混淆矩阵与二分类评价指标
本文总结的内容是二分类模型评价方式, 与二分类模型中的混淆矩阵.
一. 混淆矩阵 Confusion Matrix
1.1 为什么需要混淆矩阵
- 评价二分类模型时, 仅仅使用
Accuracy(准确率) 指标, 会变得片面. - 希望能有一种更合理的评价二分类模型的方式.
二分类模型使用 Accuracy 指标, 会产生一些不合理的情况. 比如, 一个二分类预测器将所有输入都预测为"1", 而实际数据中, "1" 标签所占比例为 90%, 那么这个分类器什么都不做就可以有 90% 的 accuracy. 比如, 在
skewed dataset类别不均衡数据集[1]中, 仅仅适用准确率作为指标, 指标偏高, 模型之间效果区分不明显.
1.2 混淆矩阵是什么
- 混淆矩阵是对预测结果进行划分, 如下图[2]所示.
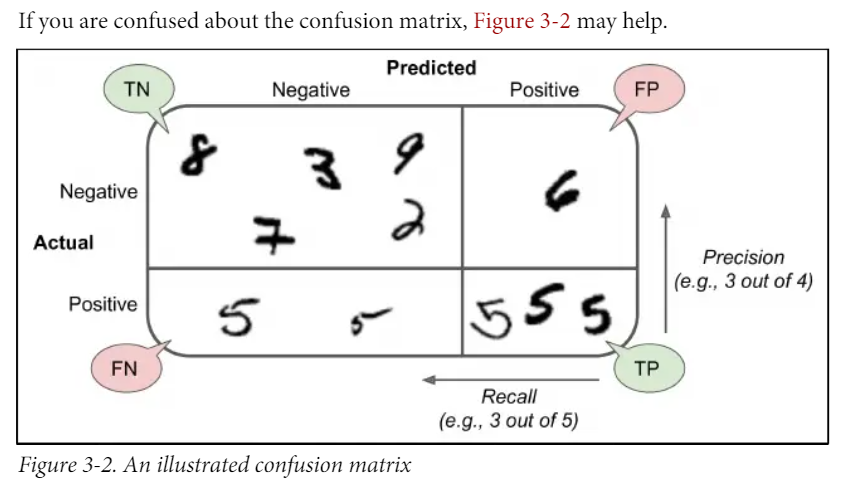
将样本的预测结果划分为四个类别, 从预测结果来看:
TN, true negatives: 预测对的 Negative 样本.FN, false positives: 预测错的 Negative 样本.FP, false negatives: 预测错的 Positive 样本.TP, true positives: 预测对的 Positive 样本.
适用混淆矩阵中的区域来表示准确率 accuracy:
二. 精确率 precision 和召回率 recall
2.1 Precision
-
precision, 准确率, 查准率; -
预测真值正确的占所有预测的比例
-
求稳"预测的都是对的" / "找到的都是对的", 表示找的准
2.2 Recall
recall, 召回率, 查全率;- 预测真值正确的占所有真值的比例
减少漏网之鱼"真值全都预测到" / "真值全部都能找到", 表示找的全
2.3 \(F_1\) score
- 权衡考虑 precision 和 recall
三. 一个例子
不妨举这样一个例子[3]: 某池塘有 1400 条鲤鱼, 300 只虾, 300只鳖. 现在以捕鲤鱼为目的. 撒一大网, 逮着了 700 条鲤鱼, 200 只虾, 100只鳖. 那么, 这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼, 虾和鳖都一网打尽, 这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见, 正确率是评估捕获的成果中目标成果所占得比例; 召回率, 顾名思义, 就是从关注领域中, 召回目标类别的比例; 而F值, 则是综合这二者指标的评估指标, 用于综合反映整体的指标.
我们希望检索结果 Precision 越高越好, 同时 Recall 也越高越好, 但事实上这两者在某些情况下有矛盾的. 比如极端情况下, 我们只搜索出了一个结果, 且是准确的, 那么 Precision 就是 100%, 但是 Recall 就很低; 而如果我们把所有结果都返回, 那么比如 Recall 是 100%, 但是 Precision 就会很低. 因此在不同的场合中需要自己判断希望 Precision 比较高或是 Recall 比较高. 如果是做实验研究, 可以绘制 Precision-Recall曲线 来帮助分析.
References
Hands on Machine Learning with Scikit Learn Keras and TensorFlow 2nd Edition ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号