主从复制高级进阶和MHA环境搭建
延时从库
介绍,SQL线程延时:数据已经写入relaylog中了,SQL线程"慢点"运行,一般企业建议3-6小时,具体看公司运维人员对于故障的反应时间
为什么要有延时从
-
物理损坏
-
主从复制非常擅长解决物理损坏.
-
逻辑损坏
-
普通主从复制没办法解决逻辑损坏
配置(在从库上执行以下操作)
mysql>stop slave; mysql>CHANGE MASTER TO MASTER_DELAY = 300; mysql>start slave; mysql> show slave status \G

延时从库的恢复思路
(1) 监控到数据库逻辑故障
(2) 停从库SQL线程,记录已经回放的位置点(截取日志起点)
stop slave sql_thread ; show slave status \G Relay_Log_File: db01-relay-bin.000002 Relay_Log_Pos: 320
(3) 截取relaylog
起点:
show slave status \G Relay_Log_File ,Relay_Log_Pos 终点: drop之前的位置点 show relaylog events in '' 进行截取
(4) 模拟SQL线程回访日志
- 从库 source
(5) 恢复业务
情况一: 就一个库的话
- 从库替代主库工作
情况二:
- 从库导出故障库,还原到主库中.
延时从库处理逻辑故障
故障演练主库
create database delay charset utf8mb4; use delay; create table t1 (id int); insert into t1 values(1),(2),(3); commit; drop database delay;
从库:
1.停止 从库SQL 线程,获取relay的位置点 320, relay_log_file oldboyedu-relay-bin.000002
mysql> stop slave sql_thread; mysql> show slave status \G
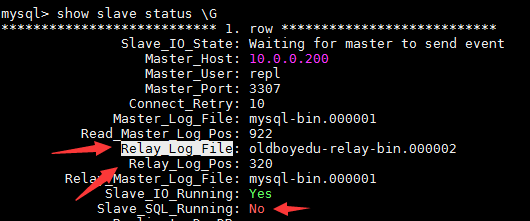
2. 找到relay的截取终点 993
mysql> show relaylog events in 'oldboyedu-relay-bin.000002';
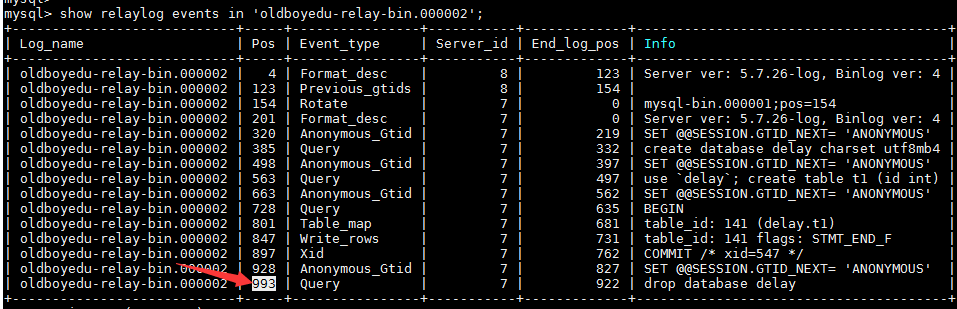
3. 截取relay
cd /data/3308/data/ mysqlbinlog --start-position=320 --stop-position=993 oldboyedu-relay-bin.000002 >/tmp/relay.sql
4. 恢复relay到从库
[root@db01 data]# mysql -uroot -p -S /data/3308/mysql.sock mysql> set sql_log_bin=0; mysql> source /tmp/relay.sql
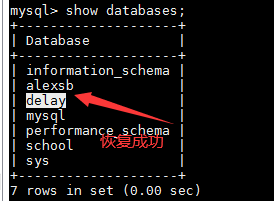
快速恢复测试环境
drop database delay ; stop slave; reset slave all; show slave status \G
主库:
mysql> reset master;
从库:
[root@db01 ~]# mysql -S /data/3308/mysql.sock CHANGE MASTER TO MASTER_HOST='10.0.0.200', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_PORT=3307, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154, MASTER_CONNECT_RETRY=10; start slave; show slave status \G
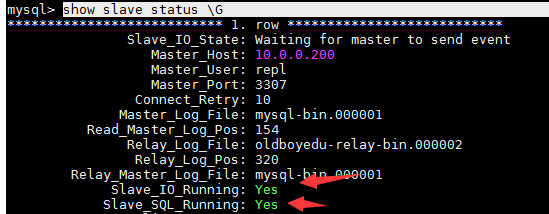
过滤复制应用
从库只复制指定的库
方法一:在主库进行配置,不常用(配置文件都是小写)
vi /data/3307/my.cnf # 白名单需要复制的库 binlog_do_db= # 黑名单忽略的库 binlog_ignore_db=
重启后执行可以看到
show master status;

