---|
.width |
页面的宽度。 |
.height |
页面的高度。 |
.objects / .chars / .lines / .rects / .curves / .images |
这些属性都是列表,每个列表包含页面上嵌入的每个此类对象的一个字典 |
相关成员方法:
| 方法 | 描述 |
|---|---|
.crop(bounding_box, relative=False, strict=True) |
返回裁剪到边界框的页面版本,边界框应表示为4元组,值为 (x0, top, x1, bottom)。裁剪的页面保留至少部分在边界框内的对象。如果对象只部分在框内,其尺寸将被切割以适应边界框。如果 relative=True,则边界框是从页面边界框的左上角偏移计算的,而不是绝对定位。(请参见 Issue #245 以获取视觉示例和解释。)当 strict=True(默认值)时,裁剪的边界框必须完全在页面的边界框内。 |
.within_bbox(bounding_box, relative=False, strict=True) |
类似于 .crop,但只保留 完全在 边界框内的对象。 |
.outside_bbox(bounding_box, relative=False, strict=True) |
类似于 .crop 和 .within_bbox,但只保留 完全在 边界框外的对象。 |
.filter(test_function) |
返回只有 test_function(obj) 返回 True 的 .objects 的页面版本。 |
从 PageImage 中获取页面图像分辨率
pages[1].images

可视化裁剪后的第二页
img = pages[1].images[0] bbox = (img["x0"], img["top"], img["x1"], img["bottom"]) cropped_page = pages[1].crop(bbox) cropped_page.to_image()

可视化裁剪后的第二页+抗锯齿
cropped_page.to_image(antialias=True)

也可以直接调高分辨率,会消耗更多的内存
cropped_page.to_image(resolution=1080)

保存图像
im = cropped_page.to_image(antialias=True)
im.save("pdf_image_test.png")
OpenAI-Translator 模块设计

 浙公网安备 33010602011771号
浙公网安备 33010602011771号