MHA高可用使用
MHA原理讲解
Manager额外参数介绍
说明: 主库宕机谁来接管? 1. 所有从节点日志都是一致的,默认会以配置文件的顺序去选择一个新主。 2. 从节点日志不一致,自动选择最接近于主库的从库 3. 如果对于某节点设定了权重(candidate_master=1),权重节点会优先选择。 但是此节点日志量落后主库100M日志的话,也不会被选择。可以配合check_repl_delay=0,关闭日志量的检查,强制选择候选节点。 (1) ping_interval=1 #设置监控主库,发送ping包的时间间隔,尝试三次没有回应的时候自动进行failover (2) candidate_master=1 #设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave (3)check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话, MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,
这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
什么是Failover
- 故障转移,主库宕机一直到业务恢复正常的处理过程(自动)
Failover让你实现怎么做?
-
(1) 快速监控到主库宕机
-
(2) 选择新主
-
(3) 数据补偿
-
(4) 解除从库身份
-
(5) 剩余从库和新主库构建主从关系
-
(6) 应用透明
-
(7) 故障节点自愈(待开发...)
-
(8) 故障提醒
MHA的Failover如何实现?
从启动--->故障--->转移--->业务恢复
-
(1) MHA通过masterha_manger脚本启动MHA的功能.
-
(2) 在manager启动之前,会自动检查ssh互信(masterha_check_ssh)和主从状态(masterha_check_repl)
-
(3) MHA-manager 通过 masterha_master_monitor脚本(每隔ping_interval秒)
-
(4) masterha_master_monitor探测主库3次无心跳之后,就认为主库宕机了.
-
(5) 进行选主过程
算法一:
-
读取配置文件中是否有强制选主的参数?
-
candidate_master=1
-
check_repl_delay=0
算法二:
- 自动判断所有从库的日志量.将最接近主库数据的从库作为新主.
算法三:
- 按照配置文件先后顺序的进行选新主.
MHA快速使用
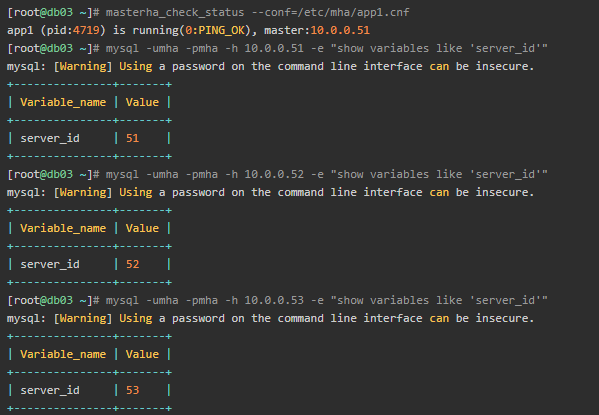
查看mha用户是否可用
[root@db03 ~]# mysql -umha -pmha -h 10.0.0.51 -e "show variables like 'server_id'" [root@db03 ~]# mysql -umha -pmha -h 10.0.0.52 -e "show variables like 'server_id'" [root@db03 ~]# mysql -umha -pmha -h 10.0.0.53 -e "show variables like 'server_id'"
故障模拟及处理
停主库db01
/etc/init.d/mysqld stop
观察manager 日志 tail -f /var/log/mha/app1/manager 末尾必须显示successfully,才算正常切换成功。
修复主库
查看日志快速过滤语句
[root@db03 bin]# grep "CHANGE MASTER TO" /var/log/mha/app1/manager Thu Jul 18 18:31:54 2019 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx'; [root@db03 bin]#
db1执行以下语句
CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123'; start slave ;
db03修改配置文件(主库停止,会把其ip在配置中移掉)
vim /etc/mha/app1.cnf [server1] hostname=10.0.0.51 port=3306
启动MHA
[root@db03 bin]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
MHA 应用透明 vip(浮动的IP类似keeplive)
以下匀在db03上操作
修改脚本内容
cp /root/master_ip_failover.txt /usr/local/bin/master_ip_failover
要修改的内容如下
vim /usr/local/bin/master_ip_failover # 没有使用的ip my $vip = '10.0.0.55/24'; # key可以任意指定 my $key = '1'; # 网卡eth0要根据自己的机器 my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
完整的代码如下


