表相关操作
1 存储引擎介绍
日常生活中文件格式有很多中,并且针对不同的文件格式会有对应不同存储方式和处理机制(如:txt, pdf, word, mp4...)
存储引擎就是不同的处理机制
存储引擎即表类型,mysql根据不同的表类型会有不同的处理机制,详见https://www.cnblogs.com/linhaifeng/articles/7213670.html
MySQL的主要存储引擎:
* Innodb
是MySQL5.5版本及之后默认的存储引擎
存储数据更加的安全,支持事务、行锁、外键
创建表对应两个文件,frm表结构、ibd表数据
* myisam
是MySQL5.5版本之前默认的存储引擎
速度要比Innodb更快 但是我们更加注重的是数据的安全
创建对应三个文件,frm表结构、MYD表数据、MYI索引
* memory
内存引擎(数据全部存放在内存中) 断电数据丢失
速度快、临时存储、断电数据丢失,只有frm表结构,数据在内存,无需文件存储
* blackhole
只有frm表结构,没有数据
无论存什么,都立刻消失(黑洞)# 查看所有的存储引擎
show engines;
# 不同的存储引擎在存储表的时候 异同点
# 创建表时可以选择存储引擎,不指定默认为innodb
create table t1(id int) engine=innodb;
create table t2(id int) engine=myisam;
create table t3(id int) engine=blackhole;
create table t4(id int) engine=memory;
# 存数据
insert into t1 values(1);
insert into t2 values(1);
insert into t3 values(1);
insert into t4 values(1);
2 表介绍
表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段。
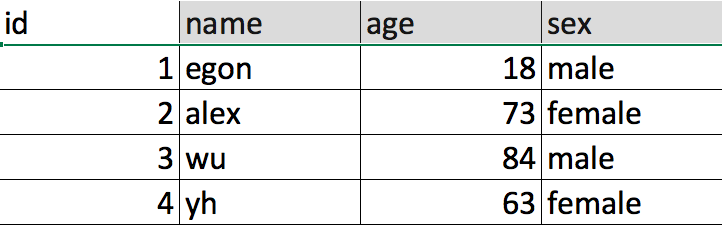
id,name,qq,age称为字段,其余的,一行内容称为一条记录。
3
#语法:
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
#注意:
1. 在同一张表中,字段名是不能相同; 字段名和类型是必须的
2. 宽度和约束条件可选
-宽度如果不设置,默认是1,宽度一般情况下指的是对存储数据的限制,只有整型括号内的数字不表示限制位数,而是显示长度
-约束条件写的话 也支持写多个,约束条件是在宽度的基础上增加的额外的约束,如not null 不能为空
-字段名1 类型(宽度) 约束条件1 约束条件2...,
create table t7(name char); 默认宽度是1
insert into t7 values('jason');
insert into t7 values(null); 关键字NULL
针对不同的版本会出现不同的效果
5.6版本默认没有开启严格模式 规定只能存一个字符你给了多个字符,那么我会自动帮你截取,只能存入'j'
5.7版本及以上默认开启了严格模式 那么规定只能存几个就不能超,一旦超出范围立刻报错 Data too long for ....
3. 最后一行不能有逗号 # create table t6(id int,name char,); 报错
4. MySQL5.7版本默认开启严格模式,必须按规定,不给数据库增加额外压力
-show variables like "%mode"; 查看严格模式
-%匹配任意多个字符
-下划线_ 匹配任意单个字符
5. 修改严格模式
-set session 只在当前窗口有效、临时有效
-set global 全局有效
-set global sql_mode='STRICT_TRANS_TABLES';
MariaDB [(none)]> create database db1 charset utf8;
MariaDB [(none)]> use db1;
MariaDB [db1]> create table t1(
-> id int,
-> name varchar(50),
-> sex enum('male','female'),
-> age int(3)
-> );
MariaDB [db1]> show tables; #查看db1库下所有表名
MariaDB [db1]> desc t1;
+-------+-----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| sex | enum('male','female') | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-----------------------+------+-----+---------+-------+
MariaDB [db1]> show create table t1\G; #查看表详细结构,可加\G
MariaDB [db1]> select id,name,sex,age from t1;
Empty set (0.00 sec)
MariaDB [db1]> select * from t1;
Empty set (0.00 sec)
MariaDB [db1]> select id,name from t1;
Empty set (0.00 sec)往表中插入数据
MariaDB [db1]> insert into t1 values
-> (1,'egon',18,'male'),
-> (2,'alex',81,'female')
-> ;
MariaDB [db1]> select * from t1;
+------+------+------+--------+
| id | name | age | sex |
+------+------+------+--------+
| 1 | egon | 18 | male |
| 2 | alex | 81 | female |
+------+------+------+--------+
MariaDB [db1]> insert into t1(id) values
-> (3),
-> (4);
MariaDB [db1]> select * from t1;
+------+------+------+--------+
| id | name | age | sex |
+------+------+------+--------+
| 1 | egon | 18 | male |
| 2 | alex | 81 | female |
| 3 | NULL | NULL | NULL |
| 4 | NULL | NULL | NULL |
+------+------+------+--------+
4 数据类型
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己的宽度,但宽度是可选的
