[luogu p5410] 【模板】扩展 KMP(Z 函数) & 扩展 KMP(Z 函数)学习笔记
Z函数 & exKMP
P5410 【模板】扩展 KMP(Z 函数) - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
我的
概念与约定
本文字符串从
下文中有些概念是我的自定义概念。
字符串的第
定义
算法讲解
既然 fail、nxt、……)相似,都是从向后递推,用前面的
现在假设我们要求
根据定义可以得到
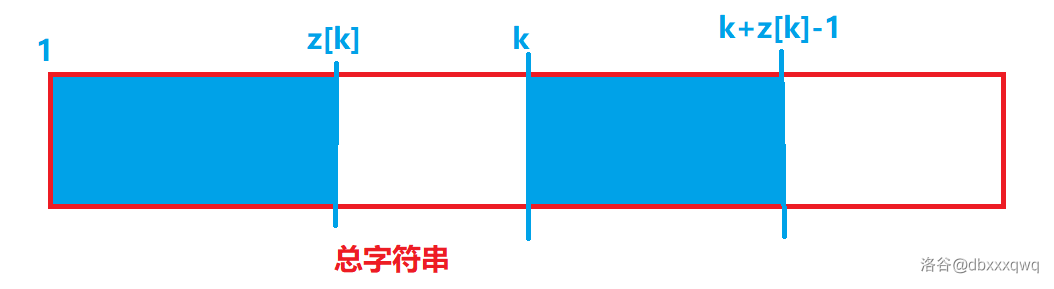
当然了,
对了,那有些人会问了,
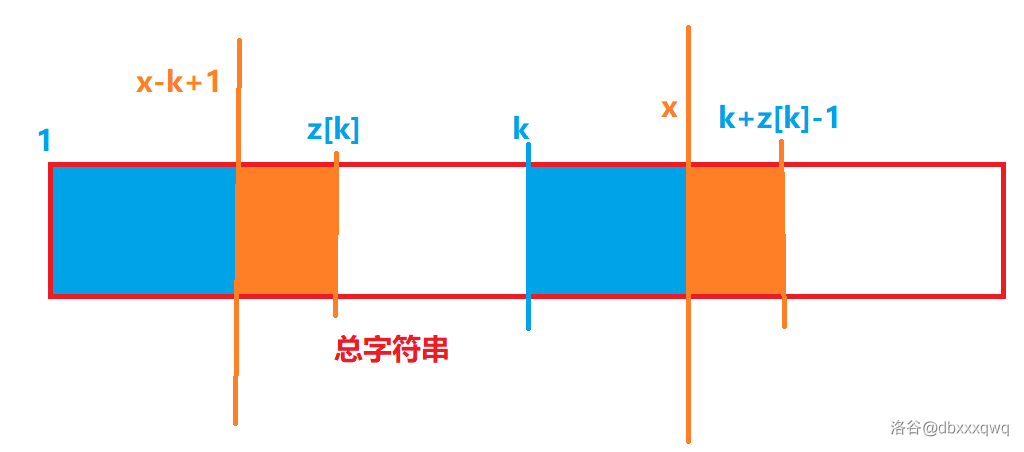
令
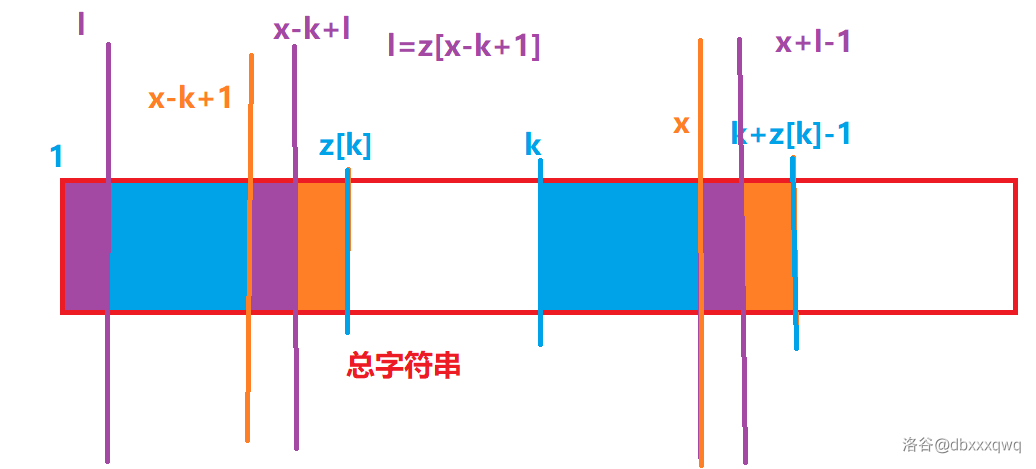
上图的紫色部分就是刚刚说的三个相等的子串。其中:
综上可以得到三个紫色块完全相同。
好的,观察这个图片,已经可以得到结论:
我们考虑上面三根紫线分别紧挨着的后面的字符,它们分别是:
首先可以证明:
其次可以看出:
因此可以得到:
于是就能证明:原串和
因此答案是
那么结束了吗?其实并没有。因为上述的图中我们可以得到这样一个结论,需要一个重要的地方做支撑:
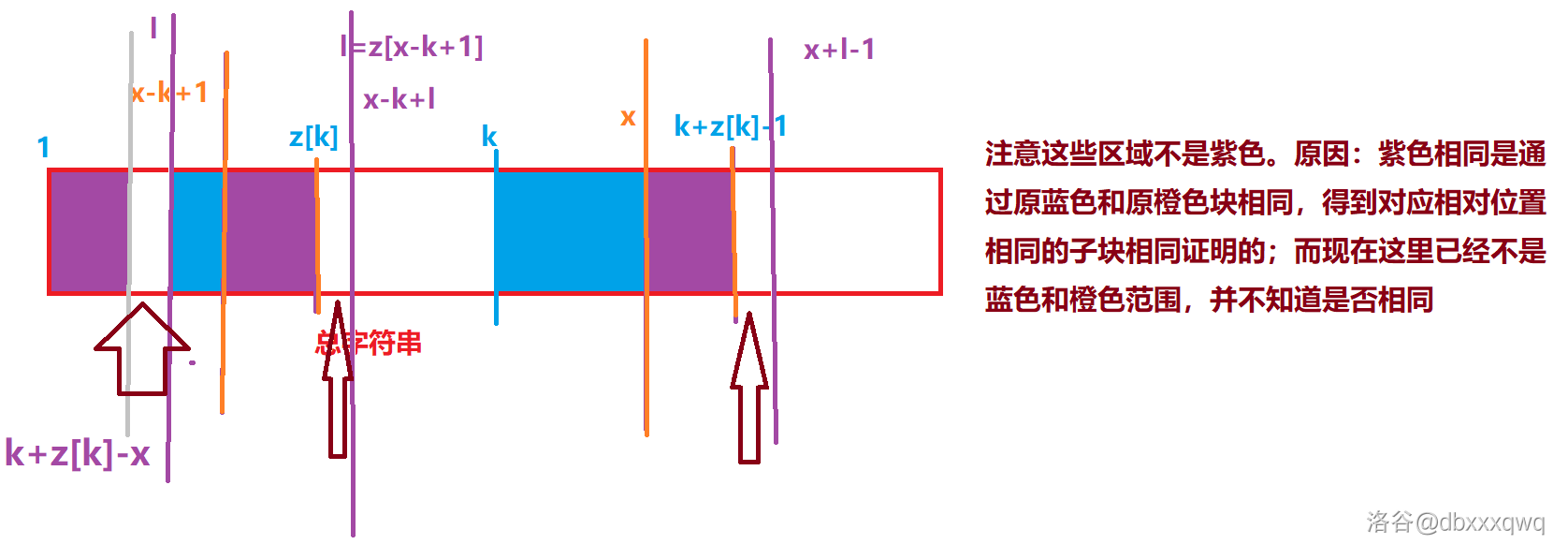
不难发现这时,紫色完全淹没了橙色。与第一种情况不同,此处箭头指向的三个区域中,前两个箭头所指区域仍然保证相同,但和三个区域不再保证相同。前两块相同仍然因为