#!/usr/bin/env perl use strict; use warnings FATAL => 'all'; use Getopt::Long; my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port ); my $vip = '10.0.0.55/24'; my $key = '1'; my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; GetOptions( 'command=s' => \$command, 'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, ); exit &main(); sub main { print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n"; if ( $command eq "stop" || $command eq "stopssh" ) { my $exit_code = 1; eval { print "Disabling the VIP on old master: $orig_master_host \n"; &stop_vip(); $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { my $exit_code = 10; eval { print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip(); $exit_code = 0; }; if ($@) { warn $@; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { print "Checking the Status of the script.. OK \n"; exit 0; } else { &usage(); exit 1; } } sub start_vip() { `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`; } sub stop_vip() { return 0 unless ($ssh_user); `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`; } sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n"; }
脚本中可能包含中文等特殊字符转码一下
yum install -y dos2unix dos2unix /usr/local/bin/master_ip_failover chmod +x /usr/local/bin/master_ip_failover
更改manager配置文件,添加vip脚本路径
[root@db03 bin]# vim /etc/mha/app1.cnf master_ip_failover_script=/usr/local/bin/master_ip_failover
第一次要在51主库上,手工生成第一个vip地址
#手工在主库上绑定vip,注意一定要和配置文件中的ethN一致,我的是eth0:1(1是key指定的值) ifconfig eth0:1 10.0.0.55/24
重启mha
[root@db03 bin]# masterha_stop --conf=/etc/mha/wordpress.cnf [root@db03 bin]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 & [root@db03 bin]# masterha_check_status --conf=/etc/mha/app1.cnf

主库db1要是停掉了,vip会转换到db2上
邮件提醒
1. 参数: report_script=/usr/local/bin/send
[root@db03 bin]# vim /etc/mha/app1.cnf report_script=/usr/local/bin/send
执行步骤如下
2. 准备邮件脚本
send_report
(1)准备发邮件的脚本(上传 email_2019-最新.zip中的脚本,到/usr/local/bin/中)
(2)将准备好的脚本添加到mha配置文件中,让其调用
3. 修改manager配置文件,调用邮件脚本
vi /etc/mha/app1.cnf
report_script=/usr/local/bin/send
(3)停止MHA
masterha_stop --conf=/etc/mha/app1.cnf
(4)开启MHA
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
(5) 关闭主库,看警告邮件
故障修复:
1. 恢复故障节点
(1)实例宕掉
/etc/init.d/mysqld start
(2)主机损坏,有可能数据也损坏了
备份并恢复故障节点。
2.恢复主从环境
看日志文件:
CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';
start slave ;
3.恢复manager
3.1 修好的故障节点配置信息,加入到配置文件
[server1]
hostname=10.0.0.51
port=3306
3.2 启动manager
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
binlog server数据补偿(db03配置)
找一台额外的机器,必须要有5.6以上的版本,支持gtid并开启,我们直接用的第二个slave(db03)
修改配置如下
vim /etc/mha/app1.cnf [binlog1] no_master=1 hostname=10.0.0.53 master_binlog_dir=/data/mysql/binlog
创建必要目录
mkdir -p /data/mysql/binlog chown -R mysql.mysql /data/*
拉取主库binlog日志
#必须进入到自己创建好的目录 cd /data/mysql/binlog mysqlbinlog -R --host=10.0.0.51 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
注意:
- 拉取日志的起点,需要按照目前主库正在使用的binlog为起点.可在主库中通过show master status 进行查询
(4) 重启MHA-manager 后db3的bin_log就和主库的一致了,会自动拉取
[root@db03 bin]# masterha_stop --conf=/etc/mha/app1.cnf [root@db03 bin]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
故障模拟及故障处理
宕掉 db01 数据库
/etc/init.d/mysqld stop
恢复故障
(1) 启动故障节点
[root@db01 ~]# /etc/init.d/mysqld start
(2) 恢复1主2从(db01)
[root@db03 bin]# grep "CHANGE MASTER TO" /var/log/mha/app1/manager Thu Jul 18 18:31:54 2019 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx'; [root@db03 bin]# db01 [(none)]>CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123'; db01 [(none)]>start slave;
(3) 恢复配置文件(db03)
[server1] hostname=10.0.0.51 port=3306 [server2] hostname=10.0.0.52 port=3306 [server3] hostname=10.0.0.53 port=3306
(4) 启动MHA
[root@db03 bin]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 & [1] 16543 [root@db03 bin]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:16543) is running(0:PING_OK), master:10.0.0.52
(5)恢复binlogserver
cd /data/mysql/binlog rm -rf /data/mysql/binlog/* mysqlbinlog -R --host=10.0.0.52 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &

 浙公网安备 33010602011771号
浙公网安备 33010602011771号