CF1746E Joking
CF1746E Joking
交互库最开始给定一个正整数
你可以向交互库提出问题:
提问一个集合
交互库可以骗人,也即交互库的回答不一定正确。但保证 交互库连续的两次回答中,至少有一次是正确的。
你还可以向交互库提交答案,直接提交一个正整数
保证
E1 Easy Version
在 Easy Version 中,限制参数
观察到提交答案的机会只有
因此我的想法是:当知道
对交互的询问进行分析,我们考虑交互库不骗人的时候怎么做。
我们大概能知道这种交互问题都是不断缩小
这里让目标范围降低多少的计算,应该按照交互库的 Yes,No 两种回答中,能让目标范围降低地最少的那个来计算,也即我们要按照最坏情况考虑。
比如当前的目标范围是 Yes,不管 No,目标范围大小只能降低
提一嘴,这里交互库自适应,所以要按照最坏情况考虑;但如果交互库不自适应,那么可能可以有正确率不是
但是可以很高的交互策略:可以算一下交互库回答两种答案的期望,从而得到目标范围降低的期望,而不是最坏情况。 如果一个交互策略的最坏情况很不优秀,但是期望比较优秀,在交互库不自适应的情况下可能也是可以做的。这是后话了。
如果交互库不骗人,策略还是比较容易想到的,折半查找即可。
设当前目标范围是 Yes,那么目标范围 No,目标范围
那么这种策略,每次可以将目标范围
如果交互库骗人呢?
首先我们要分析清楚的是,会骗人的交互库对于我们询问的回答,能给我们提供什么确定的信息。容易看出,在交互库骗人时,单独一次询问的回答什么信息都不能提供,如果我们只看不相邻的两次询问,也什么信息都不能提供。关键就是在于我们要利用好相邻两次询问最少有一次是真的,来看 相邻的两次询问能带来什么信息。
不过,在分析这个之前,我先介绍一个关键的思想:对于一次
- 交互器回答
Yes:说明本轮交互器告诉我们 - 交互器回答
No:说明本轮交互器告诉我们
请注意这里对回答 No 的思考方式,我们不要直接思考 Yes 代表 No 代表
现在来看相邻的两次询问能带来什么信息。假设我们先询问一次,得到了
这两次询问的结果在交互库不骗人时,保证均是真的,我们可以得到
而在交互库骗人时,这两条信息的真假并不确定,只保证至少有一个是真的,即:
总结一下:通过两次相邻的,反馈分别为
回想我们的目标,我们期望用这两次相邻的询问,让目标范围降低地尽可能多。
先梳理思路:
还是假设当前目标范围为
- 两次均回答
Yes,可以将目标范围进一步锁定到 - 第一次回答
No,第二次回答Yes,可以将目标范围进一步锁定到 - 第一次回答
Yes,第二次回答No,可以将目标范围进一步锁定到 - 两次均回答
No,可以将目标范围进一步锁定到
上面的等号用的是德摩根定律化简,读者处理集合问题应当熟练应用。
这里我们应该按照最坏情况讨论,即如果我们钦定询问第一次询问
- 最坏情况下,目标范围的大小至少会缩小到
- 最坏情况下,目标范围的大小至少会减少
当然,上面两条是等价的,这里我选择第二条处理(选第一条处理也很好做,读者可以自行尝试)。
我们的目标是最大化缩小效果,也即选定
对于集合问题我们可以考虑绘制韦恩图。
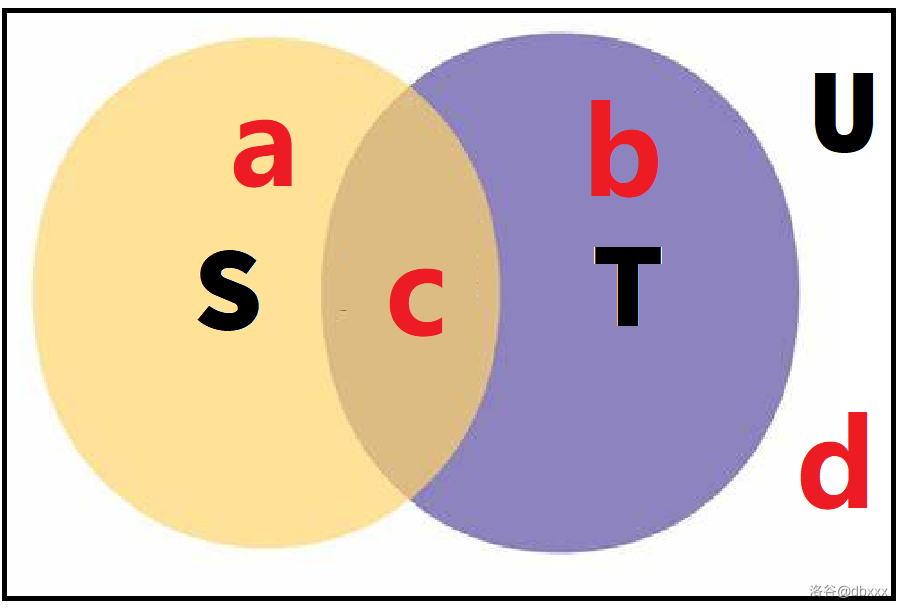
设上面黄色区域代表的集合为
容易发现,
观察目标最值的四项:
我们可以发现,
那么目标最值其实就是
目标最值已求出,那么我们将
回顾我们的构造方案,事实上,我们是将
现在我们检验这样的询问策略能否达成目标。写程序判断需要用多少询问才能把目标集合大小缩小到
int main() {
int n = (int)1e5;
for (int i = 0; i <= 83; i += 2, n - (n >> 2))
std :: cout << i << ' ' << n << std :: endl;
return 0;
}
我们发现用
其实很简单,我们每次能让目标集合减少
分析原因,其实是因为
更具体来说,假设我们的划分是 Yes 时,我们的推论是目标集合变小到
或者假设划分是 No 时,我们的推论是目标集合变小到
那么我们只能换一种策略了。既然
这里你可以尝试手玩一下(笔者其实手玩花了不少时间)。这里提供一种
先问一次 No,再问一次 No,那么目标集合可缩减到
否则,上一个状态应该是问了一次 Yes。然后直接问 Yes 目标集合为
其实这个策略是可以推广的,上面的
, , 换成集合,我们就得到了一种使用 个问题让目标集合大小减少 的做法。事实上这个减少速率是比使用 个问题让目标集合大小减少 要慢的,最坏需要 次询问才能让目标集合降低到 以内,不过这题好像没卡这个做法。
于是,我们使用了不多于
#include <bits/stdc++.h>
inline int read() {} // 读入数字的函数,省略
inline std :: string rest() {} // 读入字符串的函数,省略
inline bool query(std :: vector <int> v) {
printf("? %d ", (int)v.size());
for (int x : v)
printf("%d ", x);
puts("");
fflush(stdout);
return (rest() == " YES");
}
inline void solve(std :: vector <int> v) {
int n = (int)v.size();
