机器学习 Tensorflow 线程队列与IO操作
Tensorflow队列
在训练样本的时候,希望读入的训练样本时有序的
tf.FIFOQueue 先进先出队列,按顺序出队列
tf.RandomShuffleQueue 随机出队列
tf.FIFOQueue
FIFOQueue(capacity, dtypes, name='fifo_queue')创建一个以先进先出的顺序对元素进行排队的队列
-
capacity:整数。可能存储在此队列中的元素数量的上限
-
dtypes:DType对象列表。长度dtypes必须等于每个队列元素中的张量数,dtype的类型形状,决定了后面进队列元素形状
method
-
dequeue(name=None) 出列
-
enqueue(vals, name=None): 入列
-
enqueue_many(vals, name=None):vals列表或者元组返回一个进队列操作
-
size(name=None), 返回一个tensor类型的对象, 包含的value是整数
案例(同步操作一个出队列、+1、入队列操作)
入队列需要注意

import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def fifoqueue():
# 创建队列指定队列的元素
queue = tf.FIFOQueue(3, tf.float32)
# 向队列中添加元素
en_many = queue.enqueue_many([[0.1, 0.2, 0.3], ])
# 定义一个出列的操作
deq_op = queue.dequeue()
# 对于出列的对象 +1
# 实现了运算符的重载, 如果是加号 可以将 1转换为tensor类型 并且调用 add
incre_op = deq_op + 1
# 让 +1的对象在重新入列
enq_op = queue.enqueue(incre_op)
# 必须在会话中运行op对象
# 以下的操作都是在主线程中完成的都是同步操作
with tf.Session() as sess:
# 运行添加元素的op (0.1, 0.2, 0.3)
sess.run(en_many)
# # 完成值的处理操作
for i in range(3):
sess.run(enq_op)
# # 将队列的数据取出, 将数据交给模型开始训练
for i in range(queue.size().eval()):
ret = sess.run(deq_op)
print(ret)
if __name__ == '__main__':
fifoqueue()
分析:当数据量很大时,入队操作从硬盘中读取数据,放入内存中,主线程需要等待入队操作完成,才能进行训练。会话里可以运行多个线程,实现异步读取。
队列管理器
tf.train.QueueRunner(queue, enqueue_ops=None)创建一个QueueRunner
-
queue:A Queue
-
enqueue_ops:添加线程的队列操作列表,[]*2,指定两个线
create_threads(sess, coord=None,start=False)创建线程来运行给定会话的入队操作
-
start:布尔值,如果True启动线程;如果为False调用者
-
必须调用start()启动线
-
coord:线程协调器,后面线程管理需要用到
异步操作
- 通过队列管理器来实现变量加1,入队,主线程出队列的操作,观察效果
分析:
- 这时候有一个问题就是,入队自顾自的去执行,在需要的出队操作完成之后,程序没法结束。需要一个实现线程间的同步,终止其他线程。
线程协调器
tf.train.Coordinator()
- 线程协调员,实现一个简单的机制来协调一组线程的终止
-
request_stop()
-
should_stop() 检查是否要求停止(一般不用)
-
join(threads=None, stop_grace_period_secs=120)等待线程终止
return:线程协调员实例
import tensorflow as tf
def async_opration():
"""
通过队列管理器和线程协调器实现变量+1的
:return: None
"""
# 定义一个队列 容量1000, 类型tf.float32
queue = tf.FIFOQueue(1000, tf.float32)
# 完成一个自增的操作 并且入列的操作
var = tf.Variable(0.0)
# assign_add操作 和 enq_op 不是同步执行, assign_add操作有可能执行很多次才会执行enq_op操作
incre_op = tf.assign_add(var, tf.constant(1.0))
# 入列
enq_op = queue.enqueue(incre_op)
# 出列
deq_op = queue.dequeue()
# 定义队列管理器
qr = tf.train.QueueRunner(queue=queue, enqueue_ops=[enq_op] * 2)
init_op = tf.global_variables_initializer()
# 通过with上下文创建的会话会自动关闭, 主线程已经执行完毕了
# 子线程会自动停止吗? 子线程并不会退出 而是一种挂起的状态
with tf.Session() as sess:
# sess = tf.Session()
sess.run(init_op)
# 创建线程协调器
coord = tf.train.Coordinator()
# 通过队列管理器来创建需要执行的入列的线程
# start为True 表示创建的线程 需要立即开启, enqueue的操作已经开始执行, 并且是两个线程在执行
threads = qr.create_threads(sess=sess, coord=coord, start=True)
# 入列的操作在另外一个线程执行
for i in range(1000):
# 主线程deq 出列
ret = sess.run(deq_op)
print(ret)
# 主线程的任务执行结束
# 应该请求结束子线程
coord.request_stop()
# coord.should_stop()
# 加上线程同步
coord.join(threads=threads)
return None
if __name__ == '__main__':
async_opration()

tensorflow文件读取
文件读取流程

1、文件读取API-文件队列构造
-
tf.train.string_input_producer(string_tensor,,shuffle=True)将输出字符串(例如文件名)输入到管道队列
-
string_tensor 含有文件名的1阶张量
-
num_epochs:过几遍数据,默认无限过数据
-
return:具有输出字符串的队列
