elasticsearch—入门(进阶)
文档的 CRUD 与批量操作
create document. 自动生成 _id
POST users/_doc
{
"user": "Mike",
"post_date": "2019-04-15T14:12:12",
"message": "trying out Kibana"
}
create document. 指定Id。如果id已经存在,报错
PUT users/_doc/1?op_type=create
{
"user": "Jack",
"post_date": "2019-05-15T14:12:12",
"message": "trying out Elasticsearch"
}
指定 ID 如果已经存在,就报错
PUT users/_create/1
{
"user": "Jack",
"post_date": "2019-05-15T14:12:12",
"message": "trying out Elasticsearch"
}
Get the document by ID
GET users/_doc/1
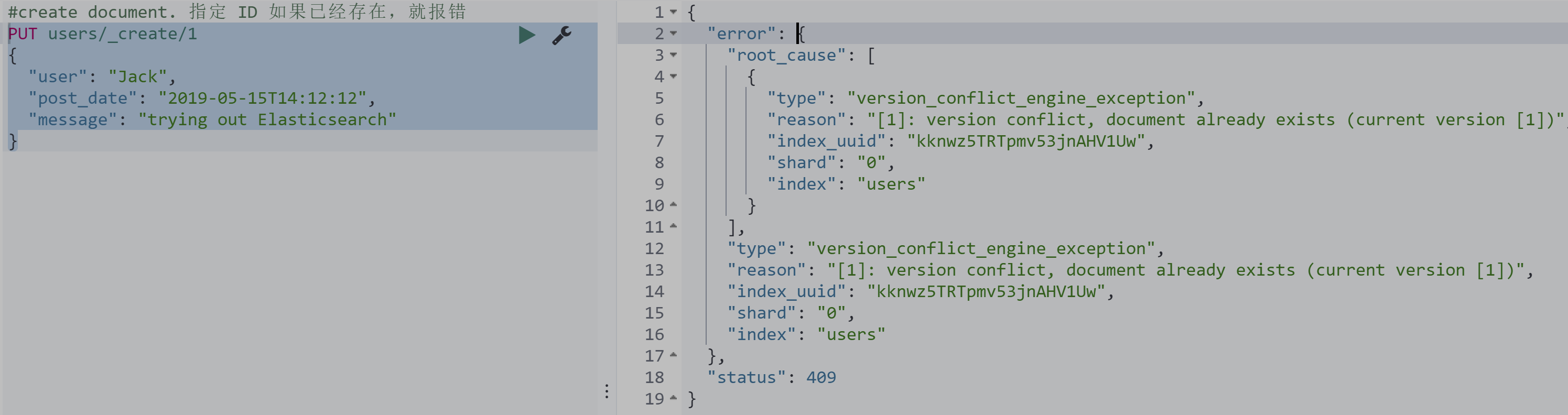
Update 指定 ID (先删除,在写入)
PUT users/_doc/1
{
"user": "Mike"
}
GET users/_doc/1

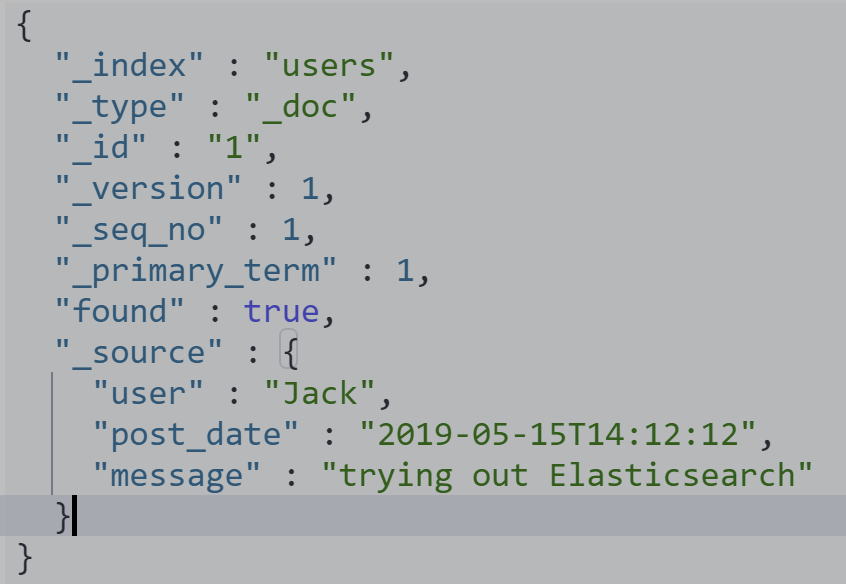
在原文档上增加字段
POST users/_update/1/
{
"doc":{
"post_date" : "2019-05-15T14:12:12",
"message" : "trying out Elasticsearch"
}
}
GET users/_doc/1
删除文档
DELETE users/_doc/1
Bulk 操作
如果一个具有相同索引的文档已经存在,则create将失败,而index将根据需要添加或替换一个文档
执行第1次
POST _bulk
{"index":{"_index":"test","_id":"1"}}
{"field1":"value1"}
{"delete":{"_index":"test","_id":"2"}}
{"create":{"_index":"test2","_id":"3"}}
{"field1":"value3"}
{"update":{"_id":"1","_index":"test"}}
{"doc":{"field2":"value2"}}
运行结果如下


{ "took": 30, "errors": false, "items": [ { "index": { "_index": "test", "_type": "_doc", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "status": 201, "_seq_no" : 0, "_primary_term": 1 } }, { "delete": { "_index": "test", "_type": "_doc", "_id": "2", "_version": 1, "result": "not_found", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "status": 404, "_seq_no" : 1, "_primary_term" : 2 } }, { "create": { "_index": "test", "_type": "_doc", "_id": "3", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "status": 201, "_seq_no" : 2, "_primary_term" : 3 } }, { "update": { "_index": "test", "_type": "_doc", "_id": "1", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "status": 200, "_seq_no" : 3, "_primary_term" : 4 } } ] }
执行第2次
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test2", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
运行结果如下
{ "took" : 2, "errors" : true, "items" : [ { "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 21, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 30, "_primary_term" : 1, "status" : 200 } }, { "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2", "_version" : 1, "result" : "not_found", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 31, "_primary_term" : 1, "status" : 404 } }, { "create" : { "_index" : "test2", "_type" : "_doc", "_id" : "3", "status" : 409, "error" : { "type" : "version_conflict_engine_exception", "reason" : "[3]: version conflict, document already exists (current version [1])", "index_uuid" : "tNhUI2pOSqqMTxTwQJyPjQ", "shard" : "0", "index" : "test2" } } }, { "update" : { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 22, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 32, "_primary_term" : 1, "status" : 200 } } ] }
mget 操作
GET /_mget
{
"docs": [
{
"_index": "test",
"_id": "1"
},
{
"_index": "test",
"_id": "2"
}
]
}

URI中指定index
GET /test/_mget
{
"docs": [
{
"_id": "1"
},
{
"_id": "2"
}
]
}
_source false 不显示,指定要返回的值
GET /_mget
{
"docs": [
{
"_index": "test",
"_id": "1",
"_source": false
},
{
"_index": "test",
"_id": "2",
"_source": [
"field3",
"field4"
]
},
{
"_index": "test",
"_id": "3",
"_source": {
"include": [
"user"
],
"exclude": [
"user.location"
]
}
}
]
}

