ES相关概念和入门操作
API简介
Elasticsearch提供了Rest风格的API,即http请求接口,而且也提供了各种语言的客户端API
Rest风格API
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
客户端API
Elasticsearch支持的客户端非常多:https://www.elastic.co/guide/en/elasticsearch/client/index.html

ElasticSearch相关概念
Elasticsearch是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
索引库(indexes)---------------------------------Databases 数据库
类型(type)----------------------------------Table 数据表
文档(Document)--------------------------Row 行
字段(Field)---------------------Columns 列
映射配置(mappings)--------- 表结构
详细说明:
| 概念 | 说明 |
|---|---|
| 索引库(indexes) | 索引库包含一堆相关业务,结构相似的文档document数据,比如说建立一个商品product索引库,里面可能就存放了所有的商品数据。 |
| 类型(type) | type是索引库中的一个逻辑数据分类,一个type下的document,都有相同的field,类似于数据库中的表。比如商品type,里面存放了所有的商品document数据。6.0版本以后一个index只能有1个type,6.0版本以前每个index里可以是一个或多个type。 |
| 文档(document) | 文档是es中的存入索引库最小数据单元,一个document可以是一条客户数据,一条商品数据,一条订单数据,通常用JSON数据结构表示。document存在索引库下的type类型中。 |
| 字段(field) | Field是Elasticsearch的最小单位。一个document里面有多个field,每个field就是一个数据字段 |
| 映射配置(mappings) | 类型对文档结构的约束叫做映射(mapping),用来定义document的每个字段的约束。如:字段的数据类型、是否分词、是否索引、是否存储等特性。类型是模拟mysql中的table概念。表是有结构的,也就是表中每个字段都有约束信息; |
索引库操作
创建索引库
Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求
语法:
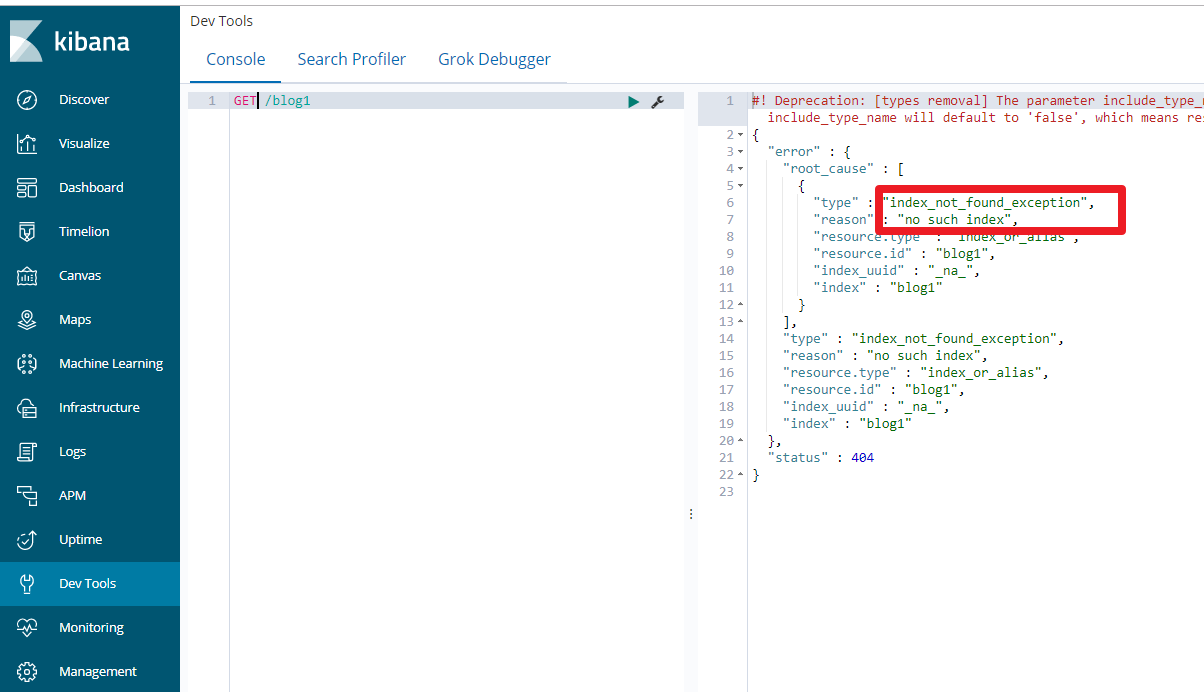
PUT /blog1
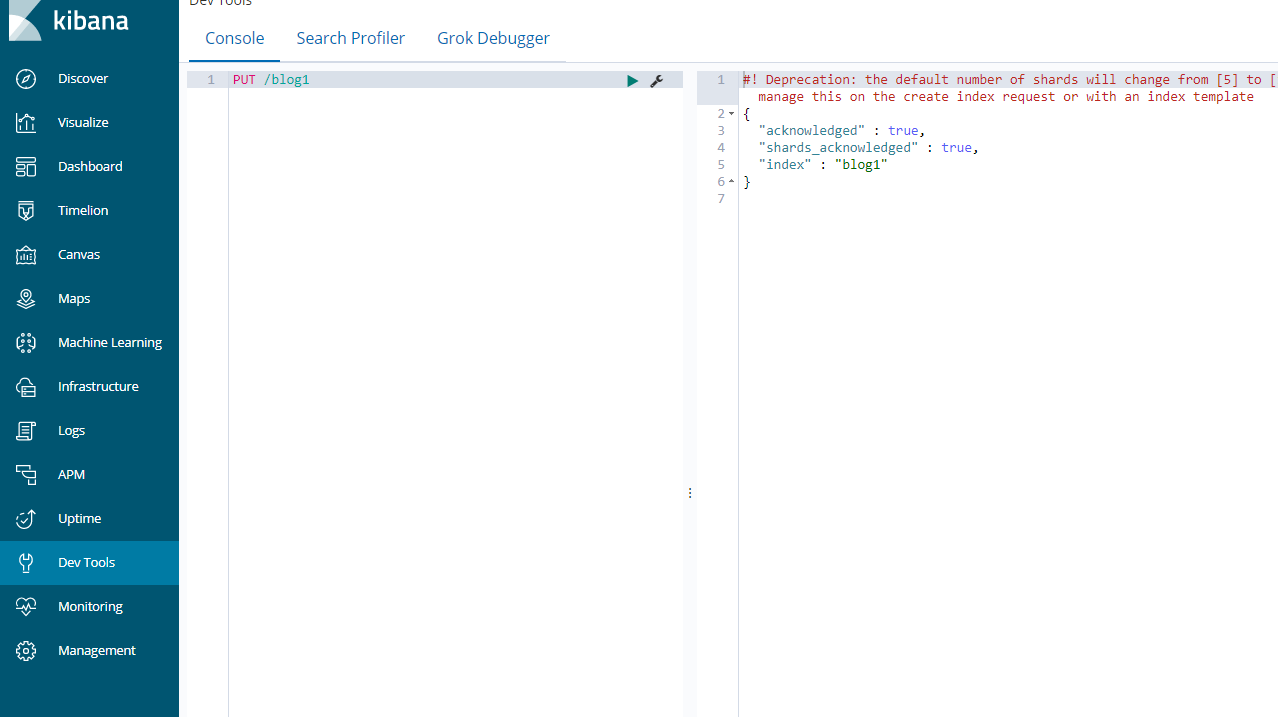
可以看到索引创建成功了。
查看索引库
语法
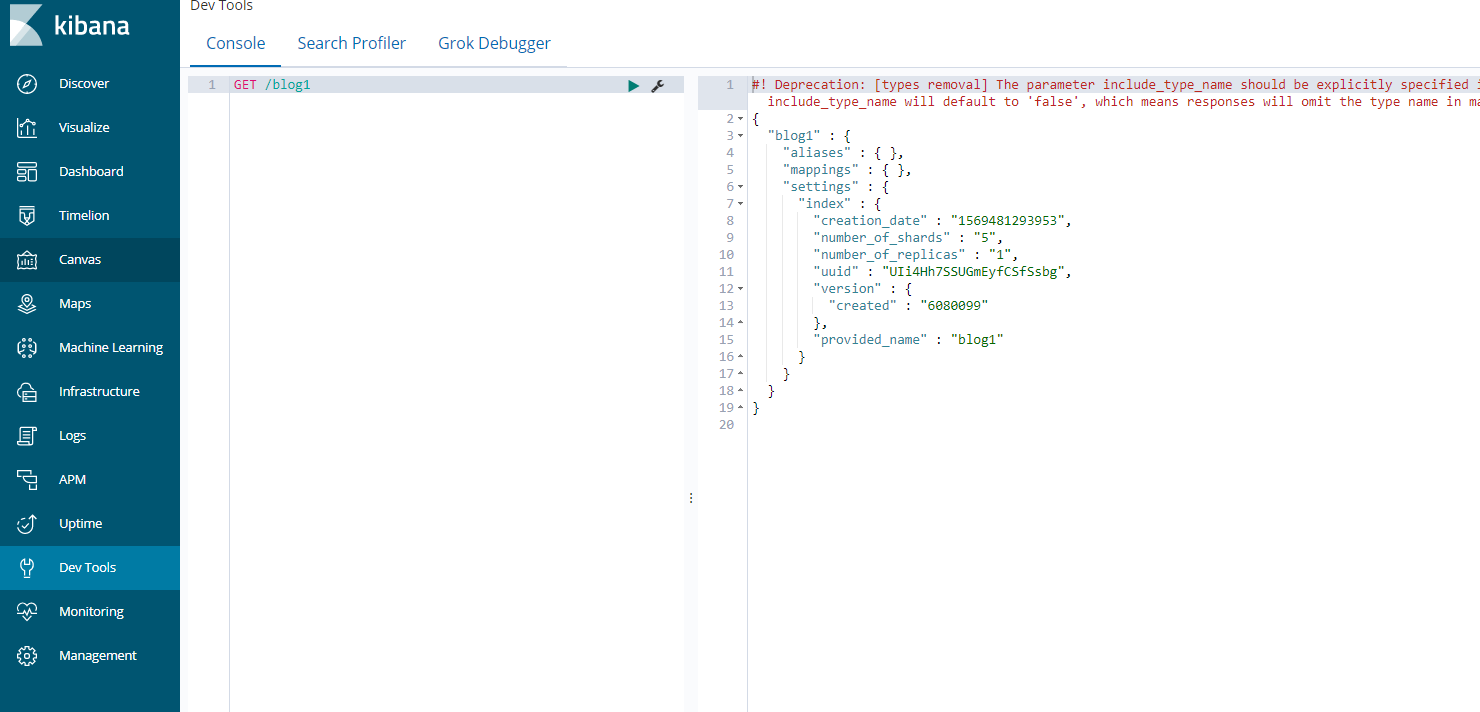
Get请求可以帮我们查看索引信息,格式:
GET /blog1
删除索引库
删除索引使用DELETE请求
DELETE /blog1
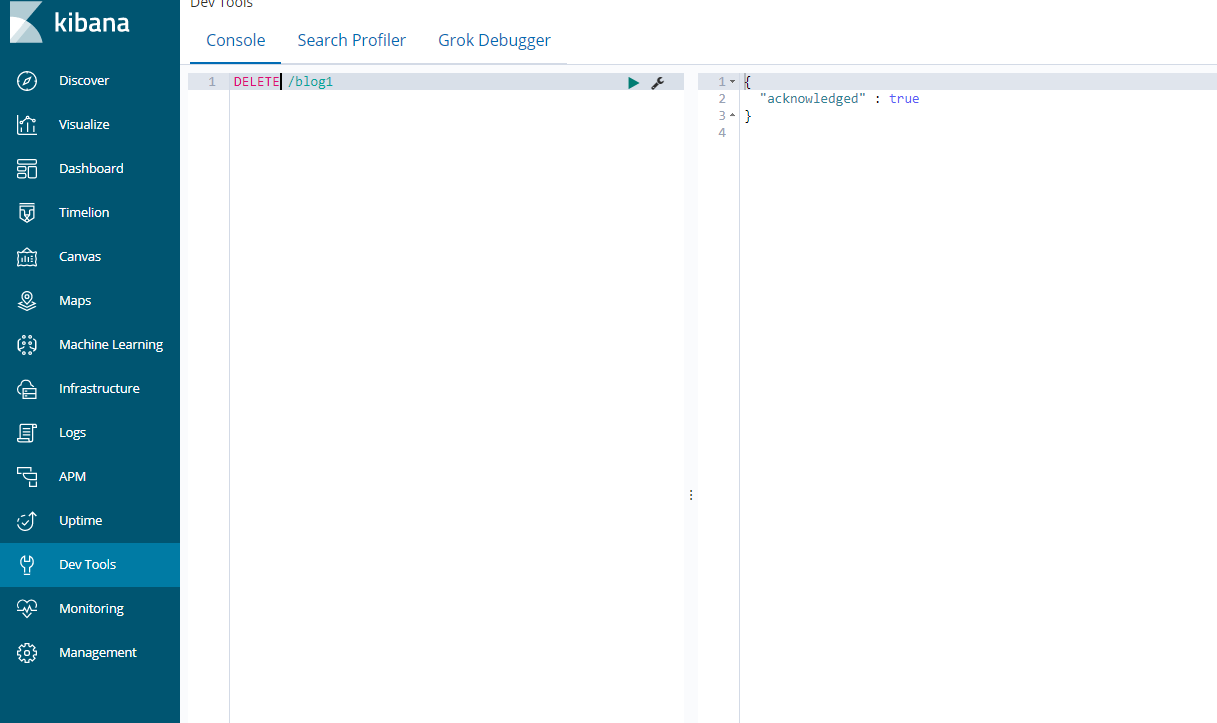
再次查看,返回索引不存在
类型及映射操作
有了索引库,等于有了数据库中的database。接下来就需要索引库中的类型了,也就是数据库中的表。创建数据库表需要设置字段约束,索引库也一样,在创建索引库的类型时,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做字段映射(mapping)
字段的约束包括但不限于:
-
字段的数据类型
-
是否要存储
-
是否要索引
-
是否分词
-
分词器是什么
创建映射字段(需先创建索引库)
请求方式依然是PUT
PUT /索引库名/_mapping/类型名称 或 索引库名/类型名称/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}
类型名称:就是前面将的type的概念,类似于数据库中的表 字段名:任意填写,下面指定许多属性,例如:
-
type:类型,可以是text、long、short、date、integer、object,keyword(关键词不分词)等
-
index:是否索引,默认为true
-
store:是否存储,默认为false
-
analyzer:分词器,这里的
ik_max_word即使用ik分词器
示例
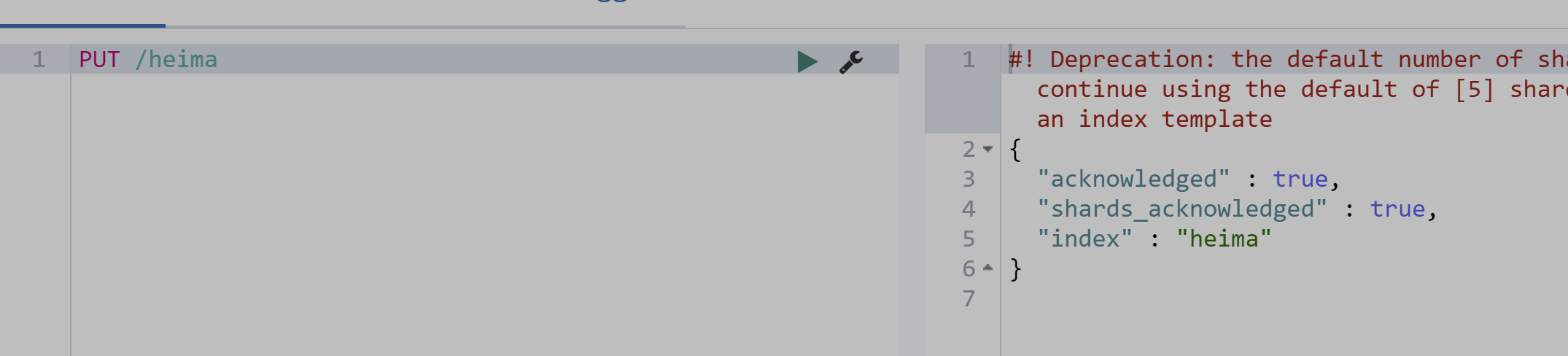
创建索引库
PUT /heima
创建good类型
发起请求
PUT /heima/_mapping/goods
{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"subtitle": {
"type": "text",
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword",
"index": "false"
},
"price": {
"type": "float"
}
}
}
响应结果:
述案例中,就给heima这个索引库添加了一个名为goods的类型,并且在类型中设置了4个字段(index默认为 true)
-
title:商品标题
-
subtitle: 商品子标题
-
images:商品图片
-
price:商品价格
并且给这些字段设置了一些属性,至于这些属性对应的含义,我们在后续会详细介绍。
映射属性详解
1)type
Elasticsearch中支持的数据类型非常丰富:
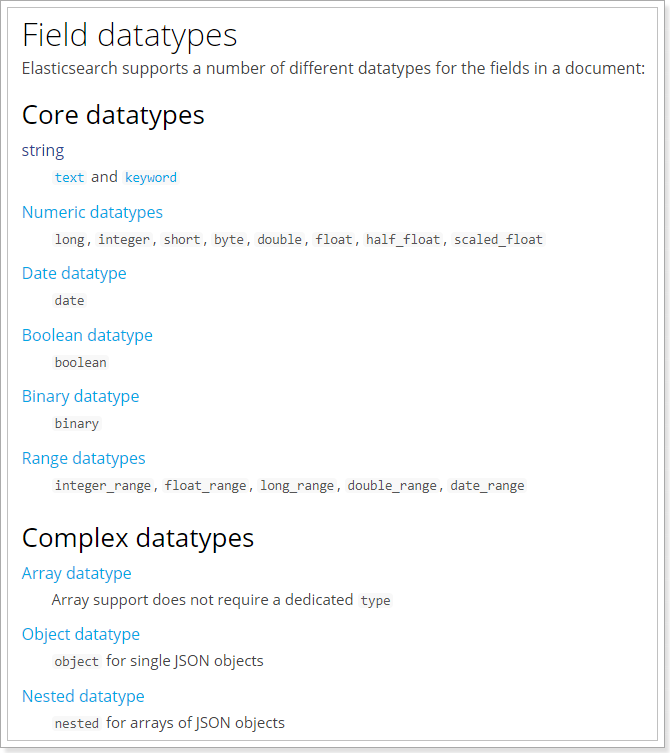
我们说几个关键的:
-
String类型,又分两种:
-
text:可分词,不可参与聚合
-
keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
-
-
Numerical:数值类型,分两类
-
基本数据类型:long、interger、short、byte、double、float、half_float
-
浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
-
-
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
-
Array:数组类型
- 进行匹配时,任意一个元素满足,都认为满足
- 排序时,如果升序则用数组中的最小值来排序,如果降序则用数组中的最大值来排序
-
Object:对象
{
name:"Jack",
age:21,
girl:{
name: "Rose", age:21
}
}
如果存储到索引库的是对象类型,例如上面的girl,会把girl变成两个字段:girl.name和girl.age
2)index
index影响字段的索引情况。
-
true:字段会被索引,则可以用来进行搜索。默认值就是true
-
false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。
3)store
是否将数据进行独立存储。
原始的文本会存储在_source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的。当然你也可以独立的存储某个字段,只要设置store:true即可,获取独立存储的字段要比从_source中解析快得多,但是也会占
用更多的空间,所以要根据实际业务需求来设置,默认为false。
查看映射关系
语法
GET /索引库名/_mapping/类型名
示例:
GET /heima/_mapping/goods
响应:
{
"heima": {
"mappings": {
"goods": {
"properties": {
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "float"
},
"subtitle": {
"type": "text",
"analyzer": "ik_max_word"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}
一次创建索引库和类型
刚才 的案例中我们是把创建索引库和类型分开来做,其实也可以在创建索引库的同时,直接制定索引库中的类型,基本语法:
put /索引库名
{
"settings":{
"索引库属性名":"索引库属性值"
},
"mappings":{
"类型名":{
"properties":{
"字段名":{
"映射属性名":"映射属性值"
}
}
}
}
}
来试一下吧:
PUT /heima2
{
"settings": {},
"mappings": {
"goods": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
结果:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "heima2"
}
文档操作
文档,即索引库中某个类型下的数据,会根据规则创建索引,将来用来搜索。可以类比做数据库中的每一行数据。
新增文档
新增并随机生成id
通过POST请求,可以向一个已经存在的索引库中添加文档数据。
语法:
POST /索引库名/类型名
{
