神经网络_2
代价函数
假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络层数,\(s_I\)表示每层的neuron个数,\(s_L\)表示最后一层(输出层)神经单元个数
神经网络可分为二分类和多分类情况
二分类:\(S_L = 1,y=0 \ or \ 1\)可以表示哪类
K分类:\(S_L=k,y_i=1\)表示分到第i类(K>2)
在逻辑回归中使用的代价函数如下
\(J(\theta) = - \frac{1}{m}[\sum_{j=1}^n \ y_{(i)}logh_\theta(x^{(i)})+(1-y^{(i)})log(1-h_\theta x^{(i)})]+\\\frac{\lambda}{2m} \ \sum_{j=1}^n \theta_j^2\)
可见逻辑回归中只有一个输出变量,标量(scalar),也只有一个应变量y,但是在神经网络中,我们可以有很多输出变量,\(h_\theta(x)\)是一个维度为k的向量,且训练集中的因变量也是同样维度 的一个向量,相比起来,代价函数比逻辑回归的代价函数更加复杂
\(h_\theta(x) \in R^K , \ (h_\theta(x))_i = i^{th}output\)
\(J(\theta) = - \frac {1}{m}[\sum_{i=1}^m \sum_{k=1}^ky_k^{(i)}log(h_\theta(x^{(i)})_k+(1-y_k^{(i)})log(1-(h_\theta(x^{(i)}))_k)]+\\\frac{\lambda}{2m}\sum^{L-1}_{l=1}\sum^{s_l}_{i=1}\sum^{s_{l+1}}_{j=1}(\theta^{(i)}_{ji})^2\)
代价函数的最终作用是一样的,用于观察算法预测结果和真实情况的误差大小,不同之处在于,对于神经网络,每一行特征都会给出k个预测,基本上我们可以利用循环对每行特征值都预测K个不同结果,然后在利用循环在K个预测中选择可能性最高的一个,与y中的实际数据进行比较。
正则化的那一项只是排除了每一层\(\theta_0\)后,每一层的\(\theta\)矩阵的和,最内层的循环j是遍历所有的行(由\(s_l+1\)层激活单元个数决定),循环i则遍历所有列,由该层(\(s_l层\))激活单元数所决定
对\(J(\theta)\)的理解,前半部分即交叉熵损失函数,\(\sum_{k=1}^k\)中的k为结果向量的长度 ,\(\sum_{i=1}^m\)中的m为样本集的数量,同逻辑回归相同,对于后半部分的正则化,则是所有特征矩阵的平方,联系神经网络图
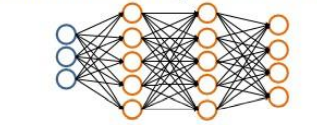
例如输入层3神经元,中间双层5神经元,输出层4神经元,可以知道的是,第一层是(3,1)向量,第二层是(5,1)向量,所以需要一个(5,3) 的特征矩阵实现输入层到第一隐含层的转变,即(5,3)*(3,1) = (5,1),第二层到第三层同理需要一个(5,5)特征矩阵,第三层到输出层需要一个(3,5)特征矩阵,以上三个特征矩阵实现了每层神经元之间的信息传递,实现了神经网络的功能。
反向传播算法
根据代价函数的表示,我们的最终目的是得到代价函数最小的特征矩阵,正向传播使我们得到了神经网络预测结果,但是为了修正结果,计算代价函数的偏导数\(\Huge \frac{\partial}{\partial \theta^{(l)}_{ij}} J(\Theta)\) ,我们需要一种方向传播方法,从最后一层的误差,一直反向求出各层的误差,一直到倒数第二层(不考虑输入层误差)
