ES简介及软件安装
Elasticsearch简介
什么是Elasticsearch
Elaticsearch简称为es,是一个开源的可扩展的全文检索引擎服务器,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es使用Java开发并使用Lucene作为其核心来实现索引和搜索的功能,但是
它通过简单的RestfulAPI**和javaAPI来隐藏Lucene的复杂性,从而让全文搜索变得简单。
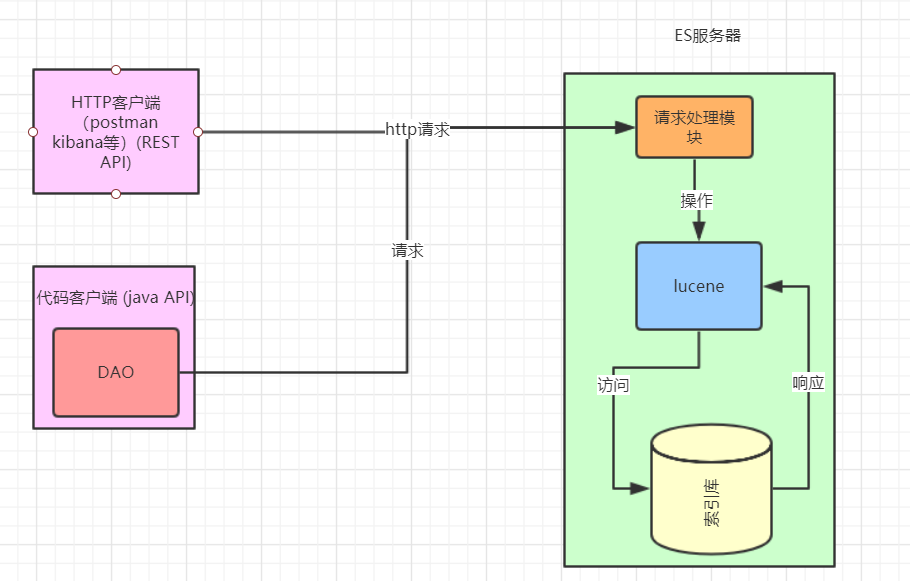
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch

Es企业使用场景
企业使用场景一般分为2种情况:
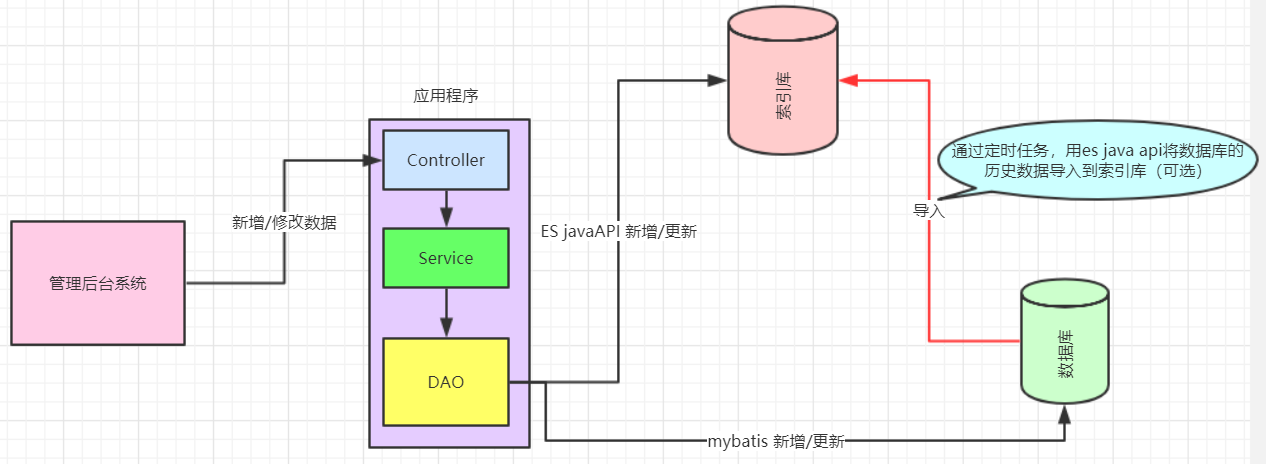
1)已经上线的系统,某些模块的搜索功能是使用数据库搜索实现的,但是已经出现性能问题或者不满足产品的高亮相关度排序的需求时候,就会对系统的搜索功能进行技术改造,使用全文检索,而es就是首选。针对这种情况企业改造的业务流
程如下图:
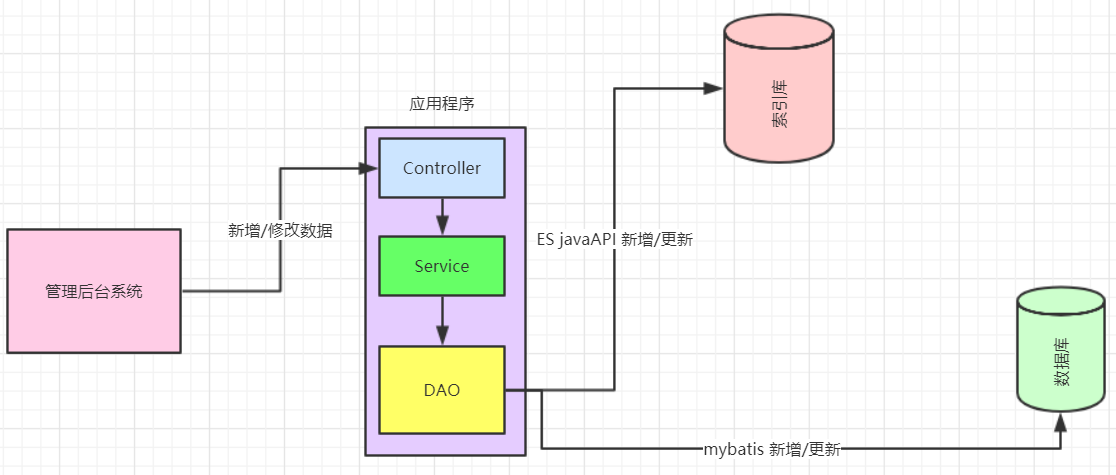
2)系统新增加的模块,产品一开始就要实现高亮相关度排序等全文检索的功能或者技术分析觉得该模块使用全文检索更适合。针对这种情况企业改造的业务流程如下图:
3)索引库(ES)存什么数据
索引库的数据是用来搜索用的,里面存储的数据和数据库一般不会是完全一样的,一般都比数据库的数据少。
那索引库存什么数据呢?
以业务需求为准,需求决定页面要显示什么字段以及会按什么字段进行搜索,那么这些字段就都要保存到索引库中。
1.1.3.版本
目前Elasticsearch最新的版本是7.3.2,我们使用6.8.0版本,建议使用JDK1.8及以上
Elasticsearch安装和配置
为了模拟真实场景,我们将在linux下安装Elasticsearch。
环境要求:
centos 7 64位
JDK8及以上
新建一个用户
出于安全考虑,elasticsearch默认不允许以root账号运行。
useradd elastic
设置密码:
passwd elastic
切换用户
su - elastic
上传安装包并解压
我们将安装包上传到:/home/elastic目录

解压缩:
tar xvf elasticsearch-6.8.0.tar.gz mv elasticsearch-6.8.0/ elasticsearch cd elasticsearch ls

-
bin 二进制脚本,包含启动命令等
-
config 配置文件目录
-
lib 依赖包目录
-
logs 日志文件目录
-
modules 模块库
-
plugins 插件目录,这里存放一些常用的插件比如IK分词器插件
-
data 数据储存目录(暂时没有,需要在配置文件中指定存放位置,启动es时会自动根据指定位置创建)
修改配置
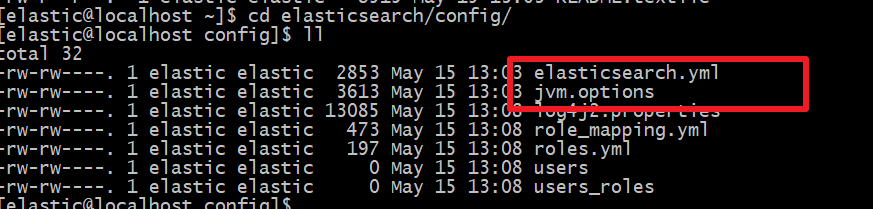
我们进入config目录:
cd config ll
需要修改的配置文件有两个
修改jvm配置
Elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数设置堆大小
vim jvm.options
默认配置如下
- -Xms1g
- -Xmx1g
内存占用太多了,我们调小一些,大家虚拟机内存设置为2G:
最小设置128m,如果虚机内存允许的话设置为512m
- -Xms256m
- -Xmx256m
修改elasticsearch.yml
vim elasticsearch.yml
修改数据和日志目录:
path.data: /home/elastic/elasticsearch/data # 数据目录位置 path.logs: /home/elastic/elasticsearch/logs # 日志目录位置
修改绑定的ip:
