单调栈学习笔记
单调栈基础
单调栈根据所维护的单调性可以分为四种:
- 严格递增栈。必须出栈至栈空或栈顶小于当前元素后,才入栈当前元素。
- 严格递减栈。必须出栈至栈空或栈顶大于当前元素后,才入栈当前元素。
- 非严格递增栈。必须出栈至栈空或栈顶小于等于当前元素后,才入栈当前元素。
- 非严格递减栈。必须出栈至栈空或栈顶大于等于当前元素后,才入栈当前元素。
单调栈基本性质
一些基本性质:
- 维护单调性的方式是:无论破坏多少个栈内的,也要让新元素进来。
- 如果是正着扫序列,则越靠近栈顶的元素,下标越大,距离当前指针越近。
接下来来看单调栈的两个实例。
NGE
NGE 基础
当用到单调栈的时候,95% 都是在解决这个问题。
给定一个数组
这个问题被称为 Next Greater Element 问题,即 NGE 问题。类似地,我们还有 NLE(Next Less Element),NNGE(Next Not Greater Element),NNLE(Next Not Less Element)问题。这四个问题分别对应四种不同的单调栈,对于 NGE 问题,我们应该选择非严格递减栈:必须出栈至栈空或栈顶大于等于当前元素后,才入栈当前元素。
于是,从左到右扫,每个数都会被入栈一次。如果
/*
* @Author: crab-in-the-northeast
* @Date: 2022-12-30 02:27:56
* @Last Modified by: crab-in-the-northeast
* @Last Modified time: 2022-12-30 02:31:37
*/
#include <bits/stdc++.h>
inline int read() {
int x = 0;
bool f = true;
char ch = getchar();
for (; !isdigit(ch); ch = getchar())
if (ch == '-')
f = false;
for (; isdigit(ch); ch = getchar())
x = (x << 1) + (x << 3) + ch - '0';
return f ? x : (~(x - 1));
}
typedef std :: pair <int, int> pii;
const int maxn = (int)3e6 + 5;
int ans[maxn];
int main() {
int n = read();
std :: stack <pii> s;
for (int i = 1; i <= n; ++i) {
int x = read();
while (!s.empty() && x > s.top().first) {
ans[s.top().second] = i;
s.pop();
}
s.push({x, i});
}
for (int i = 1; i <= n; ++i)
printf("%d ", ans[i]);
puts("");
return 0;
}
应该选择什么单调栈?
在实际做了一些单调栈题目后,我发现重要的不是你选择哪种单调性的单调栈,而是选择用于求解四个问题(NGE、NLE、NNGE、NNLE)中哪个问题的单调栈。
怎么选呢?假设我们要选择 NGE 单调栈,核心代码是这样的:
for (int i = 1; i <= n; ++i) {
int x = read();
while (!s.empty() && x > s.top().first) {
ans[s.top().second] = i;
s.pop();
}
s.push({x, i});
}
上面的 x > s.top().first 正是我们体现单调栈类型是 NGE 的地方。很好理解,s.top().first 就是栈顶的值,x 就是当前的元素,因为 x > s.top().first,所以栈顶找到了它的 NGE x,直接标记即可。
假设我们要选择 NNGE 单调栈,那么 while 里的条件应该写成:
!s.empty() && x <= s.top().first
因为 x 是栈顶的 Next Not Greater Element(即小于等于栈顶)。
当然,如果你实在想知道单调性和这四个问题的对应关系,这里我也给出:
- NGE 单调栈 = 非严格单调递减栈。
- NNLE 单调栈 = 严格单调递减栈。
- NLE 单调栈 = 非严格单调递增栈。
- NNGE 单调栈 = 严格单调递增栈。
你可以用适合自己的方法记忆。
从 NGE 问题发掘出更多性质
每个时刻单调栈内元素的含义是:待确定 NGE / NLE / NNGE / NNLE 的元素。这个思想尤为重要,可以看做单调栈的第三条性质。
下面我们以 NGE 单调栈为例。
在单调栈刚好射入
而先前被插入,后来已不在单调栈内的元素
同时,考虑任意时刻 NGE 单调栈任意两个相邻的元素
如果
如果
非常类似地,我们可以推出对于任意
所以可以推出