假如我们的训练集只有一个实例\((x^{(1)},y^{(1)})\),涉及到一个四层神经网络,K =4,\(S_L = 4,L=4\)
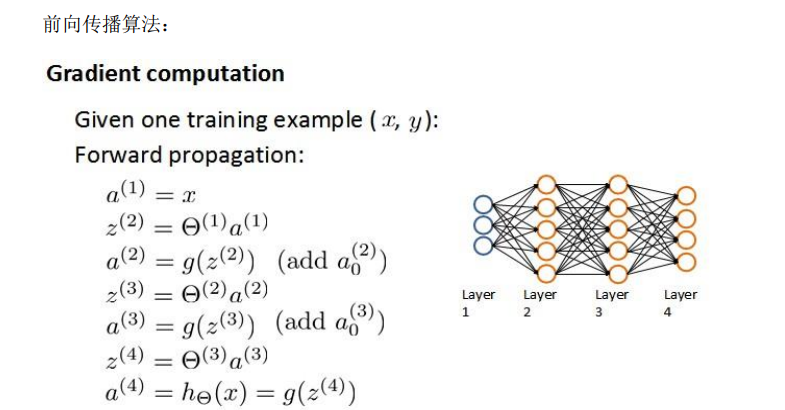
以上是前向传播的操作,每一层由上一层和特征矩阵求得并添加偏置神经元,后与后一层特征矩阵相乘得到下一层的神经元信息,一直到最后输出层。上图中是神经网络各层实际上也就对应着\(\Large a^{(i)}\)
由以上内容,我们从最后一层的误差开始计算,实际上是要求预测值\(a_k^{(4)}与实际值y^k\)之间的误差
这里我们使用\(\delta\)代表误差,即\(\Large \delta^{(4)} = a^{(4)} -y \qquad (1)\)
得到第四层的误差之后,用来计算前一层的误差
\(\Large \delta^{(3)} = (\Theta^{(3)})^T \delta^{(4)}.*g^{'}(z^{(3)})(.*代表点乘) \qquad (2)\) ,
其中\(\Large g^{'}(z^{(3)})\)是S形(图像上类似于逻辑函数从0到1的图像)函数的导数,实际上\(\Large g^{'}(z^{(3)}) = a^{(3)}*(1-a^{(3)})\)。\(\Large (\Theta^{(3)})^T \delta^{(4)}\)是参数权重导致的误差和
同理,计算第二步函数
\(\Large \delta^{(2)} = (\Theta^{(2)})^T \delta^{(3)}.*g^{'}(z^{(2)})(.*代表点乘) \qquad (3)\)
最后,第一层作为输入变量,不存在误差值,得到了所有误差之后,我们可以得到计算代价函数的偏导数,假设\(\lambda = 0\),也就是我们不做正则化处理的时候,存在\(\Large \frac{\part}{\part \Theta^{(l)}_{ij}}J(\Theta) = a^{(l)}_j\delta^{l+1}_i\) ,
该式子中l表示目前计算的层数,
j表示计算层中激活单元的下标,也就是下一次的第j个输入变量的下标
i表示下一层误差单元的下标,收到权重矩阵中第i行影响的下一层误差单元的下标
但是如果我们要考虑正则化处理,并且我们训练集是一个特征矩阵而非向量。在以上情况下,我们需要计算每一层的误差单元来计算代价函数的偏导数, 更加一般的情况下,我们同样需要计算每一层的误差单元,但是我们需要为整个训练集计算误差单元,此时的误差单元也是一个矩阵,我们用\(\Large\Delta^{(l)}_{ij}\)表示这个误差矩阵,第l层的第i个激活单元受到第j个参数影响而导致误差
算法表示为

根据上图我们可知,首先使用正向传播方法计算出每一层的激活单元\(\Large a^{(l)}\),再利用训练集中的结果和神经网络预测的结果求出最后一层的误差,然后利用该误差使用反向传播法计算出除了输入层的每一层的所有误差
在求出了\(\Large \Delta^{(l)}_{ij}\),我们可以计算代价函数的偏导数了,如下
\(\Large D_{ij}^{(l)} := \frac{1}{m}\Delta_{ij}^{(l)} + \lambda \Theta^{(l)}_{ij} \quad if \quad j \ne 0\)