详细参考:https://www.runoob.com/mysql/mysql-data-types.html
官方5.7文档:https://dev.mysql.com/doc/refman/5.7/en/
mysql常用数据类型概览:
#1. 数字:
整型:tinyinit int bigint
小数:
float :在位数比较短的情况下不精准
double :在位数比较长的情况下不精准
0.000001230123123123
存成:0.000001230000
decimal:(如果用小数,则用推荐使用decimal)
精准
内部原理是以字符串形式去存
#2. 字符串:
char(10):简单粗暴,浪费空间,存取速度快
root存成root000000
varchar:精准,节省空间,存取速度慢
sql优化:创建表时,定长的类型往前放(比如性别),变长的往后放(比如地址或描述信息)
>255个字符,超了就把文件路径存放到数据库中。
比如图片,视频等找一个文件服务器,数据库中只存路径或url。
#3. 时间类型:
最常用:datetime
#4. 枚举类型与集合类型4.1 数值类型
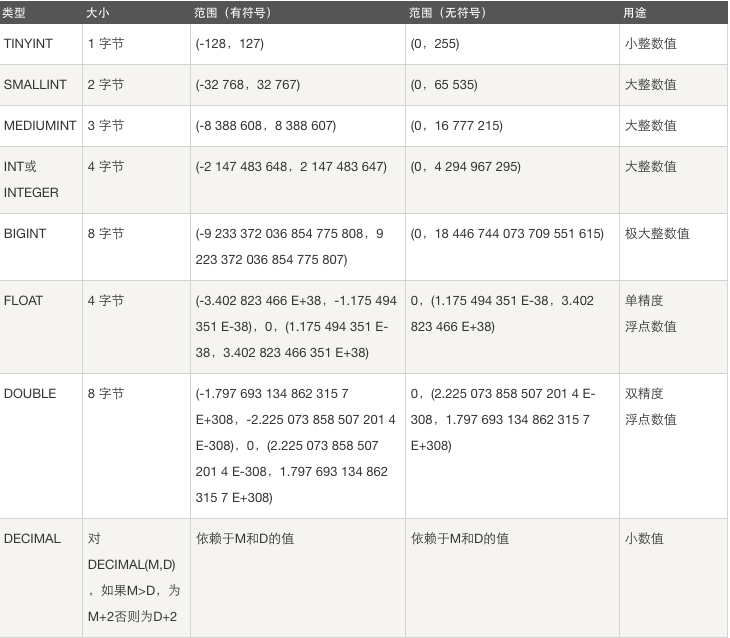
4.1.1 整数类型
整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT
作用:存储年龄,等级,id,各种号码等
========================================
tinyint[(m)] [unsigned] [zerofill]
小整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-128 ~ 127
无符号:
0 ~ 255
PS: MySQL中无布尔值,使用tinyint(1)构造。
========================================
int[(m)][unsigned][zerofill]
整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-2147483648 ~ 2147483647
无符号:
0 ~ 4294967295
========================================
bigint[(m)][unsigned][zerofill]
大整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-9223372036854775808 ~ 9223372036854775807
无符号:
0 ~ 18446744073709551615验证
=========有符号和无符号tinyint==========
#tinyint默认为有符号
MariaDB [db1]> create table t1(x tinyint); #默认为有符号,即数字前有正负号,超出限制只存最大可接受值
MariaDB [db1]> desc t1;
MariaDB [db1]> insert into t1 values
-> (-129),
-> (-128),
-> (127),
-> (128);
MariaDB [db1]> select * from t1;
+------+
| x |
+------+
| -128 | #-129存成了-128
| -128 | #有符号,最小值为-128
| 127 | #有符号,最大值127
| 127 | #128存成了127
+------+
#设置无符号tinyint
MariaDB [db1]> create table t2(x tinyint unsigned);
MariaDB [db1]> insert into t2 values
-> (-1),
-> (0),
-> (255),
-> (256);
MariaDB [db1]> select * from t2;
+------+
| x |
+------+
| 0 | -1存成了0
| 0 | #无符号,最小值为0
| 255 | #无符号,最大值为255
| 255 | #256存成了255
+------+
============有符号和无符号int=============
#int默认为有符号
MariaDB [db1]> create table t3(x int); #默认为有符号整数
MariaDB [db1]> insert into t3 values
-> (-2147483649),
-> (-2147483648),
-> (2147483647),
-> (2147483648);
MariaDB [db1]> select * from t3;
+-------------+
| x |
+-------------+
| -2147483648 | #-2147483649存成了-2147483648
| -2147483648 | #有符号,最小值为-2147483648
| 2147483647 | #有符号,最大值为2147483647
| 2147483647 | #2147483648存成了2147483647
+-------------+
#设置无符号int
MariaDB [db1]> create table t4(x int unsigned);
MariaDB [db1]> insert into t4 values
-> (-1),
-> (0),
-> (4294967295),
-> (4294967296);
MariaDB [db1]> select * from t4;
+------------+
| x |
+------------+
| 0 | #-1存成了0
| 0 | #无符号,最小值为0
| 4294967295 | #无符号,最大值为4294967295
| 4294967295 | #4294967296存成了4294967295
+------------+
==============有符号和无符号bigint=============
MariaDB [db1]> create table t6(x bigint);
MariaDB [db1]> insert into t5 values
-> (-9223372036854775809),
-> (-9223372036854775808),
-> (9223372036854775807),
-> (9223372036854775808);
MariaDB [db1]> select * from t5;
+----------------------+
| x |
+----------------------+
| -9223372036854775808 |
| -9223372036854775808 |
| 9223372036854775807 |
| 9223372036854775807 |
+----------------------+
