机器学习sklearn分类器算法
需明确几点问题:
(1)算法是核心,数据和计算是基础
(2)找准定位
- 大部分复杂模型的算法设计都是算法工程师在做,而我们分析很多的数据分析具体的业务应用常见的算法特征工程、调参数、优化
我们应该怎么做
-
学会分析问题,使用机器学习算法的目的,想要算法完成何种任务
-
掌握算法基本思想,学会对问题用相应的算法解决
-
学会利用库或者框架解决问题
机器学习开发流程
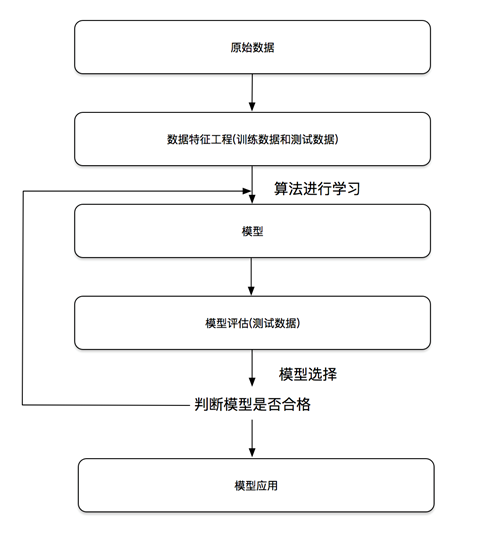
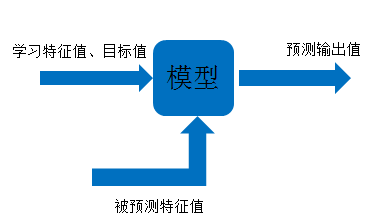
机器学习模型是什么
定义:通过一种映射关系将输入值到输出值
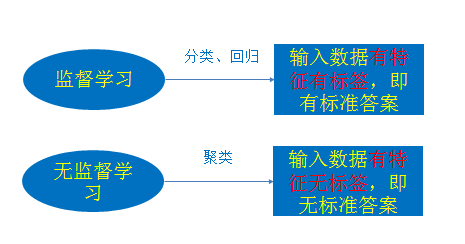
机器学习算法分类
监督学习(既有特征值也有目标值)
- 分类 k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
-
回归 线性回归、岭回归
-
标注 隐马尔可夫模型 (不做要求)
无监督学习 (只有特征值没有目标值)
- 聚类 k-means
监督学习
监督学习(英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),
或是输出是有限个离散值(称作分类)。
无监督学习
无监督学习(英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。
输入数据是由输入特征值所组成。
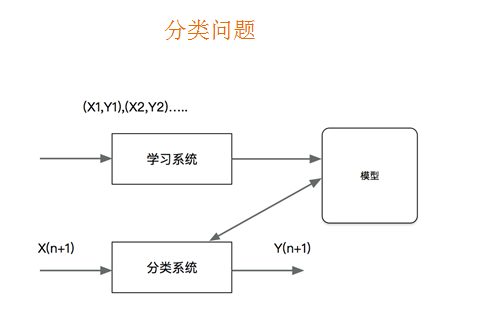
概念:
- 分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果;
分类问题的应用
-
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用
-
在银行业务中,构建一个客户分类模型,按客户按照贷款风险的大小进行分类
-
图像处理中,分类可以用来检测图像中是否有人脸出现,动物类别等
-
手写识别中,分类可以用于识别手写的数字
-
文本分类,这里的文本可以是新闻报道、网页、电子邮件、学术论文
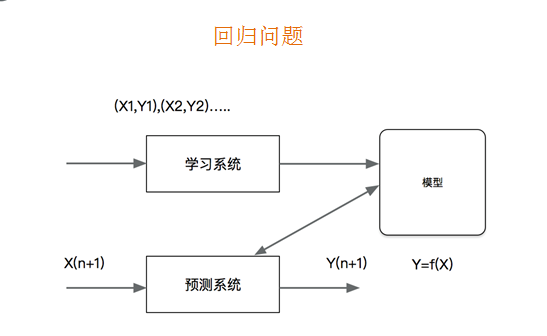
概念:
- 回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,输出是连续型的值。
回归问题的应用
-
回归在多领域也有广泛的应用
-
房价预测,根据某地历史房价数据,进行一个预测
-
金融信息,每日股票走向
sklearn数据集
数据集划分
机器学习一般的数据集会划分为两个部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
sklearn数据集划分API
- sklearn.model_selection.train_test_split
问题:
- 自己准备数据集,耗时耗力,不一定真实
scikit-learn数据集API介绍
sklearn.datasets
- 加载获取流行数据集
datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
获取数据集返回的类型
-
load*和fetch*返回的数据类型datasets.base.Bunch(字典格式)
-
data:特征数据数组,是 [n_samples * n_features] 的二维numpy.ndarray 数组
-
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
-
DESCR:数据描述
-
feature_names:特征名,新闻数据,手写数字、回归数据集没有
-
target_names:标签名
sklearn分类数据集

鸢尾花数据集合
from sklearn import datasets
def load_datasets_iris():
"""
获取sklearn提供的小量和大量的数据集
:return:
"""
# 创建鸢尾花的数据集对象
ir = datasets.load_iris()
# 特征名 feature_names
print('打印特征名')
print(ir.feature_names)
# 特征数据属组 ir.data
print("数据位: ", ir.data)
# 标签名target_names
print('打印标签名')
print(ir.target_names)
# 标签属组target
print('打印标签数组')
print(ir.target)
return None
if __name__ == '__main__':
load_datasets_iris()


用于分类的大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
-
subset: 'train'或者'test','all',可选,选择要加载的数据集.
-
训练集的“训练”,测试集的“测试”,两者的“全部”
datasets.clear_data_home(data_home=None)
- 清除目录下的数据
新闻数据集
from sklearn import datasets
def load_datasets_newsgroup():
# 调用方法
news = datasets.fetch_20newsgroups(subset='all')
# 文档数据就没有特征名称
# print(news.feature_names)
print(news.data)
# print(news.target_names)
print(news.target)
return None
if __name__ == '__main__':
load_datasets_newsgroup()

数据集进行分割
把一个完整的数据集切分成训练集和测试集
sklearn.model_selection.train_test_split(*arrays, **options)
-
x 数据集的特征值
-
y 数据集的标签值
-
test_size 测试集的大小,一般为float
-
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
-
return 训练集特征值,测试集特征值,训练标签,测试标签(默认随机取)
from sklearn import datasets
from sklearn.model_selection import train_test_split
def splitdatasets():
"""
切分鸢尾花的数据集
:return:
"""
ir = datasets.load_iris()
# data 是特征数据, target 是目标数据
# x_train: 训练特征集, x_test: 测试特征集 y_train: 训练目标集 y_test测试的目标集
x_train, x_test, y_train, y_test = train_test_split(ir.data, ir.target, test_size=0.2, random_state=11)
print(x_train)
print(x_test)
print(y_train)
print(y_test)
if __name__ == '__main__':
splitdatasets()


