03 python深入类和对象
鸭子类型和多态
当你看到一只鸟走起来像鸭子,叫起来也想鸭子,那么这只鸟就可以被成为鸭子
当我们在多个类中,定义了相同的方法,那么我们就可以给它归为一类,这就是鸭子类型
如 一个对象有__iter__( )方法或__getitem__( )方法,则称这个对象是可迭代的
如果一个对象有__iter__( )方法和__next__( )方法,则称这个对象是迭代器
何实现了 __enter__() 和 __exit__() 方法的对象都可称之为上下文管理器
‘’‘’‘’‘’‘’‘’‘’‘
python中为一个类实现某个特性的,不需要继承某一个类或使用一个接口,只要在其内部指定的魔法函数即可(鸭子类型在python中的使用),不关注对象的本身,只关注它的行为
class Cat(object): def say(self): print("i am a cat") class Dog(object): def say(self): print("i am a fish") class Duck(object): def say(self): print("i am a duck") animal_list = [Cat, Dog, Duck] for animal in animal_list: animal().say()
在python中的魔法函数就是使用了鸭子类型,我们可以在任意一个类中使用python为我们提供的魔法函数,python在调用他们时触发的条件都是统一的
extend用于两个可迭代对象的拼接,查看源码我们可以知道,我们需要传入一个可迭代的对象

大多数我们使用是这样的
a = ["bobby1", "bobby2"] b = ["bobby2", "bobby"] a.extend(b)
既然是一个可迭代的对象,那么我们在类中定义__getitem__方法后那么这个类也就编程了一个可迭代的对象,所有extend也就可以拼接这个类的时候就会触发其内部的__getitem__方法
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __getitem__(self, item):
return self.employee[item]
company = Company(["tom", "bob", "jane"])
a = ["bobby1", "bobby2"]
a.extend(company)
print(a)
输出结果如下

抽象基类(abc模块)
用途:
1 可以判断一个类中有没有一个魔法方法
2 接口的强制规定
假如我们判断一个类中是否有__len__魔法方法 , 可以使用collections.abc中的Sized
class Company(object): def __init__(self, employee_list): self.employee = employee_list def __len__(self): return len(self.employee) com = Company(["bobby1","bobby2"]) from collections.abc import Sized print(isinstance(com, Sized))
输出结果
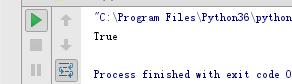
Sized的内部源码
class Sized(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __len__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
return _check_methods(C, "__len__")
return NotImplemented
当然我们也可以使用简单的
isinstance判断一个对象是否属于某个类型
class A:
pass
class B:
pass
b = B()
print(isinstance(b, A))
使用抽象基类实现接口的强制规定
当我们在写一个类的时候,强制的让别人实现某个方法通常是这样写的
class CacheBase(): def get(self, key): raise NotImplementedError def set(self, key, value): raise NotImplementedError # class RedisCache(CacheBase): pass redis_cache = RedisCache() redis_cache.get("key")
这样加入用户在继承我们的类时,如果没有指定,我们要重写的方法,在调用的时候就会抛出异常写
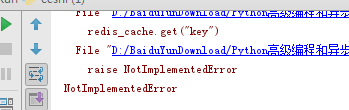
我们可以利用抽象的基类,在用户继承我们类的时候,如果没有指定我们要重写的方法,就给它抛出异常
import abc
from collections.abc import *
class CacheBase(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get(self, key):
pass
@abc.abstractmethod
def set(self, key, value):
pass
class RedisCache(CacheBase):
pass
redis_cache = RedisCache()
输出信息如下
isinstance 和 type的区别
isinstance 判断一个对象是否属于某个类型会根据这个对象的继承链去找,如果找到就返回True否则Flase
type()用来判断某个对象是属于那个类,它不会根据继承链向上找
class A: pass class B(A): pass b = B() print(isinstance(b, B)) print(isinstance(b, A)) print('='*40) print(type(b) is B) print(type(b) is A )
输出结果如下
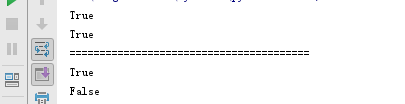
类变量和实例变量
class A:
aa = 1
def __init__(self, x, y):
self.x = x
self.y = y
a = A(2,3)
A.aa = 11
a.aa = 100
print(a.x, a.y, a.aa)
print(A.aa)
b = A(3,5)
print(b.aa)
输出结果如下