network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问
默认只允许本机访问,修改为0.0.0.0后则可以远程访问
目前我们是做的单机安装,如果要做集群,只需要在这个配置文件中添加其它节点信息即可。
elasticsearch.yml的其它可配置信息:
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
启动运行
进入elasticsearch/bin目录,可以看到下面的执行文件:
./elasticsearch 后天启动 ./elasticsearch -d

修改错误(在root用户下修改)
错误1:
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65535]
问题翻译过来就是:elasticsearch用户拥有的可创建文件描述的权限太低,至少需要65535;
我们用的是elastic用户,而不是root,所以文件权限不足
修改配置文件
vim /etc/security/limits.conf
添加下面的内容:
注意下面的 “*” 号不要去除
#可打开的文件描述符的最大数(软限制) * soft nofile 65536 #可打开的文件描述符的最大数(硬限制) * hard nofile 131072 #单个用户可用的最大进程数量(软限制) * soft nproc 4096 #单个用户可用的最大进程数量(硬限制) * hard nproc 4096
错误2:
[2]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
问题翻译过来就是:elasticsearch用户拥有的最大虚拟内存太小,至少需要262144;
继续修改配置文件:
vim /etc/sysctl.conf
添加下面内容:
vm.max_map_count=262144
然后执行命令:
sysctl -p
重启终端窗口(关掉当前终端)