"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day2/3-代码/day2_test.py [[5.1 3.5 1.4 0.2] [6.9 3.2 5.7 2.3] [7.7 2.8 6.7 2. ] [5. 3.3 1.4 0.2] [4.7 3.2 1.6 0.2] [7.7 2.6 6.9 2.3] [7.6 3. 6.6 2.1] [6.7 3. 5. 1.7] [5.5 3.5 1.3 0.2] [6. 2.7 5.1 1.6] [5. 2. 3.5 1. ] [7.9 3.8 6.4 2. ] [4.6 3.4 1.4 0.3] [6.9 3.1 4.9 1.5] [6.5 3. 5.8 2.2] [5.1 2.5 3. 1.1] [6.6 2.9 4.6 1.3] [5. 3.2 1.2 0.2] [7.4 2.8 6.1 1.9] [5.1 3.8 1.6 0.2] [6.8 3.2 5.9 2.3] [6.9 3.1 5.1 2.3] [5.9 3. 4.2 1.5] [4.9 2.5 4.5 1.7] [6.7 3.1 4.7 1.5] [4.4 3.2 1.3 0.2] [5.4 3.4 1.7 0.2] [6.5 2.8 4.6 1.5] [5.1 3.7 1.5 0.4] [5. 3.4 1.6 0.4] [6.1 2.6 5.6 1.4] [6.5 3. 5.5 1.8] [6.3 2.5 5. 1.9] [5.2 3.4 1.4 0.2] [5. 3.6 1.4 0.2] [5.4 3.4 1.5 0.4] [6.1 2.8 4.7 1.2] [5.1 3.4 1.5 0.2] [5.6 3. 4.1 1.3] [6.3 2.7 4.9 1.8] [7.1 3. 5.9 2.1] [5.5 2.6 4.4 1.2] [5. 2.3 3.3 1. ] [6.3 3.4 5.6 2.4] [5.8 2.7 5.1 1.9] [5.5 4.2 1.4 0.2] [5.6 2.7 4.2 1.3] [6.2 2.9 4.3 1.3] [6.7 2.5 5.8 1.8] [6.1 3. 4.9 1.8] [6.7 3.1 5.6 2.4] [4.6 3.2 1.4 0.2] [7.7 3.8 6.7 2.2] [5.3 3.7 1.5 0.2] [5.7 3.8 1.7 0.3] [5. 3.5 1.6 0.6] [5.1 3.5 1.4 0.3] [6.3 3.3 6. 2.5] [4.4 3. 1.3 0.2] [5. 3. 1.6 0.2] [5.1 3.8 1.5 0.3] [6. 2.9 4.5 1.5] [5.2 4.1 1.5 0.1] [6.3 2.5 4.9 1.5] [6.2 2.2 4.5 1.5] [6.4 3.1 5.5 1.8] [6.3 2.3 4.4 1.3] [4.4 2.9 1.4 0.2] [4.6 3.1 1.5 0.2] [4.9 3. 1.4 0.2] [5.2 2.7 3.9 1.4] [5.7 2.8 4.1 1.3] [7. 3.2 4.7 1.4] [6.7 3.3 5.7 2.5] [5.5 2.3 4. 1.3] [5.4 3.9 1.7 0.4] [5.7 3. 4.2 1.2] [6.4 3.2 5.3 2.3] [5. 3.5 1.3 0.3] [6.2 2.8 4.8 1.8] [6.7 3.3 5.7 2.1] [5.7 2.8 4.5 1.3] [5. 3.4 1.5 0.2] [5.8 4. 1.2 0.2] [5.1 3.8 1.9 0.4] [5.6 2.8 4.9 2. ] [4.9 2.4 3.3 1. ] [5.4 3.7 1.5 0.2] [7.3 2.9 6.3 1.8] [5.5 2.5 4. 1.3] [7.7 3. 6.1 2.3] [5.2 3.5 1.5 0.2] [5.1 3.3 1.7 0.5] [5.7 2.9 4.2 1.3] [5.7 2.6 3.5 1. ] [6. 3. 4.8 1.8] [5.6 2.9 3.6 1.3] [6.4 2.8 5.6 2.1] [5.8 2.8 5.1 2.4] [5.9 3.2 4.8 1.8] [5.8 2.7 4.1 1. ] [6.2 3.4 5.4 2.3] [6.5 3. 5.2 2. ] [4.9 3.6 1.4 0.1] [6.4 2.9 4.3 1.3] [7.2 3. 5.8 1.6] [4.9 3.1 1.5 0.2] [6.4 2.8 5.6 2.2] [7.2 3.2 6. 1.8] [4.8 3. 1.4 0.3] [5.8 2.6 4. 1.2] [7.2 3.6 6.1 2.5] [4.8 3.4 1.9 0.2] [5.8 2.7 3.9 1.2] [6.1 2.8 4. 1.3] [6.8 2.8 4.8 1.4] [4.3 3. 1.1 0.1] [5.5 2.4 3.7 1. ] [6.1 3. 4.6 1.4] [5.5 2.4 3.8 1.1]] [[6.8 3. 5.5 2.1] [6.7 3. 