DataFrame获取数据
测试数据准备
|
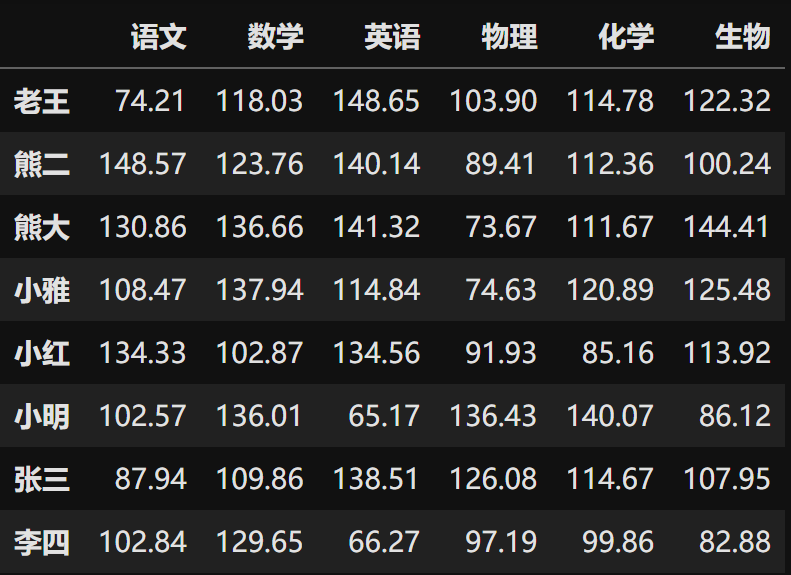 |
索引和下标的概念
- 行索引:指你设置的行索引(未设置则是默认的0、1、2...)
- 列索引:指你设置的列索引,通常也叫列名
- 行下标:指从上往下数,第0行,第1行,第2行...
- 列下标:指从左往右数,第0列,第1列,第2列...
注意:下标都是从0依次递增的,索引则是每一行每一列的名字
获取DataFrame子集的基本方法
从前往后取多行数据
默认获取前5行
# 默认取前5行数据
print(df.head())
# 获取前10行数据
print(df.head(10))默认获取后5行
# 默认取后5行数据
print(df.tail())
# 获取倒数10行数据
print(df.tail(10))随机获取N行数据
# 默认随机查看1条数据
print(df.sample())
# 随机查看5条数据
print(df.sample(5))行下标切片获取数据行
df[start:stop:step]
注意:start 和 stop 是行下标(也叫位置索引)(从0开始),从上到下第0行、第1行、第2行...,遵循左开右闭(包含开始不包含结束)原则。
# 获取第0行,返回的是DataFrame
print(df[0:1])
# 获取前5行,步长为2
print(df[:5:2])
# 获取第2行到最后行,步长为3
print(df[1::3])布尔值向量获取数据行
- 布尔值向量:完全由布尔值组成的一维数据,布尔值向量形式为
布尔值构成的列表
布尔值构成的series
布尔值构成的numpy.ndarray
- df[布尔值向量] 其中布尔值向量的布尔值个数必须和df的行数(df.shape[0])相等
布尔值列表取出对应为True的数据行
# 获取为True的数据行,返回结果是一个DataFrame
print(df[[False, True, False, False, False, True, False, True]])布尔值构成的Series取出对应为True的数据行
# 返回布尔值构成的Series对象
print(df['物理'] == 91.93)
# 获取对应为True的数据行,获取结果是一个DataFrame
print(df[df['物理'] == 91.93])布尔值构成的ndarray取出对应为True的数据行
n = np.array([False, True, False, False, False, True, False, True])
print(n) # [False True False False False True False True]
print(df[n])列索引获取一列或多列数据
获取一列数据
df[col_name]等同于df.col_name
# 获取指定列数据,返回的是Series。注意:如果列名字符串中间有空格的,只能使用df['英文']这种形式。
print(df['英文'])
print(df.英文)
# 获取指定列数据,返回的是DataFrame
print(df[['英文']])获取多列数据
df[[col_name1, col_name2,...]]