方法二:在主库进行配置(一样设置白名单和黑名单)
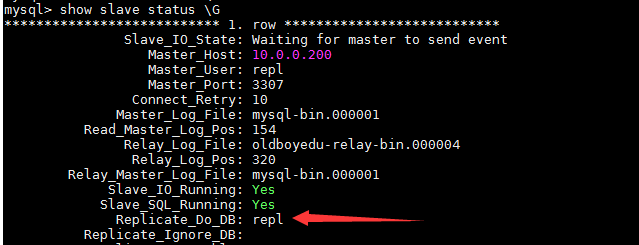
mysql> show slave status \G
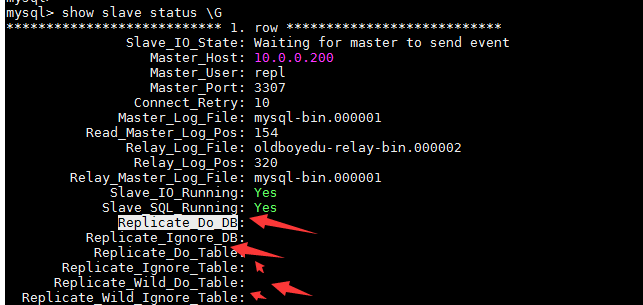
配置文件如下,只复制repl库
vim /data/3308/my.cnf replicate_do_db=repl systemctl restart mysqld3308
半同步(了解即可)
目的
解决主从数据一致性问题
半同步复制工作原理的变化
-
1. 主库执行新的事务,commit时,更新 show master status\G ,触发一个信号给
-
2. binlog dump 接收到主库的 show master status\G信息,通知从库日志更新了
-
3. 从库IO线程请求新的二进制日志事件
-
4. 主库会通过dump线程传送新的日志事件,给从库IO线程
-
5. 从库IO线程接收到binlog日志,当日志写入到磁盘上的relaylog文件时,给主库ACK_receiver线程
-
6. ACK_receiver线程触发一个事件,告诉主库commit可以成功了
-
7. 如果ACK达到了我们预设值的超时时间,半同步复制会切换为原始的异步复制.
配置半同步复制
加载插件 主: INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; 从: INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; 查看是否加载成功: show plugins; 启动: 主: SET GLOBAL rpl_semi_sync_master_enabled = 1; 从: SET GLOBAL rpl_semi_sync_slave_enabled = 1; 重启从库上的IO线程 STOP SLAVE IO_THREAD; START SLAVE IO_THREAD; 查看是否在运行 主: show status like 'Rpl_semi_sync_master_status'; 从: show status like 'Rpl_semi_sync_slave_status';
MHA环境搭建
GTID复制
介绍
GTID(Global Transaction ID)是对于一个已提交事务的唯一编号,并且是一个全局(主从复制)唯一的编号。 它的官方定义如下: GTID = source_id :transaction_id 7E11FA47-31CA-19E1-9E56-C43AA21293967:29 什么是sever_uuid,和Server-id 区别? 核心特性: 全局唯一,具备幂等性
GTID核心参数
gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 gtid-mode=on --启用gtid类型,否则就是普通的复制架构 enforce-gtid-consistency=true --强制GTID的一致性 log-slave-updates=1 --slave更新是否记入日志
GTID复制配置过程
(1) 清理环境3个节点都执行
pkill mysqld \rm -rf /data/mysql/data/* \rm -rf /data/binlog/*
(2) 准备配置文件