这意味着,非严格单调递减栈中相邻的两个元素,在原序列中间夹着的所有元素,都比这两个元素更小。称之为性质四。
另外,对于 NNLE 栈,上面那个结论是
NLE 和 NNGE 就是上面两种情况不等号反过来啦(这里不取等的接着不取等,取等的接着取等哦)。
区间端点最大 / 小问题
题意:统计数对
让
在射入
那么满足条件的
我们尝试将
一直弹到不弹为止,很明显,如果此时栈已经为空,那么上面的所有
如果栈不为空,设栈顶为
那么比
分类讨论。
【第一种情况:
考虑栈中等于
根据性质四,在原序列中,所有满足条件的
考虑比
但是,
【第二种情况:
此时,只有栈顶这个
而不在栈顶的其它元素在序列上到
到这里本题正确性已经做完了,但事实上上面的 第一种情况,我们还要从栈顶一直往栈底扫,找极长的一个元素相同段,复杂度已经不对了。
怎么办呢?这里有一个小技巧,那就是把栈中相邻的两个相等的元素“打包”,记成一个 pair 元素,其中 pair 的第一项是元素本身,第二项是元素出现了多少次。这样我们只需要获取栈顶信息即可,复杂度正确。
/*
* @Author: crab-in-the-northeast
* @Date: 2023-04-24 19:49:57
* @Last Modified by: crab-in-the-northeast
* @Last Modified time: 2023-04-24 20:09:39
*/
#include <bits/stdc++.h>
#define int long long
inline int read() {
int x = 0;
bool f = true;
char ch = getchar();
for (; !isdigit(ch); ch = getchar())
if (ch == '-')
f = false;
for (; isdigit(ch); ch = getchar())
x = (x << 1) + (x << 3) + ch - '0';
return f ? x : (~(x - 1));
}
typedef std :: pair <int, int> pii;
signed main() {
int n = read();
std :: stack <pii> s;
int ans = 0;
while (n--) {
int x = read();
while (!s.empty() && x > s.top().first) {
ans += s.top().second;
s.pop();
}
if (s.empty())
s.push({x, 1});
else if (s.top().first == x) {
int cnt = s.top().second;
ans += cnt;
s.pop();
ans += (s.empty() ? 0 : 1);
s.push({x, cnt + 1});
} else {
++ans;
s.push({x, 1});
}
}
printf("%lld\n", ans);
return 0;
}
对于其它类型的端点最值问题,该怎么解决?请接着阅读后面的例题。
例题
USACO06NOV Bad Hair Day S
P2866 USACO06NOV Bad Hair Day S
统计数对
【思路一】
考虑扫
假设现在将要处理
考虑射入
弹出所有应该弹的元素后,栈内剩下的任一元素
因此只需要让每个元素入栈时,先把该弹的弹掉,然后累计剩下的栈的大小即可。
/*
* @Author: crab-in-the-northeast
* @Date: 2023-04-25 08:19:16
* @Last Modified by: crab-in-the-northeast
* @Last Modified time: 2023-04-25 08:21:27
*/
#include <bits/stdc++.h>
#define int long long
inline int read() {
int x = 0;
bool f = true;
char ch = getchar();
for (; !isdigit(ch); ch = getchar())
if (ch == '-')
f = false;
for (; isdigit(ch); ch = getchar())
x = (x << 1) + (x << 3) + ch - '0';
return f ? x : (~(x - 1));
}
signed main() {
int n = read(), ans = 0;
std :: stack <int> s;
while (n--) {
int x = read();
while (!s.empty() && x >= s.top())
s.pop();
ans += s.size();
s.push(x);
}
printf("%lld\n", ans);
return 0;
}
【思路二】
上面这个思路很巧妙,但事实上有一个无脑做法。