# 获取指定的某几列,返回的是DataFrame
print(df[['英文', '化学']])通过行列索引获取子集df.loc[]
loc 方法
- 以行索引(index)和列索引(columns)作为参数
- 当只有一个参数时,默认是行索引(index),即抽取整行数据,包括所有列,例如 df.loc['A'],抽取的就是A行包括所有列的数据
行获取
行索引获取一行数据
df.loc[row_name]
# 选取某一行,注意:返回的是Series
print(df.loc['熊大'])行索引获取多行数据(指定的行)
df.loc[[row_name1,row_name2...]]
# 选取某些行,返回的是DataFrame
print(df.loc[['老王', '小明']])行索引切片获取多行数据(连续的行)
df.loc[start_row_name:end_row_name:step]
注意:这里是左开右开原则,df.loc[start_row_name:end_row_name:step]不等同于df[start:end:step]
# 选取所有行,返回的是DataFrame
print(df.loc[:])
print(df.loc[:, :])
# 选取第一行至某行,返回的是DataFrame
print(df.loc[:'小雅'])
# 选取某行至最后行,返回的是DataFrame
print(df.loc['小雅':])
# 选取从某行至某行,返回的是DataFrame
print(df.loc['小雅': '小明'])
# 选取不包括某行,返回的是DataFrame
print(df.loc[df.index != '小红', :])
# 选取索引列表之外的行,返回的是DataFrame
print(df.loc[~df.index.isin(['小红', '小雅'])])布尔值向量获取行数据
df.loc[布尔值向量]df.loc[[bool1,bool2,…]]等同于df[[bool1,bool2,…]]
# 布尔值列表
print(df.loc[[False, True, False, False, False, True, False, True]])
# 布尔值Series
print(df.loc[df['语文'] == 114])
# 布尔值ndarray
n = np.array([False, True, False, False, False, True, False, True])
print(n) # [False True False False False True False True]
print(df.loc[n])列获取
列索引获取一列数据
df.loc[:, col_name]
# 选取某一列,注意:返回的是Series
print(df.loc[:, '英文'])列索引获取多列数据(指定的列)
df.loc[:, [col_name1,col_name2...]]
# 选取列索引列表之中的列,返回的是DataFrame
print(df.loc[:, ['数学', '化学']])
# 选取列索引列表之外的列,返回的是DataFrame
print(df.loc[:, ~df.columns.isin(['数学', '化学'])])
# 选取不包括某列,返回的是DataFrame
print(df.loc[:, df.columns != "物理"])列索引切片获取多列数据(连续的列)
df.loc[:, start_col_name: end_col_name]
# 选取某列至最后列,返回的是DataFrame
print(df.loc[:, '英文':])
# 选取第一列至某列,返回的是DataFrame
print(df.loc[:, :'英文'])
# 选取某列至某列,返回的是DataFrame
print(df.loc[:, '数学':'化学'])
# 选取不包括某列,返回的是DataFrame
print(df.loc[:, df.columns != '物理'])行列获取
行索引取行再配合列索引取子集
df.loc[[row_name1,row_name2...], [col_name1,col_name2...]]
# 选取 小红行 语文列,返回的是DataFrame
print(df.loc[['小红'], ['语文']])
# 选取 小红、张三行,语文列,返回的是DataFrame
print(df.loc[['小红', '张三'], ['语文']])
# 选取 小红行,数学、化学列,返回的是DataFrame
print(df.loc[['小红'], ['数学', '化学']])
# 选取 小红、张三行,数学、化学列,返回的是DataFrame
print(df.loc[['小红', '张三'], ['数学', '化学']])
# 选取 行索引列表外,列索引列表内的数据,返回的是DataFrame
print(df.loc[~df.index.isin(['小红', '张三']), ['数学', '化学']])
# 选取 行索引列表内,列索引列表外的数据,返回的是DataFrame
print(df.loc[['小红', '张三'], ~df.columns.isin(['数学', '化学'])])
# 选取 行索引列表外,列索引列表外的数据,返回的是DataFrame
print(df.loc[~df.index.isin(['小红', '张三']), ~df.columns.isin(['数学', '化学'])])布尔值向量取行再配合列索引取子集
df.loc[布尔值向量, [col_name1,col_name2...]]