cat > /etc/my.cnf <<EOF [mysqld] basedir=/application/mysql/ datadir=/data/mysql/data socket=/tmp/mysql.sock server_id=51 port=3306 secure-file-priv=/tmp autocommit=0 log_bin=/data/binlog/mysql-bin binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 [mysql] prompt=db01 [\\d]> EOF
cat > /etc/my.cnf <<EOF [mysqld] basedir=/application/mysql datadir=/data/mysql/data socket=/tmp/mysql.sock server_id=52 port=3306 secure-file-priv=/tmp autocommit=0 log_bin=/data/binlog/mysql-bin binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 [mysql] prompt=db02 [\\d]> EOF
cat > /etc/my.cnf <<EOF [mysqld] basedir=/application/mysql datadir=/data/mysql/data socket=/tmp/mysql.sock server_id=53 port=3306 secure-file-priv=/tmp autocommit=0 log_bin=/data/binlog/mysql-bin binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 [mysql] prompt=db03 [\\d]> EOF
(3) 初始化数据(3个节点都执行)
mysqld --initialize-insecure --user=mysql --basedir=/application/mysql --datadir=/data/mysql/data
(4) 启动数据库
/etc/init.d/mysqld start
(5) 构建主从关系如下
-
master:51
-
slave:52,53
51(主库创建用户):
grant replication slave on *.* to repl@'10.0.0.%' identified by '123';
52\53节点绑定
change master to master_host='10.0.0.51', master_user='repl', master_password='123' , MASTER_AUTO_POSITION=1; start slave;
GTID 复制和普通复制的区别
-
(0)在主从复制环境中,主库发生过的事务,在全局都是由唯一GTID记录的,更方便Failover
-
(1)额外功能参数(3个)
-
(2)change master to 的时候不再需要binlog 文件名和position号,MASTER_AUTO_POSITION=1;
-
(3)在复制过程中,从库不再依赖master.info文件,而是直接读取最后一个relaylog的 GTID号
-
(4) mysqldump备份时,默认会将备份中包含的事务操作,以以下方式
#### SET @@GLOBAL.GTID_PURGED='8c49d7ec-7e78-11e8-9638-000c29ca725d:1-11';
告诉从库,我的备份中已经有以上事务,你就不用运行了,直接从下一个GTID开始请求binlog就行。
搭建MHA环境
搭建体验
(1)配置关键程序软连接(3个节点都执行)
ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog ln -s /application/mysql/bin/mysql /usr/bin/mysql
(2)配置互信
rm -rf /root/.ssh ssh-keygen cd /root/.ssh mv id_rsa.pub authorized_keys scp -r /root/.ssh 10.0.0.52:/root scp -r /root/.ssh 10.0.0.53:/root
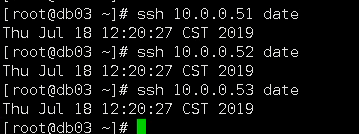
各节点验证
db01: ssh 10.0.0.51 date ssh 10.0.0.52 date ssh 10.0.0.53 date db02: ssh 10.0.0.51 date ssh 10.0.0.52 date ssh 10.0.0.53 date db03: ssh 10.0.0.51 date ssh 10.0.0.52 date ssh 10.0.0.53 date
(3)安装软件包(所有节点都做)
yum install perl-DBD-MySQL -y rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
(4) 在db01主库中创建mha需要的用户
grant all privileges on *.* to mha@'10.0.0.%' identified by 'mha';
(5) Manager软件安装(db03)
下载mha软件
-
mha官网:https://code.google.com/archive/p/mysql-master-ha/ -
github下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
(6) 配置文件准备(db03)
创建配置文件目录
mkdir -p /etc/mha
创建日志目录
mkdir -p /var/log/mha/app1
编辑mha配置文件
cat > /etc/mha/app1.cnf <<EOF
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/binlog
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=repl
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
EOF
(7) 状态检查(db03)
互信检查
# 检查互信状态 masterha_check_ssh --conf=/etc/mha/app1.cnf # 检查主从状态 masterha_check_repl --conf=/etc/mha/app1.cnf

(8) 开启MHA(db03):
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
(9) 查看MHA状态
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf


 浙公网安备 33010602011771号
浙公网安备 33010602011771号