机器学习回归算法
回归算法
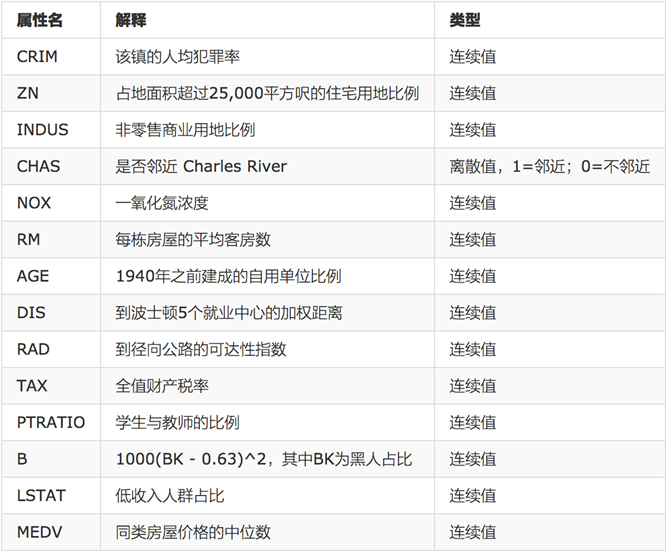
回归是统计学中最有力的工具之一。机器学习监督学习算法分为分类算法和回归算法两种,其实就是根据类别标签分布类型为离散型、连续性而定义的。回归算法用于连续型分布预测,针对的是数值型的样本,使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。那么什么是线性关系和非线性关系?
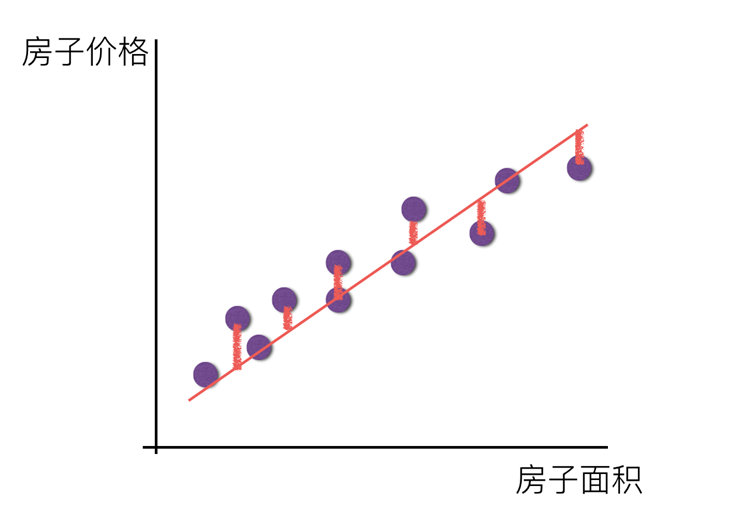
比如说在房价上,房子的面积和房子的价格有着明显的关系。那么X=房间大小,Y=房价,那么在坐标系中可以看到这些点:
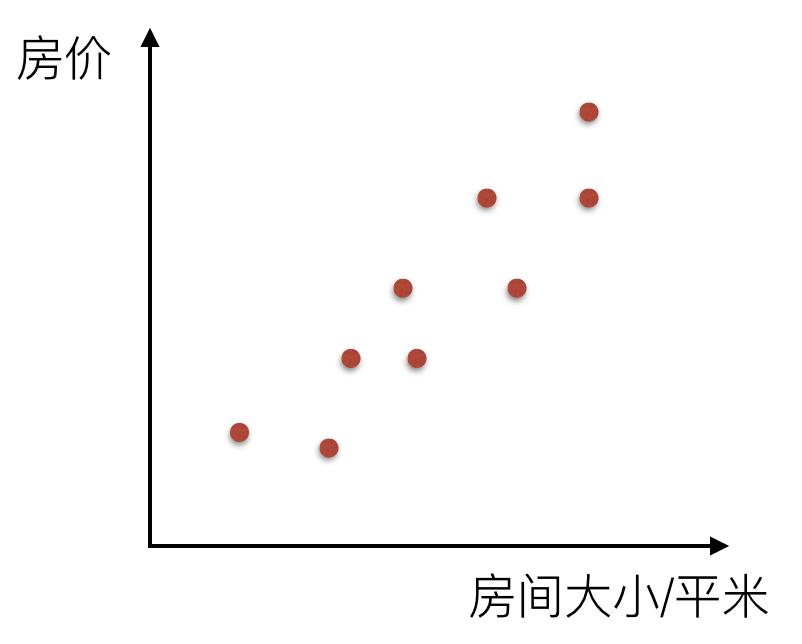
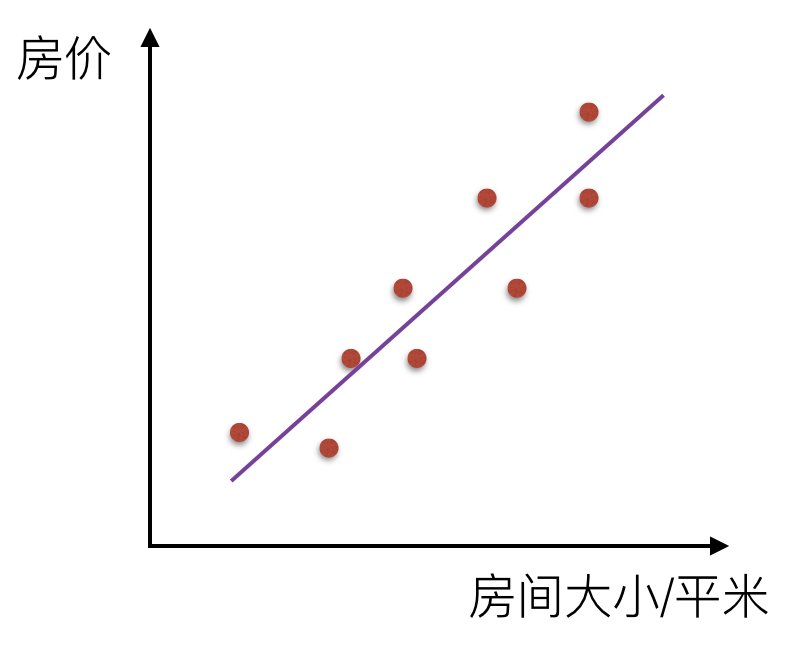
那么通过一条直线把这个关系描述出来,叫线性关系
如果是一条曲线,那么叫非线性关系
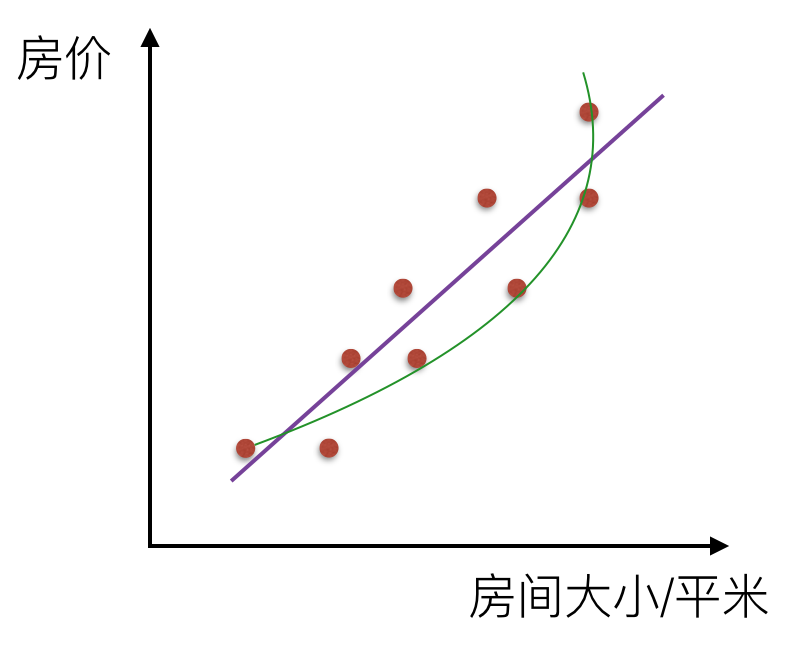
那么回归的目的就是建立一个回归方程(函数)用来预测目标值,回归的求解就是求这个回归方程的回归系数。
回归算法之线性回归
线性回归的定义是:目标值预期是输入变量的线性组合。线性模型形式简单、易于建模,但却蕴含着机器学习中一些重要的基本思想。线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
优点:结果易于理解,计算不复杂
缺点:对非线性的数据拟合不好
适用数据类型:数值型和标称型
对于单变量线性回归,例如:前面房价例子中房子的大小预测房子的价格。f(x) = w1*x+w0,这样通过主要参数w1就可以得出预测的值。
通用公式为:

