

redis实战笔记(1)-第1章 初识Redis
第1章 初识Redis
注:本书在redis3.0版本的,比如redis3.0以后支持服务端集群。3.0之前只能客户端分片。
本章主要内容
1.Redis与其他软件的相同之处和不同之处
2.Redis的用法
3.使用Python示例代码与Redis进行简单的互动
4.使用Redis解决实际问题
Redis是一个远程内存数据库, 它不仅性能强劲, 而且还具有复制特性以及为解决问题而生的独一无二的数据模型。 Redis提供了 5种不同类型的数据结构, 各式各样的问题都可以很自 然地映射到这些数据结构上: Redis的数据结构致力于帮助用户解决问题, 而不会像其他数据库那样, 要求用户扭曲问题来适应数据库。 除此之外, 通过复制、 持久化( persistence) 和客户端分片( client-side sharding) 等特性, 用户可以很方便地将Redis扩展成一个能够包含数百GB数据、 每秒处理上百万次请求的系统。
笔者第一次使用Redis是在一家公司里面, 这家公司需要对一个保存了 6万个客户联系方式的关系数据库进行搜索, 搜索可以根据名字、 邮件地址、 所在地和电话号码来进行, 每次搜索需要花费10~15秒的时间。 在花了一周时间学习 Redis的基础知识之后, 我使用Redis重写了一个新的搜索引 擎, 最终这个新的搜索系统不仅可以根据名字、 邮件地址、所在地和电话号码等信息来过滤和排序客户联系方式, 并且每次操作都可以在50毫秒之内完成, 这比原来的搜索系统足足快了 200 倍。
1.1 Redis简介
Redis是一个速度非常快的非关系数据库( non-relational database) , 它可以存储键( key) 与5种不同类型的值( value) 之间的映射( mapping) , 可以将存储在内存的键值对数据持久化到硬盘, 可以使用复制特性来扩展读性能, 还可以使用客户端分片①来扩展写性能, 接下来的几节将分别介绍Redis的这几个特性。
1.1.1 Redis与其他数据库和软件的对比
如果你熟悉关系数据库, 那么你肯定写过用来关联两个表的数据的SQL查询。 而Redis则属于人们常说的NoSQL数据库或者非关系数据库: Redis不使用表, 它的数据库也不会预定义或者强制去要求用户对Redis存储的不同数据进行关联。
memcached对比
两者都可用于存储键值映射, 彼此的性能也相差无几, 但是Redis能够自 动以两种不同的方式(AOF和RDB)将数据写入硬盘, 并且Redis除了能存储普通的字符串键之外, 还可以存储其他4种数据结构, 而memcached只能存储普通的字符串键。
这些不同之处使得Redis可以用于解决更为广泛的问题, 并且既可以用作主数据库( primary database) 使用, 又可以作为其他存储系统的辅助数据库( auxiliary database) 使用。
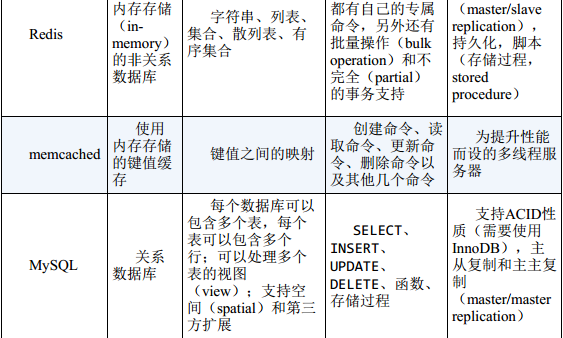
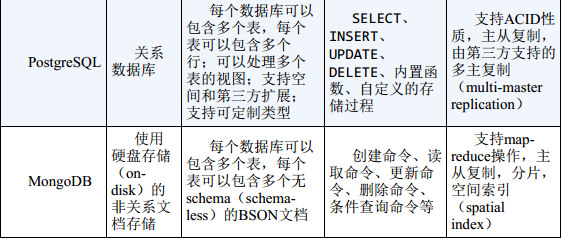
表1-1 一些数据库和缓存服务器的特性与功能