2、文件读取API-文件阅读器
根据文件格式,选择对应的文件阅读器
class tf.TextLineReader
-
阅读文本文件逗号分隔值(CSV)格式,默认按行读取
-
return:读取器实例
tf.FixedLengthRecordReader(record_bytes)
-
要读取每个记录是固定数量字节的二进制文件
-
record_bytes:整型,指定每次读取的字节数
-
return:读取器实例
tf.TFRecordReader
- 读取TfRecords文件
有一个共同的读取方法:
-
read(file_queue):从队列中读取指定数量内容
-
返回一个Tensors元组(key文件名字,value默认的内容(行或者字节或者图片))
3、文件读取API-文件内容解码器
由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
tf.decode_csv(records,record_defaults=None,field_delim = None,name = None)
-
将CSV转换为张量,与tf.TextLineReader搭配使用
-
records:tensor型字符串,每个字符串是csv中的记录行
-
record_defaults:指定分割后每个属性的类型,比如分割后会有三列,第二个参数就应该是[[1],[],['string']],不指定类型(设为空[])也可以。如果分割后的属性比较多,比如有100个,可以用[[ ] * 100]来表示
-
field_delim:默认分割符”,”
tf.decode_raw(bytes,out_type,little_endian = None,name = None)
- 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用,将字符串表示的二进制读取为uint8格式
开启线程操作
tf.train.start_queue_runners(sess=None,coord=None) 收集所有图中的队列线程,并启动线程
-
sess:所在的会话中
-
coord:线程协调器
-
return:返回所有线程队列
如果读取的文件为多个或者样本数量为多个,怎么去管道读取?
管道读端批处理
tf.train.batch(tensors,batch_size,num_threads = 1,capacity = 32,name=None)读取指定大小(个数)的张量
-
tensors:可以是包含张量的列表
-
batch_size:从队列中读取的批处理大小
-
num_threads:进入队列的线程数
-
capacity:整数,队列中元素的最大数量
-
return:tensors
tf.train.shuffle_batch(tensors,batch_size,capacity,min_after_dequeue, num_threads=1,)
-
乱序读取指定大小(个数)的张量
-
min_after_dequeue:留下队列里的张量个数,能够保持随机打乱
文件读取案例
import tensorflow as tf
import os
def csv_reader():
# 获取./data/csvdata/ 路径所有的文件
file_names = os.listdir('./csvdata/')
file_names = [os.path.join('./csvdata/', file_name) for file_name in file_names]
# file_names = ["./data/csvdata/" + file_name for file_name in file_names]
print(file_names)
# 通过文件名创建文件队列 file_queue
file_queue = tf.train.string_input_producer(file_names)
# 创建文件读取器 reader 按行读取
reader = tf.TextLineReader()
# 通过reader对象调用read reader.read(file_queue)
# 返回的结果 是 key value value 指的是某一个文件的一行
key, value = reader.read(file_queue)
print(key, value)
# 对value 进行decode操作
col1, col2 = tf.decode_csv(value, record_defaults=[['null'], ['null']],field_delim=',')
# 建立管道读的批处理
col1_batch, col2_batch = tf.train.batch(tensors=[col1, col2], batch_size=100, num_threads=2, capacity=10)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
ret = sess.run([col1_batch, col2_batch])
print(ret)
# 主线程的任务执行完毕之后, 应该请求关闭子线程
coord.request_stop()
coord.join(threads)
if __name__ == '__main__':
csv_reader()


"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day5/3-代码/day5_test.py ['./csvdata/A.csv', './csvdata/B.csv', './csvdata/C.csv'] Tensor("ReaderReadV2:0", shape=(), dtype=string) Tensor("ReaderReadV2:1", shape=(), dtype=string) 2020-01-13 22:51:39.323455: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 22:51:39.324455: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE2 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 22:51:39.324455: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE3 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 22:51:39.325455: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 