实例变量的查找顺序
1 在当前的实例中查找,如果没找到的话就会去类中获取同名的类变量
2 假如给一个实例变量动态的赋值一个和类变量同名的实例变量,不会修改类变量的值,只是动态的给自己增加一个实例变量而已
类变量是不能够向下查找的,因为对象是根据类创建的且每个对象的实例变量的值可能不同
类属性和实例属性以及查找的顺序(采用的是c3算法)
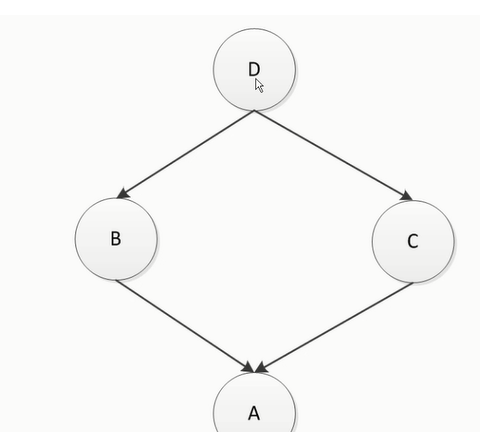
A继承B和C, B和C继承D查找顺序如下
class D:
pass
class C(D):
pass
class B(D):
pass
class A(B, C):
pass
print(A.__mro__)
输出结果如下

A继承B和C,B继承D,C继承E查找顺序如下
#新式类
class D:
pass
class E:
pass
class C(E):
pass
class B(D):
pass
class A(B, C):
pass
print(A.__mro__)
输出结果如下

类方法,静态方法和实例方法
所谓静态方法就相当于将需要外部调用的方法集成到类的内部,将命名空间并入到类中,不能在内部调用实例变量和实例方法。静态方法的缺陷是函数内return语句要调用类的名字,如果类的名字变化,静态方法也要修改,也就是通常说的硬编码
类方法相比静态方法,不在需要硬编码了(即返回一个对象只需cls()),不能在内部调用实例变量和实例方法
实例方法就很简单了,使用实例+方法+()即可
class Date:
#构造函数
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def tomorrow(self):
self.day += 1
@staticmethod
def parse_from_string(date_str):
year, month, day = tuple(date_str.split("-"))
return Date(int(year), int(month), int(day))
@staticmethod
def valid_str(date_str):
year, month, day = tuple(date_str.split("-"))
if int(year)>0 and (int(month) >0 and int(month)<=12) and (int(day) >0 and int(day)<=31):
return True
else:
return False
@classmethod
def from_string(cls, date_str):
year, month, day = tuple(date_str.split("-"))
return cls(int(year), int(month), int(day))
def __str__(self):
return "{year}/{month}/{day}".format(year=self.year, month=self.month, day=self.day)
if __name__ == "__main__":
new_day = Date(2018, 12, 31)
new_day.tomorrow()
print(new_day)
#2018-12-31
date_str = "2018-12-31"
year, month, day = tuple(date_str.split("-"))
new_day = Date(int(year), int(month), int(day))
print (new_day)
#用staticmethod完成初始化
new_day = Date.parse_from_string(date_str)
print (new_day)
#用classmethod完成初始化
new_day = Date.from_string(date_str)
print(new_day)
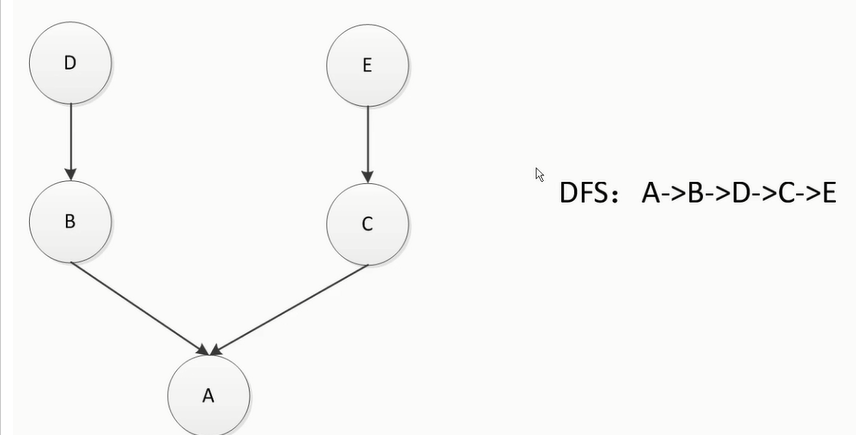
print(Date.valid_str("2018-12-32"))
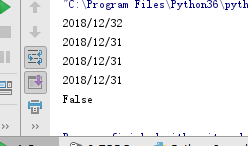
输出结果如下
数据封装和私有属性
私有属性:
class Date:
#构造函数
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def __str__(self):
return "{year}/{month}/{day}".format(year=self.year, month=self.month, day=self.day)
class User:
def __init__(self, birthday):
self.__birthday = birthday
def get_age(self):
return 2018 - self.__birthday.year
if __name__ == "__main__":
user = User(Date(1990, 2, 1))
print(user.get_age())
print(user._User__birthday)
输出结果如下