POST kibana_sample_data_ecommerce/_msearch
{}
{"query":{"match_all":{}},"size":1}
{"index":"kibana_sample_data_flights"}
{"query":{"match_all":{}},"size":2}
运行结果如下
{ "took" : 1, "responses" : [ { "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4675, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "kibana_sample_data_ecommerce", "_type" : "_doc", "_id" : "j_UFdngBnrEhdHydz7qu", "_score" : 1.0, "_source" : { "category" : [ "Men's Clothing" ], "currency" : "EUR", "customer_first_name" : "Eddie", "customer_full_name" : "Eddie Underwood", "customer_gender" : "MALE", "customer_id" : 38, "customer_last_name" : "Underwood", "customer_phone" : "", "day_of_week" : "Monday", "day_of_week_i" : 0, "email" : "eddie@underwood-family.zzz", "manufacturer" : [ "Elitelligence", "Oceanavigations" ], "order_date" : "2021-04-19T09:28:48+00:00", "order_id" : 584677, "products" : [ { "base_price" : 11.99, "discount_percentage" : 0, "quantity" : 1, "manufacturer" : "Elitelligence", "tax_amount" : 0, "product_id" : 6283, "category" : "Men's Clothing", "sku" : "ZO0549605496", "taxless_price" : 11.99, "unit_discount_amount" : 0, "min_price" : 6.35, "_id" : "sold_product_584677_6283", "discount_amount" : 0, "created_on" : "2016-12-26T09:28:48+00:00", "product_name" : "Basic T-shirt - dark blue/white", "price" : 11.99, "taxful_price" : 11.99, "base_unit_price" : 11.99 }, { "base_price" : 24.99, "discount_percentage" : 0, "quantity" : 1, "manufacturer" : "Oceanavigations", "tax_amount" : 0, "product_id" : 19400, "category" : "Men's Clothing", "sku" : "ZO0299602996", "taxless_price" : 24.99, "unit_discount_amount" : 0, "min_price" : 11.75, "_id" : "sold_product_584677_19400", "discount_amount" : 0, "created_on" : "2016-12-26T09:28:48+00:00", "product_name" : "Sweatshirt - grey multicolor", "price" : 24.99, "taxful_price" : 24.99, "base_unit_price" : 24.99 } ], "sku" : [ "ZO0549605496", "ZO0299602996" ], "taxful_total_price" : 36.98, "taxless_total_price" : 36.98, "total_quantity" : 2, "total_unique_products" : 2, "type" : "order", "user" : "eddie", "geoip" : { "country_iso_code" : "EG", "location" : { "lon" : 31.3, "lat" : 30.1 }, "region_name" : "Cairo Governorate", "continent_name" : "Africa", "city_name" : "Cairo" } } } ] }, "status" : 200 }, { "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 10000, "relation" : "gte" }, "max_score" : 1.0, "hits" : [ { "_index" : "kibana_sample_data_flights", "_type" : "_doc", "_id" : "a_UFdngBnrEhdHyd1sBb", "_score" : 1.0, "_source" : { "FlightNum" : "9HY9SWR", "DestCountry" : "AU", "OriginWeather" : "Sunny", "OriginCityName" : "Frankfurt am Main", "AvgTicketPrice" : 841.2656419677076, "DistanceMiles" : 10247.856675613455, "FlightDelay" : false, "DestWeather" : "Rain", "Dest" : "Sydney Kingsford Smith International Airport", "FlightDelayType" : "No Delay", "OriginCountry" : "DE", "dayOfWeek" : 0, "DistanceKilometers" : 16492.32665375846, "timestamp" : "2021-03-22T00:00:00", "DestLocation" : { "lat" : "-33.94609833", "lon" : "151.177002" }, "DestAirportID" : "SYD", "Carrier" : "Kibana Airlines", "Cancelled" : false, "FlightTimeMin" : 1030.7704158599038, "Origin" : "Frankfurt am Main Airport", "OriginLocation" : { "lat" : "50.033333", "lon" : "8.570556" }, "DestRegion" : "SE-BD", "OriginAirportID" : "FRA", "OriginRegion" : "DE-HE", "DestCityName" : "Sydney", "FlightTimeHour" : 17.179506930998397, "FlightDelayMin" : 0 } }, { "_index" : "kibana_sample_data_flights", "_type" : "_doc", "_id" : "bPUFdngBnrEhdHyd1sBb", "_score" : 1.0, "_source" : { "FlightNum" : "X98CCZO", "DestCountry" : "IT", "OriginWeather" : "Clear", "OriginCityName" : "Cape Town", "AvgTicketPrice" : 882.9826615595518, "DistanceMiles" : 5482.606664853586, "FlightDelay" : false, "DestWeather" : "Sunny", "Dest" : "Venice Marco Polo Airport", "FlightDelayType" : "No Delay", "OriginCountry" : "ZA", "dayOfWeek" : 0, "DistanceKilometers" : 8823.40014044213, "timestamp" : "2021-03-22T18:27:00", "DestLocation" : { "lat" : "45.505299", "lon" : "12.3519" }, "DestAirportID" : "VE05", "Carrier" : "Logstash Airways", "Cancelled" : false, "FlightTimeMin" : 464.3894810759016, "Origin" : "Cape Town International Airport", "OriginLocation" : { "lat" : "-33.96480179", "lon" : "18.60169983" }, "DestRegion" : "IT-34", "OriginAirportID" : "CPT", "OriginRegion" : "SE-BD", "DestCityName" : "Venice", "FlightTimeHour" : 7.73982468459836, "FlightDelayMin" : 0 } } ] }, "status" : 200 } ] }
相关阅读
倒排索引入门
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表
相关阅读
使用分析器进行分词
内置分词器
-
Stand Analyzer 默认分词器,按词切分小写处理
-
Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
-
Stop Analyzer – 小写处理,停用词过滤(the,a,is)
-
Whitespace Analyzer – 按照空格切分,不转小写
-
Keyword Analyzer – 不分词,直接将输入当作输出
-
Patter Analyzer – 正则表达式,默认 \W+ (非字符分隔)
-
Language – 提供了30多种常见语言的分词器
stand
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
输出结果如下
{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "<NUM>", "position" : 0 }, { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "<ALPHANUM>", "position" : 3 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "<ALPHANUM>", "position" : 4 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "<ALPHANUM>", "position" : 5 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "<ALPHANUM>", "position" : 6 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "<ALPHANUM>", "position" : 8 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "<ALPHANUM>", "position" : 9 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "<ALPHANUM>", "position" : 10 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "<ALPHANUM>", "position" : 11 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "<ALPHANUM>", "position" : 12 } ] }
simpe
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
输出结果如下
{ "tokens" : [ { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 0 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 1 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "word", "position" : 2 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "word", "position" : 3 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "word", "position" : 4 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "word", "position" : 5 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "word", "position" : 6 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "word", "position" : 7 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "word", "position" : 8 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "word", "position" : 9 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "word", "position" : 10 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "word", "position" : 11 } ] }
stop
GET _analyze { "analyzer": "stop", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
输出结果如下
{ "tokens" : [ { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 0 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 1 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "word", "position" : 2 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "word", "position" : 3 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "word", "position" : 4 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "word", "position" : 5 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "word", "position" : 6 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "word", "position" : 7 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "word", "position" : 10 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "word", "position" : 11 } ] }
whitespace
GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
输出结果如下
{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "word", "position" : 0 }, { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 1 }, { "token" : "Quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 2 }, { "token" : "brown-foxes", "start_offset" : 16, "end_offset" : 27, "type" : "word", "position" : 3 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "word", "position" : 4 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "word", "position" : 5 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "word", "position" : 6 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "word", "position" : 7 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "word", "position" : 8 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "word", "position" : 9 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "word", "position" : 10 }, { "token" : "evening.", "start_offset" : 62, "end_offset" : 70, "type" : "word", "position" : 11 } ] }
keyword
GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
输出结果如下
{
"tokens" : [
{
"token" : "2 running Quick brown-foxes leap over lazy dogs in the summer evening.",
"start_offset" : 0,
"end_offset" : 70,
"type" : "word",
"position" : 0
}
]
}
pattern
GET _analyze { "analyzer": "pattern", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
输出结果如下
{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "word", "position" : 0 }, { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 1 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 2 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "word", "position" : 3 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "word", "position" : 4 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "word", "position" : 5 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "word", "position" : 6 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "word", "position" : 7 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "word", "position" : 8 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "word", "position" : 9 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "word", "position" : 10 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "word", "position" : 11 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "word", "position" : 12 } ] }
english
GET _analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
输出结果如下
{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "<NUM>", "position" : 0 }, { "token" : "run", "start_offset" : 2, "end_offset" : 9, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "<ALPHANUM>", "position" : 3 }, { "token" : "fox", "start_offset" : 22, "end_offset" : 27, "type" : "<ALPHANUM>", "position" : 4 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "<ALPHANUM>", "position" : 5 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "<ALPHANUM>", "position" : 6 }, { "token" : "lazi", "start_offset" : 38, "end_offset" : 42, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "dog", "start_offset" : 43, "end_offset" : 47, "type" : "<ALPHANUM>", "position" : 8 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "<ALPHANUM>", "position" : 11 }, { "token" : "even", "start_offset" : 62, "end_offset" : 69, "type" : "<ALPHANUM>", "position" : 12 } ] }
icu_analyzer
POST _analyze { "analyzer": "icu_analyzer", "text": "他说的确实在理”" }
输出结果如下
{ "tokens" : [ { "token" : "他", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "说的", "start_offset" : 1, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "确实", "start_offset" : 3, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "在", "start_offset" : 5, "end_offset" : 6, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "理", "start_offset" : 6, "end_offset" : 7, "type" : "<IDEOGRAPHIC>", "position" : 4 } ] }
中文 stand
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
输出结果如下
{ "tokens" : [ { "token" : "他", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "说", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "的", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "确", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "实", "start_offset" : 4, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 4 }, { "token" : "在", "start_offset" : 5, "end_offset" : 6, "type" : "<IDEOGRAPHIC>", "position" : 5 }, { "token" : "理", "start_offset" : 6, "end_offset" : 7, "type" : "<IDEOGRAPHIC>", "position" : 6 } ] }
相关阅读
-
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/indices-analyze.html
-
https://www.elastic.co/guide/en/elasticsearch/reference/current/analyzer-anatomy.html
Search APl
URI Search
- 在URL中使用查询参数
Request Body Search
- 使 Elasticsearch用提供的,基于JSON格式的更加完备的 Query Domain Specific Language (DSL)
在索引kibana_sample_data_ecommerce查询customer_first_name:Eddie = Eddie
GET kibana_sample_data_ecommerce/_search?q=customer_first_name:Eddie
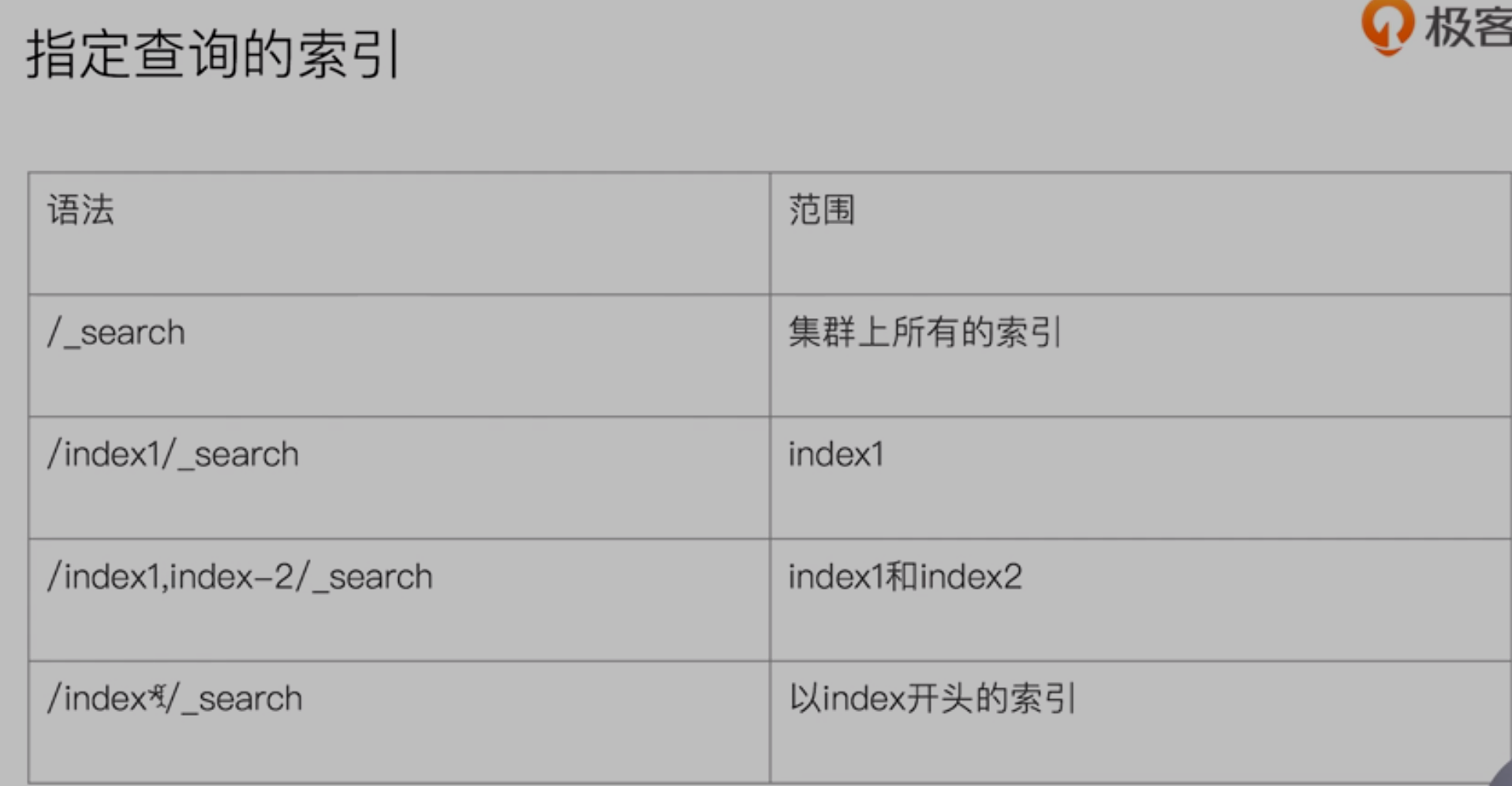
查询以kibana开头的索引查询customer_first_name:Eddie = Eddie
GET kibana*/_search?q=customer_first_name:Eddie
在所有索引中查找customer_first_name:Eddie = Eddie
GET /_all/_search?q=customer_first_name:Eddie
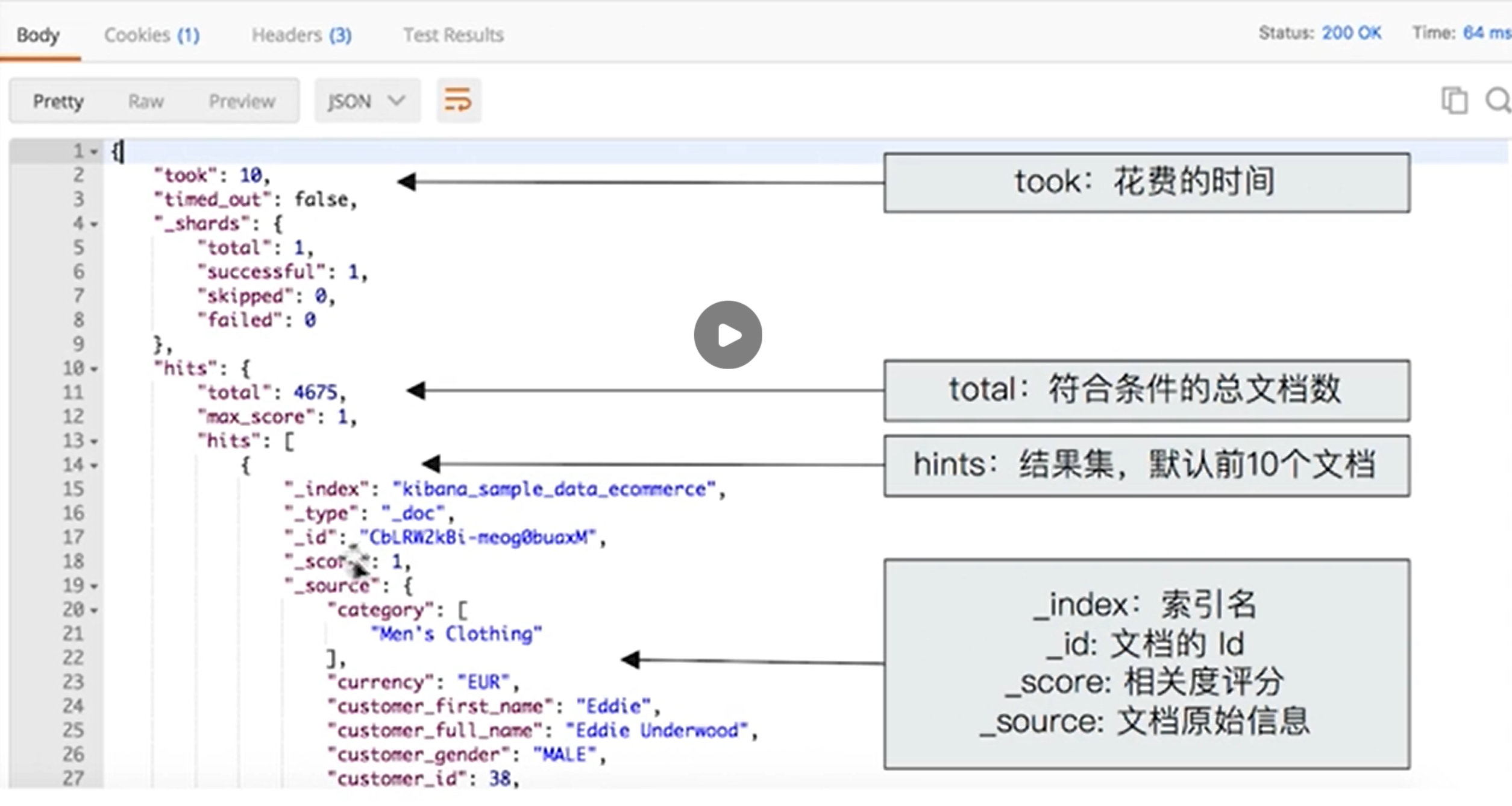
响应结果说明