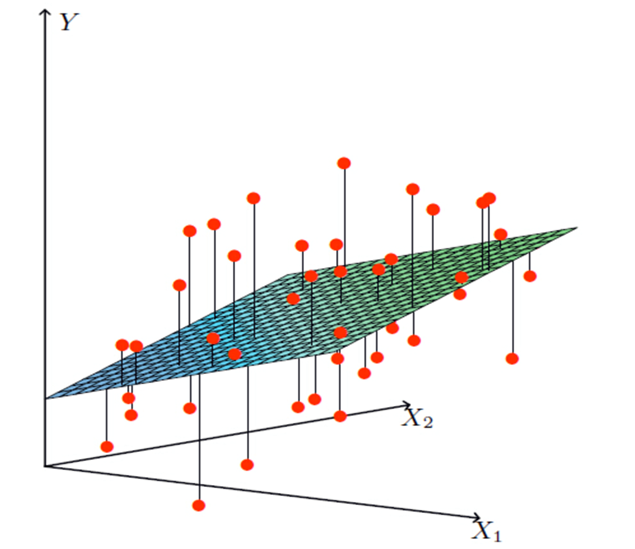
那么对于多变量回归,例如:瓜的好坏程度 f(x) = w0+0.2色泽+0.5根蒂+0.3*敲声,得出的值来判断一个瓜的好与不好的程度。
通用公式为:
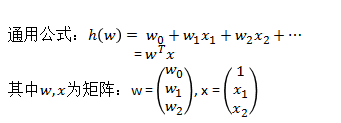
线性模型中的向量W值,客观的表达了各属性在预测中的重要性,因此线性模型有很好的解释性。对于这种“多特征预测”也就是(多元线性回归),那么线性回归就是在这个基础上得到这些W的值,然后以这些值来建立模型,预测测试数据。简单的来说就是学得一个线性模型以尽可能准确的预测实值输出标记。
预测结果与真实值是有一定的误差
单变量
多变量
损失函数
损失函数是一个贯穿整个机器学习重要的一个概念,大部分机器学习算法都会有误差,我们得通过显性的公式来描述这个误差,并且将这个误差优化到最小值。
对于线性回归模型,将模型与数据点之间的距离差之和做为衡量匹配好坏的标准,误差越小,匹配程度越大。我们要找的模型就是需要将f(x)和我们的真实值之间最相似的状态。于是我们就有了误差公式,模型与数据差的平方和最小:

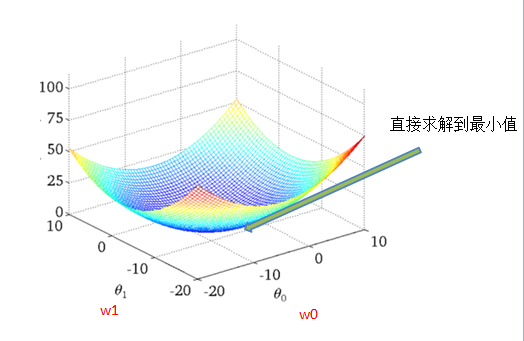
如何去求模型当中的W,使得损失最小?(目的是找到最小损失对应的W值)
最小二乘法之正规方程(不做要求)

损失函数直观图(单变量举例)
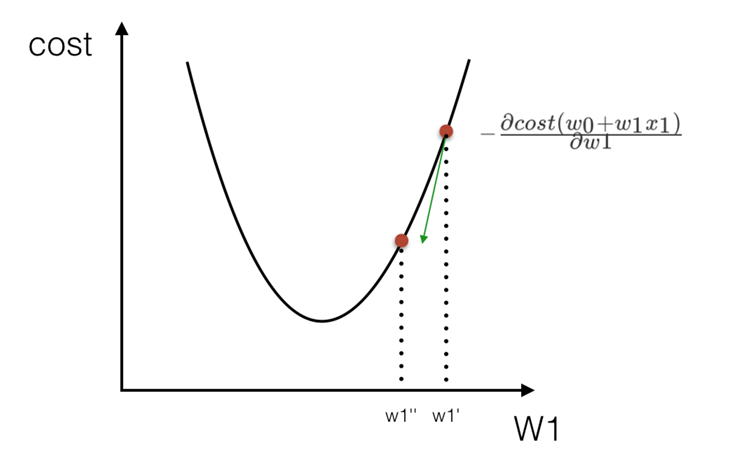
最小二乘法之梯度下降(理解过程)

sklearn线性回归正规方程、梯度下降API

sklearn.linear_model.LinearRegression()
-
普通最小二乘线性回归
-
coef_:回归系数
sklearn.linear_model.SGDRegressor( )
-
通过使用SGD最小化线性模型
-
coef_:回归系数
线性回归实例
1 sklearn线性回归正规方程、梯度下降API
2 波士顿房价数据集分析流程
-
1、波士顿地区房价数据获取
-
2、波士顿地区房价数据分割
-
3、训练与测试数据标准化处理
-
4、使用最简单的线性回归模型LinearRegression和梯度下降估计SGDRegressor对房价进行预测
正规方程
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
def example_bostan():
"""
通过线性回归对波士顿房间进行预测
:return: None
"""
bostan = datasets.load_boston()
# 切分训练集合特征集
x_train, x_test, y_train, y_test = train_test_split(bostan.data, bostan.target, test_size=0.2)
# 对于训练的特征数据 和测试的特征数据进行标准化的处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 正规方程
lr = LinearRegression()
lr.fit(x_train, y_train)
# 获取预测的结果
lr_pre = lr.predict(x_test)
print(lr_pre)
print("真实的房价: ", y_test)
# 在回归类型的问题中不适用score来进行评判
# print(lr.score(x_test, y_test))
mean_square = mean_squared_error(y_test, lr_pre)
print("均方误差值为: ", mean_square)
return None
if __name__ == '__main__':
example_bostan()
输出结果


