python 实用编程技巧 —— 文件I/O效率相关问题与解决技巧
如何读写文本文件

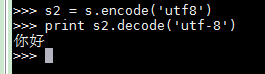
python2中,默认编码是ascii编码,这种编码不能直接存储物理硬件(磁盘的扇区、网络的socket)中,需要转换成string(由连续的字节组成)

从错误提示可以看出,字符串s不是unicode编码是而是ascii编码,不能再进行编码。
创建unicode编码字符串 在字符串前加’u’

在python中只使用内部的unicode表示字符,编解码要使用统一格式 ,否则会乱码
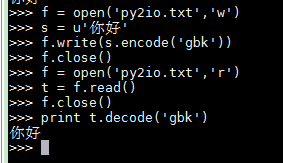
Py2中写入文件时要把unicode编码格式编码,从文件读出后,也要把读出的按统一格式解码。
Py2文件读写
在py3中的str 变成了unicode(真正意义上的连续字符串),在py3 表示byte需要在字符串前加个b
在py2中需要加个u''表示unicode字符串,而py3中默认就是unicode(也就是str),不需要添加。
在py3中open函数功能更强大,可以使用encoding指定编码格式
info = '你好'#open通过encoding参数自动编码成utf8
with open('H3','wt',encoding='utf8') as f: # t可以不写 python3 默认文本模式打开
f.write(info)
#读取文件的时候,自动解码成utf8,不要和上面存入时的编码搞混,文件里的数据显示的是连续的字节
with open('H3','rt',encoding='utf8') as f2:
print(f2.read())
如何处理二进制文件
实际案例
- wav 是一种音频文件的格式, 音频文件为二进制文件
- wav 文件由头部信息和音频采样数据构成。 前面为头部信息, 包括声道数, 采样频率, 编码位宽等等, 后面是音频采样数据
- 使用python, 分析一个 wav 文件头部信息, 处理音频数据
解决方案
- open函数以二进制文件打开, 指定mode 参数为b
- 二进制数据可以用readinto, 读入到提前分配好的buffer中
- 解析二进制数据可以使用标准库中的struct模块的unpack方法
import struct
def find_subchunk(f, chunk_name):
f.seek(12) # 从头 跳过12个字节
while True:
name = f.read(4) # 读取4个字节
chunk_size, = struct.unpack('i', f.read(4)) # i 即int 解析4个字节 h 解析两个字节
print(name)
if name == chunk_name:
return f.tell(), chunk_size # f.tell当前文件的指针位置
f.seek(chunk_size, 1) # 1 表示当前 0 表示从头 为默认
f = open('demo.wav', 'rb') # 二进制文件 带b
offset, size = find_subchunk(f, b'data')
import numpy as np
buf = np.zeros(size // 2, dtype=np.short) # array([0,0,0,0,...0], dtype=int16)
f.readinto(buf)
buf //= 8 # 除8 获得整数结果 获取声音小的声音
f2 = open('out.wav', 'wb')
f.seek(0)
info = f.read(offset)
f2.write(info)
buf.tofile(f2)
f2.clode()
如何设置文件的缓冲
将文件内容写入到硬件设备时, 使用系统调用, 这类IO操作的时间很长。为例减少IO操作的次数, 文件通常使用缓冲区(有足够多的数据才进行系统调用)。 文件的缓冲行为,分为
'全缓冲', '行缓冲', '无缓冲'
全缓冲
- 缓冲区满了 才将内容写入文件
- 全缓冲的大小和设备有关,一般一个块为4096个字节,当超过4096时才会输出到文件上。
# 全缓冲
f = open('a.bin', wb)
f.write(b'abc') # 此时 打开a.bin文件 发现什么都没有, 因为现在数据 在缓冲区中
f.write(b'efg') # 此时 缓冲区没有填满, 数据依然在缓冲区中
f.write(b'1'*(4096-6)) # 假设 磁盘的缓冲区大小为 4096 此时打开 a.bin 发现有内容了
# 文本模式下
f2 = open('a.txt', 'w')
f2.write('a'*4095) # 此时a.txt没有数据
f2.write('bc') # 超过4096 字节了 a.txt依然没有内容 为什么呢?
# 字节流wb 方式 打开 时, 数据 -> B(4096字节缓冲区 encode和decode) -> Raw(无缓冲 可以直接写入文件)
# 文本模式 打开 , 数据 -> TextIO(8192字节缓冲区) -> B -> Raw
f2.write('2'*10000) # 此时 a.txt 有内容了
指定缓冲区大小
f = open('a.bin', 'wb', buffering=8192)
f.write('........')
行缓冲
- 遇到 换行符/n 就将缓冲区的内容写入 文件, 遇不到换行符 则和全缓冲一样。
- linux 的shell终端 就是 行缓冲的
- 只能在 文本模式中 使用
# 设置为行缓冲
f = open('a.bin', 'wb', buffering=1)
f.write('huanghuanchong')
无缓冲 (实时的写入数据到磁盘中)
# 无缓冲方法
#方法一
f.raw.write('aaaaaaaaa')
# 方法二
f = open('a.bin', 'wb', buffering=0)
f.write('wuhuanchong')
如何将文件映射到内存
实际案例
- 1. 在访问某些二进制文件时, 希望能把文件映射到内存中, 可以实现随机访问('framebuffer设备文件')
- 2. 某些嵌入式设备, 寄存器被编址到内存地址空间, 我们可以映射 '/dev/mem' 某范围, 去访问这些寄存器
