elasticsearch — 分布式特性及分布式搜索的机制
维护并且更新 Cluster State 集群分布式模型及选主与脑裂问题
分布式特性
● Elasticsearch 的分布式架构带来的好处
-
存储的⽔平扩容,⽀持 PB 级数据
-
提⾼系统的可⽤性,部分节点停⽌服务,整个集群的服务不受影响
● Elasticsearch 的分布式架构
-
不同的集群通过不同的名字来区分,默认名字 “elasticsearch”
-
通过配置⽂件修改,或者在命令⾏中 -E cluster.name=geektime 进⾏设定
节点
节点是⼀个 Elasticsearch 的实例
-
其本质上就是⼀个 JAVA 进程
-
⼀台机器上可以运⾏多个 Elasticsearch 进程,但是⽣产环境⼀般建议⼀台机器上就 运⾏⼀个 Elasticsearch 实例
每⼀个节点都有名字,通过配置⽂件配置,或者启动时候 -E node.name=geektime 指定
每⼀个节点在启动之后,会分配⼀个 UID,保存在 data ⽬录下
Coordinating Node (协调节点)
处理请求的节点,叫 Coordinating Node
- 路由请求到正确的节点,例如创建索引的请求,需要路由到 Master 节点
所有节点默认都是 Coordinating Node
通过将其他类型设置成 False,使其成为 Dedicated Coordinating Node
Demo – 启动节点,Cerebro 介绍
命令行方式启动集群
bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -E http.port=9200 -E network.host=0.0.0.0 -E node.master=true bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -E http.port=9201 -E network.host=0.0.0.0 -E node.master=true bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -E http.port=9202 -E network.host=0.0.0.0 -E node.master=true
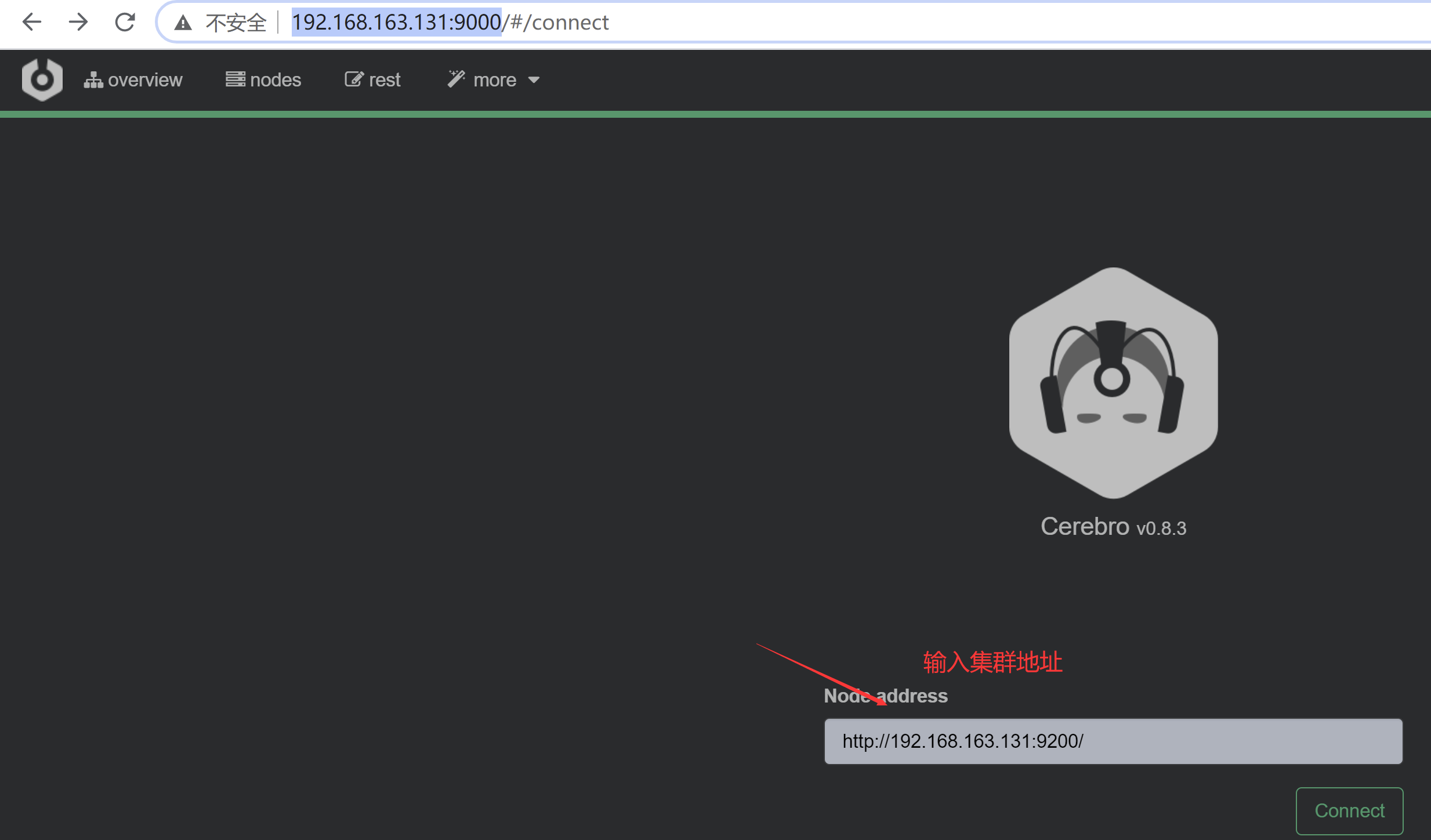
Cerebro 下载地址
- https://github.com/lmenezes/cerebro/releases
访问cerobro
- http://192.168.163.131:9000/
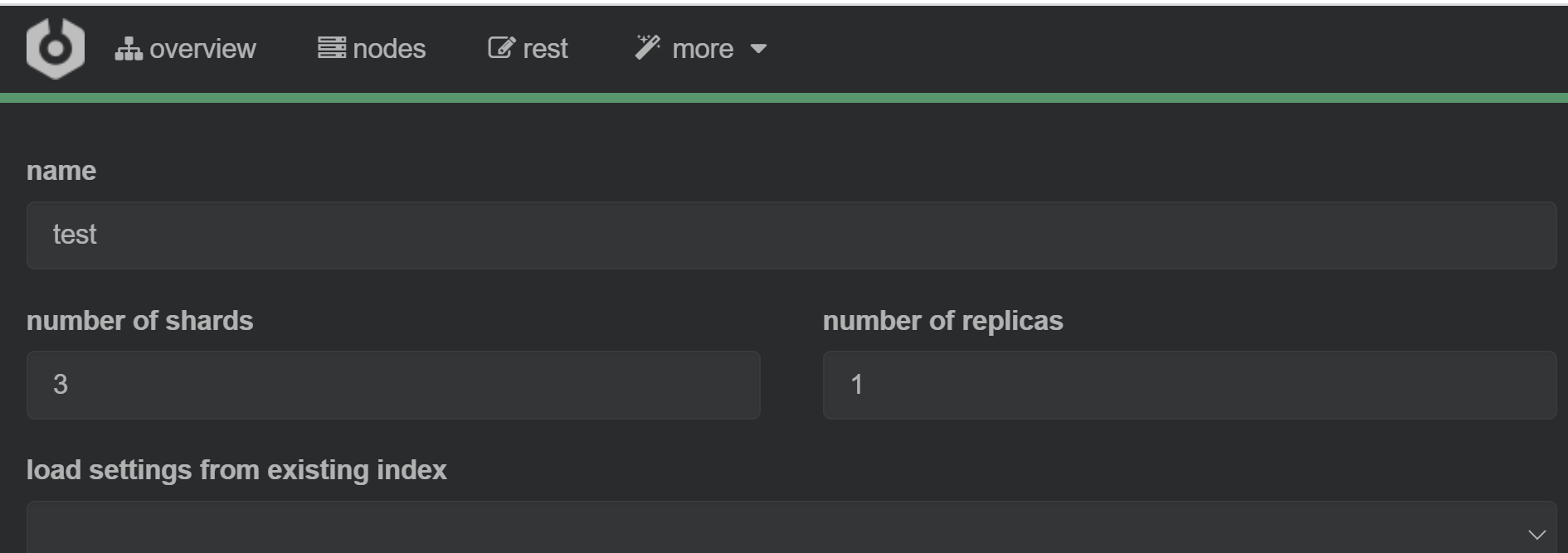
