指针和内置函数
指针
普通类型变量存的就是值,也叫值类型。指针类型存的是地址,即指针的值是一个变量的地址。
一个指针指示值所保存的位置,不是所有的值都有地址,但是所有的变量都有。使用指针可以在无需知道
变量名字的情况下,间接读取或更新变量的值。
获取变量的地址,用&,例如:var a int 获取a的地址:&a,&a(a的地址)这个表达式获取一个指向整形变量的指针,它的类型是整形指针(*int),如果值叫做p,我们说p指向x,或者p包含x的地址,p指向的变量写成
*p ,而*p获取变量的值,这个时候*p就是一个变量,所以可以出现在赋值操作符的左边,用于更新变量的值
指针类型的零值是nil
两个指针当且仅当指向同一个变量或者两者都是nil的情况才相等
通过下面小例子进行理解指针:
package main
import (
"fmt"
)
func test() {
x := 1
// &x 获取的是变量x的地址,并赋值给p,这个时候p就是一个指针
p := &x
// p是指针,所以*p获取的就是变量的值,指针指向的是变量x的值,即*p为1
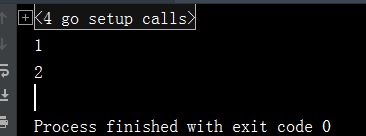
fmt.Println(*p)
// 这里*p 进行赋值,也就是更改了变量x的值,即实现不知道变量的名字更改变量的值
*p = 2
fmt.Println(x)
}
func main() {
test()
}
输出结果如下
再看一个关于通过一个函数来修改变量值的问题:
package main
import (
"fmt"
)
func modify(num int) {
num = 100
}
func main() {
a := 10
modify(a)
fmt.Println(a)
}
输出结果如下
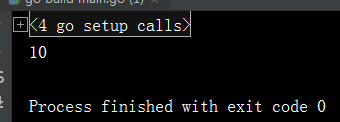
这个例子是修改变量的值,但是最后打印变量a的值是还是10,所以这里就需要知道,当通过定义的函数modify来修改变量的值时,传入变量a其实会进行一次拷贝,传入的其实是a变量的一个副本,所以当通过
modify修改的时候修改的是副本的值,并没有修改变量a的值。
当我们理解指针的之后,就可以通过指针的的方法来解决上面的这个问题,将代码更改为:
package main
import (
"fmt"
)
func modify(num *int) {
*num = 100
}
func main() {
a := 10
modify(&a)
fmt.Println(a)
}
输出结果如下
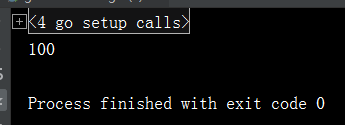
这里定义modify函数的时候参数设置的是一个指针,所以我们传入参数时,传入的是&a即变量a的地址,而这个地址指向的值是10,虽然这次传入的参数也是进行了传入的指针进行了一次拷贝,但是即使是拷贝了副本指向的值还是10,所以当我们通过指针*num修改值的时候其实就是在修改变量a的值。
内置函数
len: 用于求长度,比如string、array、slice、map、channel
new: 来分配内存,主要来分配值类型,如int、struct。返回的是指针
make: 来分配内存,主要 来分配引 类型, 如chan、map、slice
append: 来追加元素到数组、slice中
panic和recover: 来做错误(这个后续整理)
下面重点整理new和make
new函数
func new(Type) *Type
先看一下官网对这个内置函数的介绍:
内置函数 new 用来分配内存,它的第一个参数是一个类型,不是一个值,它的返回值是一个指向新分配类型零值的指针。这里要特别注意new返回的是一个指针
