「WTF」铁锅乱炖
如题所述,专门记录自己在各类考试、做题中出现的花式错误。
算法思想
-
分块相关算法写挂的:
-
[Ynoi2019模拟赛] Yuno loves sqrt technology II
写莫队发现自己没有排序,T 飞了。大致可以描述为:
void Init() { //对 Q 数组进行排序 } int main() { Init(); ...... //读入 Q return 0; }处理方式:一定要将数据读入完之后再预处理 。
-
题目见上。
写分块的时候对边角块处理不当......void UpdateBlock( int id, int l, int r, ... ); //块内处理 void UpdateAll( int L, int R ); //全局处理 { if( 左边有边角块 ) UpdateBlock( 块编号, L, R, ... ); ...... }事实上应该将左右边界限制在块的范围内。
-
其一:分块修改时,应该枚举完整个 \([lef, rig]\) 的区间,而不是只枚举 \([qL, qR]\) 内的数。这种情况主要出现在区间的元素被重排了的情况。
其二:无论是分块还是线段树,一定要注意将交集为空的情况判掉!
-
-
数据结构写挂的:
-
使用了俩优先队列的 " 可删堆 " ,结果在
push和erase的时候都没有清除多余元素,于是堆中冗余元素就超多,结果 TLE 了:typedef priority_queue<int, vector<int>, greater<int> > Heap; struct RHeap { Heap q, rub; void Push( const int v ) { q.push( v )/*这里需要 Maintain 一下*/; } void Erase( const int v ) { rub.push( v )/*这里需要 Maintain 一下*/; } int Size() { Maintain(); return q.size() - rub.size(); } int Top() { Maintain(); return q.empty() ? 0 : q.top(); } RHeap() { while( ! q.empty() ) q.pop(); while( ! rub.empty() ) rub.pop(); } void Maintain() { while( ! q.empty() && ! rub.empty() && q.top() == rub.top() ) q.pop(), rub.pop(); } }上面的“问题”已经破案了,真正的原因是
数组开小了。但是谨慎起见,最好还是每次加入
maintain一下。👍额外提醒一点,惰性删除堆千万不要删除不存在的元素。
-
这道题用单调栈维护所有位置的最值的和的时候,细节很多。尤其注意的是,每个点管辖的区间实际上是从栈内的上一个元素开始的,也就是 \((stk_{i-1},i]\) ,而不能将自己作为自己那一段的终点。请参考以下这段代码:
while( top1 && a[stk1[top1]] > a[i] ) mn -= 1ll * ( a[stk1[top1]] - a[stk1[top1 - 1]] ) * ( i - stk1[top1 - 1] - 1 ), top1 --; // 这里不能写 i-stk[top1] ,不然就会少算一些位置 mn += 1ll * ( a[i] - a[stk1[top1]] ) * ( i - stk1[top1] - 1 ) + a[i], stk1[++ top1] = i; -
线段树的边界:
写了两棵线段树,大小不一致,并且查后继时如果没有后继则默认为 \(siz+1\)(但实际上应该是 \(+\infty\))。这就导致了在较小的树上查后继的时候,得到了较小的范围,而在较大的树上查询时会查漏一些点。
处理方法:注意大小关系,注意某些特殊值的取值(无穷大无穷小等),尤其是大小不一致时容易翻车。
笑麻了,这都 1202 年了,居然还可以写错线段树。
具体来说,线段树区间修改,因为递归边界有锅,导致运行起来与暴力无异:
void Update( const int x, const int l, const int r, const int segL, const int segR, const int delt ) { if( segL > segR ) return ; if( l == r /*segL <= l && r <= segR*/ ) { Add( x, delt ); return ; } // 这里写错了 int mid = ( l + r ) >> 1; Normalize( x ); if( segL <= mid ) Update( x << 1, l, mid, segL, segR, delt ); if( mid < segR ) Update( x << 1 | 1, mid + 1, r, segL, segR, delt ); Upt( x ); } -
第一次犯错:以为区间反转对应的端点可以直接算出来,结果需要用
kth()来找;注意相对顺序会改变。第二次犯错:
kth()的时候没有下传标记。序列平衡树很久没碰过了 qwq ......
-
怎么又是平衡树:写非旋 Treap(或者其它任何结构)在结构变化的时候,一定要在结构确定下来后,更新维护的信息。
例如,非旋 Treap 就需要在子树分裂完成和子树合并完成后及时更新信息。
-
带权并查集相关:
例如 「LG P5787」二分图这道题,很多时候,带权并查集维护的是一棵生成树上,某个结点到根的信息。那么在连接 \((u,v)\) 这条边的时候,从 \(u\) 所在的根 \(r_u\),到 \(v\) 所在的根 \(r_v\),实际上是先到 \(u\),再经过 \((u,v)\) 到 \(v\),最后到 \(r_v\),因此合并信息的时候,也应该按照这条路径来合并。
-
可撤销并查集相关:
其一,断开从 \(u\) 到 \(v\) 的父子边的时候,\(u\) 的父亲应该还原成 \(u\) 而不是 0。
其二,可撤销并查集不能写路径压缩,不能写路径压缩,不能写路径压缩!!!