- 3. 如果多个进程映射同一个文件, 还能实现进程通讯的目的
解决方案
- 使用标准库 'mmap.mmap()函数', 将文件映射到 进程的内存地址空间
import mmap
# 屏幕设备文件
f = open('/dev/fb0', 'r+b')
size = 8294400
m = mmap.mmap(f.fileno(), size)
# f.fileno 得到文件描述符 , os.open获取的文件描述符一样
# size如果为0 表示 文件的全部放入内存, 这里是特殊设备文件需要计算大小用0可能会出错
# m 有 如 m.write(b'abc) 类似文件的 一些操作
m[:size//2] = b'\xff\xff\xff\x00' * (size // 4 // 2)
# 把一般的屏幕变为白色 和透明 一个字节是8位 \xff 正好一个字节
m.close()
f.close()
如何访问文件的状态
在某些项目中, 我们需要获得文件的状态, 列如:
- 1. 文件的类型('普通文件、目录、符号链接、设备文件...')
- 2. 文件的访问权限
- 3. 文件的最后的访问/ 修改/ 节点 状态更改时间
- 4. 普通文件的大小
解决方案
- 系统调用: 标准库 'os模块'中的系统调用 'stat' 获取文件状态
import os
# fd = os.open('b.py', os.O_RDONLY) # 只读方式打开, 得到文件描述符 实际上就是一个数字 如23
# os.read(fd, 10) # 文件描述符是给 系统调用的 方法用的, 读10个字节
s = os.stat('5_2.py') # 返回状态结果对象 可以传入文件, 也可以传入 文件夹
s = os.lstat('5_2.py') # 不会跟随 符号链接 比如a 是b 的符号链接(软链接) 不加l 参数a会自动变为b
'''
os.stat_result(st_mode=33261, st_ino=13242808, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20,
st_size=349, st_atime=1539776238, st_mtime=1531978808, st_ctime=1534324393)
st_mode 文件类型 和权限 如 lrwxrwxrwx
st_ino 文件系统inode 节点的索引
st_dev 当前文件所在设备 当前磁盘的分区
st_nlink 硬链接数1 表示文件本身 shell命令 :ln a.txt b.txt 创建a的硬连接b, a的硬连接会由1变为2
st_uid 文件所有者id
st_gid 文件所有者所在组id
st_size 文件大小 字节
st_atime 最近访问时间
st_mtime 最近修改时间
st_ctime 创建时间
'''
# 目前的 状态结果对象 不容易观察, 需要与特定的掩码 做与操作, python给我们定义好了
# ----------------处理st_mode---------------------
import stat
stat.S_IFDIR & s.st_mode # 0 不是目录
stat.S_IFCHR & s.st_mode # 0 不是char设备
stat.S_IFREG & s.st_mode # 32768得到数字 是普通文件
# 或者
stat.S_ISREG(s.st_mode) # true 是普通文件
stat.S_ISLNK(s.st_mode) # false 不是符号链接文件
stat.S_IRUSR & s.st_mode # 236 是否用户刻度
stat.S_IXOTH & s.st_mode # 是否用户可执行
# ----------------处理st_atime 等时间对象---------------------
import time
time.localtime(s.st_atime)
快捷函数: 标准库 'os.path' 下的一些函数, 使用起来更加简洁
os.path.isfile('5_3.py') # 是否是文件
os.path.isdir('5_3.py') # 是否是目录
os.path.getatime('5_3.py') # 获取访问时间
os.path.getsize('5_3.py') # 获取文件大小
如何使用临时文件
实际案例
某项目中, 我们从传感器采集数据, 没收集到1G 数据后, 做数据分析, 最终只保存分析结果。
这样很大的临时数据如果常驻内存, 将消耗大量内存资源, 我们可以使用临时文件存储这些临时数据('外部存储')
临时文件不用命名, 且关闭后会自动被删除
解决方案
-
使用标准库中的 TemporaryFile 以及 NamedTemporaryFile
-
一般使用TemporaryFile即可
-
当多进程 要访问同一个临时文件时, 可以使用命名的临时文件NamedTemporaryFile
TemporaryFile
由TemporaryFile创建的文件,不能由绝对路径找到,只能通过文件对象找到访问
from tempfile import TemporaryFile, NamedTemporaryFile #创建一个临时文件可以指定临时文件 放在哪个盘/目录 tf = TemporaryFile( dir='/tmp/') f = TemporaryFile() #将数据写入这个临时文件, f.write(b'abcdef'*10000) f.seek(0) print( f.read(100)) #读数据时一部分一部分读取 # 删除临时文件 f.close()

NamedTemporaryFile
由NamedTemporaryFile创建的文件,可以由绝对路径找到。临时文件关闭后也会自动删除
from tempfile import TemporaryFile, NamedTemporaryFile # 如若使临时文件关闭后不自动删除 可以修改delete参数指定 为false # ntf = NamedTemporaryFile(delete = False) ntf = NamedTemporaryFile() # 此属性描述了在文件系统下的路径 print(ntf.name)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号