"key":"value"
}
示例:
POST /heima/goods/
{
"title":"小米手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":2699.00
}
响应
{
"_index" : "heima",
"_type" : "goods",
"_id" : "vpPxHXgBhodHYWpOg0Bo",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
可以看到结果显示为:created,应该是创建成功了。
另外,需要注意的是,在响应结果中有个_id字段,这个就是这条文档数据的唯一标示,以后的增删改查都依赖这个id作为唯一标示。
可以看到id的值为:vpPxHXgBhodHYWpOg0Bo,这里我们新增时没有指定id,所以是ES帮我们随机生成的id。
查看文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把刚刚生成数据的id带上。
GET /heima/goods/2a3UTW0BTp_XthqB6lMH
查看结果:
{
"_index": "heima",
"_type": "goods",
"_id": "2a3UTW0BTp_XthqB6lMH",
"_version": 1,
"found": true,
"_source": {
"title": "小米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
}
-
_source:源文档信息,所有的数据都在里面。 -
_id:这条文档的唯一标
新增文档并自定义id
如果我们想要自己新增的时候指定id,可以这么做:
POST /索引库名/类型/id值
{
...
}
示例:
POST /heima/goods/2
{
"title":"大米手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":2899.00
}
得到的数据:
{
"_index": "heima",
"_type": "goods",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
修改数据
把刚才新增的请求方式改为PUT,就是修改了。不过修改必须指定id,
-
id对应文档存在,则修改
-
id对应文档不存在,则新增
比如,我们把使用id为3,不存在,则应该是新增:
PUT /heima/goods/3
{
"title":"超米手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":3899.00
}
结果:
{
"_index": "heima",
"_type": "goods",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
可以看到是created,是新增。
我们再次执行刚才的请求,不过把数据改一下:
PUT /heima/goods/3
{
"title":"超大米手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":3299.00