考虑满足条件的
所以直接算 NNLE 即可。
HISTOGRA
SP1805 HISTOGRA - Largest Rectangle in a Histogram
考虑最优矩形,下方一定紧贴地线,上方一定紧贴某个矩形的高。
我们考虑对于给定每条小矩形,计算目标矩形如果在这个矩形上,以这个矩形的高为高,最宽能延伸多少。
然后发现转化成了 PLE(Previous Less Element)和 NLE 问题,用两个 NLE 栈维护,一个正着扫一个倒着扫即可。
/*
* @Author: crab-in-the-northeast
* @Date: 2023-04-25 08:46:59
* @Last Modified by: crab-in-the-northeast
* @Last Modified time: 2023-04-25 09:02:00
*/
#include <bits/stdc++.h>
#define int long long
inline int read() {
int x = 0;
bool f = true;
char ch = getchar();
for (; !isdigit(ch); ch = getchar())
if (ch == '-')
f = false;
for (; isdigit(ch); ch = getchar())
x = (x << 1) + (x << 3) + ch - '0';
return f ? x : (~(x - 1));
}
inline bool gmx(int &a, int b) {
return b > a ? a = b, true : false;
}
const int maxn = (int)1e5 + 5;
int a[maxn], ple[maxn], nle[maxn];
signed main() {
for (int n = read(); n; n = read()) {
for (int i = 1; i <= n; ++i)
a[i] = read();
std :: stack <int> s;
for (int i = 1; i <= n; ++i) {
while (!s.empty() && a[i] < a[s.top()]) {
nle[s.top()] = i;
s.pop();
}
s.push(i);
}
while (!s.empty()) {
nle[s.top()] = n + 1;
s.pop();
}
for (int i = n; i; --i) {
while (!s.empty() && a[i] < a[s.top()]) {
ple[s.top()] = i;
s.pop();
}
s.push(i);
}
while (!s.empty()) {
ple[s.top()] = 0;
s.pop();
}
int ans = 0;
for (int i = 1; i <= n; ++i)
gmx(ans, a[i] * (nle[i] - 1 - ple[i]));
printf("%lld\n", ans);
}
return 0;
}
POI2008 PLA-POSTERING
首先发现答案和矩形宽度一点关系都没有。忽略!
不难发现一种可行的方案:对每个建筑分别张贴一张海报,这样海报数量为
我们必须让一张海报同时完全覆盖两个建筑,才能让需要的海报数量变小。
考虑这两个建筑的必要条件:
- 这两个建筑等高。
- 这两个建筑中间没有比这两个建筑低的建筑。
不难发现上面的条件已经充分,我们考虑优先给满足上面条件的两个建筑中间填上矩形。
这样以来矩形可能有重叠,比如按照上面的填涂规则,有如下事例:
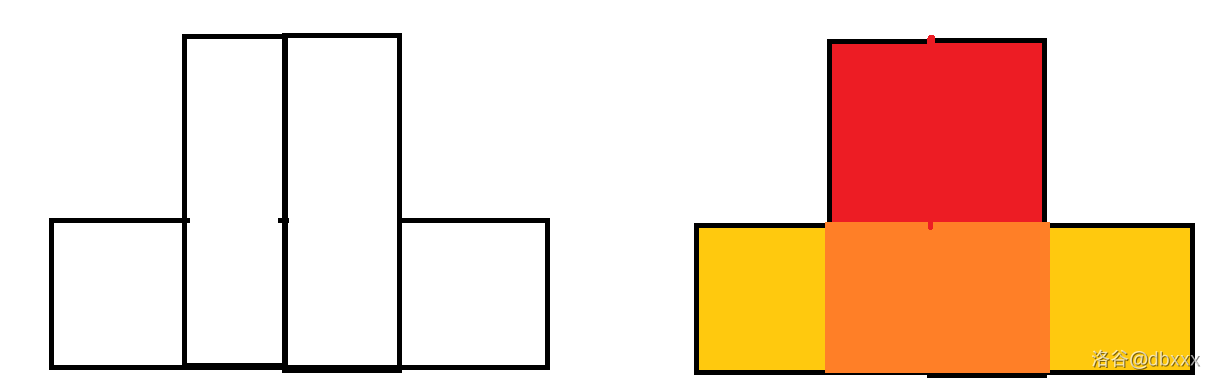
上图中,橙色矩形是红色矩形和黄色矩形的公共部分。
这个问题也很好处理,我们缩减红色的范围,让它的下界只扩展到黄色的上界就可以了。
类似的重叠问题都可以这样解决,优先满足下面的,让上面的只扩展到下面的上界即可。
因此,问题变成统计数对
统计完这个数量之后,直接用
解释一下上面为什么是
这个问题怎么做?考虑维护 NNGE 栈,扫
在射入
只用考虑栈内的元素。
考虑弹出为了射入
再考虑栈内剩余的任一元素
所以只需要维护严格递增栈的同时,弹出栈顶的时候看栈顶有没有和元素相同的即可。
/*
* @Author: crab-in-the-northeast
* @Date: 2023-04-25 13:36:30
* @Last Modified by: crab-in-the-northeast
* @Last Modified time: 2023-04-25 13:52:14
*/
#include <bits/stdc++.h>
inline int read() {
int x = 0;
bool f = true;
char ch = getchar();
for (; !isdigit(ch); ch = getchar())
