elasticsearch—数据建模
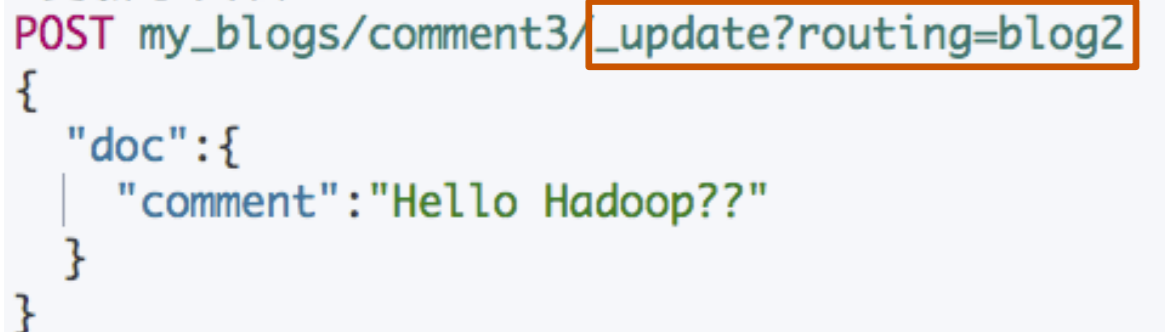
对象及 Nested 对象
数据的关联关系
真实世界中有很多重要的关联关系
-
博客 / 作者 / 评论
-
银⾏账户有多次交易记录
-
客户有多个银⾏账户
-
⽬录⽂件有多个⽂件和⼦⽬录
关系型数据库的范式化设计

Denormalization
反范式化设计
- 数据 “Flattening”,不使⽤关联关系,⽽是在⽂档中保存冗余的数据拷⻉
优点:⽆需处理 Joins 操作,数据读取性能好
- Elasticsearch 通过压缩 _source 字段,减少磁盘空间的开销
缺点:不适合在数据频繁修改的场景
- ⼀条数据(⽤户名)的改动,可能会引起很多数据的更新
Elasticsearch 中处理关联关系
关系型数据库,⼀般会考虑 Normalize 数据;在 Elasticsearch,往往考虑 Denormalize 数据
- Denormalize 的好处:读的速度变快 / ⽆需表连接 / ⽆需⾏锁
Elasticsearch 并不擅⻓处理关联关系。我们⼀般采⽤以下四种⽅法处理关联
-
对象类型
-
嵌套对象(Nested Object)
-
⽗⼦关联关系(Parent / Child )
-
应⽤端关联
案例 1:博客和其作者信息
对象类型
-
在每⼀博客的⽂档中都保留作者的信息
-
如果作者信息发⽣变化,需要修改相关的 博客⽂档
数据准备


DELETE blog # 设置blog的 Mapping PUT /blog { "mappings": { "properties": { "content": { "type": "text" }, "time": { "type": "date" }, "user": { "properties": { "city": { "type": "text" }, "userid": { "type": "long" }, "username": { "type": "keyword" } } } } } } # 插入一条 Blog 信息 PUT blog/_doc/1 { "content": "I like Elasticsearch", "time": "2019-01-01T00:00:00", "user": { "userid": 1, "username": "Jack", "city": "Shanghai" } }
通过⼀条查询即可获取到博客和作者信息
POST blog/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"content": "Elasticsearch"
}
},
{
"match": {
"user.username": "Jack"
}
}
]
}
}
}
案例 2:包含对象数组的⽂档
数据准备
DELETE my_movies # 电影的Mapping信息 PUT my_movies { "mappings": { "properties": { "actors": { "properties": { "first_name": { "type": "keyword" }, "last_name": { "type": "keyword" } } }, "title": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } } # 写入一条电影信息 POST my_movies/_doc/1 { "title": "Speed", "actors": [ { "first_name": "Keanu", "last_name": "Reeves" }, { "first_name": "Dennis", "last_name": "Hopper" } ] }
搜索包含对象数组的⽂档
POST my_movies/_search { "query": { "bool": { "must": [ { "match": { "actors.first_name": "Keanu" } }, { "match": { "actors.last_name": "Hopper" } } ] } } }
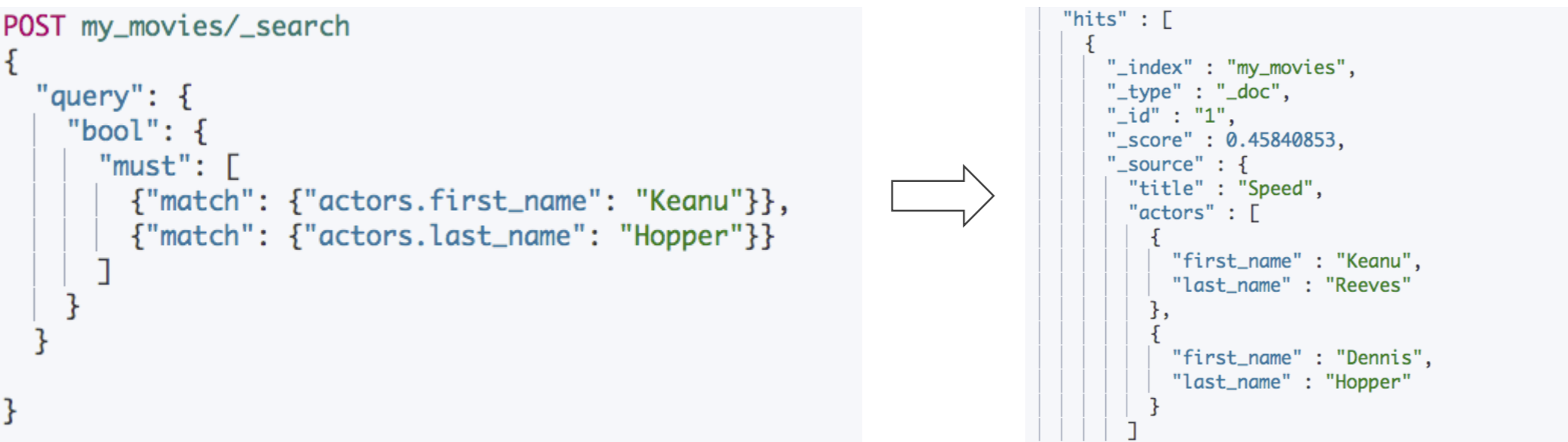
为什么会搜到不需要的结果?
-
存储时,内部对象的边界并没有考虑在内,JSON 格式被处理成扁平式键值对的结构
-
当对多个字段进⾏查询时,导致了意外的搜索结果
-
可以⽤ Nested Data Type 解决这个问题

什么是 Nested Data Type
-
Nested 数据类型:允许对象数组中的对象被独⽴索引
-
使⽤ nested 和 properties 关键字,将 所有 actors 索引到多个分隔的⽂档
-
在内部, Nested ⽂档会被保存在两个 Lucene ⽂档中,在查询时做 Join 处理
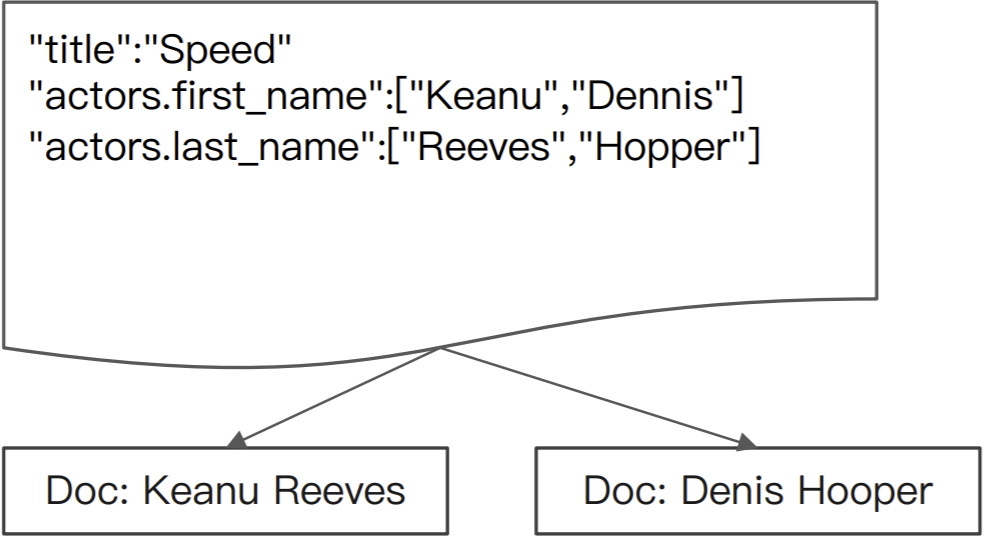
创建 Nested 对象 Mapping和数据准备
DELETE my_movies # 创建 Nested 对象 Mapping PUT my_movies { "mappings": { "properties": { "actors": { "type": "nested", "properties": { "first_name": { "type": "keyword" }, "last_name": { "type": "keyword" } } }, "title": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } } POST my_movies/_doc/1 { "title": "Speed", "actors": [ { "first_name": "Keanu", "last_name": "Reeves" }, { "first_name": "Dennis", "last_name": "Hopper" } ] }
Nested 嵌套查询
POST my_movies/_search { "query": { "bool": { "must": [ { "match": { "title": "Speed" } }, { "nested": { "path": "actors", "query": { "bool": { "must": [ { "match": { "actors.first_name": "Keanu" } }, { "match": { "actors.last_name": "Hopper" } } ] } } } } ] } } }
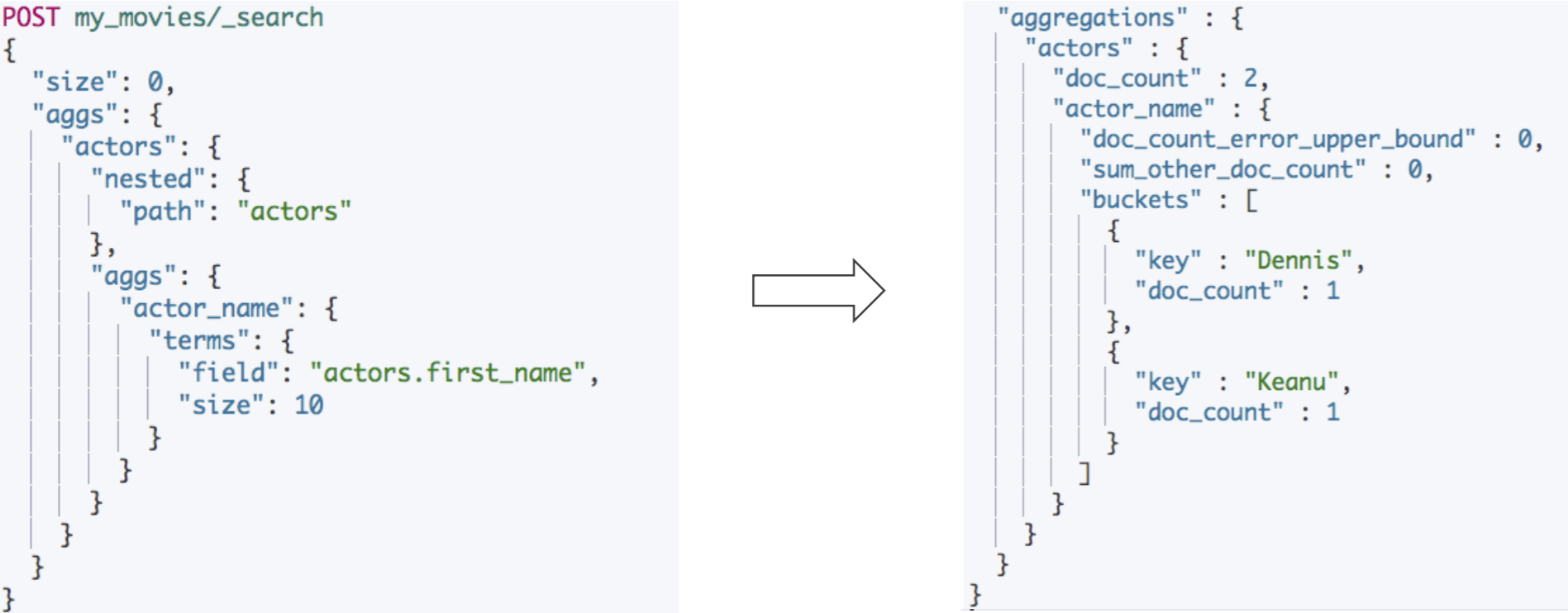
嵌套聚合
POST my_movies/_search { "size": 0, "aggs": { "actors": { "nested": { "path": "actors" }, "aggs": { "actor_name": { "terms": { "field": "actors.first_name", "size": 10 } } } } } }
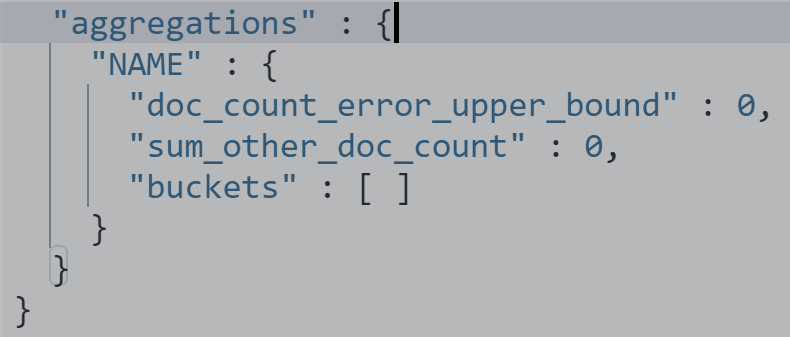
普通 aggregation不工作
POST my_movies/_search
{
"size": 0,
"aggs": {
"NAME": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}
相关阅读
⽂档的⽗⼦关系
Parent / Child
对象和 Nested 对象的局限性
- 每次更新,需要重新索引整个对象(包括根对象和嵌套对象)
ES 提供了类似关系型数据库中 Join 的实现。使⽤ Join 数据类型实现,可以通过维护 Parent / Child 的关系,从⽽分离两个对象
-
⽗⽂档和⼦⽂档是两个独⽴的⽂档
-
更新⽗⽂档⽆需重新索引⼦⽂档。⼦⽂档被添加,更新或者删除也不会影响到⽗⽂档和其他的⼦⽂档
⽗⼦关系
定义⽗⼦关系的⼏个步骤
-
设置索引的 Mapping
-
索引⽗⽂档
-
索引⼦⽂档
-
按需查询⽂档
设置 Mapping
DELETE my_blogs # 设定 Parent/Child Mapping PUT my_blogs { "settings": { "number_of_shards": 2 }, "mappings": { "properties": { "blog_comments_relation": { "type": "join", "relations": { "blog": "comment" } }, "content": { "type": "text" }, "title": { "type": "keyword" } } } }