创建索引 test 分片数设置3 副本数设置为1
Data Node
可以保存数据的节点,叫做 Data Node
- 节点启动后,默认就是数据节点。可以设置 node.data: false 禁⽌
Data Node的职责
- 保存分⽚数据。在数据扩展上起到了⾄关重要的作⽤(由 Master Node 决定如何把 分⽚分 发到数据节点上)
通过增加数据节点
- 可以解决数据⽔平扩展和解决数据单点问题
Master Node
Master Node 的职责
-
处理创建,删除索引等请求 /决定分⽚被分配到哪个节点 / 负责索引的创建与删除
-
维护并且更新 Cluster State
Master Node 的最佳实践
-
Master 节点⾮常重要,在部署上需要考虑解决单点的问题
-
为⼀个集群设置多个 Master 节点 / 每个节点只承担 Master 的单⼀⻆⾊
Master Eligible Nodes & 选主流程
⼀个集群,⽀持配置多个 Master Eligible 节点。这些节点可以在必要时(如 Master 节点出 现故障,⽹络故障时)参与选主流程,成为 Master 节点
每个节点启动后,默认就是⼀个 Master eligible 节点
- 可以设置 node.master: false 禁⽌
当集群内第⼀个 Master eligible 节点启动时候,它会将⾃⼰选举成 Master 节点
集群状态
集群状态信息(Cluster State),维护了⼀个集群中,必要的信息
-
○ 所有的节点信息
-
○ 所有的索引和其相关的 Mapping 与 Setting 信息
-
○ 分⽚的路由信息
在每个节点上都保存了集群的状态信息
但是,只有 Master 节点才能修改集群的状态信息,并负责同步给其他节点,因为,任意节点都能修改信息会导致 Cluster State 信息的不⼀致
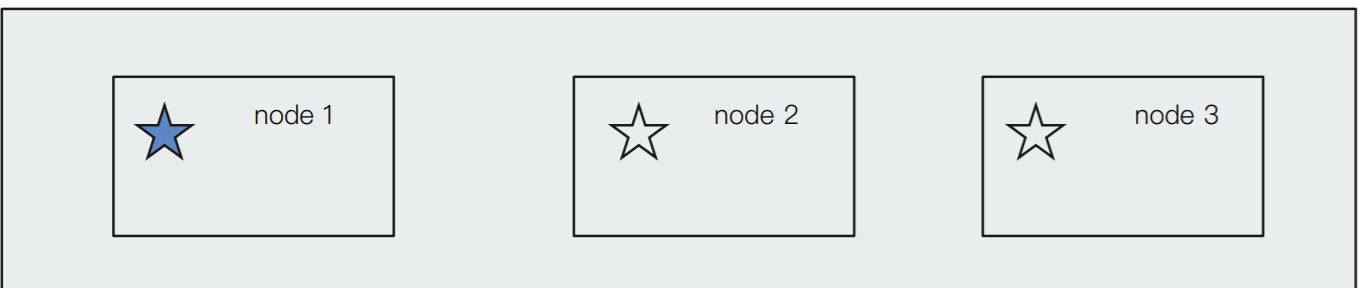
Master Eligible Nodes & 选主的过程
● 互相 Ping 对⽅,Node Id 低的会成为被选举的节点
● 其他节点会加⼊集群,但是不承担 Master 节点的⻆⾊。⼀旦发现被选中的主节点丢失, 就会选举出新的 Master 节点
脑裂问题
Split-Brain,分布式系统的经典⽹络问题,当出现⽹络问题,⼀个节点和其他节点⽆法连接
-
Node 2 和 Node 3 会重新选举 Master
-
Node 1 ⾃⼰还是作为 Master,组成⼀个集群,同时更新 Cluster State
-
导致 2 个 master,维护不同的 cluster state。当⽹络恢复时,⽆法选择正确恢复 node 1 node 2 node 3 ⽹络断开