5.2 2.3] [6.3 2.8 5.1 1.5] [6.3 3.3 4.7 1.6] [6.4 2.7 5.3 1.9] [4.9 3.1 1.5 0.1] [6.7 3.1 4.4 1.4] [5.7 4.4 1.5 0.4] [4.8 3.1 1.6 0.2] [6.1 2.9 4.7 1.4] [6. 2.2 5. 1.5] [6. 2.2 4. 1. ] [5.4 3. 4.5 1.5] [5.7 2.5 5. 2. ] [6.9 3.1 5.4 2.1] [4.5 2.3 1.3 0.3] [6.3 2.9 5.6 1.8] [5.6 3. 4.5 1.5] [6.5 3.2 5.1 2. ] [5.8 2.7 5.1 1.9] [5.6 2.5 3.9 1.1] [4.7 3.2 1.3 0.2] [4.6 3.6 1. 0.2] [6.4 3.2 4.5 1.5] [4.8 3. 1.4 0.1] [4.8 3.4 1.6 0.2] [5.9 3. 5.1 1.8] [6.6 3. 4.4 1.4] [5.4 3.9 1.3 0.4] [6. 3.4 4.5 1.6]] [0 2 2 0 0 2 2 1 0 1 1 2 0 1 2 1 1 0 2 0 2 2 1 2 1 0 0 1 0 0 2 2 2 0 0 0 1 0 1 2 2 1 1 2 2 0 1 1 2 2 2 0 2 0 0 0 0 2 0 0 0 1 0 1 1 2 1 0 0 0 1 1 1 2 1 0 1 2 0 2 2 1 0 0 0 2 1 0 2 1 2 0 0 1 1 2 1 2 2 1 1 2 2 0 1 2 0 2 2 0 1 2 0 1 1 1 0 1 1 1] [2 2 2 1 2 0 1 0 0 1 2 1 1 2 2 0 2 1 2 2 1 0 0 1 0 0 2 1 0 1] Process finished with exit code 0
转换器与预估器
想一下之前做的特征工程的步骤?
-
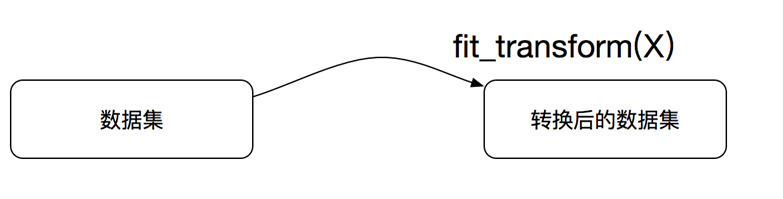
1、实例化 (实例化的是一个转换器类(Transformer))
-
2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
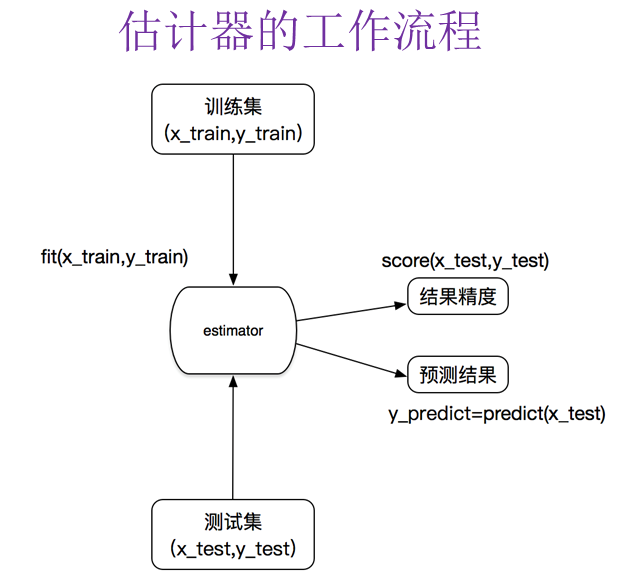
sklearn机器学习算法的实现-估计器
在 sklearn 中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
1、用于分类的估计器:
-
sklearn.neighbors k-近邻算法
-
sklearn.naive_bayes 贝叶斯
-
sklearn.linear_model.LogisticRegression 逻辑回归
-
sklearn.tree 决策树与随机森林
2、用于回归的估计器:
-
sklearn.linear_model.LinearRegression 线性回归
-
sklearn.linear_model.Ridge 岭回归
k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型
一个例子弄懂k-近邻
电影可以按照题材分类,每个题材又是如何定义的呢?那么假如两种类型的电影,动作片和爱情片。动作片有哪些公共的特征?那么爱情片又存在哪些明显的差别呢?我们发现动作片中打斗镜头的次数较多,而爱情片中接吻镜头相对更多。当然动作片中也有一些接吻镜头,爱情片中也会有一些打斗镜头。所以不能单纯通过是否存在打斗镜头或者接吻镜头来判断影片的类别。那么现在我们有6部影片已经明确了类别,也有打斗镜头和接吻镜头的次数,还有一部电影类型未知。
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| California Man | 3 | 104 | 爱情片 |
| He's not Really into dues | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped II | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
那么我们使用K-近邻算法来分类爱情片和动作片:存在一个样本数据集合,也叫训练样本集,样本个数M个,知道每一个数据特征与类别对应关系,然后存在未知类型数据集合1个,那么我们要选择一个测试样本数据中与训练样本中M个的距离,排序过后选出最近的K个,这个取值一般不大于20个。选择K个最相近数据中次数最多的分类。那么我们根据这个原则去判断未知电影的分类
| 电影名称 | 与未知电影的距离 |
|---|---|
| California Man | 20.5 |
| He's not Really into dues | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped II | 118.9 |
我们假设K为3,那么排名前三个电影的类型都是爱情片,所以我们判定这个未知电影也是一个爱情片。那么计算距离是怎样计算的呢?
欧氏距离 那么对于两个向量点$$a{1}$$和$$a{2}$$之间的距离,可以通过该公式表示:

sklearn k-近邻算法API
-
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
k近邻算法实例-预测入住位置


数据的处理
1、缩小数据集范围
- DataFrame.query()
2、处理日期数据
-
pd.to_datetime
-
pd.DatetimeIndex
3、增加分割的日期数据
4、删除没用的日期数据
-
DataFrame.drop
5、将签到位置少于n个用户的删除
-
place_count =data.groupby('place_id').count() tf = place_count[place_count.row_id > 3].reset_index()
-
data = data[data['place_id'].isin(tf.place_id)]
实例流程
-
1、数据集的处理
-
2、分割数据集
-
3、对数据集进行标准化
-
4、estimator流程进行分类预测
k-近邻算法优缺点
优点:
- 简单,易于理解,易于实现,无需估计参数,无需训练
缺点:
-
懒惰算法,对测试样本分类时的计算量大,内存开销大
-
必须指定K值,K值选择不当则分类精度不能保证
-
使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
案例代码
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
import pandas as pd
def knncls():
"""
K-近邻算法实现入住
:return: None
"""
# 1. 读取数据
data = pd.read_csv('./FBlocation/train.csv')
# 2. 筛选数据 距离x: 1~1.25, y:2.5 ~ 2.75
data = data.query("x < 1.0 & y < 1.0")
# 3. 增加时间特征 weekday, day, hour
time_value = data['time']
time_value = pd.to_datetime(time_value, unit='s')
time_value = pd.DatetimeIndex(time_value)
data['weekday'] = time_value.weekday
data['day'] = time_value.day
data = data.drop(['time'], axis=1)
# 4.1 删除入住点较少的数据
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 400].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
print('增加特征后的数据')
print(data)
# 5. 开始获取特征数据 和 目标数据
y = data['place_id']
x = data.drop(["place_id"], axis=1)
# 6. 切分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 6.1 创建标准化对象
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 7. 选择k-近邻模型开始输入训练的特征数据和目标数据来训练得到数据
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train, y_train)
# 8. 通过添加测试的训练数据 和 测试的目标数据 得到预测的准确率
ret = knn.score(x_test, y_test)
y_prdict = knn.predict(x_test)
print('预测范围')
print(ret)
return None
if __name__ == '__main__':
knncls()
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day2/3-代码/day2_test.py D:/数据分析/机器学习/day2/3-代码/day2_test.py:20: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy data['weekday'] = time_value.weekday D:/数据分析/机器学习/day2/3-代码/day2_test.py:21: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy data['day'] = time_value.day 增加特征后的数据 row_id x y accuracy place_id weekday day 149 149 0.0179 0.2321 67 8050782732 2 7 171 171 0.1489 0.2586 59 5938943847 4 2 334 334 0.9536 0.3766 95 7578348615 3 8 386 386 0.6733 0.8339 82 1273954023 3 8 402 402 0.8700 0.0681 65 7131826933 2 7 503 503 0.3432 0.3193 107 7104264675 0 5 890 890 0.1653 0.6973 103 7171064607 3 8 1049 1049 0.0226 0.9379 23 5545962225 2 7 1183 1183 0.7895 0.3364 35 4669981452 4 9 1275 1275 0.8595 0.4226 72 7269384886 4 2 1487 1487 0.5794 0.6299 60 5861856288 4 9 1567 1567 0.4756 0.0133 33 8813608705 0 5 1650 1650 0.2130 0.9755 62 6654730785 3 1 1915 1915 0.1280 0.2438 76 5938943847 4 9 2086 2086 0.3251 0.3853 144 7936666343 0 5 2183 2183 0.5892 0.8956 57 7858268564 5 3 2249 2249 0.2987 0.8530 179 2808244871 3 8 2641 2641 0.8250 0.1441 58 7121847139 3 8 2719 2719 0.4405 0.3184 158 3421175639 3 8 2934 2934 0.1639 0.2205 19 5765520742 3 8 3000 3000 0.0708 0.7346 68 7317620755 4 9 3001 3001 0.6817 0.5464 129 8507124067 3 8 3052 3052 0.0386 0.9768 14 3030461919 0 5 3090 3090 0.7620 0.4287 606 1467576612 5 3 3162 3162 0.0901 0.3543 6 8805929689 0 5 3184 3184 0.4258 0.3345 102 3421175639 1 6 3347 3347 0.2956 0.2503 122 3363064200 5 3 3505 3505 0.2293 0.9829 72 6654730785 6 4 3511 3511 0.1361 0.1308 66 3804306710 3 1 3548 3548 0.3143 0.3958 131 7936666343 4 2 ... ... ... ... ... ... ... ... 29109459 29109459 0.2285 0.6921 65 3662802511 3 8 29109463 29109463 0.4114 0.1187 70 1520475542 1 6 29110172 29110172 0.2775 0.3763 76 5715755404 5 3 29111516 29111516 0.1792 0.1973 100 5765520742 1 6 29111656 29111656 0.2092 0.7078 70 2114921534 2 7 29111784 29111784 0.1043 0.3469 7 8805929689 4 2 29112952 29112952 0.5688 0.6881 44 7010468547 4 2 29112980 29112980 0.3623 0.6896 70 7767783897 4 2 29113372 29113372 0.2591 0.0969 64 3642864292 1 6 29113647 29113647 0.7080 0.4315 69 7269384886 5 3 29113842 29113842 0.1855 0.6452 25 9138883259 5 3 29113913 29113913 0.2098 0.6954 167 3662802511 4 2 29114024 29114024 0.6804 0.2409 9 2207140084 4 2 29114069 29114069 0.6974 0.5338 8 8507124067 5 3 29114168 29114168 0.4785 0.3400 7 3421175639 0 5 29115095 29115095 0.0492 0.1035 45 5445221293 4 9 29115173 29115173 0.6066 0.3712 22 7578348615 2 7 29115534 29115534 0.8656 0.7234 10 3915691710 0 5 29115869 29115869 0.9512 0.2796 32 3536143786 0 5 29115894 29115894 0.0966 0.6492 123 9138883259 1 6 29116264 29116264 0.2490 0.3987 12 1511873045 1 6 29116576 29116576 0.2198 0.3098 656 9851590985 3 8 29116686 29116686 0.5054 0.0429 58 7858695423 5 10 29116786 29116786 0.7434 0.8181 270 2411005523 1 6 29116898 29116898 0.2153 0.0891 72 2148728558 1 6 29116914 29116914 0.7349 0.4406 73 1467576612 6 4 29116971 29116971 0.2034 0.6960 75 9958620956 3 8 29117135 29117135 0.5478 0.4678 54 7809444487 6 4 29117323 29117323 0.2266 0.9573 165 3030461919 5 3 29117441 29117441 0.8478 0.4264 2 7269384886 5 3 [123903 rows x 7 columns] 预测范围 0.5425167871900827 Process finished with exit code 0
分类算法-朴素贝叶斯算法
概率论基础
概率定义为一件事情发生的可能性。事情发生的概率可以通过观测数据中的事件发生次数来计算,事件发生的概率等于改事件发生次数除以所有事件发生的总次数。举一些例子:
- 扔出一个硬币,结果头像朝上
- 某天是晴天
- 某个单词在未知文档中出现

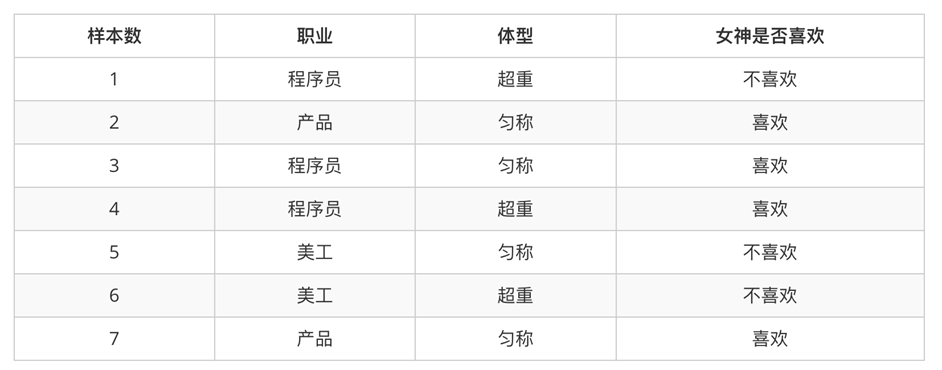
问题
1、女神喜欢的概率? 4/7
2、职业是程序员并且体型匀称的概率? 3/7 * 4/7
3、在女神喜欢的条件下,职业是程序员的概率?p(1/2)
4、在女神喜欢的条件下,职业是产品,体重是超重的概率?1/2 1/4
朴素贝叶斯-贝叶斯公式


训练集统计结果(指定统计词频):
|
特征\统计 |
科技(30篇) |
娱乐(60篇) |
汇总(90篇) |
|
“商场” |
9 |
51 |
60 |
|
“影院” |
8 |
56 |
64 |
|
“支付宝” |
20 |
15 |
35 |
|
“云计算” |
63 |
0 |
63 |
|
汇总(求和) |
100 |
121 |
221 |
现有一篇被预测文档:出现了影院,支付宝,云计算,计算属于科技、娱乐的类别概率?