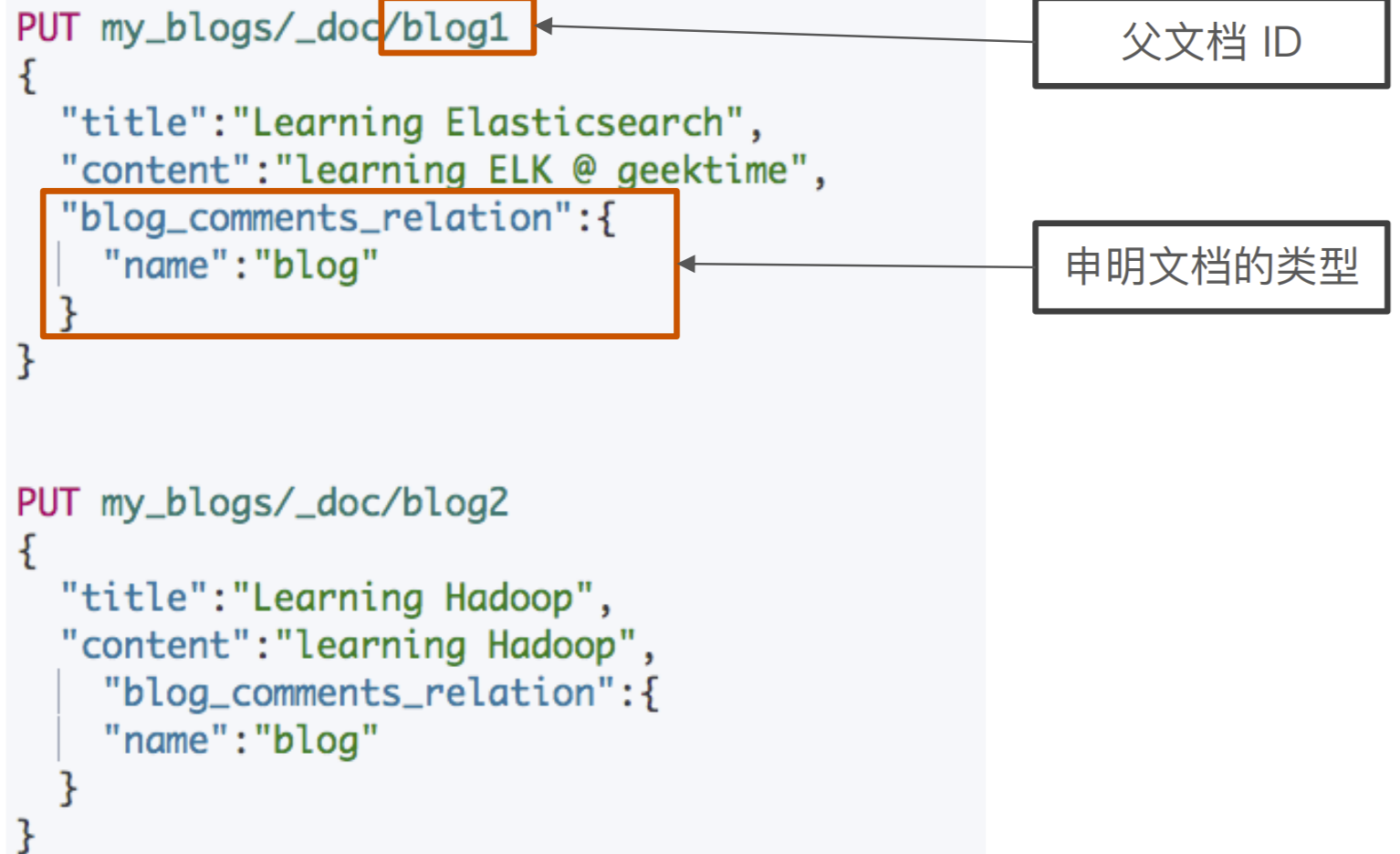
索引⽗⽂档
#索引父文档 PUT my_blogs/_doc/blog1 { "title": "Learning Elasticsearch", "content": "learning ELK @ geektime", "blog_comments_relation": { "name": "blog" } } #索引父文档 PUT my_blogs/_doc/blog2 { "title": "Learning Hadoop", "content": "learning Hadoop", "blog_comments_relation": { "name": "blog" } }
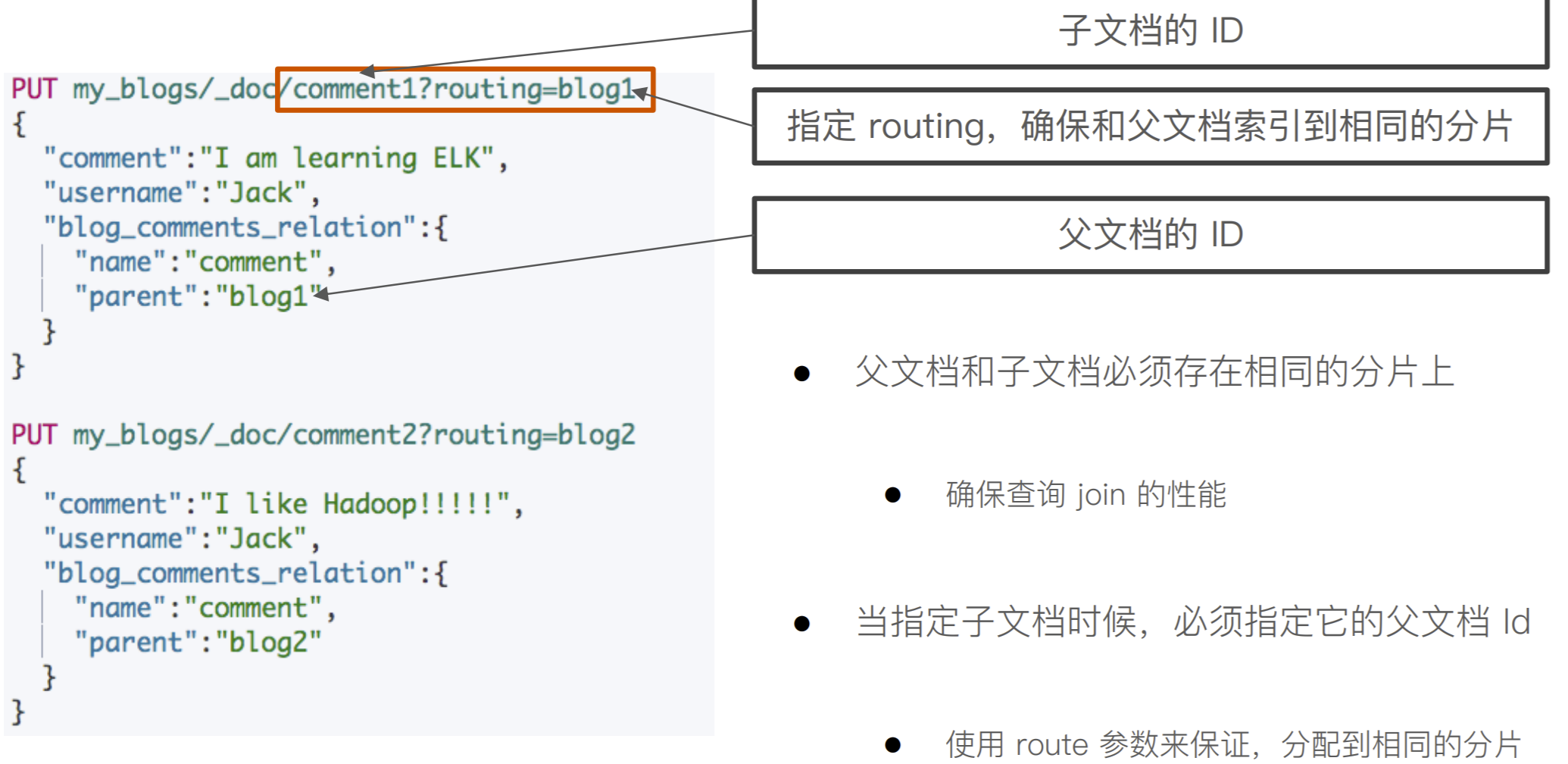
索引⼦⽂档
PUT my_blogs/_doc/comment1?routing=blog1 { "comment": "I am learning ELK", "username": "Jack", "blog_comments_relation": { "name": "comment", "parent": "blog1" } } #索引子文档 PUT my_blogs/_doc/comment2?routing=blog2 { "comment": "I like Hadoop!!!!!", "username": "Jack", "blog_comments_relation": { "name": "comment", "parent": "blog2" } } #索引子文档 PUT my_blogs/_doc/comment3?routing=blog2 { "comment":"Hello Hadoop", "username":"Bob", "blog_comments_relation":{ "name":"comment", "parent":"blog2" } }
Parent / Child 所⽀持的查询
查询所有⽂档
POST my_blogs/_search
{}
Parent Id 查询
通过对⽗⽂档 Id 进⾏查询,返回所有相关⼦⽂档
POST my_blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog2"
}
}
}
Has Child 查询,返回父文档
POST my_blogs/_search { "query": { "has_child": { "type": "comment", "query": { "match": { "username": "Jack" } } } } }