print(df.loc[df['语文'] == 114, ['数学', '化学']])通过行列下标获取子集df.iloc[]
iloc 方法
- 以行和列其下标(即 0,1,2,3, ...)作为参数,0 表示第一行,1 表示第二行,2 表示第三行,以此类推
- 当只有一个参数时,默认是行下标,即抽取整行数据,包括所有列
- 例如 df.iloc[0],抽取的就是第1行包括所有列的数据
行获取
行下标获取一行数据
df.iloc[row_n]
# 选取指定的某一行,返回的是Series
print(df.iloc[2])行下标获取多行数据(指定的行)
df.iloc[[row_1, row_2,…]]
# 选取指定的某些行,返回的是DataFrame
print(df.iloc[[0, 2]])行下标切片获取多行数据(连续的行)
df.iloc[start:end:step]左开右闭
# 选取所有行,返回的是DataFrame
print(df.iloc[:])
print(df.iloc[:, :])
# 选取指定行到最后行,返回的是DataFrame
print(df.iloc[2:])
# 选取某行至某行,左闭右开原则,返回的是DataFrame
print(df.iloc[2:6])
# 选取除从上往下数第4行外的所有行,返回的是DataFrame
print(df.iloc[np.arange(df.shape[0]) != 4])布尔值向量获取行数据
# 布尔值列表
print(df.iloc[[False, True, False, False, False, True, False, True]])
# 布尔值ndarray
n = np.array([False, True, False, False, False, True, False, True])
print(n) # [False True False False False True False True]
print(df.iloc[n])列获取
列下标获取一列数据
# 选取指定的列,返回的是DataFrame
print(df.iloc[:, [2]])列下标获取多列数据(指定的列)
# 选取列下标列表之中的列,返回的是DataFrame
print(df.iloc[:, [0, 2, 3]])
# 选取列下标列表之外的列,返回的是DataFrame
print(df.iloc[:, list(df.columns.get_loc(col) not in [2, 4] for col in df.columns)])
# 选取不包括某列,返回的是DataFrame
print(df.iloc[:, np.arange(df.shape[1]) != 4])列下标切片取多列数据(连续的列)
# 选取连续的列, 左闭右开原则(即第 0 1 2 列),返回的是DataFrame
print(df.iloc[:, :3])行列获取
行下标和列下标取子集
df.iloc[[row_1,row_2,...],[col_1,col_2,...]]
# 选取 第2行 的 第3列 的数据,返回的是DataFrame
print(df.iloc[[1], [2]])
# 选取 第0、2、4行,1、3、5列位置的数据,返回的是DataFrame
print(df.iloc[[0, 2, 4], [1, 3, 5]])行下标切片和列下标取子集
df.iloc[row_index_start:row_index_stop:row_step,[col_1,col_2,...]]
# 选取 第2行开始到最后1行的 第3列 的数据,返回的是DataFrame
print(df.iloc[1:, [2]])
# 选取 第2行开始到最后1行的 第1列 和 第3列 的数据,返回的是DataFrame
print(df.iloc[1:, [0, 2]])
# 选取 所有行 的 第4列 的数据, 返回的是Series
print(df.iloc[:, 3])
# 选取 头3行,头2列位置的数据,返回的是DataFrame
print(df.iloc[:3, :2])行下标和列下标切片取子集
df.iloc[[row_1,row_2,...], [col_index_start:col_index_stop:col_step]]
print(df.iloc[[0, 2, 4], ::2])行列下标切片取子集
df.iloc[row_index_start:row_index_stop:row_step,col_index_start:col_index_stop:col_step]
# 第0行到第4行,每2行选第1行;所有列,每2列取第1列
print(df.iloc[0:5:2, ::2])dataframe.take()
DataFrame.take(indices, axis=0, is_copy=None, **kwargs)
沿着坐标轴返回给定位置索引中的元素。
这意味着我们没有根据对象的索引属性中的实际值进行索引。我们根据元素在对象中的实际位置建立索引。
indices:一个整数数组,指示要take的位置。