MariaDB [db1]> create table t6(x bigint unsigned);
MariaDB [db1]> insert into t6 values
-> (-1),
-> (0),
-> (18446744073709551615),
-> (18446744073709551616);
MariaDB [db1]> select * from t6;
+----------------------+
| x |
+----------------------+
| 0 |
| 0 |
| 18446744073709551615 |
| 18446744073709551615 |
+----------------------+
======用zerofill测试整数类型的显示宽度=============
MariaDB [db1]> create table t7(x int(3) zerofill);
MariaDB [db1]> insert into t7 values
-> (1),
-> (11),
-> (111),
-> (1111);
MariaDB [db1]> select * from t7;
+------+
| x |
+------+
| 001 |
| 011 |
| 111 |
| 1111 | #超过宽度限制仍然可以存
+------+注意:为该类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关,存储范围如下
其实我们完全没必要为整数类型指定显示宽度,使用默认的就可以了,默认的显示宽度,都是在最大值的基础上加1
宽度在整型中,指的是数据的显示长度,比如int(8),如果数据不够8位,默认空格补位(不显示),可以用约束条件int(8) zerofill 改成用0补位,就可以显示出来;但超出范围只存最大可接收值
int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok
4.1.2 浮点型
定点数类型 DEC等同于DECIMAL
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、体重、体质参数等
======================================
#FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
有符号:
-3.402823466E+38 to -1.175494351E-38,
1.175494351E-38 to 3.402823466E+38
无符号:
1.175494351E-38 to 3.402823466E+38
精确度:
**** 随着小数的增多,精度变得不准确 ****
======================================
#DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
有符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
2.2250738585072014E-308 to 1.7976931348623157E+308
无符号:
2.2250738585072014E-308 to 1.7976931348623157E+308
精确度:
****随着小数的增多,精度比float要高,但也会变得不准确 ****
======================================
decimal[(m[,d])] [unsigned] [zerofill]
定义:
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
精确度:
**** 随着小数的增多,精度始终准确 ****
对于精确数值计算时需要用此类型
decaimal能够存储精确值的原因在于其内部按照字符串存储。验证
# 存储限制
float(255,30) # 总共255位 小数部分占30位
double(255,30) # 总共255位 小数部分占30位
decimal(65,30) # 总共65位 小数部分占30位
# 精确度验证
create table t1(id float(255,30));
create table t2(id double(255,30));
create table t3(id decimal(65,30));
insert into t1 values(1.111111111111111111111111111111);
insert into t2 values(1.111111111111111111111111111111);
insert into t3 values(1.111111111111111111111111111111);
float < double < decimal
# 要结合实际应用场景 三者都能使用4.2 位类型(了解)
BIT(M)可以用来存放多位二进制数,M范围从1~64,如果不写默认为1位。 注意:对于位字段需要使用函数读取 bin()显示为二进制 hex()显示为十六进制
验证
MariaDB [db1]> create table t9(id bit);
MariaDB [db1]> desc t9; #bit默认宽度为1
+-------+--------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------+------+-----+---------+-------+
| id | bit(1) | YES | | NULL | |
+-------+--------+------+-----+---------+-------+
MariaDB [db1]> insert into t9 values(8);
MariaDB [db1]> select * from t9; #直接查看是无法显示二进制位的
+------+
| id |
+------+
| |
+------+
MariaDB [db1]> select bin(id),hex(id) from t9; #需要转换才能看到
+---------+---------+
| bin(id) | hex(id) |
+---------+---------+
| 1 | 1 |
+---------+---------+
MariaDB [db1]> alter table t9 modify id bit(5);
MariaDB [db1]> insert into t9 values(8);
MariaDB [db1]> select bin(id),hex(id) from t9;
+---------+---------+
| bin(id) | hex(id) |
+---------+---------+
| 1 | 1 |
| 1000 | 8 |
+---------+---------+4.3 日期类型
DATE :年月日 2020-5-4
TIME :时分秒11:11:11
