
poj 2528 Mayor's posters (线段树 + 离散化)
Mayor's posters
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 34372 | Accepted: 9954 |
Description
The citizens of Bytetown, AB, could not stand that the candidates in the mayoral election campaign have been placing their electoral posters at all places at their whim. The city council has finally decided to build an electoral wall for placing the posters and introduce the following rules:
- Every candidate can place exactly one poster on the wall.
- All posters are of the same height equal to the height of the wall; the width of a poster can be any integer number of bytes (byte is the unit of length in Bytetown).
- The wall is divided into segments and the width of each segment is one byte.
- Each poster must completely cover a contiguous number of wall segments.
Input
The first line of input contains a number c giving the number of cases that follow. The first line of data for a single case contains number 1 <= n <= 10000. The subsequent n lines describe the posters in the order in which they were placed. The i-th line among the n lines contains two integer numbers li and ri which are the number of the wall segment occupied by the left end and the right end of the i-th poster, respectively. We know that for each 1 <= i <= n, 1 <= li <= ri <= 10000000. After the i-th poster is placed, it entirely covers all wall segments numbered li, li+1 ,... , ri.
Output
For each input data set print the number of visible posters after all the posters are placed.
The picture below illustrates the case of the sample input.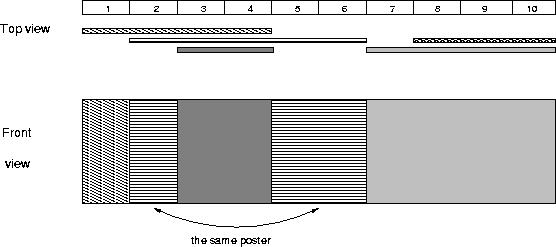
The picture below illustrates the case of the sample input.
Sample Input
1 5 1 4 2 6 8 10 3 4 7 10
Sample Output
4
【题解】:
数据大小:10000000 按这个数据建立线段树会超内存的
因为每次输入的数据量只有10000,想到离散化
离散化: 将输入的20000个 [li,ri] 存入hash数组进行排序,因为li<=ri,所以[li,ri]在hash数组的相对位置不会改变
例如下面数据:
1
3
1 10
1 3
6 10
存入hash数组{1,10,1,3,6,10}
排序:{1,1,3,6,10,10}
去掉重复的: { 1 , 3 , 6 , 10 }
| | | |
得到hash数组:{ 1 , 2 , 3 , 4 }
上面样例则变成了:
1 1
3 3
1 10 ==》 1 4
1 3 1 2
6 10 3 4
我想要说的是这题的测试数据有问题:上面这种做法原则上是错误的,但是能AC
1-10 [1 2 3 4 5 6 7 8 9 10] [1 2 3 4]
[1 2 3] [6 7 8 9 10] [1 2][3 4]
因为可以看到[4,5],所以
结果应该为3 结果为2
上面的hash法也能AC,说明测试数据水了
--------------------------------------------------可耻的分割线--------------------------------------------------------------
【精】下面提供一种完美解决方法:将数据的本身和它下一个值也同时加进hash数组 例如:[1,10] 加进hash的是[1,2,10,11]
例如下面数据:
1
3
1 10
1 3
6 10
存入hash数组{1,2,10,11,1,2,3,4,6,7,10,11}
排序:{1,1,2,2,3,4,6,,7,10,10,11,11}
去掉重复的: { 1 , 2 , 3 , 4 , 6 , 7 , 10 , 11 }
| | | | | | | |
得到hash数组:{ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 }
上面样例则变成了:
1 1
3 3
1 10 ==》 1 7
1 3 1 3
6 10 5 7
我想要说的是这题的测试数据有问题:上面这种做法原则上是错误的,但是能AC
1-10 [1 2 3 4 5 6 7 8 9 10] [1 2 3 4 5 6 7]
[1 2 3] [6 7 8 9 10] [1 2 3] [5 6 7]
因为可以看到[4,5],所以 可以看到[4,4]
结果应该为3 结果为3
得到相同结果,完美hash出来了,bingo!!!
