SQL基础应用(二)
DQL应用 select
select单独使用的情况
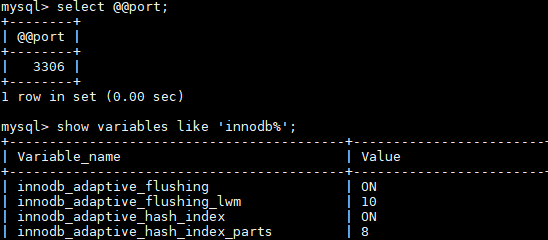
-- select @@xxx 查看系统参数 SELECT @@port; SELECT @@basedir; SELECT @@datadir; SELECT @@socket; SELECT @@server_id; select @@innodb_flush_log_at_trx_commit; show variables like 'innodb%';
mysql函数参考手册
https://dev.mysql.com/doc/refman/5.7/en/func-op-summary-ref.html?tdsourcetag=s_pcqq_aiomsg
mysql 书写顺序
select 列 from 表 where 条件 group by 条件 having 条件 order by 条件 limit
练习表说明
-
city 城市表
-
country 国家表
-
countrylanguage 国家的语言
city表结构
mysql> desc city; +-------------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+----------+------+-----+---------+----------------+ | ID | int(11) | NO | PRI | NULL | auto_increment | | Name | char(35) | NO | | | | | CountryCode | char(3) | NO | MUL | | | | District | char(20) | NO | | | | | Population | int(11) | NO | | 0 | | +-------------+----------+------+-----+---------+----------------+ 5 rows in set (0.00 sec) mysql> ID : 城市序号(1-...) name : 城市名字 countrycode : 国家代码,例如:CHN,USA district : 区域: 中国 省 美国 洲 population : 人口数
快速了解表结构
DESC ,show create table select * from city limit 5;
SELECT 配合 FROM 子句使用
查询表中所有的信息
SELECT id,NAME ,countrycode ,district,population FROM city; 或者: SELECT * FROM city;
查询表中 name和population的值
SELECT NAME ,population FROM city;
SELECT 配合 WHERE 子句使用
查询中国所有的城市名和人口数
SELECT NAME,population FROM city WHERE countrycode='CHN';
世界上小于100人的城市名和人口数
SELECT NAME,population FROM city WHERE population<100;
查询中国人口数量大于1000w的城市名和人口
SELECT NAME,population FROM city WHERE countrycode='CHN' AND population>8000000;
查询中国或美国的城市名和人口数
SELECT NAME,population FROM city WHERE countrycode='CHN' OR countrycode='USA';
查询人口数量在500w到600w之间的城市名和人口数
SELECT NAME,population FROM city WHERE population>5000000 AND population<6000000; 或者: SELECT NAME,population FROM city WHERE population BETWEEN 5000000 AND 6000000;
查询一下contrycode中带有CH开头,城市信息
SELECT * FROM city WHERE countrycode LIKE 'CH%';
注意:不要出现类似于 %CH%,前后都有百分号的语句,因为不走索引,性能极差如果业务中有大量需求,我们用"ES"来替代
查询中国或美国的城市信息
SELECT NAME,population FROM city WHERE countrycode='CHN' OR countrycode='USA';
或者:
SELECT NAME,population FROM city WHERE countrycode IN ('CHN' ,'USA');
GROUP BY
用途
将某列中有共同条件的数据行,分成一组,然后在进行聚合函数操作
统计每个国家,城市的个数
SELECT countrycode ,COUNT(id) FROM city GROUP BY countrycode;
统计每个国家的总人口数
SELECT countrycode,SUM(population) FROM city GROUP BY countrycode;
统计每个国家省的个数
SELECT countrycode, COUNT(DISTINCT district) FROM city GROUP BY countrycode;
统计中国每个省的总人口数
SELECT district, SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district;
统计中国每个省城市的个数
SELECT district, COUNT(NAME) FROM city WHERE countrycode='CHN' GROUP BY district;
统计中国每个省城市的名字列表GROUP_CONCAT()
SELECT district, GROUP_CONCAT(NAME) FROM city WHERE countrycode='CHN' GROUP BY district; # 输出一下格式 guangdong guangzhou,shenzhen,foshan.... 小扩展 anhui : hefei,huaian .... SELECT CONCAT(district,":" ,GROUP_CONCAT(NAME)) FROM city WHERE countrycode='CHN' GROUP BY district ;
SELECT 配合 ORDER BY LIMIT 子句
统计所有国家的总人口数量, 将总人口数大于5000w的过滤出来,并且按照从大到小顺序排列
SELECT countrycode,SUM(population) FROM city GROUP BY countrycode HAVING SUM(population)>50000000 ORDER BY SUM(population) DESC;
统计所有国家的总人口数量,将总人口数大于5000w的过滤出来,并且按照从大到小顺序排列,只显示前三名
SELECT countrycode,SUM(population) FROM city GROUP BY countrycode HAVING SUM(population)>50000000 ORDER BY SUM(population) DESC LIMIT 3 OFFSET 0;LIMIT M,N :跳过M行,显示一共N行
LIMIT Y OFFSET X: 跳过X行,显示一共Y行
SELECT countrycode,SUM(population) FROM city GROUP BY countrycode HAVING SUM(population)>50000000 ORDER BY SUM(population) DESC LIMIT 3 OFFSET 3
练习题
统计中国每个省的总人口数,只打印总人口数小于100w的
SELECT district ,SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district HAVING SUM(population)<1000000;
查看中国所有的城市,并按人口数进行排序(从大到小)
SELECT * FROM city WHERE countrycode='CHN' ORDER BY population DESC;
统计中国各个省的总人口数量,按照总人口从大到小排序
SELECT district ,SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district ORDER BY SUM(population) DESC ;
统计中国,每个省的总人口,找出总人口大于500w的, 并按总人口从大到小排序,只显示前三名
SELECT district ,SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district HAVING SUM(population)>5000000 ORDER BY SUM(population) DESC LIMIT 3; select disctrict , count(name) from city where countrycode='CHN' group by district having count(name) >10 order by count(name) desc limit 3;
union 和 union all
- 作用: 多个结果集合并查询的功能
区别
-
union all 不做去重复
-
union 会做去重操作
查询中或者美国的城市信息
SELECT * FROM city WHERE countrycode='CHN' OR countrycode='USA'; 改写为: SELECT * FROM city WHERE countrycode='CHN' UNION ALL SELECT * FROM city WHERE countrycode='USA';
多表连接查询 内连接
作用
- 单表数据不能满足查询需求时,连接多个表查询
数据准备


