influxdb 快速入门
通过终端进入 infliuxdb 数据库
influx -username root -password 123456
创建一个mydb数据库
CREATE DATABASE mydb
列出所有数据库
show databases
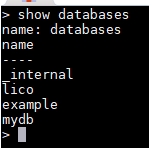
说明:_internal数据库是用来存储InfluxDB内部的实时监控数据的
大部分InfluxQL需要作用在一个特定的数据库上。你当然可以在每一个查询语句上带上你想查的数据库的名字,但是CLI提供了一个更为方便的方式USE <db-name>,这会为你后面的所以的请求设置到这个数据库上。例如
use mydb
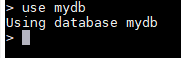
以下的操作都作用于mydb这个数据库之上
简单入门
首先对数据存储的格式来个入门介绍。InfluxDB里存储的数据被称为时间序列数据,其包含一个数值,就像CPU的load值或是温度值类似的。时序数据有零个或多个数据点,每一个都是一个指标值。数据点包括time(一个时间戳),measurement(例如cpu_load),至少一个k-v格式的field(也即指标的数值例如 “value=0.64”或者“temperature=21.2”),零个或多个tag,其一般是对于这个指标值的元数据(例如“host=server01”, “region=EMEA”, “dc=Frankfurt)
在概念上,你可以将 measurement 类比于SQL里面的 table,其主键索引总是时间戳。 tag和field是在table里的其他列,tag是被索引起来的,field没有。不同之处在于,在InfluxDB里,你可以有几百万的 measurements,你不用事先定义数据的scheme,并且 null 值不会被存储。
将数据点写入InfluxDB,只需要遵守如下的行协议
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
下面是数据写入InfluxDB的格式示例:
cpu,host=serverA,region=us_west value=0.64 payment,device=mobile,product=Notepad,method=credit billed=33,licenses=3i 1434067467100293230 stock,symbol=AAPL bid=127.46,ask=127.48 temperature,machine=unit42,type=assembly external=25,internal=37 1434067467000000000
使用CLI插入单条的时间序列数据到InfluxDB中,用INSERT后跟数据点 measurement,tag, value 依次使用 ,进行分割。
insert cpu,host=serverA,region=us_west value=0.64
这样一个 measurement 为cpu,tag是host和region,value值为0.64的数据点被写入了InfluxDB中。
现在我们查出写入的这笔数据
select * from cpu
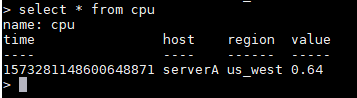
我们在写入的时候没有包含时间戳,当没有带时间戳的时候,InfluxDB会自动添加本地的当前时间作为它的时间戳
让我们来写入另一笔数据,它包含有两个字段
INSERT temperature,machine=unit42,type=assembly external=25,internal=37
查询的时候想要返回所有的字段和tag,可以用*
select * from temperature

InfluxQL还有很多特性和用法没有被提及,包括支持golang样式的正则,例如
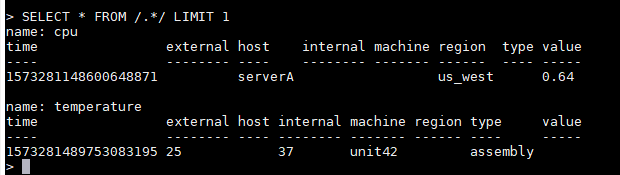
(1)显示所有表的第一条语句
SELECT * FROM /.*/ LIMIT 1
(2)显示一个表中的所有字段
SELECT * FROM "cpu_load_short"
(3)根据条件筛选某个表中的数据
SELECT * FROM "cpu_load_short" WHERE "value" > 0.9
采样和数据保留
InfluxDB每秒可以处理数十万的数据点。如果要长时间地存储大量的数据,对于存储会是很大的压力。一个很自然的方式就是对数据进行采样,对于高精度的裸数据存储较短的时间,而对于低精度的的数据可以保存得久一些甚至永久保存
InfluxDB提供了两个特性——连续查询(Continuous Queries简称CQ)和保留策略(Retention Policies简称RP),分别用来处理数据采样和管理老数据的。这一章将会展示CQs和RPs的例子,看下在InfluxDB中怎么使用这两个特性
定义
Continuous Query (CQ)是在数据库内部自动周期性跑着的一个InfluxQL的查询,CQs需要在SELECT语句中使用一个函数,并且一定包括一个GROUP BY time()语句。
Retention Policy (RP)是InfluxDB数据架构的一部分,它描述了InfluxDB保存数据的时间。InfluxDB会比较服务器本地的时间戳和请求数据里的时间戳,并删除比你在RPs里面用DURATION设置的更老的数据。一个数据库中可以有多个RPs但是每个数据库的RPs是唯一的。
数据采样
本节使用虚构的实时数据,以10秒的间隔,来追踪餐厅通过电话和网站订购食品的订单数量。我们会把这些数据存在food_data数据库里,其measurement为orders,fields分别为phone和website