如何避免脑裂问题
限定⼀个选举条件,设置 quorum(仲裁),只有在 Master eligible 节点数⼤于 quorum 时,才能 进⾏选举
-
Quorum = (master 节点总数 /2)+ 1
-
当 3 个 master eligible 时,设置 discovery.zen.minimum_master_nodes 为 2,即可避免脑裂
从 7.0 开始,⽆需这个配置
-
移除 minimum_master_nodes 参数,让Elasticsearch⾃⼰选择可以形成仲裁的节点
-
典型的主节点选举现在只需要很短的时间就可以完成。集群的伸缩变得更安全、更容易,并且可能造成丢 失数据的系统配置选项更少了
-
节点更清楚地记录它们的状态,有助于诊断为什么它们不能加⼊集群或为什么⽆法选举出主节点
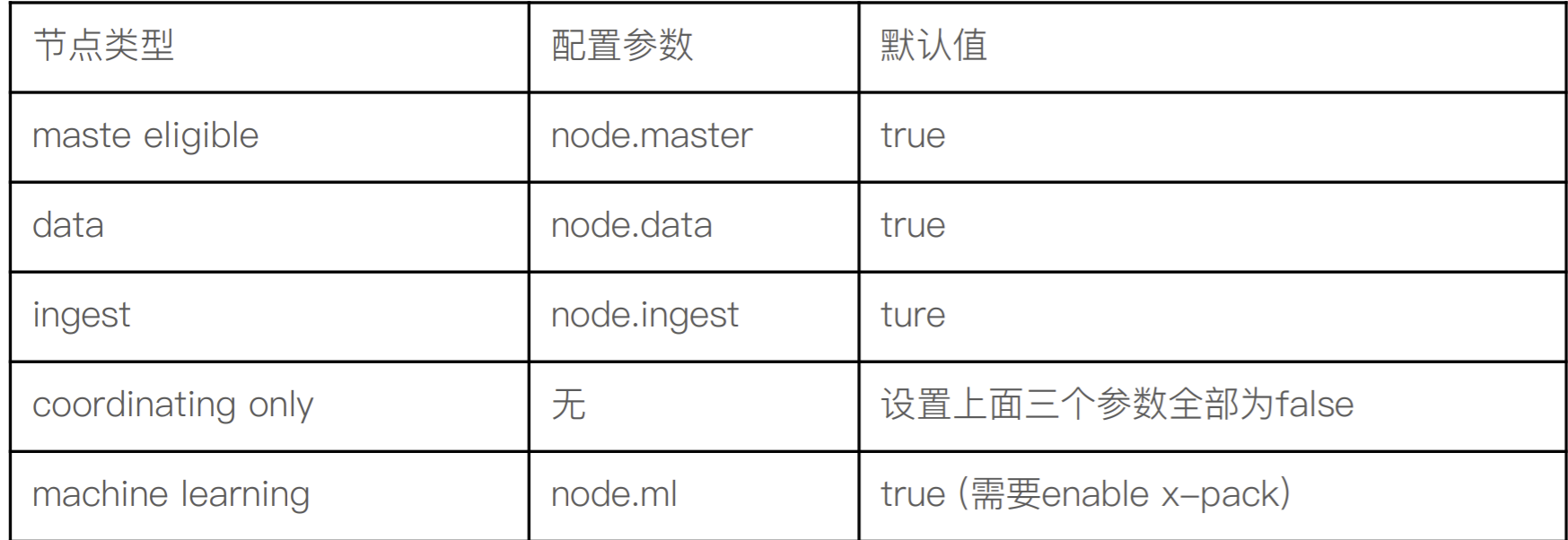
配置节点类型
⼀个节点默认情况下是⼀个 Master eligible,data and ingest node
分⽚与集群的故障转移
Primary Shard (主分片)- 提升系统存储容量
分⽚是 Elasticsearch 分布式存储的基⽯
- 主分⽚ / 副本分⽚
通过主分⽚,将数据分布在所有节点上
-
Primary Shard,可以将⼀份索引的数据,分散在多个 Data Node 上,实现存储的⽔平扩展
-
主分⽚(Primary Shard)数在索引创建时候指定,后续默认不能修改,如要修改,需重建索引
Replica Shard (副本分片)- 提⾼数据可⽤性
数据可⽤性
- 通过引⼊副本分⽚ (Replica Shard) 提⾼数据的可⽤性。⼀旦主分⽚丢失,副本分⽚可以 Promote 成主分 ⽚。副本分⽚数可以动态调整。每个节点上都有完备的数据。如果不设置副本分⽚,⼀旦出现节点硬件故 障,就有可能造成数据丢失
提升系统的读取性能
- 副本分⽚由主分⽚(Primary Shard)同步。通过⽀持增加 Replica 个数,⼀定程度可以提⾼读取的吞吐量
分⽚数的设定(默认一个主分片 0个副本分片)
如何规划⼀个索引的主分⽚数和副本分⽚数
-
主分⽚数过⼩:例如创建了 1 个 Primary Shard 的 Index,如果该索引增⻓很快,集群⽆法通过增加节点实现对这个索引的数据扩展
-
主分⽚数设置过⼤:导致单个 Shard 容量很⼩,引发⼀个节点上有过多分⽚,影响性能
-
副本分⽚数设置过多,会降低集群整体的写⼊性能
集群健康状态

⽂档分布式存储
⽂档存储在分⽚上
⽂档会存储在具体的某个主分⽚和副本分⽚上:例如 ⽂档 1, 会存储在 P0 和 R0 分⽚上
⽂档到分⽚的映射算法
-
确保⽂档能均匀分布在所⽤分⽚上,充分利⽤硬件资源,避免部分机器空闲,部分机器繁忙