use school student :学生表 sno: 学号 sname:学生姓名 sage: 学生年龄 ssex: 学生性别 teacher :教师表 tno: 教师编号 tname:教师名字 course :课程表 cno: 课程编号 cname:课程名字 tno: 教师编号 score :成绩表 sno: 学号 cno: 课程编号 score:成绩 -- 项目构建 drop database school; CREATE DATABASE school CHARSET utf8; USE school CREATE TABLE student( sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号', sname VARCHAR(20) NOT NULL COMMENT '姓名', sage TINYINT UNSIGNED NOT NULL COMMENT '年龄', ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别' )ENGINE=INNODB CHARSET=utf8; CREATE TABLE course( cno INT NOT NULL PRIMARY KEY COMMENT '课程编号', cname VARCHAR(20) NOT NULL COMMENT '课程名字', tno INT NOT NULL COMMENT '教师编号' )ENGINE=INNODB CHARSET utf8; CREATE TABLE sc ( sno INT NOT NULL COMMENT '学号', cno INT NOT NULL COMMENT '课程编号', score INT NOT NULL DEFAULT 0 COMMENT '成绩' )ENGINE=INNODB CHARSET=utf8; CREATE TABLE teacher( tno INT NOT NULL PRIMARY KEY COMMENT '教师编号', tname VARCHAR(20) NOT NULL COMMENT '教师名字' )ENGINE=INNODB CHARSET utf8; INSERT INTO student(sno,sname,sage,ssex) VALUES (1,'zhang3',18,'m'); INSERT INTO student(sno,sname,sage,ssex) VALUES (2,'zhang4',18,'m'), (3,'li4',18,'m'), (4,'wang5',19,'f'); INSERT INTO student VALUES (5,'zh4',18,'m'), (6,'zhao4',18,'m'), (7,'ma6',19,'f'); INSERT INTO student(sname,sage,ssex) VALUES ('oldboy',20,'m'), ('oldgirl',20,'f'), ('oldp',25,'m'); INSERT INTO teacher(tno,tname) VALUES (101,'oldboy'), (102,'hesw'), (103,'oldguo'); DESC course; INSERT INTO course(cno,cname,tno) VALUES (1001,'linux',101), (1002,'python',102), (1003,'mysql',103); DESC sc; INSERT INTO sc(sno,cno,score) VALUES (1,1001,80), (1,1002,59), (2,1002,90), (2,1003,100), (3,1001,99), (3,1003,40), (4,1001,79), (4,1002,61), (4,1003,99), (5,1003,40), (6,1001,89), (6,1003,77), (7,1001,67), (7,1003,82), (8,1001,70), (9,1003,80), (10,1003,96); SELECT * FROM student; SELECT * FROM teacher; SELECT * FROM course; SELECT * FROM sc;
语法
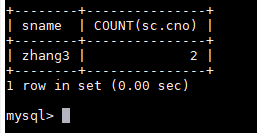
统计zhang3,学习了几门课
SELECT student.sname,COUNT(sc.cno) FROM student JOIN sc ON student.sno=sc.sno WHERE student.sname='zhang3';
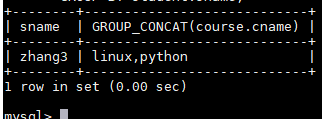
查询zhang3,学习的课程名称有哪些
SELECT student.sname,GROUP_CONCAT(course.cname) FROM student JOIN sc ON student.sno=sc.sno JOIN course ON sc.cno=course.cno WHERE student.sname='zhang3' GROUP BY student.sname;
查询oldguo老师教的学生名和个数
SELECT teacher.tname,GROUP_CONCAT(student.sname),COUNT(student.sname) FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno JOIN student ON sc.sno=student.sno WHERE teacher.tname='oldguo' GROUP BY teacher.tname;