if (n <= 2) {
for (int x : v) {
printf("! %d\n", x);
fflush(stdout);
if (rest() == " :)")
exit(0);
}
} else if (n == 3) {
if (!query({v[0]}) && !query({v[0]})) {
solve({v[1], v[2]});
} else if (query({v[1]})) {
solve({v[0], v[1]});
} else
solve({v[0], v[2]});
} else {
std :: vector <int> S;
std :: vector <int> T;
for (int i = 0; i < n; ++i) {
if (i & 1)
S.push_back(v[i]);
if (i & 2)
T.push_back(v[i]);
}
std :: vector <int> nxt;
int s = query(S) ? 1 : 0, t = query(T) ? 2 : 0;
for (int i = 0; i < n; ++i)
if (((i & 1) == s) || ((i & 2) == t))
nxt.push_back(v[i]);
solve(nxt);
}
}
int main() {
int n = read();
std :: vector <int> v;
for (int i = 1; i <= n; ++i)
v.push_back(i);
solve(v);
return 0;
}
E2 Hard Version
在 Hard Version 中,限制参数
观察我们刚才的询问策略哪里可以优化。我们从全局上查看刚才的询问策略,发现第一次询问和第二次询问是一组;第三次询问和第四次询问是一组;第五次询问和第六次询问是一组。每一组询问,我们将目标范围缩小。
然而这样“相邻两个询问必有一真”这个条件只在一组询问中的两个询问被用到;而上一组的最后一个询问和下一组的第一个询问也是相邻的,这两个询问之间也是有条件的,但我们没用到,造成了条件的浪费。
现在我们考虑怎么让每两个相邻询问的限制都用上。
一般地,假设当前的目标范围为
很明显,我们问的集合一定是
如果这次的回答是 Yes,即这次询问交互库告诉我们
如果这次的回答是 No,即这次询问交互库告诉我们
这是一个类似 dp 的转移,考虑设计状态
因为
这样以来我们还要得知
- 回答是
Yes,则 - 回答是
No,则
于是我们可以写出转移方程:
这里
这里 Yes 和 No 两种情况。交互库返回什么是我们不可预测的,并且因为交互库的自适应性,我们必须按照最坏的一种情况考虑。也即,对于 Yes 和本次询问回答 No 后,两个后继询问步数的最大值。
边界状态是:
询问的方式是:在当前
可以认为在第一次询问之前,交互器告诉了我们
然而这样的状态本身的复杂度就能达到
因此,我们考虑不将集合设入状态,而是将集合的大小设入状态。于是我们可以得到如下转移方程:
边界状态是:
询问的方式是,在当前
初始状态是
观察转移的顺序并检查转移的无环性:对于任意
那么对于
事实上,
若用到 的 转移,意味着 或 ,也就是我们选择的 或 (即 ),这均会导致计算分别扔掉 , 时至少有一种丢了空集,也即目标集合大小不变。
至于
以
考虑到上面的状态复杂度为
这里有一种启发式的思想,不妨从 E1 尽可能让全集大小降速更快的角度思考转移的过程。
当前的状态是 Yes 时,状态变为
因此,我们考虑让转移方程中的
这里我取
然而
typedef std :: pair <int, int> pii;
std :: map <pii, int> f;
std :: map <pii, pii> g;
inline int F(int a, int b) {
if (a + b <= 2)
return 0;
if (f.count({a, b}))
return f[{a, b}];
int ans = 1000, ansc = -1, ansd = -1;
for (int c = std :: max(0, (a - 1) >> 1); c <= std :: min(a, (a + 3) >> 1); ++c)
for (int d = std :: max(0, (b - 1) >> 1); d <= std :: min(b, (b + 3) >> 1); ++d) {
if ((c + d) + (a - c) == a + b && a - c <= b)
continue;
if ((a + b - c - d) + c == a + b && c <= b)
continue;
// 上面两行是为了控制 a + b = a' + b' 时的转移顺序
// 注意 a - c <= b, c <= b 的等号不能省略,这是为了防止 F(a, b) 的求解访问自身导致死递归
int now = 1 + std :: max(F(c + d, a - c), F(a + b - c - d, c));
if (now < ans) {
ans = now;
ansc = c;
ansd = d;
}
}
g[{a, b}] = {ansc, ansd};
return f[{a, b}] = ans;
}
调用 F(1e5, 0) 我们可以发现,这样运行后
注意到初始时我们应该调用