"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day3/3-代码/pandas_test.py [30.09174283 24.35418596 24.67446322 19.55873387 23.01131261 21.47756331 24.19907309 25.98086108 19.67452987 29.24483504 25.04627751 27.31733922 19.04387629 21.51641414 8.11514313 36.59872687 26.17759575 23.04240235 8.09392354 24.51971329 37.59549967 18.21121229 15.05428311 15.38751487 24.38722455 31.09798615 20.96990916 20.52897752 24.97372945 17.55512261 23.22326956 17.02155322 36.85023369 5.74644798 28.94280776 17.14071033 27.58883172 23.13555487 13.37390985 31.37592839 22.0633944 25.08090126 28.85115528 13.60070931 40.54631735 28.69485998 13.64039918 25.16991554 26.1263271 17.05536799 2.63890269 33.01384082 25.50219644 24.32779038 20.01744199 30.71789495 29.14884115 35.34452579 24.97495788 34.82273064 14.1291942 31.95922786 29.1356177 27.969123 21.22144799 24.08897676 7.15763464 18.2075256 17.04894862 24.61901955 20.92996133 17.8565169 40.69390434 28.67817026 31.6768216 16.23681922 35.00174336 32.93623526 22.5357644 23.02601443 29.00085273 15.59812244 31.07884491 17.65556086 25.01067362 19.40377331 11.40584996 28.73171112 23.15667893 8.28219486 23.41039034 31.3136874 35.94426807 32.78434922 6.65548021 22.26243424 24.39460115 21.97185919 1.21301664 22.34757311 33.15587555 22.99689787] 真实的房价: [30.5 22.2 25. 19.4 26.4 24.5 21.9 22.2 22.2 25. 29.6 22. 17.8 21.4 11.9 50. 22. 23. 7.2 50. 44. 10.9 16.2 14.1 21.5 32.5 21. 20.1 25. 19.4 24.7 19.5 42.3 7.4 26.4 18.6 25.2 20.4 14. 31.5 23.2 50. 33.4 13.9 50. 24.4 10.9 29.8 22.8 18.1 8.1 32. 23.8 27.5 20.5 28.7 22.5 38.7 24.7 43.8 9.6 33.2 24.6 25. 20.1 23.4 7. 14.5 14.9 21.4 20.5 12.7 50. 24.3 27. 8.5 33.2 28.2 20. 20.8 22.9 13.3 28.4 19.4 24.6 16.7 16.3 22.8 21.7 5. 21. 29.9 33.3 33.1 10.4 22.4 23.1 18.7 17.9 20.2 31.7 25. ] 均方误差值为: 28.70617448321829 Process finished with exit code 0
梯度下降
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
def example_bostan():
"""
通过线性回归对波士顿房间进行预测
:return: None
"""
bostan = datasets.load_boston()
# 切分训练集合特征集
x_train, x_test, y_train, y_test = train_test_split(bostan.data, bostan.target, test_size=0.2)
# 对于训练的特征数据 和测试的特征数据进行标准化的处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 梯度下降
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
sgd_pre = sgd.predict(x_test)
print("梯度下降得到的预测值: ", sgd_pre)
sgd_mean_square = mean_squared_error(y_test, sgd_pre)
print("梯度下降得到的均方误差值: ", sgd_mean_square)
if __name__ == '__main__':
example_bostan()
输出结果
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day3/3-代码/pandas_test.py 梯度下降得到的预测值: [19.90078951 32.06665072 41.91969718 30.76125997 12.82444559 29.09289212 29.20336083 30.33737599 40.78755984 32.38108995 25.46029983 24.77011043 22.55312811 27.31701467 31.25943593 26.02442998 19.95609687 21.52823512 23.00363445 10.03526343 18.1542996 22.03235402 11.75776609 8.76020641 34.47801842 23.79184334 15.32751415 23.10443373 19.87215526 19.26769275 16.84464494 16.64616847 32.81639985 14.18982555 29.24112614 13.28105392 38.38384763 21.27303446 20.04837675 19.96523731 18.06386855 26.67229929 17.11775652 19.53008804 23.55959584 33.20789964 24.90949044 21.59381108 23.67970688 17.35427008 22.15135345 6.1131036 24.60180063 17.51544641 18.47146197 25.55238119 21.36839007 19.57216419 19.84936635 20.67412093 21.25708656 8.54390574 24.31876377 13.74215993 10.82743275 17.58853389 20.54005145 8.9505265 14.8303597 31.7631329 25.09656147 26.94459331 27.1360498 37.5078696 18.78262936 23.4112618 26.61032982 14.37402946 26.98622872 19.87719876 38.31911784 21.15562473 20.07480258 31.25412552 17.17204119 20.35023053 24.11347531 36.30931966 10.33083181 28.4680554 25.15164035 13.75511993 33.3340527 25.12244079 21.82489292 27.94589106 18.62964604 18.21707095 26.63797574 28.14217916 19.88781025 17.61316994] 梯度下降得到的均方误差值: 21.86975900476781 Process finished with exit code 0
回归性能评估