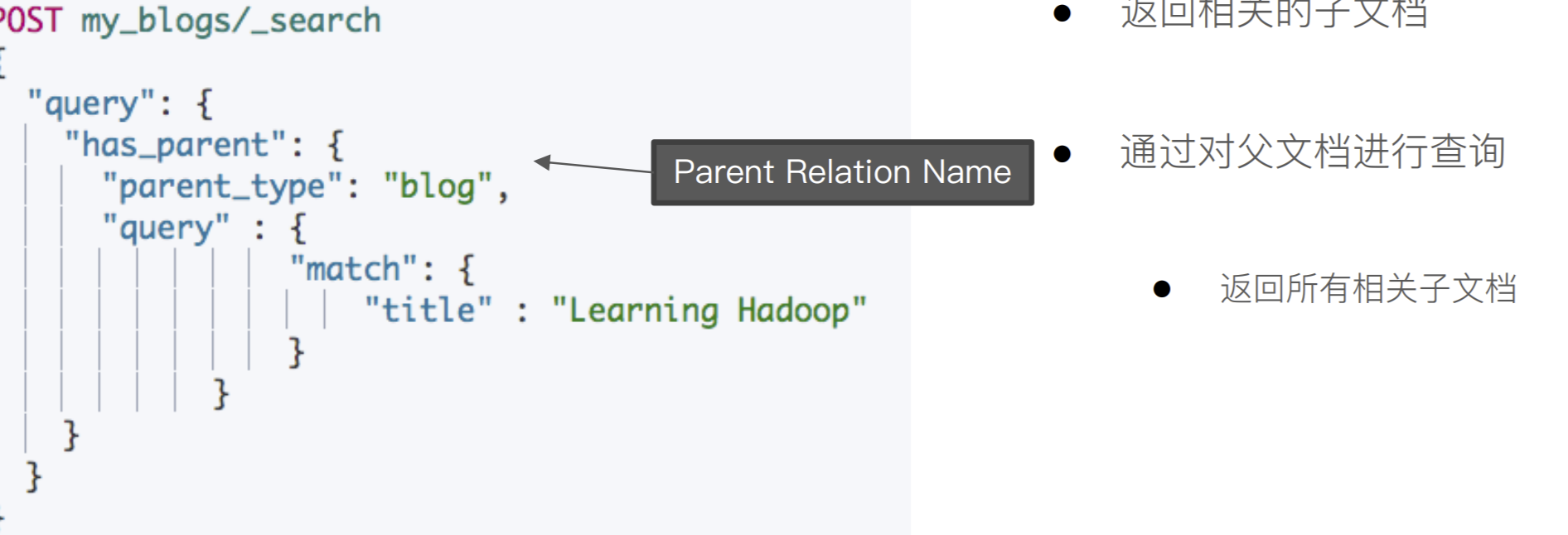
使⽤ has_parent 查询
POST my_blogs/_search { "query": { "has_parent": { "parent_type": "blog", "query": { "match": { "title": "Learning Hadoop" } } } } }
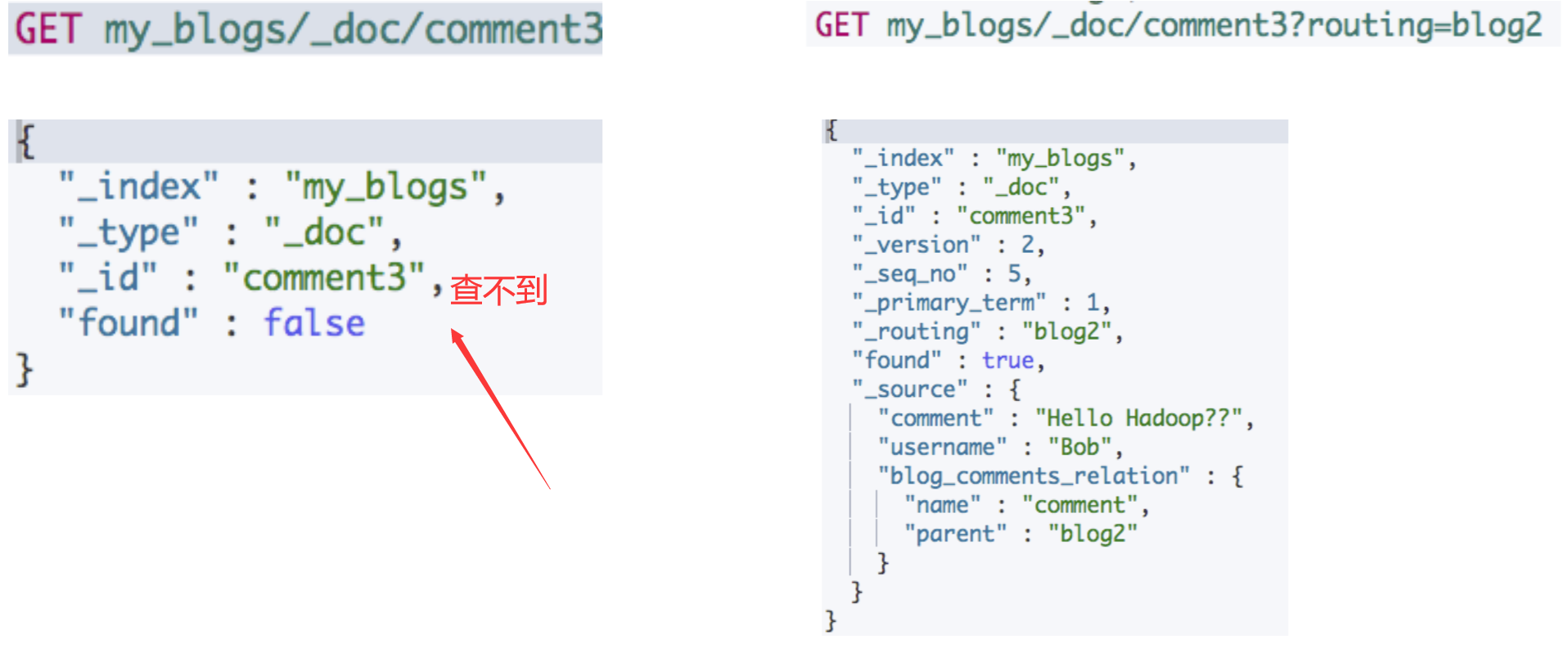
访问⼦⽂档,需指定⽗⽂档 routing 参数
#通过ID ,访问子文档 GET my_blogs/_doc/comment3 #通过ID和routing ,访问子文档 GET my_blogs/_doc/comment3?routing=blog2
更新⼦⽂档
- 更新⼦⽂档不会影响到⽗⽂档
PUT my_blogs/_doc/comment3?routing=blog2 { "comment": "Hello Hadoop??", "blog_comments_relation": { "name": "comment", "parent": "blog2" } }
嵌套对象 v.s ⽗⼦⽂档
相关阅读
-
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-has-child-query.html
-
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-has-parent-query.html
-
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-parent-id-query.html
-
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-parent-id-query.html
Update By Query & Reindex API
使⽤场景
⼀般在以下⼏种情况时,我们需要重建索引
-
索引的 Mappings 发⽣变更:字段类型更改,分词器及字典更新
-
索引的 Settings 发⽣变更:索引的主分⽚数发⽣改变
-
集群内,集群间需要做数据迁移
Elasticsearch 的内置提供的 API
-
Update By Query:在现有索引上重建
-
Reindex:在其他索引上重建索引
案例 1:为索引增加⼦字段
写入文档
DELETE blogs/
# 写入文档
PUT blogs/_doc/1
{
"content": "Hadoop is cool",
"keyword": "hadoop"
}
改变 Mapping,增加⼦字段,使⽤英⽂分词器
PUT blogs/_mapping
{
"properties": {
"content": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
# 写入文档
PUT blogs/_doc/2
{
"content": "Elasticsearch rocks",
"keyword": "elasticsearch"
}
查询新写入文
POST blogs/_search
{
"query": {
"match": {
"content.english": "Elasticsearch"
}
}
}

查询 Mapping 变更前写入的文档
POST blogs/_search
{
"query": {
"match": {
"content.english": "Hadoop"
}
}
}

执⾏ Update By Query,重建索引,在再次查询解决问题
POST blogs/_update_by_query
{}
# 查询之前写入的文档
POST blogs/_search
{
"query": {
"match": {
"content.english": "Hadoop"
}
}
}
案例 2:更改已有字段类型的 Mappings
想把以前keyword的类型变更,在已经有数据的情况下
# 查询 GET blogs/_mapping PUT blogs/_mapping { "properties" : { "content" : { "type" : "text", "fields" : { "english" : { "type" : "text", "analyzer" : "english" } } }, "keyword" : { "type" : "keyword" } } }