而且
由于本题过于启发式,时间复杂度笔者写不出来。
/*
* @Author: crab-in-the-northeast
* @Date: 2023-06-20 19:58:38
* @Last Modified by: crab-in-the-northeast
* @Last Modified time: 2023-06-20 21:59:36
*/
#include <bits/stdc++.h>
inline int read() {
int x = 0;
bool f = true;
char ch = getchar();
for (; !isdigit(ch); ch = getchar())
if (ch == '-')
f = false;
for (; isdigit(ch); ch = getchar())
x = (x << 1) + (x << 3) + ch - '0';
return f ? x : (~(x - 1));
}
inline std :: string rest(bool space = true) {
std :: string s;
char ch = getchar();
for (; !isgraph(ch); ch = getchar());
for (; isgraph(ch); ch = getchar())
s.push_back(ch);
return space ? (" " + s) : s;
}
typedef std :: pair <int, int> pii;
std :: map <pii, int> f;
std :: map <pii, pii> g;
inline int F(int a, int b) {
if (a + b <= 2)
return 0;
if (f.count({a, b}))
return f[{a, b}];
int ans = 1000, ansc = -1, ansd = -1;
for (int c = std :: max(0, (a - 1) >> 1); c <= std :: min(a, (a + 3) >> 1); ++c)
for (int d = std :: max(0, (b - 1) >> 1); d <= std :: min(b, (b + 3) >> 1); ++d) {
if ((c + d) + (a - c) == a + b && a - c <= b)
continue;
if ((a + b - c - d) + c == a + b && c <= b)
continue;
int now = 1 + std :: max(F(c + d, a - c), F(a + b - c - d, c));
if (now < ans) {
ans = now;
ansc = c;
ansd = d;
}
}
g[{a, b}] = {ansc, ansd};
return f[{a, b}] = ans;
}
inline bool ask(std :: basic_string <int> S) {
printf("? %d ", (int)S.size());
for (int x : S)
printf("%d ", x);
puts("");
fflush(stdout);
return (rest() == " YES");
}
inline void solve(std :: basic_string <int> T, std :: basic_string <int> F) {
int a = (int)T.size(), b = (int)F.size();
if (a + b <= 2) {
std :: basic_string <int> ans = T + F;
for (int x : ans) {
printf("! %d\n", x);
fflush(stdout);
if (rest() == " :)")
exit(0);
}
} else {
auto p = g[{a, b}];
int c = p.first, d = p.second;
std :: basic_string <int> T0, T1, F0, F1;
T0.assign(T.begin(), T.begin() + c);
T1.assign(T.begin() + c, T.end());
F0.assign(F.begin(), F.begin() + d);
F1.assign(F.begin() + d, F.end());
if (ask(T0 + F0))
solve(T0 + F0, T1);
else
solve(T1 + F1, T0);
}
}
int main() {
int n = read();
F(n, 0);
std :: basic_string <int> S;
S.resize(n);
std :: iota(S.begin(), S.end(), 1);
solve(S, {});
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
· SQL Server 2025 AI相关能力初探
· 为什么 退出登录 或 修改密码 无法使 token 失效
2020-06-20 [luogu p3743] kotori的设备