22:51:39.325455: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 22:51:39.326455: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations. [array([b'Sea1', b'Sea2', b'Sea3', b'Alpha1', b'Alpha2', b'Alpha3', b'Bee1', b'Bee2', b'Bee3', b'Sea1', b'Sea2', b'Sea3', b'Alpha1', b'Alpha2', b'Alpha3', b'Bee1', b'Bee2', b'Bee3', b'Alpha1', b'Alpha2', b'Alpha3', b'Sea1', b'Sea2', b'Sea3', b'Bee1', b'Bee2', b'Bee3', b'Sea1', b'Sea2', b'Sea3', b'Bee1', b'Bee2', b'Bee3', b'Alpha1', b'Alpha2', b'Alpha3', b'Sea1', b'Sea2', b'Sea3', b'Bee1', b'Bee2', b'Bee3', b'Alpha1', b'Alpha2', b'Alpha3', b'Sea1', b'Sea2', b'Sea3', b'Alpha1', b'Alpha2', b'Alpha3', b'Bee1', b'Bee2', b'Bee3', b'Bee1', b'Bee2', b'Bee3', b'Sea1', b'Sea2', b'Sea3', b'Alpha1', b'Alpha2', b'Alpha3', b'Sea1', b'Sea2', b'Sea3', b'Alpha1', b'Alpha2', b'Alpha3', b'Bee1', b'Bee2', b'Bee3', b'Alpha1', b'Alpha2', b'Alpha3', b'Sea1', b'Sea2', b'Sea3', b'Bee1', b'Bee2', b'Bee3', b'Sea1', b'Sea2', b'Sea3', b'Bee1', b'Bee2', b'Bee3', b'Alpha1', b'Alpha2', b'Alpha3', b'Bee1', b'Bee2', b'Bee3', b'Sea1', b'Sea2', b'Sea3', b'Alpha1', b'Alpha2', b'Alpha3', b'Bee1'], dtype=object), array([b'C1', b'C2', b'C3', b'A1', b'A2', b'A3', b'B1', b'B2', b'B3', b'C1', b'C2', b'C3', b'A1', b'A2', b'A3', b'B1', b'B2', b'B3', b'A1', b'A2', b'A3', b'C1', b'C2', b'C3', b'B1', b'B2', b'B3', b'C1', b'C2', b'C3', b'B1', b'B2', b'B3', b'A1', b'A2', b'A3', b'C1', b'C2', b'C3', b'B1', b'B2', b'B3', b'A1', b'A2', b'A3', b'C1', b'C2', b'C3', b'A1', b'A2', b'A3', b'B1', b'B2', b'B3', b'B1', b'B2', b'B3', b'C1', b'C2', b'C3', b'A1', b'A2', b'A3', b'C1', b'C2', b'C3', b'A1', b'A2', b'A3', b'B1', b'B2', b'B3', b'A1', b'A2', b'A3', b'C1', b'C2', b'C3', b'B1', b'B2', b'B3', b'C1', b'C2', b'C3', b'B1', b'B2', b'B3', b'A1', b'A2', b'A3', b'B1', b'B2', b'B3', b'C1', b'C2', b'C3', b'A1', b'A2', b'A3', b'B1'], dtype=object)] Process finished with exit code 0
tensorflow图像读取
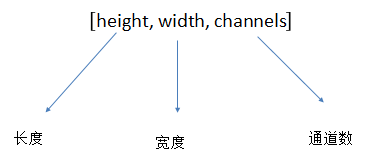
图像数字化三要素
- 三要素:长度、宽度、通道数

三要素与张量的关系
图像基本操作
目的:
-
1、增加图片数据的统一性
-
2、所有图片转换成指定大小
-
3、缩小图片数据量,防止增加开销
操作:
- 1、缩小图片大小
图像基本操作API
-
tf.image.resize_images(images, size)缩小图片
-
images:4-D形状[batch, height, width, channels]或3-D形状的张量[height, width, channels]的图片数据
-
size:1-D int32张量:new_height, new_width,图像的新尺寸返回4-D格式或者3-D格式图片
图像读取API
图像读取器
-
tf.WholeFileReader 将文件的全部内容作为值输出的读取器
-
return:读取器实例
-
read(file_queue):输出将是一个文件名(key)和该文件的内容(值)
图像解码器
tf.image.decode_jpeg(contents)
-
将JPEG编码的图像解码为uint8张量
-
return:uint8张量,3-D形状[height, width, channels]
tf.image.decode_png(contents)
-
将PNG编码的图像解码为uint8或uint16张量
-
return:张量类型,3-D形状[height, width, channels]
图片批处理案例流程
-
1、构造图片文件队列
-
2、构造图片阅读器
-
3、读取图片数据
-
4、处理图片数据
import tensorflow as tf
import os
def pic_reader():
file_names = os.listdir('./dog/')
file_names = [os.path.join('./dog/', file_name) for file_name in file_names]
# 创建文件队列
file_queue = tf.train.string_input_producer(file_names)
# 创建读取器
reader = tf.WholeFileReader()
# key是文件名, value图片的数组数据
key, value = reader.read(file_queue)
# 通过解码的方式获取value的信息
image = tf.image.decode_jpeg(value)