执行报错
-
ES 不允许在原有 Mapping 上对字段类型进⾏修改
-
只能创建新的索引,并且设定正确的字段类型,再 重新导⼊数据

Reindex API (重新建立新的索引)
Reindex API ⽀持把⽂档从⼀个索引拷⻉到另外 ⼀个索引
使⽤ Reindex API 的⼀些场景
-
修改索引的主分⽚数
-
改变字段的 Mapping 中的字段类型
-
集群内数据迁移 / 跨集群的数据迁移
DELETE blogs_fix
# 创建新的索引并且设定新的Mapping
PUT blogs_fix/
{
"mappings": {
"properties": {
"content": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
},
"keyword": {
"type": "keyword"
}
}
}
}
把blongs索引的数据迁移到blogs_fix上去
POST _reindex
{
"source": {
"index": "blogs"
},
"dest": {
"index": "blogs_fix"
}
}
测试 Term Aggregation text不支持聚合,keyword支持
GET blogs_fix/_doc/1
#
POST blogs_fix/_search
{
"size": 0,
"aggs": {
"blog_keyword": {
"terms": {
"field": "keyword",
"size": 10
}
}
}
}

OP Type
-
_reindex 只会创建不存在的⽂档
-
⽂档如果已经存在,会导致版本冲突
POST _reindex
{
"source": {
"index": "blogs"
},
"dest": {
"index": "blogs_fix",
"op_type": "create"
}
}
跨集群 ReIndex

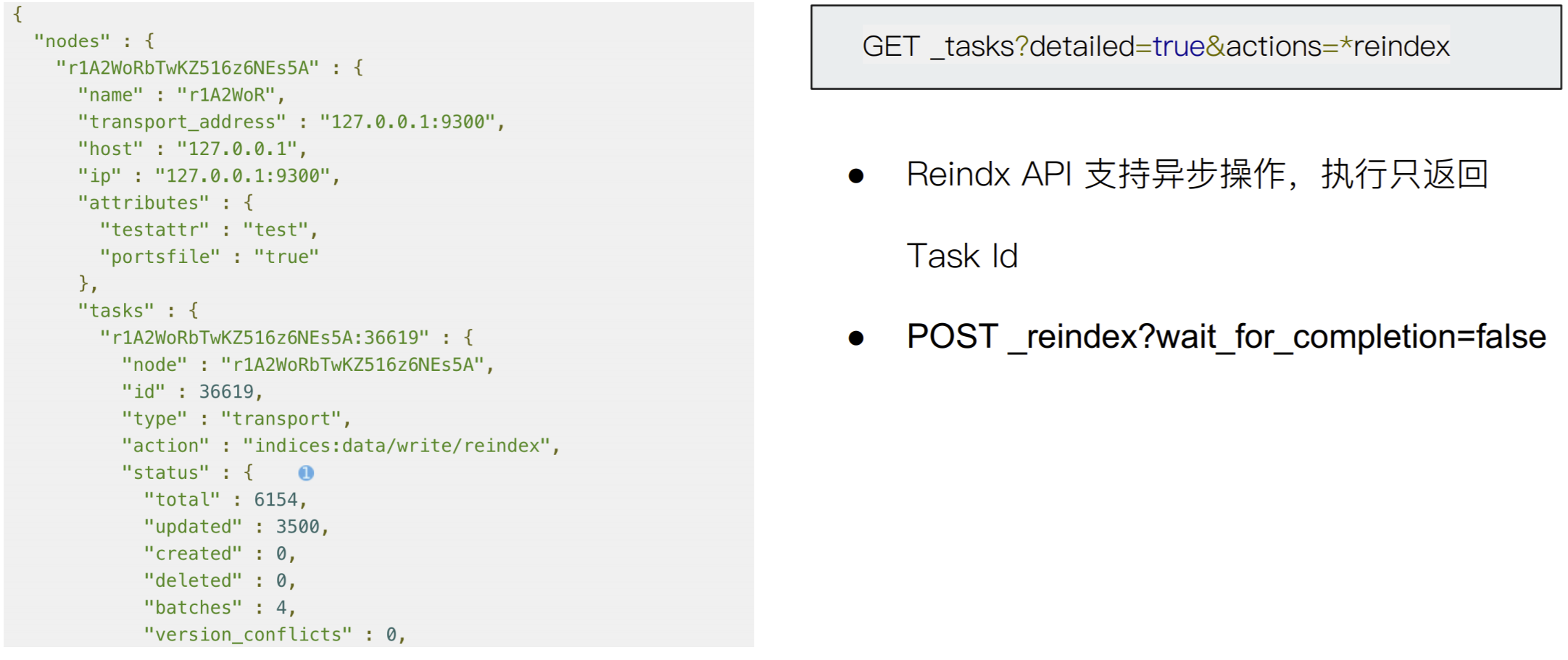
查看 Task API
相关阅读
Ingest Pipeline 与 Painless Script
需求:修复与增强写⼊的数据
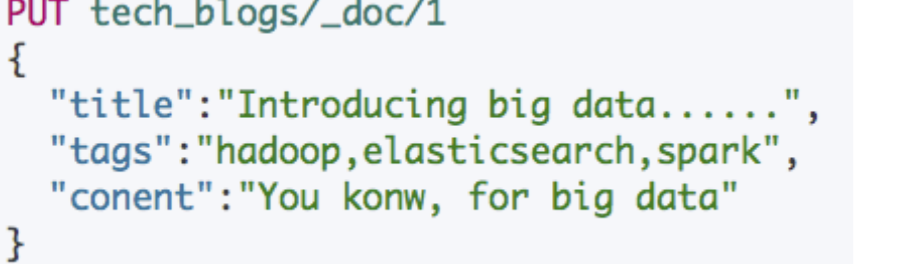
Tags 字段中,逗号分隔的⽂本应该是数组,⽽不是⼀ 个字符串
需求:后期需要对 Tags 进⾏ Aggregation 统计
Ingest Node
Elasticsearch 5.0 后,引⼊的⼀种新的节点类型。默认配置下,每个节点都是 Ingest Node
-
具有预处理数据的能⼒,可拦截 Index 或 Bulk API 的请求
-
对数据进⾏转换,并重新返回给 Index 或 Bulk API
⽆需 Logstash,就可以进⾏数据的预处理,例如
-
为某个字段设置默认值;重命名某个字段的字段名;对字段值进⾏ Split 操作
-
⽀持设置 Painless 脚本,对数据进⾏更加复杂的加⼯
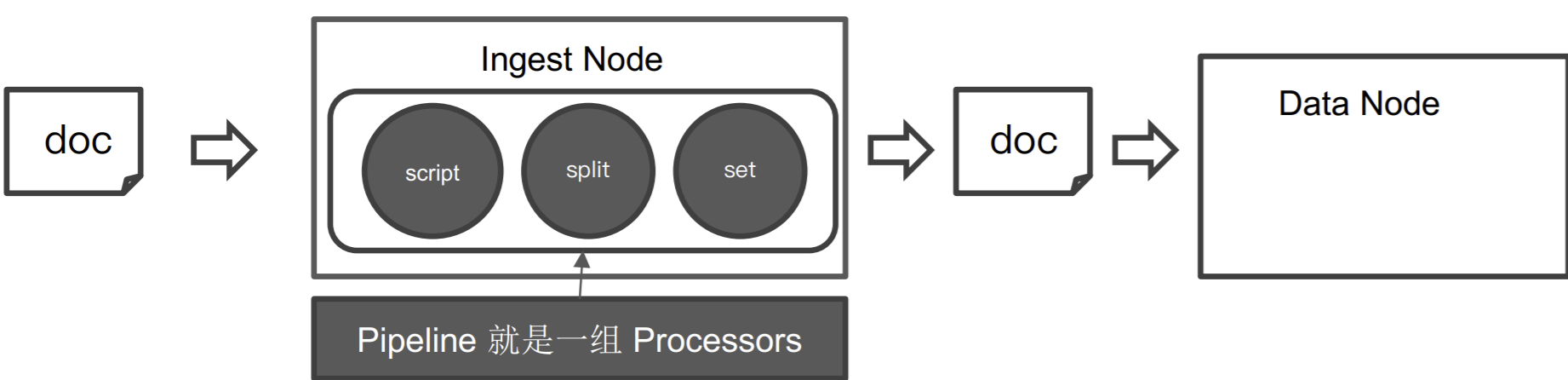
Pipeline & Processor
Pipeline - 管道会对通过的数据(⽂档),按照顺序进⾏加⼯
Processor - Elasticsearch 对⼀些加⼯的⾏为进⾏了抽象包装
- Elasticsearch 有很多内置的 Processors。也⽀持通过插件的⽅式,实现⾃⼰的 Processor
使⽤ Pipeline 切分字符串

POST _ingest/pipeline/_simulate { "pipeline": { "description": "to split blog tags", "processors": [ { "split": { "field": "tags", "separator": "," } } ] }, "docs": [ { "_index": "index", "_id": "id", "_source": { "title": "Introducing big data......", "tags": "hadoop,elasticsearch,spark", "content": "You konw, for big data" } }, { "_index": "index", "_id": "idxx", "_source": { "title": "Introducing cloud computering", "tags": "openstack,k8s", "content": "You konw, for cloud" } } ] }
为⽂档增加字段
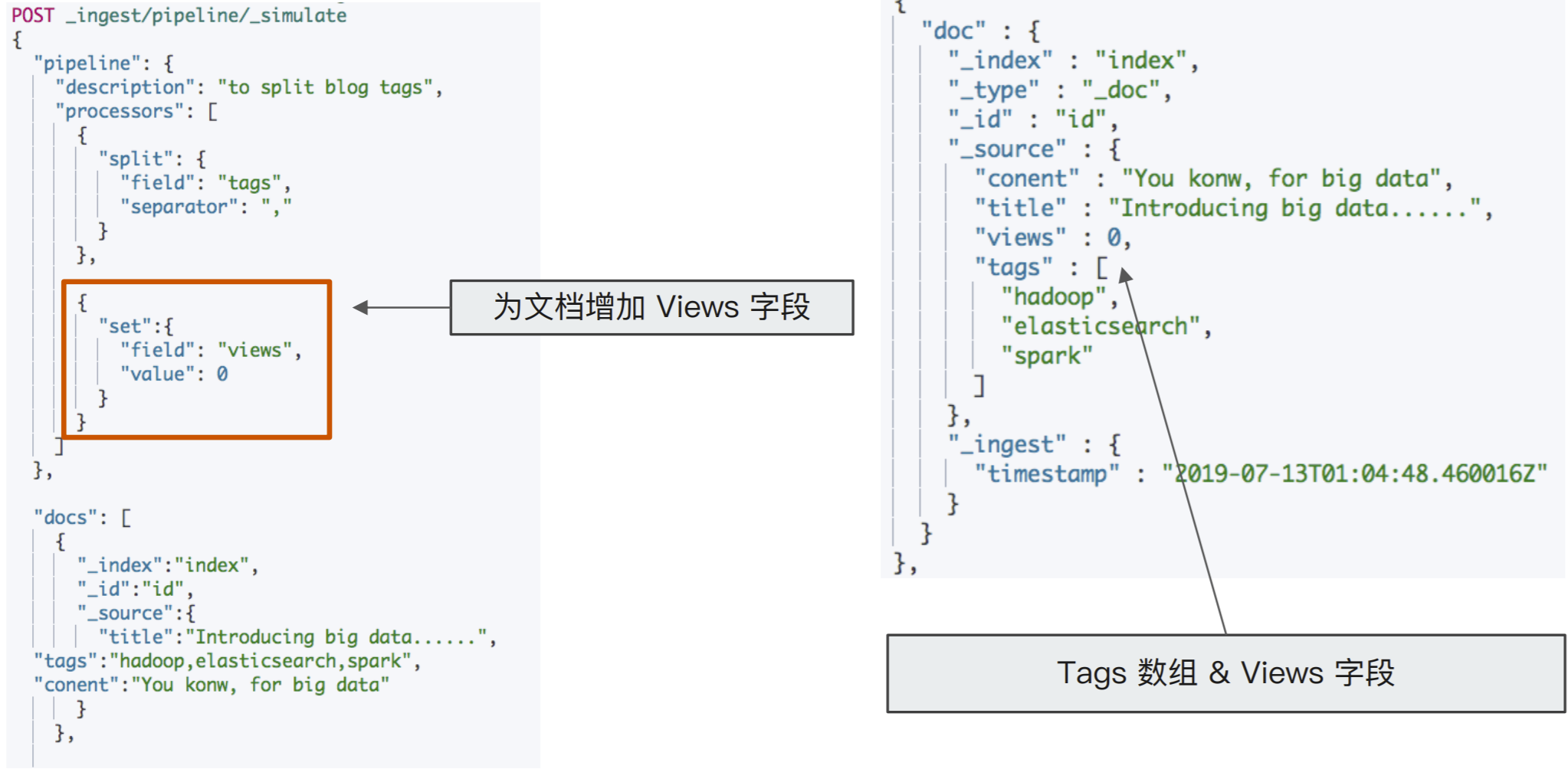
#同时为文档,增加一个字段。blog查看量 POST _ingest/pipeline/_simulate { "pipeline": { "description": "to split blog tags", "processors": [ { "split": { "field": "tags", "separator": "," } }, { "set": { "field": "views", "value": 0 } } ] }, "docs": [ { "_index": "index", "_id": "id", "_source": { "title": "Introducing big data......", "tags": "hadoop,elasticsearch,spark", "content": "You konw, for big data" } }, { "_index": "index", "_id": "idxx", "_source": { "title": "Introducing cloud computering", "tags": "openstack,k8s", "content": "You konw, for cloud" } } ] }
Pipeline API