DATETIME : 年月日时分秒 2020-5-4 11:11:11
YEAR : 年 2022
TIMESTAMP :
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
create table student(
id int,
name varchar(16),
born_year year,
birth date,
study_time time,
reg_time datetime
);
insert into student values(1,'egon','1880','1880-11-11','11:11:11','2020-11-11 11:11:11');datetime与timestamp的区别
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。下面就来总结一下两种日期类型的区别。
1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。
2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,操作系统以及客户端连接都有时区的设置。
3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。
4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP),如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
mysql> create table t1(x datetime not null default now()); # 需要指定传入空值时默认取当前时间
Query OK, 0 rows affected (0.01 sec)
mysql> create table t2(x timestamp); # 无需任何设置,在传空值的情况下自动传入当前时间
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t1 values();
Query OK, 1 row affected (0.00 sec)
mysql> insert into t2 values();
Query OK, 1 row affected (0.00 sec)
mysql> select * from t1;
+---------------------+
| x |
+---------------------+
| 2018-07-07 01:26:14 |
+---------------------+
1 row in set (0.00 sec)
mysql> select * from t2;
+---------------------+
| x |
+---------------------+
| 2018-07-07 01:26:17 |
+---------------------+
1 row in set (0.00 sec)4.4 字符串类型
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html
#注意:char和varchar括号内的参数指的都是字符的长度
#char类型:定长,简单粗暴,浪费空间,存取速度快
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储:
存储char类型的值时,会往右填充空格来满足长度
例如:指定长度为char(10),存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储
检索:
在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';)
优点:
存取简单,按几个字符存就按几个字符取,因为有空格补全
缺点:浪费硬盘空间
#varchar类型:变长,精准,节省空间,存取速度慢
字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html)
存储:
varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来
强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535)
例如:varchar(4) 数据超过四个字符直接报错 不够4个字符,有几个存几个
检索:
尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
优点:节省硬盘空间
缺点:存数据要制作报头,取数据先读取报头再读取真实数据,效率比char低一点
例如: 1bytes+egon、1bytes+jason,数据前面加报头,先读报头,报头会告诉你后面的真实数据长度测试前了解两个函数
length:查看字节数
char_length:查看字符数char填充空格来满足固定长度,但是在查询时却会很不要脸地删除尾部的空格(装作自己好像没有浪费过空间一样),然后修改sql_mode让其现出原形
mysql> create table t1(x char(5),y varchar(5));
Query OK, 0 rows affected (0.26 sec)
#char存5个字符,而varchar存4个字符
mysql> insert into t1 values('你瞅啥 ','你瞅啥 ');
Query OK, 1 row affected (0.05 sec)
mysql> SET sql_mode='';
Query OK, 0 rows affected, 1 warning (0.00 sec)
#在检索时char很不要脸地将自己浪费的2个字符给删掉了,装的好像自己没浪费过空间一样,而varchar很老实,存了多少,就显示多少
mysql> select x,char_length(x),y,char_length(y) from t1;
+-----------+----------------+------------+----------------+
| x | char_length(x) | y | char_length(y) |
+-----------+----------------+------------+----------------+
| 你瞅啥 | 3 | 你瞅啥 | 4 |
+-----------+----------------+------------+----------------+
1 row in set (0.00 sec)
#略施小计,让char现出原形 让MySQL不做自动剔除空格操作
mysql> SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';
Query OK, 0 rows affected (0.00 sec)
#这下子char原形毕露了......