-
潜在的算法
-
随机 / Round Robin。当查询⽂档 1,分⽚数很多,需要多次查询才可能查到 ⽂档
-
维护⽂档到分⽚的映射关系,当⽂档数据量⼤的时候,维护成本⾼
-
实时计算,通过⽂档 1,⾃动算出,需要去那个分⽚上获取⽂档
-
⽂档到分⽚的路由算法
shard = hash(_routing) % number_of_primary_shards
-
Hash 算法确保⽂档均匀分散到分⽚中
-
默认的 _routing 值是⽂档 id
-
可以⾃⾏制定 routing数值,例如⽤相同国家的商品,都分配到指定的 shard
-
设置 Index Settings 后, Primary 数,不能随意修改的根本原因
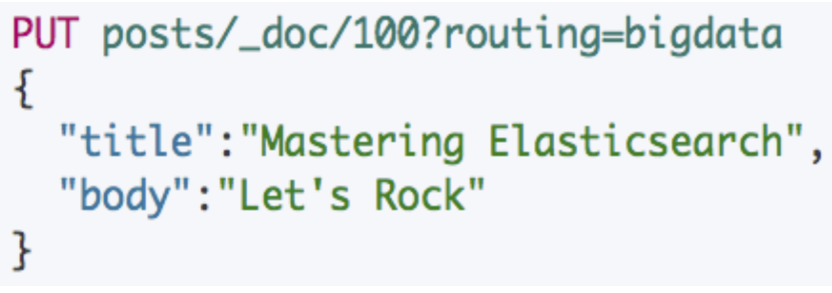
更新⼀个⽂档
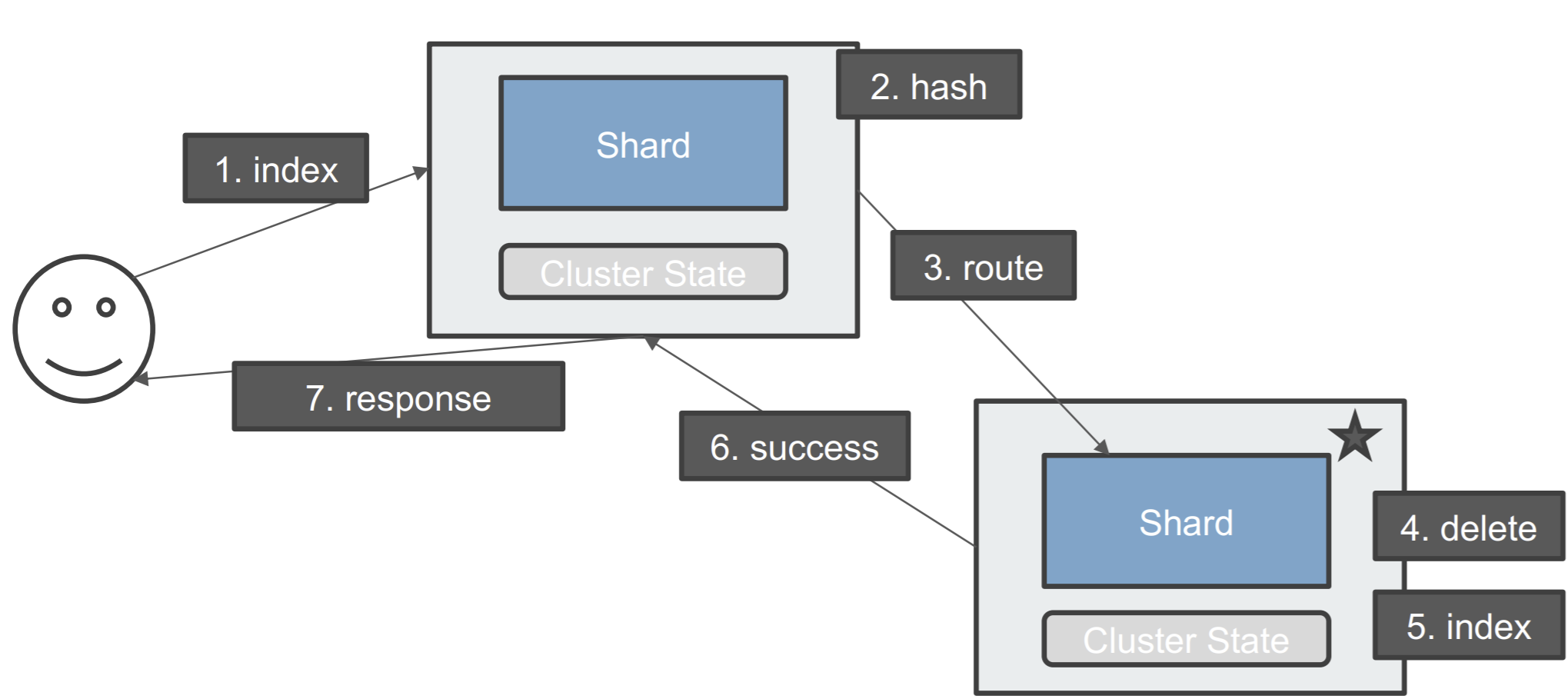
删除⼀个文档
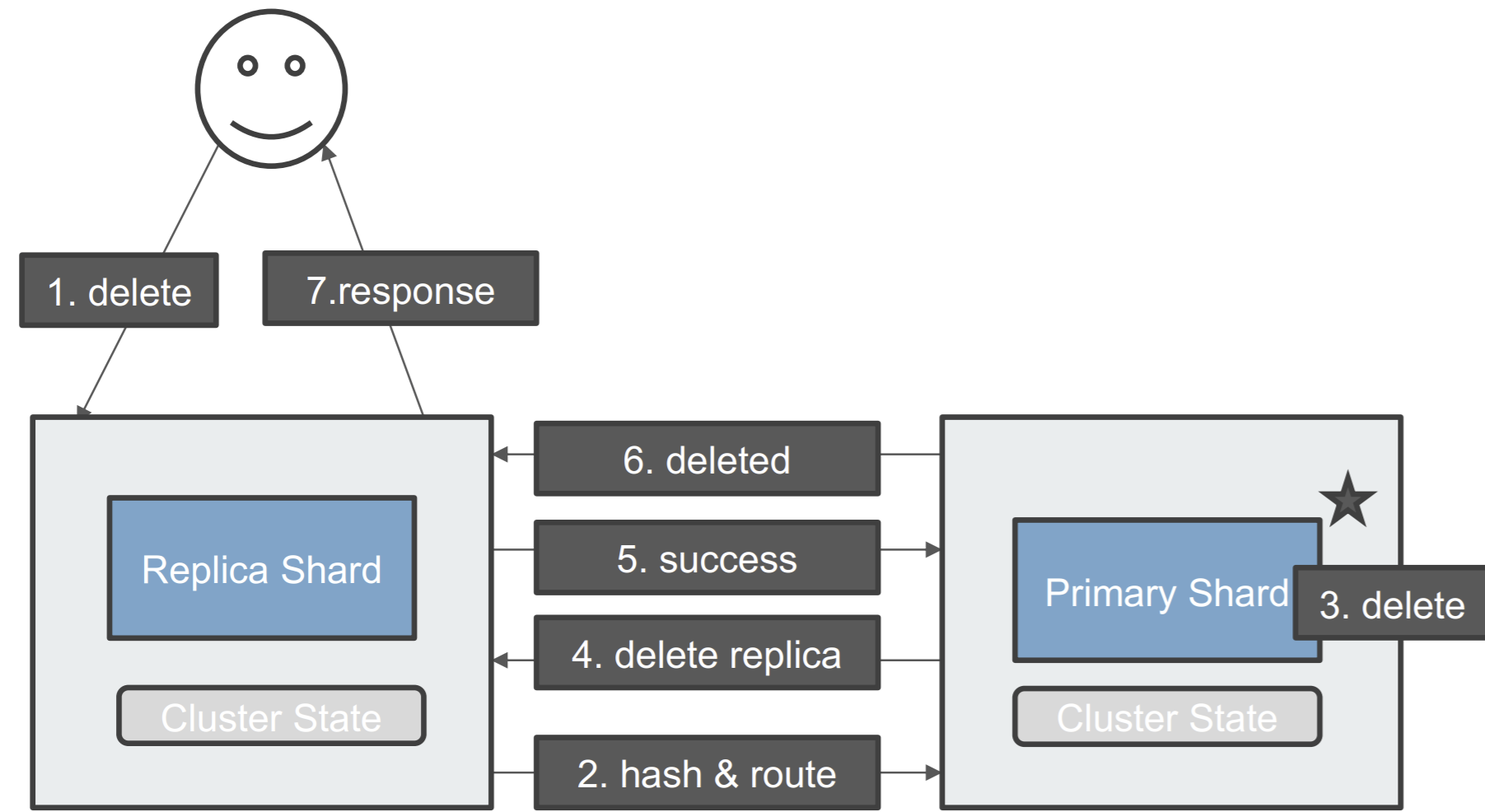
分⽚及其⽣命周期
分⽚的内部原理
什么是 ES 的分⽚
- ES 中最⼩的⼯作单元 / 是⼀个 Lucene 的 Index
⼀些问题:
-
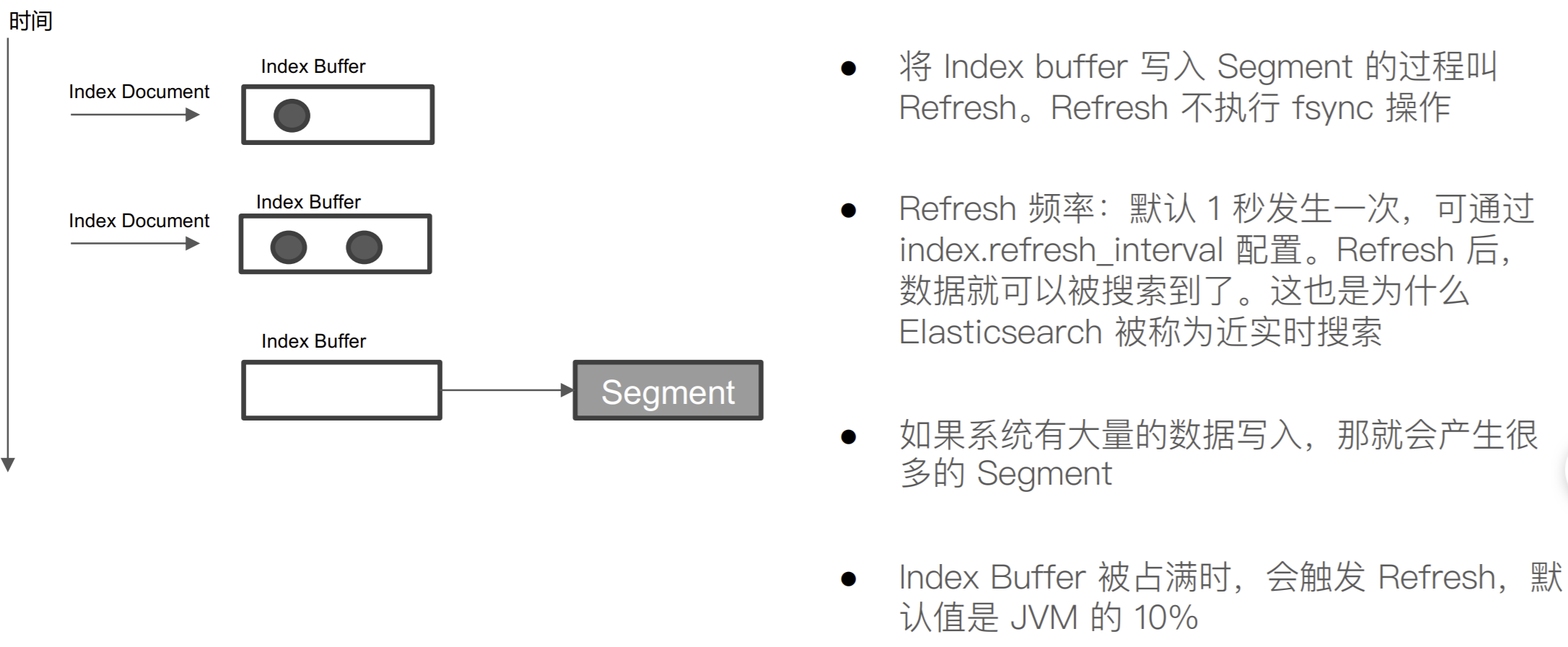
为什么 ES 的搜索是近实时的(1 秒后被搜到)
-
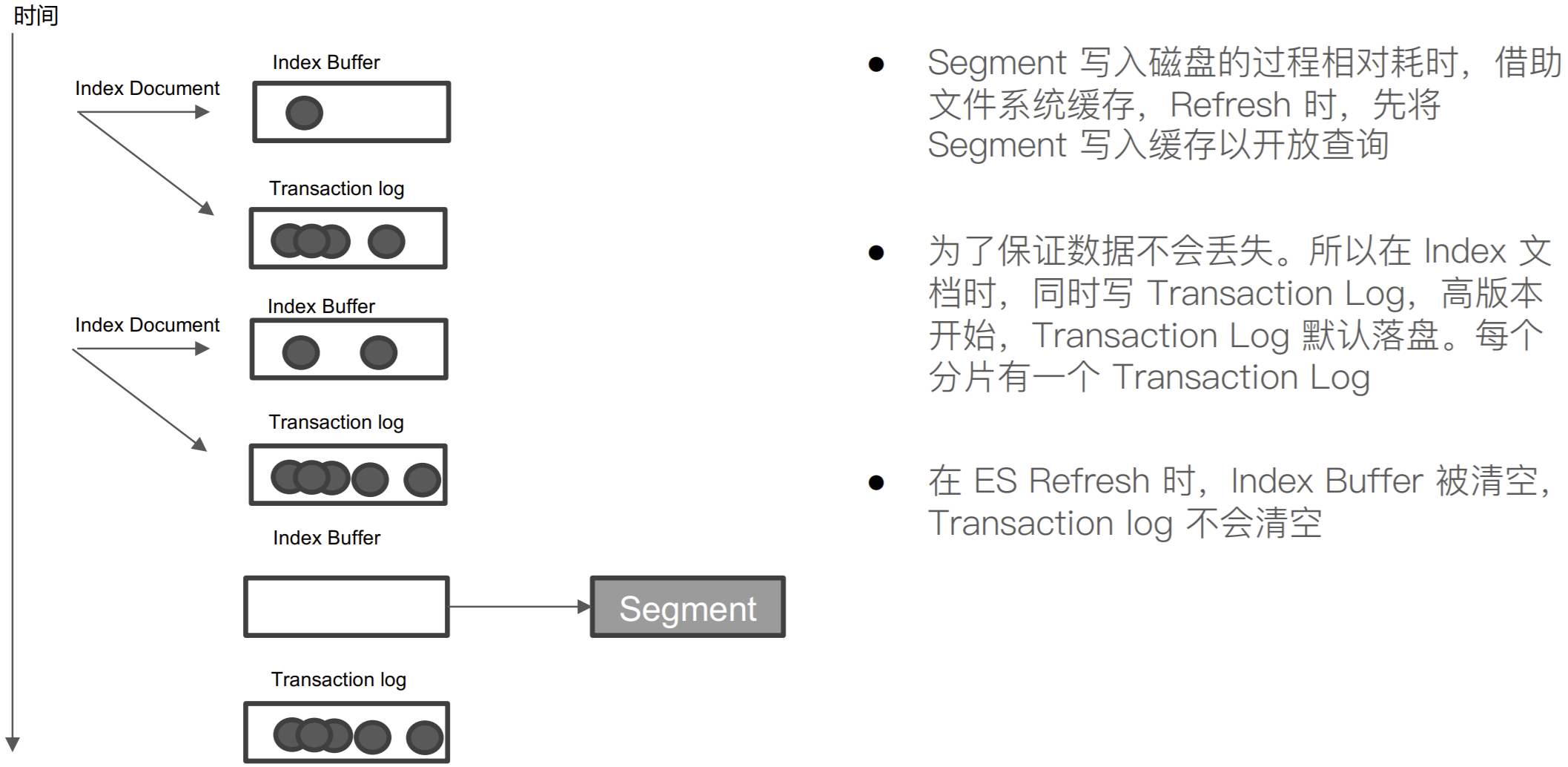
ES 如何保证在断电时数据也不会丢失
-
为什么删除⽂档,并不会⽴刻释放空间
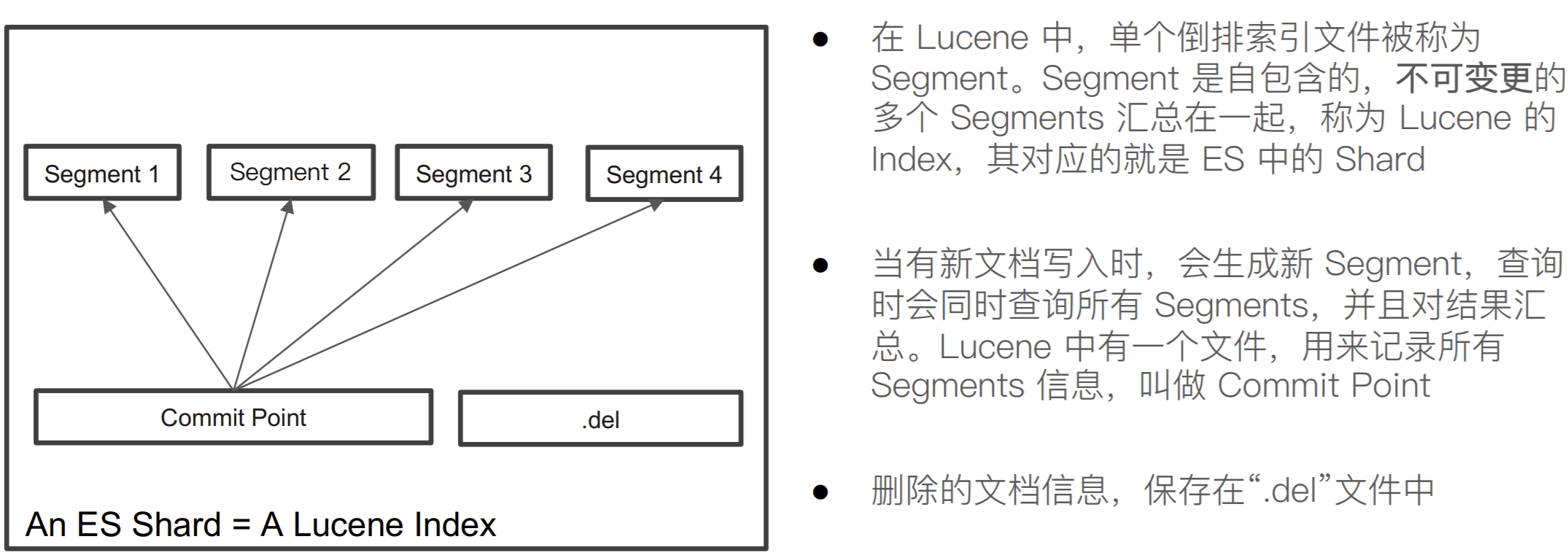
倒排索引不可变性
倒排索引采⽤ Immutable Design,⼀旦⽣成,不可更改
-
不可变性,带来了的好处如下:
-
⽆需考虑并发写⽂件的问题,避免了锁机制带来的性能问题
-
⼀旦读⼊内核的⽂件系统缓存,便留在哪⾥。只要⽂件系统存有⾜够的空间,⼤部分请求就会直接请求内 存,不会命中磁盘,提升了很⼤的性能
-
缓存容易⽣成和维护 / 数据可以被压缩
不可变更性,带来了的挑战:如果需要让⼀个新的⽂档可以被搜索,需要重建整个索引。
Lucene Index
什么是 Refresh
什么是 Transaction Log
什么是 Flush

Merge
Segment 很多,需要被定期被合并
- 减少 Segments / 删除已经删除的⽂档
ES 和 Lucene 会⾃动进⾏ Merge 操作
- POST my_index/_forcemerge
剖析分布式查询及相关性算分
分布式搜索的运⾏机制
Elasticsearch 的搜索,会分两阶段进⾏
-
第⼀阶段 - Query
-
第⼆阶段 - Fetch