# 在进行图片的批处理之前 需要讲图片的形状修改为一样的 [200, 200,?] --> [height, width,?]
resize_image = tf.image.resize_images(image, size=[200,200])
# 设置图片的管道, [200, 200,?] --> [200, 200, None]图片的形状还没有固定,可以通过set_shape
resize_image.set_shape([200, 200, 3])
print(resize_image)
# 要去进行批处理的时候还需要知道图片的通道数
image_batch = tf.train.batch(tensors=[resize_image],batch_size=100, num_threads=2,capacity=100)
print(image_batch)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord=coord)
ret = sess.run(image_batch)
print(ret)
coord.request_stop()
coord.join(threads)
if __name__ == '__main__':
pic_reader()
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day5/3-代码/day5_test.py Tensor("Squeeze:0", shape=(200, 200, 3), dtype=float32) Tensor("batch:0", shape=(100, 200, 200, 3), dtype=float32) 2020-01-13 23:34:10.831393: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 23:34:10.831393: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE2 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 23:34:10.832393: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE3 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 23:34:10.832393: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 23:34:10.832393: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-13 23:34:10.833393: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations. [[[[ 33. 47. 86. ] [ 36.725 50.725 88.235 ] [ 40.45 54.45 91.45 ] ... [ 6.2350006 3.2350006 0. ] [ 6. 3. 0. ] [ 6. 3. 0. ]] [[ 31.03 45.03 84.03 ] [ 33.28735 47.28735 86.265 ] [ 36.027348 50.027348 88.03205 ] ... [ 6.988525 5.9585247 1.97 ] [ 6.985 5.955 1.97 ] [ 6.985 5.955 1.97 ]] [[ 36.82 49.85 93.7 ] [ 37.6097 50.639698 93.044395 ] [ 38.8894 52.394703 92.8494 ] ... [ 9.167951 7.1979504 8.047951 ] [ 7.9506106 5.980611 6.8306108 ] [ 7. 5.0299997 5.88 ]] ... [[ 11.460022 14.325027 19.325027 ] [ 5.3584476 6.089023 8.854024 ] [ 12.266381 7.366382 7.406382 ] ... [ 21.872694 3.8938441 2.3638453 ] [ 18.013 2.494126 1.5141152 ] [ 13.1349945 0. 0. ]] [[ 0. 0. 5. ] [ 7.151982 7.1072836 9.849935 ] [ 22.589865 17.673965 17.65457 ] ... [ 23.177933 5.6338344 4.089736 ] [ 20.740635 3.7300262 2.7194169 ] [ 16.359985 0.2999878 0.23999023]] [[ 0. 0. 5. ] [ 21.605 20.115 22.135 ] [ 50.07 44.64 42.7 ] ... [ 32.649994 14.649994 12.649994 ] [ 31.430038 13.430038 11.430038 ] [ 28. 10. 8. ]]] [[[195. 194. 166. ] [194.5 193.5 165.5 ] [193. 192. 164. ] ... [154. 144. 108. ] [154. 144. 108. ] [151. 145. 111. ]] [[195. 194. 166. ] [194.5 193.5 165.5 ] [193. 192. 164. ] ... [154. 144. 108. ] [154. 144. 108. ] [151. 145. 111. ]] [[195. 194. 166. ] [194.5 193.5 165.5 ] [193. 192. 164. ] ... [155. 145. 109. ] [155. 145. 109. ] [152. 146. 110.52 ]] ... [[ 91. 80. 52. ] [ 91.5 80.5 50.5 ] [ 94. 86. 50. ] ... [ 87.69501 63.695007 35.695007 ] [ 92. 68. 42. ] [ 94.109985 74.109985 41.109985 ]] [[ 89.73999 78.73999 50.73999 ] [ 90.5 79.5 49.5 ] [ 94. 86. 50. ] ... [ 87.609985 63.609985 35.609985 ] [ 90.21997 66.21997 40.21997 ] [ 90.849976 70.849976 37.849976 ]] [[ 87.869995 76.869995 48.869995 ] [ 89.369995 78.369995 48.369995 ] [ 94. 86. 50. ] ... [ 83.435 59.434998 31.434998 ] [ 84.869995 60.869995 34.869995 ] [ 87.435 67.435 34.434998 ]]] [[[ 22. 22. 32. ] [ 33.535 32.535 39.545002 ] [ 10.060001 10.060001 10.080002 ] ... [118.72476 120.72476 132.72476 ] [132.96008 134.96008 146.96008 ] [123.960205 123.960205 131.9602 ]] [[ 60.1 60.1 70.1 ] [ 40.140324 39.140324 46.150326 ] [ 16.0429 16.034351 16.080002 ] ... [ 43.8519 46.8519 54.1419 ] [ 35.26266 38.26266 45.55266 ] [ 51.585205 50.875206 56.730206 ]] [[ 79.97 79.97 91.39 ] [ 36.090004 35.090004 42.100002 ] [ 18.8358 18.8258 20.8558 ] ... [ 40.415207 41.415207 45.705204 ] [ 32.694893 33.694893 37.984894 ] [ 58.731674 54.601673 58.891674 ]] ... [[100.869995 76.869995 72.869995 ] [119.936615 95.936615 91.936615 ] [167.12769 143.12769 139.12769 ] ... [149.20277 124.20277 119.20277 ] [152.75244 127.75244 122.75244 ] [127.0557 104.0557 98.0557 ]] [[128.51016 103.930145 101.38019 ] [128.22784 103.50427 101.821434 ] [126.68005 101.81003 100.420105 ] ... [141.86383 115.993805 111.43316 ] [143.90657 117.74654 114.776596 ] [134.34804 110.76802 105.05803 ]] [[143.13007 117.130066 118.130066 ] [123.900116 97.40511 101.39511 ] [126.49757 99.497574 104.497574 ] ... [158.9558 130.9558 127.47078 ] [156.62021 127.62021 129.62021 ] [137.70328 112.703285 107.703285 ]]] ... [[[145. 