所有错误修改完毕,关闭连接虚拟机的会话,重新连接使配置生效。
切换至elastic重新启动
su - elastic
./elasticsearch
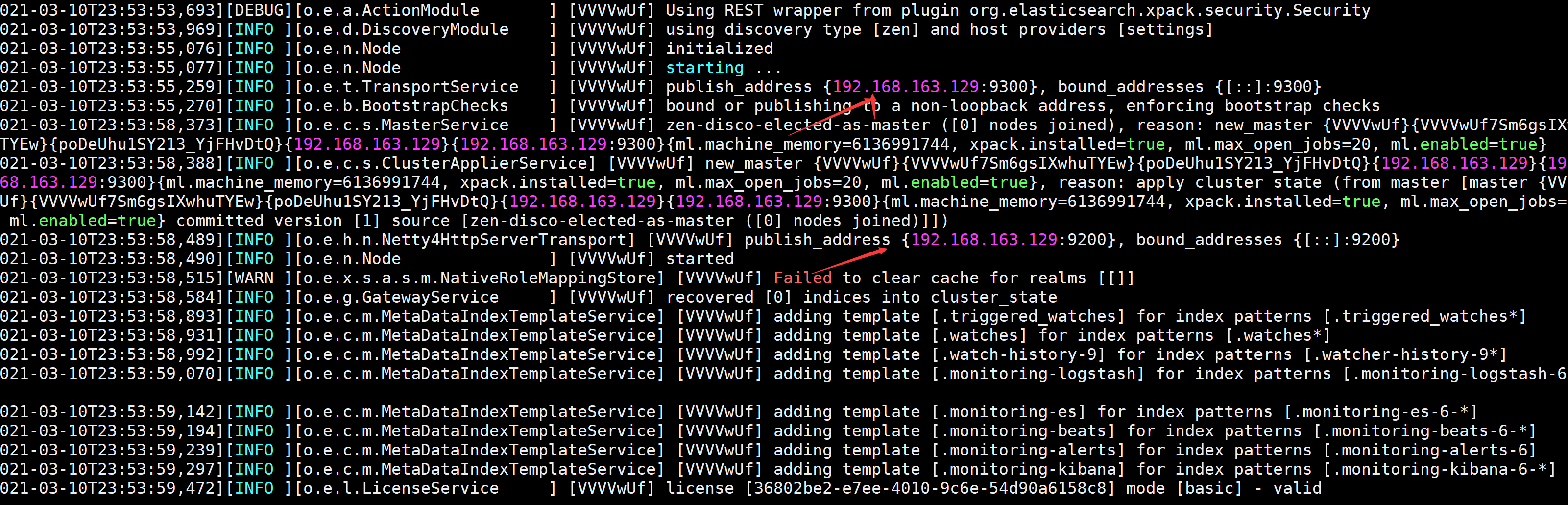
可以看到绑定了两个端口:
- 9300:集群节点间通讯接口,接收tcp协议
- 9200:客户端访问接口,接收Http协议
验证是否启动成功:
在浏览器中访问:http://192.168.163.129:9200/,如果不能访问,则需要关闭虚拟机防火墙,需要root权限
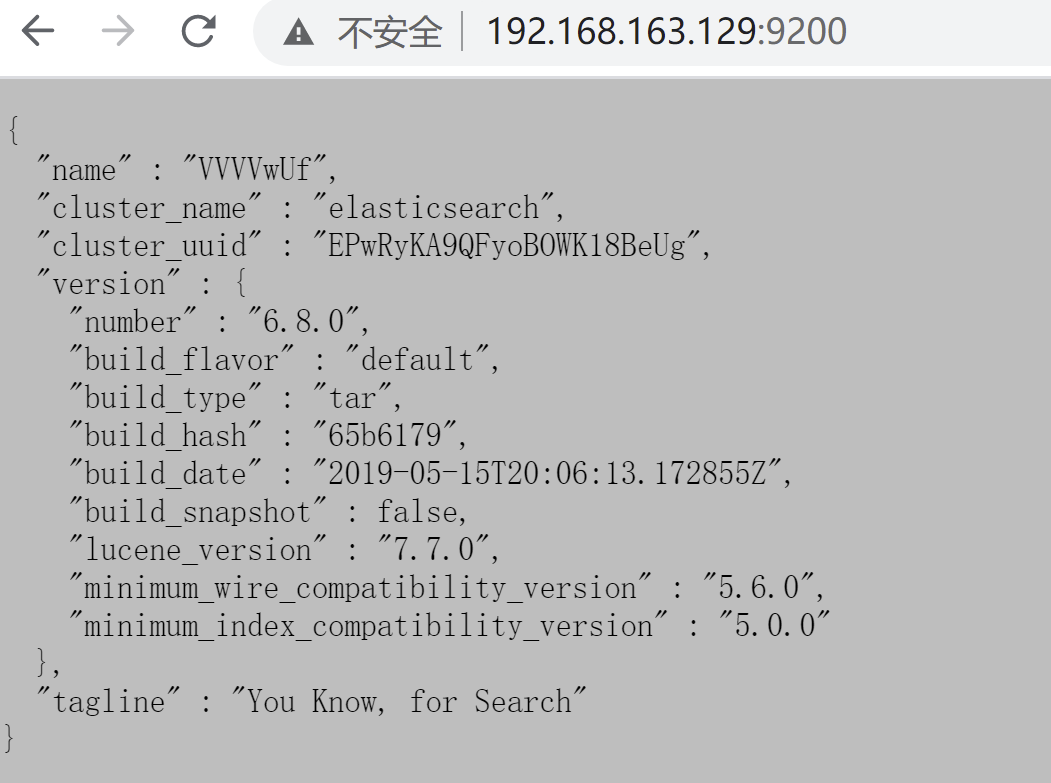
如果不能访问需要关掉防火墙
查看防火墙: firewall-cmd --state (centos7) 关闭防火墙: systemctl stop firewalld.service (centos7) 禁止开机启动防火墙: systemctl disable firewalld.service (centos7)
插件安装
#安装插件 bin/elasticsearch-plugin install analysis-icu #查看插件 bin/elasticsearch-plugin list #查看安装的插件 GET http://localhost:9200/_cat/plugins?v
图形化可视工具安装
kibana 安装
ElasticSearch没有自带图形化界面,我们可以通过安装ElasticSearch的图形化插件,完成图形化界面的效果,完成索引数据的查看。
tar -xvf kibana-6.8.0-linux-x86_64.tar.gz
mv kibana-6.8.0-linux-x86_64 kibana
修改配置
cd kibana/config vim kibana.yml
修改内容如下
server.host: "0.0.0.0" i18n.locale: "zh-CN"
启动之前要先把es先启动