目标
假定在长时间的运行中,我们只关心每三十分钟通过手机和网站订购的平均数量,我们希望用RPs和CQs实现下面的需求
-
自动将十秒间隔数据聚合到30分钟的间隔数据
-
自动删除两个小时以上的原始10秒间隔数据
-
自动删除超过52周的30分钟间隔数据
数据库准备
在写入数据到数据库food_data之前,我们先做如下的准备工作,在写入之前设置CQs是因为CQ只对最近的数据有效; 即数据的时间戳不会比now()减去CQ的FOR子句的时间早,或是如果没有FOR子句的话比now()减去GROUP BY time()间隔早
(1)创建数据库
CREATE DATABASE "food_data"
(2)创建一个两小时的默认 RP
如果我们写数据的时候没有指定RP的话,InfluxDB会使用默认的RP,我们设置默认的RP是两个小时。使用 CREATE RETENTION POLICY语句来创建一个默认RP:
CREATE RETENTION POLICY "two_hours" ON "food_data" DURATION 2h REPLICATION 1 DEFAULT
这个RP的名字叫two_hours作用于food_data数据库上,two_hours保存数据的周期是两个小时,并作为food_data的默认RP
复制片参数(REPLICATION 1)是必须的,但是对于单个节点的InfluxDB实例,复制片只能设为1
说明:在步骤1里面创建数据库时,InfluxDB会自动生成一个叫做autogen的RP,并作为数据库的默认RP,autogen这个RP会永远保留数据。在输入上面的命令之后,two_hours会取代autogen作为food_data的默认RP
创建一个保留52周数据的RP
接下来我们创建另一个RP保留数据52周,但不是数据库的默认RP。最终30分钟间隔的数据会保存在这个RP里面
使用CREATE RETENTION POLICY语句来创建一个非默认的RP
CREATE RETENTION POLICY "a_year" ON "food_data" DURATION 52w REPLICATION 1
这个语句对数据库food_data创建了一个叫做a_year的RP,a_year保存数据的周期是52周。去掉DEFAULT参数可以保证a_year不是数据库food_data的默认RP。这样在读写的时候如果没有指定,仍然是使用two_hours这个默认RP
创建CQ
现在我们已经创建了RPs,现在我们要创建一个CQ,去将10秒间隔的数据采样到30分钟的间隔,并把它们安装不同存储策略把它们存在不同的measurement里
使用CREATE CONTINUOUS QUERY来生成一个CQ
CREATE CONTINUOUS QUERY "cq_30m" ON "food_data" BEGIN
SELECT mean("website") AS "mean_website",mean("phone") AS "mean_phone"
INTO "a_year"."downsampled_orders"
FROM "orders"
GROUP BY time(30m)
END
上面创建了一个叫做cq_30m的CQ作用于food_data数据库上。cq_30m告诉InfluxDB每30分钟计算一次measurement为orders并使用默认RPtow_hours的字段website和phone的平均值,然后把结果写入到RP为a_year,两个字段分别是mean_website和mean_phone的measurement名为downsampled_orders的数据中。InfluxDB会每隔30分钟跑对之前30分钟的数据跑一次这个查询
说明:注意到我们在INTO语句中使用了"<retention_policy>"."<measurement>"这样的语句,当要写入到非默认的RP时,就需要这样的写法
结果
使用新的CQ和两个新的RPs,food_data已经开始接收数据了。之后我们向数据库里写数据,并且持续一段时间之后,我们可以看到两个measurement分别是orders和downsampled_orders
> SELECT * FROM "orders" LIMIT 5 name: orders --------- time phone website 2016-05-13T23:00:00Z 10 30 2016-05-13T23:00:10Z 12 39 2016-05-13T23:00:20Z 11 56 2016-05-13T23:00:30Z 8 34 2016-05-13T23:00:40Z 17 32 > SELECT * FROM "a_year"."downsampled_orders" LIMIT 5 name: downsampled_orders --------------------- time mean_phone mean_website 2016-05-13T15:00:00Z 12 23 2016-05-13T15:30:00Z 13 32 2016-05-13T16:00:00Z 19 21 2016-05-13T16:30:00Z 3 26 2016-05-13T17:00:00Z 4 23
在orders里面是10秒钟间隔的裸数据,保存时间为2小时。在downsampled_orders里面是30分钟的聚合数据,保存时间为52周
注意到downsampled_orders返回的第一个时间戳比orders返回的第一个时间戳要早,这是因为InfluxDB已经删除了orders中时间比本地早两个小时的数据。InfluxDB会在52周之后开始删除downsampled_orders中的数据
说明:注意这里我们在第二个语句中使用了"<retention_policy>"."<measurement>"来查询downsampled_orders,因为只要不是使用默认的RP我们就需要指定RP。
默认InfluxDB是每隔三十分钟check一次RP,在两次check之间,orders中可能有超过两个小时的数据,这个check的间隔可以在InfluxDB的配置文件中更改。
使用RPs和CQs的组合,我们已经成功地创建的数据库并保存高精度的裸数据较短的时间,而保存高精度的数据更长时间。现在我们对这些特性的工作有了大概的了解,我们推荐到CQs和RPs去看更详细的文档
https://blog.csdn.net/u010185262/article/details/53158786

 浙公网安备 33010602011771号
浙公网安备 33010602011771号