1.1.2 附加特性
在使用类似Redis这样的内存数据库时, 一个首先要考虑的问题就是“当服务器被关闭时, 服务器存储的数据将何去何从呢?
”Redis拥有两种不同形式的持久化方法, 它们都可以用小而紧凑的格式将存储在内存中的数据写入硬盘:
第一种(快照)持久化方法为时间点转储( point-in-timedump) , 转储操作既可以在“指定时间段内有指定数量的写操作执行”这
一条件被满足时执行, 又可以通过调用两条转储到硬盘( dump-todisk) 命令中的任何一条来执行;
第二种(AOF)持久化方法将所有修改了数据库的命令都写入一个只追加( append-only) 文件里面, 用户可以根据数据的重要程度, 将只追加写入设置为从不同步( sync) 、 每秒同步一次或者每写入一个命令就同步一次。 我们将在第4章中更加深入地讨论这些持久化选项。
另外, 尽管Redis的性能很好, 但受限于Redis的内存存储设计, 有时候只使用一台Redis服务器可能没有办法处理所有请求。 因此, 为了扩展Redis的读性能, 并为Redis提供故障转移( failover) 支持,
Redis实现了主从复制特性: 执行复制的从服务器会连接上主服务器, 接收主服务器发送的整个数据库的初始副本( copy) ; 之后主服务器执行的写命令, 都会被发送给所有连接着的从服务器去执行, 从而实时地更新从服务器的数据集。 因为从服务器包含的数据会不断地进行更新, 所以客户端可以向任意一个从服务器发送读请求, 以此来避免对主服务器进行集中式的访问。 我们将在第4章中更加深入地讨论Redis从服务器。
1.2 Redis数据结构简介
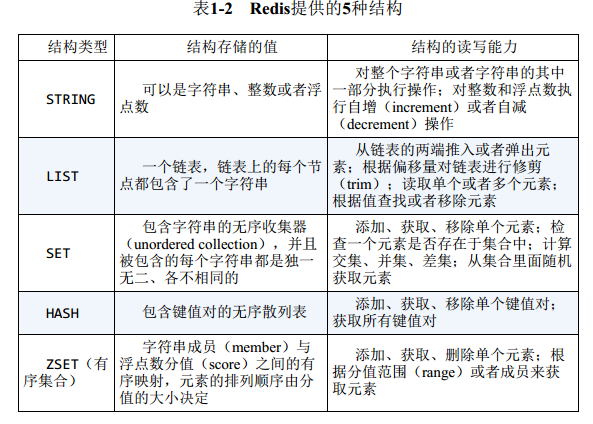
Redis可以存储键与5种不同数据结构类型之间的映射, 这5种数据结构类型分别为STRING(字符串) 、 LIST(列表) 、 SET(集合) 、 HASH(散列) 和ZSET(有序集合) 。 有一部分Redis命令对于这5种结构都是通用的, 如DEL、 TYPE、 RENAME等
1.2.1 Redis中的字符串
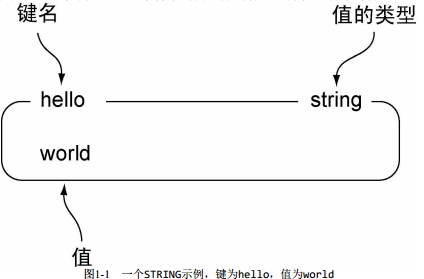
图1-1以键
为hello、 值为world的字符串为例, 分别标记了方框的各个部分。

1.2.2 Redis中的列表
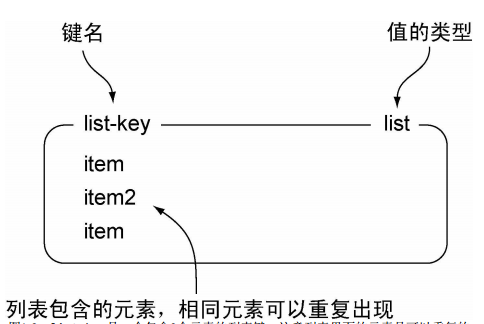

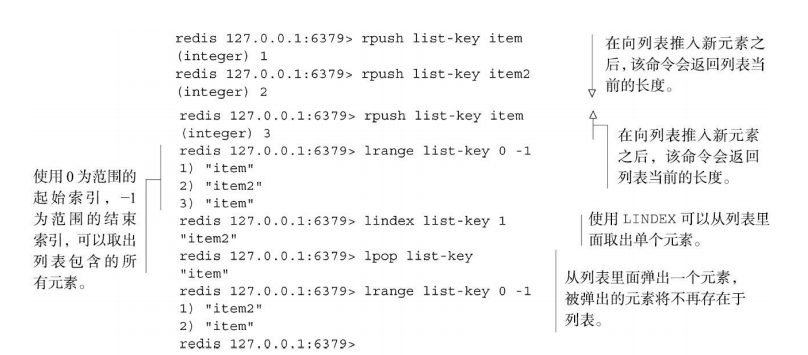
Redis列表还拥有从列表里面移除元素的命令、 将元素插入列表中间的命令、 将列表修剪至指定长度(相当于从列表的其中一端或者两端移除元素) 的命令, 以及其他一些命令。
1.2.3 Redis的集合
Redis 的集合和列表都可以存储多个字符串, 它们之间的不同在于,列表可以存储多个相同的字符串, 而集合则通过使用散列表来保证自 己存储的每个字符串都是各不相同的
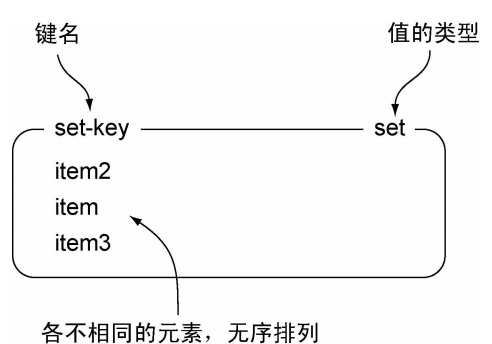
因为Redis的集合使用无序( unordered) 方式存储元素, 所以用户不能像使用列表那样, 将元素推入集合的某一端, 或者从集合的某一端弹出元素。 不过用户可以使用SADD命令将元素添加到集合, 或者使用SREM命令从集合里面移除元素。 另外还可以通过SISMEMBER命令快速地检查一个元素是否已经存在于集合中, 或者使用SMEMBERS命令获取集合包含的所有元素(如果集合包含的元素非常多, 那么SMEMBERS命令的执行速度可能会很慢, 所以请谨慎地使用这个命令) 。