}
查看结果:
{
"_index": "heima",
"_type": "goods",
"_id": "3",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
可以看到结果是:updated,显然是更新数据
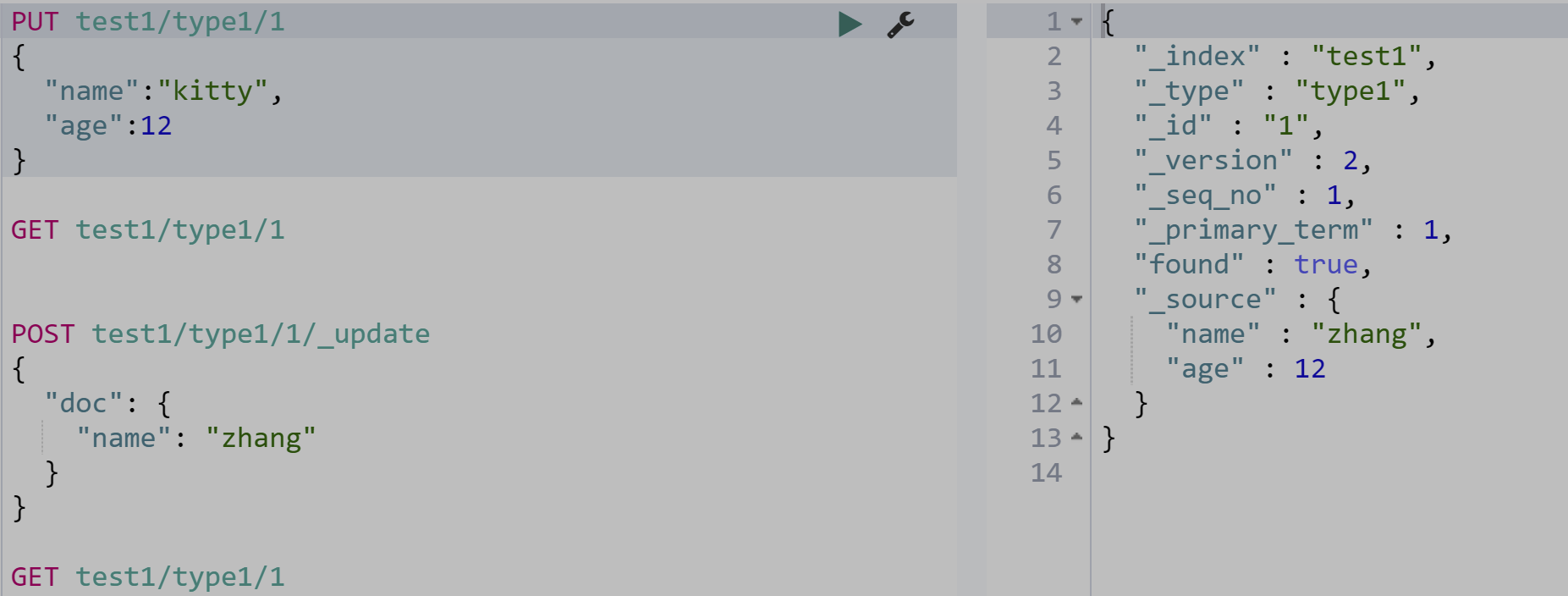
post修改制定的字段
语法 _update doc
PUT test1/type1/1
{
"name":"kitty",
"age":12
}
GET test1/type1/1
POST test1/type1/1/_update
{
"doc": {
"name": "zhang"
}
}
GET test1/type1/1
删除数据
1)根据id进行删除:
语法
DELETE /索引库名/类型名/id值
实例:
DELETE heima/goods/3
结果:
{
"_index": "heima",
"_type": "goods",
"_id": "3",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
可以看到结果是:deleted,显然是删除数据
2)根据查询条件进行删除
语法
POST /索引库名/_delete_by_query
{
"query": {
"match": {
"字段名": "搜索关键字"
}
}
}
示例:
POST heima/_delete_by_query
{
"query": {
"match": {
"title": "小米"
}
}
}
结果:
{
"took": 269,
"timed_out": false,
"total": 1,
"deleted": 1,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
删除所有数据
POST 索引库名/_delete_by_query
{
"query": {
"match_all": {}
}
}
示例:
POST heima/_delete_by_query
{
"query": {
"match_all": {}
}
}
结果:
{
"took": 11,
"timed_out": false,
"total": 1,
"deleted": 1,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
查询
我们从7块来讲查询:
- 基本查询
_source过滤- 结果过滤
- 高级查询
- 排序
- 高亮
- 分页
导入数据,这里是采用批处理的API,大家直接复制到kibana运行即可,注意千万别使用kibana的格式化
POST /heima/goods/_bulk
{"index":{}}
{"title":"大米手机","images":"http://image.leyou.com/12479122.jpg","price":3288}
{"index":{}}