思考:属于某个类别为0,合适吗?
拉普拉斯平滑

sklearn朴素贝叶斯实现API
-
sklearn.naive_bayes.MultinomialNB
-
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
朴素贝叶斯算法案例
sklearn20类新闻分类
20个新闻组数据集包含20个主题的18000个新闻组帖子
朴素贝叶斯案例流程
-
1、加载20类新闻数据,并进行分割
-
2、生成文章特征词
-
3、朴素贝叶斯estimator流程进行预估
朴素贝叶斯分类优缺点
优点:
-
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
-
对缺失数据不太敏感,算法也比较简单,常用于文本分类
-
分类准确度高,速度快
缺点:
- 由于使用了样本属性独立性的假设,所以如果样本属性有关联时其效果不好
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
def byas():
"""
通过朴素贝叶斯算法对新闻类型进行预测
:return: None
"""
news = datasets.fetch_20newsgroups(subset='all')
# 将数据分成训练集合测试集
# x_test 测试的特征数据
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.2)
print(y_test)
# 对数据进行tfidf的处理操作
tf = TfidfVectorizer()
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test)
# 创建朴素贝叶斯的模型 来训练数据
nav = MultinomialNB()
nav.fit(x_train, y_train)
# 通过测试的特征数据获取模型预测的数据
y_predict = nav.predict(x_test)
print("预测的结果为: ", y_predict)
ret = nav.score(x_test, y_test)
print("准确率为: ", ret)
return None
if __name__ == '__main__':
byas()

分类模型的评估
在许多实际问题中,衡量分类器任务的成功程度是通过固定的性能指标来获取。一般最常见使用的是准确率,即预测结果正确的百分比。然而有时候,我们关注的是负样本是否被正确诊断出来。例如,关于肿瘤的的判定,需要更加关心多少恶性肿瘤被正确的诊断出来。也就是说,在二类分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵。
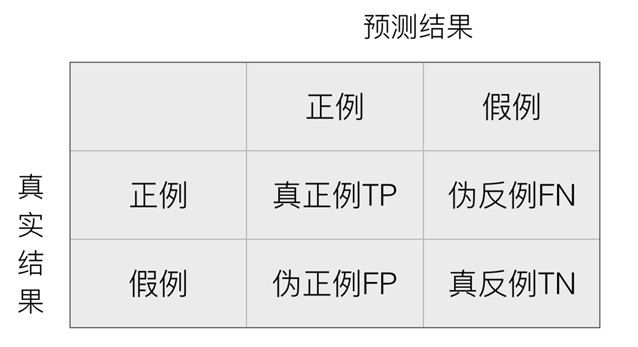
精确率(Precision)与召回率(Recall)
精确率:预测结果为正例样本中真实为正例的比例(查得准)

召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)