数据准备
DELETE tech_blogs #Blog数据,包含3个字段,tags用逗号间隔 PUT tech_blogs/_doc/1 { "title": "Introducing big data......", "tags": "hadoop,elasticsearch,spark", "content": "You konw, for big data" }
添加blog_pipeline Pipeline
PUT _ingest/pipeline/blog_pipeline { "description": "a blog pipeline", "processors": [ { "split": { "field": "tags", "separator": "," } }, { "set": { "field": "views", "value": 0 } } ] } #查看Pipleline GET _ingest/pipeline/blog_pipeline
测试 blog_pipeline pipeline
POST _ingest/pipeline/blog_pipeline/_simulate
{
"docs": [
{
"_source": {
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
}
]
}
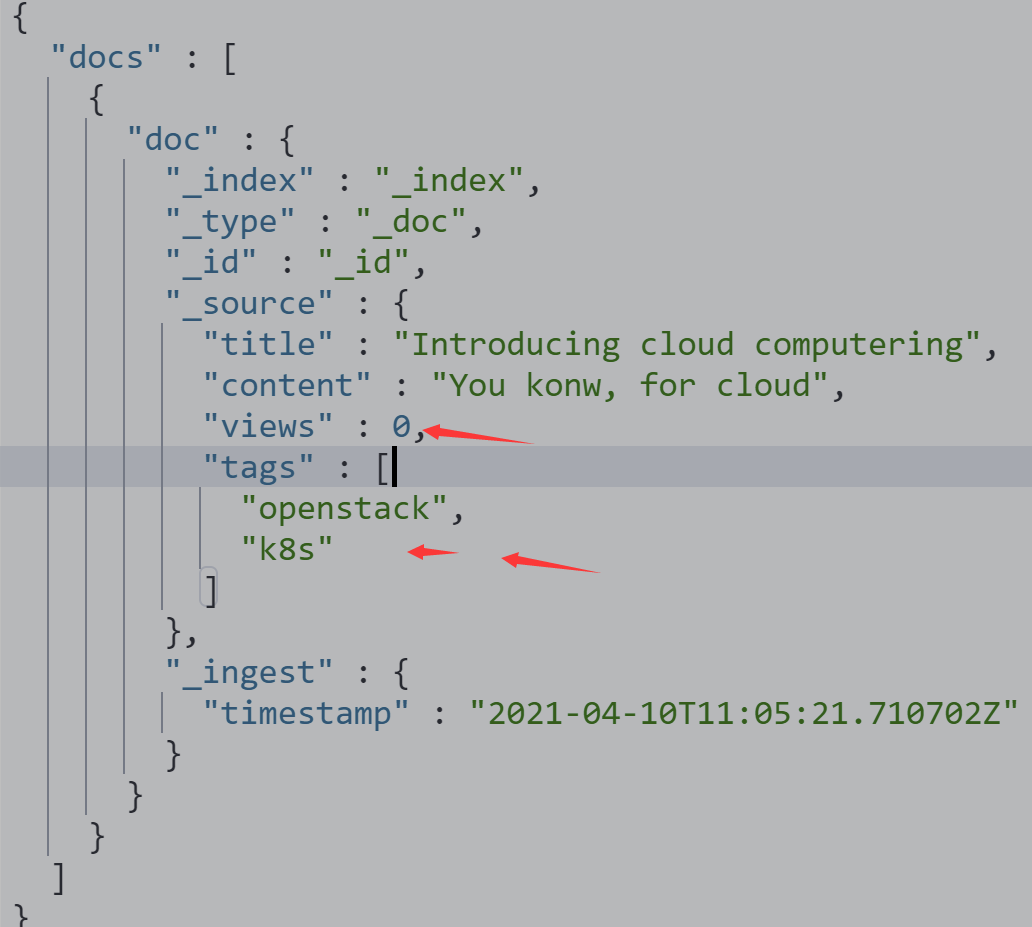
更新数据
#不使用pipeline更新数据
PUT tech_blogs/_doc/1
{
"title": "Introducing big data......",
"tags": "hadoop,elasticsearch,spark",
"content": "You konw, for big data"
}
#使用pipeline更新数据
PUT tech_blogs/_doc/2?pipeline=blog_pipeline
{
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
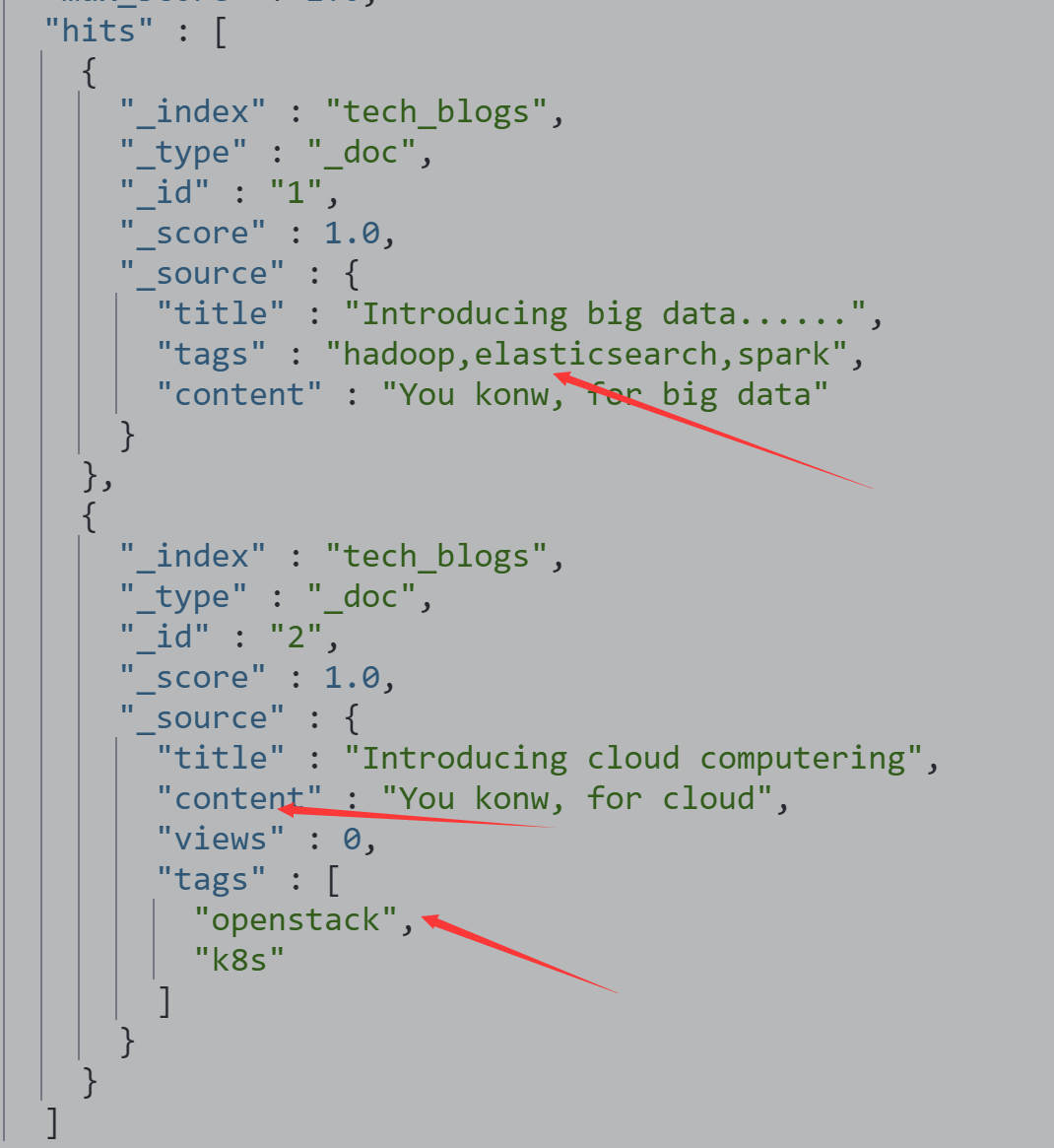
查看两条数据,一条被处理,一条未被处理
POST tech_blogs/_search
{}
对已有的数据根据pipeline重建索引,会报错
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{}
增加update_by_query的条件
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "views"
}
}
}
}
}
查看两条数据,都被pipeline处理
POST tech_blogs/_search
{}
⼀些内置 Processors
- https://www.elastic.co/guide/en/elasticsearch/reference/7.1/ingest-processors.html
-
Split Processor (例:将给定字段值分成⼀个数组)
-
Remove / Rename Processor (例:移除⼀个重命名字段)
-
Append (例:为商品增加⼀个新的标签)
-
Convert(例:将商品价格,从字符串转换成 float 类型)
-
Date / JSON(例:⽇期格式转换,字符串转 JSON 对象)
-
Date Index Name Processor (例:将通过该处理器的⽂档,分配到指定时间格式的索引中)
-
Fail Processor (⼀旦出现异常,该 Pipeline 指定的错误信息能返回给⽤户)
-
Foreach Process(数组字段,数组的每个元素都会使⽤到⼀个相同的处理器)
-
Grok Processor(⽇志的⽇期格式切割)
-
Gsub / Join / Split(字符串替换 / 数组转字符串/ 字符串转数组)
-
Lowercase / Upcase(⼤⼩写转换)
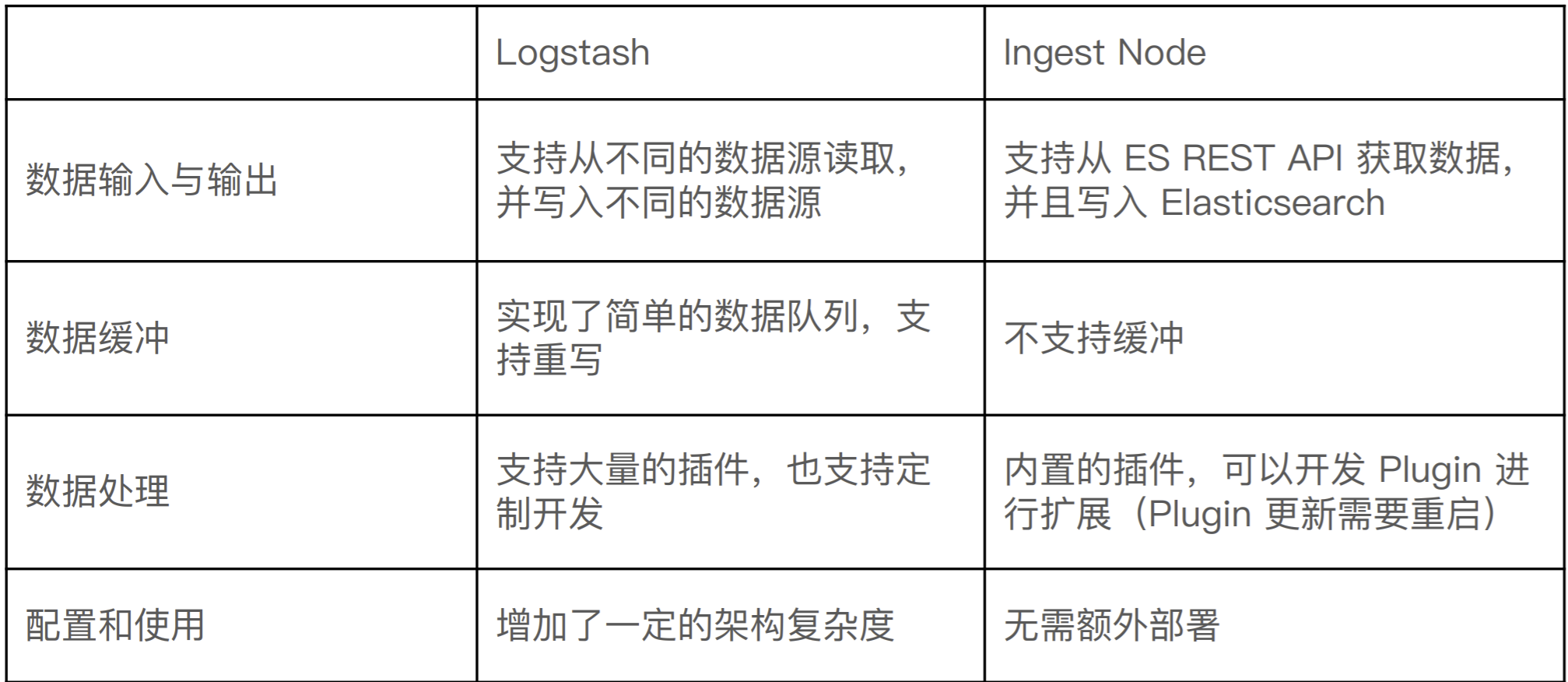
Ingest Node v.s Logstash
- https://www.elastic.co/cn/blog/should-i-use-logstash-or-elasticsearch-ingest-nodes
Painless 简介
⾃ Elasticsearch 5.x 后引⼊,专⻔为 Elasticsearch 设计,扩展了 Java 的语法。
6.0 开始,ES 只⽀持 Painless。Groovy, JavaScript 和 Python 都不再⽀持
Painless ⽀持所有 Java 的数据类型及 Java API ⼦集
Painless Script 具备以下特性
-
⾼性能 / 安全
-
⽀持显示类型或者动态定义类型
Painless 的⽤途
可以对⽂档字段进⾏加⼯处理
-
更新或删除字段,处理数据聚合操作
-
Script Field:对返回的字段提前进⾏计算
-
Function Score:对⽂档的算分进⾏处理
在 Ingest Pipeline 中执⾏脚本
在 Reindex API,Update By Query 时,对数据进⾏处理
通过 Painless 脚本访问字段
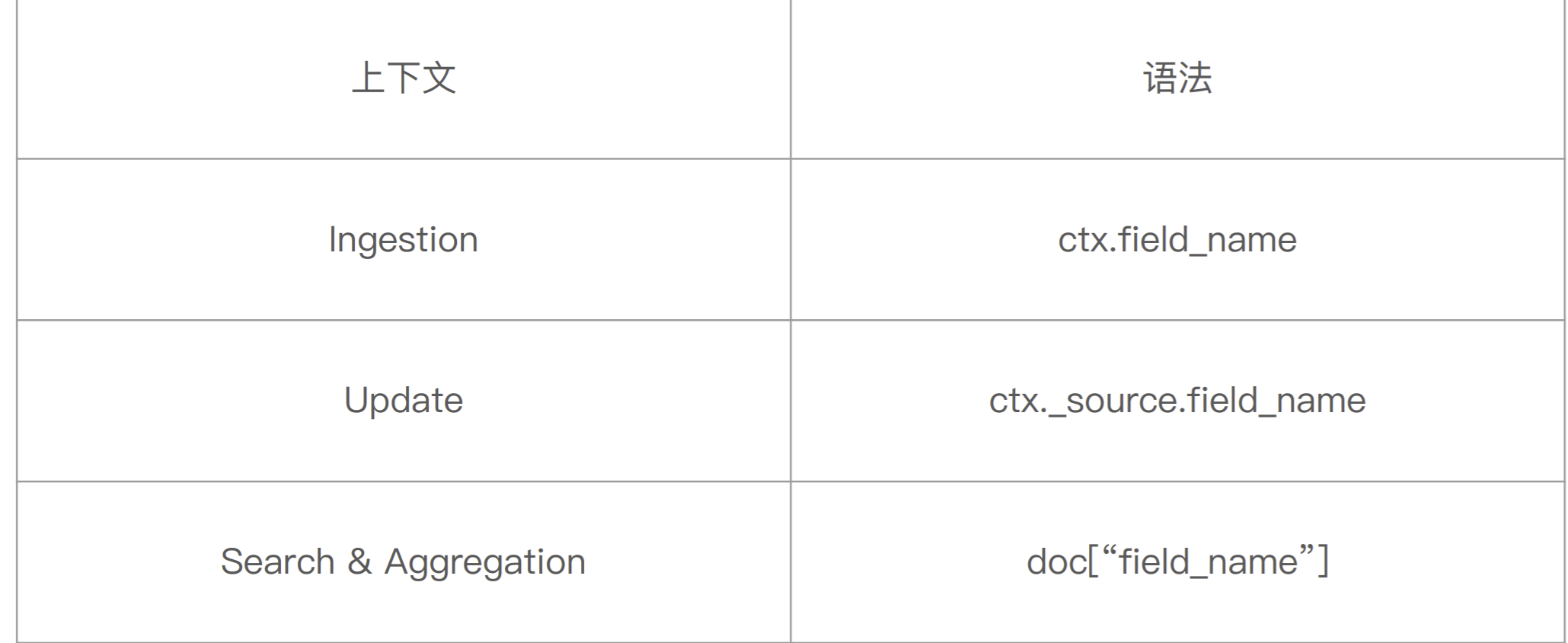