python对象的自省机制
自省机制:也就是通过一些方法查询对象的内部结构
说明:
#自省是通过一定的机制查询到对象的内部结构 from chapter04.class_method import Date class Person: """ 人 """ name = "user" class Student(Person): def __init__(self, scool_name): self.scool_name = scool_name if __name__ == "__main__": user = Student("学校") #通过__dict__查询属性 print(user.__dict__) user.__dict__["school_addr"] = "北京市" print(user.school_addr) print(Person.__dict__) print(user.name) a = [1,2] print(dir(a))
输出结果如下

super函数真的就是调用父类吗
既然我们重写了继承的构造函数, 为什么还要去调用super?
这样我们就可以用到父类的和我们自己的方法,如果不调用super那么只能用我们自己的
super到底执行顺序是什么样的?
执行的顺序和类的查找 __mro__顺序一样
class A:
def __init__(self):
print ("A")
class B(A):
def __init__(self):
print ("B")
super().__init__()
class C(A):
def __init__(self):
print ("C")
super().__init__()
class D(B, C):
def __init__(self):
print ("D")
super(D, self).__init__()
if __name__ == "__main__":
print(D.__mro__)
d = D()
输出结果如下

Mixin继承案例 django restframework
class GoodsListViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet):
"""
商品列表页, 分页, 搜索, 过滤, 排序
"""
# throttle_classes = (UserRateThrottle, )
queryset = Goods.objects.all()
serializer_class = GoodsSerializer
pagination_class = GoodsPagination
# authentication_classes = (TokenAuthentication, )
filter_backends = (DjangoFilterBackend, filters.SearchFilter, filters.OrderingFilter)
filter_class = GoodsFilter
search_fields = ('name', 'goods_brief', 'goods_desc')
ordering_fields = ('sold_num', 'shop_price')
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
instance.click_num += 1
instance.save()
serializer = self.get_serializer(instance)
return Response(serializer.data)
在这个类中,一个类可以完成商品列表页, 分页, 搜索, 过滤, 排序,
mixins.ListModelMixin源码 我们可以看到实现的功能单一
class ListModelMixin(object):
"""
List a queryset.
"""
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
Mixin其实和普通的多继承是本质一样的,但是Mixin有以下特点:
① Minin里面功能比较单一,尽量简化
② 不和我们真正的类一样,不和基类关联,可以和任意基类组合,基类不和Mixin关联就能初始化成功,Minin只是定义了一个方法
③ Minin中不要使用super的方法,因为super会根据mro算法去调用他的方法,因为尽量不要和基类关联
④ 命名尽量使用Mixin结尾(约定俗成)
上下文管理器
里面包括两个魔法函数__enter__和__exit__
__enter__():主要执行一些环境准备工作,同时返回一资源对象。如果上下文管理器open("test.txt")的__enter__()函数返回一个文件对象。
__exit__():完整形式为__exit__(type, value, traceback),这三个参数分别为异常类型、异常信息和堆栈。如果执行体语句没有引发异常,则这三个参数均被设为None。否则,它们将包含上下文的异常信息。__exit_()方法返回True或False,分别指示被引发的异常有没有被处理,如果返回False,引发的异常将会被传递出上下文。如果__exit__()函数内部引发了异常,则会覆盖掉执行体的中引发的异常。处理异常时,不需要重新抛出异常,只需要返回False,with语句会检测__exit__()返回False来处理异常。
class Sample:
def __enter__(self):
print ("enter")
#获取资源
return self
def __exit__(self, exc_type, exc_val, exc_tb):
#释放资源
print ("exit")
def do_something(self):
print ("doing something")
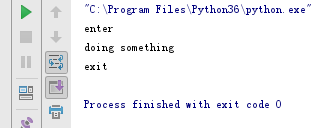
with Sample() as sample:
sample.do_something()
输出结果如下
contextlib简化上下文管理器
其中yield上面的print相当于__enter__,下面的print相当于__exit__
import contextlib
@contextlib.contextmanager
def file_open(file_name):
print ("file open")
yield {} # 返回一个空字典,可以不返回
print ("file end")
with file_open("bobby.txt") as f_opened:
print ("file processing")
f_opened['name'] = 'zhang'
print(f_opened)
输出结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号