-
标记处理的问题:
-
注意:左偏树删除堆顶的时候,它的标记可能还没有下传。因此需要下传标记之后再合并左右子树。
有的数据结构也是同样的。如果在删除的时候,被删除的节点对于其他节点的影响需要全部清除。
-
-
-
图论算法写挂的:
-
使用 Boruvka 算法的时候,一定要注意,找出的是点,对应的是连通块,并查集维护的根与连通块的编号没有任何关系,千万不要用混了!
-
网络流的建图:
调了一个半小时,终于发现问题所在:竟然是反向边弄错了,最初
cnt赋值为 0 而非 1 !!!处理方法:单个变量不要忘记初始化!
-
关于 SPFA 判断有无负环的注意事项:
- SPFA 只能判断从起点出发能不能遇到负环。如果有一个负环不能从起点出发达到,这个负环就碰不到。
- 一些简单的优化有极佳的效果,例如
dist[]初值设置为 0 和 DFS 版 SPFA 在负环判断中表现良好。
-
一定要注意,如果用 Dijkstra 跑费用流,那么每次最短路求完之后一定要修改势为当前最短路的结果。
设在当前完成了最短路之后,结点 \(u\) 的最短路标号为 \(d_u\),那么在一次增广后,原先图上的边 \((u,v,w)\) 仍然满足 \(d_v\le d_u+w\)。而如果当前边有流经过,反向边 \((v,u,-w)\) 被加入图中,那么 \((u,v,w)\) 必然在原图最短路上,也即 \(d_v=d_u+w\),反过来也可以得到 \(d_u=d_v-w\),所以此时 \(w'=w+d_v-d_u=0\),仍然是非负的。
最初的时候我们会跑一次最短路求出势,而这个势只是对于原图有效,增广后就不能再使用它了。由于原图上可能有一些特殊性质,因而我们可以用非 Bellman-Ford 类算法求出它,以获得较好的复杂度。
-
二分图匹配的匈牙利算法:
枚举点搜索增广路的时候,理论上如果点已经匹配,那么再去搜索就是无效的,甚至可能导致错误。
......然而我没有判掉这种情况,甚至愉快地通过了 uoj 的模板题.....
二分图最大权匹配的 KM 算法:
话说这个东西貌似也可以叫做匈牙利算法。如果某些点的
slack还不够小,那么记得修改slack而不是让它保持原样。rep( i, 1, N ) if( ! visY[i] ) { if( slk[i] > delt ) slk[i] -= delt; // REMEMBER to reduce slack due to change of labX !!!!! else { ... } } -
分治过程中,如果在点上有信息或限制,并且运算不满足幂等性,那么应当保证分治重心的信息不会被重复统计,在“统计”和“存入”的时候需要注意是否应当计入分治重心。
-
判断(半)欧拉图、求欧拉(回)路一定要检查图是否连通!!!
-
在图上进行记忆化搜索的时候,如果没有搜索到需要的结果,那么也要声明某个状态已经被搜索过了,不能把状态留在那里等着其它起点再去找一遍,浪费时间。
-
一道重链剖分的题目,写错了两个地方:
-
其一,居然把重链剖分写成了轻链剖分😢,就一个符号写错了;
- 其二,中途某个位置没有开
long long,一直没有检查到;
处理方法:第一个问题属于写错了只会影响复杂度的类型,应该多测一下极限数据,什么样子的都应该测一下;第二个问题则应该检查每一个变量类型开得是否合理。
- 其二,中途某个位置没有开
-
-
-
思考不全面的:
-
发呆想了半天才发现枚举的那一天可以放在钦定的前 \(k\) 个里面。
处理方法:思路一定要全,分清问题的主从关系。
-
注意,Pollard Rho 的原理是,假如 \(n=p\times q,p<q\),那么我们随机生成一组数 \(x_1,x_2,\dots,x_k\) 之后,如果 存在 \(i,j,x_i\equiv x_j\pmod p,x_i\not\equiv x_j\pmod n\),那么 \(\gcd(x_i-x_j,n)\) 一定会生成一个 \(n\) 的一个非平凡因子。
因此,朴素做法是枚举环长,也即 \(j-i\),并取 gcd;而加上 Floyd 判环法之后则是枚举 \(i\) 并检查 \(2i,i\) 两个元素。加上了倍增,其实也就是在倍增环长,因此需要每次和路径首个元素做差,而非和前一个元素做差。
又把 Pollard Rho 写错一遍.jpg。
错误一:对于迭代方程 \(x_{i+1}=x_i^2+c\),其中初始值 \(x_0\) 和 \(c\) 都应该在范围 \([1,n-1]\) 中生成,否则在 \(n\) 非常小的时候会翻大车。
比如,当 \(n=4\) 的时候,很容易直接陷入死循环。
错误二:如果样本累积若干次后,变成了 0,就应该直接退出该次取样,而不能取 \(\gcd\) 之后以为找到了非平凡因子。
-