sklearn回归评估API
- sklearn.metrics.mean_squared_error
mean_squared_error(y_true, y_pred)
-
均方误差回归损失
-
y_true:真实值
-
y_pred:预测值
-
return:浮点数结果
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.metrics import mean_squared_error
def example_bostan():
"""
通过线性回归对波士顿房间进行预测
:return: None
"""
bostan = datasets.load_boston()
# 切分训练集合特征集
x_train, x_test, y_train, y_test = train_test_split(bostan.data, bostan.target, test_size=0.2)
# 对于训练的特征数据 和测试的特征数据进行标准化的处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 正规方程
lr = LinearRegression()
lr.fit(x_train, y_train)
# 获取预测的结果
lr_pre = lr.predict(x_test)
print(lr_pre)
print("真实的房价: ", y_test)
# 在回归类型的问题中不适用score来进行评判
# print(lr.score(x_test, y_test))
mean_square = mean_squared_error(y_test, lr_pre)
print("均方误差值为: ", mean_square)
# 梯度下降
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
sgd_pre = sgd.predict(x_test)
print("梯度下降得到的预测值: ", sgd_pre)
sgd_mean_square = mean_squared_error(y_test, sgd_pre)
print("梯度下降得到的均方误差值: ", sgd_mean_square)
return None
if __name__ == '__main__':
example_bostan()
输出结果
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day3/3-代码/pandas_test.py [24.23671306 8.94807269 30.04540559 24.59512272 19.74266273 22.59666355 25.29064432 25.36582658 30.45162902 17.24856809 35.55882402 13.91992992 27.72685504 42.06132521 22.98983672 22.92632429 25.13996243 20.94930659 15.89847602 39.73576725 6.41692025 18.25292043 22.81025812 27.1507218 23.8333941 23.16079861 36.3795284 22.26897084 13.33407797 35.24526355 15.55623589 17.17232741 15.8972156 26.30618 27.9865121 25.37383626 11.35899516 26.10444663 26.95644083 23.57931661 20.06126359 23.85117787 4.2045075 14.86017522 25.08431098 22.45315797 17.78633038 30.12412604 22.56476099 38.77410958 32.24025682 27.34321344 17.630634 19.7126615 20.36751331 16.67434648 22.81028469 21.31719984 34.39706519 20.27904987 21.45742485 20.27152854 21.08523585 20.85201265 25.20541179 32.70280219 32.30365647 34.2799029 19.97956851 7.99721776 29.83179856 18.18110787 19.25414888 19.13836119 28.83447614 9.63560002 20.86338889 30.95433539 28.12768829 10.33327808 16.66155398 17.64647347 36.2755654 22.9262353 29.44280152 25.04131617 32.09056971 30.22428918 22.01247905 12.90299125 18.36103148 11.80099668 38.68128159 8.30266275 21.30302783 15.94912747 28.84390267 19.7080051 26.07204693 16.64911444 37.14484164 16.96390796] 真实的房价: [24.3 7.2 30.5 29.6 17.8 26.4 30.1 24.2 37. 17.8 33.1 19.7 24.5 50. 20.3 22.6 25. 24.5 18.9 50. 10.2 16.1 20. 22.1 22.2 22.4 50. 23.2 13.9 37.3 15.2 20. 21.9 22.3 28.7 23.2 11.8 23.8 23.3 24.4 17.1 26.2 8.4 15.7 24.7 22.9 18.7 34.7 21.1 50. 30.3 23.7 19.6 19.6 23. 10.2 11.9 21.2 28.5 19.2 18.7 21.4 21.2 20.4 23.8 37.2 31.1 34.6 19.9 14.6 25. 19.8 18.4 18. 26.4 8.3 18.9 29.9 22.8 16.5 19.1 22.5 48.3 23.8 22.9 15. 31.5 23.6 22.2 12.8 20. 23.1 43.5 13.2 21.8 13.4 24.6 19.4 19.4 14.3 41.7 23.1] 均方误差值为: 19.193635265625293 梯度下降得到的预测值: [23.9790426 9.15820715 30.30922291 24.6273008 20.24615036 22.24742693 24.57761511 25.26338708 30.76260658 17.19585103 35.56872645 14.1137637 27.50707958 42.23952305 21.98963221 22.70107994 25.09237619 20.85645934 16.45720142 39.79845024 6.3758154 18.34844258 22.86977939 27.09675206 23.48760663 23.22466817 36.42014358 22.20566845 13.37920919 34.79631392 15.67147073 17.14000138 15.7734431 26.23464522 27.60126366 25.3755171 11.59869179 26.01744652 26.83449213 23.38617196 20.07520177 23.82923821 4.4331186 13.83928911 25.11192655 22.30770891 17.36423113 30.10850356 22.17828719 38.86338048 32.29759753 27.1424072 17.69987562 19.92995842 20.58446066 16.77163812 22.80936549 21.57284218 33.90362303 20.50834819 21.19429627 20.31552786 21.18145363 21.13313027 25.1988067 32.5594419 32.22008788 34.34810587 19.87896983 8.14151237 29.23432692 18.11324762 19.39811478 19.37084342 28.60781244 9.73989651 20.70992093 31.02096338 27.89500324 10.17228274 16.54782219 17.37648722 36.32269765 22.8081351 28.85532301 25.27751595 32.01464752 30.42338987 21.83993565 12.9752914 18.43828223 11.44764897 38.62739129 8.45607575 21.11498318 16.15247248 28.83357887 20.00998934 25.83015129 16.79132573 37.19899041 17.24318482] 梯度下降得到的均方误差值: 19.051538713538378 Process finished with exit code 0
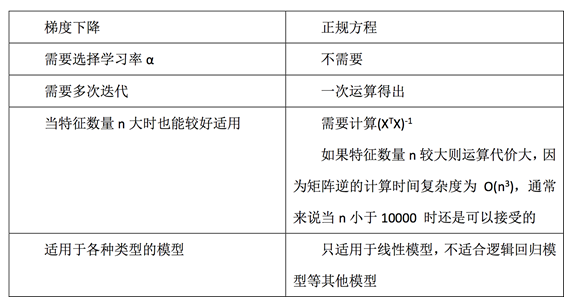
正规方程与梯度下降的对比
1、LinearRegression与SGDRegressor评估
2、特点:线性回归器是最为简单、易用的回归模型。
从某种程度上限制了使用,尽管如此,在不知道特征之
间关系的前提下,我们仍然使用线性回归器作为大多
系统的首要选择。
小规模数据:LinearRegression(不能解决拟合问题)以及其它
大规模数据:SGDRegressor
回归性能评估与欠拟合和过拟合
机器学习中的泛化,泛化即是,模型学习到的概念在它处于学习的过程中时模型没有遇见过的样本时候的表现。在机器学习领域中,当我们讨论一个机器学习模型学习和泛化的好坏时,我们通常使用术语:过拟合和欠拟合。我们知道模型训练和测试的时候有两套数据,训练集和测试集。在对训练数据进行拟合时,需要照顾到每个点,而其中有一些噪点,当某个模型过度的学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差,这样的话模型容易复杂,拟合程度较高,造成过拟合。而相反如果值描绘了一部分数据那么模型复杂度过于简单,欠拟合指的是模型在训练和预测时表现都不好的情况,称为欠拟合。
我们来看一下线性回归中拟合的几种情况图示:
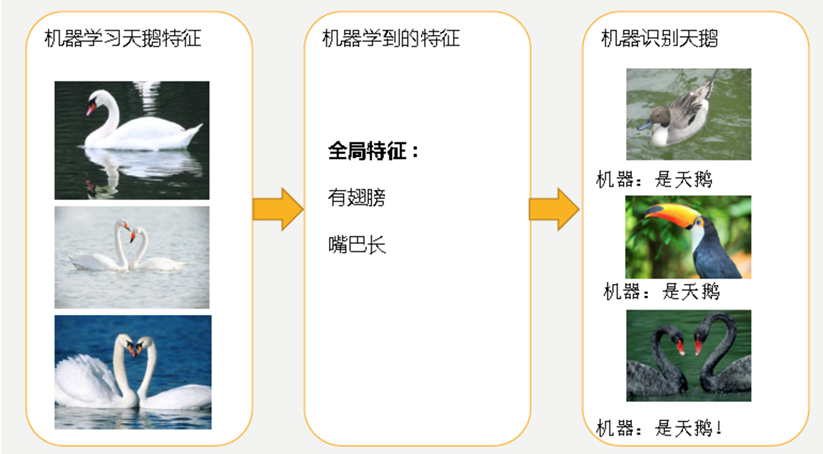
图1
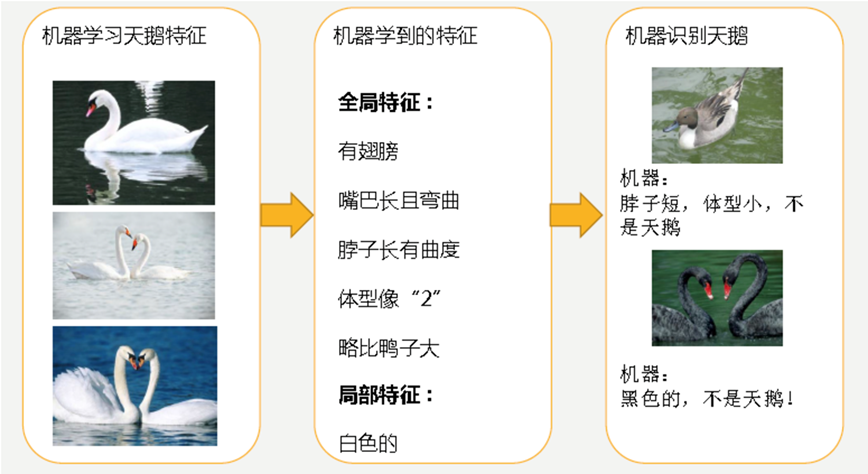
图2
分析上图 1
- 经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的。简单的认为有这些特征的都是天鹅。因为机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅。
分析上图 2
机器通过这些图片来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个"2"且略大于鸭子。这时候机器已经基本能区别天鹅和其他动物了。然后,很不巧已有的天鹅图片全是白天鹅的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅。
对线性模型进行训练学习会变成复杂模型
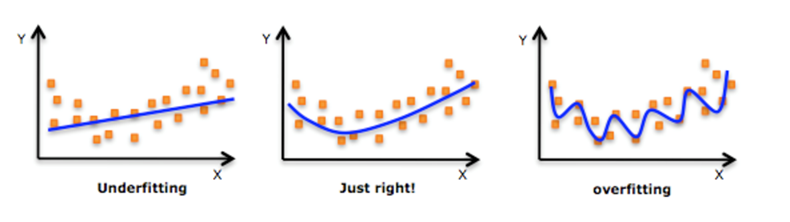
欠拟合原因以及解决办法
原因:
- 学习到数据的特征过少
解决办法:
- 增加数据的特征数量
过拟合原因以及解决办法
原因:
-
原始特征过多,存在一些嘈杂特征,
-
模型过于复杂是因为模型尝试去兼顾
-
各个测试数据点
解决办法:
-
进行特征选择,消除关联性大的特征(很难做)
-
交叉验证(让所有数据都有过训练)
-
正则化(了解)