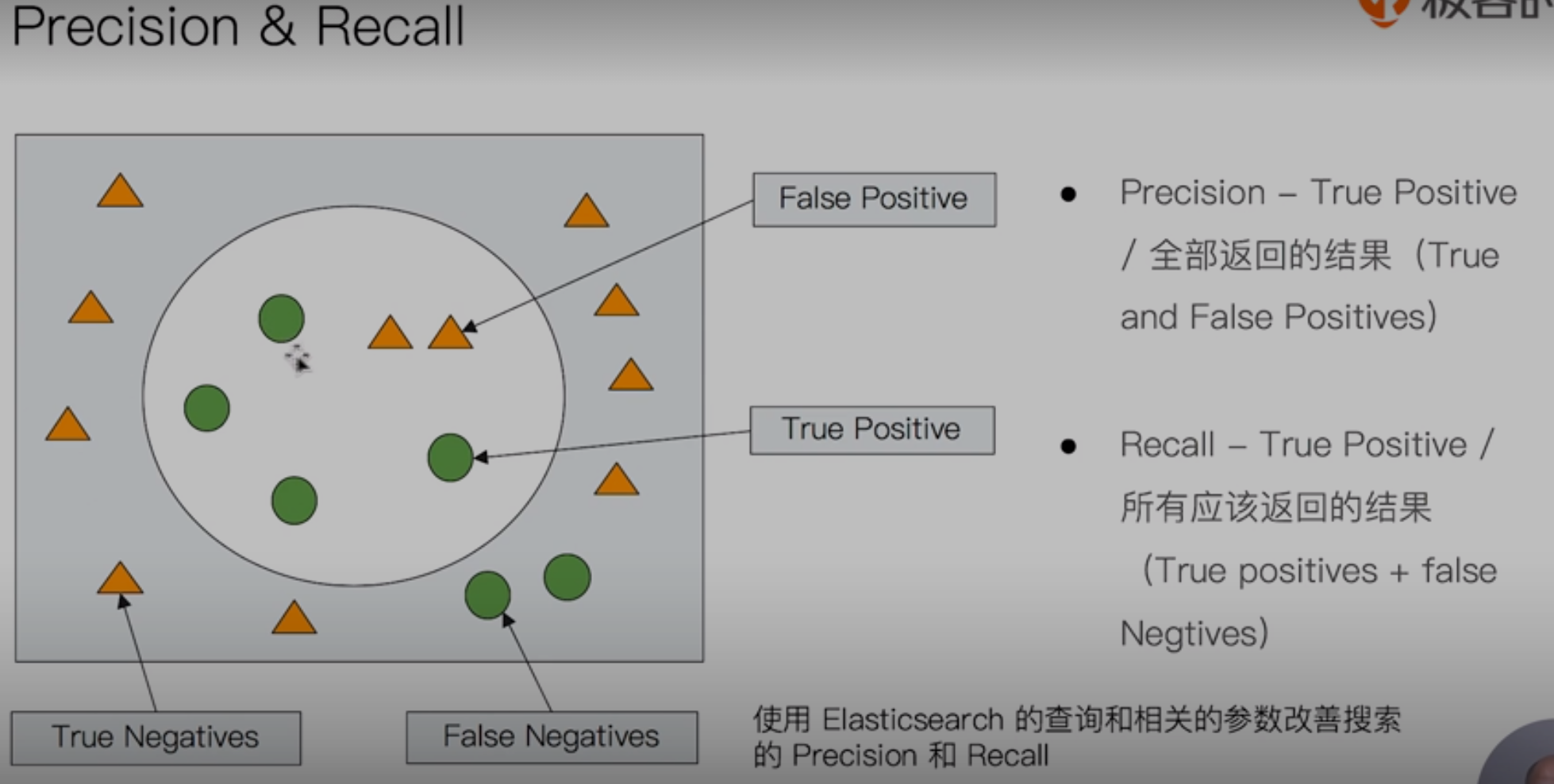
衡量相关性
Information Retrieval
-
Precision(查准率)-尽可能返回较少的无关文档
-
Recall(查全率)-尽量返回较多的相关文档
-
Ranking--是否能够按照相关度进行排序?
相关阅读
-
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/search-search.html
-
https://searchenginewatch.com/sew/news/2065080/search-engines-101
-
https://www.huffpost.com/entry/search-engines-101-part-i_b_1104525
-
https://baike.baidu.com/item/%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E%E5%8F%91%E5%B1%95%E5%8F%B2/2422574
URI Search详解
URI SearchURI-通过 query实现搜索
GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
-
q指定查询语句,使用 Query String Syntax
-
df默认字段,不指定时,会对所有字段进行查询
-
Sort排序/from和size用于分页
-
Profile可以查看查询是如何被执行的
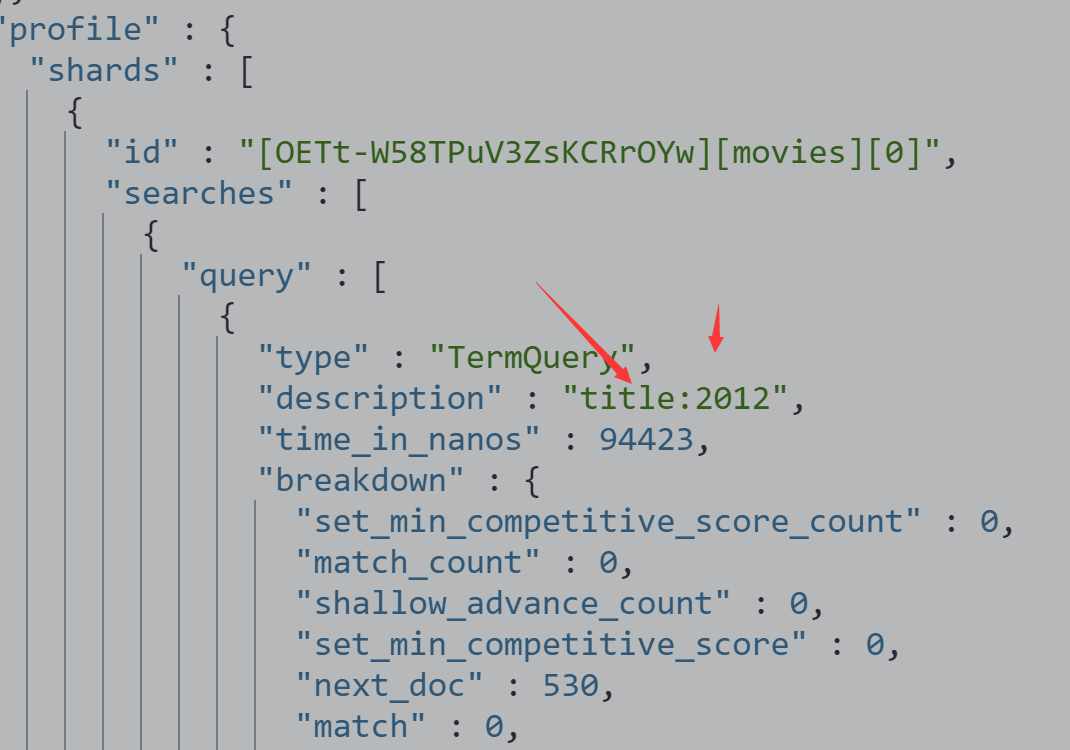
指定字段vs泛查询 q=title:2012/q=2012
基本查询 (查title中包含2012的数据)
GET /movies/_search?q=2012&df=title
{
"profile":"true"
}
泛查询,正对_all,所有字段
GET /movies/_search?q=2012
{
"profile": "true"
}
指定字段查询(不用指定df和q联合写法)
GET /movies/_search?q=title:2012&sort=year:desc&from=0&size=10&timeout=1s
{
"profile": "true"
}
执行过程如下
Term v. Phrase (同时出现顺序一致)
-
Beautiful Mind等效于 Beautiful OR Mind
-
“Beautiful Mind”,等效于 Beautiful AND Mind. Phrase查询,还要求前后顺序保持一致(不拆分都要有)
GET /movies/_search?q=title:Beautiful Mind
{
"profile": "true"
}
可以看到会把在title中包含 beautiful or Mind的结果都查出来

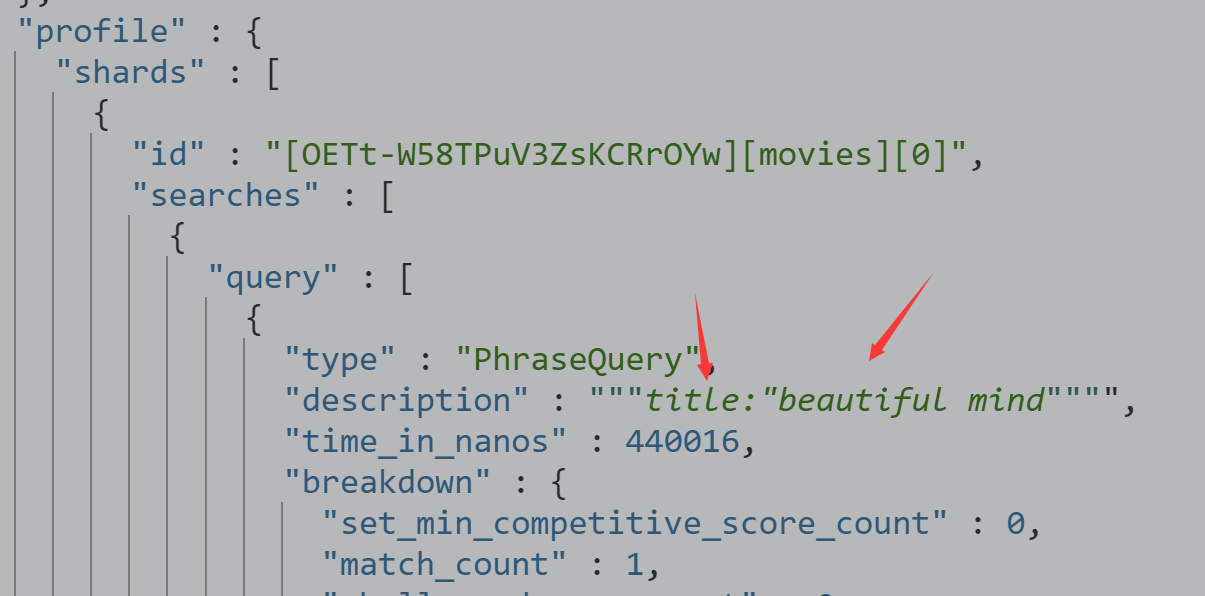
使用引号,Phrase查询
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}
把title中包含 beautiful Mind的结果查出来
分组与引号
-
title: (Beautiful AND Mind)
-
title=“Beautiful Mind”
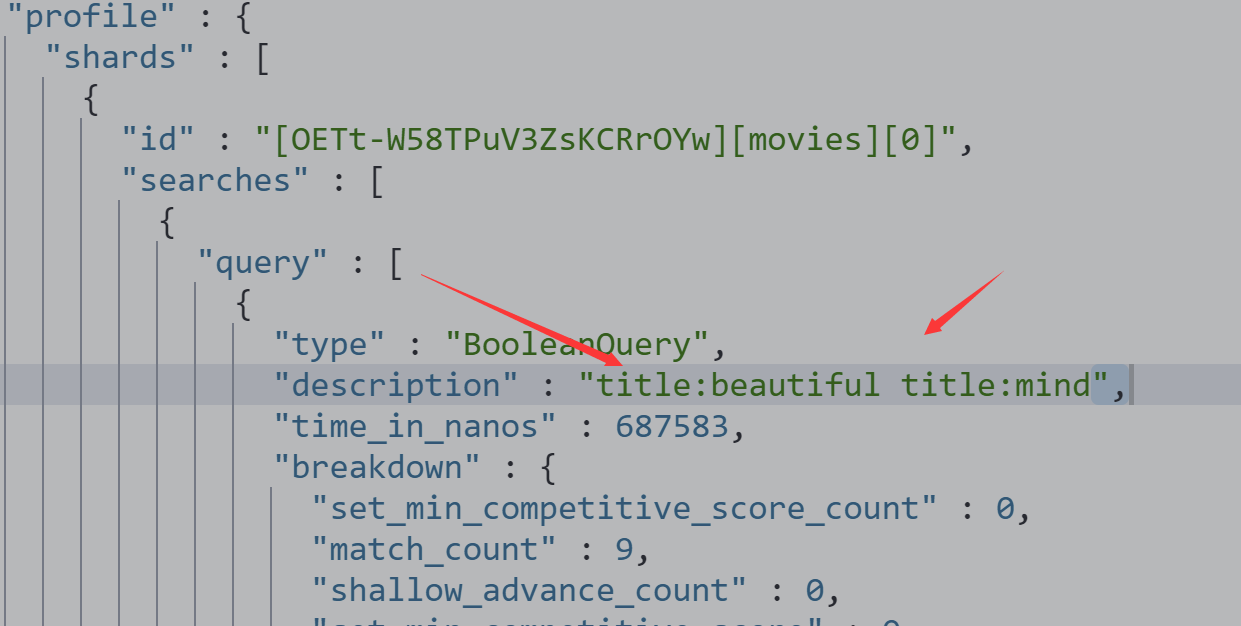
分组泛查询
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile": "true"
}
布尔查询
AND/OR/NOT或者&&/!
- 必须大写
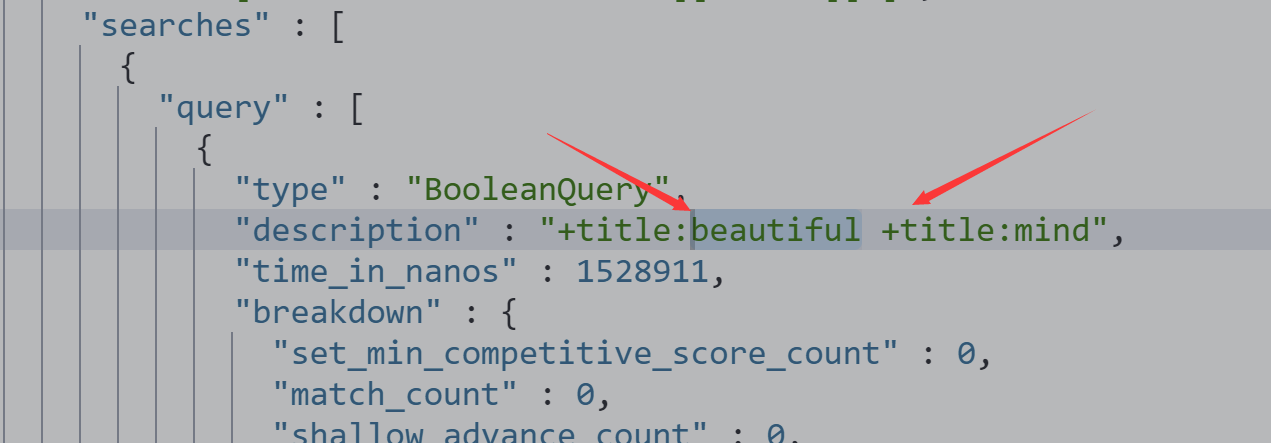
分组
-
+表示must
-
-表示must_not
GET /movies/_search?q=title:(Beautiful AND Mind)
{
"profile":"true"
}
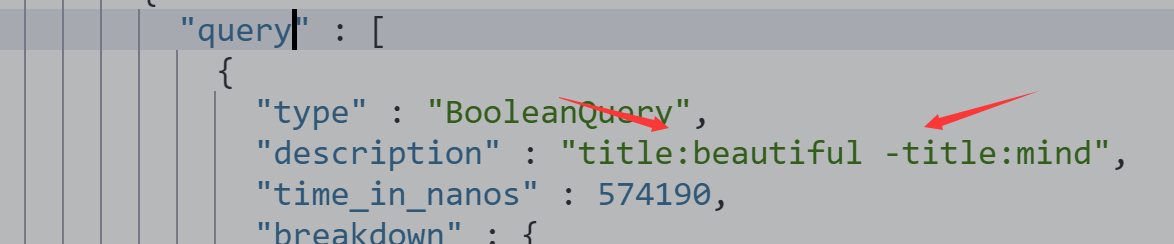
NOT 不包含
GET /movies/_search?q=title:(Beautiful NOT Mind)
{
"profile":"true"
}
包含 Beautiful 不包含Mind
范围查询
区间表示:[闭区间,{}开区间
-
year:2019to2018]
-
year:[* TO 2018]
算数符号
-
year:>2010
-
year(>2010&&<=2018
-
year:+>2010+<=2018)
查询电影大于等于1980年
GET /movies/_search?q=year>=1980
{
"profile":"true"
}
通配符查询