注意,旋转的时候是寻找 \((i,i+1)\) 这条边的对踵点,因此假如为 \(j\),那么应该检查 \(\operatorname{dist}(i,j)\) 和 \(\operatorname{dist}(i,j+1)\)。
当然将四个点对全部检查一遍自然没什么问题 -
一定要注意,如果用 Dijkstra 跑费用流,那么每次最短路求完之后一定要修改势为当前最短路的结果。
设在当前完成了最短路之后,结点 \(u\) 的最短路标号为 \(d_u\),那么在一次增广后,原先图上的边 \((u,v,w)\) 仍然满足 \(d_v\le d_u+w\)。而如果当前边有流经过,反向边 \((v,u,-w)\) 被加入图中,那么 \((u,v,w)\) 必然在原图最短路上,也即 \(d_v=d_u+w\),反过来也可以得到 \(d_u=d_v-w\),所以此时 \(w'=w+d_v-d_u=0\),仍然是非负的。
最初的时候我们会跑一次最短路求出势,而这个势只是对于原图有效,增广后就不能再使用它了。由于原图上可能有一些特殊性质,因而我们可以用非 Bellman-Ford 类算法求出它,以获得较好的复杂度。
-
关于网格图上高斯消元的问题。
设网格大小为 \(n\times m\),且 \(n,m\) 同阶。这类问题一般有两种解决方案:
-
带状矩阵高斯消元,本质上就是利用位置 hash 的性质偷了个懒,大大减少了所需扫描的范围。复杂度为 \(O(nm\times \min\{n,m\}^2)\)。
但是这个方法在网格图消元之外比较危险。网格图上可以保证对角线上系数为 1,但是其它问题中就不一定了。如果出现了需要换行的情况就比较麻烦,不好好处理很容易直接破坏掉带性质;一般来说,如果需要换,那么我们会选择换列而非换行,这是因为如果某一列之下有超出带的范围的系数,我们可以在之后的消元中解决掉它。
-
确定主元,这个相对来说适用性更广,效率更高,可以做到 \(O(n^3)\),但是写起来较为复杂......
-
-
关于 BSGS 算法和扩展 BSGS 算法:
一句话:求离散对数的时候一定要注意 \(p=1\) 和 \(b=1\) 的特殊情况!!!
-
注意一点,当 \(t> \max \{\lfloor\log_2 s\rfloor\}\) 的时候,此时倍增长度不再由 \(\log_2 s\) 决定,而是由 \(\log_2 n\) 决定。注意边界的细节。
-
注意当直线的方向向量为 \(\vec 0\) 的时候,这样的直线一般来说需要特判。
-
数学真奇妙;没有交换律真奇妙。
\(n\) 阶方阵群是一个典型的半群,这上面没有交换律。
相应地,系数为 \(n\) 阶方阵的多项式群也是半群,这上面也没有交换律。
在这上面进行多项式求逆的时候,传统步骤中的一步:
\[(G_0-G)^2\equiv O\pmod {x^n} \]展开之后得到的就是:
\[G_0^2-GG_0-G_0G+G^2\equiv O\pmod {x^n} \]没错!半群上没有交换律,完全平方公式失效了!!!
由于 \(GG_0\) 和 \(G_0G\) 同时存在,这个方法已经走不下去了。可行的方法是从 \(G_0F-I\equiv O\pmod {x^{\lceil\frac n 2\rceil}}\) 出发:
\[\begin{aligned} (G_0F-I)^2&\equiv O\\ G_0FG_0F-2G_0F+I^2&\equiv O\\ G_0FG_0-2G_0+G&\equiv O\pmod {x^n} \end{aligned} \]最后移项即可得到 \(G\)。又有一点需要注意,半群上 \(a^2b^2\not=(ab)^2\),所以中途出现了 \(G_0FG_0F\) 这种东西。
-
-
其它算法各种乱七八糟铁锅乱炖导致写挂的:
-
关于整体二分的写法问题。
这里由于我们不能简单地修改要求,所以在进入右区间的时候,我们必须保证左区间的边已经被加入。
如果写法是在离开区间时删除新加入的边,且在进入右区间之前将所有的左边的边加入,那么没有问题。
但是如果写法是在叶子的位置加入边,并且之后不删除,那么就必须保证叶子可以到达(现在外层相当于是遍历线段树的过程)。因此如果:
void Divide( const int qL, const int qR, const int vL, const int vR ){ if( vL > vR || qL > qR ) return ; ...}那么就有问题(因为很有可能询问区间为空就返回,没有到叶子节点)。
-
多校赛某题。
\(n=10^{10}\) 的时候做杜教筛,预处理范围只有 \(10^6\),导致杜教筛跑得非常慢......
处理方法:熟悉时间复杂度原理,杜教筛需要预筛到 \(n^{\frac{2}{3}}\) 才可以。
-
后缀数组模板。
注意中间的“桶”数组大小与字符串长度相同,而非与字符集大小相同!