\(\Large D_{ij}^{(l)} := \frac{1}{m}\Delta_{ij}^{(l)} \quad if \quad j = 0\)
反向传播算法直观理解
重温一下前向传播算法
由传入的\(x^{(i)}\)计算得到 \(z^{(i)}\)并通过激活函数非线性化为\(a^{(i)}\) ,在每层之间同等操作后得到输出结果a
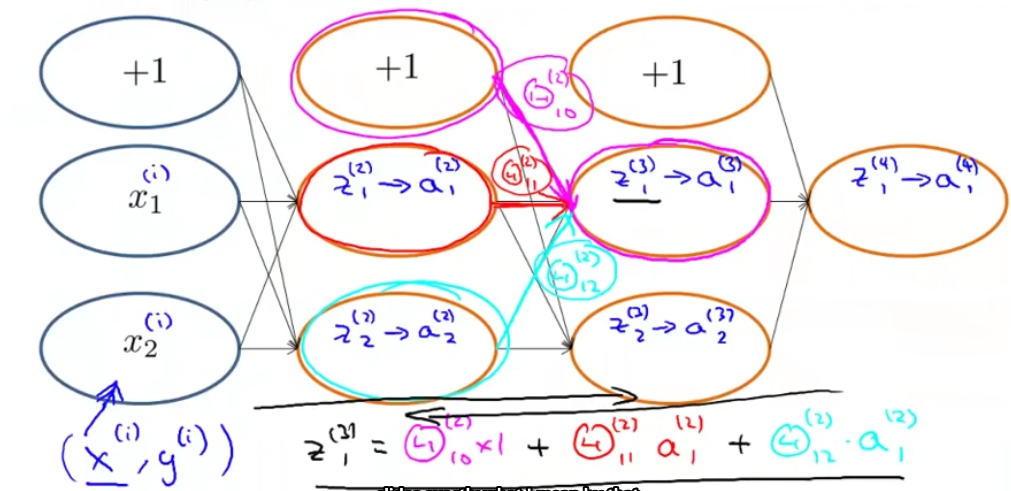
回到损失函数上来,
\(J(\theta) = - \frac {1}{m}[\sum_{i=1}^m \sum_{k=1}^ky_k^{(i)}log(h_\theta(x^{(i)})_k+(1-y_k^{(i)})log(1-(h_\theta(x^{(i)}))_k)]+\\\frac{\lambda}{2m}\sum^{L-1}_{l=1}\sum^{s_l}_{i=1}\sum^{s_{l+1}}_{j=1}(\theta^{(i)}_{ji})^2\)
,在单个测试用例上,单个输出单元并且忽略正则化(\(\lambda=0\)) 的情况下
\(\Large cost(i) = y^{(i)}logh_\theta(x^{(i)}) + (1-y^{(i)}logh_\theta(x^{(i)}))\)
简单的来说,也可以理解为
\(\Large cost(i) = (h_\theta(x^{(i)})-y^{(i)})^2)\)
\(\Large \delta^{(l)}_j\) 就是激活单元 \(\Large a^{(l)}_j\) 的误差值(l层的单元j)
实际上,\(\Large \delta^{(l)}_j\)的本质是代价函数关于中间项的偏微分 即\(\Large \delta^{(l)}_j =\frac{\part}{\part z_j^{(l)}}cost(i) \\\Large cost(i) = y^{(i)}logh_\Theta(x^{(i)})+(1-y^{(i)})logh_\Theta(x^{(i)})\)
展开参数
在知道如何使用反向传播计算代价函数的导数之后,还需要将参数矩阵展开为向量,以便满足高级最优化步骤中的使用需要
例如一个三层的神经网络,每层神经元数量分别为 10, 10, 1
也就是说考虑到每层添加的偏置神经元,我们需要三个参数矩阵规模分别为10x11 10x11 1x11
将\(\Large \theta_1\theta_2\theta_3\)按行展开后,我们可以得到一个长度为232的向量,同样我们也可以通过函数使其重新矩阵化
梯度检验
在对一个神经网络类的复杂的模型使用梯度下降的算法的时候,可能会存在一些误差,这些误差最终会导致代价虽然不断减小,但是最终结果不是最优解的问题。
为了规避这个问题,我们可以通过对梯度矩阵进行对比计算,通过反向传播得到的梯度矩阵和通过微积分中求偏导计算得到的梯度矩阵进行校验梯度值是否符合要求,足够准确
随机初始化
如果在优化算法开始前,我们将所有的参数初始化为0,这种方法对逻辑回归是可行的,但是对神经网络来说,会导致第二层所有的激活单元获得相同的值,同理,设置一个相同的数,也会导致一样的情况,所以在开始梯度下降之前,我们需要设置一个参数\(\epsilon\), 且初始化参数在正负 \(\epsilon\)之间,获得一个随机的参数矩阵

 浙公网安备 33010602011771号
浙公网安备 33010602011771号