查询title中包含以b开头的单词
GET /movies/_search?q=title:b*
{
"profile":"true"
}
模糊匹配&近似度匹配 ~加数字可以指定运行输错几个字符
GET /movies/_search?q=title:beautifl~1
{
"profile":"true"
}

相关阅读
Request Body 与 Query DSL
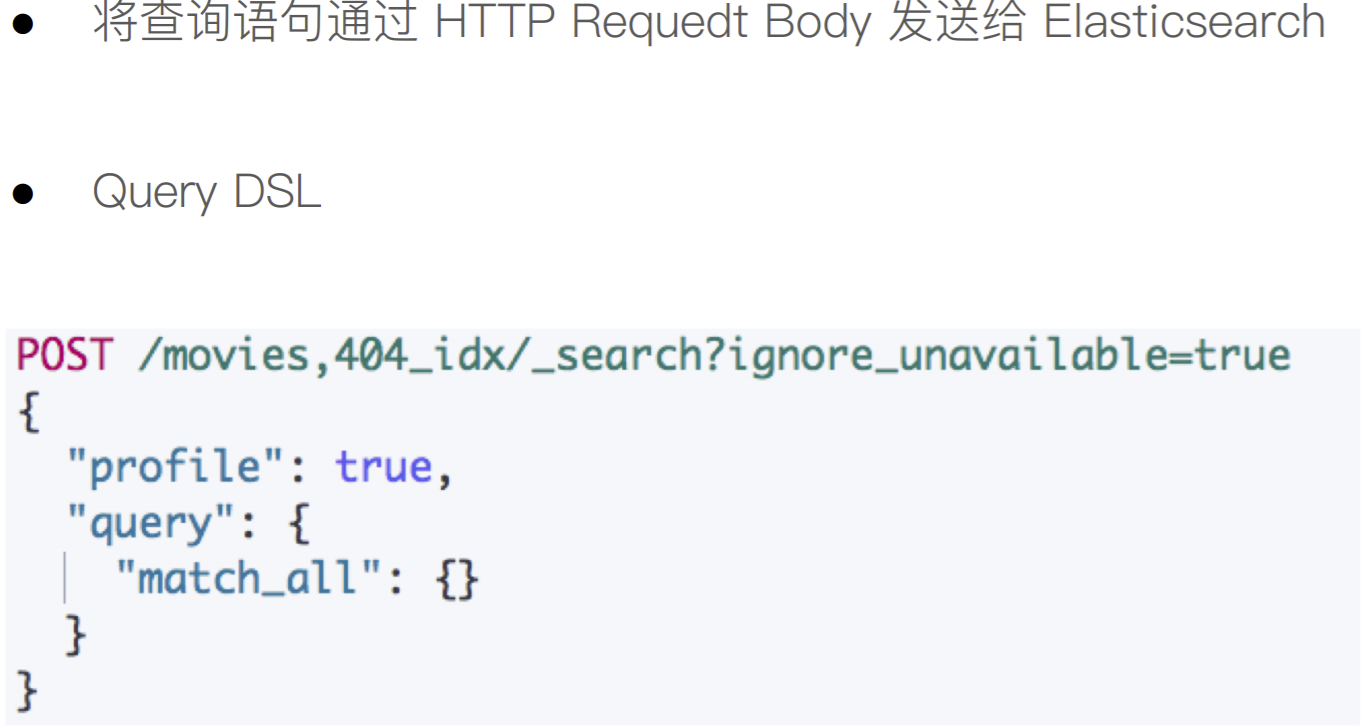
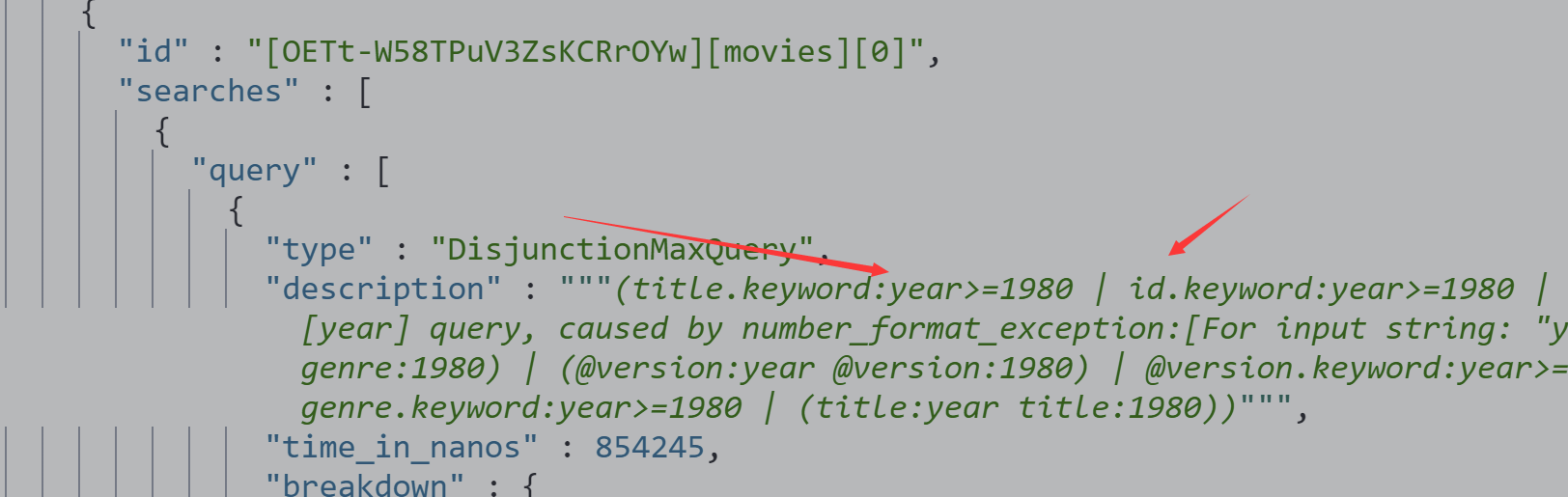
ignore_unavailable=true,可以忽略尝试访问不存在的索引“404_idx”导致的报错查询movies分页
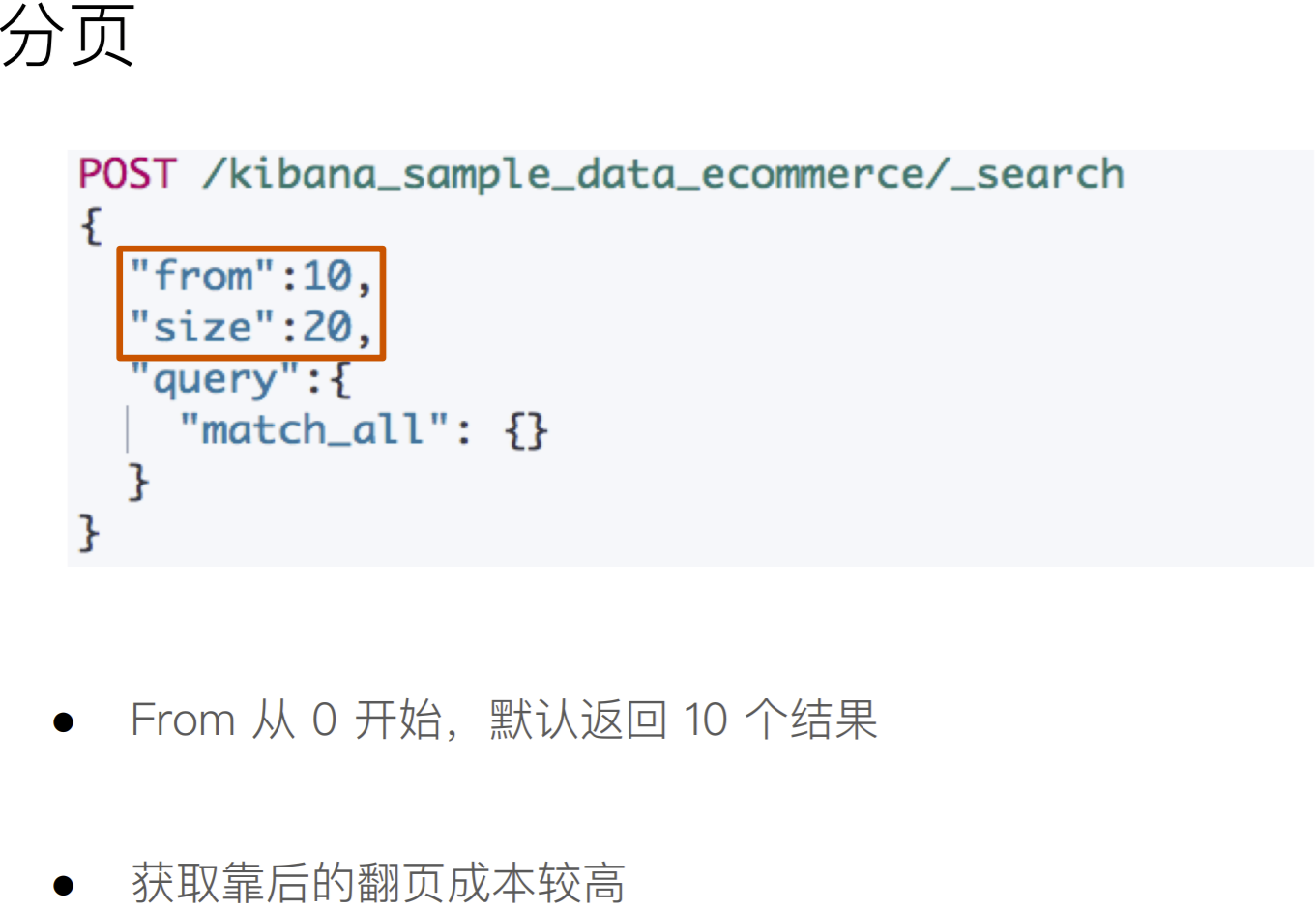
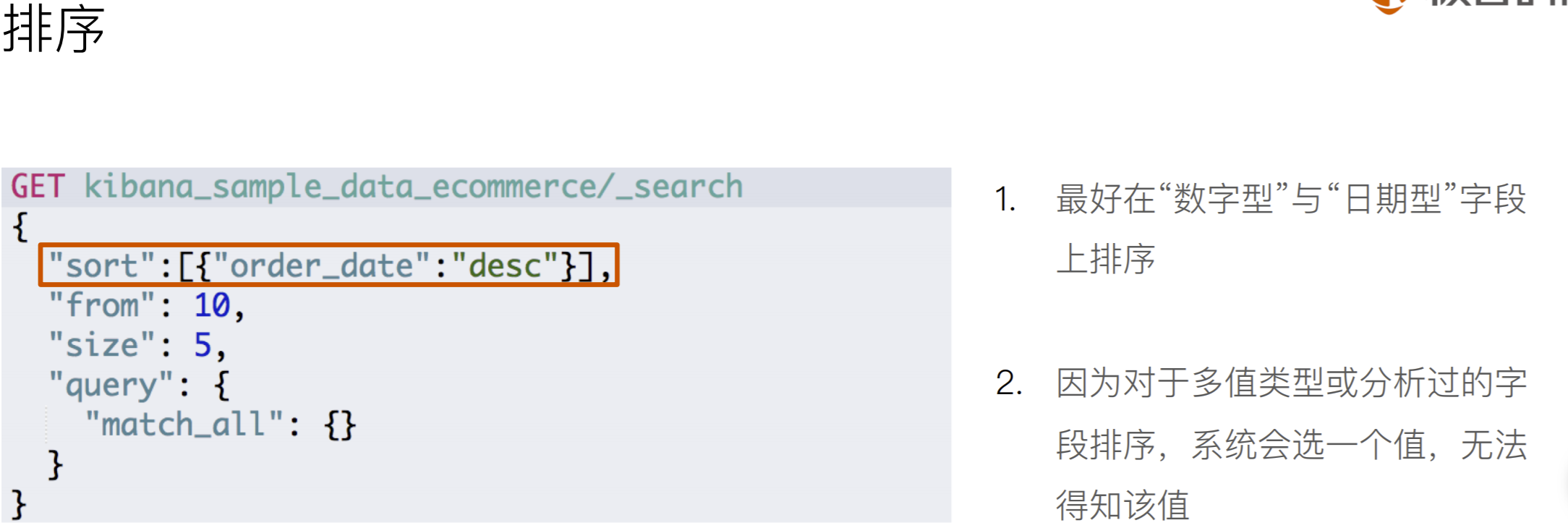
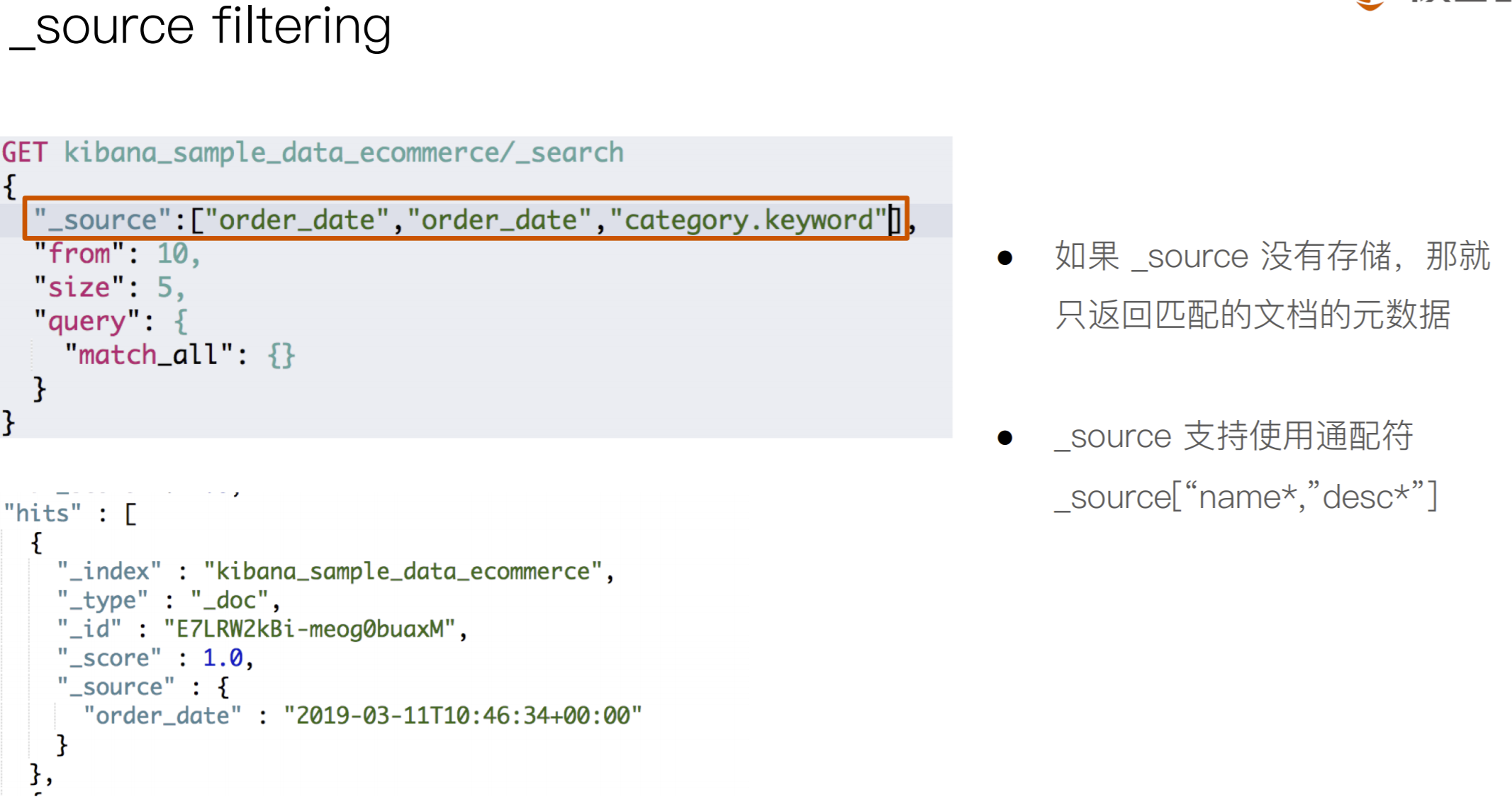
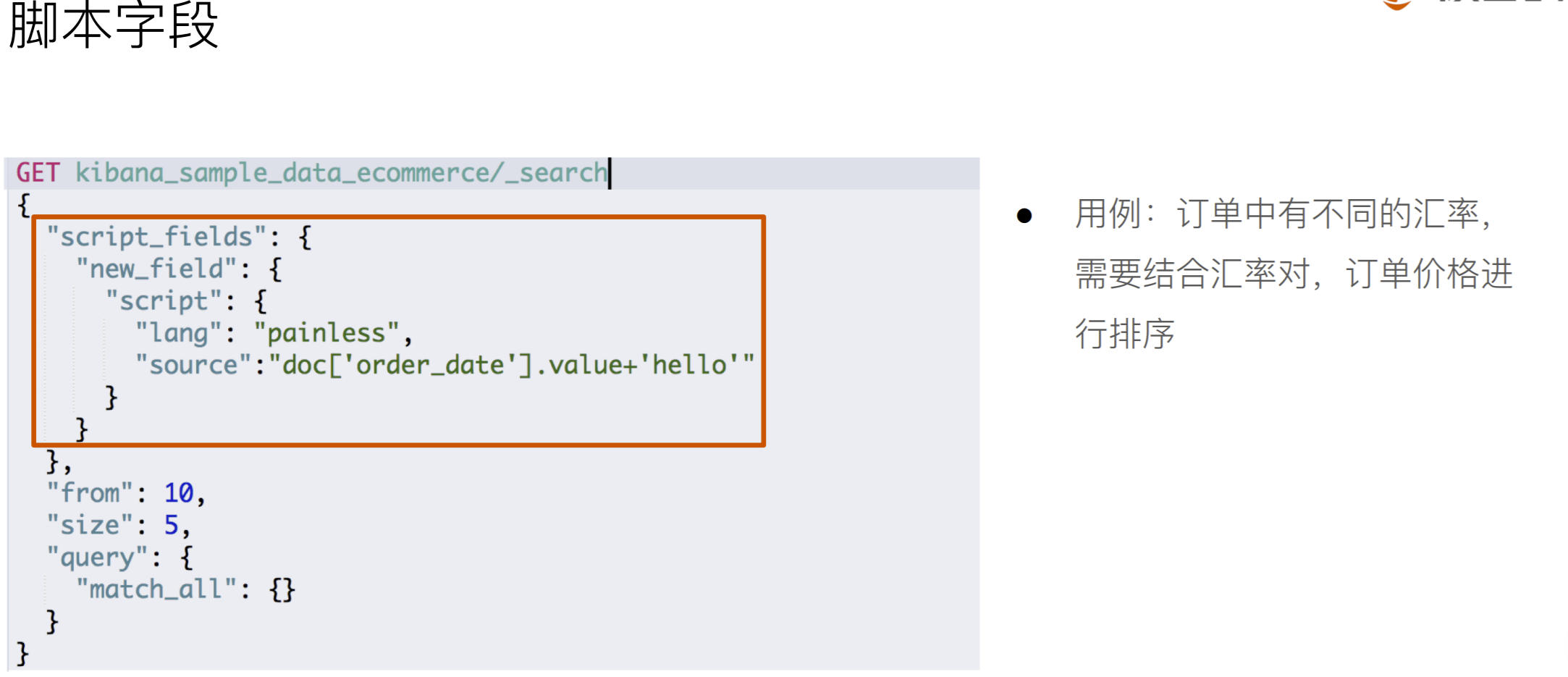
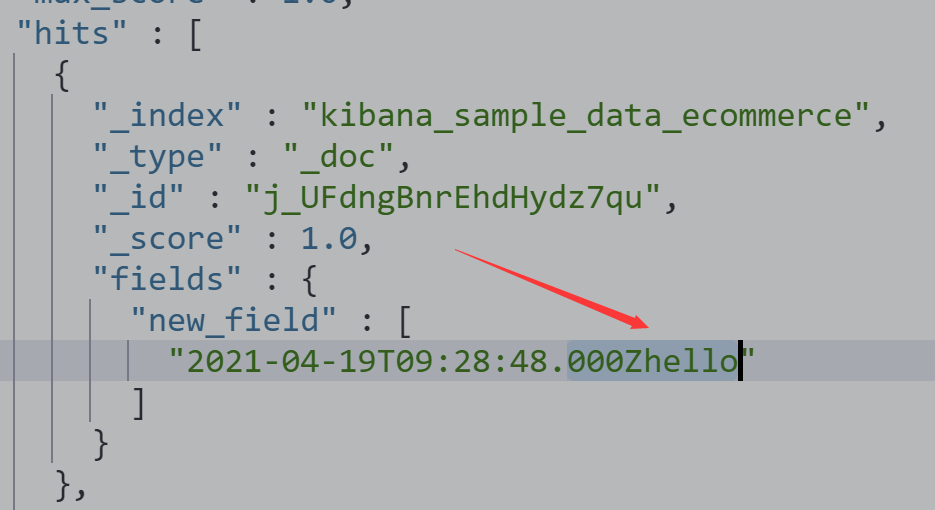
日期和hello拼接样式如下
使用查询表达式 —— Match
返回包含 last or christmas 的数据
POST movies/_search
{
"query": {
"match": {
"title": "last christmas"
}
}
}
返回包含 last christmas 的数据
POST movies/_search
{
"query": {
"match": {
"title": {
"query": "last christmas",
"operator": "and"
}
}
}
}
短语搜索 - Match Phrase 在一条语句中搜索短语
适用于在一条语句中用短语进行查询
POST movies/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love"
}
}
}
}
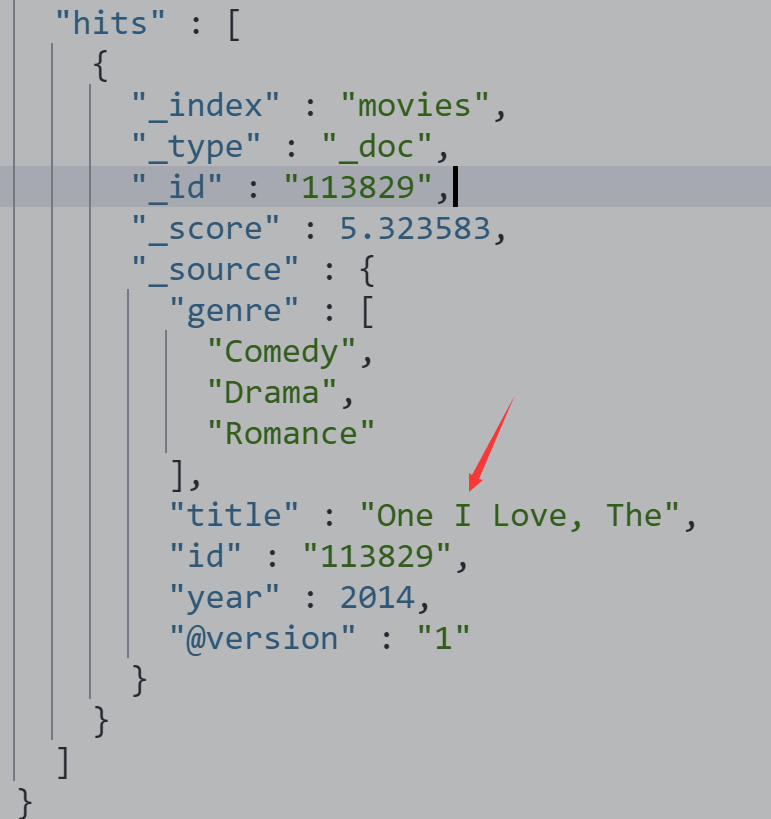
比如我们想在 title中搜索 one Love 但中间有个词不记得了,可以加入 slop参数
POST movies/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love",
"slop": 1
}
}
}
}
多字段短语匹配
POST movies/_search
{
"query": {
