
Prometheus之入门
官方文档资料:https://prometheus.io/docs/introduction/overview/
一、Prometheus是什么?
Prometheus 是由 SoundCloud 构建的开源监控告警解决方案
1.1、结构图 (先上图比较直观)
Prometheus本身是一个以进程方式启动,之后以多进程和多线程实现监控数据收集、计算、查询、更新、存储的这样一个C/S模型运行模式。

1.1.1、Prometheus server
Prometheus server 根据配置定时去抓取或拉取各个节点暴露的时间序列数据来工作,默认使用的拉取方式是pull,也可以使用pushgateway提供的push方式获取各个监控节点的时间序列数据。将获取到的数据均以metric形式存入TSDB,一款时序型数据库。此时prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。它的报警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和发送报警的一个组件。prometheus原生的图标功能过于简单,可将prometheus数据接入grafana,由grafana进行统一管理。
prometheus数据模型:
Prometheus收集时间序列数据,为了处理这些数据,它使用一个多维时间序列数据模型。这个时间序列数据模型结合了时间序列名称(metric)和称为标签(label)的键/值对,每个时间序列由时间序列名称和标签的组合唯一标识。时间序列的真实值是采样(sample)的结果,它包括两部分:一个float64类型的数值;一个毫秒精度的时间戳
Metric类型:
-
Counter: 一种累加的metric,如请求的个数,累计访问量、出现的错误数(计数器,可被清理,只增不减) -
Gauge: 常规的metric,如温度,可任意加减。其为瞬时的,与时间没有关系的,可以任意变化的数据 。内存、硬盘余量等 -
Histogram: 柱状图,用于观察结果采样,分组及统计,如:请求持续时间,响应大小。其主要用于表示一段时间内对数据的采样,并能够对其指定区间及总数进行统计。 -
Summary: 类似Histogram,用于表示一段时间内数据采样结果,其直接存储quantile数据,而不是根据统计区间计算出来的。不需要计算,直接存储结果
prometheus存储(local storage):
prometheus是把时间序列数据,以一种自定义的格式存储在本地硬盘上
prometheus的本地TS数据库以每两小时为间隔来分block(块)存储,每一个块中又分为多个chunk文件,chunk文件是用来存放采集过来的TS数据
index 文件是对metrics和 labels进行索引后存储在chunk中,chunk是作为存储的基本单位,index and metadata是作为子集。
prometheus平时是将采集过来的数据先都存放在内存之中(prometheus对内存的消耗还是不小的)以类似缓存的方式用于加快搜索和访问。
当出现宕机时,prometheus有一种保护机制叫做WAL,可以将数据定期存入硬盘中,以Chunk来表示,并在重新启动时,用以恢复进内存
远程存储集成(remote storage)
普罗米修斯的本地存储在其可扩展性和耐用性方面受到单个节点的限制。但是普罗米修斯没有试图解决其自身的集群存储问题,而是拥有一组允许与远程存储系统集成的接口。(read/write)
Prometheus支持两种类型的远程存储集成:
可以将指标样本写入远程目标;
可以从远程目标读取指标样本。
远程存储协议使用基于HTTP的Snappy压缩协议缓冲编码,在Prometheus中通过remote_write块和remote_read块进行配置
目前,Prometheus支持各种用于写入和读取的端点:(官网:https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage)
Prometheus服务发现:(解决集群监控目标多变、比如容器和基于云的实例的动态集群等)
三种方式:
从配置管理工具生成的文件中接收目标列表;查询API以获取目标列表;使用DNS记录以返回目标列表。
1.1.2、采集客户端
客户端主要有两种方式采集数据:
- pull 主动拉取的形式;客户端(被监控机器)先安装各类已有exporter(由社区或企业、开发的监控客户端插件)在系统上,exporters以守护进程的模式运行并开始采集数据。exporter本身也是一个http_server可以对http请求作出响应,返回数据。prometheus用pull这种主动拉取的方式(Http get)去访问每个节点上exporter并采集回需要的数据。
- push 被动推送的形式;在客户端(或者服务端)安装官方提供的Pushgateway插件,然后运行自己开发的各种脚本,把监控数据组织成k-v的形式(metrics)形式,发送给pushgateway之后,pushgateway再推送给prometheus
1.1.3、promQL
rate( node_network_receive_bytes[1m] ) #获取1分钟内每秒的增量increase(node_cpu[1m]) #获取CPU总使用时间1分钟的增量sum( increase(node_cpu{mode='idle'}[1m]) )sum( increase(node_cpu{mode='idle'}[1m]) ) by (instance) #每台服务器空闲CPU一分钟增量topk(3,increase(node_network_receive_bytes[20m])) #20分钟内网卡下载的前3排名v中每个时间系列元素的第一个和最后一个值之间的差值。示例:如果未来2小时后磁盘使用率为负数就触发报警,predict_linear( node_filesystem_free_bytes{mountpoint="/"}[1h],2*3600 ) < 0 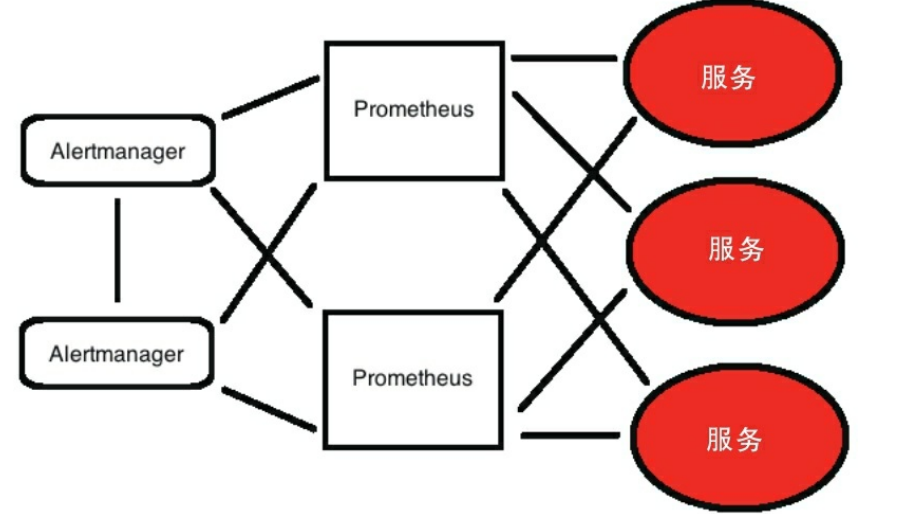

 浙公网安备 33010602011771号
浙公网安备 33010602011771号