【code】:
1 #include<iostream> 2 #include<stdio.h> 3 #include<string.h> 4 #include<algorithm> 5 6 #define N 10000010 7 #define M 20010 8 #define lson p<<1 9 #define rson p<<1|1 10 11 using namespace std; 12 13 struct Nod 14 { 15 int l,r; 16 int val; //颜色( 1 - m) 17 int flag; //[l,r]是否同色(1,0) 18 }node[M<<3]; 19 20 int ml[N],mr[N],mark[M<<3]; 21 22 int hash[N]; 23 24 int discrete(int n) 25 { 26 int temp[M<<3],tmp[M<<3]; 27 int k=0; 28 int i; 29 for(i=1;i<=n;i++) 30 { 31 scanf("%d%d",ml+i,mr+i); 32 temp[k++]=ml[i]; 33 temp[k++]=ml[i]+1; //将相邻的下一个加入(重要) 34 temp[k++]=mr[i]; 35 temp[k++]=mr[i]+1; 36 } 37 sort(temp,temp+k); //排序 38 int j=0; 39 tmp[0] = temp[0]; 40 for(i=1;i<k;i++) //去掉数组中重复的数 41 { 42 if(tmp[j]!=temp[i]) 43 tmp[++j]=temp[i]; 44 } 45 for(i=0;i<=j;i++) hash[tmp[i]]=i+1; //得到hash数组 46 return j+1; 47 } 48 49 void building(int l,int r,int p) //建树 50 { 51 node[p].l = l; 52 node[p].r = r; 53 node[p].val = 0; 54 node[p].flag = 1; 55 if(l==r) return; 56 int mid = (l+r)>>1; 57 building(l,mid,lson); 58 building(mid+1,r,rson); 59 } 60 61 void update(int l,int r,int val,int p) 62 { 63 if(node[p].l==l&&node[p].r==r||node[p].l==node[p].r) 64 { 65 node[p].val = val; 66 node[p].flag = 1; 67 return; 68 } 69 if(node[p].flag&&node[p].val!=val) //当[l,r]区间为纯色并且val值需要更新时 70 { 71 node[p].flag = 0; //区间同色标记取消 72 node[lson].flag = node[rson].flag = 1; //左右区间标记加上 73 node[lson].val = node[rson].val = node[p].val; //val值向下更新 74 } 75 int mid = (node[p].l+node[p].r)>>1; 76 if(r<=mid) update(l,r,val,lson); 77 else if(l>mid) update(l,r,val,rson); 78 else 79 { 80 update(l,mid,val,lson); 81 update(mid+1,r,val,rson); 82 } 83 if(node[lson].flag&&node[rson].flag&&node[lson].val==node[rson].val) //左右区间同色,同值,合并 84 { 85 node[p].flag = 1; 86 node[p].val = node[lson].val; 87 } 88 } 89 90 void query(int p,int t) 91 { 92 if(node[p].flag||node[p].l==node[p].r) //同色叶子即返回 93 { 94 mark[node[p].val] = t; //标记,最后统计用,用t标记省时(技巧) 95 return; 96 } 97 query(lson,t); 98 query(rson,t); 99 } 100 101 int main() 102 { 103 int t; 104 scanf("%d",&t); 105 while(t) 106 { 107 int n,i; 108 scanf("%d",&n); 109 int m = discrete(n); 110 building(1,m,1); 111 for(i=1;i<=n;i++) 112 { 113 update(hash[ml[i]],hash[mr[i]],i,1); 114 } 115 query(1,t); 116 int ans = 0; 117 for(i=1;i<=m;i++) 118 { 119 if(mark[i]==t) ans++; //统计 120 } 121 printf("%d\n",ans); 122 t--; 123 } 124 return 0; 125 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号