"multi_match": {
"query": "one love",
"type": "phrase",
"fields": ["title", "id"],
"slop": 1
}
}
}
相关阅读
Query & Simple Query String Query
数据准备
PUT /users/_doc/1 { "name":"Ruan Yiming", "about":"java, golang, node, swift, elasticsearch" } PUT /users/_doc/2 { "name":"Li Yiming", "about":"Hadoop" } POST users/_search { "query": { "query_string": { "default_field": "name", "query": "Ruan AND Yiming" } } } POST users/_search { "query": { "query_string": { "fields":["name","about"], "query": "(Ruan AND Yiming) OR (Java AND Elasticsearch)" } } }
Simple Query 默认的operator是 Or 不支持bool 表达式
POST users/_search
{
"query": {
"simple_query_string": {
"query": "Ruan AND Yiming",
"fields": ["name"]
}
}
}

operator 设置成AND
POST users/_search
{
"query": {
"simple_query_string": {
"query": "Ruan Yiming",
"fields": ["name"],
"default_operator": "AND"
}
}
}

query_string 支持复杂的表达式
查询同时出现(AND)
POST /movies/_search
{
"profile": true,
"query": {
"query_string": {
"default_field": "title",
"query": "Beautiful AND Mind"
}
}
}
查询同时出现(+)
GET /movies/_search
{
"profile": true,
"query": {
"simple_query_string": {
"query": "Beautiful +mind",
"fields": [
"title"
]
}
}
}