因此我们现在只能下结论说
总结一下:
- 否则,初始令
恭喜你,已经学会了
第一种情况显然是
最后来到了喜闻乐见的细节:
代码(事实上没有注释后相当短小好记):
void get_z(char *P) {
int m = strlen(P) - 1; // 注意,这里的 m 其实就是字符串 P 的长度,只是我从 1 开始,因此 strlen 得到的长度会多 1
for (int i = 2, k = 1; i <= m; ++i) {
if (k + z[k] - i <= z[i - k + 1]) { // 第二种情况
// 相当于 z[i - k + 1] >= k + z[k] - i
// 也就是补齐后的紫色大于等于橙色时,进入第二种情况
z[i] = k + z[k] - i; // 将z[i] 调到 k + z[k] - i,这是它的最小值
if (z[i] < 0) // 判断,防止负数出现
z[i] = 0;
while (i + z[i] <= m && P[z[i] + 1] == P[i + z[i]])
++z[i]; // 暴力枚举,判断字符相等
k = i; // 直接令 k = i
} else
z[i] = z[i - k + 1]; // 第一种情况
}
z[1] = m; // 题目中要求 z[1] = m,在算法处理后赋值
return ;
}
exKMP
exKMP 也就是求模式串
一种做法:令
还有一种做法(真正的exKMP),只需要在
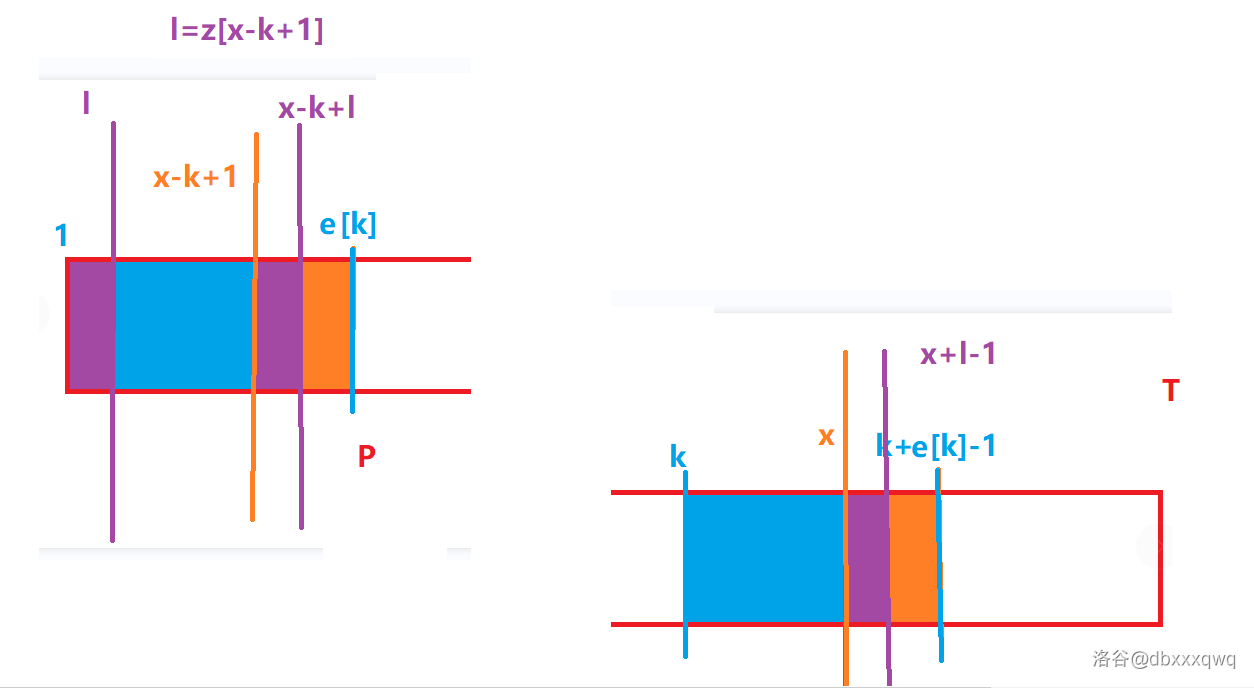
需要提前预处理出
代码:
void exkmp(char *T, char *P) {
int n = strlen(T) - 1, m = strlen(P) - 1; // 同上,注意这里 n 和 m 就是分别实际的文本串和模式串的长度
for (int i = 1, k = 0; i <= n; ++i) { // 注意哪些地方换成了 p(也就是刚刚我说的 e),哪些还是原来的 z
// 这里让 k = 0,一定会走到第二种情况暴力判断,然后 k = 1 就正常了
if (k + p[k] - i <= z[i - k + 1]) {
p[i] = k + p[k] - i;
if (p[i] < 0)
p[i] = 0;
while (i + p[i] <= n && p[i] < m && P[p[i] + 1] == T[i + p[i]])
++p[i];
k = i;
} else
p[i] = z[i - k + 1];
}
return ;
}
后话
洛谷该题目模板中,最高赞的一篇题解是 George1123 写的
模板洛谷 P5410。
谢谢。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】