领回归
具有L2正则化的线性最小二乘法。岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。当数据集中存在共线性的时候,岭回归就会有用。
sklearn.linear_model.Ridge
sklearn.linear_model.Ridge(alpha=1.0)
-
具有l2正则化的线性最小二乘法
-
alpha:正则化力度
-
coef_:回归系数
线性回归 LinearRegression与Ridge对比
- 岭回归:回归得到的回归系数更符合实际,更可靠。另外,能让估计参数的波动范围变小,变的更稳定。在存在病态数据偏多的研究中有较大的实用价值。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import RidgeCV
from sklearn.metrics import mean_squared_error
def example_bostan():
"""
通过线性回归对波士顿房间进行预测
:return: None
"""
bostan = datasets.load_boston()
# 切分训练集合特征集
x_train, x_test, y_train, y_test = train_test_split(bostan.data, bostan.target, test_size=0.2)
# 岭回归
ridge = RidgeCV(alphas=(1.0, 0.5, 0.01))
ridge.fit(x_train, y_train)
rid_pre = ridge.predict(x_test)
print("梯度下降得到的预测值: ", rid_pre)
rid_mean_square = mean_squared_error(y_test, rid_pre)
print("梯度下降得到的均方误差值: ", rid_mean_square)
print(ridge.alpha_)
return None
if __name__ == '__main__':
example_bostan()
输出结果
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day3/3-代码/pandas_test.py 梯度下降得到的预测值: [25.31211417 27.00825159 13.23142045 27.54341527 23.73816306 19.45241338 13.50754117 16.46618019 26.03461396 20.8752829 21.12220884 23.40705084 13.21489526 31.15043226 24.48485593 15.67838862 21.31367128 16.50153924 16.81153403 14.58888221 26.90425528 25.13722277 23.09655536 20.79419964 13.3711855 29.01509621 20.83619459 17.89736917 28.35712967 32.23711234 25.20310247 22.18723155 32.77895844 28.40905594 17.20724812 21.53322596 15.61529743 40.92564887 33.66828478 17.42386385 17.94874643 14.8595128 37.10015613 21.77955187 20.94434297 21.49899091 17.72622416 24.67896399 45.38755273 34.51996568 16.96430989 30.84548285 22.62642985 27.41570506 38.76878087 30.04766331 25.39030342 27.76665121 22.17489131 36.41096618 27.63246233 21.18841377 21.79313062 24.93231468 21.28939489 30.27390916 34.49476761 28.61177471 26.55724229 34.08177177 6.27387734 24.90620504 20.04572402 16.34749475 16.11311267 17.24951999 3.71470227 18.23004646 16.39847316 17.58552765 8.89109394 15.51311652 27.70814647 19.62020448 16.84418411 14.32722282 21.65237901 20.47660272 27.11758537 19.67501247 30.86531829 22.29150565 22.60656498 24.8625239 15.07463758 24.70799616 22.33361394 31.39931669 24.52547484 16.83607312 34.4230722 13.68137534] 梯度下降得到的均方误差值: 26.828168501012566 0.01 Process finished with exit code 0
分类算法逻辑回归
使用场景:
-
广告点击率
-
是否为垃圾邮件
-
是否患病
-
是否金融诈骗
-
是否为虚假账号
逻辑回归是解决二分类问题的利器