const int MAXN = 1e6 + 5, MAXC = 300;int buc[MAXN]; // 注意不是 MAXC -
关于不同颜色计数的树上差分方式。
如果按照 DFN 排序之后,某个颜色之前和之后都有颜色出现了,那么应该选择一个较低的 LCA 来删除多于贡献,而不应该在两个 LCA 上都删除一遍。
-
DP 的转移:
比较下面的两种转移写法:
#define rep( i, a, b ) for( int i = (a) ; i <= (b) ; i ++ ) #define per( i, a, b ) for( int i = (a) ; i >= (b) ; i -- ) int h[][]; //other codes omitted. per( p, N, 0 ) per( q, N + 1, 0 ) { int tmp = 0; for( int k = 0, up = 1 ; i * k <= p && j * k <= q ; k ++ ) Upt( tmp, Mul( h[p - i * k][q - j * k], Mul( ifac[k], up ) ) ), up = Mul( up, Add( g[i][j], k ) ); h[p][q] = tmp; }#define rep( i, a, b ) for( int i = (a) ; i <= (b) ; i ++ ) #define per( i, a, b ) for( int i = (a) ; i >= (b) ; i -- ) int h[][]; //other codes omitted. for( int k = 1, up = 1 ; i * k <= N && j * k <= N + 1 ; k ++ ) { up = Mul( up, Add( g[i][j], k - 1 ) ); for( int p = N - i * k ; ~ p ; p -- ) for( int q = N + 1 - j * k ; ~ q ; q -- ) Upt( h[p + i * k][q + j * k], Mul( Mul( ifac[k], up ), h[p][q] ) ); }如果要求用
g[i][j]将所有k都转移一遍之后,h[][]才能发生变动,那么第二种写法就有问题。这是因为,转移过程中较小的k会对较大的k造成影响,相当于是按照k划分而不是按照g[i][j]划分。总而言之,明确 DP 过程的阶段,同时找出合适的写法。
-
二分的结果:
如果在二分过程中计算方案,那么最终二分出来的答案是
l而不是上一次代入的参数。因此,输出方案之前需要重新构造一遍!!! -
关于高斯消元。
之一:高斯-约旦消元的精度似乎比高斯消元的精度要高。但是据说如果高斯消元不处理精度误差那么就不会出现问题。
之二:跟行列式不同,需要将单行的主元系数化一。
-
关于 WQS 二分。
我们二分的是切凸包的斜率。如果目标位置被共线的边卡住了,那么我们只能二分出正确的斜率,而多半不能找到正确的切点。但是我们只需要知道截距和斜率就可以算出答案,所以此时的答案不是切点的结果,而是目标位置在该斜率下的结果。
-
实现细节
-
编译过程出错的:
-
由于
g++的版本与现行版本不一致,库的包含关系就不完全相同。这个时候如果缺少头文件也有可能会本地通过编译,但是提交后可能会 CE。典型例子就是
Dev-C++上cmath还包含在algorithm里面。如果仅包含algorithm并且使用cmath内部的函数,在新版的g++下编译就会报错。 -
经典的“隐形”库函数
y0(double), y1(double), yn(int,double); j0(double), j1(double), jn(int,double),这几个小混蛋都在cmath里面,存在于编译器的include文件夹里的math.h里面。问题是,它们几乎找不到踪迹。如果去 C++ reference 里面查你根本找不到它们。
如果在 Windows 环境下使用 9.3.0 版本的
g++编译也不会检查出问题,但是,但是,一旦包含cmath并且自定义了重名的变量/函数,那么在Linux环境下编译的时候才会 CE。😓去查了一下,发现
j.()表示的是第一类贝塞尔函数,y.()表示的是第二类贝塞尔函数。 -
初始化疑云:
这里集中了一些由于不当初始化而导致的编译问题。
在 Compiler Explorer 上以
-std=c++17编译,所以汇编码应该对应的是 Intel x86-64 的 CPU。-
经典错误一:使用大括号初始化数组:
如果是平凡地直接使用大括号括起来,全部清空,那么初始化不会出问题:
struct QwQ { // something }; int a[100000] = {}; QwQ b[100000] = {};无论使用内置类型或自定义类型。
但是,如果在大括号里面初始化了某些位置的值,那么会导致大括号被展开成完整的初始化列表(补上空白)。一个直接的表现就是编译出来的可执行文件非常大。当数组很大的时候效果尤其明显:
int a[10000000] = { 1, 2 }; // with a large *.exe appearing -