案例 1:Script Processor
POST _ingest/pipeline/_simulate { "pipeline": { "description": "to split blog tags", "processors": [ { "split": { "field": "tags", "separator": "," } }, { "script": { "source": """ if(ctx.containsKey("content")){ ctx.content_length = ctx.content.length(); }else{ ctx.content_length=0; } """ } }, { "set": { "field": "views", "value": 0 } } ] }, "docs": [ { "_index": "index", "_id": "id", "_source": { "title": "Introducing big data......", "tags": "hadoop,elasticsearch,spark", "content": "You konw, for big data" } }, { "_index": "index", "_id": "idxx", "_source": { "title": "Introducing cloud computering", "tags": "openstack,k8s", "content": "You konw, for cloud" } } ] }
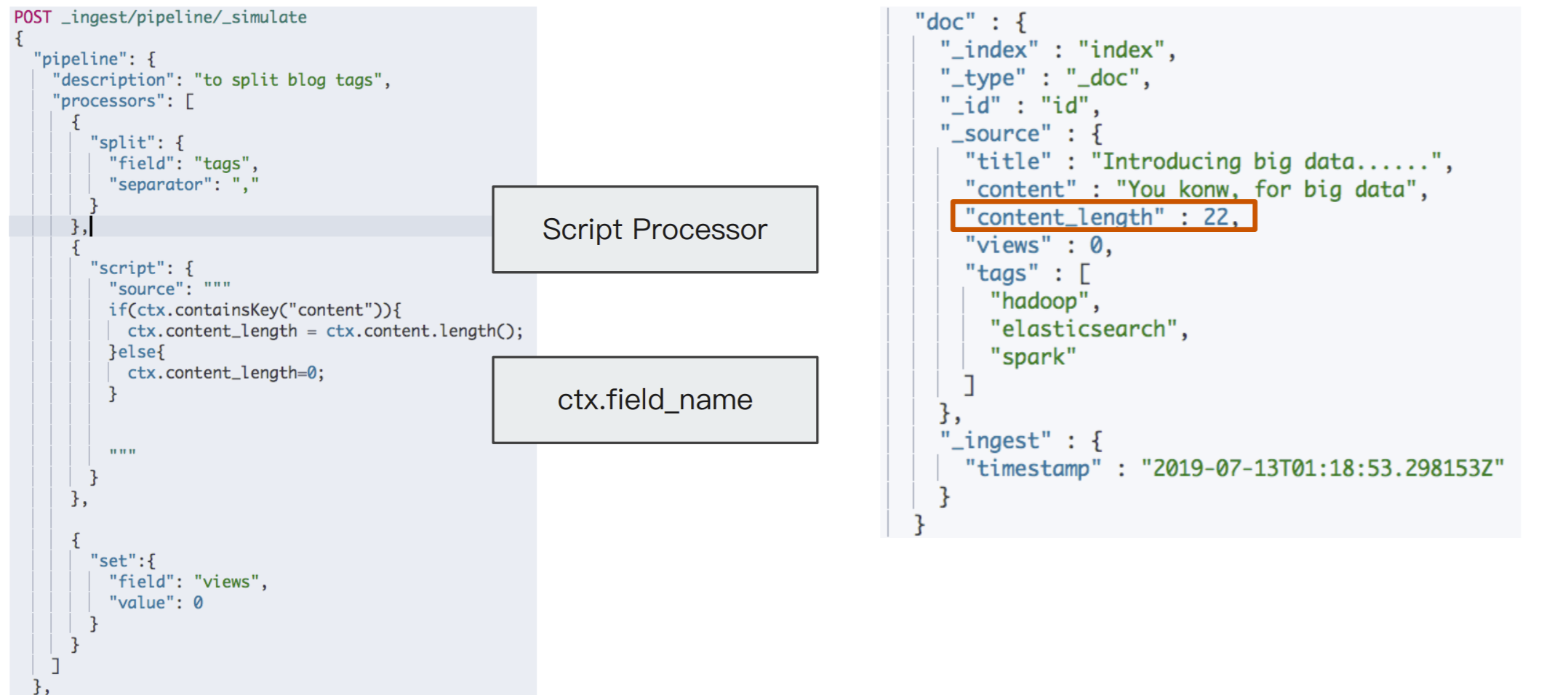
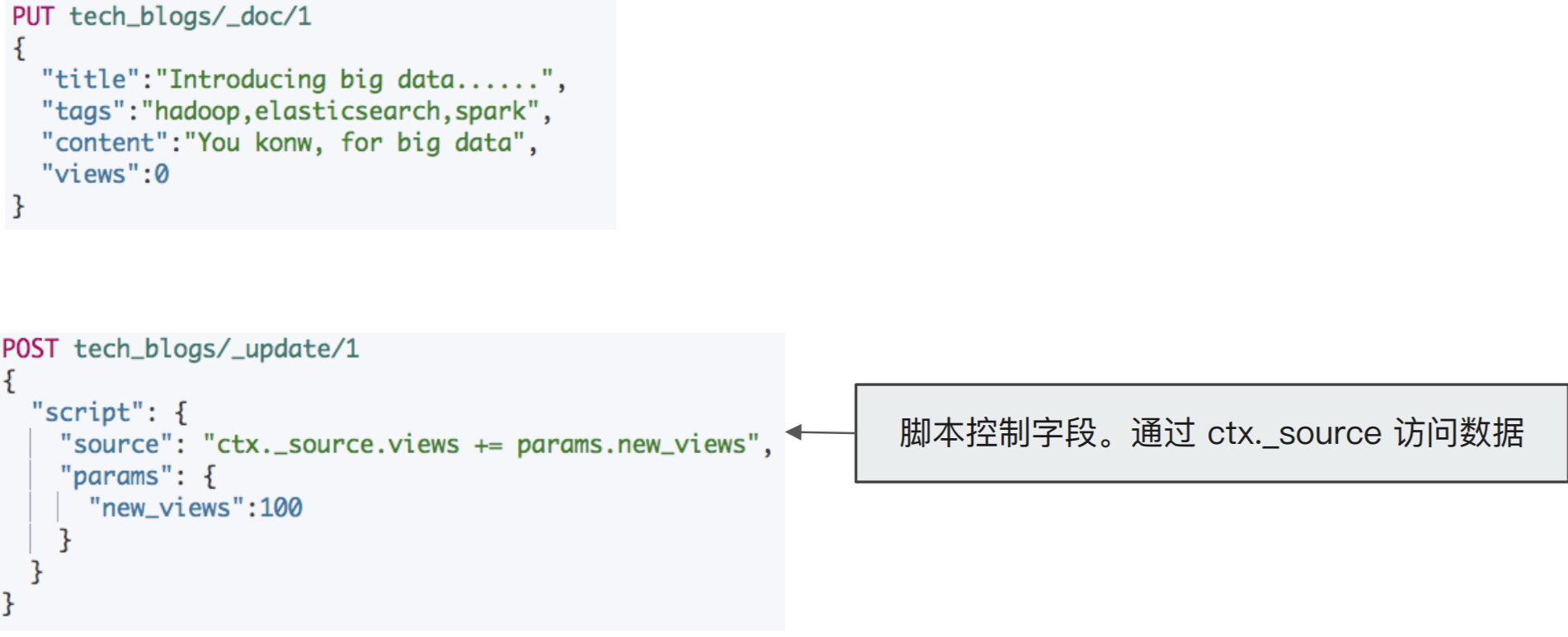
案例 2:⽂档更新计数
DELETE tech_blogs PUT tech_blogs/_doc/1 { "title": "Introducing big data......", "tags": "hadoop,elasticsearch,spark", "content": "You konw, for big data", "views": 0 } POST tech_blogs/_update/1 { "script": { "source": "ctx._source.views += params.new_views", "params": { "new_views": 100 } } } # 查看views计数 POST tech_blogs/_search {}
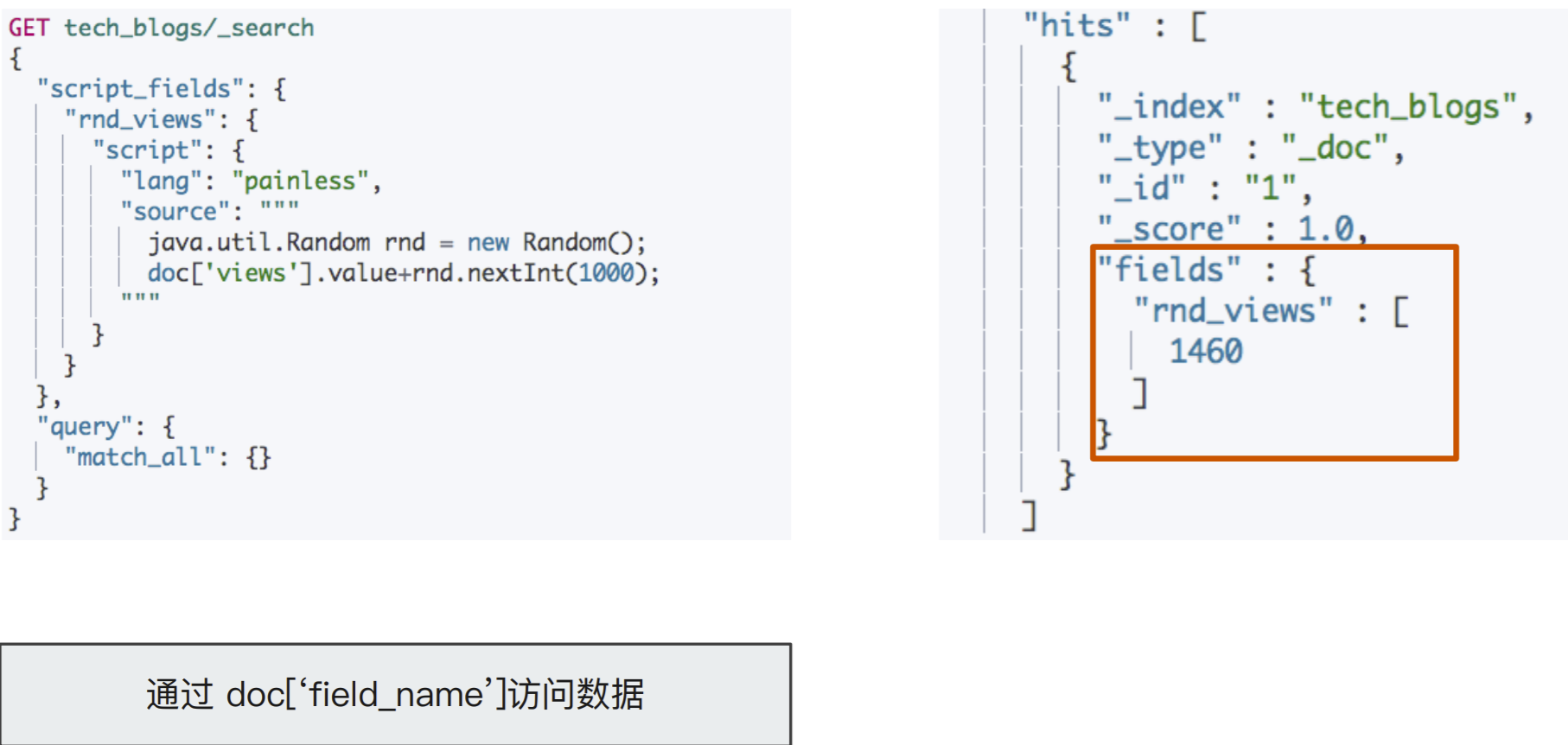
案例 3:搜索时的 Script 字段
GET tech_blogs/_search { "script_fields": { "rnd_views": { "script": { "lang": "painless", "source": """ java.util.Random rnd = new Random(); doc['views'].value+rnd.nextInt(1000); """ } } }, "query": { "match_all": {} } }
保存脚本在 Cluster State
POST _scripts/update_views { "script": { "lang": "painless", "source": "ctx._source.views += params.new_views" } } POST tech_blogs/_update/1 { "script": { "id": "update_views", "params": { "new_views": 1000 } } }
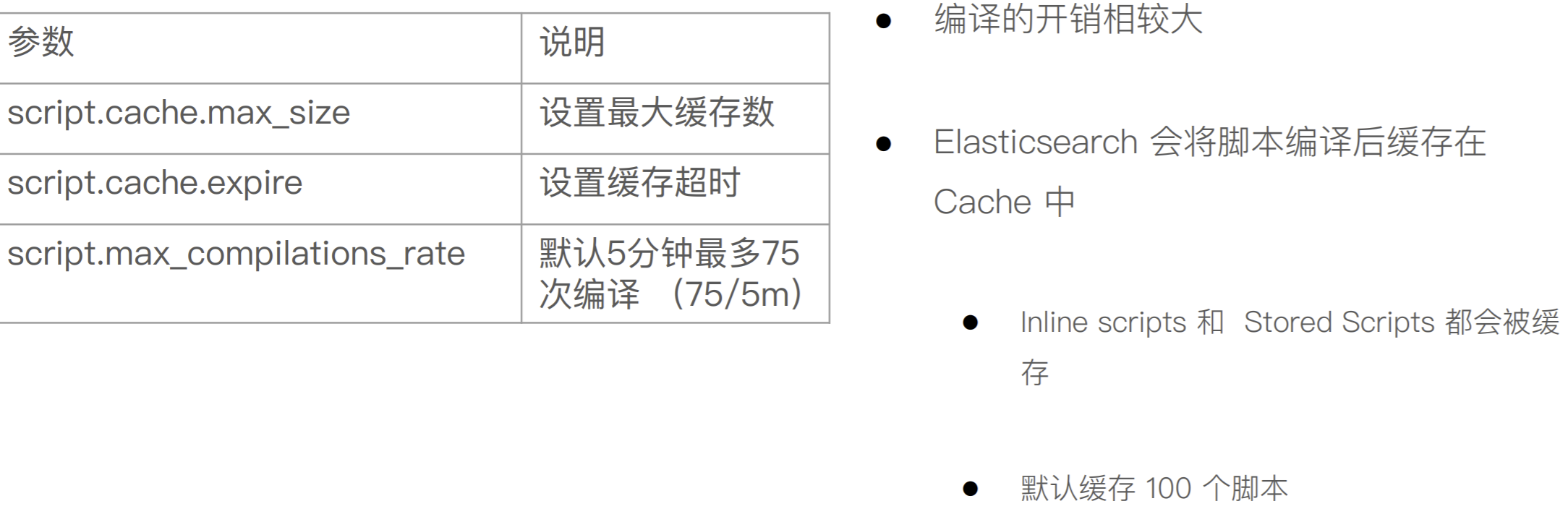
脚本缓存
相关阅读
-
https://www.elastic.co/cn/blog/should-i-use-logstash-or-elasticsearch-ingest-nodes
-
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/ingest-apis.html
-
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/ingest-processors.html
-
https://www.elastic.co/guide/en/elasticsearch/painless/7.1/painless-lang-spec.html
-
https://www.elastic.co/guide/en/elasticsearch/painless/7.1/painless-api-reference.html
Elasticsearch 数据建模实例
什么是数据建模?
数据建模(Data modeling), 是创建数据模型的过程
- 数据模型是对真实世界进⾏抽象描述的⼀种⼯具和⽅法,实现对现实世界的映射,博客 / 作者 / ⽤户评论
三个过程:概念模型 => 逻辑模型 => 数据模型(第三范式)
- 数据模型:结合具体的数据库,在满⾜业务读写性能等需求的前提下,确定最终的定义
数据建模:功能需求 + 性能需求
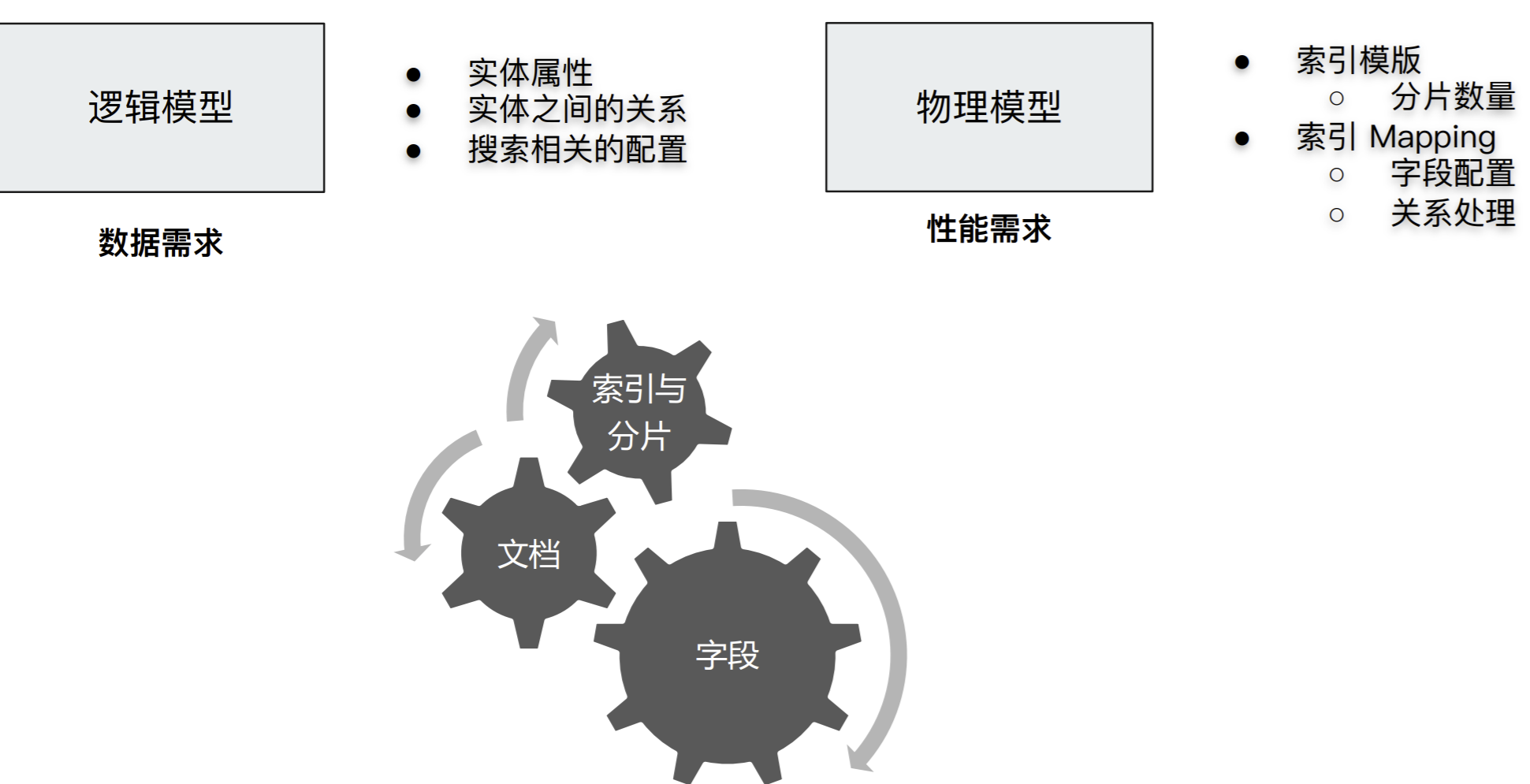
如何对字段进⾏建模