147. 142. ] [143.425 145.425 140.425 ] [141.85 143.8 138.8 ] ... [131.52493 100.099945 82.22492 ] [138.34996 106.39996 91.14995 ] [139. 107. 92. ]] [[145. 147. 142. ] [143.425 145.425 140.425 ] [141.8775 143.8275 138.8275 ] ... [130.97493 99.54994 81.67492 ] [137.79996 105.84996 90.599945 ] [138.45 106.45 91.45 ]] [[145. 147. 142. ] [143.425 145.425 140.425 ] [141.9 143.85 138.85 ] ... [130.42493 98.99995 81.23992 ] [137.24995 105.299965 90.05995 ] [137.9 105.9 90.9 ]] ... [[116.849945 116.849945 114.849945 ] [117.89995 117.89995 115.89995 ] [118.49494 118.49494 116.49494 ] ... [157.77997 161.77997 162.77997 ] [162.81996 166.81996 167.81996 ] [163.29999 167.29999 168.29999 ]] [[111.89999 111.89999 109.89999 ] [112.94999 112.94999 110.94999 ] [113.37998 113.37998 111.37998 ] ... [157.94498 161.94498 162.94498 ] [161.82997 165.82997 166.82997 ] [162.2 166.2 167.2 ]] [[111. 111. 109. ] [112.05 112.05 110.05 ] [112.45 112.45 110.45 ] ... [157.97498 161.97498 162.97498 ] [161.64998 165.64998 166.64998 ] [162. 166. 167. ]]] [[[225. 219. 207. ] [214. 208. 196. ] [213. 207. 195. ] ... [221.85016 215.85016 199.85016 ] [212.99002 206.99002 190.99002 ] [216. 210. 198. ]] [[213.015 207.015 195.015 ] [217.97 211.97 199.97 ] [219.02501 213.02501 201.02501 ] ... [217.87288 211.87288 195.87288 ] [216.9946 210.9946 194.9946 ] [215. 209. 197. ]] [[220.09 214.09 202.09 ] [216.93544 210.93544 198.93544 ] [214.9997 208.9997 196.9997 ] ... [221.33514 215.33514 199.33514 ] [219.00926 213.00926 197.00926 ] [214.97 208.97 196.97 ]] ... [[226.78546 226.60553 226.56055 ] [237.53633 237.3564 236.36595 ] [233.38574 233.20581 231.16083 ] ... [229.70834 217.61838 204.63339 ] [222.8302 214.69525 195.73933 ] [212.04216 200.9522 168.9522 ]] [[187.28864 188.28864 190.28864 ] [169.6994 171.6994 170.6994 ] [163.03944 165.03944 162.05885 ] ... [236.34972 226.83562 213.29066 ] [217.00072 210.00072 191.00072 ] [214.48495 203.48495 171.48495 ]] [[146.98502 171.98502 152.98502 ] [159.41502 174.44504 159.43503 ] [169.93037 177.96037 164.95036 ] ... [228.96277 227.44778 217.29794 ] [227.82532 218.81534 187.77542 ] [208.52728 203.52728 174.52728 ]]] [[[145. 147. 142. ] [143.425 145.425 140.425 ] [141.85 143.8 138.8 ] ... [131.52493 100.099945 82.22492 ] [138.34996 106.39996 91.14995 ] [139. 107. 92. ]] [[145. 147. 142. ] [143.425 145.425 140.425 ] [141.8775 143.8275 138.8275 ] ... [130.97493 99.54994 81.67492 ] [137.79996 105.84996 90.599945 ] [138.45 106.45 91.45 ]] [[145. 147. 142. ] [143.425 145.425 140.425 ] [141.9 143.85 138.85 ] ... [130.42493 98.99995 81.23992 ] [137.24995 105.299965 90.05995 ] [137.9 105.9 90.9 ]] ... [[116.849945 116.849945 114.849945 ] [117.89995 117.89995 115.89995 ] [118.49494 118.49494 116.49494 ] ... [157.77997 161.77997 162.77997 ] [162.81996 166.81996 167.81996 ] [163.29999 167.29999 168.29999 ]] [[111.89999 111.89999 109.89999 ] [112.94999 112.94999 110.94999 ] [113.37998 113.37998 111.37998 ] ... [157.94498 161.94498 162.94498 ] [161.82997 165.82997 166.82997 ] [162.2 166.2 167.2 ]] [[111. 111. 109. ] [112.05 112.05 110.05 ] [112.45 112.45 110.45 ] ... [157.97498 161.97498 162.97498 ] [161.64998 165.64998 166.64998 ] [162. 166. 167. ]]]] Process finished with exit code 0
小案例
import tensorflow as tf
import os
class Cifar(object):
"""
读取二进制文件的演示, 将二进制文件得到的数据存储到TFRecords 并且读取TFRecords数据
"""
def __init__(self):
self.height = 32
self.width = 32
self.channels = 3 # 彩色的图片
self.label_bytes = 1
self.image_bytes = self.height * self.width * self.channels
# 每次需要读取的字节大小
self.bytes = self.label_bytes + self.image_bytes
def read_and_decode(self, file_names):