mysql> select x,char_length(x),y,char_length(y) from t1;
+-------------+----------------+------------+----------------+
| x | char_length(x) | y | char_length(y) |
+-------------+----------------+------------+----------------+
| 你瞅啥 | 5 | 你瞅啥 | 4 |
+-------------+----------------+------------+----------------+
1 row in set (0.00 sec)
#char类型:3个中文字符+2个空格=11Bytes
#varchar类型:3个中文字符+1个空格=10Bytes
mysql> select x,length(x),y,length(y) from t1;
+-------------+-----------+------------+-----------+
| x | length(x) | y | length(y) |
+-------------+-----------+------------+-----------+
| 你瞅啥 | 11 | 你瞅啥 | 10 |
+-------------+-----------+------------+-----------+
1 row in set (0.00 sec)了解concat
mysql> select concat('数据: ',x,'长度: ',char_length(x)),concat(y,char_length(y)
) from t1;
+------------------------------------------------+--------------------------+
| concat('数据: ',x,'长度: ',char_length(x)) | concat(y,char_length(y)) |
+------------------------------------------------+--------------------------+
| 数据: 你瞅啥 长度: 5 | 你瞅啥 4 |
+------------------------------------------------+--------------------------+
1 row in set (0.00 sec)#InnoDB存储引擎:建议使用VARCHAR类型
单从数据类型的实现机制去考虑,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。
但对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针);
因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列性能要好。
因而,主要的性能因素是数据行使用的存储总量。由于CHAR平均占用的空间多于VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。
#其他字符串系列(效率:char>varchar>text)
TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT
BLOB 系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB
BINARY系列 BINARY VARBINARY
text:text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
mediumtext:A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters.
longtext:A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters.扩展:字符类型可以用于存整数和小数,不存在精确度问题,遇到数学运算,再转型即可。
4.5 枚举类型与集合类型
字段的值只能在给定范围中选择,如单选框,多选框
枚举(enum) 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
集合(set)多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
#枚举类型(enum)
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small');
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','big'); #报错 枚举字段后期在存数据的时候只能从枚举里面选择一个存储
#集合类型(set)
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
INSERT INTO myset (col) VALUES ('a'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
INSERT INTO myset (col) VALUES ('a'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,f'); #报错 集合可以只存入一个,但是不能写没有列举的
5 表完整性约束
5.1 介绍
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性 主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 针对整型,浮点型,默认带符号,改为不带符号
ZEROFILL 针对整型不够位数默认用空格补位,改为用0补位说明:
1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值
2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值
sex enum('male','female') not null default 'male'
age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20
3. 是否是key
主键 primary key
外键 foreign key
索引 (index,unique...)5.2 not null与default
是否可空,null表示空,非字符串 not null - 不可空 null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值 create table tb1( nid int not null defalut 2, num int not null )
验证
==================not null====================
mysql> create table t1(id int); #id字段默认可以插入空
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t1 values(); #可以插入空
mysql> create table t2(id int not null); #设置字段id不为空
mysql> desc t2;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t2 values(); #不能插入空
ERROR 1364 (HY000): Field 'id' doesn't have a default value
==================default====================
#设置id字段有默认值后,则无论id字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值
mysql> create table t3(id int default 1);
mysql> alter table t3 modify id int not null default 1;
==================综合练习====================
mysql> create table student(
-> name varchar(20) not null,
-> age int(3) unsigned not null default 18,
-> sex enum('male','female') default 'male',
-> hobby set('play','study','read','music') default 'play,music'
-> );
mysql> desc student;