经典错误二:错误地使用结构体初始化:如果在结构体或类的初始化中对非内置类型数组进行初始化,无论如何赋初值,如下:
struct Rubbish { int rub[1000]; Rubbish(): rub{} {} // safe operation }; struct RubbishBin { Rubbish a[1000]; RubbishBin(): a{} {} // DANGEROUS operation }; RubbishBin rb;只要对这样的类型进行实例化,那么在汇编码中,构造函数会被完全展开。在上面的这段代码中,实际效果就是对于
a中每个对象都调用Rubbish :: Rubbish()。直接看一下汇编码的样子: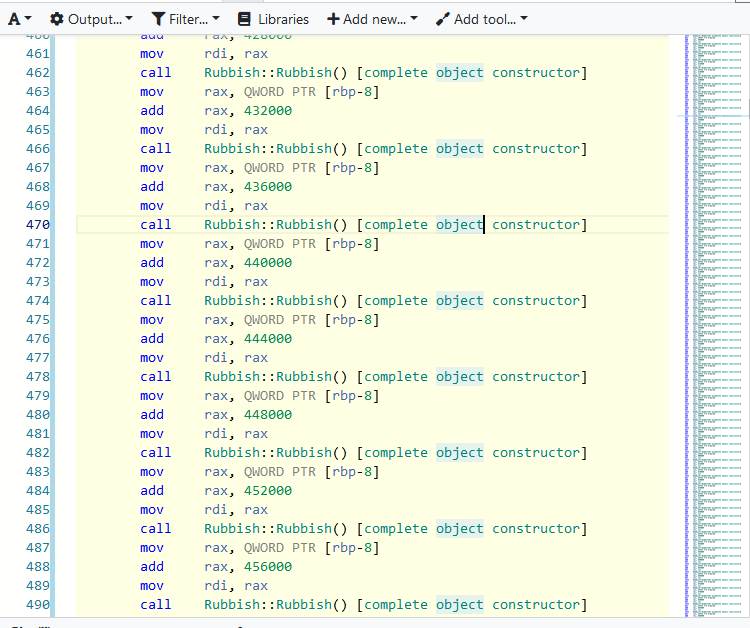
外在的表现就是编译时间变长,但是可执行文件大小正常,嗯。
实际上,由于全局变量会自动清空(汇编码里面会有一个
.zero的指令)所以写成:struct Rubbish { int rub[1000]; Rubbish(): rub{} {} // safe operation }; struct RubbishBin { Rubbish a[1000]; RubbishBin()/*: a{}*/ {} // Fine }; RubbishBin rb;也可以达到清空的效果,并且不会出问题。
-
-
-
清空的问题
-
同一变量多次重复使用,中间没有清空,直接暴毙:
int lst = N + 1; for( int i = N ; ~ i ; i -- ) { nxt[i][1] = lst; if( S[i] == '1' ) lst = i; } //这里本应该清空 lst 的 for( int i = N ; ~ i ; i -- ) { if( S[i] == '1' || S[i + 1] == '0' ) nxt[i][0] = lst; if( S[i] == '0' ) lst = i; } -
对于判定性问题,如果我们一旦搜索到符合要求的结果就退出,那么在多次搜索的情况下,一定要注意在退出之前有没有将公共内存清空。无论是使用
return结束语句还是使用throw跳转都需要注意这个问题。 -
注意分治过程中,公共数组的清空,特别是在改写法的时候,不要忘了加上被修改结构的清空过程。
-
-
注意边界
-
预处理应该按照值域为范围来清,结果只清到了点数范围。
-
模拟赛中出现的 typo 。
按理说应该是很常见的问题,我居然还在犯。遍历 \(n\times m\) 的平面的时候,弄混了 \(n\) 和 \(m\) 的关系,于是写错了循环边界,成功地挂分了:
for( int i = 1 ; i <= n ; i ++ ) //这里的 n 应该是 m ...记清楚变量的含义,尤其是常见易混变量 \(n,m,x,y\) 之类的。
-
这次在预处理逆元的时候,恰好处理到了 \(2^{18}-1\) 的范围,但是实际调用时使用到了 \(2^{18}\) 的逆元,然后就爆炸了......
处理方法:一定要注意,使用任何函数/循环/数组内存时,是否会越界或超出有效范围;此外,在对复杂度影响不大时也可以适当使用快速幂/exgcd 求逆元;
-
「Gym102979L」Lights On The Road
第一次写 K 短路,结果被坑到了两个地方:
-
建图都建错了,头尾两个虚点不能连在一起,而 \(n=1\) 的时候我会连起来。这个写的时候确实没想到;
-
当 \(n=1\) 的时候,最短路树上没有非树边,这个时候堆为空。将空节点插进去做 K 短路就会 RE......
这个问题更大一些,写的时候想到了这一点,但是没有想到堆会成为空,没有判。
处理方法:注意边界情况,不要被细节卡了。
-
-
某道计数题。
数据范围明确给出:

这就说明,输入数据可以有 \(n<k\)。但是我的程序,如果不特判 \(n<k\) 就会干出奇奇怪怪的事情,导致各种 WA。
-
答案的范围是 \([0,2^{31})\),所以计算 \(L,R\) 的时候,如果中途不取模可能会爆
int。处理方式:涉及到的变量如果非常之大,每一步都取模是必要的;对拍的时候也应该造完全极限的数据。
-
最终求出来的次小生成树的答案可以达到 \(10^{14}\),但是最大值只开到了 \(10^9\)。
处理方法:注意,不同的数据类型应该单独设计最大值,最大值尽量不要多个数据类型通用。
-
最开始,给每个数组开一个
vector,里面存的是真实值,所以范围是 \([0,10^8]\),用int完全装得下。后来,发现不应该装真实值,应该装前缀和,所以就改了内容,没改类型,范围变成了 \([0,10^{14}]\),
int就会爆炸。这样的问题应该在最初编写期就解决,这说明思考还不完全就着急写代码了。
-
保证下标或指针指向的是有效的空间。
这里主要关注如何控制下标或指针不会越界,而不考虑空间开小了的情况。
例如 「模板」最小表示法,如果给定的串是
aaa...aa的形式,则需要判断长度指针 \(k\) 是否到达了 \(|S|\),否则会访问到有效的空间之外。又注:对于下标进行运算的时候也要注意是否会越界。例如,进行减法的时候需要确认是否会越过下界,进行加法的时候需要确认是否会超出上界。尤其是下标从 0 开始计算的时候尤其容易算错!!!