Query-then-Fetch
Query 阶段
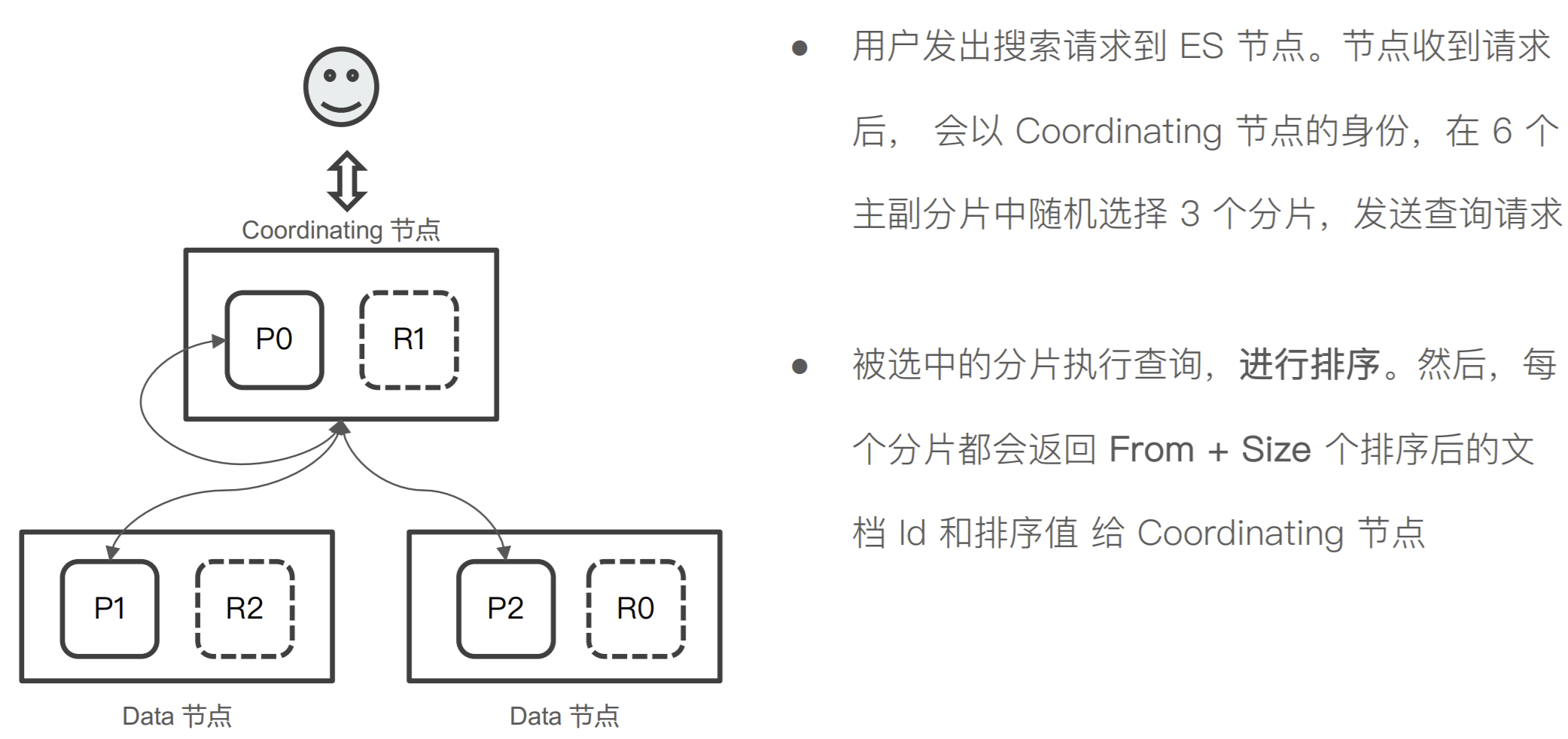
Fetch 阶段
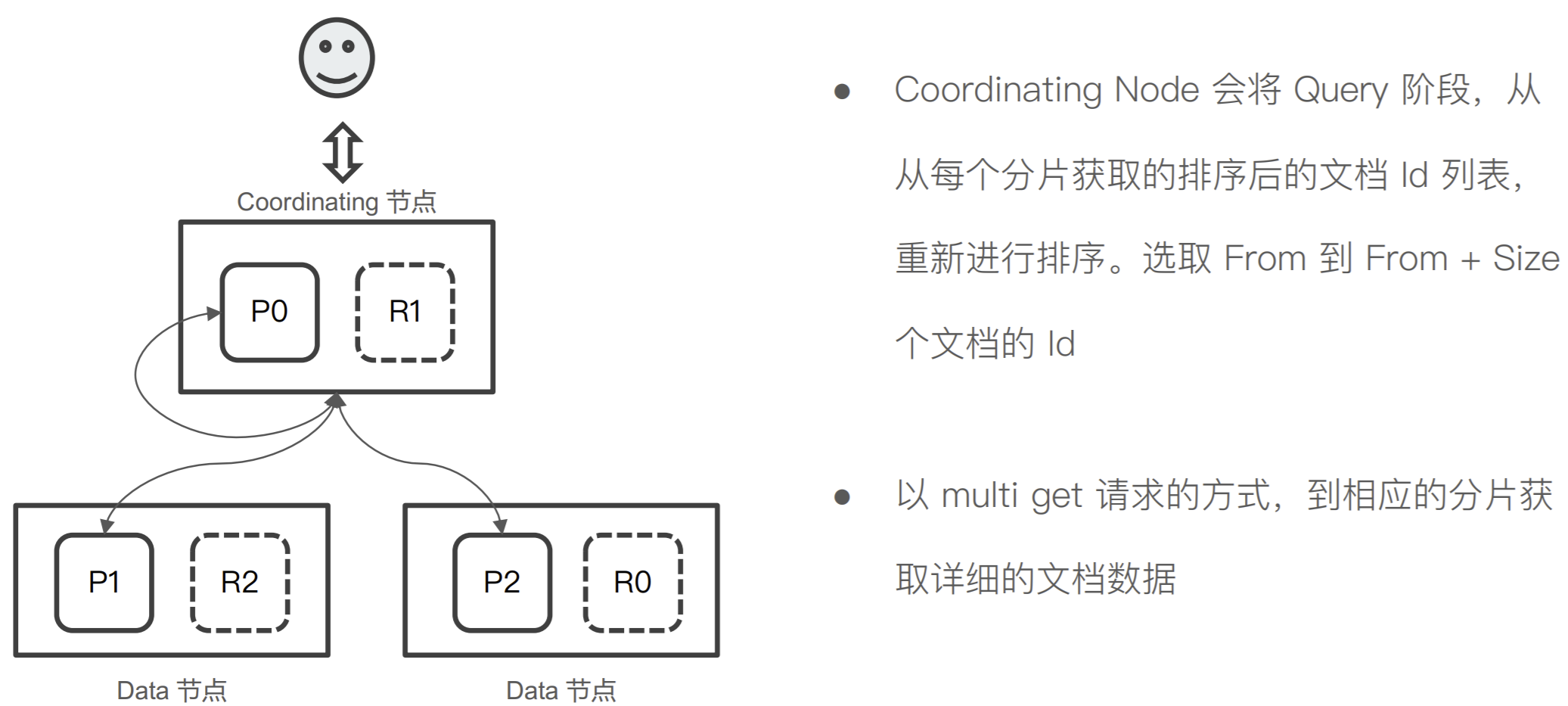
Query Then Fetch 潜在的问题
性能问题
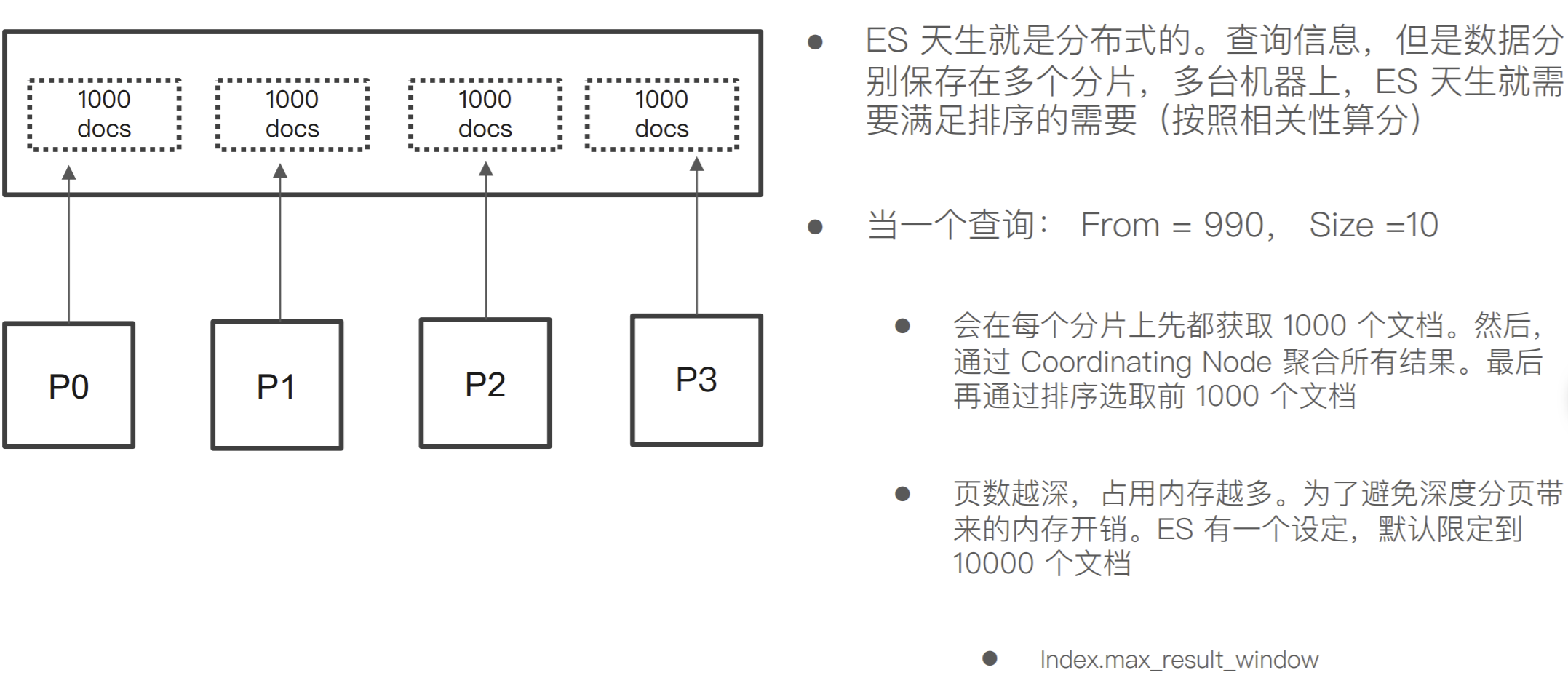
-
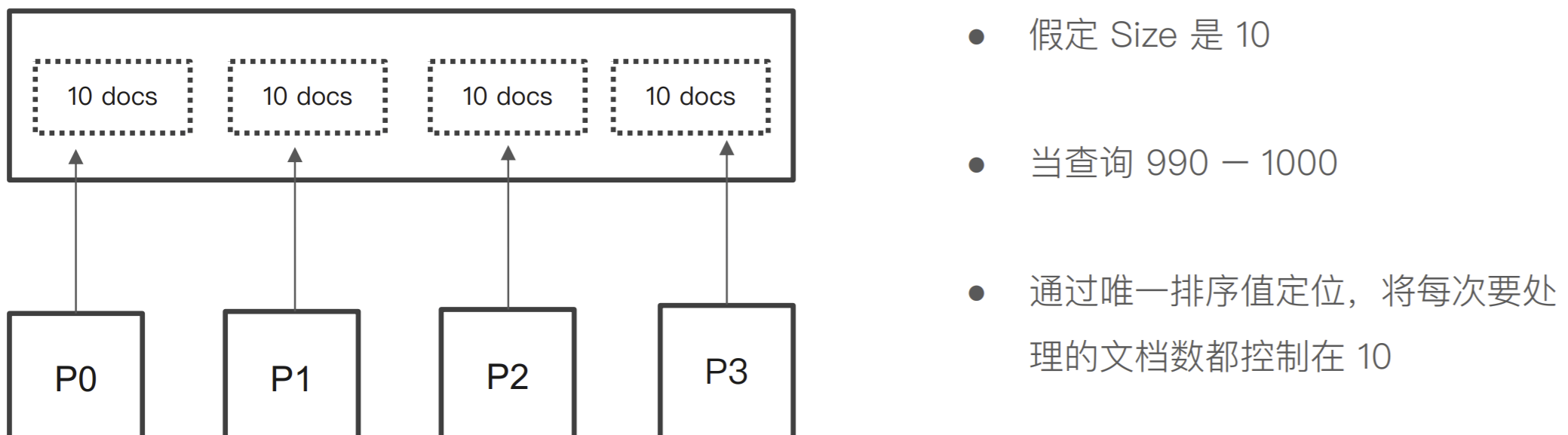
每个分⽚上需要查的⽂档个数 = from + size
-
最终协调节点需要处理:number_of_shard * ( from+size )
-
深度分⻚
相关性算分
- 每个分⽚都基于⾃⼰的分⽚上的数据进⾏相关度计算。这会导致打分偏离的情况,特别是 数据量很少时。相关性算分在分⽚之间是相互独⽴。当⽂档总数很少的情况下,如果主分 ⽚⼤于 1,主分⽚数越多 ,相关性算分会越不准
解决算分不准的⽅法
数据量不⼤的时候,可以将主分⽚数设置为 1
- 当数据量⾜够⼤时候,只要保证⽂档均匀分散在各个分⽚上,结果⼀般就不会出现 偏差
使⽤ DFS Query Then Fetch
-
搜索的URL 中指定参数 “_search?search_type=dfs_query_then_fetch”
-
到每个分⽚把各分⽚的词频和⽂档频率进⾏搜集,然后完整的进⾏⼀次相关性算分, 耗费更加多的 CPU 和内存,执⾏性能低下,⼀般不建议使⽤
POST message/_search?search_type=dfs_query_then_fetch
{
"query": {
"term": {
"content": {
"value": "good"
}
}
}
}
排序及 Doc Values & Field Data
排序
-
Elasticsearch 默认采⽤相关性算分对结果进⾏ 降序排序
-
可以通过设定 sorting 参数,⾃⾏设定排序
-
如果不指定_score,算分为 Null


POST /kibana_sample_data_ecommerce/_search { "size": 5, "query": { "match_all": {} }, "sort": [ { "order_date": { "order": "desc" } } ] }

多字段进⾏排序
-
组合多个条件
-
优先考虑写在前⾯的排序
-
⽀持对相关性算分进⾏排序
POST /kibana_sample_data_ecommerce/_search { "size": 5, "query": { "match_all": {} }, "sort": [ { "order_date": { "order": "desc" } }, { "_doc": { "order": "asc" } }, { "_score": { "order": "desc" } } ] }