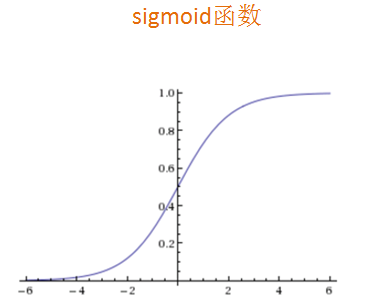


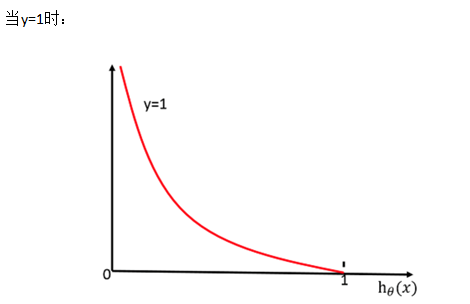
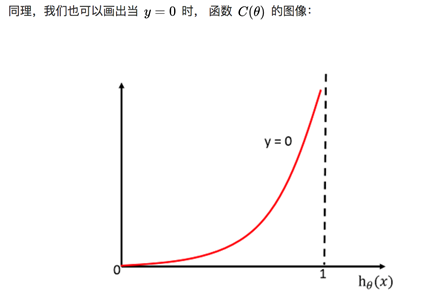
sklearn逻辑回归API
- sklearn.linear_model.LogisticRegression

LogisticRegression回归案例
- 良/恶性乳腺癌肿瘤预测
原始数据的下载地址:
- https://archive.ics.uci.edu/ml/machine-learning-databases/
数据描述
-
(1)699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤相关的医学特征,最后一列表示肿瘤类型的数值。
-
(2)包含16个缺失值,用”?”标出。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
def logistic():
"""
通过逻辑回归对肿瘤数据分析
:return: None
"""
column_names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data", names=column_names)
# 处理缺失值 ?
# 将 ? 替换为 nan
data = data.replace(to_replace='?', value=np.nan)
# 删除缺失值的数据
data = data.dropna()
# 获取特征数据 和 目标数据
x = data[column_names[1:10]]
y = data[column_names[10]]
# 切分训练集合 和 测试集合
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
log = LogisticRegression()
# fit数据
log.fit(x_train, y_train)
print("回顾的参数为: ", log.coef_)
log_pre = log.predict(x_test)
print(log_pre)
# 获取预测值
# 预测的准确率
score = log.score(x_test, y_test)
print("逻辑回归预测的准确率: ", score)
ret = classification_report(y_test, log_pre,labels=[2,4],target_names=["良性", '恶性'])
print(ret)
return None
if __name__ == '__main__':
logistic()
输出结果如下
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day3/3-代码/day3_test.py
回顾的参数为: [[ 0.7081866 -0.11357033 0.21913334 0.34883572 -0.12931481 0.52450199
0.66097954 0.4811952 0.84532057]]
[2 4 4 2 2 4 4 4 2 2 2 4 4 2 2 2 4 4 2 4 2 2 2 2 4 2 2 2 2 4 2 4 2 4 2 4 4
4 4 2 2 4 2 4 4 2 4 2 2 2 4 2 4 2 2 2 2 2 4 2 4 2 2 2 4 2 2 4 2 4 2 2 2 2
4 4 2 2 2 2 2 4 4 2 4 4 4 2 4 2 4 4 4 4 2 4 4 2 2 4 2 2 2 2 2 2 4 2 4 4 2
2 4 2 4 2 2 2 4 2 4 2 2 2 2 2 4 4 4 4 2 2 2 2 4 2 2]
逻辑回归预测的准确率: 0.9635036496350365
precision recall f1-score support
良性 0.96 0.97 0.97 80
恶性 0.96 0.95 0.96 57
accuracy 0.96 137
macro avg 0.96 0.96 0.96 137
weighted avg 0.96 0.96 0.96 137
Process finished with exit code 0
LogisticRegression总结
-
应用:广告点击率预测、电商购物搭配推荐
-
优点:适合需要得到一个分类概率的场景,简单,速度快
-
缺点:不好处理多分类问题
非监督学习
无监督学习,顾名思义,就是不受监督的学习,一种自由的学习方式。该学习方式不需要先验知识进行指导,而是不断地自我认知,自我巩固,最后进行自我归纳,在机器学习中,无监督学习可以被简单理解为不为训练集提供对应的类别标识
“物以类聚,人以群分”