-
经典错误:如果用
vector实现多项式,那么在写加法的时候,很容易忘记边界,将任意位置的计算都写成F[i]+G[i]。但实际上,如果i取遍所有有效位,那么下标很有可能越界,导致 UB,返回一些乱七八糟的值。 -
阳间边界问题:左移超出边界是 Undefined Bahaviour,比如不能算
1llu << 64,不然返回什么东西谁也说不清楚。
-
-
实现有误、不精细导致超时的:
-
[HDU6334]Problem C. Problems on a Tree
画蛇添足,本身不需要用
map的地方偏偏使用了,导致程序及其慢,map占用了将近 \(\frac 1 3\) 的时间。补充:可以使用
clock()检查运行时间。 -
[CF446C]DZY Loves Fibonacci Numbers
分块写法,清理标记的时候,没有判断有没有标记:void Normalize( int id ) { //这里缺少了是否存在标记的判断 for( int k = lef[id] ; k <= rig[id] ; k ++ ) //...... }最开始以为分块的标记和线段树类似,现在才意识到,分块下放标记的时间是 \(O(T)\) 的,所以不判掉就会特别慢......
-
求欧拉路一定要用当前弧优化。
-
对于编码方式比较复杂的问题,一定要注意各种编码是否正确转换了。
比如,二分图匹配的时候,经常会犯忘了特殊处理右部点标号的问题。
-
注意,邻接表建图后,遍历边的顺序是与输入顺序相反的。
-
只要可以离散化,都建议写离散化之后再写线段树。权值线段树实在是太慢了......
当年冰火战士也有这个诡异的坑点。
-
保证复杂度的剪枝写太弱了,导致复杂度是错的。
需要注意写下来的代码(比如剪枝)是否和所想的相同。本质上还是在问思路是否清晰。
在洛谷上居然还可以卡过去,实在是误人子弟。 -
nmd 这个东西是真的诡异。大一点的高维数组寻址奇慢无比,自带满打满算
x2常数。警告:写比较大的高维数组的时候一定要谨慎,如果可以就开内存池,真的可以有效降低常数。
-
-
数据杂糅,不进行区分:
-
题目本身并不难,但是要注意,由于我们将值存储在
Trie的末尾,所以被删除了的节点本质上就是变成了空节点。因此,空节点存储的值应该等于被删除了的值。例如,如果空节点值为0,那么被删除的节点的值也应该是0。否则,
Trie的结构就可能导致将空节点判断为有值的节点的错误出现(例如,插入一个较长串,并查询它的前缀)。处理方式:同类标记尽量统一。
-
线段树(以及任何静态结构)上,如果需要删除结点,那么在维护最值的时候我们一般会将要删除的结点赋成一个极值。
但是一定要注意,这里的极值应当区分初始化的极值,尤其是在需要同时取出极值所在的位置的时候。这里就需要明确:初始化所赋的极值是可以取的,但是删除所赋的极值就是为了避免取到的。
-
-
类型写错的:
-
整除分块的时候,使用中间变量记录取整除的值,但这个中间变量没有开
long long:for( long long l = 1, r ; l <= n ; l = r + 1 ) { int val = n / l; // 就是这里!!!应该开 long long!!! }
-
-
各种奇怪的问题:
-
最大生成树,运算符直接重载为了小于。
-
【UR #2】跳蚤公路
循环变量用上了不常用的名字,结果之后就写错名字:for( 对 i 循环 ) for( int u = 1 ; i <= n ; u ++ ) //......处理方式:尽量规避奇怪的循环变量名称,同时写的时候也要带脑子。
-
关于取模安全的问题
其实就是计算过程中,尤其是取模,很容易写着写着就忘记取模了。
简单的加减乘除还比较容易记住,但是进行像自加、自减、赋字面量这样的运算的时候很容易忘记取模。
比较安全的做法是:
- 封装几个函数替代常用的运算,然后在函数内部取模。运算时强制使用它们;
- 封装模域类,然后只用这个类运算。这个对于多模数的情况比较友好;
常见的问题有:
-
注意特殊的模数,尤其是题目输入模数的时候,注意模数是否可能为 1。
例如,有的题目取模的模数是单独输入的,特别注意模数可否为 1,特别注意赋的初始值是否落在正确的范围内,不确定可以取一下模;
没有把握就在输出取模,
虽然这看起来也只是权益之计。
-
DP 的边界、清理:
-
联测某题。
在转移的时候,本应在所有数据计算完之后再对不合法数据进行清理,结果边清理边计算,导致较小的不合法数据影响了之后的结果。
处理方法:注意操作的顺序,不止是在 DP 的转移中,写的时候就应该注意到顺序的问题。
-
-
浮点数的精度问题:
-
「Gym102798E」So Many Possibilities...
实数概率 DP,因为 \(\epsilon\) 设得太大,导致用它判空状态的时候将有效状态也判成空,漏了不少结果,答案偏小......
用实数算 DP 的时候,没有必要用上 \(\epsilon\)。需要用来卡常的时候,算好可能的系数量级,然后反推 \(\epsilon\) 的大小;宁可设得小一点,也不要漏掉有效状态。不要再出现这样不知所谓还被卡了半天的错误!