+-------+------------------------------------+------+-----+------------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------------------------+------+-----+------------+-------+
| name | varchar(20) | NO | | NULL | |
| age | int(3) unsigned | NO | | 18 | |
| sex | enum('male','female') | YES | | male | |
| hobby | set('play','study','read','music') | YES | | play,music | |
+-------+------------------------------------+------+-----+------------+-------+
mysql> insert into student(name) values('egon');
mysql> select * from student;
+------+-----+------+------------+
| name | age | sex | hobby |
+------+-----+------+------------+
| egon | 18 | male | play,music |
+------+-----+------+------------+补充知识点:插入数据时可以指定字段,表名后加入字段名,传入数据必须一一对应
示例一:
create table t1(
id int,
name char(16)
);
insert into t1(name, id) values('tank', 1)
示例二:
create table user(id int, name char(16), gender enum('male', 'female', 'other') default 'male');
insert into user(id,name) values(1,'egon'); # 注意gender字段设置了默认值,插入数据时,要用指定字段传值,不能直接按位置传值
insert into user values(2,'lqz','female'); # 按位置插入数据,全部字段都要传值5.3 unique
============设置唯一约束 UNIQUE 单例唯一===============
方法一:
create table department1(
id int,
name varchar(20) unique,
comment varchar(100)
);
方法二:
create table department2(
id int,
name varchar(20),
comment varchar(100),
constraint uk_name unique(name)
);
mysql> insert into department1 values(1,'IT','技术');
Query OK, 1 row affected (0.00 sec)
mysql> insert into department1 values(1,'IT','技术'); # name字段是唯一,重复插入报错
ERROR 1062 (23000): Duplicate entry 'IT' for key 'name' not null+unique的化学反应,非空且唯一=主键
mysql> create table t1(id int not null unique);
Query OK, 0 rows affected (0.02 sec)
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
+-------+---------+------+-----+---------+-------+
1 row in set (0.00 sec)联合唯一
create table service(
id int primary key auto_increment,
name varchar(20),
host varchar(15) not null,
port int not null,
unique(host,port) #联合唯一
);
mysql> insert into service values
-> (1,'nginx','192.168.0.10',80),
-> (2,'haproxy','192.168.0.20',80),
-> (3,'mysql','192.168.0.10',3306)
-> ;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into service(name,host,port) values('nginx','192.168.0.10',80); #ip和port单个都可以重复 但是加载一起必须是唯一的
ERROR 1062 (23000): Duplicate entry '192.168.0.10-80' for key 'host' 5.4 primary key
从约束角度看primary key字段的值不为空且唯一,那我们直接使用not null+unique不就可以了吗,要它干什么?
主键primary key是innodb存储引擎组织数据的依据,innodb称之为索引组织表,一张表中必须有且只有一个主键。因为它类似于书的目录,能够帮助提升查询效率并且也是建表的依据。
特殊情况:
1 一张表中有且只有一个主键,如果你没有设置主键,那么会从上往下搜索,直到遇到一个非空且唯一的字段将它自动升级为主键
2 如果表中没有主键,也没有其他任何的非空且唯一字段,那么Innodb会采用自己内部提供的一个隐藏字段作为主键,意味着你无法使用到它,只保证表能够建起来,但无法提升查询速度
3 一张表中通常都应该有一个主键字段,并且通常将id/uid/sid字段作为主键
# 也意味着 以后我们在创建表的时候id字段一定要加primary key一个表中可以:单列做主键 多列做主键(复合主键)
单列主键
============单列做主键===============
#方法一:not null+unique
create table department1(
id int not null unique, #主键
name varchar(20) not null unique,
comment varchar(100)
);
mysql> desc department1;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | NO | UNI | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.01 sec)
#方法二:在某一个字段后用primary key
create table department2(
id int primary key, #主键
name varchar(20),
comment varchar(100)
);
mysql> desc department2;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.00 sec)
#方法三:在所有字段后单独定义primary key
create table department3(
id int,
name varchar(20),
comment varchar(100),
constraint pk_name primary key(id); #创建主键并为其命名pk_name
mysql> desc department3;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.01 sec)多列主键
==================多列做主键================
create table service(
ip varchar(15),
port char(5),
service_name varchar(10) not null,
primary key(ip,port) #多个字段联合起来作为表的主键 本质还是一个主键
);
mysql> desc service;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| ip | varchar(15) | NO | PRI | NULL | |
| port | char(5) | NO | PRI | NULL | |
| service_name | varchar(10) | NO | | NULL | |
+--------------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
mysql> insert into service values
-> ('172.16.45.10','3306','mysqld'),
-> ('172.16.45.11','3306','mariadb')
-> ;