分类模型评估API
- sklearn.metrics.classification_report
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
-
y_true:真实目标值
-
y_pred:估计器预测目标值
-
target_names:目标类别名称
-
return:每个类别精确率与召回率
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
import pandas as pd
def knncls():
"""
K-近邻算法实现入住
:return: None
"""
# 1. 读取数据
data = pd.read_csv('./FBlocation/train.csv')
# 2. 筛选数据 距离x: 1~1.25, y:2.5 ~ 2.75
data = data.query("x < 1.0 & y < 1.0")
# 3. 增加时间特征 weekday, day, hour
time_value = data['time']
time_value = pd.to_datetime(time_value, unit='s')
time_value = pd.DatetimeIndex(time_value)
data['weekday'] = time_value.weekday
data['day'] = time_value.day
data = data.drop(['time'], axis=1)
# 4.1 删除入住点较少的数据
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 400].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 5. 开始获取特征数据 和 目标数据
y = data['place_id']
x = data.drop(["place_id"], axis=1)
# 6. 切分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 6.1 创建标准化对象
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 7. 选择k-近邻模型开始输入训练的特征数据和目标数据来训练得到数据
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train, y_train)
# 8. 通过添加测试的训练数据 和 测试的目标数据 得到预测的准确率
ret = knn.score(x_test, y_test)
y_prdict = knn.predict(x_test)
print(ret)
cls = classification_report(y_test,y_prdict)
print(cls)
if __name__ == '__main__':
knncls()
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day2/3-代码/day2_test.py D:/数据分析/机器学习/day2/3-代码/day2_test.py:21: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy data['weekday'] = time_value.weekday D:/数据分析/机器学习/day2/3-代码/day2_test.py:22: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy data['day'] = time_value.day 0.5450994318181818 precision recall f1-score support 1006316884 0.58 0.74 0.65 188 1040385378 0.79 0.87 0.83 143 1080544242 0.52 0.76 0.62 207 1134034750 0.34 0.58 0.43 212 1164138621 0.71 0.94 0.81 116 1218151301 0.49 0.62 0.55 107 1254758593 0.47 0.75 0.58 353 1267886014 0.72 0.69 0.70 131 1273954023 0.61 0.80 0.69 293 1292505932 0.36 0.55 0.43 166 1342336464 0.55 0.73 0.63 224 1467576612 0.42 0.64 0.51 250 1511873045 0.46 0.70 0.56 368 1520475542 0.30 0.38 0.33 107 1551629822 0.39 0.50 0.44 108 1576193977 0.64 0.69 0.67 154 1657332889 0.66 0.83 0.74 247 1696809785 0.41 0.34 0.37 118 1736666630 0.41 0.39 0.40 128 1761037932 0.12 0.13 0.13 137 1839447108 0.68 0.72 0.70 131 1890025047 0.55 0.70 0.61 276 1960971062 0.38 0.57 0.45 91 1983039994 0.40 0.60 0.48 237 2008663555 0.20 0.26 0.23 114 2114921534 0.25 0.36 0.30 143 2148728558 0.48 0.76 0.59 237 2168937138 0.35 0.59 0.44 165 2198209291 0.37 0.38 0.38 234 2207140084 0.24 0.29 0.26 226 2224730807 0.25 0.31 0.28 147 2411005523 0.64 0.75 0.69 287 2668032691 0.46 0.54 0.50 153 2741351737 0.30 0.34 0.32 198 2743965716 0.34 0.56 0.42 189 2784881316 0.53 0.50 0.51 256 2808244871 0.58 0.56 0.57 232 2845871326 0.24 0.22 0.23 134 2938610161 0.60 0.51 0.55 99 2965211586 0.72 0.71 0.72 241 3027578816 0.25 0.23 0.24 192 3030461919 0.29 0.20 0.24 105 3052798933 0.53 0.59 0.56 219 3131575096 0.67 0.77 0.72 336 3138618272 0.30 0.24 0.27 135 3181810487 0.43 0.41 0.42 111 3363064200 0.40 0.43 0.42 138 3421175639 0.55 0.55 0.55 336 3536143786 0.80 0.82 0.81 194 3602140667 0.24 0.30 0.27 176 3642864292 0.29 0.20 0.24 109 3662802511 0.61 0.85 0.71 291 3804306710 0.45 0.35 0.39 197 3853789552 0.12 0.10 0.11 110 3915691710 0.61 0.79 0.69 184 3918442764 0.33 0.50 0.40 197 4207727523 0.40 0.56 0.47 126 4388715331 0.60 0.67 0.63 150 4492862780 0.42 0.41 0.41 152 4562877996 0.77 0.74 0.75 149 4669981452 0.64 0.68 0.66 138 4682130071 0.50 0.53 0.52 304 4691592935 0.18 0.19 0.19 164 4756338983 0.44 0.49 0.46 180 4838446899 0.85 0.68 0.75 121 4872304139 0.38 0.25 0.30 108 4912058389 0.58 0.62 0.60 136 4914943817 0.71 0.74 0.72 225 4967325204 0.62 0.64 0.63 244 4982492326 0.80 0.58 0.67 142 5082530812 0.42 0.45 0.44 97 5108647025 0.64 0.70 0.67 317 5168726215 0.46 0.34 0.39 151 5215991518 0.40 0.55 0.46 105 5423060397 0.48 0.52 0.50 114 5435138423 0.42 0.37 0.39 197 5445221293 0.76 0.76 0.76 200 5473477945 0.60 0.74 0.66 292 5530597808 0.68 0.56 0.61 168 5545962225 0.40 0.39 0.40 181 5555641279 0.56 0.25 0.34 109 5715755404 0.26 0.18 0.21 138 5747062935 0.47 0.54 0.50 190 5758936842 0.64 0.61 0.63 235 5765520742 0.35 0.41 0.38 153 5778628528 0.47 0.38 0.42 157 5861856288 0.57 0.62 0.60 329 5938943847 0.65 0.81 0.72 250 5957043142 0.36 0.21 0.27 200 5961905764 0.59 0.70 0.64 233 5987007085 0.69 0.68 0.69 186 6138533400 0.52 0.47 0.49 158 6260881309 0.46 0.33 0.39 205 6327495460 0.51 0.47 0.49 196 6349154168 0.49 0.57 0.53 159 6635157126 0.56 0.32 0.41 150 6654730785 0.60 0.41 0.48 157 6659756057 0.45 0.24 0.31 106 6803385643 0.60 0.57 0.59 225 6842880073 0.68 0.51 0.58 148 7010468547 0.73 0.47 0.57 203 7104264675 0.52 0.37 0.43 188 7121847139 0.74 0.68 0.71 123 7123189219 0.59 0.66 0.62 295 7131826933 0.55 0.40 0.47 267 7138351709 0.27 0.17 0.21 102 7163230644 0.60 0.67 0.63 258 7171064607 0.37 0.29 0.33 163 7269384886 0.53 0.64 0.58 196 7277335021 0.45 0.34 0.39 177 7300335457 0.56 0.26 0.35 156 7317620755 0.78 0.70 0.74 181 7332689429 0.69 0.63 0.66 244 7408405796 0.46 0.38 0.42 289 7470260459 0.78 0.86 0.82 304 7510694143 0.35 0.13 0.19 119 7517407233 0.76 0.47 0.58 182 7578348615 0.57 0.39 0.47 250 7609453580 0.57 0.51 0.54 320 7657872067 0.67 0.52 0.59 102 7767783897 0.70 0.64 0.67 266 7809444487 0.67 0.64 0.66 146 7858268564 0.73 0.80 0.76 352 7858695423 0.54 0.55 0.54 277 7859245214 0.67 0.64 0.65 135 7860106684 0.62 0.49 0.54 148 7895152961 0.34 0.33 0.33 123 7923566448 0.30 0.17 0.22 197 7936666343 0.49 0.21 0.29 189 7939037427 0.64 0.43 0.51 198 7942904509 0.56 0.41 0.48 210 8021153733 0.66 0.44 0.53 107 8030555584 0.47 0.29 0.36 155 8050782732 0.86 0.73 0.79 153 8114087113 0.50 0.18 0.26 125 8125628639 0.34 0.18 0.24 105 8163003872 0.48 0.43 0.45 251 8249069139 0.73 0.67 0.70 135 8370753254 0.83 0.84 0.83 159 8507124067 0.78 0.81 0.80 364 8542857252 0.66 0.58 0.62 152 8556108428 0.91 0.77 0.83 199 8586387677 0.81 0.84 0.82 196 8609501758 0.78 0.72 0.75 295 8640331242 0.70 0.55 0.61 194 8738299697 0.58 0.42 0.48 214 8805929689 0.61 0.67 0.64 288 8808326741 0.82 0.58 0.68 180 8813608705 0.69 0.32 0.44 96 8927934999 0.79 0.59 0.67 107 9019303744 0.55 0.42 0.47 154 9068528669 0.44 0.23 0.30 104 9138883259 0.46 0.28 0.35 248 9159149619 0.86 0.65 0.74 176 9162465743 0.79 0.64 0.71 190 9256600334 0.53 0.36 0.43 100 9344706553 0.69 0.71 0.70 156 9388604588 0.69 0.34 0.45 130 9504749083 0.76 0.69 0.72 250 9527297544 0.48 0.41 0.44 99 9569696637 0.51 0.37 0.43 110 9626303390 0.91 0.54 0.67 110 9682965513 0.61 0.53 0.57 125 9794494979 0.78 0.68 0.72 179 9851461344 0.40 0.26 0.31 140 9851590985 0.57 0.50 0.53 155 9949829448 0.56 0.33 0.42 106 9958620956 0.42 0.36 0.39 187 accuracy 0.55 30976 macro avg 0.54 0.51 0.52 30976 weighted avg 0.55 0.55 0.54 30976 Process finished with exit code 0
模型的选择与调优
1、交叉验证
2、网格搜索
交叉验证:
- 为了让被评估的模型更加准确可信
交叉验证过程
将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。
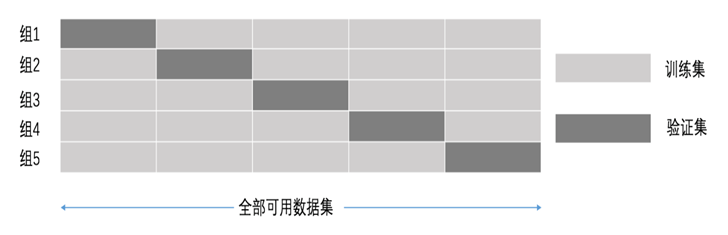
超参数搜索-网格搜索
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

