Python基础之(装饰器,迭代器、生成器)
一、装饰器
1.1、什么是装饰器?
装饰器本质上就是一个python函数,他可以让其他函数在不需要做任何代码变动的前提下,增加额外的功能,装饰器的返回值也是一个函数对象。
1.2、装饰器的原则
- 不修改被装饰对象的源代码
- 不修改被装饰对象的调用方式
1.3、装饰器的目标
在遵守装饰器原则的前提下,为被装饰对象添加上新功能
1.4、装饰器应用场景:插入日志,性能测试,事务处理,缓存等等
1.5、装饰器的形成过程
现在有一个需求,需要在不改变原函数代码的情况下去计算这个函数的执行时间
import time
def fun():
time.sleep(1)
print("hello world")
def timer(f):
def inner():
start = time.time()
f()
end = time.time()
print("run time is %s"%(end-start))
return inner
fun = timer(fun)
fun()
执行结果:

如果有多个函数想让你测试他们的执行时间,每次是不是都得是:函数名=timer(函数名),这样还是有点麻烦,所以更简单的方法就是Python提供的语法糖
import time
def timer(f):
def inner():
start = time.time()
f()
end = time.time()
print("run time is %s"%(end-start))
return inner
@timer #语法糖
def fun():
time.sleep(1)
print("hello world")
fun()
刚刚我们讨论的装饰器都是装饰不带参数的函数,现在要装饰一个带参数的函数怎么办呢?
import time
def timer(f):
def inner(*args,**kwargs):
start = time.time()
f(*args,**kwargs)
end = time.time()
print("run time is %s"%(end-start))
return inner
@timer #语法糖
def fun(a):
print(a)
time.sleep(1)
print("hello world")
@timer
def fun1(a,b):
print(a,b)
fun(1)
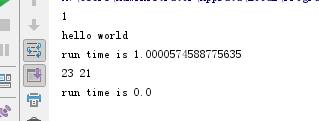
fun1(23,21)
执行结果:
上面的装饰器已经非常完美了,但是有我们正常情况下查看函数信息的方法在此处都会失效:
def fun():
'''in the fun'''
print('from fun')
print(fun.__doc__) #查看函数注释的方法
print(fun.__name__) #查看函数名的方法
解决方法:
from functools import wraps
def demo(func):
@wraps(func) #加在最内层函数正上方
def wrapper(*args,**kwargs):
return func(*args,**kwargs)
return wrapper
@demo
def fun():
'''in the fun'''
print('from fun')
print(fun.__doc__)
print(fun.__name__)
1.6、带参数的装饰器
假如你有500个函数使用了一个装饰器,现在你需要把这些装饰器都取消掉,你要怎么做?过两天你又需要加上...
import time
flag=False #通过flag的值来判断是否进行装饰
def fun(flag):
def demo(func):
def inner(*args,**kwargs):
if flag:
start=time.time()
func(*args,**kwargs)
end=time.time()
print("run time is %s"%(end-start))
else:
func(*args,**kwargs)
return inner
return demo
@fun(flag)
def fun1():
time.sleep(0.1)
print("welocme you")
fun1()
登录认证例子:
user = "crazyjump"
passwd = "123"
def auth(auth_type):
def func(f):
def wrapper(*args, **kwargs):
if auth_type == "local":
username = input("Username:").strip()
password = input("Password:").strip()
if user == username and passwd == password:
print("\033[32;1mlogin successful\033[0m")
f()
else:
exit("\033[31;1mInvalid username or password\033[0m")
elif auth_type == "ldap":
f()
print("不会")
return wrapper
return func
@auth(auth_type="local")
def crazyjump():
print("welcome to crazyjump")
crazyjump()
1.7、多个装饰器装饰一个函数
fun1和fun2的加载顺序:自下而上
inner函数的执行顺序为:自上而下
def fun1(func):
def inner():
print('fun1 ,before')
func()
print('fun1 ,after')
return inner
def fun2(func):
def inner():
print('fun2 ,before')
func()
print('fun2 ,after')
return inner
@fun2
@fun1
def f():
print('in the f')
f()
执行结果:

1.8、开放封闭原则
- 对扩展是开放的
为什么要对扩展开放呢?
我们说,任何一个程序,不可能在设计之初就已经想好了所有的功能并且未来不做任何更新和修改。所以我们必须允许代码扩展、添加新功能。
- 对修改是封闭的
为什么要对修改封闭呢?
就像我们刚刚提到的,因为我们写的一个函数,很有可能已经交付给其他人使用了,如果这个时候我们对其进行了修改,很有可能影响其他已经在使用该函数的用户。
装饰器完美的遵循了这个开放封闭原则。
二、迭代器
2.1、可迭代对象
可迭代对象指的是内置有__iter__方法的对象,即obj.__iter__,如:
from collections import Iterable
li = [1, 2, 3, 4]
tu = (1, 2, 3, 4)
di = {1: 2, 3: 4}
se = {1, 2, 3, 4}
print(isinstance(se, Iterable)) #判断是否是可迭代对象
print(isinstance(di, Iterable))
print(isinstance(tu, Iterable))
print(isinstance(li, Iterable))
执行结果:

字符串、列表、元组、字典、集合都可以被for循环,说明他们都是可迭代的,我们现在所知道:可以被for循环的都是可迭代的,要想可迭代,内部必须有一个__iter__方法。(查看内部方法dir(obj))
2.2、迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。迭代器必须有__iter__方法和__next__方法。将可迭代对象转化成迭代器。(可迭代对象.__iter__())
from collections import Iterator li = [1,2,3,4] list_iter = li.__iter__() # 将可迭代的转化成迭代器 print(isinstance(list_iter,Iterator)) #判断是否是迭代器,结果为True
看个例子:
from collections import Iterable
from collections import Iterator
class a():
def __next__(self):pass
def __iter__(self):pass #为a定义两个方法
dd=a() #实例化
print(isinstance(dd, Iterator))
print(isinstance(dd, Iterable))
#结果都为True,如果去掉__next__方法即第一个结果为False
#迭代器对象一定是可迭代对象,而可迭代对象不一定是迭代器对象
2.3、for循环
for循环,能遍历一个可迭代对象,他的内部到底进行了什么?
- 将可迭代对象转化成迭代器。(可迭代对象.__iter__())
- 内部使用__next__方法,一个一个取值。
- 加了异常处理功能,取值到底后自动停止。
用while循环模拟for循环
l=[1,2,3,4]
ss=l.__iter__()
while 1:
try:
print(ss.__next__())
except Exception as e:
break
执行结果:

对于序列类型:字符串、列表、元组,我们可以使用索引的方式迭代取出其包含的元素。但对于字典、集合、文件等类型是没有索引的,怎样取出其内部包含的元素?而for循环就是基于迭代器协议提供了一个统一的可以遍历所有对象的方法,即在遍历之前,先调用对象的__iter__方法将其转换成一个迭代器,然后使用迭代器协议去实现循环访问,这样所有的对象就都可以通过for循环来遍历了,而且你看到的效果也确实如此,这就是无所不能的for循环,最重要的一点,转化成迭代器,在循环时,同一时刻在内存中只出现一条数据,极大限度的节省了内存。
#基于for循环,我们可以完全不再依赖索引去取值了
dic={'a':1,'b':2,'c':3}
for k in dic:
print(dic[k])
2.4、迭代器优缺点:
优点:
- 提供一种统一的、不依赖于索引的迭代方式
- 惰性计算,节省内存
缺点:
- 无法获取长度(只有在next完毕才知道到底有几个值)
- 一次性的,只能往后走,不能往前退
三、生成器
本质:迭代器(所以自带了__iter__方法和__next__方法,不需要我们去实现)
特点:惰性运算节省内存,开发者自定
Python中提供的生成器:
- 生成器函数:常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
- 生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
3.1、生成器函数
包含yield关键字的函数就是一个生成器函数。yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束。
def fun():
a=123
yield a
b=456
yield b
ret=fun()
print("ret:",ret) #ret为生成器
print("1:",next(ret)) #返回第一个yield结果
print("2:",next(ret)) #返回第二个yield结果 next()等同__next__()
执行结果:

生成器有什么好处呢?就是不会一下子在内存中生成太多数据。
例如:假设你需要去工厂订购10000000台苹果手机,工厂应该是先答应下来然后再去生产,你可以一台一台的取,也可以根据需要一批一批的找工厂拿。而不能是一说要生产10000000台苹果手机,工厂就立刻生产出10000000台苹果手机,这样工厂的工人和生产线肯定都是要爆掉的.....
def produce():
"""生产手机"""
for i in range(1,10000000):
yield "生产了第%s台手机"%i
ret = produce()
print(ret.__next__()) #要第一台手机
print(ret.__next__()) #第二台手机
print(ret.__next__()) #再要一台手机
count = 0
for i in ret: #要一批手机,比如6台
print(i)
count +=1
if count == 6:
break
执行结果:

send传值
import time
def consumer(name):
print("%s 准备生产手机了!" %name)
while True:
iPhone = yield
print("[%s]被[%s]生产出来了!" %(iPhone,name))
def producer():
c = consumer('A')
c2 = consumer('B')
c.__next__()
c2.__next__()
print("开始生产手机了!")
for i in range(10):
time.sleep(1)
c.send(i)
c2.send(i) #传值给yield
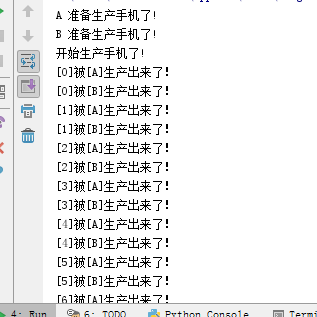
producer()
#send 获取下一个值的效果和next基本一致
#只是在获取下一个值的时候,给上一yield的位置传递一个数据
#使用send的注意事项
# 第一次使用生成器的时候 是用next获取下一个值
# 最后一个yield不能接受外部的值
执行结果:
3.2、生成器表达式
3.2.1、三元表达式
name="jump" res='SB' if name == 'crazyjump' else 'xxx' print(res) #结果xxx
3.2.2、列表推导式
j=[i for i in range(10) if i >5] #没有else print(j)
执行结果:

3.2.3、生成器表达式
j=(i for i in range(10) if i >5) print(next(j)) print(j)
执行结果:
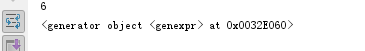
- 把列表推导式的[]换成()得到的就是生成器表达式
- 列表推导式与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号