"""
读取并且解码二进制的图片
:return: 将批处理的图片和标签返回
"""
# 构建文件队列 通过文件名的列表
file_queue = tf.train.string_input_producer(file_names)
# 创建文件读取器 并且指定每次读取的字节大小 为 self.bytes
reader = tf.FixedLengthRecordReader(self.bytes)
# 读取二进制文件数据的 uint8 一个字节 3073 = 1 + 3072
key, value = reader.read(file_queue)
# 完成对于二进制数据的解码操作
label_image = tf.decode_raw(value, tf.uint8)
# 在decode image 之前需要讲读取的3073个字节分割成 1 和 3072
# 通过切片的方式获取3073个字符串中的第一个 是一个字符串类型
# 截取的起始位置和长度需要通过一个一阶的张量来表示
# 将self.bytes 切分为 self.label_bytes 和 self.image_bytes
label = tf.cast(tf.slice(label_image, [0], [self.label_bytes]),tf.int32)
image = tf.cast(tf.slice(label_image, [self.label_bytes], [self.image_bytes]), tf.int32)
# 图片的字节为3072, 需要将这个3072个字节的形状重新设置 [32 * 32 * 3] ---> 就是图片的张量
reshape_image = tf.reshape(image, shape=[32, 32, 3])
# 由于读取的图片的形状都是一样的 就不需要做resize处理 就可以直接进行批处理的操作
image_batch, label_batch = tf.train.batch([reshape_image, label], batch_size=100, num_threads=2, capacity=100)
return image_batch, label_batch
def save_to_tfrecords(self):
"""
将读取的图片数据存储为tfrecord格式的文件
:return:
"""
return None
def read_from_tfrecords(self):
"""
从tfrecords格式的文件读取对应的数据
:return:
"""
return None
def call_cifar():
# 获取某一个路径下的文件名
file_names = os.listdir('./cifar-10-batches-bin/')
file_names = [os.path.join('./cifar-10-batches-bin/', file_name) for file_name in file_names if file_name[-3:] == 'bin']
# 创建对象 调用对象方法
cifar = Cifar()
batch_image, batch_label = cifar.read_and_decode(file_names)
print("===========")
print(batch_image, batch_label)
# # 运行已经设定好的图
with tf.Session() as sess:
# 开启子线程执行
coord = tf.train.Coordinator() # 线程协调器
threads = tf.train.start_queue_runners(sess, coord=coord)
ret = sess.run([batch_image, batch_label])
print(ret)
coord.request_stop()
coord.join(threads)
if __name__ == '__main__':
call_cifar()
输出结果图片存储,计算的类型
存储:uint8(节约空间)
矩阵计算:float32(提高精度)
TFRecords分析、存取
-
TFRecords是Tensorflow设计的一种内置文件格式,是一种二进制文件
-
它能更好的利用内存,更方便复制和移动为了将二进制数据和标签(训练的类别标签)数据存储在同一个文件中
TFRecords存储
1、建立TFRecord存储器
tf.python_io.TFRecordWriter(path),写入tfrecords文件
-
path: TFRecords文件的路径
-
return:写文件
method
-
write(record):向文件中写入一个字符串记录
-
close():关闭文件写入器
注:字符串为一个序列化的Example,Example.SerializeToString()
2、构造每个样本的Example协议块
tf.train.Example(features=None) 写入tfrecords文件
-
features:tf.train.Features类型的特征实例
-
return:example格式协议块
tf.train.Features(feature=None)
构建每个样本的信息键值对feature:字典数据,key为要保存的名字,
-
value为tf.train.Feature实例
-
return:Features类型
-
tf.train.Feature(**options)
**options:例如
-
bytes_list=tf.train. BytesList(value=[Bytes])
-
int64_list=tf.train. Int64List(value=[Value])
-
tf.train. Int64List(value=[Value])
-
tf.train. BytesList(value=[Bytes])
-
tf.train. FloatList(value=[value])
TFRecords读取方法
同文件阅读器流程,中间需要解析过程
解析TFRecords的example协议内存块
tf.parse_single_example(serialized,features=None,name=None) 解析一个单一的Example原型
-
serialized:标量字符串Tensor,一个序列化的Example
-
features:dict字典数据,键为读取的名字,值为FixedLenFeature
-
return:一个键值对组成的字典,键为读取的名字
-
tf.FixedLenFeature(shape,dtype)
-
shape:输入数据的形状,一般不指定,为空列表
-
dtype:输入数据类型,与存储进文件的类型要一致类型只能是float32,int64,string
CIFAR-10 批处理结果存入tfrecords流程
-
1、构造存储器
-
2、构造每一个样本的Example
-
3、写入序列化的Example
读取tfrecords流程
-
1、构造TFRecords阅读器
-
2、解析Example
-
3、转换格式,bytes解码
"""
读取二进制文件转换成张量,写进TFRecords,同时读取TFRcords
"""
import tensorflow as tf
# 命令行参数
FLAGS = tf.app.flags.FLAGS # 获取值
tf.app.flags.DEFINE_string("tfrecord_dir", "cifar10.tfrecords", "写入图片数据文件的文件名")
# 读取二进制转换文件
class CifarRead(object):
"""
读取二进制文件转换成张量,写进TFRecords,同时读取TFRcords
"""
def __init__(self, file_list):
"""
初始化图片参数
:param file_list:图片的路径名称列表
"""
# 文件列表
self.file_list = file_list
# 图片大小,二进制文件字节数
self.height = 32
self.width = 32
self.channel = 3
self.label_bytes = 1
self.image_bytes = self.height * self.width * self.channel
self.bytes = self.label_bytes + self.image_bytes
def read_and_decode(self):
"""
解析二进制文件到张量
:return: 批处理的image,label张量
"""
# 1.构造文件队列
file_queue = tf.train.string_input_producer(self.file_list)
# 2.阅读器读取内容
reader = tf.FixedLengthRecordReader(self.bytes)
key, value = reader.read(file_queue) # key为文件名,value为元组
print(value)