多fields中查询包含2012
GET /movies/_search
{
"profile": true,
"query": {
"query_string": {
"fields": [
"title",
"year"
],
"query": "2012"
}
}
}
Dynamic Mapping 和常见字段类型





相关demo演示
写入文档,查看 Mapping PUT mapping_test/_doc/1 { "firstName": "Chan", "lastName": "Jackie", "loginDate": "2018-07-24T10:29:48.103Z" } #查看 Mapping文件 GET mapping_test/_mapping #Delete index DELETE mapping_test #dynamic mapping,推断字段的类型 PUT mapping_test/_doc/1 { "uid": "123", "isVip": false, "isAdmin": "true", "age": 19, "heigh": 180 } #查看 Dynamic GET mapping_test/_mapping #默认Mapping支持dynamic,写入的文档中加入新的字段 PUT dynamic_mapping_test/_doc/1 { "newField":"someValue" } #该字段可以被搜索,数据也在_source中出现 POST dynamic_mapping_test/_search { "query": { "match": { "newField": "someValue" } } } #修改为dynamic false PUT dynamic_mapping_test/_mapping { "dynamic": false } #新增 anotherField PUT dynamic_mapping_test/_doc/10 { "anotherField": "someValue" } #该字段不可以被搜索,因为dynamic已经被设置为false POST dynamic_mapping_test/_search { "query": { "match": { "anotherField": "someValue" } } } get dynamic_mapping_test/_doc/10 #修改为strict PUT dynamic_mapping_test/_mapping { "dynamic": "strict" } #写入数据出错,HTTP Code 400 PUT dynamic_mapping_test/_doc/12 { "lastField": "value" } DELETE dynamic_mapping_test
相关阅读
显式Mapping设置与常见参数介绍
如何显示定义一个 Mapping

自定义 Mapping 的建议

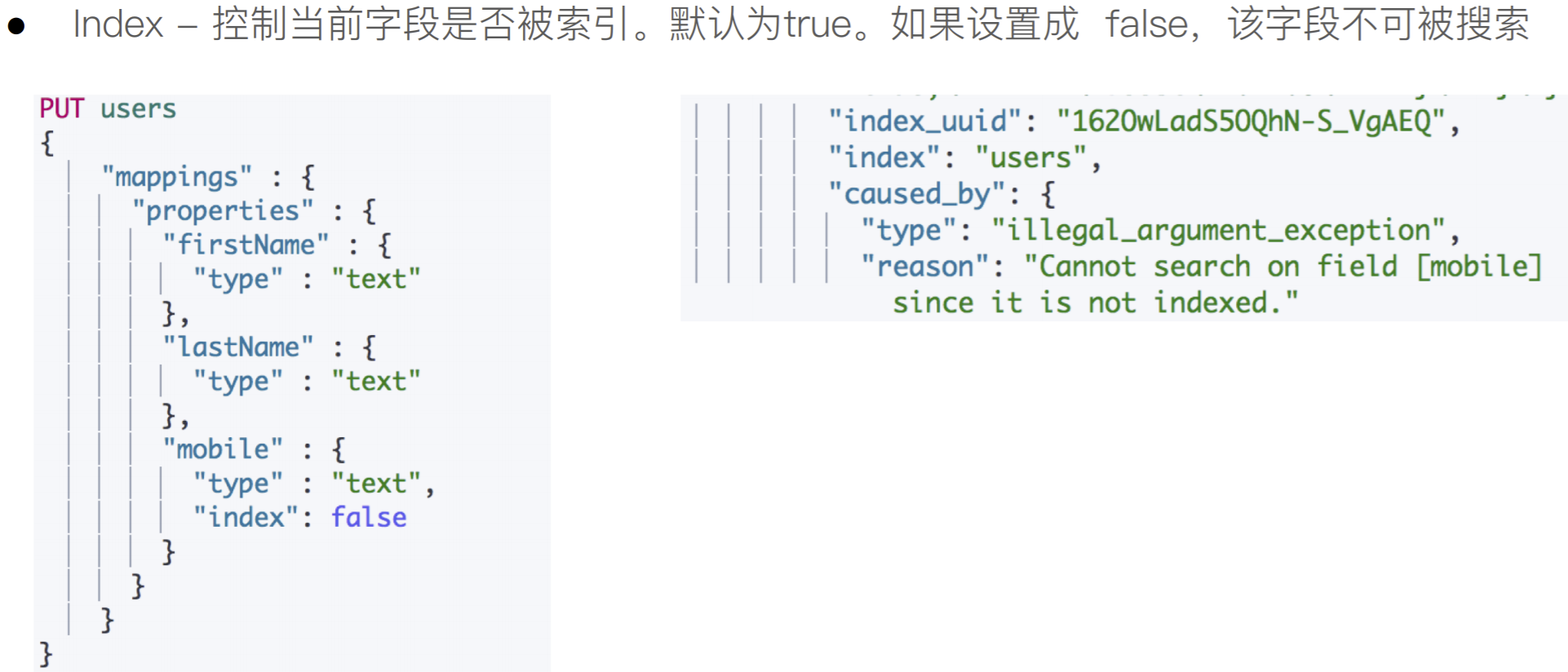
控制当前字段是否被索引
Index Options

null value

DELETE users PUT users { "mappings": { "properties": { "firstName": { "type": "text" }, "lastName": { "type": "text" }, "mobile": { "type": "keyword", "null_value": "NULL" } } } } PUT users/_doc/1 { "firstName": "Ruan", "lastName": "Yiming", "mobile": null } PUT users/_doc/2 { "firstName": "Ruan2", "lastName": "Yiming2" } GET users/_search { "query": { "match": { "mobile": "NULL" } } }

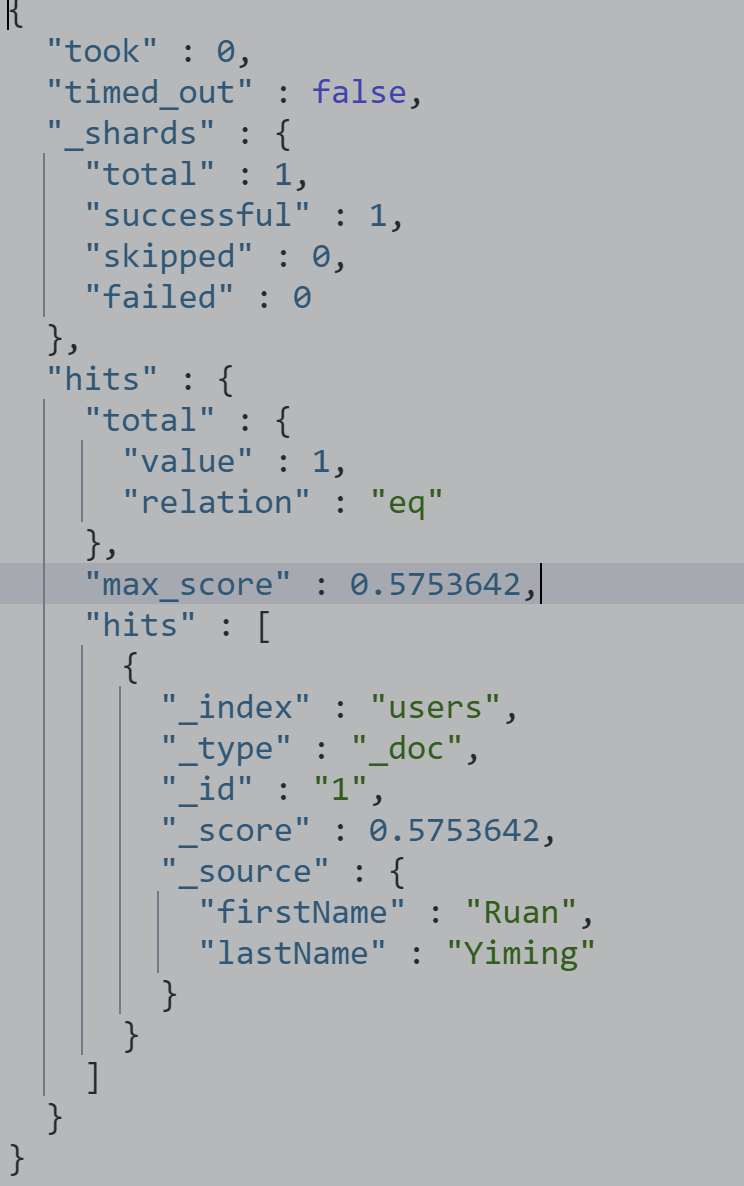
copy to

DELETE users PUT users { "mappings": { "properties": { "firstName": { "type": "text", "copy_to": "fullName" }, "lastName": { "type": "text", "copy_to": "fullName" } } } } PUT users/_doc/1 { "firstName": "Ruan", "lastName": "Yiming" } GET users/_search?q=fullName:(Ruan Yiming) POST users/_search { "query": { "match": { "fullName": { "query": "Ruan Yiming", "operator": "and" } } } }
数组类型

PUT users/_doc/1 { "name": "onebird", "interests": "reading" } PUT users/_doc/1 { "name": "twobirds", "interests": [ "reading", "music" ] } POST users/_search { "query": { "match_all": {} } } GET users/_mapping
补充阅读
多字段特性及Mapping中配置自定义Analyzer
多字段类型

Exact Values Vs Full text

Exact Values 不需要被分词
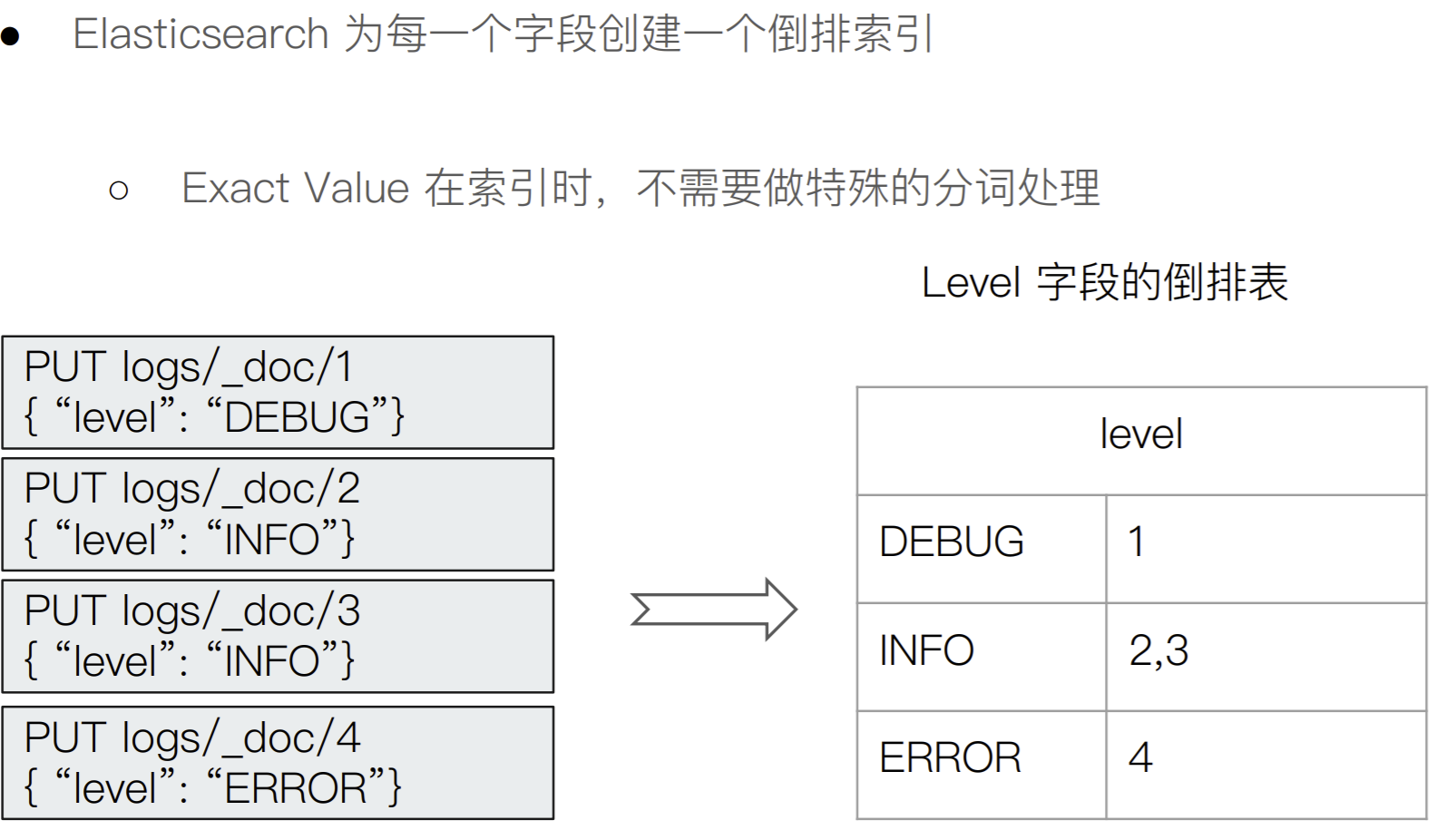
自定义分词

Character Filter

POST _analyze
{
"tokenizer": "keyword",
"char_filter": [
"html_strip"
],
"text": "<b>hello world</b>"
}