{"title":"小米手机","images":"http://image.leyou.com/12479122.jpg","price":2699}
{"index":{}}
{"title":"小米电视4A","images":"http://image.leyou.com/12479122.jpg","price":4288}
基本查询
基本语法
POST /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
-
查询类型:
- 例如:
match_all,match,term,range等等
- 例如:
-
查询条件:查询条件会根据类型的不同,写法也有差异,后面详细讲解
查询所有(match_all)
示例:
POST /heima/_search
{
"query":{
"match_all": {}
}
}
-
query:代表查询对象 -
match_all:代表查询所有
结果:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "3a3hTW0BTp_XthqB2lMR",
"_score": 1,
"_source": {
"title": "大米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 3288
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "3q3hTW0BTp_XthqB2lMR",
"_score": 1,
"_source": {
"title": "小米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "363hTW0BTp_XthqB2lMR",
"_score": 1,
"_source": {
"title": "小米电视4A",
"images": "http://image.leyou.com/12479122.jpg",
"price": 4288
}
}
]
}
}
-
took:查询花费时间,单位是毫秒
-
time_out:是否超时
-
_shards:分片信息
-
hits:搜索结果总览对象
-
total:搜索到的总条数
-
max_score:所有结果中文档得分的最高分
-
hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
-
_index:索引库
-
_type:文档类型
-
_id:文档id
-
_score:文档得分
-
_source:文档的源数据
-
-
匹配查询(match)
现在,索引库中有2部手机,1台电视;
- 默认 or 关系
match类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系
POST /heima/_search
{
"query":{
"match":{
"title":"小米电视4A"
}
}
}
结果:
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 2.5141225,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "363hTW0BTp_XthqB2lMR",