字段类型:Text v.s Keyword
Text
-
⽤于全⽂本字段,⽂本会被 Analyzer 分词
-
默认不⽀持聚合分析及排序。需要设置 fielddata 为 true
Keyword
-
⽤于 id,枚举及不需要分词的⽂本。例如电话号码,email地址,⼿机号码,邮政编码,性别等
-
适⽤于 Filter(精确匹配),Sorting 和 Aggregations
设置多字段类型
-
默认会为⽂本类型设置成 text,并且设置⼀个 keyword 的⼦字段
-
在处理⼈类语⾔时,通过增加“英⽂”,“拼⾳”和“标准”分词器,提⾼搜索结构
字段类型 :结构化数据
数值类型
- 尽量选择贴近的类型。例如可以⽤ byte,就不要⽤ long
枚举类型
- 设置为 keyword。即便是数字,也应该设置成 keyword,获取更加好的性能
其他
- ⽇期 / 布尔 / 地理信息
检索
如不需要检索,排序和聚合分析
- Enable 设置成 false
如不需要检索
- Index 设置成 false
对需要检索的字段,可以通过如下配置,设定存储粒度
- Index_options / Norms :不需要归⼀化数据时,可以关闭
聚合及排序
如不需要检索,排序和聚合分析
- Enable 设置成 false
如不需要排序或者聚合分析功能
- Doc_values / fielddata 设置成 false
更新频繁,聚合查询频繁的 keyword 类型的字段
- 推荐将 eager_global_ordinals 设置为 true
额外的存储
是否需要专⻔存储当前字段数据
-
Store 设置成 true,可以存储该字段的原始内容
-
⼀般结合 _source 的 enabled 为 false 时候使⽤
Disable _source:节约磁盘;适⽤于指标型数据
-
⼀般建议先考虑增加压缩⽐
-
⽆法看到 _source字段,⽆法做 ReIndex,⽆法做 Update
-
Kibana 中⽆法做 discovery
⼀个数据建模的实例