new函数也是创建变量的一种方式。表达式new(T)创建一个未命名的T类型变量,初始化T类型的零值,并返回其地址(地址类型为*T)
通过下面例子进行理解:
package main
import "fmt"
func newFunc() {
p := new(int)
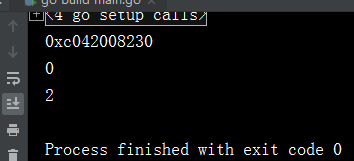
fmt.Println(p) //打印是地址
fmt.Println(*p) //int类型的零值为0这里打印0
*p = 2
fmt.Println(*p) //*p已经为其地址指向了一个变量2,所以这里打印为2
}
func main() {
newFunc()
}
输出结果如下
这里我们要知道new创建的变量和取其地址的普通局部变量没有什么不同,只是语法上的便利
下面是两种方式的例子:
func newInt() *int {
return new(int)
}
func newInt2() *int {
var res int
return &res
}
如果我们定义一个指针是不能直接给这个指针赋值的,而是需要先给这个指针分配内存,然后才能赋值
下面例子先不初始化分配内存,直接赋值:
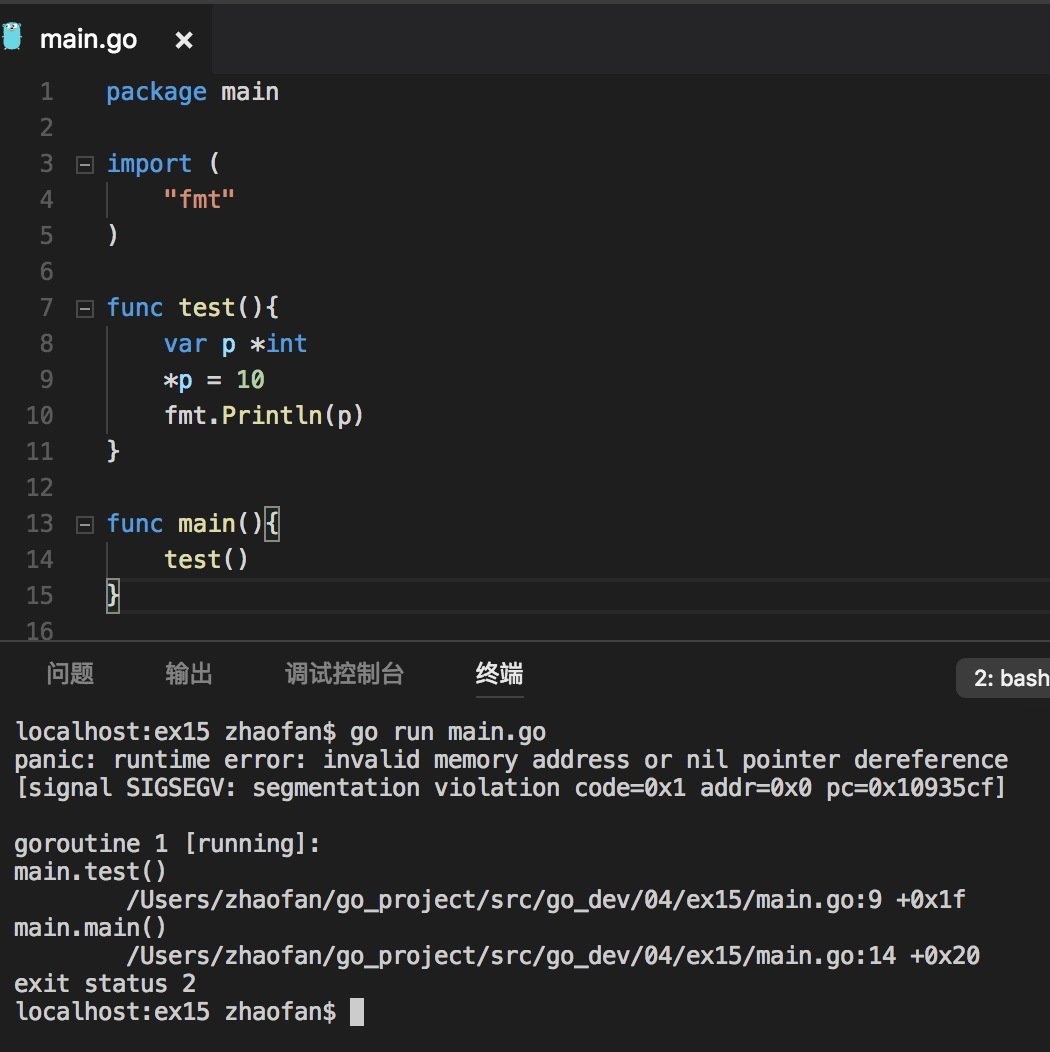
正确的做法是我们需要先通过new初始化,正确代码如下:
package main
import (
"fmt"
)
func test(){
var p *int
p = new(int)
*p = 10
fmt.Println(*p)
}
func main(){
test()
}
make函数
func make(Type, size IntegerType) Type
先看一下官网对这个内置函数的介绍:
内置函数make用来为slice,map或chan类型分配内存或初始化一个对象(这里需要注意:只能是这三种类型)
第一次参数也是一个类型而不是一个值
返回的是类型的引用而不是指针,而且返回值也依赖具体传入的类型
注意:make返回初始化后的(非零)值。
其实在上一篇整理切片slice的时候就用到了make如:
make([]type,len)
当时通过make来初始化slice的时候,第二个参数指定了它的长度,如果吗,没有第三个参数,它的容量和长度相等,当然也可以传入第三个参数来指定不同的容量值,但是注意不能比长度值小
这里提前说一下通过make初始化map的时候,根据size大小来初始化分配内存,不过分配后的map长度为0,如果size被忽略了,会在初始化分配内存的时候分配一个小的内存
关于new和make的一个小结:
new 的作用是初始化一个指向类型的指针 (*T),make的作用是为slice,map或者channel初始化,并且返回引用 T
函数
函数的声明语法:func 函数名 (参数 表) [(返回值 表)] {}
这了要注意第一个花括号必须和func在一行
常见的几种声明函数的方法:
func add(){
}
func add(a int,b int){
}
func add(a int,b int) int{
}
func add(a int, b int)(int,int){
}
func add(a ,b int)(int,int){
}
golang函数的特点:
- 不支持重载,即一个包不能有两个名字一样的函数
- 函数也是一种类型,一个函数可以赋值给变量
- 匿名函数
- 多返回值
演示一些函数的例子:
package main
import (
"fmt"
)
func add(a, b int) int {