-
模拟赛题目。
需要对浮点数进行 \(10^6\) 组运算,每组运算
+,-,*,/都齐了。结果就
不出意外地爆掉了double的精度,只有开long double才能通过。注意
double在大数小数混合运算时的精度问题!!! -
奇妙的题目。构造割的时候,如果源点的出边全部满流了,那么一种割就是 \(\newcommand\set[1]{\{#1\}}[s,V\setminus \set{s}]\),然而这显然不是我们想要的。
为了避免这种情况,我们必须调整答案,使得源点的出边略有剩余容量;具体操作起来就是让答案变小一点,而后从 \(s\) 开始遍历寻找一组割。
-
-
STL 的奇妙特性:
众所周知,为了
使操作更麻烦简化操作,STL 的set和map等关联容器内部基本上都提供了reverse_iterator这种迭代器。从字面意思就可以知道,这种迭代器是逆向访问容器的。比如
set默认使用 < 比较,如果用reverse_iterator来访问它则会从大到小遍历set的元素。相应地,容器也会有rbegin()和rend()这样的函数,一看就懂了。问题是,
reverse_iterator的运算也是和iterator呈镜像对称。比如++ reverse_iterator,那么从set原本的顺序来看,就相当于向变小的方向移动,反过来也类似。如果和
iterator混用就很容易弄错,比如今天上午我就调了 0.5 h。此外,一般来说容器的
erase()都只会接受iterator。既不可以往里面丢reverse_iterator,也并不存在rerase()这样的函数。
对于
vector这样使用random access iterator的容器,一般来说使用迭代器访问的效率低于下标访问。另外,如果用
for( x : y )这样的循环,那么内部是使用迭代器实现的,因此需要注意大数据下的运行效率。
set如果删除不存在的元素,那么它不会RE,而是会直接略过这一次操作。相当于是它会自己检查元素是否存在。
vector的resize()只会对新添加的元素执行构造函数(或者进行指定的初始化,如果存在第二个参数的话),不会修改已有的元素。 -
读题出错的:
-
有点奇怪。题目里面说
There is no pipe which connects nodes number 1 and N,但是它的真正含义是不存在从 1 流向 \(n\) 的管道,但是可以存在从 \(n\) 流向 1 的管道。这个时候就会出现环流,因此需要建立新的源点与汇点,避免“源”和“汇”出现环。思考的时候要细致一点,每个方面都要想到;同时对于题目理解要清晰到位,结合好题目前提与背景。
-
-
任何时候,使用 DFS 传回
bool信息表示某个过程是否已经结束时,应该在任何一次递归调用结束之后,查询返回值并判断是否应该结束过程。否则会导致各种乱七八糟的问题。 -
注意任何数学运算是否安全。
例如 「POI2011 R1」避雷针 Lightning Conductor 这一题,需要注意的细节是,实值函数 \(a_j+\sqrt{|i-j|}\) 才具有单调性。虽然实际求答案的时候,\(a_j+\sqrt{|i-j|}\) 和 \(a_j+\lceil\sqrt{|i-j|}\rceil\) 是一样的,但是前者是实值函数,后者是整值函数。而在整值函数上单调性已经被破坏了,因此只要涉及到与决策有关的比较,都必须用实值而非整值。
-
多组数据,注意输出换行!!!
不是开玩笑,尤其是在用
cout输出的时候。由于不常用,就很容易忘记输出endl。
-
-
调整代码时出的问题:
-
对某个数组进行平移(或者其它下标变换)时,并没能做到对于每个用到数组的位置都去修改下标,最终导致错误访问。
这个问题解决起来比较麻烦,最好的方法还是一开始就确定好如何定下标,避免以后再去修改。
-
比赛与策略
-
2020.08.24 的模拟赛
-
多组数据,小范围搜索,大范围骗分的时候,没有注意小范围搜索的用时,导致 TLE 。
处理方式:不要贪心,同时严格把控小范围的时间空间开销,自己要预先测试!
-
从母串 \(S\) 里面提取子串 \(T\) ,然后本应该在 \(T\) 上进行的操作,全部搞在了 \(S\) 上面,导致 WA 。
-
中途修改写法,把外部的写成的某一个步骤封装或者改写成函数。其中函数的某个参数是全局变量,但是内部相关参数没有改名字,导致 WA 。
处理方式:善用替换功能。
-
-
2020.08.27 的模拟赛
-
写 DP,虽然时间复杂度不对头,但是
我很自信,于是就把空间开到了极限,希望能卡过。然后它就 MLE 了,呜呜呜~
处理方式:比赛最后检查的时候一定要算一遍空间,不要太贪心。
补充:善用
MinGW内部提供的size,可以作为静态空间的参考; -
最后 45 分钟 rush 一个正解。由于人很慌,而且是数据结构题目,所以小数据就拼了个暴力上去,想着是有保底的分数。
测出来我就发现,我正解写对了,但是暴力居然写错了?!
-
以为 T3 不太难,于是硬刚它。没有想到它是很恶心的结论题目,于是我就花费很多时间,换来了 10pts 的好分数。
处理方式:开场时每道题先粗略地思考一下,评估难度;规划好时间,避免吊死在一棵树上,一定不可干这种傻事!。
补充:如果觉得题目难度比较大,那么应该果断先写出正确的暴力争取基础分。
-
-
2020.09.19 的模拟赛:
-
不读题的:
某题有多解,要求输出 " 字典序最小的一组 " 。
由于方案构造起来并不复杂,所以......直接没有看到这个要求(甚至过了大样例),暴毙。
-
-
2021.03.27 的 NOI Online:
想了简单的 \(O(nk^2)\) 之后,觉得这个算法:啊, " 反正 ' 最多 ' 只能过 \(k\le 100\) 的部分分,就照着空间开吧 " 。
于是给 \(k\) 开了 100 的 int 的空间,于是就爆炸了!