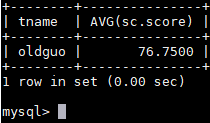
查询oldguo所教课程的平均分数
SELECT teacher.tname,AVG(sc.score) FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno WHERE teacher.tname='oldguo' GROUP BY sc.cno;
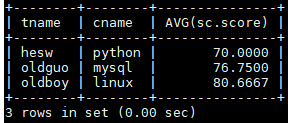
每位老师所教课程的平均分,并按平均分排序
SELECT teacher.tname,course.cname,AVG(sc.score) FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno GROUP BY teacher.tname,course.cname ORDER BY AVG(sc.score);
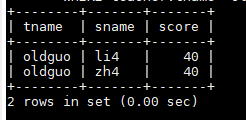
查询oldguo所教的不及格的学生姓名
SELECT teacher.tname,student.sname,sc.score FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno JOIN student ON sc.sno=student.sno WHERE teacher.tname='oldguo' AND sc.score<60;
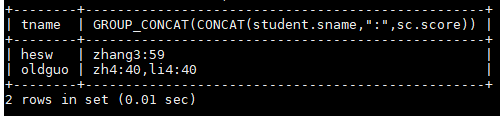
查询所有老师所教学生不及格的信息
SELECT teacher.tname,GROUP_CONCAT(CONCAT(student.sname,":",sc.score)) FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno JOIN student ON sc.sno=student.sno WHERE sc.score<60 GROUP BY teacher.tno;
别名应用
表别名,表别名是全局调用的
SELECT t.tname,GROUP_CONCAT(CONCAT(st.sname,":",sc.score)) FROM teacher as t JOIN course as c ON t.tno=c.tno JOIN sc ON c.cno=sc.cno JOIN student as st ON sc.sno=st.sno WHERE sc.score<60 GROUP BY t.tno;
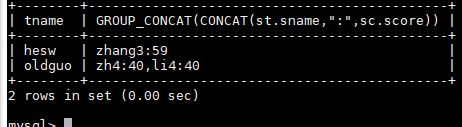
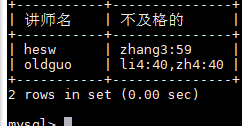
列别名,列别名可以被 having 和 order by 调用
SELECT t.tname as 讲师名 ,GROUP_CONCAT(CONCAT(st.sname,":",sc.score)) as 不及格的 FROM teacher as t JOIN course as c ON t.tno=c.tno JOIN sc ON c.cno=sc.cno JOIN student as st ON sc.sno=st.sno WHERE sc.score<60 GROUP BY t.tno;
元数据获取
元数据是存储在"基表"中,通过专用的DDL语句,DCL语句进行修改,通过专用视图和命令进行元数据的查询,information_schema中保存了大量元数据查询的视图,show 命令是封装好功能,提供元数据查询基础功能
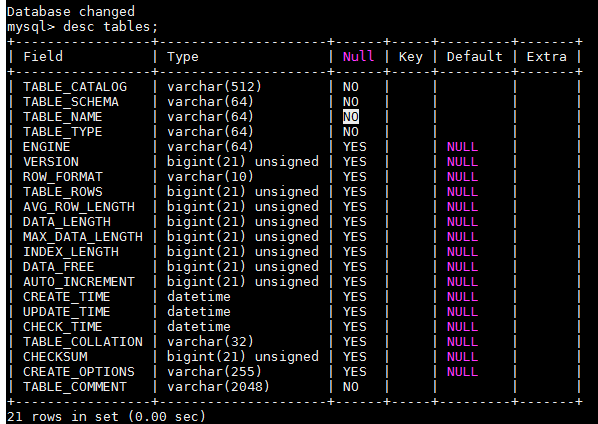
information_schema的基本应用
tables 视图的应用
-
TABLE_SCHEMA 表所在的库名
-
TABLE_NAME 表名
-
ENGINE 存储引擎
-
TABLE_ROWS 数据行
-
AVG_ROW_LENGTH 平均行长度
-
INDEX_LENGTH 索引长度
mysql> use information_schema; mysql> desc tables;
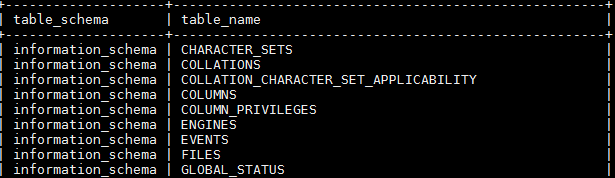
显示所有的库和表的信息
SELECT table_schema,table_name FROM information_schema.tables;
以下模式world city,country,countrylanguage,显示所有的库和表的信息
SELECT table_schema,GROUP_CONCAT(table_name) FROM information_schema.tables GROUP BY table_schema \G;