启动es ./elasticsearch 启动kibana ./kibana
访问kibana
http://192.168.163.129:5601
简单的快捷键使用
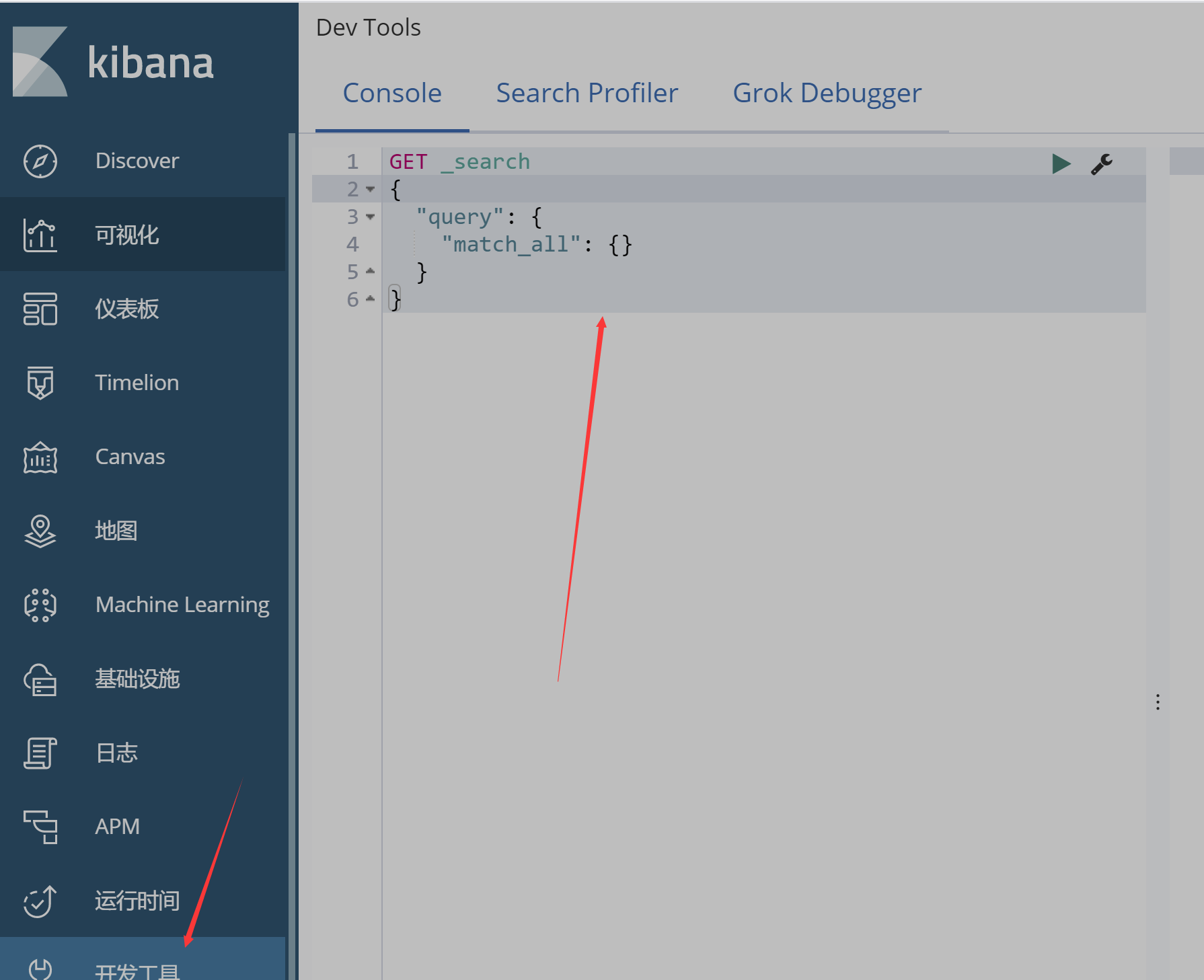
ctrl + 回车键 发送请求
ctrl + i 折叠缩进
kibana问题
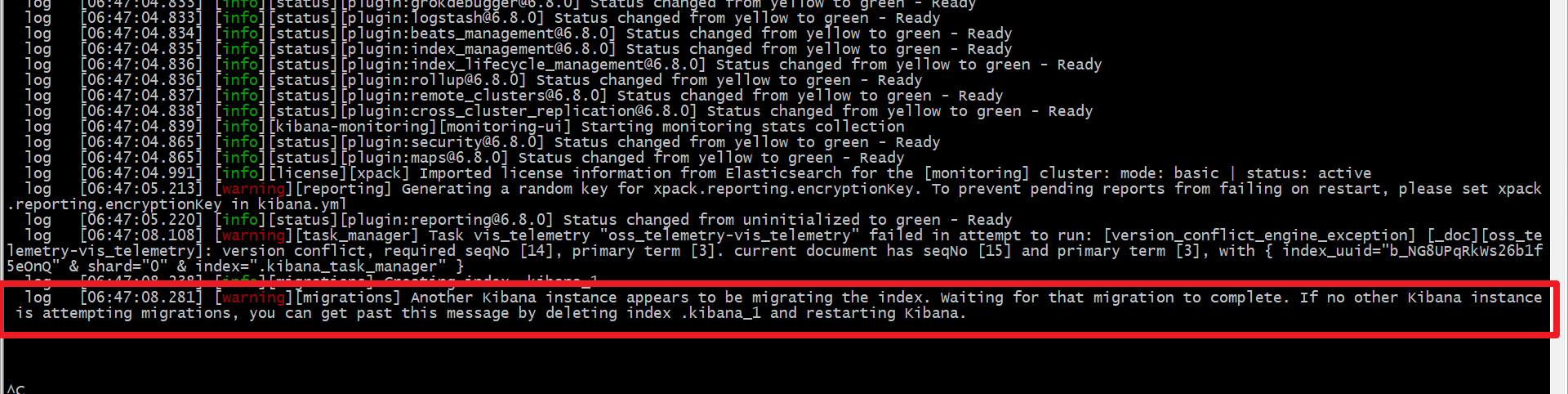
如果出现上述问题,可以使用elasticsearch-head删除kibana的相关索引,然后再启动kibana。
head 插件安装
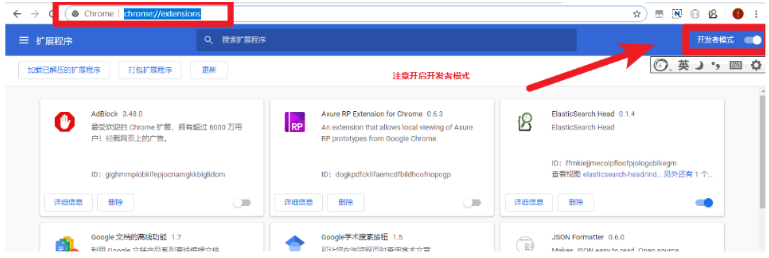
在Chrome浏览器地址栏中输入:chrome://extensions/
-
打开Chrome扩展程序的开发者模式
-
将资料中的elastic-head0.1.5_0.crx插件拖入浏览器的插件页面
如果上面流程安装失败:
-
Chrome浏览器输入 chrome://extensions/
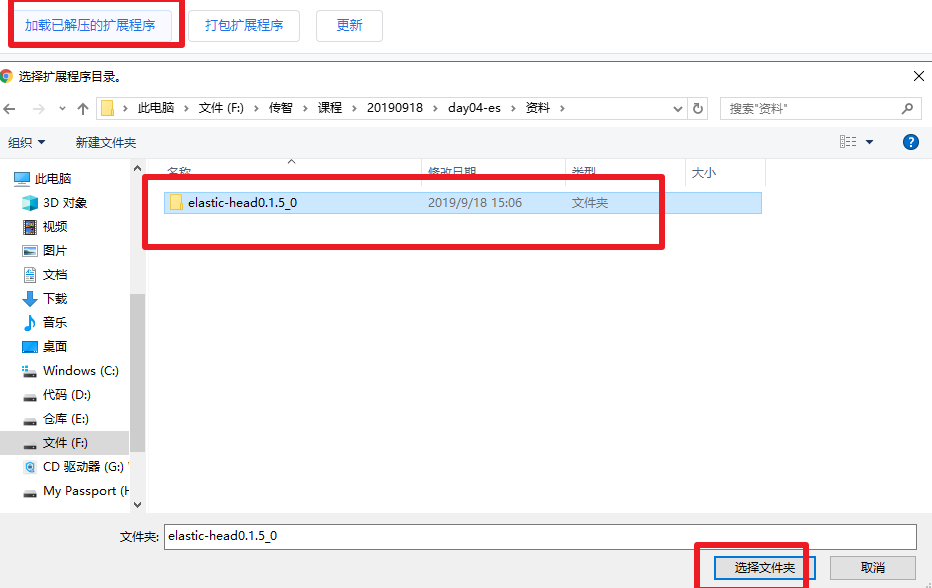
访问

集成ik分词器
Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为Elasticsearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致
https://github.com/medcl/elasticsearch-analysis-ik
使用插件安装(方式一)
1)在elasticsearch的bin目录下执行以下命令,es插件管理器会自动帮我们安装,然后等待安装完成:
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.0/elasticsearch-analysis-ik-6.8.0.zip
2)下载完成后会提示 Continue with installation?输入 y 即可完成安装