排序的过程
排序是针对字段原始内容进⾏的。 倒排索引⽆法发挥作⽤
需要⽤到正排索引。通过⽂档 Id 和字段快速得到字段原始内容
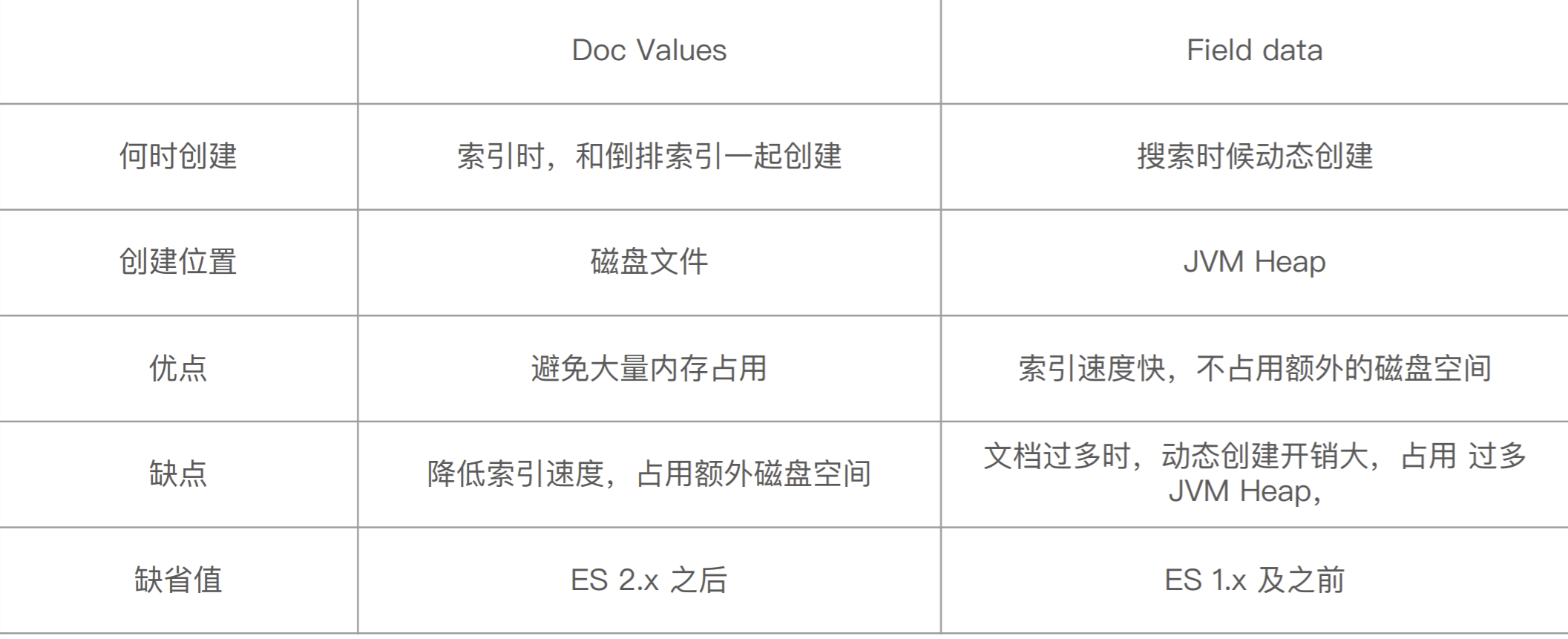
Elasticsearch 有两种实现⽅法
-
Fielddata
-
Doc Values (列式存储,对 Text 类型⽆效)
Doc Values vs Field Data
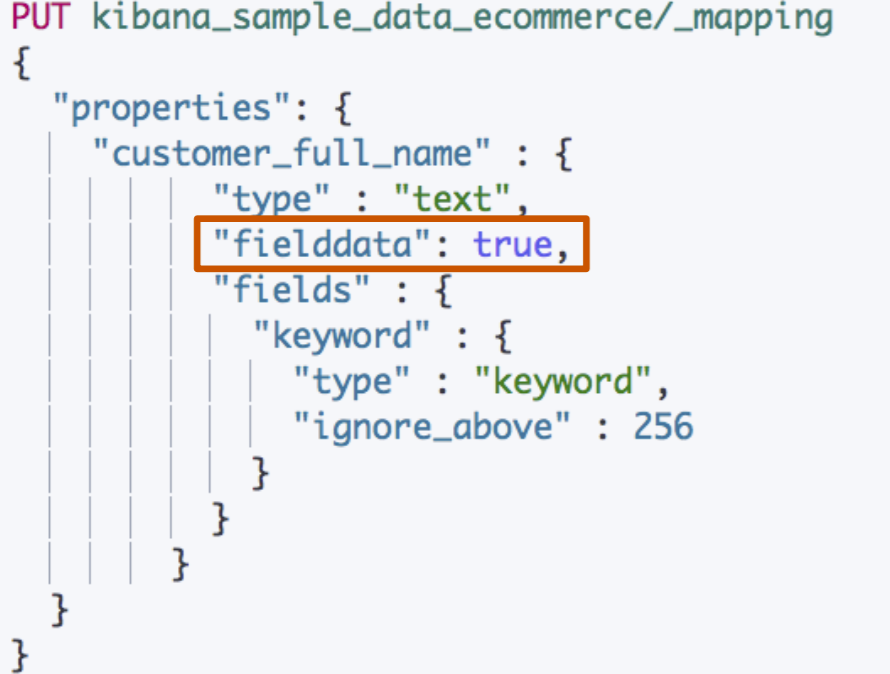
Fielddata
-
默认关闭,可以通过 Mapping 设置打开。修改 设置后,即时⽣效,⽆需重建索引
-
其他字段类型不⽀持,只⽀持对 Text 进⾏设定
-
打开后,可以对 Text 字段进⾏排序。但是不能对 分词后的 term 排序,所以,结果往往⽆法满⾜ 预期,不建议使⽤
-
部分情况下打开,满⾜⼀些聚合分析的特定需求
打开 Fielddata
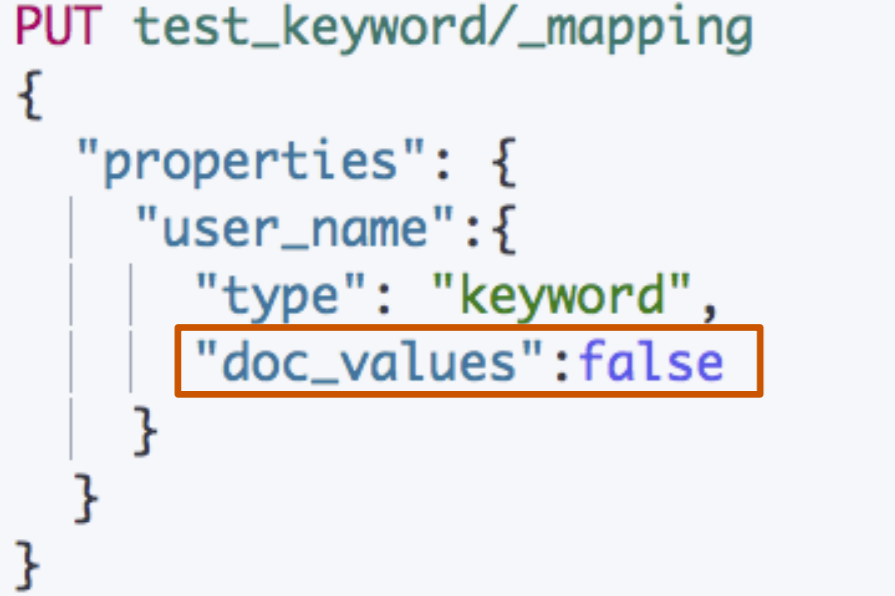
Doc Values
默认启⽤,可以通过 Mapping 设置关闭,增加索引的速度 / 减少磁盘空间
如果重新打开,需要重建索引
什么时候需要关闭
- 明确不需要做排序及聚合分析
关闭 Doc Values
获取 Doc Values & Fielddata 中存储的内容
Text 类型的不⽀持 Doc Values
Text 类型打开 Fielddata后,可以查看分词 后的数据
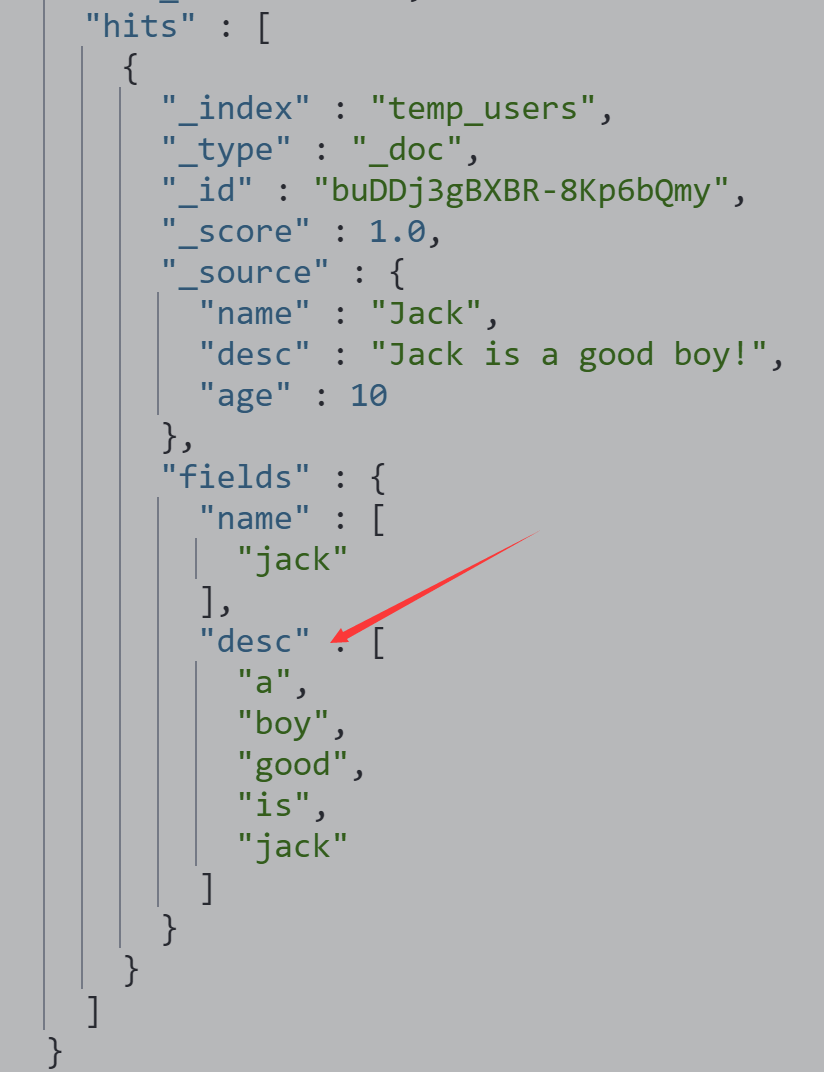
打开fielddata 后,查看 docvalue_fields数据
DELETE temp_users PUT temp_users PUT temp_users/_mapping { "properties": { "name":{"type": "text","fielddata": true}, "desc":{"type": "text","fielddata": true} } } POST temp_users/_doc {"name":"Jack","desc":"Jack is a good boy!","age":10} #打开fielddata 后,查看 docvalue_fields数据 POST temp_users/_search { "docvalue_fields": [ "name","desc" ] }
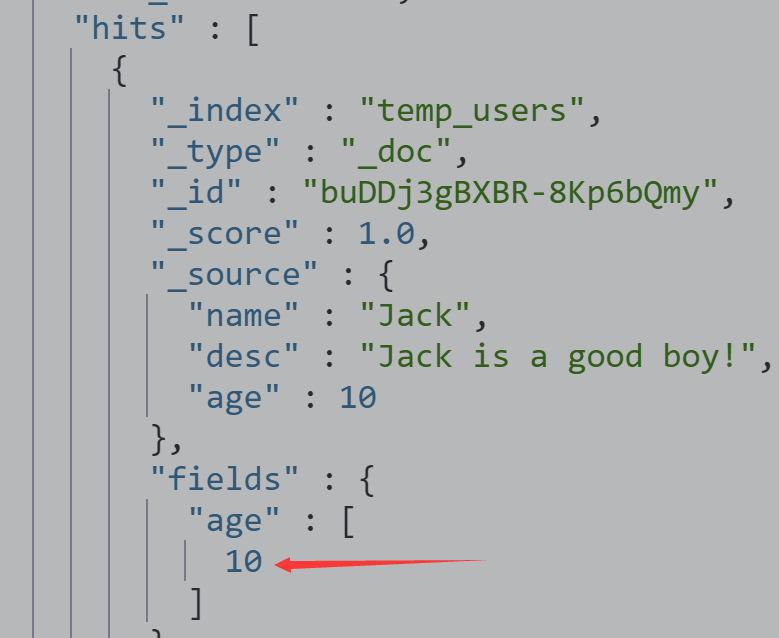
查看整型字段的docvalues