处理方法:请对着题目数据范围,在保证不会失分,不会 MLE 的情况下开空间。
-
UNR #5 T3
暴力 40pts,最后应该需要检查每一个状态,但是我直接把最后一个状态当做答案......
明明写个对拍就能找出的错,居然没有发现,也没有想过去写对拍,反而测了中样例就不管了......
即使当场只准备写骗分,也一定要将工作做齐备,对拍、人肉调错不能少!
-
某道计数题。
数据范围明确给出:
这就说明,输入数据可以有 \(n<k\)。但是我的程序,如果不特判 \(n<k\) 就会干出奇奇怪怪的事情,导致各种 WA。
明确提示:
-
一定要注意数据范围,注意特判边界情况;
-
读题不要想当然,如果有时间可以考虑更全面的情况,把程序修改得尽量健壮;
-
造数据自测和对拍的时候一定要注意达到任何可能的边界,极大极小都要碰到;
-
检查流程不能遗漏,万不可白丢分。
-
-
2021.10.11 模拟赛:
有一道题目改到一半弃疗了,结果提交的源程序包含了错误的代码,甚至会直接 CE,导致💥。
处理方法:检查时间要留充分,需要检查文件、空间、编译和所有样例!!!
-
2021.10.16 模拟赛:
策略出大问题,后面两道题目选一道死磕,以为自己写好了正解,结果发现读错题了,最后暴力都没写过。
总结:一者,如果模拟赛的后面两道题明显不简单,则一定要积极写部分分,千万不要死磕正解;二者,写较难的题目的时候一定要从暴力先写起,一来可以验证正确性,二来可以保底;三者,给每道题安排好时间,避免死磕在某一题目上。
-
2021.10.17 模拟赛:
以为自己 T3 过了,其实是假算法,
还过了大样例,挂麻了。总结:对于有一定思维过程的题目,只要不是太难写,一定要写好纯暴力对拍!
-
2021.10.18 模拟赛:
第一题比较简单,以为自己可以写对,并且觉得对拍效果不大,结果就没有写对拍,然后就 WA 爆了。
总结:前面两道题目一定不能丢分!!!基础题目一定要保证稳当!!!一定要留出 30min+ 的时间检查题目,尤其是前两道题!!!写对拍!!!
-
2021.11.3 模拟赛:
最后一道题目的部分分没有深入思考。明明有一个很简单的部分分居然都没有去想过。
如果有时间,一定要在准备骗分的题目上多思考几个部分分。不要因为某道题准备骗分而留出较少的时间来思考和实现。
-
2021.11.7 模拟赛:
比赛开始粗略地扫了一眼题目,结果把最后一题的题目意思读错了。等到去做题的时候颇为匆忙,也没有来得及再仔细确认题目,导致悲惨的读错题几乎爆炸。
读题一定要仔细,一开始可以只把握大意,但是在做题之前一定要认真阅读题面。
-
2021.11.14 模拟赛:
很多人挂掉了 T1,包括我。
简单地转化了问题之后,就开始把一道类似但实际上并不等同的题目的思路往上面套,并且用错误思路同时完成了提交代码和对拍程序,最后两个错误程序拍得相当欢快——然后爆炸了。
世界上没有两个相同的问题,进行任何类型的迁移都要比较两个情景是否是一致的,是否有边界区分......总之,无论什么时候,“套做法”都得慎之又慎;
此外,尽量避免对拍用的“正确”程序和测试程序有较大重合,包括思路和实现——除非测试内容与重合内容关系不大,否则不要冒险。
-
2021.11.16 模拟赛:
今天的比赛时间分配比较失衡。
T1 明明很简单,结果自己想的时候就只会很复杂的做法,在这上面花了 1 h 40 min。
T2 其实也不难,但是想题的时候掉到死胡同里去了,居然也不会倒出来重新想一想;一条道走到黑,这是个坏习惯。
T3, T4 总共只花了 1 h,导致需要相当思考的 T4 连暴力也很难写出来。
完成前两题就花了 2 h 30 min,效率低而且收益也低,写代码难以集中,错码率挺高的。
之后模拟赛不多,一定要有紧迫感,抓紧时间。如果觉得一时半会儿想不出来就先写个保证正确的暴力,保证每道题目的保底暴力分数。
-
2021.11.17 模拟赛:
主要是 T2 一开始思路错了,导致白花了 40 min 而一分也没有。
注意,一定要深入思考之后,确定没有问题再开始写代码,不要空耗时间寻求心理安慰;如果把这些浪费的时间投入到之后的暴力中,事实证明收益也很不错。
-
2022.02.12 模拟赛:
这场题目比较简单,但是发挥得并不是很好。
T1 失误比较大。本来是一道比较简单的 DP 题却没有做出来,说明这类细节比较多但是本身并不难的 DP 还需要多练习。分析过程也显得不够精准间接,分析序列的差分数组肯定没有分析序列本身来得快。
T2 做得还不错;T3 里面遇到了一个不太熟悉的 NTT 技巧,需要学习一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号