"_score": 2.5141225,
"_source": {
"title": "小米电视4A",
"images": "http://image.leyou.com/12479122.jpg",
"price": 4288
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "3q3hTW0BTp_XthqB2lMR",
"_score": 0.22108285,
"_source": {
"title": "小米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
}
]
}
}
在上面的案例中,不仅会查询到电视,而且与小米相关的都会查询到,多个词之间是or的关系。
- and关系
某些情况下,我们需要更精确查找,我们希望这个关系变成and,可以这样做:
POST /heima/_search
{
"query": {
"match": {
"title": {
"query": "小米电视4A",
"operator": "and"
}
}
}
}
结果:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 2.5141225,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "363hTW0BTp_XthqB2lMR",
"_score": 2.5141225,
"_source": {
"title": "小米电视4A",
"images": "http://image.leyou.com/12479122.jpg",
"price": 4288
}
}
]
}
}
本例中,只有同时包含小米和电视的词条才会被搜索到。
多字段查询(multi_match)
multi_match与match类似,不同的是它可以在多个字段中查询
为了测试效果我们在这里新增一条数据:
POST /heima/goods
{
"title": "华为手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 5288,
"subtitle": "小米"
}
示例:
POST /heima/_search
{
"query": {
"multi_match": {
"query": "小米",
"fields": ["title","subtitle"]
}
}
}
结果:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.5442147,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "3q3hTW0BTp_XthqB2lMR",
"_score": 0.5442147,
"_source": {
"title": "小米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "363hTW0BTp_XthqB2lMR",