POST temp_users/_search
{
"docvalue_fields": [
"age"
]
}
分⻚与遍历 – From,Size,Search After & Scroll API
From / Size
默认情况下,查询按照相关度算分排序,返回前 10 条记录
容易理解的分⻚⽅案
-
From:开始位置
-
Size:期望获取⽂档的总数
分布式系统中深度分⻚的问题
From + Size 必须⼩与 10000否则会报错

Search After 避免深度分⻚的问题
-
避免深度分⻚的性能问题,可以实时获取下⼀⻚⽂ 档信息
-
不⽀持指定⻚数(From)
-
只能往下翻
-
第⼀步搜索需要指定 sort,并且保证值是唯⼀的 (可以通过加⼊ _id 保证唯⼀性)
-
然后使⽤上⼀次,最后⼀个⽂档的 sort 值进⾏查询
导入数据
#Scroll API DELETE users POST users/_doc {"name":"user1","age":10} POST users/_doc {"name":"user2","age":11} POST users/_doc {"name":"user2","age":12} POST users/_doc {"name":"user2","age":13} POST users/_count POST users/_search { "size": 1, "query": { "match_all": {} }, "sort": [ {"age": "desc"} , {"_id": "asc"} ] }
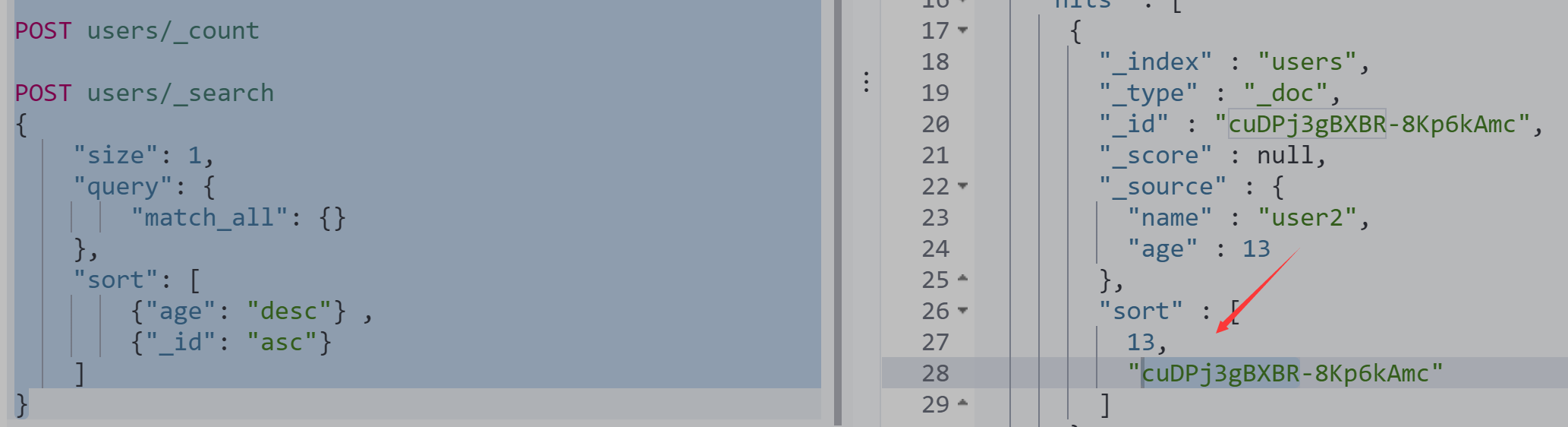
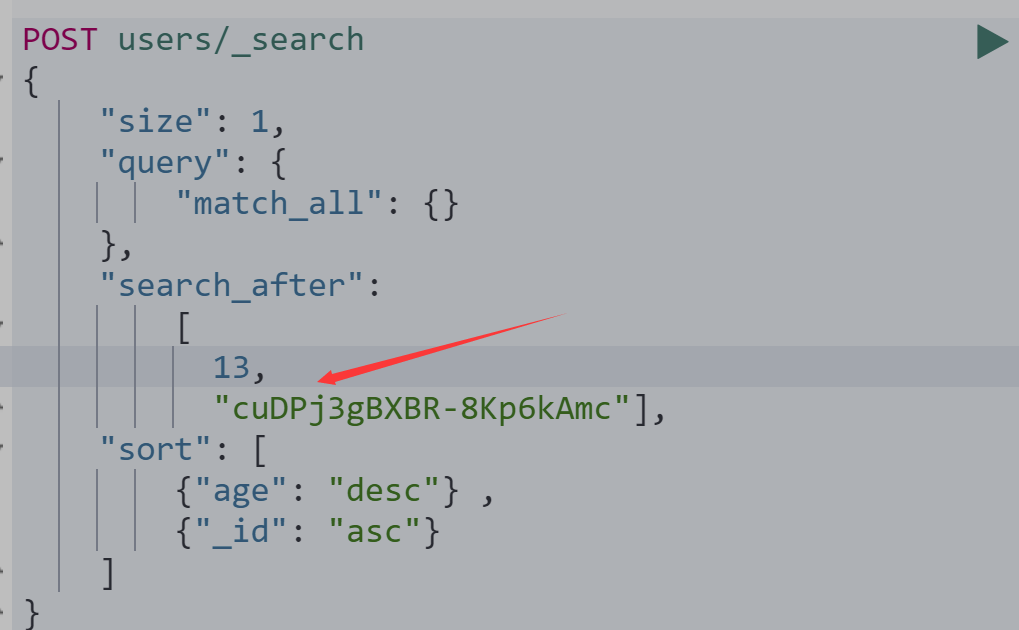
使用sort查询
POST users/_search { "size": 1, "query": { "match_all": {} }, "search_after": [ 13, "cuDPj3gBXBR-8Kp6kAmc"], "sort": [ {"age": "desc"} , {"_id": "asc"} ] }
Search After 是如何解决深度分⻚的问题
Scroll API
创建⼀个快照,有新的数据写⼊以后,⽆ 法被查到
每次查询后,输⼊上⼀次的 Scroll Id
创建一个5分钟的快照
#Scroll API DELETE users POST users/_doc {"name":"user1","age":10} POST users/_doc {"name":"user2","age":20} POST users/_doc {"name":"user3","age":30} POST users/_doc {"name":"user4","age":40} POST /users/_search?scroll=5m { "size": 1, "query": { "match_all": {} } }