超参数搜索-网格搜索API
- sklearn.model_selection.GridSearchCV
GridSearchCV
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
结果分析:
- best_score_:在交叉验证中验证的最好结果
- best_estimator_:最好的参数模型
- cv_results_:每次交叉验证后的测试集准确率结果和训练集准确率结果
K-近邻网格搜索案例
将前面的k-近邻算法案例改成网格搜索
from sklearn import datasets
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
import pandas as pd
def knncls():
"""
K-近邻算法实现入住
:return: None
"""
# 1. 读取数据
data = pd.read_csv('./FBlocation/train.csv')
# 2. 筛选数据 距离x: 1~1.25, y:2.5 ~ 2.75
data = data.query("x < 1.0 & y < 1.0")
# 3. 增加时间特征 weekday, day, hour
time_value = data['time']
time_value = pd.to_datetime(time_value, unit='s')
time_value = pd.DatetimeIndex(time_value)
data['weekday'] = time_value.weekday
data['day'] = time_value.day
data = data.drop(['time'], axis=1)
# 4.1 删除入住点较少的数据
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 400].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 5. 开始获取特征数据 和 目标数据
y = data['place_id']
x = data.drop(["place_id"], axis=1)
# 6. 切分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 6.1 创建标准化对象
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 7. 选择k-近邻模型开始输入训练的特征数据和目标数据来训练得到数据
knn = KNeighborsClassifier(n_neighbors=3)
crv = GridSearchCV(knn, param_grid={"n_neighbors": [1,3,5]}, cv=2)
crv.fit(x_train, y_train)
print("网格搜索和交叉验证")
print(crv.score(x_test, y_test))
print(crv.best_score_)
print(crv.best_estimator_)
print(crv.cv_results_)
return None
if __name__ == '__main__':
knncls()
"C:\Program Files\Python36\python.exe" D:/数据分析/机器学习/day2/3-代码/day2_test.py D:/数据分析/机器学习/day2/3-代码/day2_test.py:21: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy data['weekday'] = time_value.weekday D:/数据分析/机器学习/day2/3-代码/day2_test.py:22: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy data['day'] = time_value.day 网格搜索和交叉验证 0.5632747933884298 0.5069355479150179 KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=1, p=2, weights='uniform') {'mean_fit_time': array([0.21851254, 0.22101271, 0.21551239]), 'std_fit_time': array([4.50038910e-03, 1.19209290e-07, 1.50001049e-03]), 'mean_score_time': array([3.98722804, 4.69476855, 5.00078607]), 'std_score_time': array([0.11800659, 0.03750217, 0.0215013 ]), 'param_n_neighbors': masked_array(data=[1, 3, 5], mask=[False, False, False], fill_value='?', dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}], 'split0_test_score': array([0.50727445, 0.46541408, 0.45794594]), 'split1_test_score': array([0.50659665, 0.46421884, 0.45216624]), 'mean_test_score': array([0.50693555, 0.46481646, 0.45505609]), 'std_test_score': array([0.0003389 , 0.00059762, 0.00288985]), 'rank_test_score': array([1, 2, 3])} Process finished with exit code 0
分类算法之决策树
决策树是一种基本的分类方法,当然也可以用于回归。我们一般只讨论用于分类的决策树。决策树模型呈树形结构。在分类问题中,表示基于特征对实例进行分类的过程,它可以认为是if-then规则的集合。在决策树的结构中,每一个实例都被一条路径或者一条规则所覆盖。通常决策树学习包括三个步骤:特征选择、决策树的生成和决策树的修剪
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理逻辑回归等不能解决的非线性特征数据
缺点:可能产生过度匹配问题
适用数据类型:数值型和标称型
特征选择
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的京都影响不大。通常特征选择的准则是信息增益,这是个数学概念。通过一个例子来了解特征选择的过程。
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
我们希望通过所给的训练数据学习一个贷款申请的决策树,用以对文莱的贷款申请进行分类,即当新的客户提出贷款申请是,根据申请人的特征利用决策树决定是否批准贷款申请。特征选择其实是决定用那个特征来划分特征空间。下图中分别是按照年龄,还有是否有工作来划分得到不同的子节点
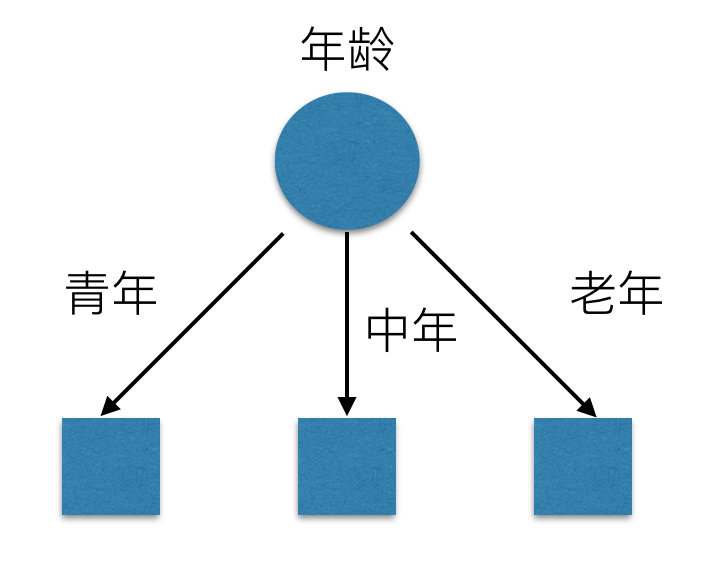
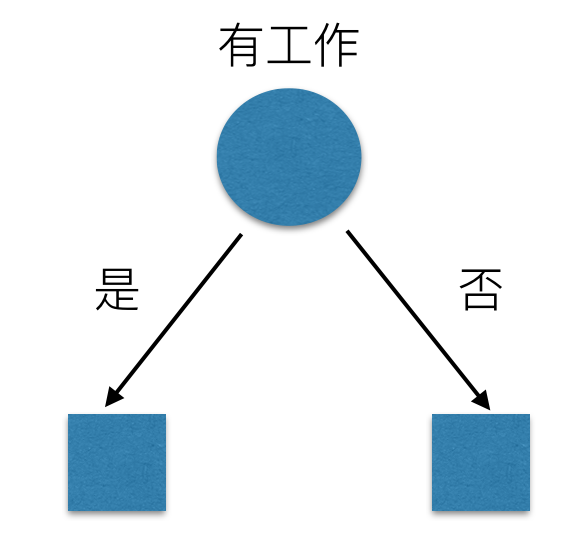
问题是究竟选择哪个特征更好些呢?那么直观上,如果一个特征具有更好的分类能力,是的各个自己在当前的条件下有最好的分类,那么就更应该选择这个特征。信息增益就能很好的表示这一直观的准则。这样得到的一棵决策树只用了两个特征就进行了判断:
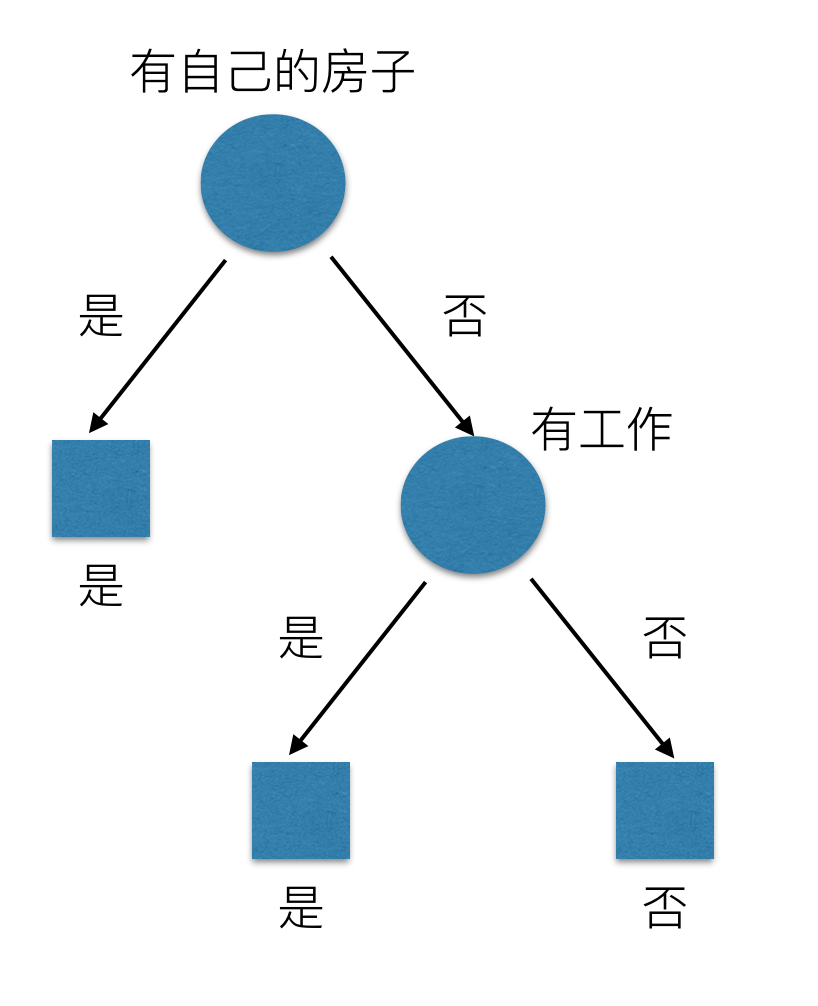
通过信息增益生成的决策树结构,更加明显、快速的划分类别。下面介绍scikit-learn中API的使用
我们常说信息有用,那么它的作用如何客观、定量地体现出来呢?信息用途的背后是否有理论基础呢?这个问题一直没有很好的回答,直到1948年,香农在他的论文“通信的数学原理”中提到了“信息熵”的概念,才解决了信息的度量问题,并量化出信息的作用。
猜谁是冠军?假设有32支球队
每猜一次给一块钱,告诉我是否猜对了,那么我需要掏多少钱才能知道谁是冠军?我可以把球编上号,从1到32,然后提问:冠 军在1-16号吗?依次询问,只需要五次,就可以知道结果。