3)重启es 和kibana
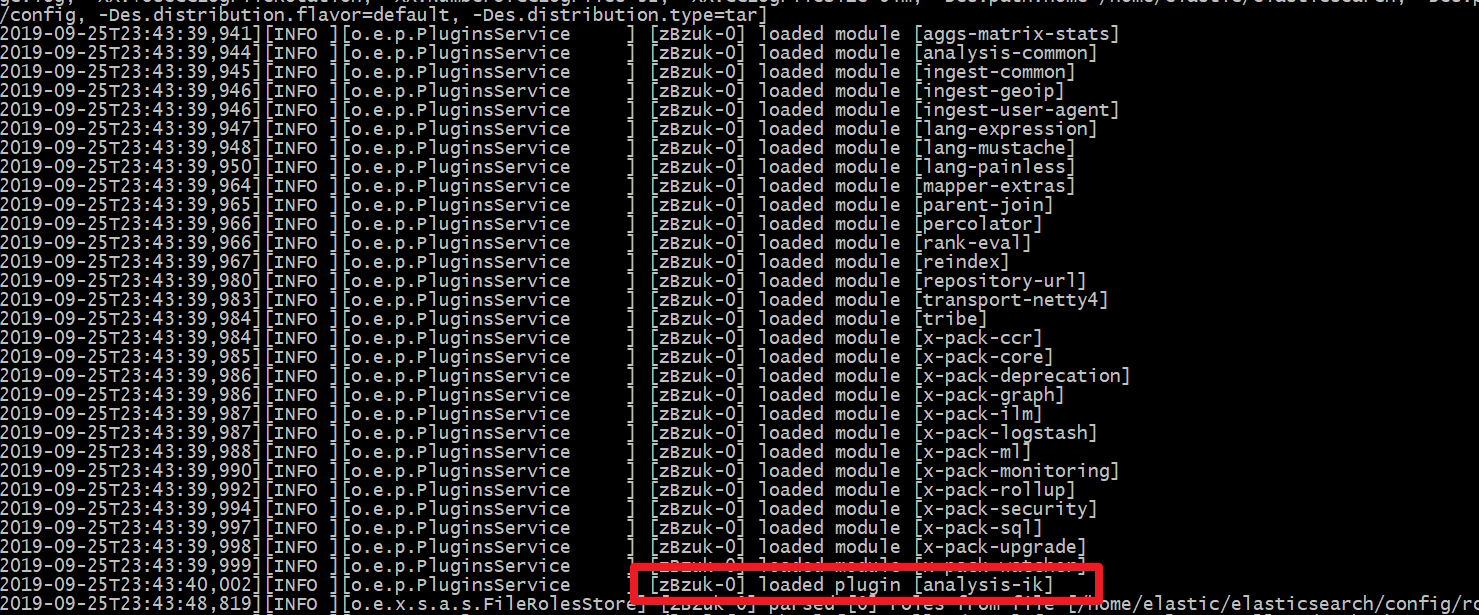
上传安装包安装(方式二)
1)在elasticsearch的plugins目录下新建 analysis-ik 目录
#新建analysis-ik文件夹 mkdir analysis-ik #切换至 analysis-ik文件夹下 cd analysis-ik #rz上传资料中的 elasticsearch-analysis-ik-6.8.0.zip rz #解压 unzip elasticsearch-analysis-ik-6.8.0.zip #解压完成后删除zip rm -rf elasticsearch-analysis-ik-6.8.0.zip
2)重启es 和kibana

测试
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word (常用)
会将文本做最细粒度的拆分
2、ik_smart
会做最粗粒度的拆分
大家先不管语法,我们先在kibana测试一波输入下面的请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}
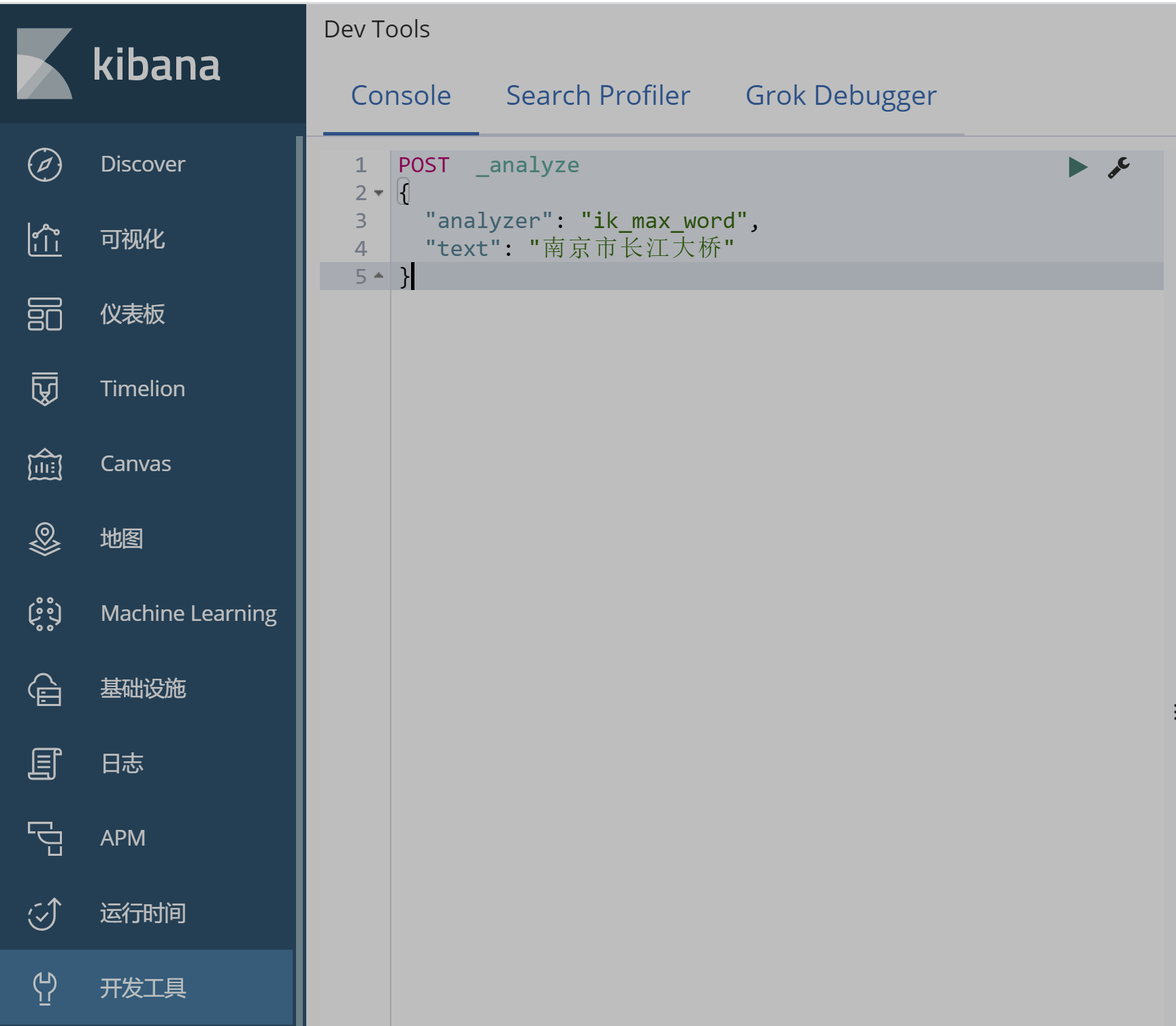
ik_max_word 分词模式运行得到结果:


{ "tokens" : [ { "token" : "南京市", "start_offset" : 0, "end_offset" : 3, "type" : "CN_WORD", "position" : 0 }, { "token" : "南京", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 1 }, { "token" : "市长", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "市", "start_offset" : 