"_score": 0.36928856,
"_source": {
"title": "小米电视4A",
"images": "http://image.leyou.com/12479122.jpg",
"price": 4288
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "5a3yTW0BTp_XthqBcFOL",
"_score": 0.2876821,
"_source": {
"title": "华为手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 5288,
"subtitle": "小米"
}
}
]
}
}
本例中,我们会假设在title字段和subtitle字段中查询小米这个词
词条匹配 (term)
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串
POST /heima/_search
{
"query":{
"term":{
"price":2699
}
}
}
---------------------
POST /heima/_search
{
"query": {
"term": {
"price": {
"value": "2699"
}
}
}
}
结果:
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "3q3hTW0BTp_XthqB2lMR",
"_score": 1,
"_source": {
"title": "小米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
}
]
}
}
多词条精确匹配(terms)
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于mysql的in:
POST /heima/_search
{
"query":{
"terms":{
"price":[2699,5288]
}
}
}
结果:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "heima",
"_type": "goods",
"_id": "3q3hTW0BTp_XthqB2lMR",
"_score": 1,
"_source": {
"title": "小米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2699
}
},
{
"_index": "heima",
"_type": "goods",
"_id": "5a3yTW0BTp_XthqBcFOL",
"_score": 1,
"_source": {
"title": "华为手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 5288,
"subtitle": "小米"
}
}
]
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号