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> insert into service values ('172.16.45.10','3306','nginx');
ERROR 1062 (23000): Duplicate entry '172.16.45.10-3306' for key 'PRIMARY'5.5 auto_increment
约束字段为自动增长,被约束的字段必须同时被key约束
#不指定id,则自动增长
create table student(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') default 'male'
);
mysql> desc student;
+-------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | YES | | male | |
+-------+-----------------------+------+-----+---------+----------------+
mysql> insert into student(name) values
-> ('egon'),
-> ('alex')
-> ;
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
| 2 | alex | male |
+----+------+------+
#也可以指定id
mysql> insert into student values(4,'asb','female');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(7,'wsb','female');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+------+--------+
| id | name | sex |
+----+------+--------+
| 1 | egon | male |
| 2 | alex | male |
| 4 | asb | female |
| 7 | wsb | female |
+----+------+--------+
#对于自增的字段,在用delete删除后,主键的自增不会停止,重新插入的数据序号会接着之前的,不会重新开始排序
mysql> delete from student;
Query OK, 4 rows affected (0.00 sec)
mysql> select * from student;
Empty set (0.00 sec)
mysql> insert into student(name) values('ysb');
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 8 | ysb | male |
+----+------+------+
#应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,并且重置主键,在删除大表时用它
mysql> truncate student;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student(name) values('egon');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
+----+------+------+
1 row in set (0.00 sec)总结:
1、以后在创建表的id(数据的唯一标识id、uid、sid)字段的时候
id int primary key auto_increment
2、auto_increment通常都是加在主键上的 不能给普通字段加
create table t9(
id int primary key auto_increment,
name char(16),
cid int auto_increment
);
ERROR 1075 (42000): Incorrect table definition; there can be only one auto column and it must be defined as a key
3、delete from t1 删除表中数据后 主键的自增不会停止
truncate t1 清空表数据并且重置主键5.6 foreign key
5.6.1 快速理解foreign key
员工信息表有三个字段:工号 姓名 部门
公司有3个部门,但是有1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费。
将所有关联数据放在一张表会出现的问题:
# 1 该表的组织结构不是很清晰,分不清重点(可忽视)
# 2 重复、冗余部分,浪费硬盘空间(可忽视)
# 3 数据的扩展性极差,修改数据不方便(无法忽视的)解决方法:
# 解耦合,将表拆分,拆分后的两张表需要建立相互之间的约束和联系
# 将员工表拆分为员工表和部门表
# 然后让员工信息表关联部门表,如何关联,即foreign key外键:就是用来帮助我们建立表与表之间特殊关系的(建立表与表关系的特殊字段)
5.6.2 一对多表关系
分析步骤:
换位思考,分别站在两张表的角度考虑
员工表与部门表为例
#1 先站在员工表角度
思考一个员工能否对应多个部门(一条员工数据能否对应多条部门数据)
不能!!!
(不能直接得出结论,一定要两张表都考虑完全)
#2 再站在部门表角度
思考一个部门能否对应多个员工(一条部门数据能否对应多条员工数据)
能!!!
#3 得出结论
员工表与部门表是单向的一对多
所以表关系就是一对多##########通过SQL语句建立表关系##########
foreign key
1 一对多表关系 外键字段建在多的一方
2 在创建表的时候 一定要先建被关联表(部门是被关联表,先有部门再有员工)
3 在录入数据的时候 也必须先录入被关联表
# SQL语句建立表关系
create table dep(
id int primary key auto_increment,
dep_name char(16),
dep_desc char(32)
);
create table emp(
id int primary key auto_increment,
name char(16),
gender enum('male','female','others') default 'male',
dep_id int,
foreign key(dep_id) references dep(id) #申明dep_id是一个外键字段,跟dep表中的id字段有关系
);
insert into dep(dep_name,dep_desc) values('sb教学部','教书育人'),('外交部','多人外交'),('nb技术部','技术能力有限部门');
insert into emp(name,dep_id) values('jason',2),('egon',1),('tank',1),('kevin',3);
# 修改dep表里面的id字段
update dep set id=200 where id=2; 不行
# 删除dep表里面id=2的数据
delete from dep where id=2; 不行
# 1 先删除外交部对应的员工数据 之后再删除部门
操作太过繁琐
# 2 真正做到数据之间有关系
更新就同步更新
删除就同步删除
"""
级联更新 >>> 同步更新
级联删除 >>> 同步删除
"""
create table dep(
id int primary key auto_increment,
dep_name char(16),
dep_desc char(32)
);
create table emp(
id int primary key auto_increment,
name char(16),
gender enum('male','female','others') default 'male',
dep_id int,
foreign key(dep_id) references dep(id)
on update cascade # 同步更新
on delete cascade # 同步删除
);
insert into dep(dep_name,dep_desc) values('sb教学部','教书育人'),('外交部','多人外交'),('nb技术部','技术能力有限部门');
insert into emp(name,dep_id) values('jason',2),('egon',1),('tank',1),('kevin',3);5.6.3 多对多表关系
分析步骤:
换位思考,分别站在两张表的角度考虑
书籍表与作者表为例
#1 先站在书籍表角度
思考一本书能否对应多个作者(一条书籍数据能否对应多条作者数据)
能!!! 考虑联合出版的情况
(不能直接得出结论,一定要两张表都考虑完全)
#2 再站在作者表角度
思考一个作者能否对应多本书籍(一条作者数据能否对应多条书籍数据)
能!!!