# 3.进行解码,处理格式
label_image = tf.decode_raw(value, tf.uint8)
print(label_image)
# 处理格式,image,label
# 进行切片处理,标签值
# tf.cast()函数是转换数据格式,此处是将label二进制数据转换成int32格式
label = tf.cast(tf.slice(label_image, [0], [self.label_bytes]), tf.int32)
# 处理图片数据
image = tf.slice(label_image, [self.label_bytes], [self.image_bytes])
print(image)
# 处理图片的形状,提供给批处理
# 因为image的形状已经固定,此处形状用动态形状来改变
image_tensor = tf.reshape(image, [self.height, self.width, self.channel])
print(image_tensor)
# 批处理图片数据
image_batch, label_batch = tf.train.batch([image_tensor, label], batch_size=10, num_threads=1, capacity=10)
return image_batch, label_batch
def write_to_tfrecords(self, image_batch, label_batch):
"""
将文件写入到TFRecords文件中
:param image_batch:
:param label_batch:
:return:
"""
# 建立TFRecords文件存储器
writer = tf.python_io.TFRecordWriter('cifar10.tfrecords') # 传进去命令行参数
# 循环取出每个样本的值,构造example协议块
for i in range(10):
# 取出图片的值, #写进去的是值,而不是tensor类型,
# 写入example需要bytes文件格式,将tensor转化为bytes用tostring()来转化
image = image_batch[i].eval().tostring()
# 取出标签值,写入example中需要使用int形式,所以需要强制转换int
label = int(label_batch[i].eval()[0])
# 构造每个样本的example协议块
example = tf.train.Example(features=tf.train.Features(feature={
"image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])),
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
}))
# 写进去序列化后的值
writer.write(example.SerializeToString()) # 此处其实是将其压缩成一个二进制数据
writer.close()
return None
def read_from_tfrecords(self):
"""
从TFRecords文件当中读取图片数据(解析example)
:param self:
:return: image_batch,label_batch
"""
# 1.构造文件队列
file_queue = tf.train.string_input_producer(['cifar10.tfrecords']) # 参数为文件名列表
# 2.构造阅读器
reader = tf.TFRecordReader()
key, value = reader.read(file_queue)
# 3.解析协议块,返回的值是字典
feature = tf.parse_single_example(value, features={
"image": tf.FixedLenFeature([], tf.string),
"label": tf.FixedLenFeature([], tf.int64)
})
# feature["image"],feature["label"]
# 处理标签数据 ,cast()只能在int和float之间进行转换
label = tf.cast(feature["label"], tf.int32) # 将数据类型int64 转换为int32
# 处理图片数据,由于是一个string,要进行解码, #将字节转换为数字向量表示,字节为一字符串类型的张量
# 如果之前用了tostring(),那么必须要用decode_raw()转换为最初的int类型
# decode_raw()可以将数据从string,bytes转换为int,float类型的
image = tf.decode_raw(feature["image"], tf.uint8)
# 转换图片的形状,此处需要用动态形状进行转换
image_tensor = tf.reshape(image, [self.height, self.width, self.channel])
# 4.批处理
image_batch, label_batch = tf.train.batch([image_tensor, label], batch_size=10, num_threads=1, capacity=10)
return image_batch, label_batch
if __name__ == '__main__':
# 找到文件路径,名字,构造路径+文件名的列表,"A.csv"...
# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
import os
file_names = os.listdir('./cifar-10-batches-bin/')
file_list = [os.path.join('./cifar-10-batches-bin/', file_name) for file_name in file_names if file_name[-3:] == 'bin']
# 初始化参数
cr = CifarRead(file_list)
# 读取二进制文件
# image_batch, label_batch = cr.read_and_decode()
# 从已经存储的TFRecords文件中解析出原始数据
image_batch, label_batch = cr.read_from_tfrecords()
with tf.Session() as sess:
# 线程协调器
coord = tf.train.Coordinator()
# 开启线程
threads = tf.train.start_queue_runners(sess, coord=coord)
print(sess.run([image_batch, label_batch]))
print("存进TFRecords文件")
cr.write_to_tfrecords(image_batch,label_batch)
print("存进文件完毕")
# 回收线程
coord.request_stop()
coord.join(threads)
输出结果如下
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day5/3-代码/tet.py 2020-01-22 17:51:59.917717: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE instructions, but these are available on your machine and could speed up CPU computations. 2020-01-22 17:51:59.918717: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE2 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-22 17:51:59.918717: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE3 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-22 17:51:59.918717: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-22 17:51:59.919717: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations. 