axis:{0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0,选择元素的轴。0表示选择行,1表示选择列。
is_copy:在pandas 1.0之前,is_copy=False可以指定以确保返回值是实际副本。从pandas 1.0开始, take始终返回一个副本,因此不推荐使用该关键字。从1.0.0版开始不推荐使用。
**kwargs:与兼容numpy.take()。对输出没有影响。
# 选取行下标为0,2,4的行
print(df.take([0, 2, 4]))
# 选取列下标为1,2的列(列选择)
print(df.take([1, 2], axis=1))选取指定单元格位置的数据
# 选取行索引为 小雅,列索引为 英文 位置的数据
print(df.at["小雅", "英文"])
# 选取第4行,第3列位置的数据, 注意:这里是行列下标
print(df.iat[3, 2])
# 选取行索引为小雅, 列索引为数学,单元格的值
print(df.loc['小雅', '数学'])
# 选取 第4行 的 第2列 的值(即访问某一单元格的值)
print(df.iloc[3, 1])通过查询函数获取子集df.query()
测试数据:
|
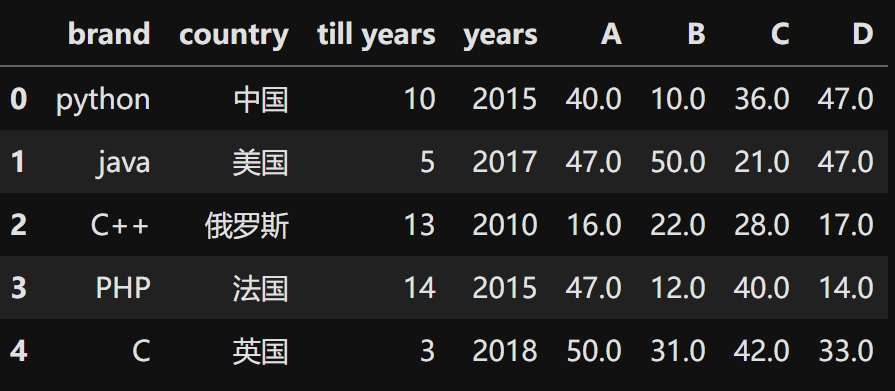 |
常用方法
# 筛选 "brand" 列中值为 "python" 的行
df.query('brand == "python"')
# 上面用 query 函数筛选数据,用下面的方法也是可以实现的
df[df['brand'] == "python"]通过数学表达式筛选
除了直接通过等于某个值来筛选, query 函数还支持通过数学表达式来进行数据筛选,包括 >、 <、 +、 -、 *、 / 等。
df.query("A > B")
df.query("A + B <= C + D")
df.query("A * 2 <= C + D")通过变量筛选
# 通过变量来筛选数据,在变量前使用 @ 符号即可
name = 'python'
df.query('brand == @name')列表数据筛选
当需要在某列中筛选多个符合要求的值的时候,可以通过列表(list)来实现
# 需要注意下 双引号 和 单引号的分开使用
df.query('brand in ["python","PHP"]')
df.query("brand in ['java','C++']")
df.query("brand not in ('java','C++')")多条件筛选
- 两者都需要满足的并列条件使用符号 & 或 单词 and
- 只需要满足其中之一的条件使用符号 | 或 单词 or
df.query('brand in ["python","C"] & A > 3')
df.query('brand in ["python","C++"] and A > 3')列名称有空格的情况
当 dataframe 的列名称中有空格或其他特殊符号的时候,需要使用 反引号(backtick mark),即键盘ESC键下面的按键(就是键盘上第二排第一个按键,有‘~’这个符号的按键) 来将列名包裹起来。
df.query("`till years` < 5")注意:如果使用单引号,将会报错。
筛选后选取数据列
在数据筛选后,还可以选择需要的数据列
df.query("A + B <= C + D")[['brand', 'A', 'C']]还可以链式调用:
# 链式调用
df.query('country =="中国" or country == "俄罗斯" or country == "美国"').query('years in [2015, 2016, 2017, 2018, 2019]')查询索引 通常当我们想根据索引值检索行时,可以使用loc[]索引器,在query中使用如下语句:
data_query=data.query('index==1') # 索引等于1
data_query=data.query('index<5') # 索引小于5
data_query=data.query('6 <= index < 20') # 索引为6到19的的记录Series 方法筛选
可以直接在列名上调用各种 Series 方法来进行筛选:
筛选First_Name字符串长度小于5的记录
data_query=data.query('First_Name.str.len() < 5')筛选First_Name字符串以A开头的记录,注意要先把空值去掉,否则会报错
data_query=data.dropna(subset=['First_Name']).query('First_Name.str.startswith("A")')筛选First_Name包含ce的记录,注意要先把空值去掉,否则会报错
data_query=data.dropna(subset=['First_Name']).query('First_Name.str.contains("ce")')
posted on 2024-10-10 22:10 【1758872】的博客 阅读(117) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号