#3 得出结论
两张表是双向的一对多成立,那么两张表就是“多对多”表关系
书籍表与作者表是多对多关系"""
图书表和作者表
针对多对多字段表关系 不能在两张原有的表中创建外键
需要你单独再开设一张 专门用来存储两张表数据之间的关系
author_id与author表主键关联,book_id与book表主键关联,都是一对多关系
在修改/删除book表时,与author表没有关系,反之同理,都只与“中介”表有关系
"""
create table book(
id int primary key auto_increment,
title varchar(32),
price int
);
create table author(
id int primary key auto_increment,
name varchar(32),
age int
);
create table book2author(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(author_id) references author(id) on update cascade on delete cascade,
foreign key(book_id) references book(id) on update cascade on delete cascade
);| id | book_id | author_id |
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
5.6.4 一对一表关系
分析步骤:
换位思考,分别站在两张表的角度考虑
id name age addr phone hobby email........
如果一个表的字段特别多,每次查询又不是所有的字段都能用得到,可以将表一分为二
作者表拆分
作者表
id name age
作者详情表
id addr phone hobby email........
作者表与作者详情表为例
#站在作者表角度
一个作者能否对应多个作者详情 不能!!!
#站在作者详情表角度
一个详情能否属于多个作者 不能!!!
#结论:
两张表单向的一对多都不成立,那么这个时候两者之间的表关系就是一对一 或者没有关系# 一对一表关系 外键字段建在任意一方都可以,但是推荐你建在查询频率比较高的表中
create table authordetail(
id int primary key auto_increment,
phone int,
addr varchar(64)
);
create table author(
id int primary key auto_increment,
name varchar(32),
age int,
authordetail_id int unique, #外键额外加限制条件,因为两张表数据是一一对应,不能一对多,必须是唯一的
foreign key(authordetail_id) references authordetail(id)
on update cascade
on delete cascade
)5.6.5 补充
表与表之间如果有关系的话,可以有两种建立联系的方式
1、通过外键强制性建立关系
2、通过sql语句逻辑层面上建立关系
在实际项目中,创建外键会消耗一定的资源,并且增加了表与表之间的契合度(强制建立了外键关联,数据增删改都需要严格遵循表之间的关联)
如果表特别多,可以直接通过SQL语句来建立逻辑层面上的关系,如DjangoORM设置外键时,设置db_constraint=False,表示逻辑上的关联,没有强制外键联系
6 修改表ALTER TABLE
语法:
1. 修改表名
ALTER TABLE 表名 RENAME 新表名;
2. 增加字段
ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…], #默认加在尾部
ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST; #加在最开始
ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; #加在某个字段后
3. 删除字段
ALTER TABLE 表名 DROP 字段名;
4. 修改字段
ALTER TABLE 表名 MODIFY 字段名 数据类型 [完整性约束条件…]; #用来修改字段类型、约束条件等
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…]; #修改字段名字
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];示例
示例:
1. 修改存储引擎
mysql> alter table service
-> engine=innodb;
2. 添加字段
mysql> alter table student10
-> add name varchar(20) not null,
-> add age int(3) not null default 22;
mysql> alter table student10
-> add stu_num varchar(10) not null after name; #添加name字段之后
mysql> alter table student10
-> add sex enum('male','female') default 'male' first; #添加到最前面
3. 删除字段
mysql> alter table student10
-> drop sex;
mysql> alter table service
-> drop mac;
4. 修改字段类型modify
mysql> alter table student10
-> modify age int(3);
mysql> alter table student10
-> modify id int(11) not null primary key auto_increment; #修改为主键
5. 增加约束(针对已有的主键增加auto_increment)
mysql> alter table student10 modify id int(11) not null primary key auto_increment;
ERROR 1068 (42000): Multiple primary key defined
mysql> alter table student10 modify id int(11) not null auto_increment;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
6. 对已经存在的表增加复合主键
mysql> alter table service2
-> add primary key(host_ip,port);
7. 增加主键
mysql> alter table student1
-> modify name varchar(10) not null primary key;
8. 增加主键和自动增长
mysql> alter table student1
-> modify id int not null primary key auto_increment;
9. 删除主键
a. 删除自增约束
mysql> alter table student10 modify id int(11) not null;
b. 删除主键
mysql> alter table student10
-> drop primary key;7 复制表
我们sql语句查询的结果其实也是一张虚拟表
复制表结构+记录 (key不会复制: 主键、外键和索引)
mysql> create table new_service select * from service; #不能复制主键、外键、索引,只复制表结构与表数据
只复制表结构
mysql> select * from service where 1=2; #条件为假,查不到任何记录
Empty set (0.00 sec)
mysql> create table new1_service select * from service where 1=2; #复制时可以添加条件,当不符合条件时,会创建一个新表
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> create table t4 like employees;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人