使用快照查询
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAA5EWT0VUdC1XNThUUHVWM1pzS0NSck9Zdw=="
}
不同的搜索类型和使⽤场景
Regular(默认的返回最新的10条数据)
- 需要实时获取顶部的部分⽂档。例如查询最新的订单
Scroll
- 需要全部⽂档,例如导出全部数据
Pagination
-
From 和 Size
-
如果需要深度分⻚,则选⽤ Search After
处理并发读写操作
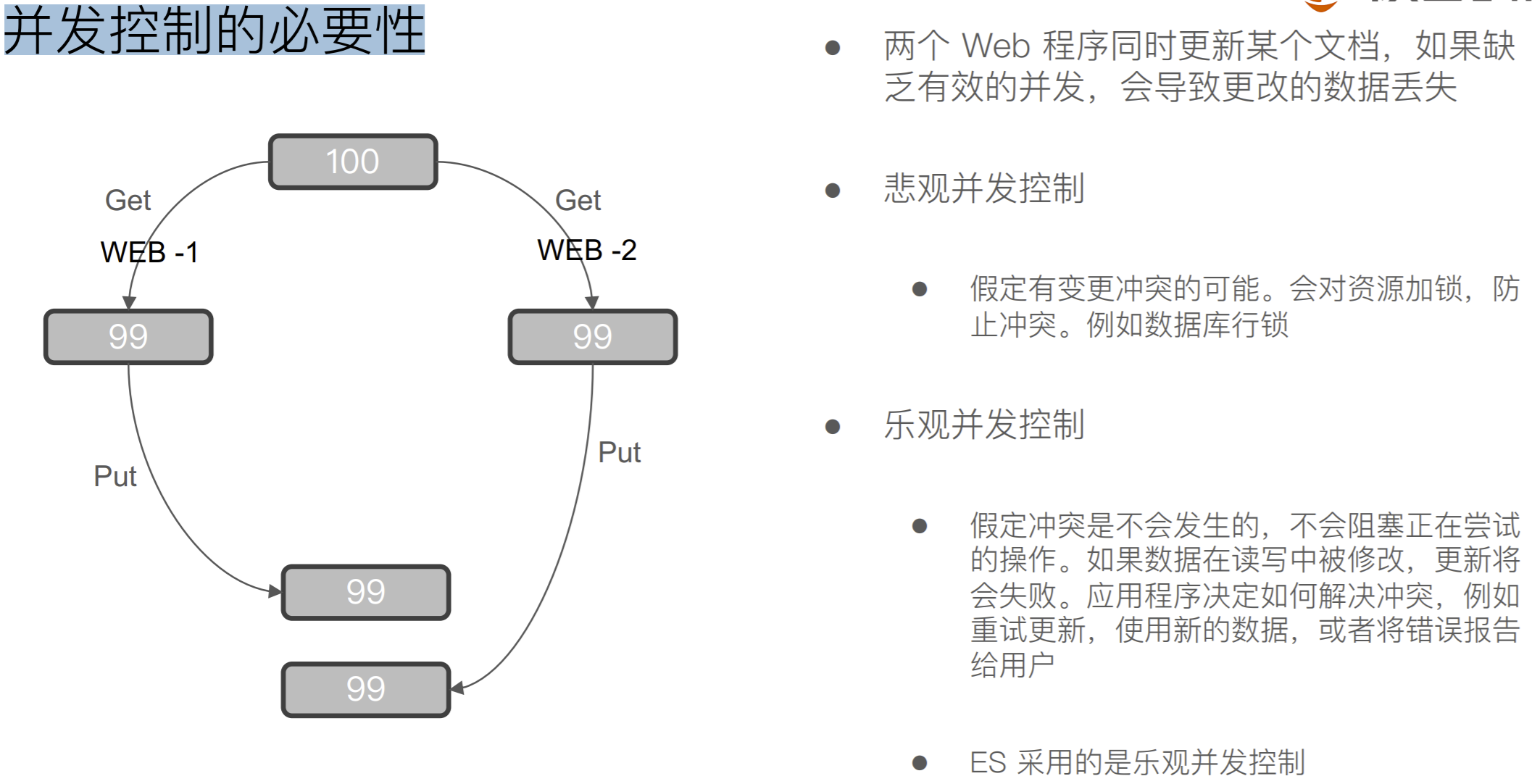
ES 的乐观并发控制
ES 中的⽂档是不可变更的。如果你更新⼀个⽂档,会将 就⽂档标记为删除,同时增加⼀个全新的⽂档。同时⽂档 的 version 字段加 1
内部版本控制
- If_seq_no + If_primary_term
使⽤外部版本(使⽤其他数据库作为主要数据存储)
- version + version_type=external
准备一条数据
DELETE products PUT products PUT products/_doc/1 { "title": "iphone", "count": 100 } GET products/_doc/1
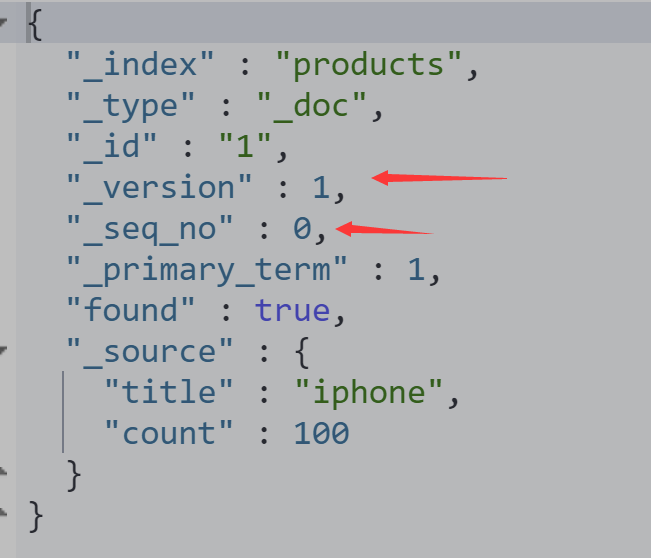
使用乐观锁对其修改需要指定参数 seq_no 和primary_term才不会锁表
PUT products/_doc/1?if_seq_no=0&if_primary_term=1
{
"title": "iphone",
"count": 100
}
也可以自定义version后再发起调用
PUT products/_doc/1?if_seq_no=100&if_primary_term=1
{
"title": "iphone",
"count": 100
}
PUT products/_doc/1?version=100&version_type=external
{
"title": "apple",
"count": 100
}
PUT products/_doc/1?if_seq_no=101&if_primary_term=1
{
"title": "app",
"count": 10
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号