优化字段设定

# Index 一本书的信息 PUT books/_doc/1 { "title":"Mastering ElasticSearch 5.0", "description":"Master the searching, indexing, and aggregation features in ElasticSearch Improve users’ search experience with Elasticsearch’s functionalities and develop your own Elasticsearch plugins", "author":"Bharvi Dixit", "public_date":"2017", "cover_url":"https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg" } #查询自动创建的Mapping GET books/_mapping DELETE books #优化字段类型 PUT books { "mappings" : { "properties" : { "author" : {"type" : "keyword"}, "cover_url" : {"type" : "keyword","index": false}, "description" : {"type" : "text"}, "public_date" : {"type" : "date"}, "title" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 100 } } } } } } #Cover URL index 设置成false,无法对该字段进行搜索 POST books/_search { "query": { "term": { "cover_url": { "value": "https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg" } } } } #Cover URL index 设置成false,依然支持聚合分析 POST books/_search { "aggs": { "cover": { "terms": { "field": "cover_url", "size": 10 } } } }
需求变更

查询图书:解决字段过⼤引发的性能问题
-
返回结果不包含 _source 字段
-
对于需要显示的信息,可以在在查询中指定 “stored_fields"
-
禁⽌ _source 字段后,还是⽀持使⽤ highlights API,⾼亮显示 content 中匹配的相关信息
DELETE books #新增 Content字段。数据量很大。选择将Source 关闭 PUT books { "mappings": { "_source": { "enabled": false }, "properties": { "author": { "type": "keyword", "store": true }, "cover_url": { "type": "keyword", "index": false, "store": true }, "description": { "type": "text", "store": true }, "content": { "type": "text", "store": true }, "public_date": { "type": "date", "store": true }, "title": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 100 } }, "store": true } } } } # Index 一本书的信息,包含Content PUT books/_doc/1 { "title": "Mastering ElasticSearch 5.0", "description": "Master the searching, indexing, and aggregation features in ElasticSearch Improve users’ search experience with Elasticsearch’s functionalities and develop your own Elasticsearch plugins", "content": "The content of the book......Indexing data, aggregation, searching. something else. something in the way............", "author": "Bharvi Dixit", "public_date": "2017", "cover_url": "https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg" } #查询结果中,Source不包含数据 POST books/_search {} #搜索,通过store 字段显示数据,同时高亮显示 conent的内容 POST books/_search { "stored_fields": ["title","author","public_date"], "query": { "match": { "content": "searching" } }, "highlight": { "fields": { "content":{} } } }
Mapping 字段的相关设置
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
-
Enabled – 设置成 false,仅做存储,不⽀持搜索和聚合分析 (数据保存在 _source 中)
-
Index – 是否构倒排索引。设置成 false,⽆法被搜索,但还是⽀持 aggregation,并出现在 _source 中
-
Norms – 如果字段⽤来过滤和聚合分析,可以关闭,节约存储
-
Doc_values – 是否启⽤ doc_values,⽤于排序和聚合分析
-
Field_data – 如果要对 text 类型启⽤排序和聚合分析, fielddata 需要设置成true
-
Store – 默认不存储,数据默认存储在 _source。
-
Coerce – 默认开启,是否开启数据类型的⾃动转换(例如,字符串转数字)
-
Multifields 多字段特性
-
Dynamic – true / false / strict 控制 Mapping 的⾃动更新
脚本更新字段
POST legislation/_update_by_query
{
"track_total_hits": true,
"query": {
"term": {
"source_type": {
"value": "migrate"
}
}
},
"script": {
"source": "ctx._source.norm_citation = ctx._source.enactment_citation"
}
}
修改 es 中的id
POST _reindex
{
"source": {
"index": "legislation_clean_dev"
},
"dest": {
"index": "legislation_clean_dev_test"
},
"script": {
"inline": "ctx._id= ctx._source['object_id']",
"lang": "painless"
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号