非监督学习之k-means
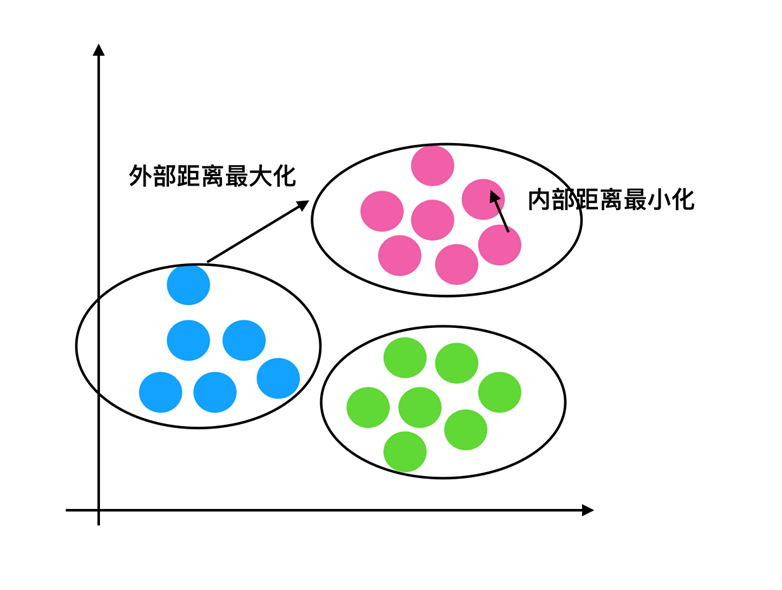
K-means通常被称为劳埃德算法,这在数据聚类中是最经典的,也是相对容易理解的模型。算法执行的过程分为4个阶段。
- 1.首先,随机设K个特征空间内的点作为初始的聚类中心。
- 2.然后,对于根据每个数据的特征向量,从K个聚类中心中寻找距离最近的一个,并且把该数据标记为这个聚类中心。
- 3.接着,在所有的数据都被标记过聚类中心之后,根据这些数据新分配的类簇,通过取分配给每个先前质心的所有样本的平均值来创建新的质心重,新对K个聚类中心做计算。
- 4.最后,计算旧和新质心之间的差异,如果所有的数据点从属的聚类中心与上一次的分配的类簇没有变化,那么迭代就可以停止,否则回到步骤2继续循环。
K均值等于具有小的全对称协方差矩阵的期望最大化算法
k-means API
sklearn.cluster.KMeans
- sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
k-means聚类
-
n_clusters:开始的聚类中心数量
-
init:初始化方法,默认为'k-means ++’
-
labels_:默认标记的类型,可以和真实值比较(不是值比较)


k-means API
- sklearn.cluster.KMeans

Kmeans性能评估指标API
- sklearn.metrics.silhouette_score

k-means案例分析
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from matplotlib import pyplot as plt
from sklearn.metrics import silhouette_score
orders = pd.read_csv("./data/instacart/orders.csv")
aisles = pd.read_csv("./data/instacart/aisles.csv")
order_products_prior = pd.read_csv("./data/instacart/order_products_prior.csv")
products = pd.read_csv("./data/instacart/products.csv")
me = pd.merge(orders, order_products_prior, on=['order_id','order_id'])
me = pd.merge(me, products, on=['product_id', 'product_id'])
me = pd.merge(me, aisles, on=['aisle_id','aisle_id'])
# 用户和商品类别的关系
me = pd.crosstab(me['user_id'],me['aisle'])
#创建pca降维对象
pca = PCA(n_components=100)
# fit_transform
me = pca.fit_transform(me)
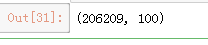
me.shape
x_train = me[:1000] x_test = me[1000:1300] x_train = me[:1000] x_test = me[1000:1300] km = KMeans(n_clusters=4) # 只需要添加特征数据 km.fit(x_train)
example = km.predict(x_test) example

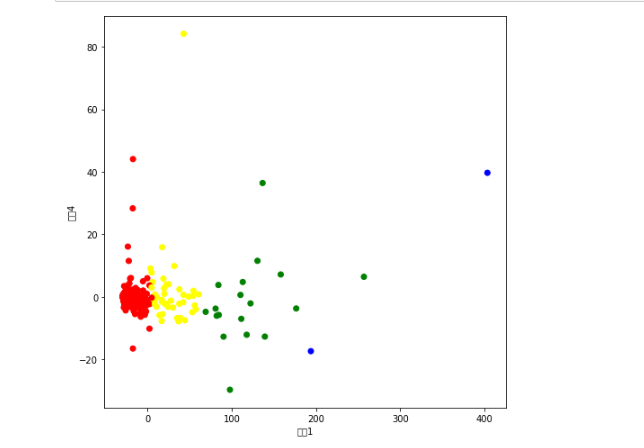
plt.figure(figsize=(8,8))
colors = ["red","yellow","green","blue"]
colored = [colors[i] for i in example]
plt.scatter(x_test[:, 0],x_test[:, 4], color=colored)
plt.xlabel("特征1")
plt.ylabel("特征4")
plt.show()
silhouette_score(x_test, example)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号