信息的单位:比特

信息和消除不确定性是相联系的



常见决策树使用的算法
ID3
- 信息增益 最大的准则
C4.5
- 信息增益比 最大的准则
CART
-
回归树: 平方误差 最小
-
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则
sklearn决策树API
- class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器
-
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
-
max_depth:树的深度大小
-
random_state:随机数种子
method:
- decision_path:返回决策树的路径
泰坦尼克号数据
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。在泰坦尼克号的数据帧不包含从剧组信息,但它确实包含了乘客的一半的实际年龄。关于泰坦尼克号旅客的数据的主要来源是百科全书
Titanica。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
其中age数据存在缺失。
泰坦尼克号乘客生存分类模型
-
1、pd读取数据
-
2、选择有影响的特征,处理缺失值
-
3、进行特征工程,pd转换字典,特征抽取
-
x_train.to_dict(orient="records")
-
4、决策树估计器流程
决策树的结构、本地保存
1、sklearn.tree.export_graphviz() 该函数能够导出DOT格式
- tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
2、工具:(能够将dot文件转换为pdf、png)
安装graphviz
- ubuntu:sudo apt-get install graphviz Mac:brew install graphviz
3、运行命令
- $ dot -Tpng tree.dot -o tree.png
决策树的优缺点以及改进
优点:
- 简单的理解和解释,树木可视化。需要很少的数据准备,其他技术通常需要数据归一化
缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
改进:
-
减枝cart算法
-
随机森林
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多。
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import pandas as pd
def decisiontree():
"""
通过决策树对泰坦尼克号数据分析
:return: None
"""
# 读取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 获取特征值 和 目标值
x = titan[["age","sex","pclass"]]
y = titan["survived"]
# 处理年龄的缺失值 以平均值填充
x['age'].fillna(x['age'].mean(), inplace=True)
# 切分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 需要数据转换为字典格式
x_train = x_train.to_dict(orient="records")
x_test = x_test.to_dict(orient="records")
# 对训练集和测试集的特征数据 进行特征提取
dict_vec = DictVectorizer(sparse=False)
x_train = dict_vec.fit_transform(x_train)
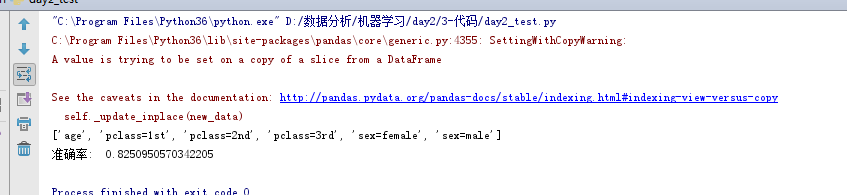
print(dict_vec.get_feature_names())
x_test = dict_vec.transform(x_test)
# 创建模型
de = DecisionTreeClassifier(max_depth=3)
de.fit(x_train, y_train)
score = de.score(x_test, y_test)
print("准确率: ", score)
export_graphviz(de,'./tree.dot',feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=女性'])
return None
if __name__ == '__main__':
decisiontree()
集成学习方法-随机森林
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个数的结果是False, 那么最终结果会是True.
学习算法
根据下列算法而建造每棵树:
用N来表示训练用例(样本)的个数,M表示特征数目。
一次随机选出一个样本,重复N次, (有可能出现重复的样本)
随机去选出m个特征, m <<M,建立决策树采取bootstrap抽样
为什么要随机抽样训练集?
- 如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林
最后分类取决于多棵树(弱分类器)的投票表决。
集成学习API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None)
-
n_estimators:integer,optional(default = 10) 森林里的树木数量
-
criteria:string,可选(default =“gini”)分割特征的测量方法
-
max_depth:integer或None,可选(默认=无)树的最大深度
-
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
随机森林的优点
-
在当前所有算法中,具有极好的准确率
-
能够有效地运行在大数据集上
-
能够处理具有高维特征的输入样本,而且不需要降维
-
能够评估各个特征在分类问题上的重要性
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
def rand_tree():
"""
通过决策树对泰坦尼克号数据分析
:return: None
"""
# 读取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 获取特征值 和 目标值
x = titan[["age","sex","pclass"]]
y = titan["survived"]
# 处理年龄的缺失值 以平均值填充
x['age'].fillna(x['age'].mean(), inplace=True)
# 切分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 需要数据转换为字典格式
x_train = x_train.to_dict(orient="records")
x_test = x_test.to_dict(orient="records")
# 对训练集和测试集的特征数据 进行特征提取
dict_vec = DictVectorizer(sparse=False)
x_train = dict_vec.fit_transform(x_train)
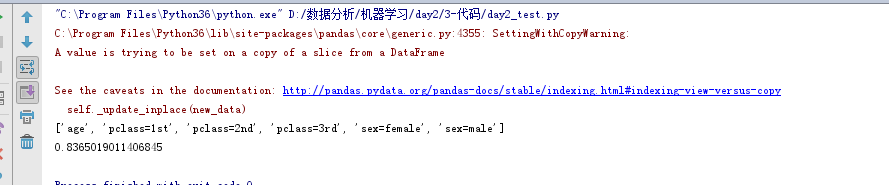
print(dict_vec.get_feature_names())
x_test = dict_vec.transform(x_test)
rand_tree=RandomForestClassifier(max_depth=3)
rand_tree.fit(x_train,y_train)
score=rand_tree.score(x_test,y_test)
print(score)
return None
if __name__ == '__main__':
rand_tree()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号