if (ch == '-')
f = false;
for (; isdigit(ch); ch = getchar())
x = (x << 1) + (x << 3) + ch - '0';
return f ? x : (~(x - 1));
}
int main() {
int n = read(), ans = n;
std :: stack <int> s;
for (int i = 1; i <= n; ++i) {
read(); int x = read();
while (!s.empty() && x <= s.top()) {
if (s.top() == x)
--ans;
s.pop();
}
s.push(x);
}
printf("%d\n", ans);
return 0;
}
我们已经看了两道类似端点最值问题的习题了,大概总结一下方法⑧。
首先,我们要明确,这种问题找到合法
那么怎么确定找那种类型的单调栈呢?看已经确定了
统计数对
的数量,满足 。
为方便判断,我们将上面的最值形式做一些转化。首先就是先把 关于
满足
。
然后 将最值转成“对于任意
满足对于任意
都有 。
考虑 什么时候会破坏这个条件,显然,就是
满足存在
使得 。
也就是
再来看这个例子:
统计满足
。
首先砍去
满足
。
最值转任意
对于任意
有 。
破坏:
存在一个
有 。
所以用 NNLE 栈。
另外,上面那个 Bad Hair Day S 的思路一,也可以看成端点最值问题(只是不再将
判断完应该使用哪个栈之后,剩余的部分就是看栈里的什么元素满足条件,一般分为两种看:
- 为射入
- 射入
根据一些取等细节,上面两类可能分为更细的类,需要自己判断。
长方形
对于每个
从每个点
然后就变成了
HISTOGRA,但是计算矩形的数量。
考虑一下怎么做。
对第
这样以来可能会有重复计数吗?
考虑并排放置的两个等高小矩形,即
怎么办呢?考虑更换
我们验证一下是否真的不重不漏了。
每次以
首先很明显,满足条件的
其次,考虑找到
很明显,
对于任意
对于任意
也就是说,对于任何一个左端点为
/*
* @Author: crab-in-the-northeast
* @Date: 2023-04-25 17:53:24
* @Last Modified by: crab-in-the-northeast
* @Last Modified time: 2023-04-25 18:04:25
*/
#include <bits/stdc++.h>
#define int long long
inline int read() {
int x = 0;
bool f = true;
char ch = getchar();
for (; !isdigit(ch); ch = getchar())
if (ch == '-')
f = false;
for (; isdigit(ch); ch = getchar())
x = (x << 1) + (x << 3) + ch - '0';
return f ? x : (~(x - 1));
}
inline char rech() {
char ch = getchar();
while (!isgraph(ch))
ch = getchar();
return ch;
}
const int maxm = 1005;
int h[maxm], ple[maxm], nnge[maxm];
signed main() {
int ans = 0, n = read(), m = read();
while (n--) {
for (int i = 1; i <= m; ++i)
h[i] = (rech() == '.') ? (h[i] + 1) : 0;
std :: stack <int> s;
for (int i = 1; i <= m; ++i) {
while (!s.empty() && h[i] <= h[s.top()]) {
nnge[s.top()] = i;
s.pop();
}
s.push(i);
}
while (!s.empty()) {
nnge[s.top()] = m + 1;
s.pop();
}
for (int i = m; i; --i) {
while (!s.empty() && h[i] < h[s.top()]) {
ple[s.top()] = i;
s.pop();
}
s.push(i);
}
while (!s.empty()) {
ple[s.top()] = 0;
s.pop();
}
for (int i = 1; i <= m; ++i)
ans += h[i] * (i - ple[i]) * (nnge[i] - i);
}
printf("%lld\n", ans);
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】