2020-01-22 17:51:59.919717: W c:\tf_jenkins\home\workspace\release-win\m\windows\py\36\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations. [array([[[[115, 118, 121], [122, 124, 126], [129, 133, 136], ..., [156, 155, 155], [153, 147, 144], [143, 140, 139]], [[125, 125, 127], [130, 132, 135], [137, 140, 143], ..., [164, 164, 163], [161, 156, 153], [150, 148, 149]], [[135, 136, 138], [141, 143, 145], [147, 149, 151], ..., [174, 174, 174], [175, 177, 174], [167, 165, 167]], ..., [[112, 113, 113], [112, 113, 114], [114, 116, 116], ..., [188, 188, 185], [174, 140, 120], [111, 106, 107]], [[102, 105, 109], [111, 114, 116], [118, 118, 116], ..., [183, 150, 121], [115, 113, 110], [108, 103, 83]], [[109, 107, 106], [103, 100, 99], [102, 104, 111], ..., [119, 117, 111], [108, 109, 108], [ 91, 77, 70]]], [[[ 71, 70, 72], [ 77, 78, 78], [ 81, 85, 87], ..., [108, 114, 117], [107, 103, 108], [108, 101, 99]], [[ 93, 92, 106], [154, 168, 154], [173, 191, 194], ..., [114, 111, 111], [113, 115, 136], [187, 203, 163]], [[159, 163, 156], [175, 179, 179], [182, 178, 181], ..., [122, 123, 138], [164, 163, 158], [169, 155, 126]], ..., [[143, 106, 63], [ 43, 11, 17], [ 28, 38, 46], ..., [119, 129, 138], [150, 159, 155], [159, 167, 163]], [[122, 87, 86], [ 92, 66, 83], [112, 115, 123], ..., [ 95, 80, 75], [ 80, 87, 77], [ 94, 120, 142]], [[145, 144, 146], [151, 156, 157], [155, 159, 165], ..., [154, 155, 152], [147, 128, 130], [152, 155, 158]]], [[[ 55, 78, 90], [ 82, 75, 81], [105, 116, 135], ..., [154, 156, 175], [186, 196, 199], [204, 206, 201]], [[141, 136, 126], [126, 122, 94], [ 86, 86, 91], ..., [112, 129, 143], [185, 169, 141], [155, 178, 181]], [[118, 61, 79], [108, 129, 158], [128, 110, 122], ..., [147, 132, 124], [115, 96, 113], [112, 62, 97]], ..., [[ 93, 82, 98], [ 94, 94, 105], [118, 115, 98], ..., [ 71, 74, 77], [ 64, 71, 66], [ 62, 48, 41]], [[117, 110, 121], [123, 121, 99], [ 75, 48, 65], ..., [125, 107, 106], [104, 86, 86], [ 75, 50, 50]], [[100, 114, 153], [171, 146, 130], [ 87, 62, 70], ..., [186, 190, 197], [177, 180, 192], [184, 174, 172]]], ..., [[[176, 173, 167], [183, 223, 174], [181, 168, 168], ..., [129, 90, 125], [139, 139, 131], [116, 103, 113]], [[160, 162, 149], [156, 169, 150], [145, 141, 131], ..., [153, 137, 100], [127, 191, 154], [131, 129, 122]], [[144, 162, 165], [191, 204, 192], [191, 173, 168], ..., [151, 127, 59], [ 78, 167, 123], [ 86, 87, 75]], ..., [[139, 156, 164], [157, 149, 146], [144, 133, 119], ..., [122, 118, 121], [118, 118, 117], [116, 119, 122]], [[182, 149, 136], [134, 141, 143], [145, 140, 143], ..., [141, 154, 139], [137, 132, 132], [130, 128, 123]], [[127, 126, 143], [185, 213, 207], [168, 146, 144], ..., [136, 137, 126], [125, 121, 123], [125, 117, 115]]], [[[ 36, 41, 36], [ 33, 37, 35], [ 36, 44, 61], ..., [ 47, 44, 40], [ 36, 36, 30], [ 31, 26, 26]], [[ 29, 23, 27], [ 30, 30, 41], [ 46, 35, 33], ..., [ 60, 45, 41], [ 44, 35, 32], [ 31, 36, 36]], [[ 50, 49, 34], [ 29, 30, 44], [ 58, 59, 61], ..., [ 59, 53, 68], [ 49, 47, 55], [ 86, 46, 31]], ..., [[ 29, 64, 96], [131, 138, 130], [159, 182, 129], ..., [ 67, 61, 57], [ 28, 12, 32], [ 39, 32, 32]], [[ 8, 26, 40], [ 82, 112, 132], [164, 175, 134], ..., [ 66, 21, 2], [ 2, 3, 21], [ 25, 27, 34]], [[ 9, 23, 23], [ 42, 72, 118], [150, 136, 132], ..., [ 5, 3, 2], [ 3, 9, 16], [ 17, 25, 23]]], [[[255, 253, 253], [254, 254, 253], [253, 253, 253], ..., [253, 251, 251], [251, 251, 251], [251, 251, 253]], [[255, 253, 227], [214, 209, 199], [198, 199, 199], ..., [ 22, 15, 1], [ 2, 1, 0], [ 57, 158, 213]], [[255, 249, 137], [ 37, 36, 29], [ 43, 39, 25], ..., [ 8, 10, 19], [ 9, 10, 3], [ 45, 104, 187]], ..., [[255, 248, 132], [ 31, 30, 26], [ 27, 20, 16], ..., [ 30, 28, 35], [ 23, 19, 24], [ 51, 94, 184]], [[255, 247, 129], [ 23, 28, 22], [ 18, 24, 27], ..., [ 85, 90, 78], [ 68, 71, 73], [ 86, 122, 198]], [[255, 248, 223], [161, 116, 102], [100, 101, 102], ..., [222, 222, 222], [222, 222, 222], [224, 234, 246]]]], dtype=uint8), array([0, 7, 4, 2, 5, 3, 0, 4, 1, 3])] 存进TFRecords文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号