2, "end_offset" : 3, "type" : "CN_CHAR", "position" : 3 }, { "token" : "长江大桥", "start_offset" : 3, "end_offset" : 7, "type" : "CN_WORD", "position" : 4 }, { "token" : "长江", "start_offset" : 3, "end_offset" : 5, "type" : "CN_WORD", "position" : 5 }, { "token" : "大桥", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 6 } ] }
测试2
POST _analyze
{
"analyzer": "ik_smart",
"text": "南京市长江大桥"
}
ik_smart分词模式运行得到结果:
{
"tokens" : [
{
"token" : "南京市",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "长江大桥",
"start_offset" : 3,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 1
}
]
}
如果现在假如江大桥是一个人名,是南京市市长,那么上面的分词显然是不合理的,该怎么办?
添加扩展词典和停用词典
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。
扩展词:就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥
自定义扩展词库
-
进入到 elasticsearch/config/analysis-ik/(插件安装方式) 或 elasticsearch/plugins/analysis-ik/config(安装包安装方式) 目录下, 新增自定义词典
vim myext_dict.dic
输入 :江大桥
将我们自定义的扩展词典文件添加到IKAnalyzer.cfg.xml配置中

vim IKAnalyzer.cfg.xml

然后重启:

再次测试
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}
出现江大桥

相关阅读
-
安装指南 https://www.elastic.co/guide/en/elasticsearch/reference/7.1/install-elasticsearch.html
-
Elastic Support Matrix(OS / JDK ) https://www.elastic.co/cn/support/matrix
-
Elasticsearch 的一些重要配置 https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html
-
https://www.elastic.co/guide/en/elasticsearch/reference/current/settings.html
-
https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html
-
Elasticsearch on Kuvernetes https://www.elastic.co/cn/blog/introducing-elastic-cloud-on-kubernetes-the-elasticsearch-operator-and-beyond
-
CAT Plugins API https://www.elastic.co/guide/en/elasticsearch/reference/7.1/cat-plugins.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号