自定义分词器过滤 HTMl标签
PUT my_index { "mappings": { "properties": { "text": { "type": "text", "analyzer": "my_analyzer" } } }, "settings": { "analysis": { "analyzer": { "my_analyzer": { "tokenizer": "standard", "char_filter": [ "my_char_filter" ] } }, "char_filter": { "my_char_filter": { "type": "html_strip" } } } } } PUT my_index/_doc/1 { "text":"<b>hello world</b>" } PUT my_index/_doc/2 { "text":"<good>hello world</good>" } PUT my_index/_doc/3 { "text":"<hello>test world</hello>" } PUT my_index/_doc/4 { "text":"<hello world='1'>test 1</hello>" } GET my_index/_search { "query": { "match_all": {} } } GET my_index/_search { "query":{ "query_string":{ "query":"world" } } }
Tokenizer

POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/user/ymruan/a/b/c/d/e"
}

Tokenizer Filter

使用char filter进行替换
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type": "mapping",
"mappings": [
"- => _"
]
}
],
"text": "123-456, I-test! test-990 650-555-1234"
}

char filter 替换表情符号
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type": "mapping",
"mappings": [
":) => happy",
":( => sad"
]
}
],
"text": [
"I am felling :)",
"Feeling :( today"
]
}
white space and snowball
GET _analyze
{
"tokenizer": "whitespace",
"filter": [
"stop",
"snowball"
],
"text": [
"The gilrs in China are playing this game!"
]
}
输错结果如下
{ "tokens" : [ { "token" : "The", "start_offset" : 0, "end_offset" : 3, "type" : "word", "position" : 0 }, { "token" : "gilr", "start_offset" : 4, "end_offset" : 9, "type" : "word", "position" : 1 }, { "token" : "China", "start_offset" : 13, "end_offset" : 18, "type" : "word", "position" : 3 }, { "token" : "play", "start_offset" : 23, "end_offset" : 30, "type" : "word", "position" : 5 }, { "token" : "game!", "start_offset" : 36, "end_offset" : 41, "type" : "word", "position" : 7 } ] }
whitespace与stop
GET _analyze
{
"tokenizer": "whitespace",
"filter": [
"stop",
"snowball"
],
"text": [
"The rain in Spain falls mainly on the plain."
]
}
输错结果如下
GET _analyze
{
"tokenizer": "whitespace",
"filter": [
"stop",
"snowball"
],
"text": [
"The rain in Spain falls mainly on the plain."
]
}
输出结果下 大写的 The 还存在
{ "tokens" : [ { "token" : "The", "start_offset" : 0, "end_offset" : 3, "type" : "word", "position" : 0 }, { "token" : "rain", "start_offset" : 4, "end_offset" : 8, "type" : "word", "position" : 1 }, { "token" : "Spain", "start_offset" : 12, "end_offset" : 17, "type" : "word", "position" : 3 }, { "token" : "fall", "start_offset" : 18, "end_offset" : 23, "type" : "word", "position" : 4 }, { "token" : "main", "start_offset" : 24, "end_offset" : 30, "type" : "word", "position" : 5 }, { "token" : "plain.", "start_offset" : 38, "end_offset" : 44, "type" : "word", "position" : 8 } ] }
GET _analyze
{
"tokenizer": "whitespace",
"filter": [
"lowercase",
"stop",
"snowball"
],
"text": [
"The gilrs in China are playing this game!"
]
}
正则表达式
GET _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type": "pattern_replace",
"pattern": "http://(.*)",
"replacement": "$1"
}
],
"text": "http://www.elastic.co"
}

Dynamic Template和Index Template
什么是 Index Template

Index Template 的工作方式

Demo

创建索引模板
PUT _template/template_default
{
"index_patterns": [
"*"
],
"order": 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT /_template/template_test
{
"index_patterns": [
"test*"
],
"order": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 2
},
"mappings": {
"date_detection": false,
"numeric_detection": true
}
}
查看template信息
GET /_template/template_default GET /_template/temp*
写入新的数据,index以test开
PUT testtemplate/_doc/1
{
"someNumber":"1",
"someDate":"2019/01/01"
}
GET testtemplate/_mapping
可以看到日期没有转换成时间格式,字符串转换成数字类型

GET testtemplate/_settings
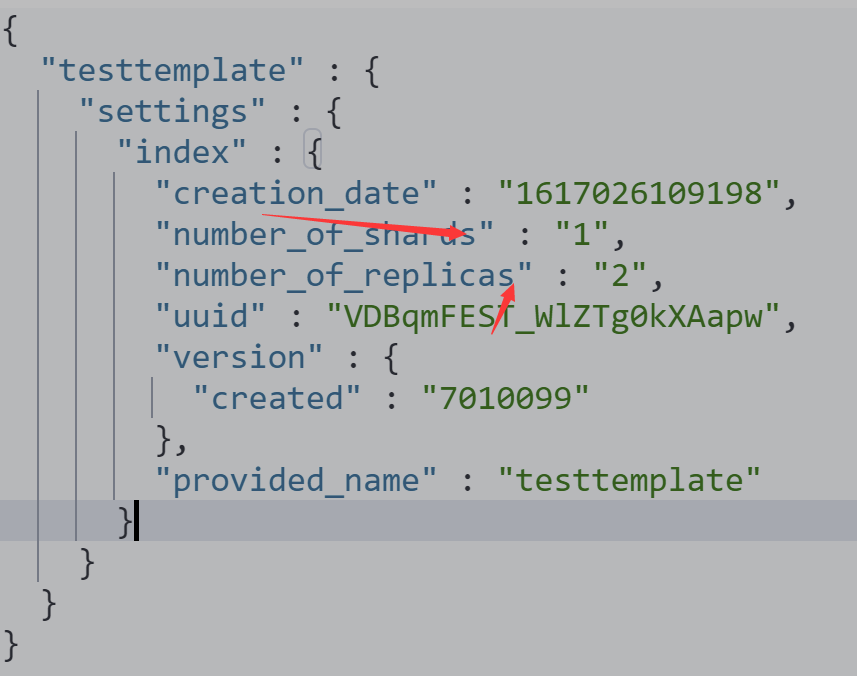
PUT testmy
{
"settings": {
"number_of_replicas": 5
}
}
PUT testmy/_doc/1
{
"key": "value"
}
GET testmy/_settings
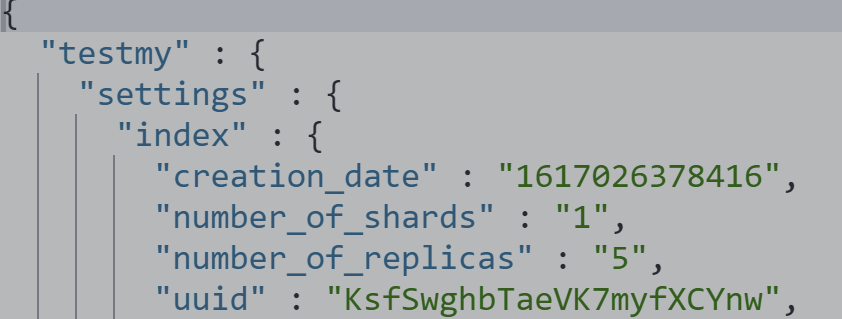
DELETE testmy DELETE /_template/template_default DELETE /_template/template_test
什么是Dynaminc Mapping

Dynaminc Template

PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string",
"match": "is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "text"
}
}
}
]
}
}
PUT my_index/_doc/2
{
"firstName":"Ruan",
"isVIP":"true"
}
GET my_index/_mapping
is开头的字段名修改成bool类,字符串的字段名设置为keyword

匹配规则参数

以name开头的字段,不以 middle结尾的
DELETE my_index #结合路径 PUT my_index { "mappings": { "dynamic_templates": [ { "full_name": { "path_match": "name.*", "path_unmatch": "*.middle", "mapping": { "type": "text", "copy_to": "full_name" } } } ] } } PUT my_index/_doc/1 { "name": { "first": "John", "middle": "Winston", "last": "Lennon" } } PUT my_index/_doc/2 { "namesamiddle": { "first": "asd", "middle": "dasd", "last": "Lennon" } } GET my_index/_search?q=full_name:John

相关阅读
Elasticsearch聚合分析简介
什么是聚合

集合的分类

Metric & Bucket
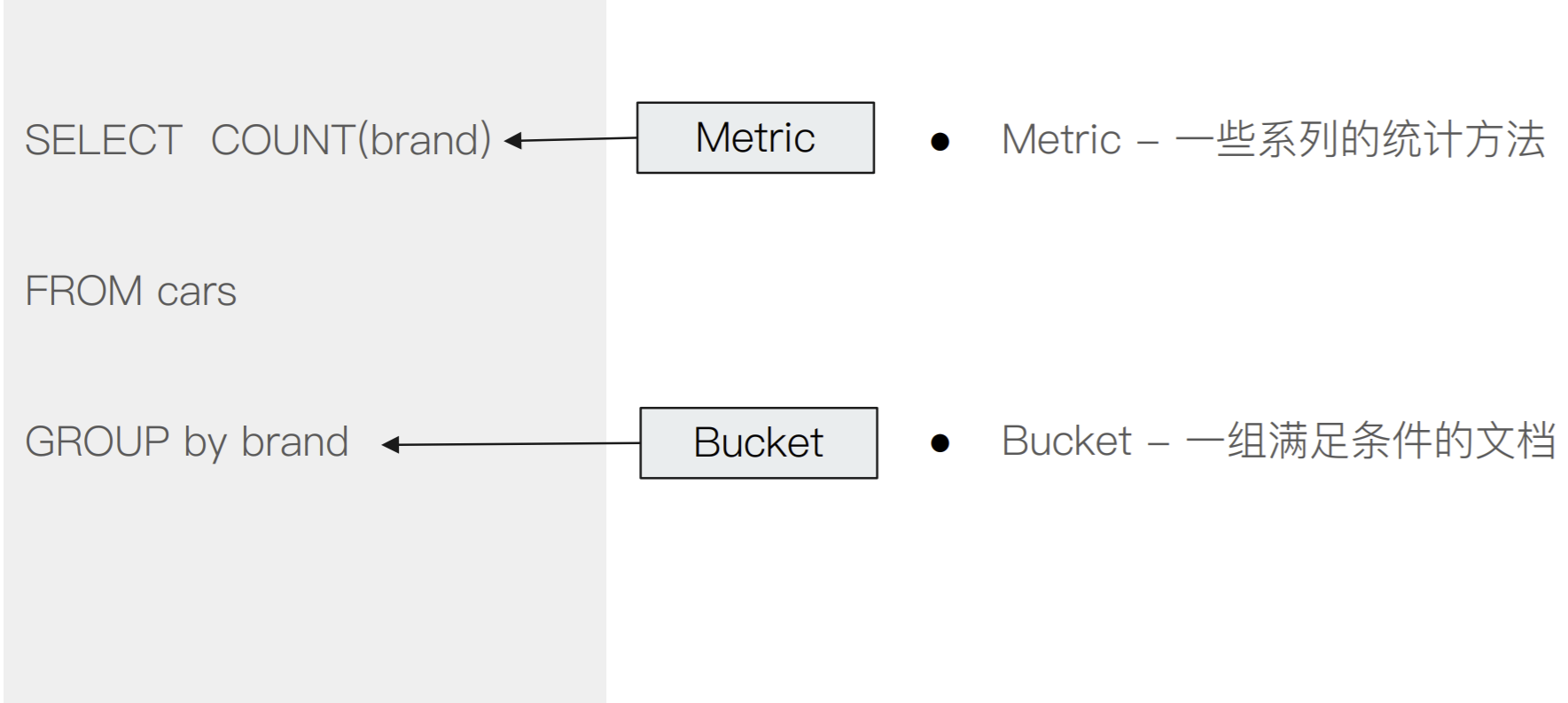
Bucket
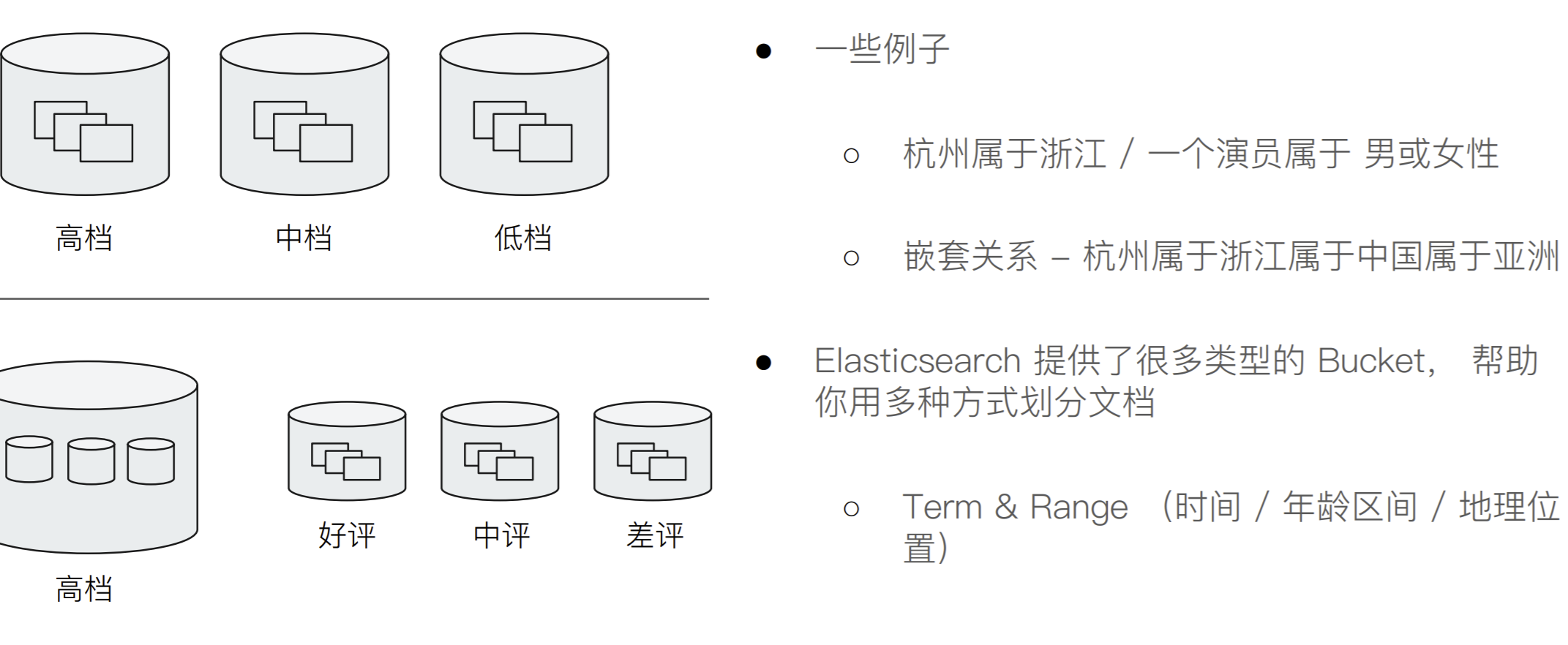
Metric

