05 python深入python的set和dict
dict的abc继承关系
dict属于mapping类型,下面通过查看源码来分析它的继承关系
from collections.abc import Mapping, MutableMapping
查看MutableMapping源码
class MutableMapping(Mapping):
__slots__ = ()
"""A MutableMapping is a generic container for associating
key/value pairs.
This class provides concrete generic implementations of all
methods except for __getitem__, __setitem__, __delitem__,
__iter__, and __len__.
"""
@abstractmethod
def __setitem__(self, key, value):
raise KeyError
@abstractmethod
def __delitem__(self, key):
raise KeyError
__marker = object()
def pop(self, key, default=__marker):
'''D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
If key is not found, d is returned if given, otherwise KeyError is raised.
'''
try:
value = self[key]
except KeyError:
if default is self.__marker:
raise
return default
else:
del self[key]
return value
def popitem(self):
'''D.popitem() -> (k, v), remove and return some (key, value) pair
as a 2-tuple; but raise KeyError if D is empty.
'''
try:
key = next(iter(self))
except StopIteration:
raise KeyError
value = self[key]
del self[key]
return key, value
def clear(self):
'D.clear() -> None. Remove all items from D.'
try:
while True:
self.popitem()
except KeyError:
pass
def update(*args, **kwds):
''' D.update([E, ]**F) -> None. Update D from mapping/iterable E and F.
If E present and has a .keys() method, does: for k in E: D[k] = E[k]
If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v
In either case, this is followed by: for k, v in F.items(): D[k] = v
'''
if not args:
raise TypeError("descriptor 'update' of 'MutableMapping' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('update expected at most 1 arguments, got %d' %
len(args))
if args:
other = args[0]
if isinstance(other, Mapping):
for key in other:
self[key] = other[key]
elif hasattr(other, "keys"):
for key in other.keys():
self[key] = other[key]
else:
for key, value in other:
self[key] = value
for key, value in kwds.items():
self[key] = value
def setdefault(self, key, default=None):
'D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D'
try:
return self[key]
except KeyError:
self[key] = default
return default
MutableMapping.register(dict)
可以看到MutableMapping继承的是Mapping(不可变) ,最后把dict注册到MutableMapping.中 MutableMapping.register(dict)
可以通过 isinstance 查看一个字典的类型
from collections.abc import Mapping, MutableMapping
#dict属于mapping类型
a = {}
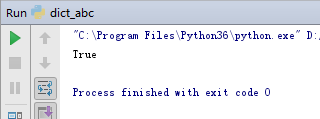
print (isinstance(a, MutableMapping))
测试结果如下
dict的常用方法
copy(这里是浅拷贝)
a = {"biao1":{"company":"imooc"},
"biao2": {"company": "imooc2"}
}
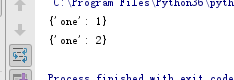
#copy, 返回浅拷贝
new_dict = a.copy()
new_dict["bobby1"]["company"] = "imooc3"
调试结果如下

fromkeys把可迭代的对象转变为dict
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
调试结果如下

get取值,可以设置一个默认值避免字典中keyerror异常
a = {"name1": "jack", "name2": "jane"}
value = a.get("name3", "not exist")
调试结果如下

setdefault(),和get()相似,不同的是如果没有某个键名,会把此键名和默认值加入到字典中
a = {"name1": "jack", "name2": "jane"}
# 没有指定键名时
a.setdefault("name3", "not exist")
调试结果如下

update(), 可用于添加字典元素
a = {"name1": "jack", "name2": "jane"}
# 直接添加字典方式
a.update({"name3": "hong"})
# 使用参数名方式
a.update(name4="lilei", name5="mei")
调试结果如下

dict的子类
如果我们想要继承dict重写我们的逻辑 ,不建议继承list和dict 因为他们是c语言写的,我们重写的函数有可能不会生效
#不建议继承list和dict
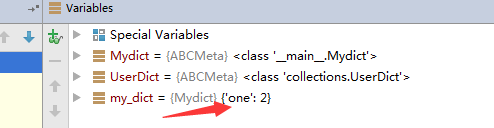
class Mydict(dict):
def __setitem__(self, key, value):
super().__setitem__(key, value*2)
my_dict = Mydict(one=1) # 在这个时候没生效
print (my_dict)
my_dict["one"] = 1 # 在这个时候生效
print(my_dict)
打印结果
应该使用python为我们提供的UserDict
from collections import UserDict
class Mydict(UserDict):
def __setitem__(self, key, value):
super().__setitem__(key, value*2)
my_dict = Mydict(one=1)
pass
调试结果如下
dict 的子类defaultdict
当我们取值一个不存在的值的时候,它会返回一个 {}
from collections import defaultdict my_dict = defaultdict(dict) my_value = my_dict["bobby"]
调试结果如下

内部源码分析


set和frozenset
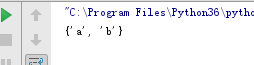
初始化一个set
# 使用set关键字
s1 = set('abc')
# 使用{}
s2 = {'a', 'b'}
print(type(s1), type(s2))

向set中添加元素
s1 = set('abc')
s1.add('d')
print(s1)
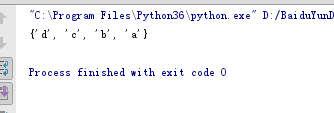
使用update()函数更新set
s1 = set('abc')
s2 = set('xy')
s1.update(s2)
print(s1)
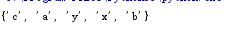
difference()函数来求两个集合的差集
s1 = set('abc')
s2 = set('cd')
# 相当于s1 - s2
re_set = s1.difference(s2)
print(re_set)
set的数学运算
s1 = set('abc')
s2 = set('cd')
# 差集
print(s1-s2)
# 交集
print(s1 & s2)
# 并集
print(s1 | s2)
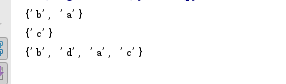
issubset()判断集合A是否为集合B的子集
s1 = set('abc')
s2 = set('c')
print(s2.issubset(s1))

dict和set的实现原理
list和dict的性能比较
1 dict的查找性能远大于list
2 在list中随着list数据量的增大,查找相同数据量的时间也会增大
3 在dict中随着dict数据量的增大,查找相同数据量的时间不怎么受影响
dict原理小结
dict找一个值之所以快,是因为他会根据这个键,进行哈希获得偏移量,直接取值,时间复杂度为0(1)
1)dict的key或者set的值都必须是可hash的,他们的实现原理相同。不可变对象都是可hash的,比如string, tuple, fronzenset
2)dict的内存花销大,但是查询速度快;自定义的类中,只要加上魔法函数__hash__, 那么这个类就是可hash的
3)dict的存储顺序和元素添加顺序有关,因hash值冲突的原因
4)添加数据的时候有可能会改变已有数据的顺序:存储dict的时候,python会预先申请一段大于dict数据需求的连续内存空间,以减少hash冲突的概率,当添加数据量使得大于分配内存空间的1/3的时候,python就会另申请一个较大的内存空间,把原先的数据进行迁移,重新进行hash值的计算

 浙公网安备 33010602011771号
浙公网安备 33010602011771号