Web框架
1 web框架
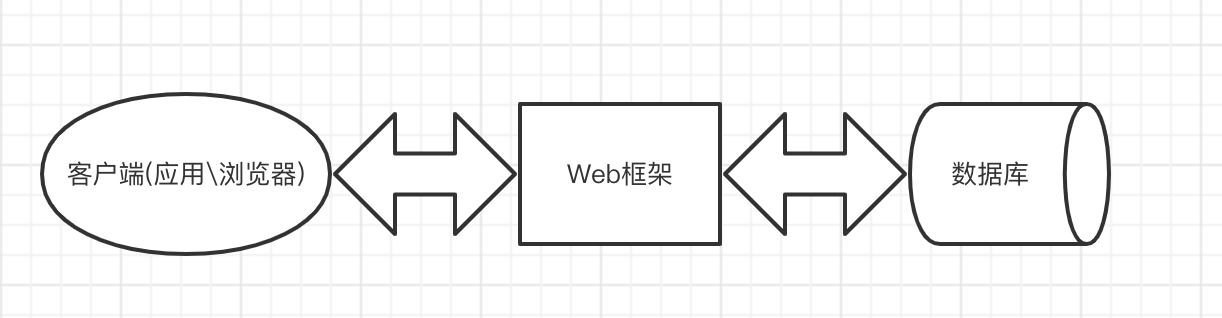
Web框架(Web framework)是一种开发框架,用来支持动态网站、网络应用和网络服务的开发。这大多数的web框架提供了一套开发和部署网站的方式,也为web行为提供了一套通用的方法。web框架已经实现了很多功能,开发人员使用框架提供的方法并且完成自己的业务逻辑,就能快速开发web应用了。浏览器和服务器的是基于HTTP协议进行通信的。
web框架本质上可以看成是一个功能强大的socket服务端,用户的浏览器可以看成是拥有可视化界面的socket客户端。两者通过网络请求实现数据交互,学者们也可以从架构层面上先简单的将Web框架看做是对前端、数据库的全方位整合。
2 纯手撸web框架
2.1 搭建socket服务端
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock, addr = server.accept()
data = sock.recv(1024)
# 此处一会儿需要按照步骤2、3做修改
sock.send(b'hello world')2.2 浏览器发送请求
# 服务端响应的数据需要符合HTTP响应格式
sock.send(b'HTTP1.1 200 OK\r\n\r\nhello world')2.3 路由对应响应
浏览器访问不同的路由(后缀),服务端返回不同的内容
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, addr = server.accept()
data = conn.recv(1024)
# 将客户端请求相关数据先转成字符串,字符串的规律是空格切分,将其切割得到列表,索引1的位置正是url的路由(后缀)
current_path = data.decode('utf-8').split(' ')[1]
conn.send(b'HTTP/1.1 200 ok\r\n\r\n') # 构造出符合http协议格式的数据
# 根据后缀的不同返回不同的内容
if current_path == '/index':
conn.send(b'it is index')
elif current_path == '/login':
conn.send(b'it is login')
else:
conn.send(b'hello world')
# 可以读取文件内容再返回
# with open('a.html', 'rb') as f:
# conn.send(f.read())
conn.close()总结
纯手撸框架缺陷:
1.socket代码过于重复(每次搭建服务端都需要反复造轮子)
2.针对HTTP请求数据没有完善的处理方式(目前只能定向切割),并且只能拿到url后缀,其他数据获取繁琐
3.需要自己处理并发与粘包问题
3.1 wsgiref模块
我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口协议来实现这样的服务器软件,让我们专心用Python编写Web业务。这个接口就是WSGI:Web Server Gateway Interface。而wsgiref模块就是python基于wsgi协议开发的服务模块。
from wsgiref import simple_server
def run(request, response):
"""
:param request: 请求相关的数据
:param response: 响应相关的数据
:return: 返回给客户端的展示数据
"""
response('200 OK', []) # 固定编写 无需掌握
return [b'hello web']
if __name__ == '__main__':
server = simple_server.make_server('127.0.0.1', 8080, run)
'''监听本机8080端口 一旦有请求访问 自动触发run方法的执行'''
server.serve_forever()
# 模块封装了socket代码并将请求数据处理成诸多k:v键值对
# request是一个大字典,包含了http协议请求头里所有数据,还封装了一些其他数据3.3 路由对应响应
# run函数体中添加下列代码
current_path = request.get("PATH_INFO") # request封装的字典,key为"PATH_INFO"对应的就是路由
if current_path == '/login':
return [b'hello login html']
elif current_path == '/register':
return [b'hello register html']
return [b'404 error']3.4 路由拆分流程
1.当有很多路由和响应的情况下不可能无限制编写if判断语句,应该设置对应关系并动态调用
def register(request):
return 'register'
def login(request):
return 'login'
def error(request):
with open(r'templates/error.html', 'r', encoding='utf8') as f:
return f.read()
urls = (
('/login',login),
('/register',register)
)
def run(request, response):
response('200 OK', [])
current_path = request.get("PATH_INFO")
func_name = None