一个Bucket的例子
按照目的地进行分组统计
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry"
}
}
}
}
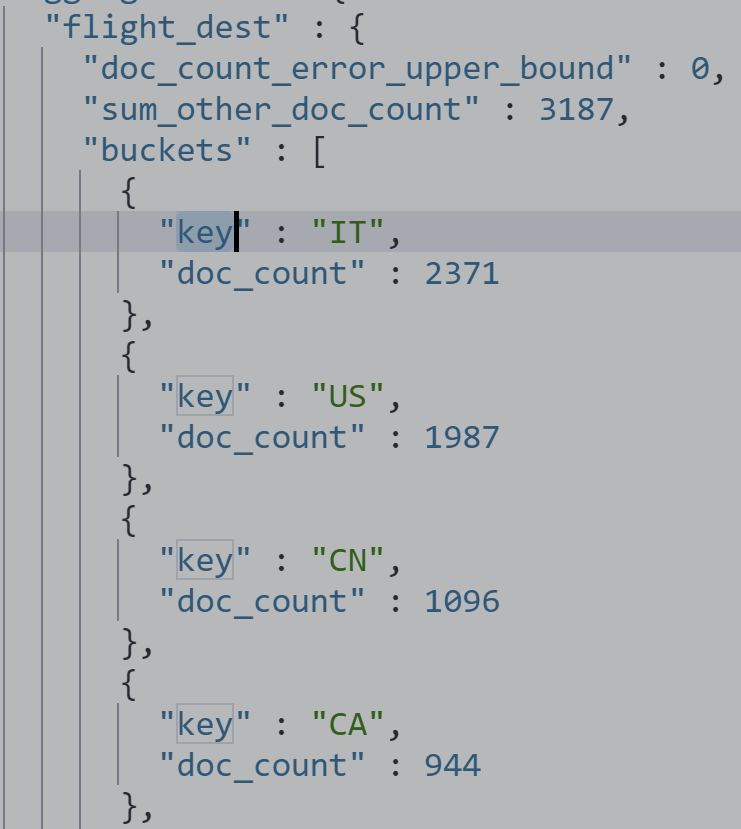
加入Metric 查看航班目的地的统计信息,增加平均,最高最低价格
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry"
},
"aggs": {
"avg_price": {
"avg": {
"field": "AvgTicketPrice"
}
},
"max_price": {
"max": {
"field": "AvgTicketPrice"
}
},
"min_price": {
"min": {
"field": "AvgTicketPrice"
}
}
}
}
}
}
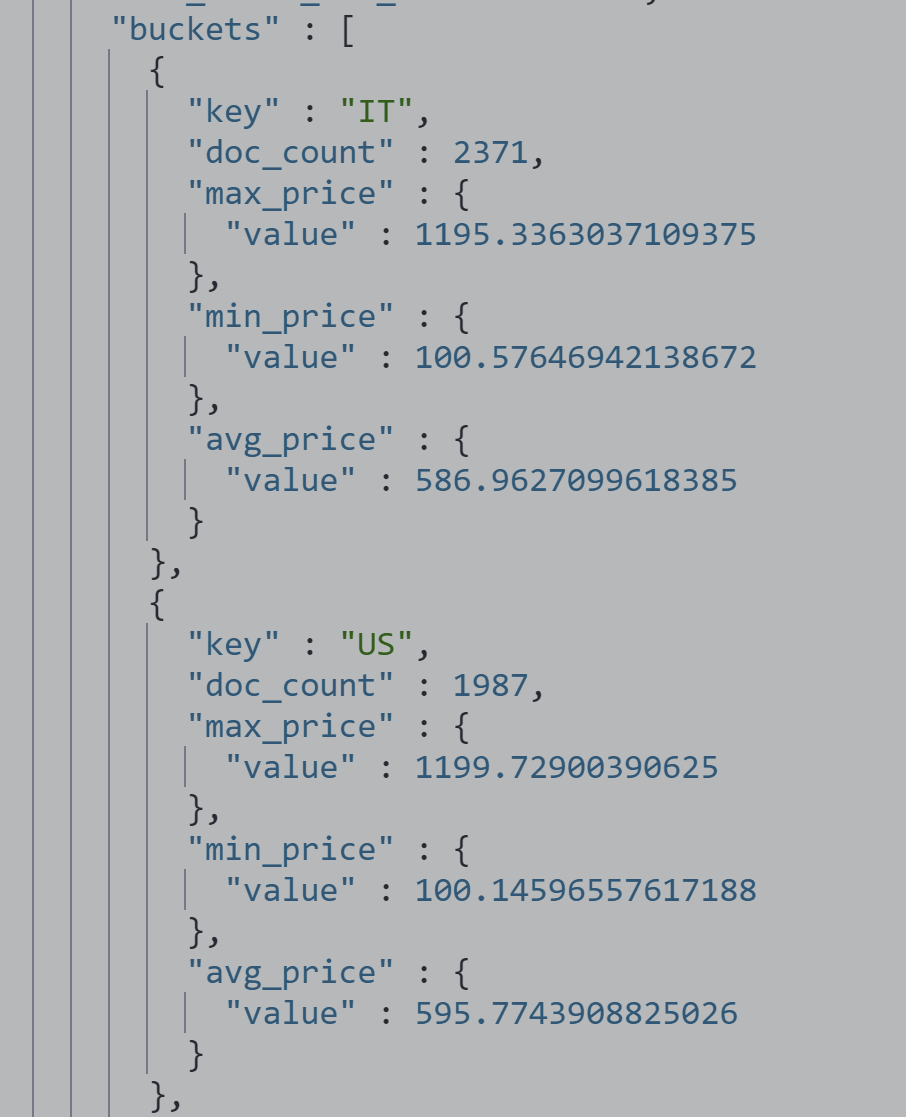
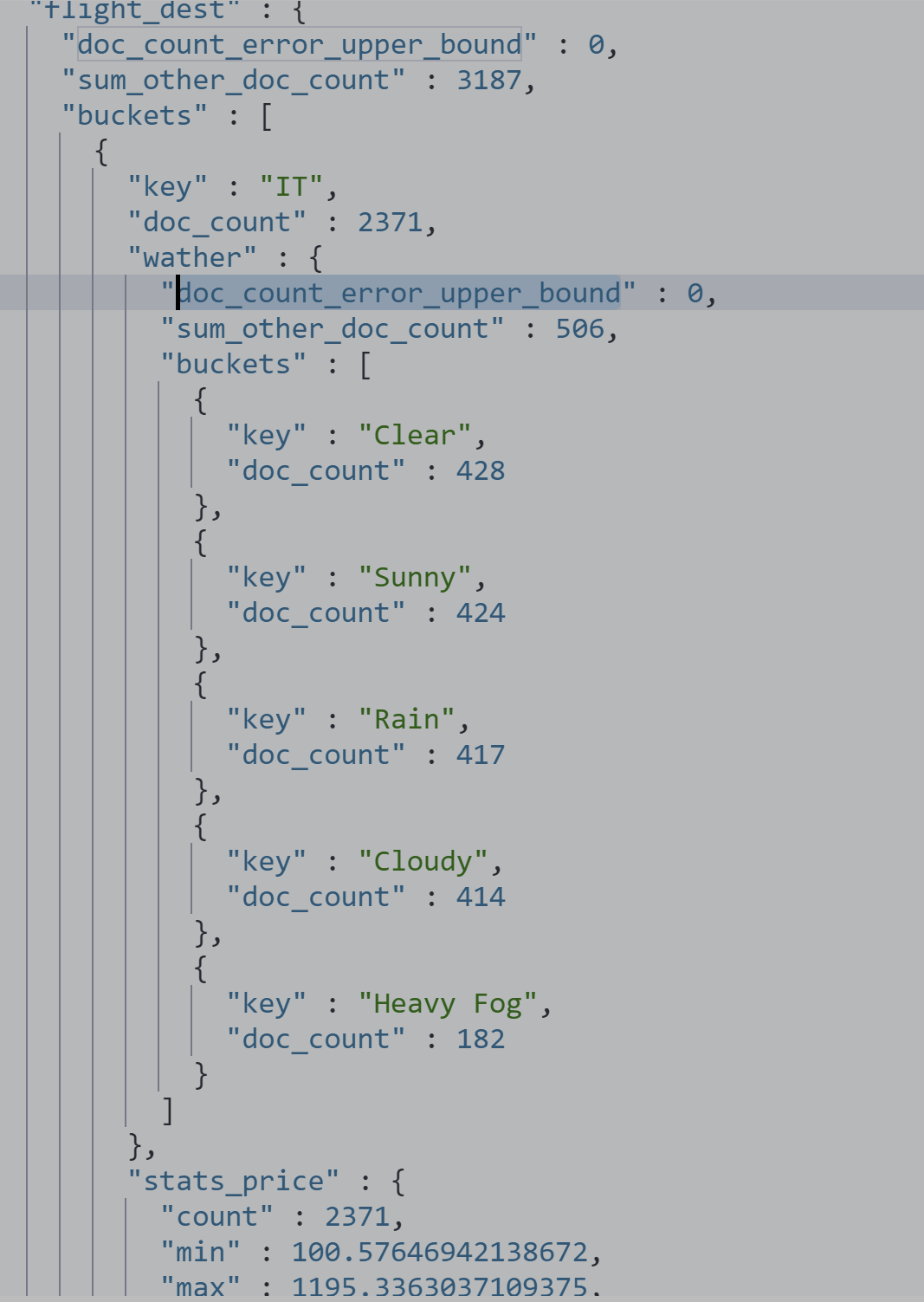
嵌套查看价格统计信息+天气信息
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry"
},
"aggs": {
"stats_price": {
"stats": {
"field": "AvgTicketPrice"
}
},
"wather": {
"terms": {
"field": "DestWeather",
"size": 5
}
}
}
}
}
}
elasticsearch 添加索引字段
PUT legislation-qa/_mapping
{
"properties": {
"repeal_date": {
"type": "date",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
查询数量超过 10000的问题
POST legislation/_search
{
"track_total_hits": true,
"query": {
"match_all": {}
}
}
自我测试

答案

测试2

答案

批量更新出现错误
Too many dynamic script compilations within, max: [75/5m]; please use indexed, or scripts with parameters instead; this limit can be changed by the [script.context.update.max_compilations_rate] setting')
大概意思就是每分钟编译的内容太多了,默认是75/5m,
那把这个设置大点就可以了:
PUT _cluster/settings
{
"transient" : {
"script.max_compilations_rate" : "1000/1m"
}
}
修改 结果返回最大数量
PUT legislation/_settings
{
"index":{
"max_result_window":1000000
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号