集合除了基本的添加操作和移除操作之外,还支持很多其他操作, 比如SINTER、 SUNION、 SDIFF这3个命令就可以分别执行常见的交集计算、 并集计算和差集计算
1.2.4 Redis的散列
和字符串一样, 散列存储的值既可以是字符串又可以是数字值, 并且用户同样可以对散列存储的数字值执行自 增操作或者自 减操作
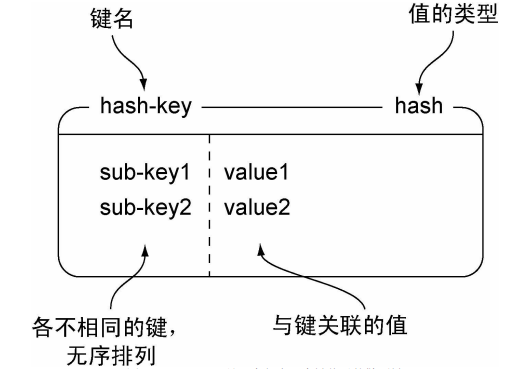
散列在很多方面就像是一个微缩版的Redis, 不少字符串命令都有相应的散列版本

熟悉文档数据库的读者可以将Redis的散列看作是文档数据库里面的文档, 而熟悉关系数据库的读者则可以将Redis的散列看作是关系数据库里面的行, 因为散列、 文档和行这三者都允许用户同时访问或者修改一个或多个域( field) 。
1.2.5 Redis的有序集合
有序集合和散列一样, 都用于存储键值对: 有序集合的键被称为成员( member) , 每个成员都是独各不相同; 而有序集合的值则被称为分值( score) , 分值必须为浮点数。
有序集合是Redis里面唯一一个既可以根据成员访问元素(这一点和散列一样) , 又可以根据分值以及分值的排列顺序来访问元素的结构
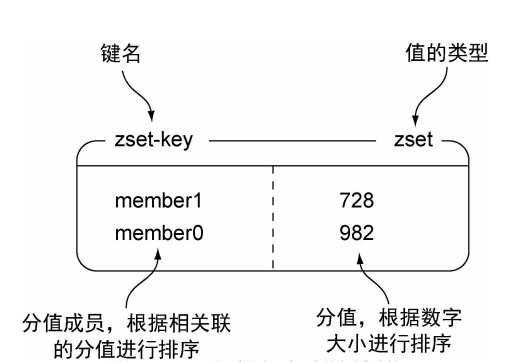
和Redis的其他结构一样, 用户可以对有序集合执行添加、 移除和获取等操作,

代码清单1-5 ZADD、 ZRANGE、 ZRANGEBYSCORE和ZREM的使用示例

1.3 你好Redis
如何使用Redis来构建一个简单的文章投票网站的后端。
小结
本章希望向读者传达这样一个概念: Redis是一个可以用来解决问题的工具
1.它既拥有其他数据库不具备的数据结构, 又拥有内存存储(这使得Redis的速度非常快) 、远程(这使得Redis可以与多个客户端和服务器进行连接) 、
2.持久化(这使得服务器可以在重启之后仍然保持重启之前的数据)
3.可扩展(通过主从复制和分片) 等多个特性, 这使得用户可以以熟悉的方式为各种不同的问题构建解决方案。
① 分片是一种将数据划分为多个部分的方法, 对数据的划分可以基于键包含的ID、 基于键的散列值, 或者基于以上两者的某种组合。 通过对数据进行分片, 用户可以将数据存储到多台机器里面, 也可以从多台机器里面获取数据, 这种方法在解决某些问题时可以获得线性级别的性能提升。
② 客观来讲, memcached也能用在这个简单的场景里, 但使用Redis存储聚合数据有以下3个好处: 首先, 使用Redis可以将彼此相关的聚合数据放在同一个结构里面, 这样访问聚合数据就会变得更为容易;其次, 使用Redis可以将聚合数据放到有序集合里面, 构建出一个实时的排行榜; 最后, Redis的聚合数据可以是整数或者浮点数, 而memcached的聚合数据只能是整数。