for url_tuple in urls:
if current_path == url_tuple[0]:
# 先获取对应的函数名
func_name = url_tuple[1]
# 一旦匹配上了 后续的对应关系就无需在循环比对了
break
# for循环运行完毕之后 func_name也有可能是None
if func_name:
res = func_name(request) # 执行路由对应的函数,并把request也传给函数 便于后续数据的获取
else:
res = error(request) # 不存在的路由,返回404页面
return [res.encode('utf8')] # 最终返回给浏览器的数据是二进制,要进行编码2.根据功能的不同拆分成不同的py文件
-views.py --存储路由与函数对应关系
# 视图函数
def register(request):
return 'register'
def login(request):
return 'login'
def index(request):
return 'index'
def error(request):
with open(r'templates/error.html', 'r', encoding='utf8') as f:
return f.read()-urls.py --路由与视图函数对应关系
from views import *
# 后缀匹配
urls = (
('/register', register),
('/login', login),
('/index', index),
)-server.py --存储启动及分配代码
from wsgiref import simple_server
from urls import urls
from views import error
def run(request, response):
response('200 OK', [])
current_path = request.get("PATH_INFO")
func_name = None
for url_tuple in urls: # ('/register', register)
if current_path == url_tuple[0]:
func_name = url_tuple[1]
break
if func_name:
res = func_name(request)
else:
res = error(request)
return [res.encode('utf8')]
if __name__ == '__main__':
server = simple_server.make_server('127.0.0.1', 8080, run)
server.serve_forever()总结:拆分后好处在于要想新增一个功能,只需要在views.py中编写函数,urls.py添加对应关系即可
3.模板文件与静态文件
-templates文件夹 --存储html文件
-static文件夹 --存储html页面所需静态资源
4 Jinja2模板语法
后端从数据库获取到数据,如何展示到HTML页面上?
4.1 页面展示当前时间
def get_time(request):
# 1.获取当前时间
import time
c_time = time.strftime('%Y-%m-%d %X')
# 2.读取html文件
with open(r'templates/get_time.html','r',encoding='utf8') as f:
data = f.read()
# 3.思考:如何给字符串添加一些额外的字符串数据>>>:字符串替换
new_data = data.replace('random_str',c_time)
return new_data<h1>展示后端获取的时间数据</h1>
<span>random_str</span>4.2 jinja2模板语法
第三方模块需要先下载后使用
pip3 install jinja2
功能阐述:支持将数据传递到html页面并提供近似于后端的处理方式简单快捷的操作数据
-views.py
from jinja2 import Template
def get_dict(request):
user_dict = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
new_list = [11, 22, 33, 44, 55, 66]
with open(r'templates/get_dict.html', 'r', encoding='utf8') as f:
data = f.read()
temp_obj = Template(data)
res = temp_obj.render({'user':user_dict,'new_list':new_list})
return res-templates --get_dict.html
<h1>字典数据展示</h1>
<p>{{ user }}</p>
<p>{{ user.name }}</p>
<p>{{ user['pwd'] }}</p>
<p>{{ user.get('hobby') }}</p>
<h1>列表数据展示</h1>
<p>
{% for i in new_list%}
<span>元素:{{ i }}</span>
{% endfor %}
</p>
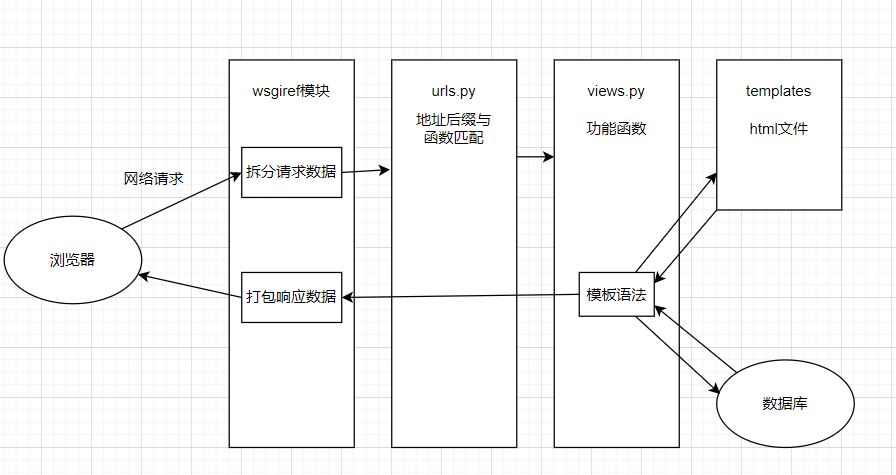
5 框架请求流程


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人