return a + b
}
func main() {
c := add //这里把函数名赋值给变量c
fmt.Printf("%p %T", c, add)
sum := c(10, 20) //调用c其实就是在调用add
fmt.Println(sum)
}
golang函数还有一个用法例子:
package main
import (
"fmt"
)
type addFunc func(int, int) int
func add(a, b int) int {
return a + b
}
func operator(op addFunc, a int, b int) int {
return op(a, b)
}
func main() {
c := add
sum := operator(c, 100, 200)
fmt.Println(sum)
}
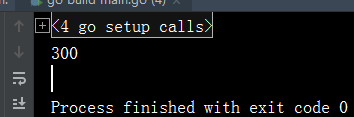
输出结果如下
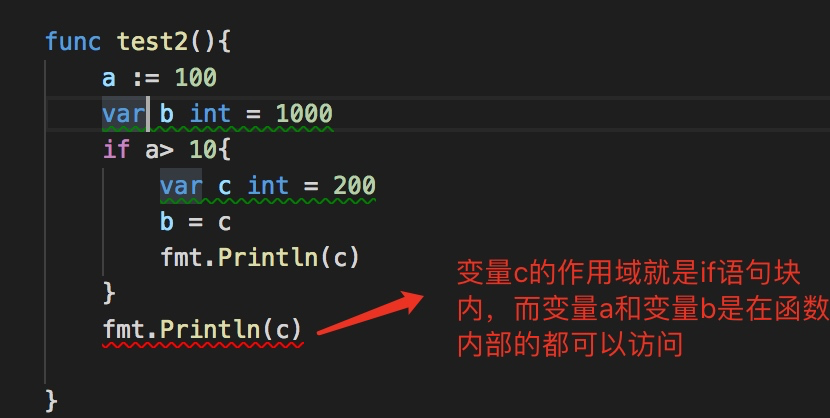
变量作用域
在函数外面的变量是全局变量
函数内部的变量是局部变量
go中变量的作用域有多种情况:
函数级别的,代码块级别的
通过下面例子理解:
关于函数的可变参数
变长函数被调用的时候可以有可变的参数个数
在参数列表最后的类型名称前使用省略号...可以声明一个变长的函数,
例如:
0个或多个参数
func add(arg...int) int{
}
1个或多个参数
func add(a int,arg...int) int{
}
2个或多个参数
func add(a int,b int,arg...int)int{
}
关于函数参数的传递
不管是值类型还是引用传递,传递给函数的都是变量的副本
注意:map,slice,chan,指针,interface默认以引用方式传递
延迟函数defer的调用
语法上,一个defer语句就是一个普通的函数或者方法调用,在调用之前加上关键字defer。函数和参数表达式会在语句执行时求值,但是无论是正常情况还是执行return语句或者函数执行完毕,以及不正常情况下,如程序发生宕机,实际的调用推迟到包含defer语句的函数结束后才执行,defer语句没有限制使用次数。
defer用途:
- 当函数返回时,执行defer语句,因此可以用来做资源清理
- 多个defer语句,按先进后出的方式执行
- defer语句中的变量,在defer声明时就决定了
先通过一个小例子理解defer:
package main
import (
"fmt"
)
func testDefer(){
a := 100
fmt.Printf("before defer:a=%d\n",a)
defer fmt.Println(a)
a = 200
fmt.Printf("after defer:a=%d\n",a)
}
func main(){
testDefer()
}
输出结果如下
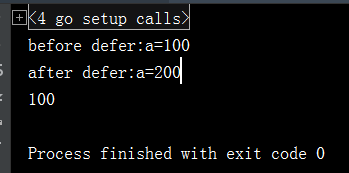
这里我们可以这样理解当我们执行defer语句的时a=100,这个时候压入到栈中,等程序最后结束的时候才会调用defer语句,所以打印的顺序是最后才打印一个数字100
defer语句经常使用成对的操作,比如打开和关闭,连接和断开,加锁和解锁
下面拿关闭一个打开文件操作为例子,当我们通过os.Open()打开一个文件的时候可以在后面添加defer f.Close() 这样在函数结束时就可以帮我们自动关闭一个打开的文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号