查询所有innodb引擎的表
SELECT table_schema,table_name ,ENGINE FROM information_schema.tables WHERE ENGINE='innodb';

统计school下的student表占用空间大小,表的数据量=平均行长度*行数+索引长度
AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH
SELECT table_name,(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024 FROM information_schema.TABLES WHERE table_schema='school' AND table_name='student';

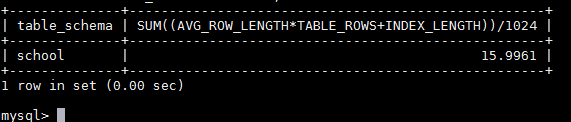
统计school库数据量总大小
SELECT table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024 FROM information_schema.TABLES WHERE table_schema='school';
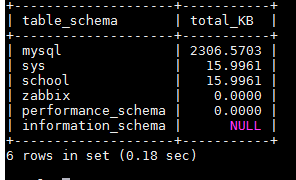
统计每个库的数据量大小,并按数据量从大到小排序
SELECT table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024 AS total_KB FROM information_schema.TABLES GROUP BY table_schema ORDER BY total_KB DESC ;
concat()函数拼接语句或命令
模仿以下语句,进行数据库的分库分表备份
mysqldump -uroot -p123 world city >/bak/world_city.sql
SELECT
CONCAT("mysqldump -uroot -p123 ",table_schema," ",table_name
," >/bak/",table_schema,"_",table_name,".sql")
FROM information_schema.tables;

模仿以下语句,进行批量生成对school库下所有表进行操作
ALTER TABLE world.city DISCARD TABLESPACE;
SELECT
CONCAT("ALTER TABLE ",table_schema,".",table_name," DISCARD TABLESPACE;")
FROM information_schema.tables
WHERE table_schema='school';

show介绍
show databases; 查看数据库名 show tables; 查看表名 show create database xx; 查看建库语句 show create table xx; 查看建表语句 show processlist; 查看所有用户连接情况 show charset; 查看支持的字符集 show collation; 查看所有支持的校对规则 show grants for xx; 查看用户的权限信息 show variables like '%xx%' 查看参数信息 show engines; 查看所有支持的存储引擎类型 show index from xxx 查看表的索引信息 show engine innodb status\G 查看innoDB引擎详细状态信息 show binary logs 查看二进制日志的列表信息 show binlog events in '' 查看二进制日志的事件信息(放文件名) show master status ; 查看mysql当前使用二进制日志信息 show slave status\G 查看从库状态信息 show relaylog events in '' 查看中继日志的事件信息(放文件名) show status like '' 查看数据库整体状态信息
注意问题:
关于group by的sql_mode
说明:
-
1. 在5.7版本中MySQL sql_mode参数中自带,5.6和8.0都没有
-
2. 在带有group by 字句的select中,select 后的条件列(非主键列),要么是group by后的列,要么需要在函数中包裹

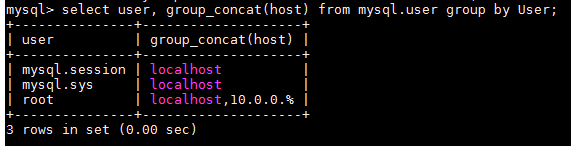
解决1 函数包裹
select user, group_concat(host) from mysql.user group by User;
解决2 在sql_mode中禁用 only_full_group_by
select @@sql_mode; mysql> select @@sql_mode; +------------------------------------------------------------------------------------------------------------------------------------- ------+ | @@sql_mode | +------------------------------------------------------------------------------------------------------------------------------------- ------+ | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTIT UTION | +------------------------------------------------------------------------------------------------------------------------------------- ------+ 1 row in set (0.00 sec)
在配置文件中禁用
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTIT UTION

 浙公网安备 33010602011771号
浙公网安备 33010602011771号